
LLM продолжают свое пребывание в центре технологических дискуссий. Они трансформируют наши взаимодействия с технологиями, поскольку предоставляют возможность усовершенствованной работы в обработке и генерации текстов. Однако и упомянутые модели не идеальны, так как одна из их самых значительных проблем - галлюцинации, критическое препятствие в развитии LLM, возникающие в основном из-за качества обучающих данных, поскольку они могут быть неполными или противоречивыми.
Для эффективной работы с LLM крайне важно понимать что такое, эти "галлюцинации" и как их обнаружить. В статье мы опробуем обнаружение галлюцинаций, исследуя различные метрики сходства текста, и проанализируем их релевантность.
Что это такое?
Дадим следующее определение галлюцинации (hallucination) - это сгенерированный контент, который не соответствует оригинальному предоставленному материалу и не имеет логической ценности. Исходником, или оригинальным предоставленным материалом, может служить, например, мировое знание, если задача представляет собой вопросно-ответную систему.
Для примера рассмотрим как раз формат вопроса-ответа:

Начнем с более простых в проверке утверждений, которые маловероятно могут служить галлюцинацией.
Попробуем другое:

Здесь мы не задаем контекста, оттого получаем неверный ответ, точнее он может быть правильным, но не в нашем случае, поскольку мы спрашивали именно про модели (мы можем это легко исправить, расписав наш вопрос более детально).
Или пример из другой статьи про галлюцинации:

На первый взгляд выглядит как последовательный и убедительный ответ, однако, если мы зададимся вопросом "а правда ли это?", мы не сможем ни подтвердить, ни опровергнуть ответ модели, поскольку не обладаем достаточным количеством информации. Мы не имеем контекста с подтвержденными фактами для проверки полученного утверждения. Вполне возможно, что такого человека в принципе не существовало. Можем считать это той самой галлюцинацией.
Предлагаю перейти к метрикам сходства текста, с помощью которых мы сможем обнаружить галлюцинацию LLM.
BertScore
BertScore представляет собой метод оценки качества суммаризации текстов, который оценивает степень схожести текстового резюме с исходным документом.
BertScore успешно преодолевает две ключевые сложности, характерные для метрик, основанных на анализе n-грамм. Во-первых, методология n-грамм зачастую неадекватно оценивает парафразирование, так как семантически верные выражения могут существенно отличаться от формулировок в эталонном тексте, что порождает ошибки в оценке качества. В отличие от этого, BertScore использует контекстно-зависимые векторные представления слов, что демонстрирует большую точность в распознавании смысловых нюансов. Во-вторых, методы, базирующиеся на n-граммах, не способны уловить дальнодействующие лексические связи и часто неправильно оценивают семантически обоснованные изменения порядка слов.

Шаг 1: Создание контекстуальных векторов: Эталонные тексты и предлагаемые варианты текста кодируются в контекстуальные векторы, которые учитывают окружающие слова. Эти векторы получаются с помощью передовых моделей, таких как BERT, Roberta, XLNET и XLM.
Шаг 2: Определение косинусного сходства: Векторные представления эталонных и кандидатских текстов сравниваются, чтобы определить степень их схожести, используя метод косинусного сходства.
Шаг 3: Выравнивание токенов для оценки точности и полноты: Каждый токен из предложенного текста сопоставляется с наиболее подходящим токеном из эталонного текста и наоборот. Это позволяет оценить точность и полноту перевода. Результаты этих оценок затем объединяются для расчёта итогового показателя F1.

Шаг 4: Придание веса редким словам: Применяется обратная частота документов (IDF), чтобы учесть значимость редких слов, повышая их вес в расчёте BERTScore. Это внедрение не является обязательным и может варьироваться в зависимости от специфики задачи.
Шаг 5: Нормализация результатов: Чтобы сделать результаты BERTScore более понятными для человека, они подвергаются линейному масштабированию. Таким образом, значения приводятся к диапазону, который легче интерпретировать, с использованием данных из монолингвальных корпусов, таких как Common Crawl.
