

Меня зовут Владимир Медин, я работаю в подразделении SberWorks, которое внедряет практики DevOps и MLOps. Хочу поделиться нашим опытом повышения надёжности enterprise-систем, вводимых в эксплуатацию, особенно впервые. Для кого-то эта статья будет в большей степени спасательным кругом, но с напутствием. Многие подходы к обеспечению надёжности у нас регламентированы, но есть и «неуставные» решения, которые вырабатываются только с опытом. Кому-то могут бы непонятны некоторые тонкости, диктуемые условиями крупной компании, поэтому по мере рассказа буду объяснять, почему это важно. Впрочем, на мой взгляд, эти правила применимы в работе компании любого размера, дорожащей стабильностью качества своих услуг.
А нужен ли production?
В Сбере выход любой системы в эксплуатацию — это выделение какого-либо бюджета и оборудования, проведение специальных мероприятий для подтверждение качества продукта. Поэтому мы в первую очередь привыкаем отвечать себе на вопрос: «А нужен ли он вообще, этот прод?» Но почему он вообще возник?
Сначала мы должны определить тип сервиса. Это влияет на выбор конвейера для проверки качества. Сервис может быть внутренним, то есть и он, и его потребители находятся внутри корпоративной сети:
Сервис может быть представлен как услуга для внешних пользователей, но при этом размещён внутри нашего периметра:
Или он может быть полностью внешний:

Затем нужно понять, какие будут последствия при падении сервиса каждого тип. Я все три варианта собрал на одной иллюстрации:

В некоторых случаях падение сервиса совсем не критично. Скажем, если это генератор поздравительных открыток внутри нашей организации, то никто сильно не обидится, если он полежит некоторое время. А если этот сервис помогает зарабатывать, приносит прибыль, то такие потери не простят. Между этими крайностями есть сервисы, чья неработоспособность неприятна, но не критична, можно подождать.
Какой прод нам нужен?
Определившись с типом сервиса, мы понимаем, как выстраивать свои конвейеры для того, чтобы начать разработку и завершить всё вводом в эксплуатацию, знаем о возможных последствиях. Давайте рассмотрим весь процесс на примере сервиса с максимально высокими требованиями.
Сначала нужно определить целевой уровень доступности. Пойдём от простых принципиальных схем к более сложным, чтобы по мере повествования я мог объяснять, как может изменяться ситуация при добавлении того или иного аргумента.
У нас есть пользователи и приложение, предоставляющее услугу. Его ожидаемый уровень доступности — четыре девятки. Это важно, потому что мы уже должны помнить о георезервировании, переключениях, размещении в ЦОДах и прочих механизмах. Мы должны уже понимать, что всё будет по-серьёзному. Какие технологии используются при работе этого сервиса? Пусть это будет обычный веб-интерфейс по протоколу HTTP.

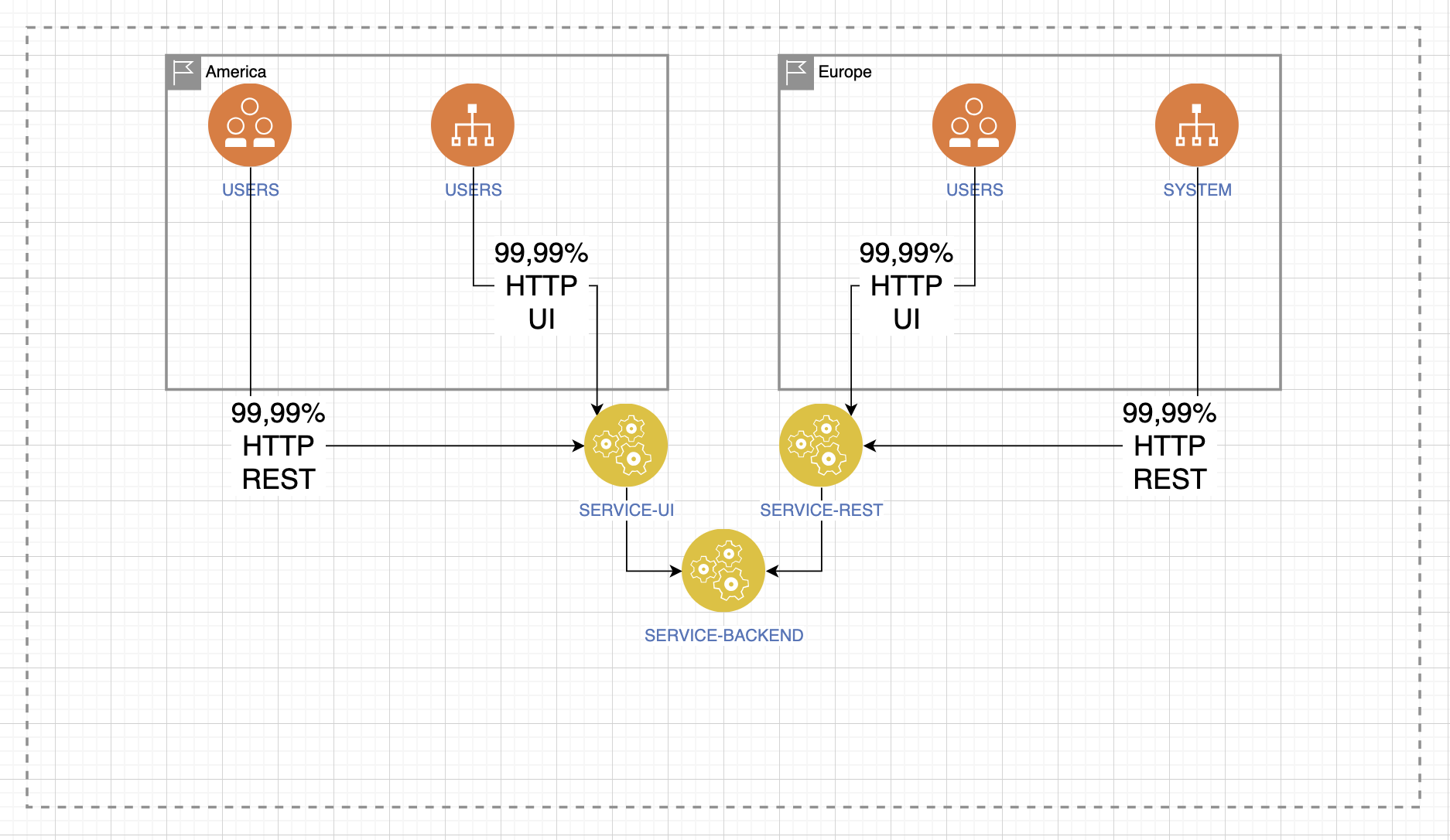
Но где находятся наши пользователи? И как только мы подходим к этому вопросу, схема сразу усложняется: добавляются новые конечные точки, появляются системные интеграции, использование сервиса по REST. Ведь разнообразие географии не только нашей промышленной среды, но и наших пользователей будет сильно влиять на то, как мы будем обеспечивать доступность.

