
Это история о том, как написать компилятор Python, генерирующий оптимизированные ядра и при этом позволяющий сохранить простоту кода.
Предисловие
Наши читатели традиционно интересуются, как и что работает под капотом, будь то интерпретаторы, компиляторы и различные среды исполнения. Особенно важно при этом учитывать, на какие компромиссы в области производительности в каких случаях требуется идти. Для разбора всех этих вопросов отлично подходит Python: язык популярен благодаря своей простоте, но именно эта простота зачастую оборачивается плохой производительностью, как только приходит время серьёзных рабочих нагрузок.
Вот почему автор решил написать этот пост в соавторстве с Юсуфом Олокобой, основателем компании Muna. Ниже рассмотрено, как можно вывести Python за привычные рамки его скорости и улучшить портируемость кода. Для этого нужно написать компилятор, который будет превращать обычный код в быстрые и легко переносимые исполняемые файлы.
Здесь мы не будем собирать очередной JIT-компилятор или переписывать всё на C++, а расскажем, как создавать оптимизированные ядра, при этом совершенно не затрагивая исходный код Python. Этот материал непосредственно связан с такими темами, как внутреннее устройство CPython и инженерия производительности. Для изучения этих тем необходимо понимать, как устроены системы на максимально низком уровне.
Введение
Идея этого проекта родилась у соавторов в начале 2024 года, когда мы пытались подробнее разобраться, как именно интерпретатор Python работает под капотом. Мы хотели написать инструмент, который мог бы компилировать первозданный код Python в кроссплатформенный машинный код.
Ранее к этой идее неоднократно подступались в разных формах: разрабатывали среды исполнения (Jython, RustPython), предметно-ориентированные языки (Numba, PyTorch) и даже новые языки программирования (Mojo). Но по причинам, которые будут рассмотрены ниже в этой статье, нам требовался инструмент, который умел бы следующее:
Компилировать Python в полностью опережающем режиме, без каких-либо модификаций.
Работать без интерпретатора Python и без какого-либо другого интерпретатора.
Работать с минимальными накладными расходами по сравнению с программой, написанной на необработанном C или C++.
Самое важное, что код должен работать на любой платформе — сервер, ПК, мобильные устройства и браузер.
В этой статье мы подробно разберём, как зародилась эта на первый взгляд безумная идея, расскажем, как приступили к реализации решения, как оказалось, что недостающее звено в нашем случае – это ИИ, как мы доросли до обслуживания тысяч уникальных устройств в месяц, и как нам в этом помогают описанные здесь скомпилированные функции, написанные на Python.
Контейнеры — не лучший вариант для распространения сборок при работе с ИИ
Я взялся за исследование искусственного интеллекта в 2018 году, когда его ещё было принято называть «глубокое обучение». Тогда я год как окончил колледж и приобретал опыт на моём первом стартапе. Я был сооснователем стартапа по технологиям в области недвижимости (proptech), поднятого за счёт привлечения венчурного капитала. В тот период мне пришлось решать по работе одну очень интересную задачу: реализовать рендеринг для поисковой выдачи объектов недвижимости. Каждый месяц фотограф по объектам выдавал на аутсорсинг тысячи фотографий домов, которые приходилось вручную редактировать в Photoshop и Lightroom перед тем, как вывесить их на региональном мультилистинге или на Zillow.
Я заручился поддержкой старого друга, и мы взялись написать полностью автоматизированный редактор изображений, воспользовавшись для этого (тогда ещё) новоиспечёнными ИИ-моделями компьютерного зрения, которые называются «генеративно-состязательные нейронные сети» (GAN). Мы самостоятельно разрабатывали архитектуры моделей, которые сами же обучали на тренировочных множествах данных (датасетах), а затем тщательно тестировали, чтобы убедиться, что они функционируют правильно. Но когда пришло время передавать эти ИИ-модели нашим партнёрам-дизайнерам, мы просто застряли. На данном этапе я потратил массу времени, пытаясь упаковать наши модели в такой форме, в которой их было бы максимально легко распространять. Но после многомесячных мытарств с докерфайлами и сторонними сервисами я предельно чётко осознал: контейнеры не подходят для распространения рабочих нагрузок, связанных с использованием искусственного интеллекта.
Чтобы понять, почему так, давайте подробнее рассмотрим, что такое контейнер. Контейнеры — это просто самодостаточные файловые системы Linux, в которых изолирована среда исполнения и налажено управление ресурсами. Поэтому при развёртывании ИИ-модели в качестве контейнера нам пришлось бы упаковать в него код логического вывода, веса модели, все зависимости пакетов Python, сам интерпретатор Python и все другие необходимые программы. Фактически, в контейнере должен лежать мгновенный снимок полноценной операционной системы Linux.

