
Фото, базовые принципы и немного синтетических тестов внутри…

Современные информационные системы и темпы их развития диктуют свои правила развития ИТ-инфраструктуры. Системы хранения на твердотельных носителях уже очень давно превратились из роскоши в средство достижения необходимого дискового гаранта SLA. Итак, вот она — система, способная выдать более миллиона IOPS.

Базовые принципы
Данная система хранения является флеш-массивом с увеличенным быстродействием за счет использования модулей MicroLatency и оптимизации технологии MLC.

Когда мы спросили нашего пресейла, какие технологии используются для обеспечения отказоустойчивости и сколько же на самом деле гигабайтов спрятано внутри (IBM заявляет 11,4 Тб чистого пространства), он ответил уклончиво.
Как оказалось, все не так просто. Внутри каждого модуля располагаются чипы памяти и 4 FPGA контроллера, на них построен Raid c переменным страйпом (Variable Stripe RAID, VSR).
Каждый чип модуля делят на так называемые слои. На каждом N-слое всех чипов внутри модуля строится Raid5 переменной длины.

При выходе из строя одного слоя на чипе длина страйпа уменьшается, и битая ячейка памяти перестает использоваться. За счет избыточного количества ячеек памяти, полезный объем сохраняется. Как выяснилось, на системе намного более 20 Тб сырого флеша, т.е. почти на уровне Raid10, и за счет избыточности мы обходимся без перестройки всего массива при выходе из строя одного чипа.

Получив Raid на уровне модуля, FlashSystem объединяет модули в стандартный Raid5.
Таким образом, для достижения нужного уровня отказоустойчивости, из системы с 12 модулями по 1,2 Тб (маркировка на модуле) мы получаем чуть более 10 Тб.
Тестирование
После получения системы от партнера, производим установку системы в стойку и подключение в текущую инфраструктуру.