Затем нужно ответить себе на вопрос: «монолит или нет?» Выстраивание конвейера от разработки до эксплуатации, до соединения всех этапов непрерывным процессом поставки артефактов, довольно-таки сильно зависит от архитектуры приложения.
Когда дело доходит до скорого ввода в эксплуатацию, подумайте о том, как это было разработано и какое окружение. Под окружением я понимаю тот или иной реверс-прокси, будь то балансировщик нагрузки, Nginx, HAProxy — не важно, какие базы данных, сервисы кешей или очередей нам нужно предоставить для минимального запуска нашего приложения?

Если всё это умножить на количество окружений, то настойчиво возникает мысль, что руками мы этим точно не будем управлять.
Журналирование
Следующий вопрос, на который мы должны ответить: «а что у нас с журналированием?» Представим обычный сервис с микросервисной архитектурой. У нас есть какой-либо агрегатор логов, есть окружение.

Логи не должны иметь разные форматы: log, frog, grog. Иначе невозможно будет отслеживать критические инциденты, деградацию и другие изменения. Договоритесь с разработчиками, чтобы на уровне приложений логи были в одном формате, с общим набором атрибутов. Часть этих атрибутов важна линиям поддержки, часть — самим разработчикам, часть — бизнесу.

Готовность к нагрузке
Любая система агрегации должна потреблять и перерабатывать такой же поток логов, как и ваши сервисы, если они все подключены к этой системе. Если ваш сервис чуть сложнее самого простого, то уже моветон ходить в консоли виртуальных машин или в поды, чтобы посмотреть логи. В условиях дикой спешки вы просто не будете замечать самого важного. Поэтому проверьте, может ли ваша система агрегации перерабатывать весь поток логов. Посчитайте возможную нагрузку, например, с помощью системных аналитиков.

Не забудьте, что есть ещё и логи окружения, которое обеспечивает работу вашего сервиса. Всё, что там происходит, должно быть качественно собрано в одном месте и предоставлено всем заинтересованным лицам.

