
if __name__ == '__main__':
data = sio.loadmat('ex6data1.mat')
y = data['y'].astype(np.float64)
X = data['X']
visualize_boundary_linear(X, y, None)
C = 1
model = svm_train(X, y, C, linear_kernel, 0.001, 20)
visualize_boundary_linear(X, y, model)
C = 100
model = svm_train(X, y, C, linear_kernel, 0.001, 20)
visualize_boundary_linear(X, y, model)
x1 = np.array([1, 2, 1], dtype=np.float64)
x2 = np.array([0, 4, -1], dtype=np.float64)
sigma = 2.0
sim = gaussian_kernel(x1, x2, sigma);
print('Gaussian Kernel between x1 = [1; 2; 1], x2 = [0; 4; -1], sigma = 0.5 : (this value should be about 0.324652)')
print('Actual = {}'.format(sim))
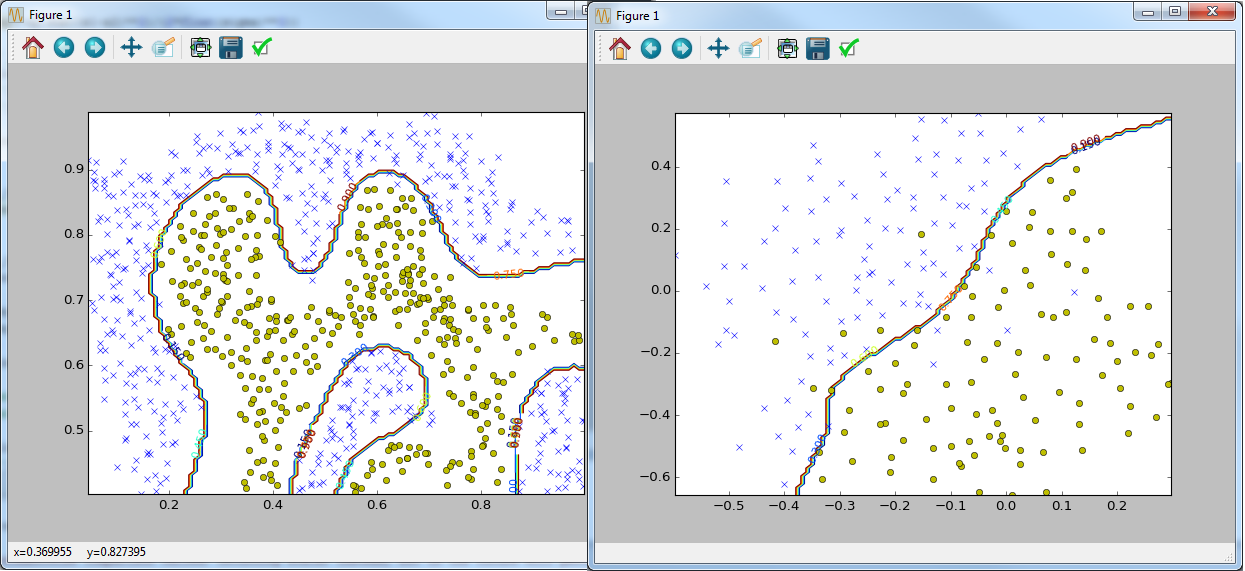
data = sio.loadmat('ex6data2.mat')
y = data['y'].astype(np.float64)
X = data['X']
visualize_data(X, y).show()
C = 1.0
sigma = 0.1
partialGaussianKernel = partial(gaussian_kernel, sigma=sigma)
partialGaussianKernel.__name__ = gaussian_kernel.__name__
model= svm_train(X, y, C, partialGaussianKernel)
visualize_boundary(X, y, model)
data = sio.loadmat('ex6data3.mat')
y = data['y'].astype(np.float64)
X = data['X']
Xval = data['Xval']
yval = data['yval'].astype(np.float64)
visualize_data(X, y).show()
best_C = 0
best_sigma = 0
best_error = len(yval)
best_model = None
for C in [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]:
for sigma in [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]:
partialGaussianKernel = partial(gaussian_kernel, sigma=sigma)
partialGaussianKernel.__name__ = gaussian_kernel.__name__
model= svm_train(X, y, C, partialGaussianKernel)
ypred = svm_predict(model, Xval)
error = np.mean(ypred != yval.ravel())
if error < best_error:
best_error = error
best_C = C
best_sigma = sigma
best_model = model
visualize_boundary(X, y, best_model)
Но так как Python есть своя популярная библиотека для этих целей scikit-learn, я попытался переписать некоторые задания с использованием этой возможности(соответствующие файлы с суффиксом sklearn). Как и требовалось ожидать код с библиотекой работает быстрые и выглядит компактнее и понятнее(с моей точки зрения).