Подключаем СХД, согласно заранее согласованной схеме, настраиваем зоннинг и проверяем доступность из среды виртуализации. Далее — готовим лабораторный стенд. Стенд состоит из 4-х блейд-серверов, подключенными к тестируемому СХД двумя независимыми 16 Гбитными оптическими фабриками.
Так как «ИТ-парк» сдает в аренду виртуальные машины, то в тесте будет оцениваться производительность одной виртуальной машины и целого кластера виртуалок под управлением vSphere 5.5.
Немного оптимизируем наши хосты: настроим многопоточность (roundrobin и лимит количества запросов), также увеличим глубину очереди на драйвере FC HBA.
На каждом блейд-сервере создаем по одной виртуальной машине (16ГГц, 8 Гб RAM, системный диск 50 Гб). К каждой машине подключим 4 жестких диска (каждый на своем Flash луне и на своем Paravirtual контроллере).
В тестировании рассмотрим синтетическое тестирование малым блоком 4К (чтение/запись) и большим блоком 256К (чтение/запись). СХД стабильно отдавала 750к IOPS, что для нас выглядело очень неплохо, несмотря на заявленную производителем космическую цифру в 1,1М IOPS. Не забываем, что всё прокачивается через гипервизор и драйвера ОС.
Также отметим, что, как и у всех известных вендоров, заявленная производительность достигается только в тепличных лабораторных условиях (огромное количество SAN аплинков, специфичная разбивка LUN, использование выделенных серверов с RISK архитектурой и специально сконфигурированными программами-генераторами нагрузки).
Выводы
Плюсы: огромная производительность, простота настройки, дружелюбный интерфейс.
Минусы: за пределами емкости одной системы, масштабирование осуществляется дополнительными полками. «Продвинутый» функционал (снимки, репликация, компрессия) вынесен в слой виртуализации хранения. IBM построил четкую иерархию СХД, во главе которой виртуализатор хранения (SAN Volume Controller или Storwize v7000), который обеспечит многоуровневость, виртуализацию и централизованное управление вашей сети хранения.
Итог: IBM Flashsystem 900 выполняет свои задачи по обработке сотен тысяч IO. В текущей тестовой инфраструктуре удалось получить 68% производительности, заявленной производителем, что дает впечатляющую плотность производительности на ТБ.
Современные информационные системы и темпы их развития диктуют свои правила развития ИТ-инфраструктуры. Системы хранения на твердотельных носителях уже очень давно превратились из роскоши в средство достижения необходимого дискового гаранта SLA. Итак, вот она — система, способная выдать более миллиона IOPS.
Технические характеристики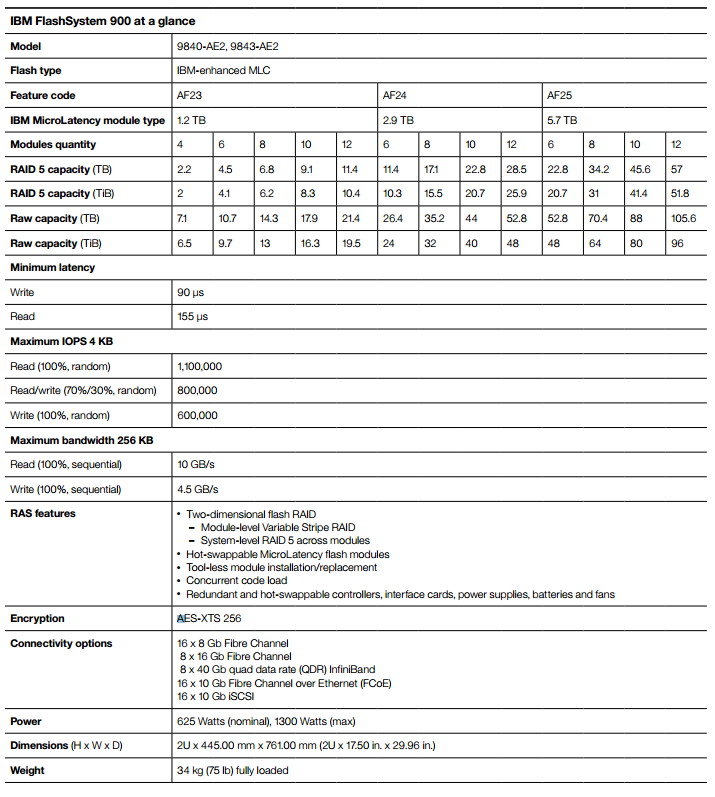
Базовые принципы
Данная система хранения является флеш-массивом с увеличенным быстродействием за счет использования модулей MicroLatency и оптимизации технологии MLC.
Когда мы спросили нашего пресейла, какие технологии используются для обеспечения отказоустойчивости и сколько же на самом деле гигабайтов спрятано внутри (IBM заявляет 11,4 Тб чистого пространства), он ответил уклончиво.
Как оказалось, все не так просто. Внутри каждого модуля располагаются чипы памяти и 4 FPGA контроллера, на них построен Raid c переменным страйпом (Variable Stripe RAID, VSR).
Внутренности модуля, две двухсторонние платы



Каждый чип модуля делят на так называемые слои. На каждом N-слое всех чипов внутри модуля строится Raid5 переменной длины.
При выходе из строя одного слоя на чипе длина страйпа уменьшается, и битая ячейка памяти перестает использоваться. За счет избыточного количества ячеек памяти, полезный объем сохраняется. Как выяснилось, на системе намного более 20 Тб сырого флеша, т.е. почти на уровне Raid10, и за счет избыточности мы обходимся без перестройки всего массива при выходе из строя одного чипа.
Получив Raid на уровне модуля, FlashSystem объединяет модули в стандартный Raid5.
Таким образом, для достижения нужного уровня отказоустойчивости, из системы с 12 модулями по 1,2 Тб (маркировка на модуле) мы получаем чуть более 10 Тб.
Web-интерфейс системы
Да, оказался старым знакомым (привет кластерам v7k) с жуткой функцией вытягивания локали из браузера. У FlashSystem интерфейс управления схож с Storwize, но они существенно отличается по функционалу. У FlashSystem софт служит для настройки и мониторинга, а прослойка софтверная (виртуализатор) как у сторвайза отсутсвует, так как системы предназначены для разных задач.