Повторяемость
Мы недавно добавили одну из утилит, собирающую логи, и уже видим много элементов, которыми нужно уметь управлять, и повторять это вне зависимости от вашего этапа.
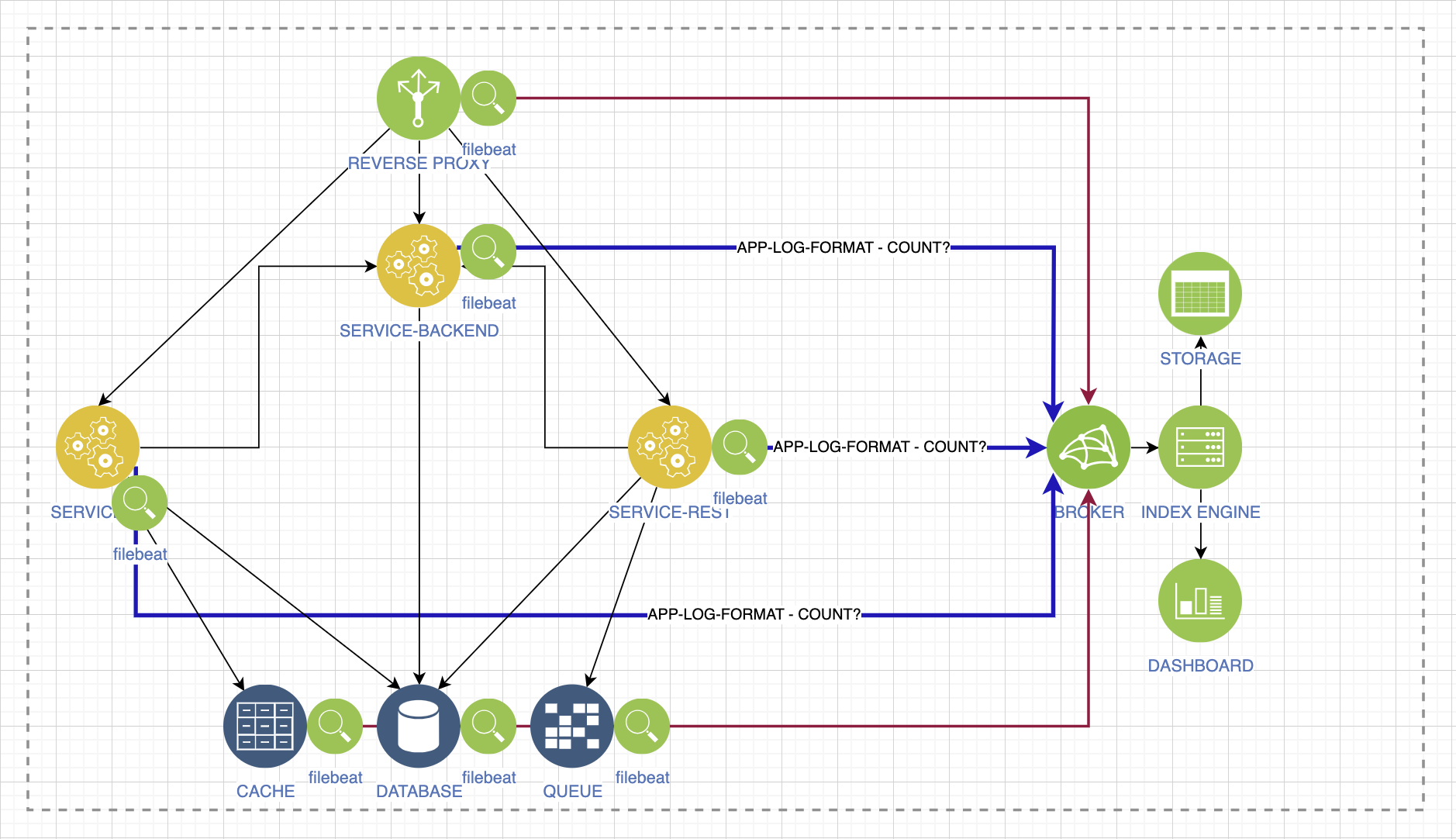
Система агрегации логов будет расти, появятся новые сервисы, и вручную вы не сможете обеспечить повторяемость. Даже если какой-то стенд был потерян полностью. Автоматизируйте. Подход инфраструктура-как-код позволяет повторять окружение, удобно управлять им и выстраивать новое, даже проверять гипотезы.

А что с мониторингом?
Напоследок расскажу про золотые правила, в каждом из которых будет много контекста. Определите инструменты, с помощью которых вы будете собирать метрики. Вот плохой пример, когда разные уровни мониторятся разными системами:

Не надо делать так. Выберите одну систему, которая будет отвечать всем вашим потребностям, и собирайте всё в ней.

Разделите поступающие данные на слои отслеживания метрик. Определите, что вам нужно нужно для работоспособности сервиса, что может повлиять на качество предоставляемой услуги. Собирайте все типы метрик. Для каждого типа окружения сейчас есть отличные экспортёры, или можно разработать их самостоятельно, если есть время. Здесь я попытался разделить стандартные уровни, которые необходимо отслеживать для контроля работоспособности нашего стека:

Первый слой — это метрики нашего прокси, который первым принимает запросы наших пользователей. Второй слой — это уровень приложения, прозрачность поведения нам обеспечивают минимум четыре золотых сигнала. У нас есть метрики окружения: базы данных, кеша или очереди. У нас есть низкоуровневые метрики, которые отражают платформу, на которой работает наш стек. И зависимые метрики. То есть мы в процессе работы можем использовать Active Directory, внешние системы хранения секретов и другой конфиденциальной информации. Всё это крайне важно и будет влиять на вашу работу, даже если вам кажется, что это железобетонно работающие сервисы. Это не так.
Обеспечьте оповещение со всех уровней, которые вы собираете. Уровни также разделяются по важности. Самые критичные, допустим, это оповещения о снижении качества услуги.