Но что если мы не будем оперировать не полноценной операционной системой, а сделаем самодостаточный исполняемый файл, который будет гонять нашу ИИ-модель и больше ничего не делать? Польза от этого более чем ощутима: в таком случае можно было бы распространять гораздо более компактные контейнеры, которые при этом будут быстрее запускаться, поскольку не придётся упаковывать ненужные пакеты Python, сам интерпретатор Python, а также весь прочий избыточный мусор, который обычно попадает в контейнер. При этом даже важнее, что нам удалось запускать эти исполняемые файлы не только на наших серверах с Linux, но и где угодно.
Arm64, Apple и Unity: как всё начиналось
Я начал программировать, когда мне было одиннадцать — спасибо папе, который отчаянно отказывался покупать мне PlayStation 2, опасаясь за мою успеваемость в школе. Из крайней упорности, унаследованной как от него, так и от мамы, я решил: раз уж он не будет дарить мне игровую приставку, придётся мне писать игры самостоятельно. Тепло вспоминаю Rumble Racing и Sly Cooper: не самые известные тайтлы для PS2, но именно те игры, которые мне особенно ценны и связаны с самыми сентиментальными воспоминаниями, оставшимися у меня со времён взросления.
Мне повезло найти интуитивно понятный игровой движок, позволявший разработчику собрать проект однажды, а затем развернуть где угодно — и, самое главное, бесплатный. Это был Unity Engine.
В конце 2013 года выкатила iPhone 5S — первый смартфон, оборудованный относительно новой тогда архитектурой с набором команд armv8-a. В отличие от начинки более ранних моделей, это была 64-разрядная архитектура, работавшая на процессоре ARM. Благодаря ней приложения могли адресовать гораздо больше памяти, а также использовать массу приёмов для повышения производительности. В связи с этим Apple вскоре ввела обязательное требование компилировать все новые приложения под arm64.
Движок Unity с его обширной экосистемой для разработчиков вошёл в штопор. Чтобы понять, почему, давайте в более широком контексте рассмотрим, как именно работает Unity. Поскольку Unity — это игровой движок, внутриигровые объекты можно программировать в виде скриптов, закладывая в них таким образом специальные поведения. В качестве скриптового языка в Unity выбрали C#, на нём эти поведения и программируются. Но C# не компилируется в объектный код, поэтому ему требуется виртуальная машина, которая работала бы во время выполнения (знакомо звучит?). В Unity для этой цели используется Mono, но Mono не поддерживает arm64.
В Unity всерьёз взялись за разработку такой штуки, которая, как я считаю, до сих пор остаётся наивысшим шедевром их инженерного мастерства: IL2CPP. Как понятно из названия, компилятор IL2CPP берёт байт-код «высокоуровневого ассемблера» Common Intermediate Language bytecode (т.e., промежуточное представление, сгенерированное компилятором C#), а затем выдаёт эквивалентный ему исходный код на C++. Имея исходный код C++, вы можете его скомпилировать и запускать этот код практически где угодно: от видеокарт Nvidia и WebAssembly до Apple Silicon и на всём, что между ними.