Тестирование
После получения системы от партнера, производим установку системы в стойку и подключение в текущую инфраструктуру.
Подключаем СХД, согласно заранее согласованной схеме, настраиваем зоннинг и проверяем доступность из среды виртуализации. Далее — готовим лабораторный стенд. Стенд состоит из 4-х блейд-серверов, подключенными к тестируемому СХД двумя независимыми 16 Гбитными оптическими фабриками.
Схема подключения
Так как «ИТ-парк» сдает в аренду виртуальные машины, то в тесте будет оцениваться производительность одной виртуальной машины и целого кластера виртуалок под управлением vSphere 5.5.
Немного оптимизируем наши хосты: настроим многопоточность (roundrobin и лимит количества запросов), также увеличим глубину очереди на драйвере FC HBA.
Настройки ESXi
Наши настройки могут отличаться от ваших!


На каждом блейд-сервере создаем по одной виртуальной машине (16ГГц, 8 Гб RAM, системный диск 50 Гб). К каждой машине подключим 4 жестких диска (каждый на своем Flash луне и на своем Paravirtual контроллере).
Настройки ВМ
В тестировании рассмотрим синтетическое тестирование малым блоком 4К (чтение/запись) и большим блоком 256К (чтение/запись). СХД стабильно отдавала 750к IOPS, что для нас выглядело очень неплохо, несмотря на заявленную производителем космическую цифру в 1,1М IOPS. Не забываем, что всё прокачивается через гипервизор и драйвера ОС.
Графики IOPS, задержек и, как мне кажется notrim
1 ВМ, Блок 4к, 100% чтение, 100% случайно. При предоставлении всех ресурсов с одной виртуальной машины, график производительности вел себя нелинейно и прыгал в пределах от 300к до 400к IOPS. В среднем, мы получили около 400k IOPS
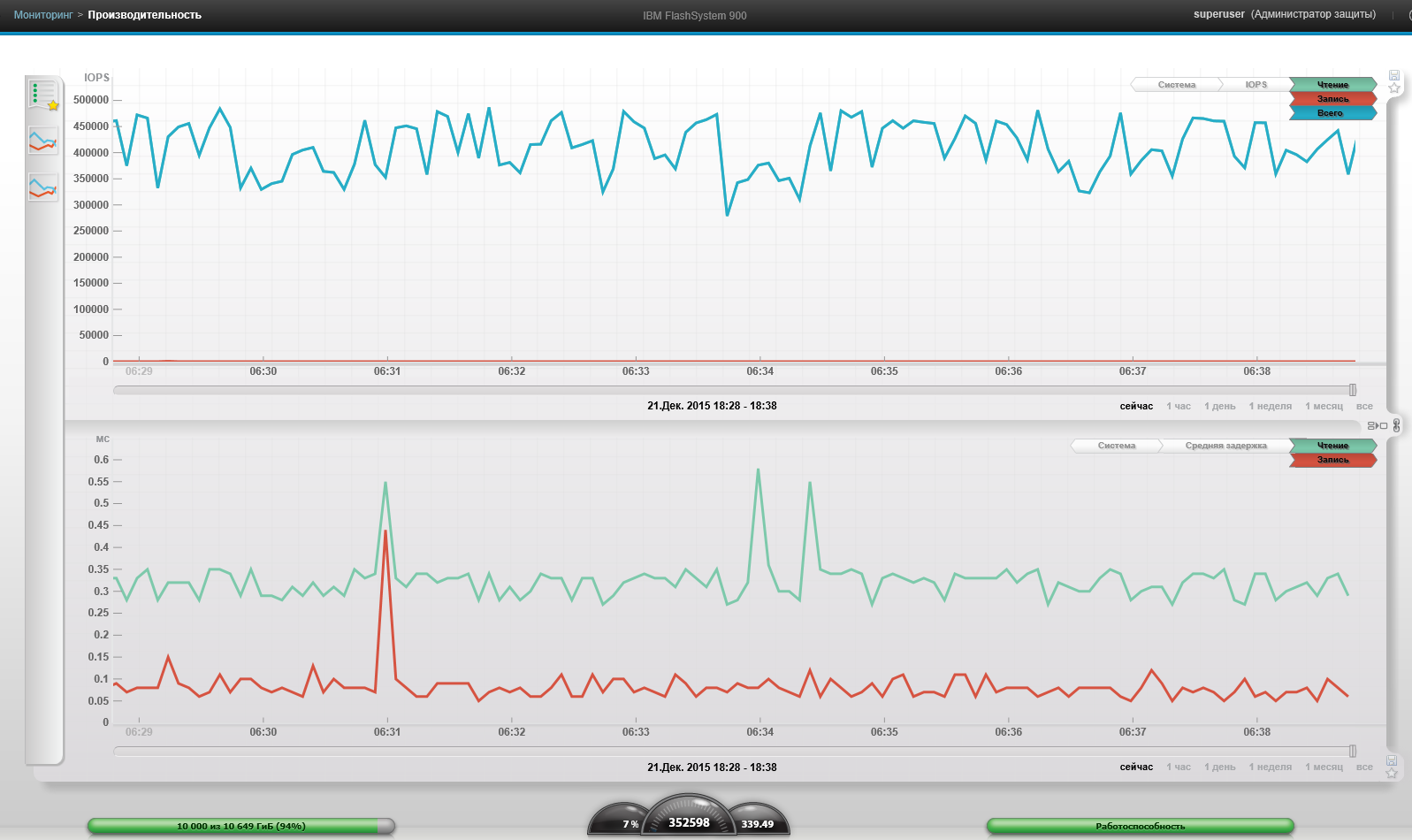
4 ВМ, Блок 4к, 100% чтение, 100% случайно