Каждый из типов оповещений должен предоставляться разным типам потребителей. Какие-то из этих метрик очень важны бизнесу, какие-то важны дежурной смене 24 на 7, какие-то просто нужны для оповещения, потому что у нас есть какое-то изменение, не критичное, но его нельзя оставить без внимания.
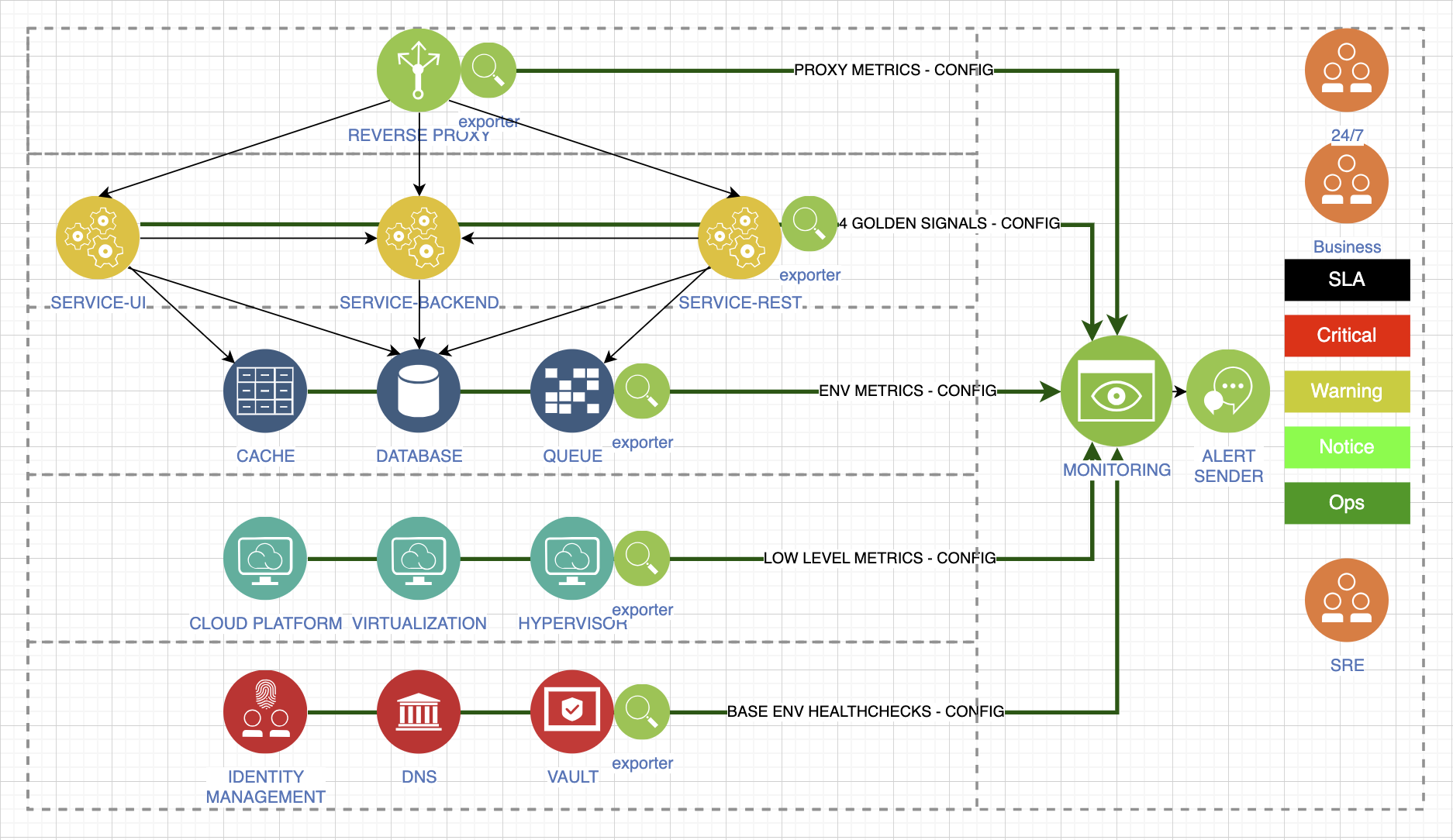
Управляйте оповещением и во время проведения плановых работ. Не надо увеличивать количество спама в тяжёлой ситуации, это может сбить вас с толку.

