

В Отусе я прошла курс ML Advanced и открыла для себя интересные темы, связанные с анализом временных рядов, а именно, их сегментацию и кластеризацию. Я решила позаимствовать полученные знания для своей дипломной университетской работы по ивент-анализу социальных явлений и событий и описать часть этого исследования в данной статье.
Шаг 1. Сбор данных
В качестве источника данных я взяла информационно-новостной ресурс Лента.ру, так как с него легко парсить данные, новости разнообразны и пополняются в большом объеме ежедневно. Для теста я спарсила новости за последний год (март 2023 – март 2024) с помощью питоновских BeautifulSoup и requests.
В коде происходит процедура сбора заголовка, даты и тематики новостей:
dates = []
topics = []
titles = []
for day in range(1,366):
num_pages = 1
while True: #получить все новости за дату разом нельзя, как и узнать количество страниц, поэтому пришлось прибегнуть к while:
date = ((datetime.datetime.today() - datetime.timedelta(days=day)).strftime('%Y/%m/%d')
link = requests_session.get('https://lenta.ru/{}/page/{}/'.format(date, num_pages))
soup = BeautifulSoup(link.text, 'lxml')
news_list = soup.find_all('a', {"class": "card-full-news _archive"}, href=True)
if len(news_list) == 0: #если на странице нет новостей, переходим к следующей дате
break
for news in news_list: #собираем данные по каждой новости
dates.append(date)
title = news.find_all('h3', {"class": "card-full-news__title"})
titles.append((titles[0].get_text() if len(title) > 0 else 'None'))
topic = news.find_all('span', {"class": "card-full-news__info-item card-full-news__rubric"})
topics.append((topic[0].get_text() if len(topic) > 0 else 'None'))
num_pages+=1
df = pd.DataFrame({'dates': dates, 'topics': topics, 'titles': titles })Итого, после удаления ненужных категорий, получился датасет из ~93000 новостей:

Шаг 2. Формирование датасета
Немного отвлекусь на сам ивент-анализ. Как метод политической науки он зародился в 1960-х годах в научных трудах Чарльза Макклелланда. Ивент-анализ - это метод качественного исследования, который используется для описания и объяснения социального поведения и взаимодействий.
Первый шаг из классической методологии я уже сделала – собрала данные. Вторым шагом идет определение системы так называемых классификаторов: проще говоря, категорий, по которым эти данные надо проклассифицировать для дальнейшего анализа. Сначала я брала в качестве классификаторов готовые рубрики новостей с Ленты, но, посмотрев на их список, можно увидеть, что они не особо репрезентативны для социальной сферы и вряд ли из них можно получить интересные результаты: Экономика, Наука и техника, Путешествия, Силовые структуры, Нацпроекты, Среда обитания, Забота о себе, Спорт, Интернет и СМИ, Россия, Бизнес, Бывший СССР, Ценности, Мир, Культура, Дом, Оружие.
Поэтому я решила составить свои классификаторы. Сначала получила списки предварительных, более узких категорий для базовых рубрик, обучив Word2Vec на новостных заголовках. Это помогло определить те темы, которые освечиваются на данном новостном ресурсе, а не выбирать наугад. Фрагмент результатов определения топа слов с самыми близкими векторами:
Исходная категория |
Список самых контексто-близких слов |
Экономика |
кризис, отрасль, инфляция, нефть, промышленность, энергетика, дефолт, рынок, энергокризис, бюджет, безработица, ввп, госдолг, бедность, неурожай, газ, инвестор, рецессия, экспорт, рождаемость |
Политика |
стратегия, разногласие, демократия, союзник, кризис, санкции, русофобия, суверенитет, импичмент, конституция, альянс, распад, реформа, заговор, дефолт, революция, война, государство, преступление |
СМИ |
телеканал, журналист, издание, олигарх, хакер, политик, спецслужба, дипломат, роскомнадзор, пропаганда, telegram, facebook, оппозиция, цензура, сайт, meta, минюст, иноагент, блокировка, соцсеть |
Технологии |
инновации, интеллект, наука, алгоритм, импортозамещение, корпорация, нейросеть, медицина, промышленность, инвестиции, туризм, космос, исследование, образование, мониторинг, экосистема, сколково, модернизация, виртуальный, микроэлектроника |
Культура |
национальный, народный, студенческий, музыкальный, молодёжный, патриотический, архитектура, искусство, фестиваль, литература, наследие, общество, театральный, музей, кинофестиваль, язык, возрождение, концертный, фотовыставка, цифровизация |
Далее сформировала из полученных слов список тематик таким образом, чтобы они имели выраженную эмоциональную окраску – так анализ выйдет более интересным и информативным. Затем несколько раз прогоняла и в полуавтоматическом режиме модифицировала списки новых категорий-классификаторов на готовой модели Zero-shot классификации mDeBERTa-v3-base-mnli-xnli, пока не получила средний скор модели для каждого классификатора > 0.8.
Из этого можно сделать вывод, что я более или менее охватила базовый набор категорий, которые можно привязать к социальной сфере и их формулировки при этом были понятны модели, нет явных новостей-«изгоев», по которым не нашлось подходящего класса. Конечно, какие-то классификаторы получились более широкими и охваченными, а какие-то – более узконаправленными, но тут еще есть, куда расти)
На итоговом списке классификаторов я уже получила такое частотное распределение:

Как видно, проблемы в новостях все-таки любят освещать больше) Но тут следует делать поправки на то, что модель тематической классификации не всегда идеально определяет контекст, плюс некоторые сообщения имеют нейтральную эмоциональную окраску, но для получения общей картинки это хороший и быстрый вариант.
Шаг 3. Сегментация временных рядов
Переходим, собственно, к временным рядам, а именно, к их сегментации. Временные ряды я строила отдельно для каждого классификатора, где по оси x – дата, по оси y – количество новостей по данному классификатору за эту дату. Для сегментации был использован алгоритм PELT. Алгоритм ищет набор точек «перегиба» для заданного временного ряда таким образом, чтобы их количество и местоположение минимизировали заданную «стоимость» сегментации.
Основные шаги алгоритма заключаются в определении функции «стоимости» для сегмента, затем итерации по всем возможным начальным и конечным точкам сегмента и проверке того, уменьшает ли разделение на новые сегменты значение функции стоимости по сравнению с сегментом без разделения.
Общая форма функции потерь:

Здесь C – функция «стоимости» сегмента, t – точка «перегиба», m – общее количество точек «перегиба», βf(m) – регуляризатор для предотвращения переобучения.
Было выявлено, что точки минимума и периоды сниженной новостной активности на временных рядах совпадают с праздничными днями и выходными. Поэтому данные по этим дням были удалены из выборки, чтобы временные ряды получились более сглаженными и не находилось ложных корреляций.
Для решения задачи я использовала библиотеку ruptures.
Для параметра «model» было выбрано значение «l1», так как результаты получились визуально лучше, другие варианты – это «l2» и «rbf».
Параметр min_size – минимальная длина сегмента, в нашем случае – минимальное количество дней, которые можно объединить в один сегмент. Соответственно, чем он больше, тем меньше сегментов получится. В данном примере было выбрано объединение в сегменты размером не меньше недели.
Параметр pen – это параметр регуляризации, который подбирается экспериментально, чтобы предотвратить переобучение алгоритма. Один из популярных подходов – брать регуляризацию как два логарифма от длины исходного ряда. Чем меньше значение параметра регуляризации, то есть меньше «штраф», тем больше сегментов выделяется.
Часть кода по подготовке датасета опущена, так как требуется просто получить следующие столбцы:
дата (dates)
категория (category)
количество новостей за эту дату по этой категории (news_count)
import ruptures as rpt
import matplotlib.pyplot as plt
%matplotlib inline
for category in category_list:
points = np.array(df_time_series[df_time_series[‘category’]== category]['news_count'])
algo = rpt.Pelt(model="l1", min_size=7).fit(points)
result = algo.predict(pen= np.log(np.log(len(points))))
result.append(len(points))
result.pop(0)
fig, ax_arr = rpt.display(points, result, result, figsize=(35, 3))
plt.title(f"{ topics_name }", size=20, fontweight="bold")
plt.xticks(result, [df_time_series[df_time_series[‘category’]== category]['dates'].tolist()[i-1] for i in result], rotation=90, fontsize=20)
plt.show()Здесь можно посмотреть, какие сегменты по каким категориям получились, подробный анализ получившихся данных с выводами – это уже больше для научной работы). В дальнейшем будет интересно повыделять ключевые слова для сегментов, точек «перегиба» и экстремальных значений.
Временные ряды по всем категориям с сегментацией