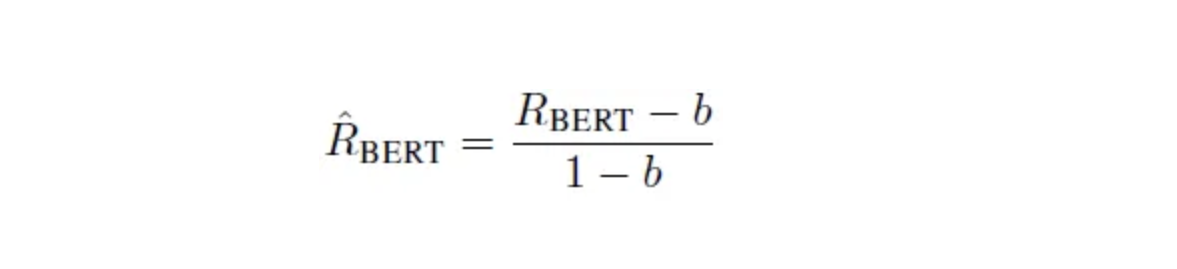
# Импорт функции загрузки из модуля evaluate
from evaluate import load
try:
# Загрузка модель BERT для оценки
bert_model = load("bert")
# Задаем текст запроса и ответа
original_text = "В этой статье мы будем обнаруживать галлюцинации в наших данных,..."
translated_text = "Галлюцинации в данных представляют собой неточные или несвязанные с запросами ответы..."
# Вычисление оценку BERT для перевода
bert_result = bert_model.compute(predictions=[translated_response], references=[original_prompt])
# Вывод результат
print("Результат оценки BERT:", bert_result)
except Exception as e:
# Обработка исключения при ошибке загрузки или вычисления
print("Произошла ошибка:", e)Задействуя метод расчета косинусного сходства между векторами каждого слова в тексте запроса и ответа, оценка BERT дает возможность точнее измерить семантическое соответствие. Этот метод показывает особенно хорошие результаты в случаях, когда ответы сформулированы иными словами: хотя буквальное совпадение слов может быть невелико, сохраняется общий смысл высказывания.
from whylogs.util import WhyLogs
from whylogs.metrics import BERTScore
from evaluate import load # Предполагается, что функция load определена в модуле evaluate
Инициализация объекта WhyLogs
whylogs = WhyLogs()
Определение пользовательской метрики для оценки BERTScore
@whylogs.register_metric("bert_score")
def compute_bert_score(text):
# Проверка наличия загруженной модели BERT перед использованием
if "bert" not in globals():
raise ValueError("Model 'bert' is not loaded. Please load it before using.")
# Вычисление оценки BERTScore
result = bert.compute(predictions=[text["response"]], references=[text["prompt"]])
return [result["f1"]]
# Применение пользовательской метрики к данным
annotated_chats = whylogs.applyUDFsFromSchema(CHATS_DATASET)
# Вывод первых 10 записей с BERTScore менее 0.5
filtered_chats = annotated_chats[annotated_chats["bert_score"] < 0.5]
print(filtered_chats.head(10))Анализируя распределение оценок BERT и рассматривая случаи с низкими значениями, мы можем обнаружить потенциальные отклонения в ответах, которые значительно меняют семантическое содержание по сравнению с запросом. Тем не менее, следует учесть, что иногда даже корректные ответы могут получать низкие оценки BERT, если тематика или контекст ответа отличается от того, что представлен в запросе.
BLEU Score
BLEU (Bilingual Evaluation Understudy) представляет собой метрику для оценки качества автоматического перевода текстов, сравнивая его с одним или несколькими эталонными переводами.
Оценка BLEU, выраженная числом между 0 и 1, отражает степень соответствия машинного перевода эталонным версиям: 0 указывает на отсутствие совпадений (низкое качество), тогда как 1 свидетельствует о полном совпадении (высокое качество).