Мы снова пришли от простой схемы к сложной, хотя описали сбор метрик только для одного из типов окружений: вам нужно сохранить повторяемость,автоматизировать её, использовать практики управления конфигурацией инфраструктуры как код. Поняв, какой сервис нам нужен, нужно определиться с технологиями и мониторингом.
Но какая ожидается нагрузка?
Не имея ответа на этот вопрос, даже предыдущие советы могут не сильно вам помочь. Исследуйте вашего клиента. Определите географию нагрузки, откуда она может прийти. Рассмотрим на примере межматерикового взаимодействия.
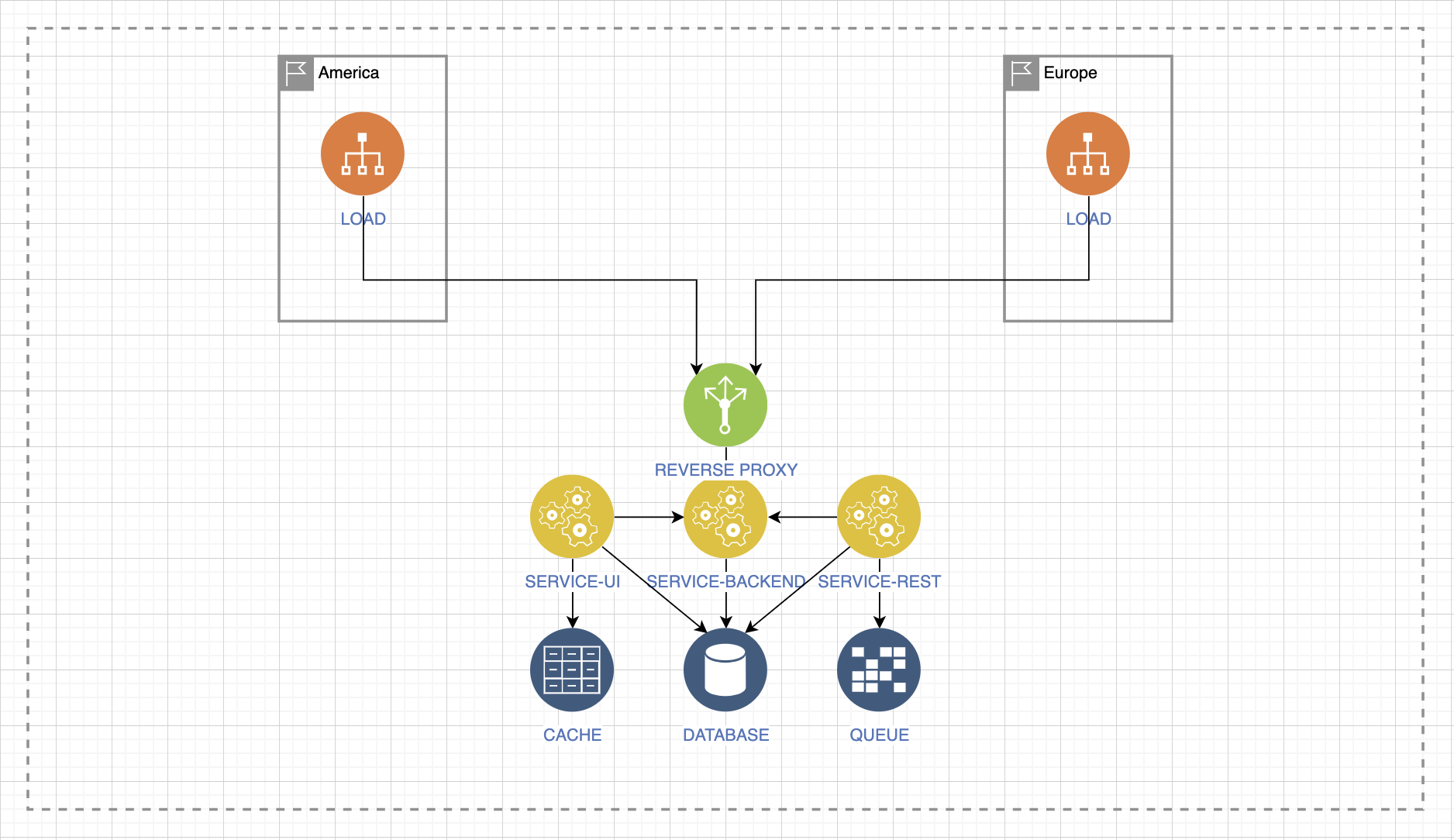
Допустим, из Европы к нам приходят в основном запросы, и они самые важные, а в Америке самый важный ответ, который даёт наш сервис. При этом нагрузка из Европы всего лишь запрашивает статическую информацию, а нагрузка из Америки ожидает быстрый ответ в формате JSON.

Поэтому давление нагрузки изменяет своё поведение и приводит к волнообразному отклику внутри системы, уже за входной точкой балансировки или за входной точкой реверс-проксирования, будь это конечная точка, сервис или ещё что-то.

В данном случае мы видим, что при большой нагрузке запросы статичной информации вызовут давление на кеш, на сервисы бэкенда, на сервис UI. При этом остальные сервисы будут простаивать.
Также может быть другая ситуация, когда важен ответ быстрый ответ в виде JSON-файлов, которые могут быть большого размера.