У данной задачи есть и свои подводные камни, которые могут вносить шум и приводить к ложным корреляциям. Все события можно поделить на две глобальных группы:
Первая группа – это связанные друг с другом события из одной цепочки, имеющей жизненный цикл, как, например, события из ситуации со специальной военной операцией.
Вторая группа – это, так сказать, «одноразовые» и не особо значимые для анализа события, которые слабо зависят от других и могут вносить характер случайности в частотное распределение по категориям. В идеале – научиться определять и удалять сообщения о таких событиях, а также о тех, которым невозможно дать ярко выраженную эмоциональную окраску.
В общем и целом, метод показал интересные результаты, хотя тут следует еще поэкспериментировать с параметрами. Я посмотрела некоторые события, повлекшие за собой выбивающиеся сегменты. Например, резкий скачок в категории развития бизнеса и торговли после ноября 2023 года в основном произошел из-за начала продажи новых китайских автомобилей, что повлекло сообщения о развитии автомобильной отрасли в России.
Чтобы посмотреть, есть ли корреляции этого события с сообщениями из других категорий, да и в целом, какие категории коррелируют друг с другом, нужно рассмотреть еще один, не менее интересный метод – кластеризацию временных рядов.
Шаг 4. Кластеризация временных рядов
Для проведения кластеризации лучше всего брать временные ряды не по дням, а по месяцам, так как корреляции будут видны лучше. Для начала преобразуем исходный датасет в вид, пригодный для анализа, а также нормализуем временные ряды:
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from tslearn.clustering import TimeSeriesKMeans, silhouette_score
df_clust = pd.DataFrame()
for category in category_list:
df_tmp = df_time_series[df_time_series['category']==category][['news_count', 'year_month']].reset_index(drop=True)
df_reshaped = pd.DataFrame(df_tmp['news_count'].values.reshape(1,-1), columns=df_tmp['year_month'])
df_reshaped = df_ reshaped.rename_axis(None, axis=1)
df_reshaped.insert(0, 'category', t)
df_clust = pd.concat([df_clust, df_reshaped], axis=0 , ignore_index=True)
scaler = StandardScaler()
df_clust_scaled = scaler.fit_transform(df_clust.iloc[:, 1:].T).T
Для кластеризации я взяла классический k-means. Для данной задачи этот метод подходит лучше, так как нам важна именно близость в частотном распределении по месяцам. Более же продвинутый DTW ищет ряды с похожими шаблонами. По k-means считается евклидово расстояние между эмбеддингами несмещенных временных рядов, для них ищутся центроиды и наконец определяются кластеры в результате перемещения центроид по количеству итераций.
Так как заранее не известно оптимальное количество кластеров, нужно определить это значение по методу «локтя» и по метрике силуэта.
Метод локтя показывает оптимальное количество кластеров по следующему принципу: если после визуального «локтя» на графике идет резкое убывание общей ошибки, то такое количество считается оптимальным, но если кластеров много, то ошибка будет минимизироваться, но не будет смысла в кластеризации в принципе. Считается cумма квадратов расстояний от объектов до центра кластера (иначе говоря, ошибок).
По методу силуэта оптимальное количество кластеров - пиковое значение на графике, после которого идет резкий спад. Метрика считает для каждого объекта среднее расстояние между ним и объектами внутри кластера (a) и между ним и объектами в ближайшем кластере (b). Чем больше нормализованное b-a, тем лучше.
def optimal_clusters(df_clust_scaled , metric):
distortions = []
silhouette = []
n_clusters = range(2, 10)
for n in n_clusters:
kmeanModel = TimeSeriesKMeans(n_clusters=n, metric=metric, n_jobs=6, max_iter=10, random_state=0)
kmeanModel.fit(df_clust_scaled )
distortions.append(kmeanModel.inertia_)
silhouette.append(silhouette_score(df_clust_scaled, kmeanModel.labels_, metric=metric, random_state=0))
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
ax1.plot(K, distortions, 'b-')
ax2.plot(K, silhouette, 'r-')
ax1.set_xlabel('K clusters')
ax1.set_ylabel('Elbow Method', color='b')
ax2.set_ylabel('Silhouette', color='r')
plt.show()
optimal_clusters(df_clust_scaled, 'euclidean')
По обеим метрикам лучше всего подходит количество кластеров, равное шести. Обучаем модель кластеризации на наших временных рядах для их деления на 6 кластеров, а также строим усредненные временные ряды для каждого из кластеров.
n_clusters = 6
ts_kmeans = TimeSeriesKMeans(n_clusters=n_clusters, metric='euclidean', max_iter=5)
ts_kmeans.fit(df_clust_scaled)
plt.figure(figsize=(20,10))
for n in range(n_clusters):
plt.plot(ts_kmeans.cluster_centers[cluster_number, :, 0].T, label=n)
plt.xticks(range(len(df_clust.columns[1:].tolist())), labels=df_clust.columns[1:].tolist(), rotation=90, fontsize=10)
plt.legend()
plt.show()
Далее визуализируем полученные кластеры и смотрим, какие категории оказались в одной группе.
df_clust['cluster_kmeans'] = ts_kmeans.predict(df_clust_scaled)
def plot_clusters(current_cluster):
fig, ax = plt.subplots(int(np.ceil(current_cluster.shape[0]/4)),3,figsize=(15, 3*int(np.ceil(current_cluster.shape[0]/4))), sharex=True)
fig.autofmt_xdate(rotation=90)
ax = ax.reshape(-1)
for index, (_, row) in enumerate(current_cluster.iterrows()):
ax[index].plot(row.iloc[1:-1])
ax[index].set_title(f"{row.category}")
plt.xticks(rotation=90)
if current_cluster.shape[0]%3 == 2: #костыль, чтобы не выводились пустые сабплоты
fig.delaxes(ax[-1])
if current_cluster.shape[0]%3 == 1:
fig.delaxes(ax[-1])
fig.delaxes(ax[-2])
plt.tight_layout()
plt.show()
for n in range(n_clusters):
print(f"Кластер №{n+1}")
plot_clusters(df_clust[df_clust['cluster_kmeans']==n])Кластер №1