Как правило, оценка BLEU снижается по мере удлинения переводимого предложения. Тем не менее, степень этого снижения может отличаться в зависимости от конкретной модели перевода, применяемой в процессе. Для наглядности приведем график, который демонстрирует изменение оценки BLEU в зависимости от длины предложения:

С математической точки зрения, формулу можно отобразить так:
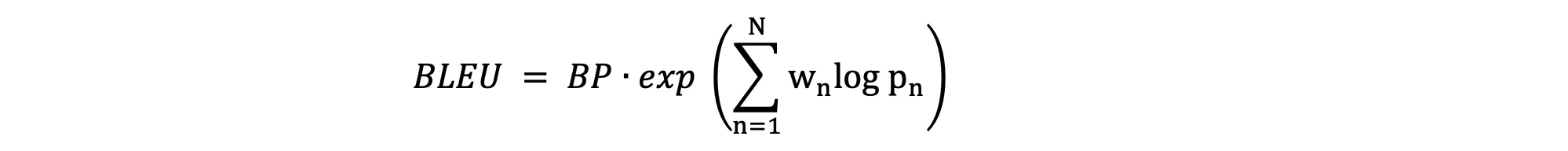
Здесь BP является Brevity Penalty, который можно определить так:
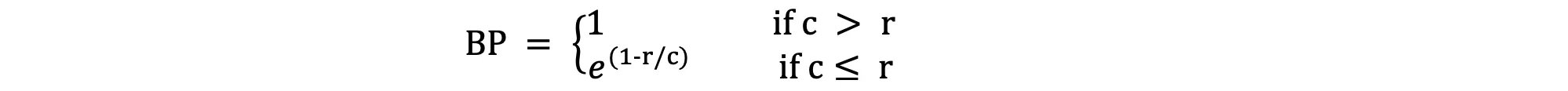
И - это модифицированный балл точности, который определяется как:

Необходимо учитывать, что, несмотря на полезность оценок BLEU, они обладают рядом ограничений. Величина оценки может сильно изменяться в зависимости от выбранного набора данных, что делает сложным определение общих стандартов качества. Помимо этого, оценки BLEU основаны исключительно на сравнении отдельных слов или фраз, что может привести к упущению из виду семантических нюансов.
# Импорт функции load из модуля evaluate
from evaluate import load
try:
# Загрузка языковой модели для оценки качества
language_model = load("blue")
# Задание текста запроса и ответа
original_text = "В этой статье мы будем обнаруживать галлюцинации в наших данных,..."
translated_text = "Галлюцинации в данных представляют собой неточные или несвязанные с запросами ответы..."
# Вычисление оценки с использованием языковой модели
blue_score = language_model.compute(predictions=[translated_text], references=[[original_text]])
# Вывод результата оценки
print("Blue score:", blue_score)
except Exception as e:
# Обработка исключений при возникновении ошибок
print("An error occurred:", e)
Через процесс визуализации распределения оценок BLEU и детального рассмотрения примеров с низкими показателями можно выявить возможные случаи галлюцинаций в переводе. Однако крайне важно учитывать, что низкие оценки BLEU не всегда свидетельствуют о галлюцинациях; они могут также отражать различия в стиле изложения или понимании смысла.
from whylogs.util import WhyLogs
from whylogs.metrics import BleuScore
# Инициализация объекта WhyLogs
whylogs = WhyLogs()
# Определение пользовательской метрики для BLEU-оценки
@whylogs.register_metric("bleu_score")
def compute_bleu_score(text):
blue_score = blue.compute(predictions=[text["response"]], references=[[text["prompt"]]])
return [blue_score["blue"]]
# Применение пользовательской метрики к данным
annotated_chats = whylogs.applyUDFsFromSchema(CHATS_DATASET)
# Группировка данных по BLEU-оценке и вывод первых 10 результатов
bleu_scores_grouped = annotated_chats.groupby("bleu_score").count().reset_index()
top_10_bleu_scores = bleu_scores_grouped.sort_values("bleu_score", ascending=True).head(10)
print(top_10_bleu_scores)Response Self-Similarity
Сопоставление запросов и ответов может предоставить значимые взгляды, но для глубокого понимания феномена галлюцинаций более продуктивно сравнивать различные ответы, созданные одной языковой моделью на один и тот же запрос. Такая методика, которую называют Response Self-Similarity, дает возможность оценить устойчивость и консистентность результатов, предоставляемых языковой моделью.