4 ВМ, Блок 4к, 0% чтение, 100% случайно
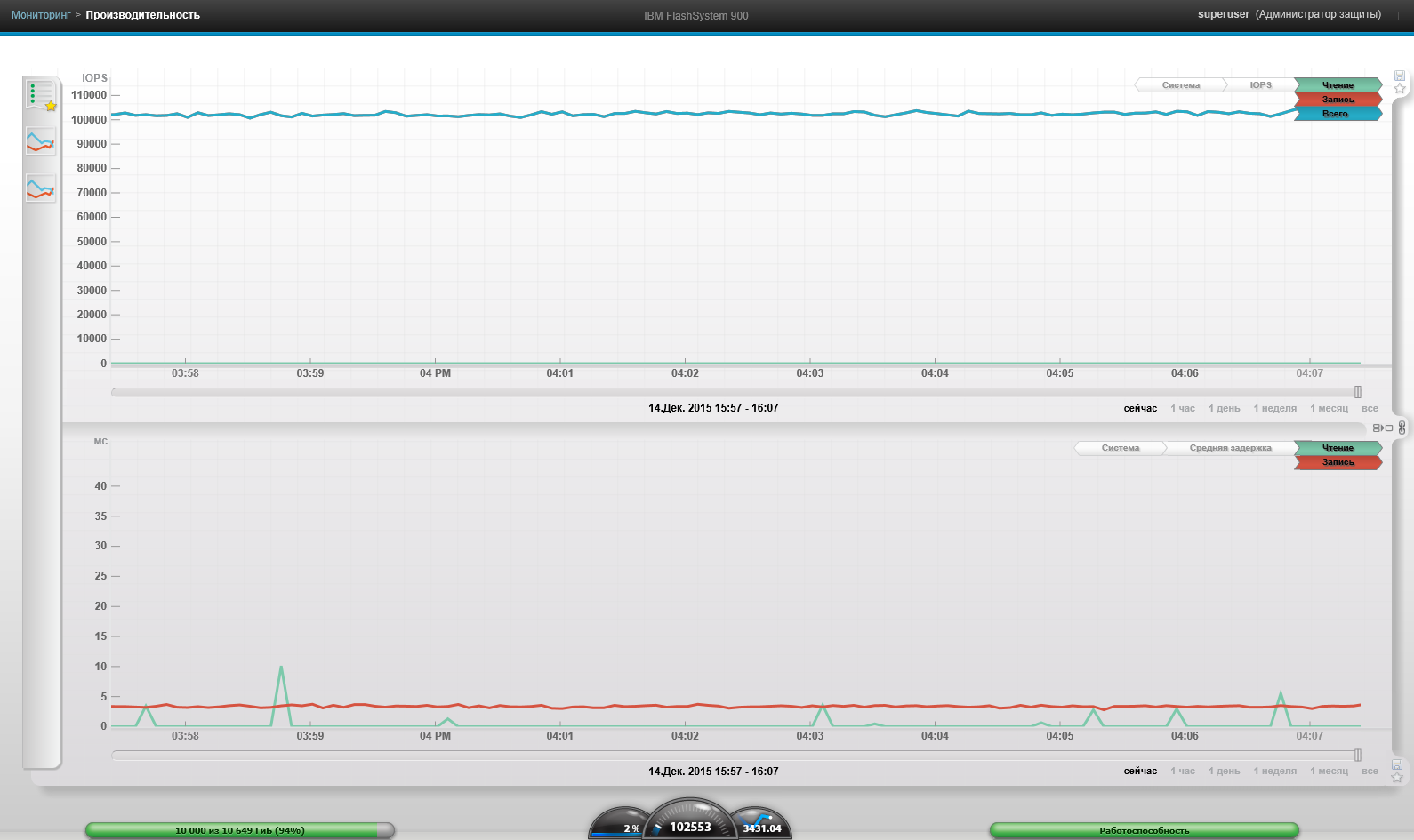
4 ВМ, Блок 4к, 0% чтение, 100% случайно, спустя 12 часов. Просадки в производительности мы не увидели.