if __name__ == '__main__':
data = sio.loadmat('ex6data1.mat')
y = data['y'].astype(np.float64).ravel()
X = data['X']
visualize_boundary(X, y, None)
C = 1
lsvc = LinearSVC(C=C, tol=0.001)
lsvc.fit(X, y)
svc = SVC(C=C, tol=0.001, kernel='linear')
svc.fit(X, y)
visualize_boundary(X, y, {'SVM(linear kernel) C = {}'.format(C): svc,
'LinearSVC C = {}'.format(C): lsvc})
C = 100
lsvc = LinearSVC(C=C, tol=0.001)
lsvc.fit(X, y)
svc = SVC(C=C, tol=0.001, kernel='linear')
svc.fit(X, y)
visualize_boundary(X, y, {'SVM(linear kernel) C = {}'.format(C): svc,
'LinearSVC C = {}'.format(C): lsvc})
data = sio.loadmat('ex6data2.mat')
y = data['y'].astype(np.float64).ravel()
X = data['X']
visualize_boundary(X, y)
C = 1.0
sigma = 0.1
gamma = sigma_to_gamma(sigma)
svc = SVC(C=C, tol=0.001, kernel='rbf', gamma=gamma)
svc.fit(X, y)
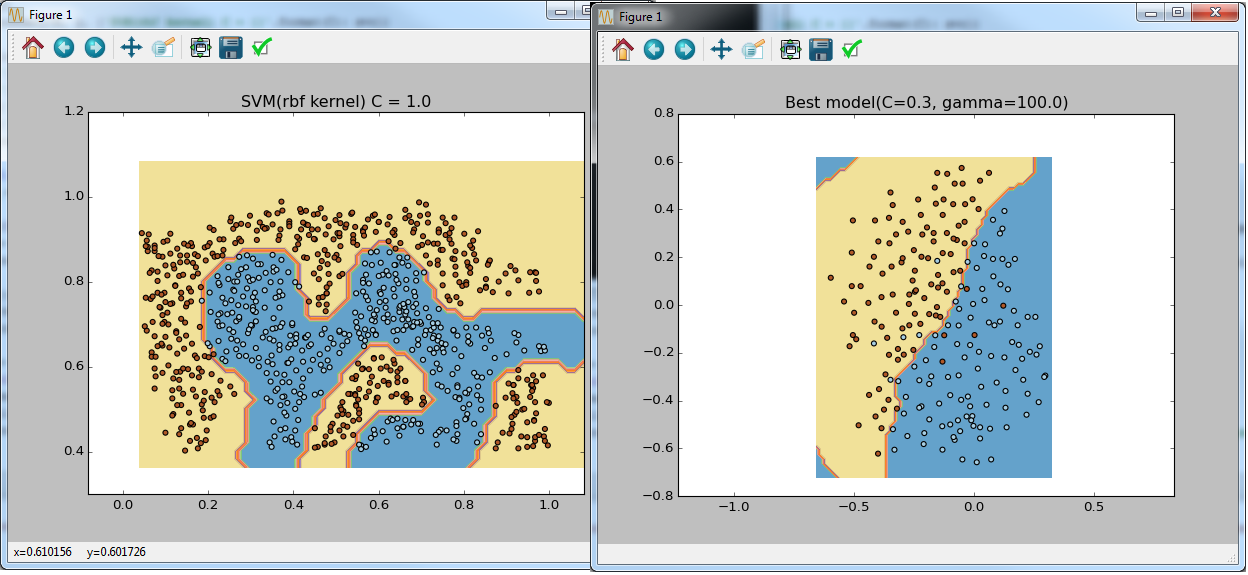
visualize_boundary(X, y, {'SVM(rbf kernel) C = {}'.format(C): svc})
data = sio.loadmat('ex6data3.mat')
y = data['y'].astype(np.float64).ravel()
X = data['X']
Xval = data['Xval']
yval = data['yval'].astype(np.float64).ravel()
visualize_boundary(X, y)
C_coefs = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]
sigma_coefs = [0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30]
svcs = (SVC(C=C, gamma=sigma_to_gamma(sigma), tol=0.001, kernel='rbf') for C in C_coefs for sigma in sigma_coefs)
best_model = max(svcs, key=lambda svc: svc.fit(X, y).score(Xval, yval))
visualize_boundary(X, y, {'Best model(C={}, gamma={})'.format(best_model.C, best_model.gamma): best_model})
#Let's do the similar thing but using sklearn feature
X_all = np.vstack((X, Xval))
y_all = np.concatenate((y, yval))
parameters = {'C':C_coefs, 'gamma': map(sigma_to_gamma, sigma_coefs)}
svr = SVC(tol=0.001, kernel='rbf')
clf = GridSearchCV(svr, parameters, cv=2)
clf.fit(X_all, y_all)
visualize_boundary(X, y, {'Best model(C={}, gamma={})'.format(clf.best_params_['C'], clf.best_params_['gamma']): clf})
P.S.
Для тех кому интересна библиотека Sklearn я бы посоветовал:
Курс на udacity
Видео 1 с pycon
Видео 2 с pycon
P.P.S
Для разработки и запуска примеров я использовал дистрибутив Anaconda
Комментарии (17)

myxo
02.02.2016 13:57+4Мил человек, извините, но это не дело. Я вполне уверен, что где-нибудь в правилах написано, что статья — это не просто портянка кода. К тому же все это уже делали до вас (например вот — github.com/subokita/mlclass 1 выдача в гугле).