Тогда возникает давление на другие сервисы. Вы должны понимать, что будет с вашим сервисом, когда на него будет приходить нагрузка разного типа.
Допустим, есть два потока нагрузки из Европы и Америки. И есть сервис, который распределяет нагрузку между двумя ЦОДами. Это самый практичный вариант балансировки и обеспечения отказоустойчивости на уровне материкового взаимодействия.
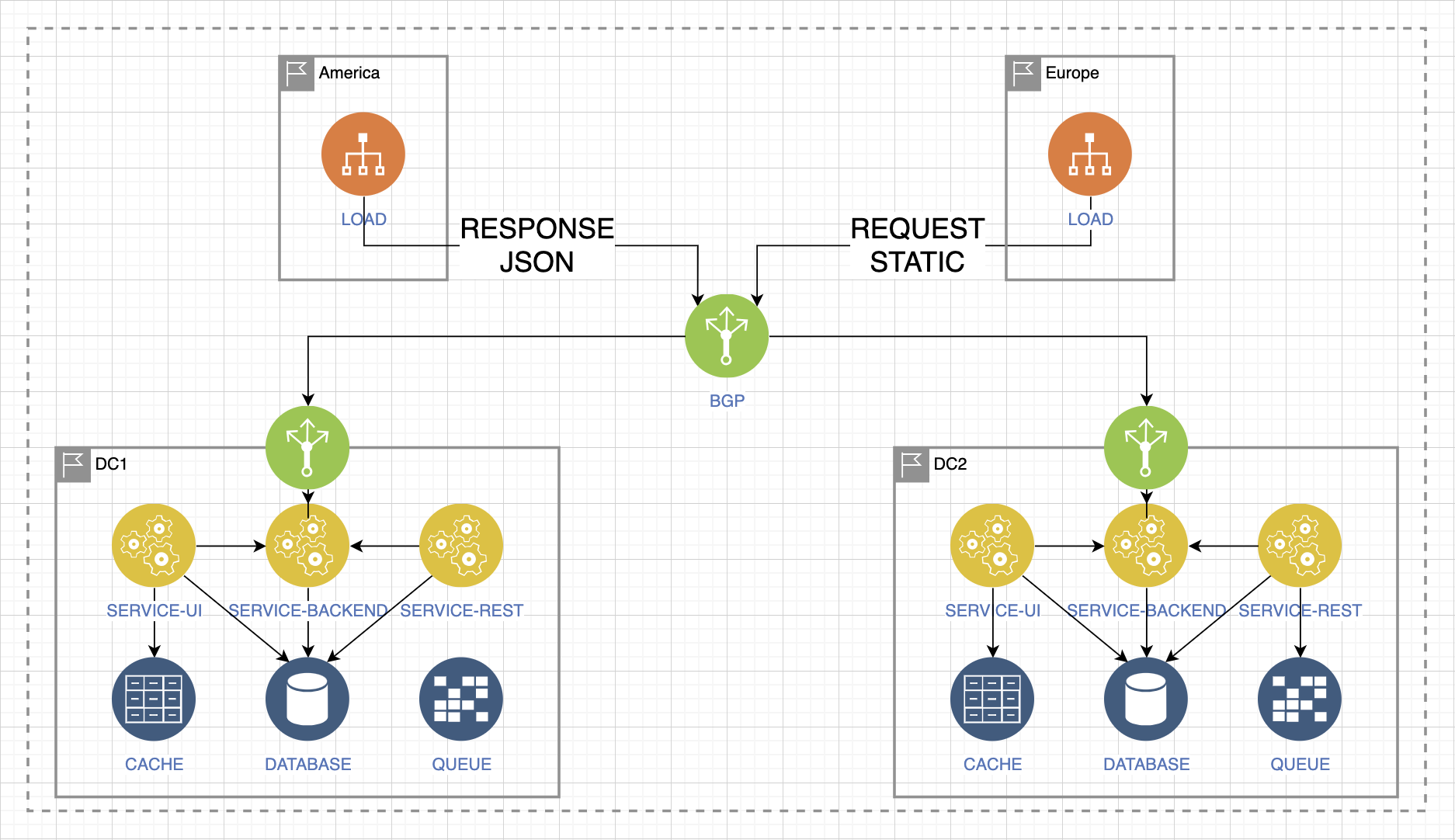
У нас есть контролируемая зона и неконтролируемая. Неконтролируемая — это та, которой мы не можем управлять. Контролируемая — это та, где мы можем изменить всю ситуацию в случае непредвиденностей.