1 ВМ, Блок 256к, 0% чтение, 0% случайно

4 ВМ, Блок 256к, 100% чтение, 0% случайно
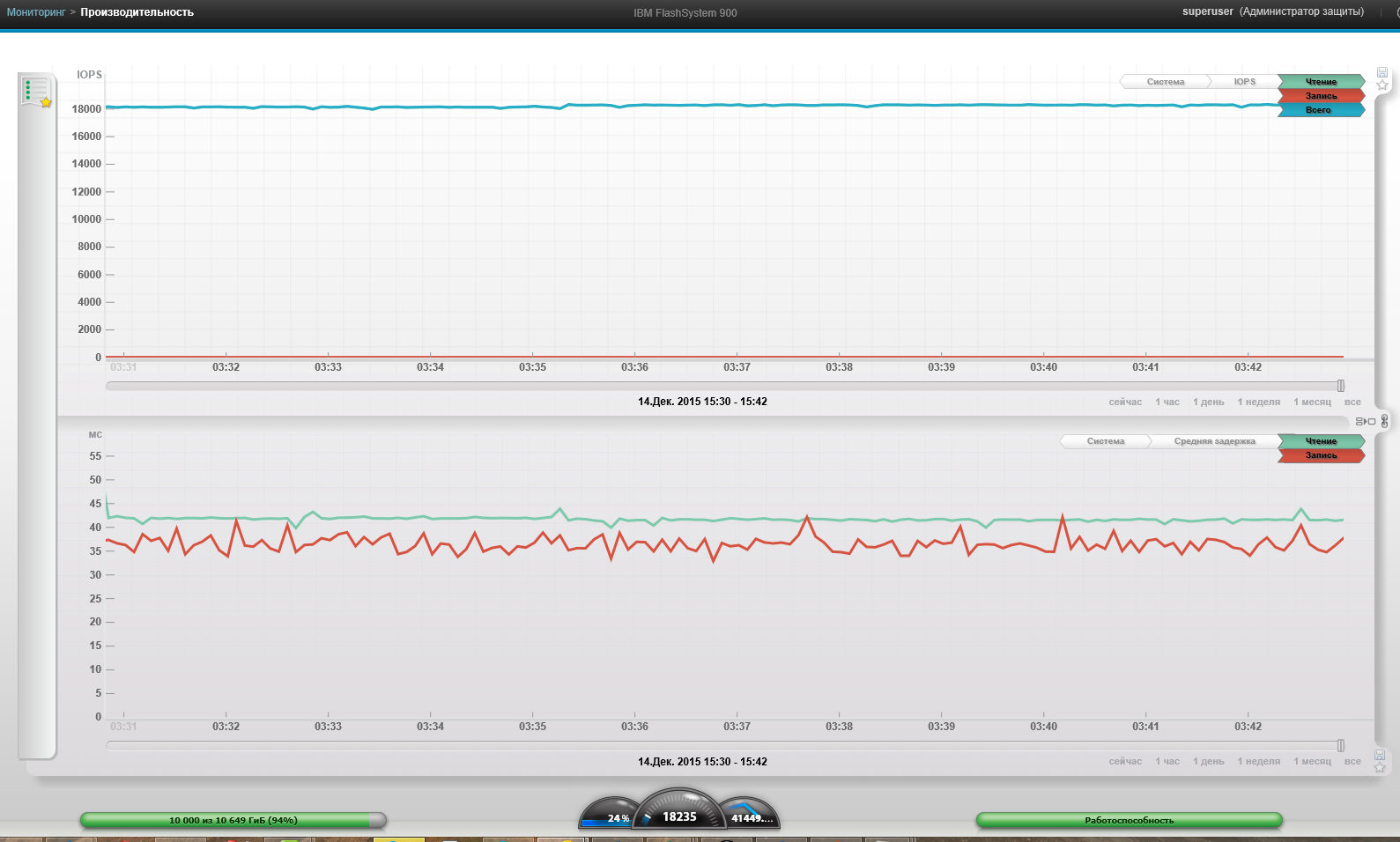
4 ВМ, Блок 256к, 0% чтение, 0% случайно