yorko
02.02.2016 13:58+1Ну и сложно не дать ссылки на курсы отчественного корифея К.В. Воронцова & Co на Coursera с ВШЭ ( курс идет сейчас) и МФТИ (целая специализация, скоро начнется). Там все примеры и домашки на Python с Anaconda.

Zenker
02.02.2016 17:07+2К сожалению, пока этот курс нельзя сравнивать с лучшими представителями жанра (Вашингтон и Стэнфорд). Собственно, курсом это назвать сложно, получился скорее обзор имеющихся инструментов в области ML. Лекции представляют собой проговаривание формул и определений из книжек без особой причинно-следственной связи и для человека, не владеющего предметом на уровне одного из вышеобозначенных курсов — абсолютно бесполезны. А в практических заданиях самое сложное — угадать, в каком формате нужно предоставить ответ, чтобы он прошёл валидацию. Такое вот впечатление от первых двух недель.
yorko
02.02.2016 14:27+1redlinelm, начинание неплохое, но статья, извините, отстой. Позвольте дать Вам несколько советов, чтоб люди не чмырили:
- Перед тем, как что-то публиковать, изучите, что делали до Вас. Это верно и для академической, и для корпоративной, и для бизнес-активности.
- Пишите комментарии в коде. Это необходимое условие командной работы. Причем комментарии подробные, а не # так лучше. Scikit-learn стал так популярен в том числе благодаря прекрасной документации.
- Статью пишите на русском. Если это не тьюториал, кода в ней вообще не должно быть. Для кода есть GitHub.
- В проекте GitHub опять-таки должен быть внятный README, если Вы с кем-то делитесь кодом.
- Наконец, пишите грамотно. «Решил я познакомится»… уже с этих трех слов уровень доверия к источнику падает. Описание проекта у Вас «This is python implementation of Programming Exercises for».
Zenker
02.02.2016 16:58Есть хорошая серия курсов по ML от University of Washington, как раз на питоне: www.coursera.org/specializations/machine-learning
PS Курсы можно проходить бесплатно по отдельности, не в составе специализации.
yorko
Идея переписать все самому на Python с Sklearn похвальна. По крайней мере, самому это очень полезно.
Подобный репозиторий уже, однако, есть.
yorko
Правда, зачем в статье код без коментов — непонятно. Код можно и на гитхабе почитать.