Допустим, у нас пропадает доступ к ЦОД1, падает сервис приёма запросов:
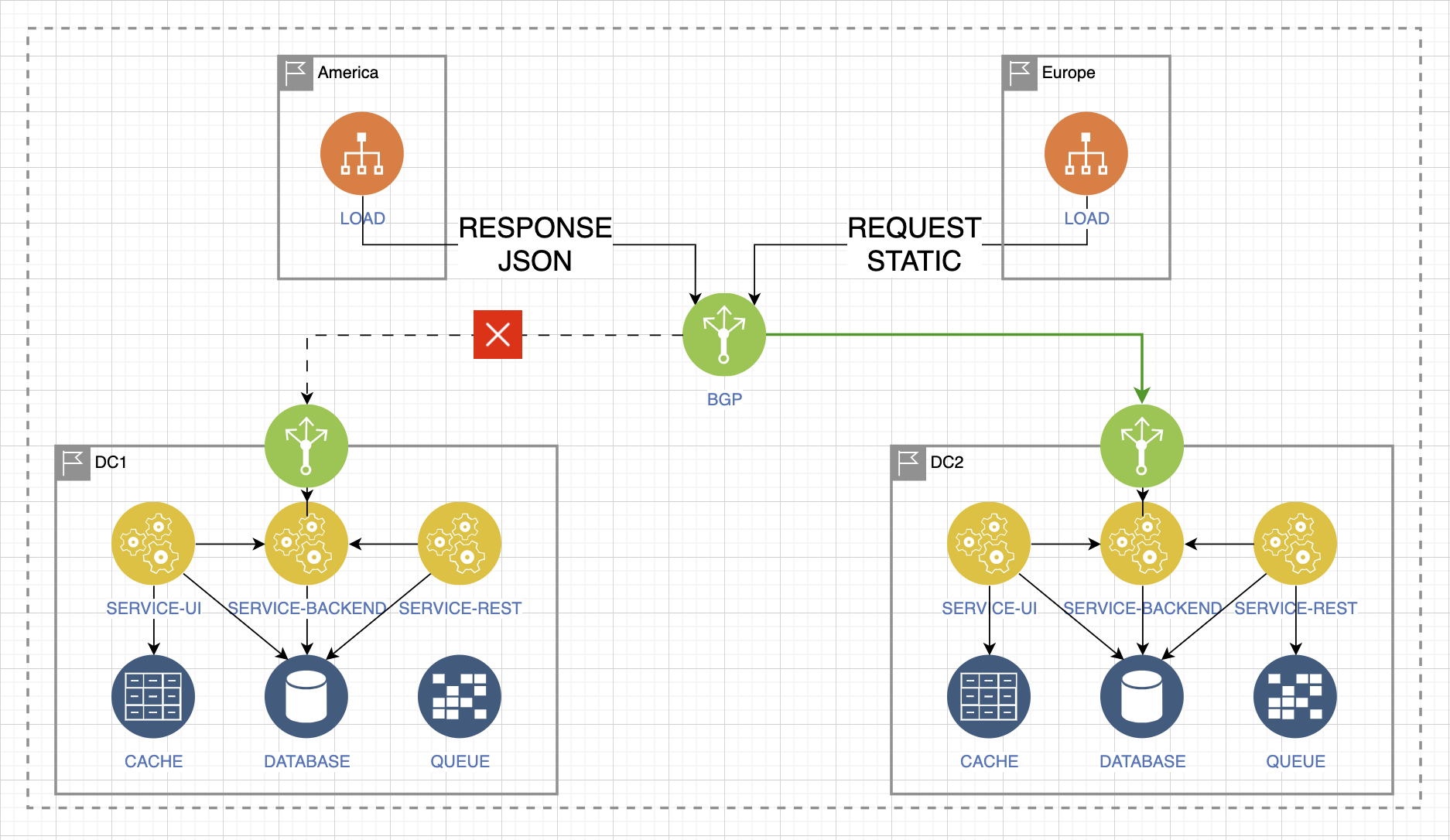
Нам нужно быстро принять решение и переключить этот трафик. Он попадает в ЦОД2. При этом от повышенной нагрузки не выдерживает база данных. Нам нужно уметь быстро переключить этот трафик в базу данных в ЦOД1 по серым сетям.

Но при этом трафик возвращается обратно, и из-за повышенной, нетипичной волнообразной нагрузки в ЦОД1 ломается сервис бэкенда. Чтобы сохранять работоспособность, нам нужно быстро переключить всё в ЦОД2 именно в этой части интеграции.

Но при возврате сетей и при возврате доступности всех сервисов у нас может сломаться кворум — самый простой пример сценария нагрузки и деградации.

Не нужно делать какие-то полноценные нагрузочные тестирования, искать точки максимума. Конечно, это очень важно, но на разработку методики и исследование последствий может уйти слишком много времени, хотя такие сценарии вполне можно посоставлять, собравшись с командой. Так что будьте готовы, сразу закладывайте эти механизмы и представляйте, как вы будете выкручиваться в подобной ситуации. Бывают случаи, когда за одной неполадкой тянутся другие, параллельно происходит ещё что-то. И без автоматизации и инструментов быстрого реагирования у вас может просто каскадно рухнуть вся эксплуатационная среда.
Управляйте конфигурацией. Подконтрольная зона намного больше, чем неконтролируемая. Готовьте скрипты заранее, подумайте о сценариях, заложите бэклог, подумайте о том, какие сценарии могут понадобиться. Применяйте все возможные практики, чтобы не прибегать к ручному управлению.