Для расчета Response Self-Similarity мы применяем векторные представления, которые отражают смысловую нагрузку целых фраз или текстовых фрагментов, вместо анализа индивидуальных слов. Измеряя косинусное расстояние между такими векторными представлениями оригинального ответа и его вариаций, мы можем точно определить уровень их взаимного сходства.
from sentence_transformers import SentenceTransformer
from whylogs.util import WhyLogs
from whylogs.metrics import SentenceEmbeddingSelfSimilarity
from sentence_transformers.util import cos_sim
# Загрузка модели SentenceTransformer для получения векторных представлений предложений
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Задание трех ответов
response1 = "Галлюцинации в данных представляют собой неточные или несвязанные с запросами ответы..."
response2 = "Галлюцинации возникают, когда LLM генерирует ответы, которые не имеют отношения или фактически неверны."
response3 = "Галлюцинации - это явление, когда LLM производит выводы, не связанные с входным запросом."
# Получение векторных представлений для каждого ответа
embedding1 = model.encode(response1)
embedding2 = model.encode(response2)
embedding3 = model.encode(response3)
# Инициализация объекта WhyLogs для записи метрик
wl = WhyLogs()
# Определение пользовательской метрики для оценки самоподобия ответов
@wl.register_metric("response_self_similarity")
def response_self_similarity(text):
embeddings = [
model.encode(text["response"]),
model.encode(text["response2"]),
model.encode(text["response3"])
]
# Рассчитываем косинусное сходство между векторами предложений
similarities = [cos_sim(embeddings[0], embedding) for embedding in embeddings[1:]]
# Среднее значение сходства
return [sum(similarities) / len(similarities)]
# Применение пользовательской метрики к данным
annotated_chats = wl.applyUDFsFromSchema(CHATS_DATASET)
# Вывод первых 10 записей с самоподобием ответов менее 0.8
filtered_chats = annotated_chats[annotated_chats["response_self_similarity"] < 0.8]
print(filtered_chats.head(10))Через визуализацию распределения оценок Response Self-Similarity и детальный анализ случаев с низкими значениями, мы имеем возможность обнаружить ситуации, когда ответы, сгенерированные языковой моделью, заметно отличаются друг от друга. Это может свидетельствовать о наличии галлюцинаций или нестыковках в логике модели.
LLM Self-Evaluation
Существующие метрики для анализа текстовых данных часто опираются на фиксированные алгоритмы и модели для определения схожести текстов. Однако мы можем также задействовать возможности самих LLM для оценки уровня однородности и взаимосвязи их собственных ответов. Этот метод, известный как LLM Self-Evaluation, включает в себя обращение к LLM с просьбой оценить последовательность и актуальность её же ответов.

LLM Self-Evaluation охватывает ряд ключевых аспектов: языковую выразительность, логическую согласованность, понимание контекста, точность в отражении фактов и способность создавать ответы, которые не только соответствуют теме, но и несут в себе значимую информацию.
Для того чтобы инициировать самооценку с помощью LLM, мы можем сформулировать запрос, который представляет разнообразие ответов, и попросить модель оценить их взаимную согласованность или схожесть. В качестве примера можно привести следующее:
import openai
# Функция для оценки самоподобия ответов LLM
def evaluate_self_similarity(data, index):
# Создание промпта для запроса оценки согласованности
prompt = f"""
Контекст: {data.loc[index, 'prompt']}
Ответ 1: {data.loc[index, 'response']}
Ответ 2: {data.loc[index, 'response2']}
Ответ 3: {data.loc[index, 'response3']}
Оцените согласованность Ответа 1 с предоставленным контекстом (Ответами 2 и 3) на шкале от 0 до 1, где 0 означает полное несоответствие, а 1 - полное соответствие.