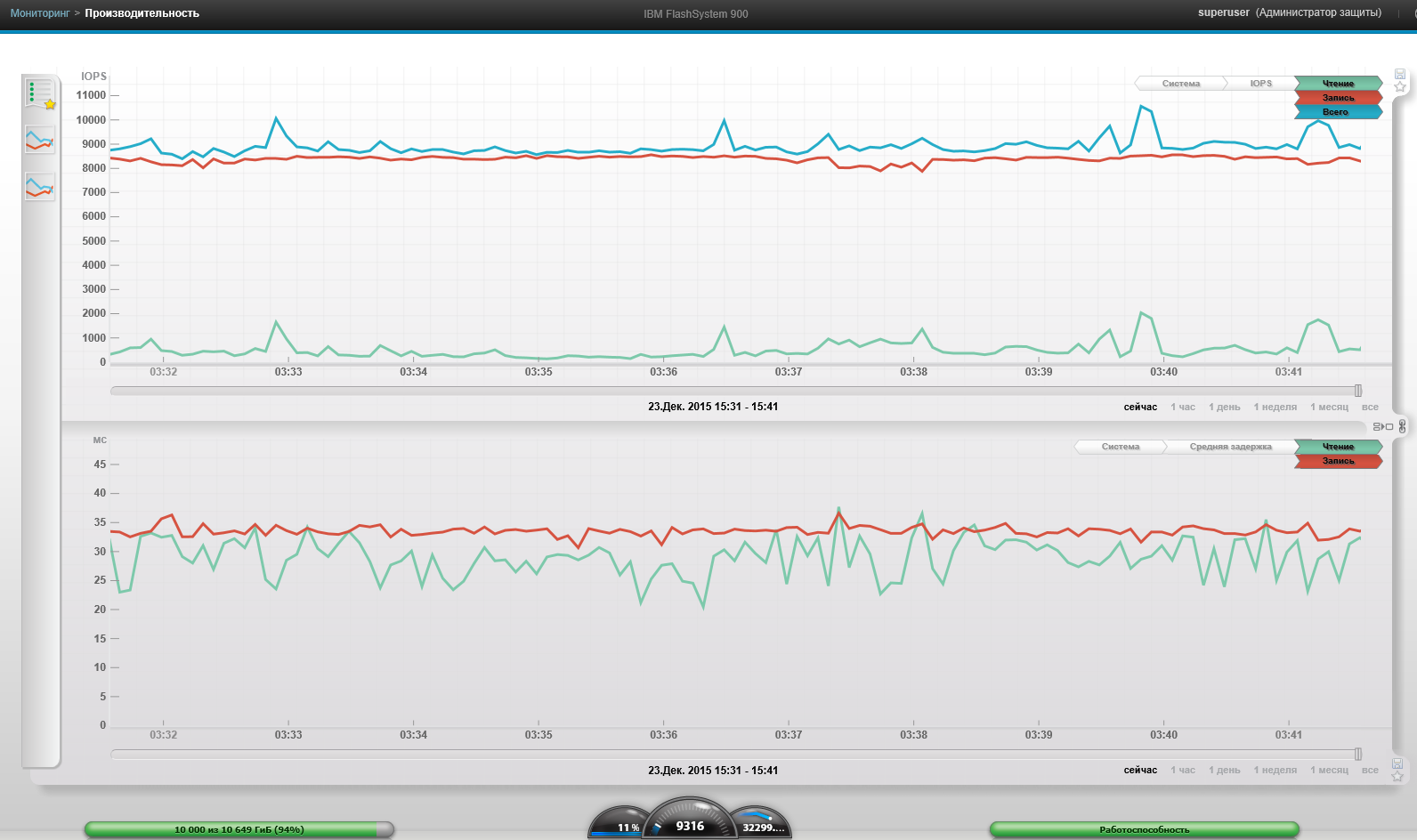
Максимальная пропускная способность системы (4 ВМ, Блок 256к, 100% чтение, 0% случайно)