Кластер №2
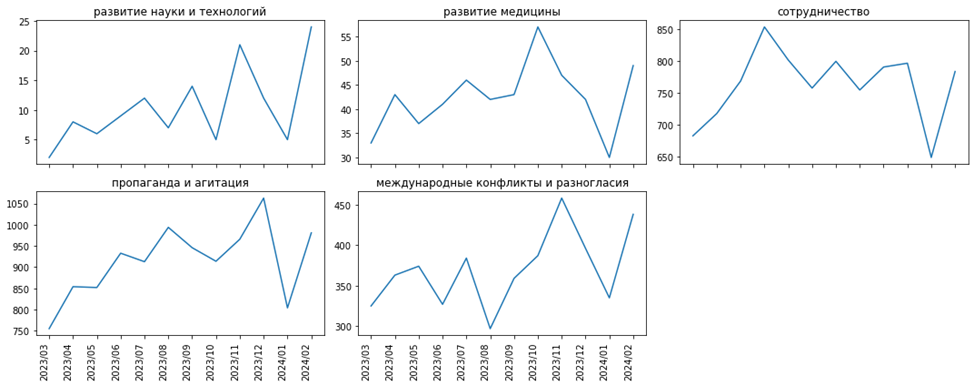
Кластер №3

Кластер №4

Кластер №5

Кластер №6

Большинство кластеров выглядят вполне логично, и взаимосвязи видны именно на временных рядах с периодом по месяцам, а не по дням. Вспомним наш пример с китайскими автомобилями, относящимся к категории «развитие бизнеса и торговли», и увидим, что резкий качок после ноября 2023 года произошел также в категориях «экономическое развитие» и «инновации и импортозамещение». Связаны ли эти события – это уже другая задача, но, определенно, есть корреляции во временных рядах этих тематик.
Также интересны кластеры № 2, 3, 4: логически похожи ряды с «безработицей и бедностью» и «социальными проблемами», с «санкциями и русофобией», «преступлениями» и «политическими проблемами», с «катастрофами и катаклизмами» и «войной и оружием», с «пропагандой и агитацией» и «международными конфликтами и разногласиями».
Есть, конечно, и выбивающиеся из общей логики временные ряды, но это, скорее всего, можно списать на обычные совпадения. В любом случае, для получения более интересных результатов нужно использовать дополнительные методы, в том числе анализ лингвистической составляющей новостей.
Заключение
Итак, я рассмотрела задачи сегментации и кластеризации временных рядов применительно к анализу новостей. Результаты вышли достаточно интересными и логичными, но для получения более информативных выводов в задаче анализа социальных явлений и процессов необходимо собрать больше данных, определить больше категорий, добавить дополнительные проверки и этапы, в частности, связанные с NLP.
Комментарии (9)

vagon333
06.04.2024 18:24Любопытный подход.
Можно-ли определить каталог категорий для незнакомой области?
Или нужно начинать с некоторого списка категорий, а затем корректировать (сужать/расширять)?
У меня 600+к новостей из разных источников (банковские, с 1990) и определение трендов может быть полезен для читателей.
Datactive Автор
06.04.2024 18:24Интересный вопрос! Думаю, что есть более продвинутые методы выделения ключевых слов из новостей, и на основании этого уже можно будет определять либо сразу какие-то крупные высокочастотные категории, либо потом с помощью того же W2V более узкие


Alexander26984
06.04.2024 18:24Я так никогда не делал, поэтому интересно, сколько времени заняла первая часть кода с парсингом 365 страниц и выделением 93к строк для дф?

IduMimo71
06.04.2024 18:24+1Очень интересно! Всегда раздражала имитация новостей в играх - по-моему, отсюда можно что-то применить для хорошей модели блока событий в выдуманных мирах - события мира, недоинформированность СМИ, преднамеренные и непреднамеренные искажения и откровенные фейки в зависимости от культуры обществ и целей СМИ, утеря связующих событий между казалось бы несвязанными сообщениями.
Mirilis
очень круто! очень интересный инструмент получается. Вас теперь могут пригласить в Ленту аналитиком)
Datactive Автор
Спасибо! Интересный вариант)