"""
try:
# Запрос оценки согласованности у модели OpenAI
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=100,
n=1,
stop=None,
temperature=0.7,
)
# Возвращение текста оценки согласованности
return response.choices[0].text.strip()
except Exception as e:
# В случае возникновения ошибки выводим сообщение об ошибке
print("An error occurred while evaluating self-similarity:", e)
return None
# Инициализация объекта WhyLogs для записи метрик
wl = WhyLogs()
# Определение пользовательской метрики для оценки самоподобия
@wl.register_metric("prompted_self_similarity")
def prompted_self_similarity(text):
# Вызов функции для оценки самоподобия ответов
similarity_score = evaluate_self_similarity(text, text.name)
# Преобразование результата в числовой формат и возвращение
return [float(similarity_score)] if similarity_score is not None else None
# Применение пользовательской метрики к данным
annotated_chats = wl.applyUDFsFromSchema(CHATS_DATASET)
# Вывод первых 10 записей с оценкой самоподобия менее 0.8
filtered_chats = annotated_chats[annotated_chats["prompted_self_similarity"] < 0.8]
print(filtered_chats.head(10))
Запросив у LLM оценку степени согласованности и похожести между его собственными ответами, мы можем эффективно задействовать его языковые аналитические способности для выявления возможных недочетов в логике или галлюцинаций. Однако следует учитывать, что достижение однородности в ответах LLM может быть затруднено из-за переменчивости того, как модель интерпретирует запросы.
Один из возможных путей усовершенствования этой стратегии — попросить LLM предоставить оценку отдельных фраз или конкретных элементов ответа, вместо выдачи универсальной числовой оценки.
Подводя итоги, мы поговорили о галлюцинациях, что затормаживают нашу работу с нейросетью, а также рассмотрели различные методы выявления галлюцинаций в LLM. Проблема не сказать чтобы очень новая, но я совру, если обзову ее старой, а потому крайне важно искать возможные решения для ее обнаружения.
Методы имеют свои плюсы и минусы (как впрочем и все, что нас окружает), надеюсь, эта статья смогла дать ответы на ваши вопросы или хотя бы подтолкнула к размышлениям в поиске своего решения этой проблемы.
Спасибо за прочтение(: Будем рады видеть вас в комментариях!
Комментарии (4)

phenik
04.04.2024 19:30Как обнаружить галлюцинации в LLM?
Современные нейросети еще не могут галлюцинировать) По определению галлюцинации возникают без внешнего стимула, т.е. в случае ИНС без внешнего ввода. Пока они не активные, а статические решения, вопрос - ответные. Галлюцинации больше соответствуют зрительным образам, т.е. генераторам изображений, с их многопальцами) Это больше похоже на фантазирование на заданную тему. А фантазирование одна из основ творчества, особенно литературного. Бороться нужно с избыточным фантазированием, ложью. Это достигается введение аналога логического уровня мышления, а также критического уровня, вообще типов мышления много. ЯМ реализуют в основном один уровень ассоциативного мышления (Система 1, быстрое мышление в двухуровневой модели мышления Каннемана; логический, медленный уровень мышления соответствует Системе 2). В этих публикациях 1, 2 предлагаются некоторые решения на эту тему. Галлюцинации, бред без внешней причины могут возникнуть возможно в нейроморфных сетях, которые больше соответствуют по своим свойствам биологическим прототипам, т.к. могут содержать некотрые аналоги генераторов спонтанной активности в НС, и активироваться от неспецифических воздействий в условиях соответствующих депривации. Хотя термин, введенный без должного анализа уже устоялся, но вызывает некоторое недоумение у знакомых с терминологией принятой в психофизиологии, и может влиять на адекватность выбора средств борьбы с ним.
rPman
Т.е. сначала мы генерируем текст а затем пытаемся разобраться с тем что намудрили...