4 ВМ, Блок 4к, 100% чтение, 100% случайно
4 ВМ, Блок 4к, 0% чтение, 100% случайно
4 ВМ, Блок 4к, 0% чтение, 100% случайно, спустя 12 часов. Просадки в производительности мы не увидели.
1 ВМ, Блок 256к, 0% чтение, 0% случайно
4 ВМ, Блок 256к, 100% чтение, 0% случайно
4 ВМ, Блок 256к, 0% чтение, 0% случайно
Максимальная пропускная способность системы (4 ВМ, Блок 256к, 100% чтение, 0% случайно)
Также отметим, что, как и у всех известных вендоров, заявленная производительность достигается только в тепличных лабораторных условиях (огромное количество SAN аплинков, специфичная разбивка LUN, использование выделенных серверов с RISK архитектурой и специально сконфигурированными программами-генераторами нагрузки).
Выводы
Плюсы: огромная производительность, простота настройки, дружелюбный интерфейс.
Минусы: за пределами емкости одной системы, масштабирование осуществляется дополнительными полками. «Продвинутый» функционал (снимки, репликация, компрессия) вынесен в слой виртуализации хранения. IBM построил четкую иерархию СХД, во главе которой виртуализатор хранения (SAN Volume Controller или Storwize v7000), который обеспечит многоуровневость, виртуализацию и централизованное управление вашей сети хранения.
Итог: IBM Flashsystem 900 выполняет свои задачи по обработке сотен тысяч IO. В текущей тестовой инфраструктуре удалось получить 68% производительности, заявленной производителем, что дает впечатляющую плотность производительности на ТБ.
Smasher
Все понятно с синтетическими тестами, но неплохо тестировать хотя бы с 8к блоком. Не знаю приложений, которые в реальной жизни работают с 4к блоком.
Что будет с производительностью и задержками, когда на пути данных появится SVC?
team_itpark
Oracal, например, работает с 4к блоками, некоторые файловые системы. По производительности: 110мкс время отклика самой флешки, 200 мкс время отклика SVC (при блоке 4к), т.е. IBM говорит, что SVC не просядет.