Мы решили написать ровно такой же инструмент для работы с Python.
Компилятор для Python: общий план

В самом общем виде он должен:
Поглощать обычный код на Python, который для этого никак не требуется модифицировать.
Трассировать его, чтобы на основе полученной информации сгенерировать граф промежуточного представления (IR).
Понижать IR до исходного кода на C++.
Компилировать исходный код C++ так, чтобы он работал на самых разных платформах и архитектурах.
Прежде, чем взяться за это со всей серьёзностью, вы могли бы спросить: а зачем лишний раз утруждать себя предварительной генерацией кода на C++? Почему бы не перейти от IR сразу к объектному коду?
Напомню, по какой причине мы вообще пошли по этому пути. Основной акцент тех задач, которыми нам приходилось заниматься в Muna, заключался в работе с приложениями, требовавшими высокоинтенсивных вычислений — в частности, мы имели дело с логическим выводом ИИ. Если вы уже работали в этой сфере, то слышали о таких технологиях как CUDA, MLX, TensorRT и т.д. Но на самом деле у нас в распоряжении настолько больше прочих фреймворков, библиотек и даже недокументированных стандартных архитектур (ISA), что в приложениях можно ускорить практически любые операции — от перемножения матриц до компьютерного зрения.
Мы хотели спроектировать систему, в которой можно было бы задействовать настолько много вариантов выполнения конкретной вычислительной операции, сколько вообще доступно на конкретном образце железа. Мы расскажем вам, как у нас это получилось, и как такой дизайн открыл нам новый подход к оптимизации производительности с опорой на данные.
Пишем символьный трассировщик для Python
Приступая к созданию компилятора, нам первым делом требовалось построить символьный трассировщик. Задача трассировщика — принять функцию Python и на её основе выдать граф промежуточного представления (IR), в которой полностью схвачен поток управления, реализуемый на протяжении этой функции.
Наши самые первые прототипы мы собрали на основе символьного трассировщика PyTorch FX, появившегося в PyTorch 2.0. Они разработали свой символьный трассировщик, опираясь на PEP 523 — одну возможность CPython, позволявшую разработчикам, оперирующим C, переопределять, как именно интерпретатор будет вычислять кадры байт-кода. Здесь я не буду слишком вдаваться в детали, поскольку и этот инструмент по праву считается шедевром программной инженерии. Если коротко, благодаря PEP 523 команда PyTorch смогла регистрировать хук, через который записывался вызов каждой отдельной функции, вычисляемой интерпретатором.
К сожалению, у TorchFX нашлось два существенных недостатка, из-за которых нам пришлось писать наш собственный трассировщик. Во-первых, как только вы подрубаетесь к интерпретатору CPython, собираясь записать вашу функцию PyTorch, вам не обойтись без прогона указанной функции. В PyTorch это не проблема, так как вашу функцию можно вызвать с так называемыми «фиктивными тензорами», имеющими правильные типы данных, форму и настроенные на нужные устройства — но под которые при этом не выделяется память. Более того, если вызывать таким образом функцию лишь для того, чтобы её отследить, то эта функция будет отлично встраиваться. Именно так и были устроены API для сериализации, унаследованные из Torch (torch.jit и torch.onnx).
Поскольку нам требуется возможность компилировать произвольные функции, из которых (в лучшем случае) малая толика будет написана на PyTorch, хотелось бы иметь подобный механизм. При помощи такого механизма разработчики могли бы предоставлять нам в качестве ввода свою информацию, которую мы бы затем отслеживали. Но, в отличие от PyTorch, мы не могли сымитировать ни картинку, ни строку, ни вообще что-нибудь. Так что для нас этот путь оказался тупиковым.
Вторая проблема заключалась в следующем: даже при успешном создании фиктивных данных в качестве ввода для трассировщика TorchFX оказалось, что он может записывает только операции, выполненные с применением PyTorch. Нам пришлось бы сильно модифицировать и расширять инструмент, чтобы поддерживать трассировку произвольных функций, относящихся к сотням и тысячам библиотек Python. Таким образом, мы решили написать трассировщик, который захватывал бы функцию Python путём разбора её абстрактного синтаксического дерева (AST). Рассмотрим в качестве примера следующую функцию:

Сначала наш трассировщик извлечёт AST вот так:

compute_area, приведённой выше Затем он шаг за шагом проходит дерево, разрешает все вызовы функций (то есть выясняет, из какой библиотеки происходит каждая конкретная функция), а затем выдаёт их в проприетарном IR-формате. В настоящее время наш символьный трассировщик поддерживает статический анализ (путём парсинга AST); частичное вычисление исходного кода Python; live-интроспекцию значений (через песочницу) и многое другое. Но так сложилось, что это наименее интересная часть конвейера, реализованного в нашем компиляторе.
Понижение до C++ путём распространения типов
Вот здесь становится по-настоящему интересно. Язык Python динамический, поэтому переменная может быть любого типа, и типы у переменных могут легко меняться:

С другой стороны, C++ — строго типизированный язык, где переменные обладают отчётливыми неизменяемыми типами, и тип переменной должен быть известен уже на этапе его объявления. Притом, что попытка совместить два таких языка может показаться неосуществимой, мы обнаружили ключевой фактор, который как раз нам пригодился. Python и C++ сочетаются, если понизить код Python, и, чтобы понять этот механизм, нужно разобраться, как в C++ работает неявное инстанцирование шаблонов. Функция Python определяет шаблонную функцию. На ввод подаются типы, на основе которых мы затем создаём конкретный экземпляр функции.
Когда мы вызываем функцию Python, на ввод которой даны некоторые значения, мы можем точно определить каждый промежуточный тип, который переменная принимает в рамках этой функции:

Если мы знаем, что входные значения x и y являются экземплярами float, то нам известно, чем определяется тип, который будет у их произведения (т.e., tmp_1). То есть, мы поймём тип результирующего значения, что бы ни вернула функция operator.mul. Но как именно мы определяем operator.mul и узнаём её возвращаемый тип? В этом нам поможет C++.
Строго говоря, наш компилятор выдаёт код не только в C++. C++ — наш основной язык для генерации кода, но иногда мы также получаем из него код на Objective-C и Rust. В настоящее время мы также активно исследуем компиляцию Python в Mojo.

Как показано выше, теперь мы узнали, что tmp_1 обязательно должна быть типа float. Этот процесс можно повторить с вызовом, в котором выполняется сложение (tmp_1 + z) и получить окончательный результат.
Здесь давайте сделаем паузу и предварительно подытожим, чего мы уже добились:
Можно взять функцию Python и сгенерировать промежуточное представление (IR), в котором полностью зафиксировано всё, что делает эта функция.
Затем можно пользоваться информацией о параметрах типа. В реализации оператора Python на C++ (напр.,
operator.mul) это позволит полностью определить первую промежуточную переменную в нашей функции Python.Шаг (2) можно повторить со всеми промежуточными переменными нашей функции Python и так до тех пор, пока мы не распространим типы в пределах всей функции.
Инициируем процесс распространения типов
Здесь стоит подробнее обсудить один момент: как получить начальную информацию о параметрах типа, чтобы можно было приступить к распространению типа. То есть, возвращаясь к предыдущему примеру, откуда мы узнаем, что каждый экземпляр x, y и z относится к типу float?
Попробовав несколько разных подходов к прототипированию, мы остановились на PEP 484, в котором в Python добавляются аннотации типов. Сам Python такие аннотации типов игнорирует, поскольку во время выполнения они не используются. Из этого правила есть одно важное исключение: это библиотеки для валидации данных, такие, как Pydantic. Они опираются на подсказки типов при выстраивании схем для валидации и сериализации данных.
Действительно, аннотации решают проблему запуска распространения типов, но нам не подошли по двум серьёзным причинам. Во-первых, они противоречат самой важной цели, которую мы ставили при проектировании, ведь при работе с ними код Python требуется немного изменить. При этом аннотации типов нужны только в той функции, которая служит точкой входа в компилятор (речь о функции, декорированной при помощи @compile). Все прочие функции по принципу утиной типизации считаются нормальными:

На первый взгляд, код особенно не изменился, и есть мнение, что аннотации типов идут коду Python только на пользу.
Вторая проблема заключалась в следующем: чтобы выстроить простой модульный интерфейс, через который потреблялись бы скомпилированные функции, потребовалось бы ограничить количество разных подаваемых на вход типов, имеющихся в распоряжении у разработчиков. В конечном итоге мы решили, что на это можно пойти ради повышения эргономичности. Естественно, это ограничение распространяется лишь на ту функцию, что служит точкой входа в компилятор (ту самую, которая декорирована при помощи @compile). Все прочие функции принимают на вход какие угодно типы и на выход также возвращают произвольные типы.
Пишем библиотеку операторов C++
Возможно, вы уже заметили, что в нашем проекте зияет огромная проблема: нам потребуется реализовывать на C++ десятки тысяч, а то и сотни тысяч функций Python, рассеянных по разным библиотекам. К счастью, сделать это гораздо проще, чем может показаться. Рассмотрим функцию, приведённую ниже:

Компилируя cosecant, замечаем в ней вызовы функций sin и reciprocal. Сначала наш компилятор проверит, может ли он до конца проследить каждый из этих вызовов функций. Например, у нас нет определения функции sin (только import), поэтому полностью проследить её мы не можем. Так в дереве образуется листовой узел, который нам придётся вручную реализовать на C++. Наш декоратор @compile может предоставить список модулей trace_modules, в который вносятся целые модули для отслеживания. Те функции, которые не предоставляются в исходном коде Python от разработчика, нужно явно заносить в список для отслеживания.
Можно полностью проследить вызов к reciprocal, поэтому так мы и сделаем, а также получим для неё граф промежуточного представления. Этот код можно понизить и использовать в других точках вызова.
Важнейший вывод, который следует из вышеизложенного — каждая из большинства функций Python, которые попадутся нашему компилятору, сама представляет собой набор более мелких элементарных функций. При этом встречающийся в программах код на Python настолько разнообразен не потому, что таких элементарных функций слишком много, а потому, насколько разнообразные комбинации из них складываются.
Тем не менее, можно утверждать, что в различных библиотеках потенциально могут найтись тысячи таких элементарных функций, и все их нам придётся учесть — и это абсолютно верно. К счастью, теперь у нас есть мощное орудие, при помощи которого эта проблема легко решается. Я говорю о генерации кода с поддержкой ИИ.
Современные большие языковые модели (БЯМ) способны писать проверяемо корректный высокопроизводительный код на самых разных языках программирования. В таких условиях мы выстраиваем инфраструктуру, позволяющую ограничивать генерируемый ими код, проверять код, обеспечивая его корректность и обрабатывать вспомогательную логику, касающуюся таких вещей как управление зависимостями и условная компиляция. Мы уже успели при помощи ИИ сгенерировать реализации сотен функций Python из таких популярных библиотек как Numpy, OpenCV и PyTorch.
Оптимизация производительности путём исчерпывающего поиска
Наконец, стоит обсудить оптимизацию производительности. Наиболее популярные подходы, применяемые в данном случае — выкатывать написанный вручную код (например, на ассемблере или PTX); использовать гетерогенные ускорители (напр., GPU, NPU); выполнение алгоритмической выборки на эвристической основе во время выполнения (напр., алгоритмический поиск с использованием свёрточных нейронных сетей, см. ArmCL и cuDNN). Возможна какая-то комбинация этих методов.
Имеющийся у нас опыт (ранее мы создавали конвейеры компьютерного зрения для встраиваемых систем, и в этих системах требуется максимально низкая задержка) научил нас горькой правде: эффективная оптимизация производительности всегда делается эмпирически. Задержка, характерная для заданной операции или для конкретного аппаратного компонента зависит от столь многих факторов, что, желая проверить наверняка, вы просто будете вынужден вручную проверить каждый из применяемых вами подходов. В командах разработчиков это обычно не делается только потому, что такой подход непрактичен; вам пришлось бы переписывать код десятки или сотни раз, а затем тестировать каждый вариант… но подождите!
Ранее мы разобрали, как можно распространять типы через функцию Python при помощи оператора C++. Но я тогда не упомянул, что мы используем не просто отдельно взятый оператор C++, а столько таких операторов, сколько сможем написать (эхм, сгенерировать). То есть, вместо вот этого:

Понимаете, мы не просто генерируем программу C++ на основе функции Python.
Вот что происходит на самом деле:

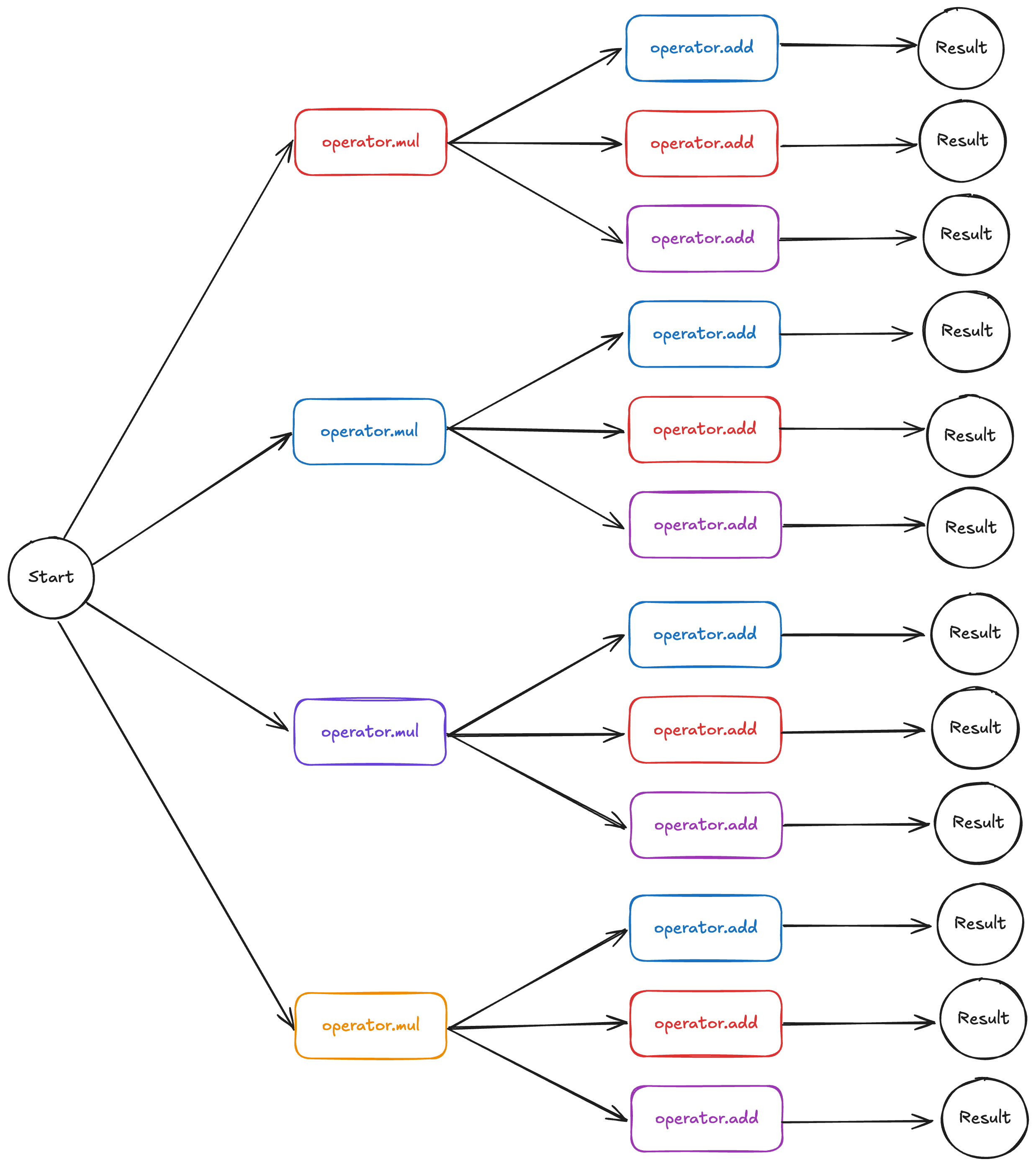{kind=link}
Из отдельно взятой функции на Python мы сгенерируем столько программ на C++, сколько сможем.
Каждый путь от start до result — это уникальная программа, гарантированно корректная относительно исходной функции Python. Но каждый оператор C++ (разноцветные прямоугольники) может работать на основе разных алгоритмов, библиотек и даже аппаратных ускорителей. Давайте разберём конкретный пример:

Функция, приведённая выше, пересчитывает размер полученного на вход изображения, задавая ему формат 64x64. Это делается методом билинейной дискретизации при помощи библиотеки torchvision. Если нужно скомпилировать эту функцию под Apple Silicon (macOS, iOS или visionOS), то искомое преобразование можно сделать несколькими способами, в частности:

Выше приведены лишь некоторые возможности, поскольку существует очень много способов реализовать изменение размера изображения с билинейной дискретизацией на Apple Silicon (напр., с использованием GPU, Neural Engine). В данном случае наиболее важно, что при генерации кода с использованием LLM можно получить сколько угодно таких вариантов, а потом собрать по отдельной программе для использования каждой из этих версий — предела нет. Таким образом, в предыдущем примере компилятор выдаст на основе пользовательской функции, написанной на Python, четыре уникальные программы только для Apple Silicon. При тестировании такого подхода в реальных условиях случалось, что на материале одной функции Python компилятор выдавал почти 200 уникальных программ для 9 целевых платформ.
Отталкиваясь от этого, можно с лёгкостью протестировать каждую скомпилированную функцию и выяснить, какая из них быстрее всего выполняется на заданной аппаратной платформе. Мы собирали данные телеметрии с высокой детализацией, в которых фиксировалась задержка для каждой операции. На основе этих данных мы строили статистические модели, позволявшие спрогнозировать, какой вариант окажется самым быстрым. Такой подход к проектированию имеет два важных достоинства:
Можно оптимизировать код чисто эмпирически. Мы не делаем никаких допущений о том, какой код может оказаться самым быстрым; также не приходится в качестве отдельного этапа оптимизировать производительность уже сгенерированного кода. Мы просто пускаем в работу каждый из имеющихся у нас скомпилированных двоичных файлов, собираем информацию о телеметрии и на основании этих данных находим самый быстрый вариант.
Нам на помощь приходит сетевой эффект. Дело в том, что одни и те же операторы C++ используются сразу в тысячах скомпилированных функций. При этом, поскольку мы рассылаем скомпилированные функции на сотни тысяч уникальных устройств всем нашим пользователям, у нас есть настоящее изобилие данных, на основе которых можно оптимизировать любой фрагмент сгенерированного нами кода.
А нашим пользователям кажется, будто скомпилированные функции Python со временем работают всё быстрее, как на автопилоте.
Разрабатываем пользовательский интерфейс для компилятора
Теперь давайте заключим всё вышеописанное в пользовательский интерфейс. Самый важный принцип, которым мы руководствуемся — минимально нагружать голову, что бы мы ни проектировали. В частности, мы хотим, чтобы для работы с компилятором разработчикам не приходилось изучать ничего нового. Поэтому мы решили обойтись декораторами, описанными в PEP 318:

Разработчики могут просто декорировать имеющуюся функцию Python при помощи @compile, указав таким образом входную точку, с которой начнётся компиляция. Затем функция и все её зависимости будут скомпилированы с использованием CLI:


Мы настолько влюбились в парадигму с использованием декораторов, так как увидели, что разработчики решительно предпочитают программировать сложную инфраструктуру как код. При этом мы вдохновлялись такими проектами как Pulumi и Modal. Кроме того, это свойство уже было известно нам из работы с экосистемой Python, в частности, поскольку получило распространение в Numba и PyTorch. По декоратору CLI может найти функцию, которая служит отправной точкой для компилятора, оттолкнуться от неё как от трамплина и далее проплыть через весь прочий код зависимостей (как предоставленных самим разработчиком, так и взятых из сторонних пакетов, установленных через pip или uv).
Кроме того, декоратор @compile послужит основной точкой кастомизации для разработчиков, компилирующих свою функцию. Кроме обязательных tag (который служит уникальным идентификатором функции на нашей платформе) и description программисты могут предоставить описание песочницы, по которому можно будет воссоздать ту локальную среду, в которой разрабатывалась функция (напр., указать, какие пакеты Python установить, закачать файлы). Наряду с этим используется атрибут metadata, помогающий компилятору при генерации кода (например, с логическим ИИ-выводом в PyTorch с применением ONNXRuntime, TensorRT, CoreML, IREE, QNN и пр.).
После того, как функция скомпилирована, кто угодно может выполнить её где угодно:

Заключительные мысли
Со всей серьёзностью должны признаться, что сами не могли поверить, что что-либо из этого действительно сработает. При всём сказанном, у компилятора есть ряд стандартных недостатков Python, связанных с тем, что в этом языке что-то отсутствует или реализовано частично: речь об исключениях, лямбда-выражениях, рекурсивных функциях и классах. Общая беда, которую вызывают все эти недостающие звенья, прослеживается на уровне разработанной нами системы распространения типов. Притом, что распространение типов хорошо работает на уровне простых функций, имеющих унитарные параметры и возвращаемые типы, эта система требует лишний раз задуматься, как работать с составными типами (например, объединениями) и типами высшего порядка (например, классами, лямбда-выражениями).
Другой важный аспект, который мы до сих пор не довели до ума — процедура отладки. Положительный момент в том, что мы гарантируем: будучи скомпилирован, написанный разработчиком код Python станет работать именно так, как ожидается. Тем самым разработчик целиком избавлен от необходимости отлаживать код во время выполнения. Напоминает ситуацию с использованием Docker или других технологий контейнеризации: прибегая к ним, рассчитываешь, что всё просто сразу будет работать. Почти никто не отлаживает слои в своём образе Docker. Отрицательный момент в том, что, поскольку мы позволяем разработчикам запускать их код Python где угодно, именно нам приходится позаботиться о том, чтобы наш код получался максимально безопасным и придумать, как в случае поступления исключения от какой-либо функции собрать высоко детализированные данные трассировки. Эта проблема тем более осложняется тем, что нам приходится стараться предоставлять максимально компактные и быстрые двоичные файлы. Поэтому мы компилируем код в полностью оптимизированном виде, что вынуждает нас убирать из него ценную информацию, которая могла бы пригодиться при отладке.
Правда, всё это было не так сложно, в особенности потому, что постоянно развивающийся стандарт C++ сильно облегчил нам работу. Продукт Muna не состоялся бы без C++20, поскольку при генерации кода мы очень во многом полагаемся на концепции std::span, а также на корутины. Из стандарта C++23 нам очень важны std::generator для поддержки потоковой обработки, <stdfloat> для поддержки float16_t и bfloat16_t и на <stacktrace> для поддержки исключений Python.
Комментарии (2)

Roman_Cherkasov
29.11.2025 13:12Интересный кейс конечно. Но как я понимаю - сгенерированный код не предназначен для чтения и доработки - так что можно было бы и к Nuitka присоединиться, вместо собственного велосипеда - допилить чужой.
Сколько граблей ещё не собрано)
Jijiki
да, но чтобы работал везде нужен С -ansi пайтон поидее