Управление конфигурацией
Я не раз говорил про автоматизацию, управление распределёнными системами или средой эксплуатации без применения рук. Давайте поговорим про это. Представим простейший стек:

А теперь умножим все сервисы на тысячу. И тогда ваш текущий уровень автоматизации сразу станет выглядеть иначе в ваших глазах:

Фундаментом развития является стандартная циклическая картинка: инженер и ручная рутинная операция на виртуальной машине.

Эта петля может работать бесконечно. Когда что-то где-то будет происходить, инженер будет выходить из точки равновесия и пытаться ухватиться сразу за всё. А приоритет задач может довольно часто меняться. Поэтому после успешного выполнения ручной операции положите задачу в бэклог, разберите его и расставьте в команде задачи, передавайте их в спринты, постепенно исполняя и автоматизируя. Совсем не сложно зайти в IDE, написать какой-то скрипт и положить в систему контроля версий. Совсем не сложно это протестировать и доставить в свои среды, от тестовой до эксплуатационной. Где-то вам покажется, что автоматизация потребует слишком много времени — пропустите их. Сначала приучите себя к бесконечному процессу постановки себе задач: «я это сделал вручную, я это должен автоматизировать». Вы освободите своё время и сможете дальше исследовать и развивать систему.

Определитесь с инструментарием. Не нужно использовать, к примеру, одновременно Ansible, Chef и Salt. Или Bitbucket, GitLab и SVN. Это всё интересно и очень заманчиво, кажется, что вот именно в этом инструменте есть то, что нам всегда было нужно. Но нет, этот зоопарк приводит только к раздраю на уровне команды, а то и на уровне целого предприятия. Выбирайте инструменты взвешенно и совместно.

Уважайте код. Всё, что мы автоматизируем — это тоже код, как и у разработчиков. С таким же вниманием нужно проводить проверки, работать с ветками. На этой иллюстрации нет точки начала, потому что процесс бесконечный:

Запускайте этот процесс, как только впервые возникла потребность развернуться в тестовом окружении. До эксплуатации вам будет намного проще выйти, и будет намного меньше техдолга. Автоматизируйте тестирование, проверку чистоты кода. Проверяйте код своих коллег и поправляйте их. Делайте автоматическую доставку и следите за поведением системы.
Управление развёртыванием
Скажу про главное:
Определите механику развёртывания. Это может быть blue/green, канареечный релиз, shadow copy или другая механика — лишь бы она была единой для всех. Зоопарк не приводит ни к чему хорошему.
Автоматизируйте smoke‑тесты. Это обязательный завершающий этап развёртывания. Без него вы не сможете гарантированно подтвердить, что изменения прошли успешно.
Учитывайте зависимости работающих сервисов. Нельзя выкатывать приложение без работающей базы, или выкатывать кеш без работающего сервиса DNS.
Представляйте отсутствие доступа к консоли. Это выработает у вас навык работы исключительно в коде и научит бесшовно выстраивать свои конвейеры.
SLA
C точки зрения бизнеса, SLA — это просто, но в реальности всё не так однозначно. Чтобы рассчитать SLA, нужно сделать уйму итераций и понять, что же именно представляет собой конечный сервис, какие составные части работают отвечают за нужный уровень обслуживания и как это всё поставить на поток.
Для инженеров SLA — лучшая мотивация к развитию.
Четыре девятки — это очень сложно, если считать правильно. Развернув систему, мы не перестаём заботиться о её доступности и надёжности, это постоянная работа.
Напутствие
Эксплуатация — непрерывный и развивающийся процесс. Если мы запустили какой-то сервис и отладили его, то это не означает, что наша работа заканчивается. Есть много практик и механизмов, которые помогают нам развиваться самим и развивать систему. Обратная связь от инженеров сопровождения должна поступать разработчикам и архитекторам, чтобы взращивать свой инструмент там, где непосредственно зарабатываются деньги.
Нагрузка — это постоянно растущий показатель, даже для внутренних сервисов. Это верно для любой компании, если сервис действительно востребован, так что планируйте это.
Надёжность не имеет высшего предела. Как я уже говорил, достичь четыре девятки очень сложно. Особенно в комплексной системе, где очень много разных взаимосвязей и внешних интеграций. Вкладывайтесь в это, изучайте. Мы хорошо изучили разные инструменты и конфигурации, но до сих пор иногда приходится заглядывать в потаённые уголки документации.
DevOps — это неотъемлемая часть производства. Без практик этой методологии, без автоматизации не может быть всего того, чего сейчас добивается Сбер.
Комментарии (2)

blindmen
22.04.2024 22:18Эх, для тех кто пропустил этап планирования проще сгореть и начать по вашей методичке)
Thomas_Hanniball
Материал полезный, хоть и очень объёмный получился, поэтому добавил в закладки, чтобы осилить его по частям.
Если для каждого сервиса делать всё так, как описано в статье, то "можно умереть от тысячи микросервисов и микропроцессов", а онбординг новых сотрудников в команду эксплуатации будет стремиться к бесконечности.