Так как генерация текста это случайный процесс, происходящий (обычно, но само собой не обязательно) последовательно слева на право, то каждый раз, когда алгоритм принимает решение о выборе следующего слова (токена), он добавляет ответу хаотичности. Да, чем лучше внутри LLM построена модель знаний, тем с большими шансами она будет пытаться выйти на верное реение, т.е. если следующий токен ухудшил ситуацию с верным ответом, сеть попытается выкрутиться и следующими сообщениями вернуть смысл на место.. само собой это не всегда возможно, но возможно часто потому что чаще всего разные токены это некая вода в тексте - не критичный шум, без которого можно было бы обойтись, но великий рандом заставил выбрать именно этот путь.
Собственно это и есть одна из причин галлюцинаций, да, конечно, сама сеть не идеально строит модель знаний внутри себя, она тоже шумит, и этот шум вылезает в разбросе между полученными вероятностями для следующего токена и фактическими, теми что предполагает запрос в действительности. Простой пример - мы просим (llm обученную только складывать цифры) сложить два числа '2+3=' и фактические вероятности должны быть '5' - 100%, остальные цифры 0%, но сеть выдаст что то типа '5' - 85% и каждая цифра тоже какой то процент +-1%, и алгоритмы рандомизации токена с некоторой не нулевой вероятностью могут выбрать не максимально верное значение а рядом стоящее....
И да, если отключить рандомизацию temp=0 то проблема шумящей области знаний внутри вылезет другим боком (например зацикливание - повторение символов).
К сожалению, не существует красивого алгоритма принятия решения (но исследователи стараются) шаг за шагом... но скорее всего это можно сделать, если позволить алгоритму делать шаг назад, т.е. сгенерировав несколько токенов, и если видно что получается что то не то, вернуться назад и выбрать другой токен.
p.s. Если задача может быть валидирована после (например генерация кода, который можно проверить, запустив его после) то можно решать задачу перебором всех ветвей дерева выбора токенов (и соответственно оптимизацию вести в этом направлении, зайдя внутрь нейронки).
riv9231
Недавно мне порекомендовали вот этот ролик посмотреть о создании бота через какой-то китайский сервис. Бот получился неожиданно полезный, например может находить промокоды :-) Но я не об этом. Я использовал его, в основном как кодер и иногда спрашивал про ошибки в логах linux. И вот этот бот явно под капотом что-то подобное имеет. По тому что иногда он вместо ответа выдает что-то типа:
команда завершилась ошибкой, тогда попробуем по другому: ... далее идет "другое" решение.
Интересно то, что когда я его спросил, а какую именно команду он пытался выполнить, оказалось, что он все сделал правильно, просто в его песочнице окружение не подразумевает корректную работу этой команды (речь шла об ipmitools и управлении вентиляторами), а у меня все сработало правильно.
И ещё интересно вот что. Там явно какие-то необычные приемы используются. Например я проверю модели так, начинаю с ними беседовать о космонавтах подлетающих к горизонту событий черной дыры. Довольно быстро модели либо начинают противоречить сами себе, либо впадают в мразматическое морализаторство, предупреждая об опасности черной дыры для космонавтов, в общем теряют нить разговора.
С этим ботом такого не происходит: он стоит на своём, иногда приводит ссылки на научные работы, уверенно отстаивает устоявшиеся научные представления, не давая себя стаскивать путем многократного построения ложных утверждений.
Подведу итог: там точно используются песочницы, бот может обращаться к интернету в реальном времени, по видимому, он перепроверяет свои же собственные высказывания и когда они его не удовлетворяют, генерация длится намного дольше, чем обычно.
excoder
Спасибо, попробуем!