
Привет, Хабр! Меня всё ещё зовут Данила Федюкин, и я продолжаю быть тимлидом в X5 Digital. Руковожу командой, которая занимается метчингом. В прошлый раз я рассказывал, как мы перешли на собственную систему рекомендаций, а в этот раз о том, как делаем то же самое, но с метчингом товаров.
X5 Digital – один из цифровых бизнесов Х5. Мы работаем в режиме Highload с RPS в 7500 и отвечаем за всю онлайн-доставку в более чем 1000 городах и населённых пунктах России.
Этот канал постоянно растёт. В 2024 году покупатели Х5 совершили свыше 119,5 млн заказов продуктов на дом.
Мы делаем собственную in-house WMS для дарксторов, приложения для сборщиков и курьеров, CRM, каталоги товаров и другие онлайн-продукты, а ещё мобильное приложение для торговых сетей.
Всё это, отталкиваясь от разных форматов доставки. В «Перекрёстке» среднее время доставки CTD (Click-to-Delivery — от оформления заказа до его получения клиентом) сократилось до 45 минут, в «Чижике» — до 37 минут, а в «Пятёрочке» порядка 40% заказов доставляются клиентам менее чем за 20 минут.
Какую проблему бизнеса решали
Наша задача — сопоставление одинаковых или наиболее похожих друг на друга товаров, которые есть и у нас, и на рынке, то есть метчи. В современном бизнесе, особенно в сфере электронной коммерции, метчинг товаров позволяет эффективно управлять ассортиментом и ценами, основываясь на актуальных данных о рынке. Основная цель метчинга — обеспечить конкурентоспособность, позволяя быстро реагировать на изменения цен и предложений на рынке. Это критически важно для поддержания ценностного предложения, которое выдвигают торговые сети.
Однако при работе с подрядчиками могут возникать проблемы. Например, длительное исправление ошибок тормозит процессы ценообразования и обновления информации о товарах. А это может привести к упущенным возможностям на рынке. Кроме того, необходимость ручных привязок для взаимодействия с собственными торговыми марками и готовой едой создаёт дополнительные сложности и увеличивает вероятность ошибок. Исходя из этого мы решили разработать собственное решение.
Что нам нужно
Формулируя требования к решению мы ориентировались на объёмы поставок от подрядчика, но добавили запас на возможное увеличение ассортимента.
В результате сформулировали такие требования:
Возможность обрабатывать 20 миллионов товаров за трое суток, чтобы максимально быстро получать данные о ценах.
Возможность сопоставлять НЕ брендовые товары, такие как готовая еда или товары собственной торговой марки.
-
Две ключевые метрики:
Покрытие нашего ассортимента сопоставлениями.
Точность сопоставлений.
Исходя из этих вводных сформировали требования к сервису по производительности минимум в 77 RPS на весь пайплайн.
Техническое решение
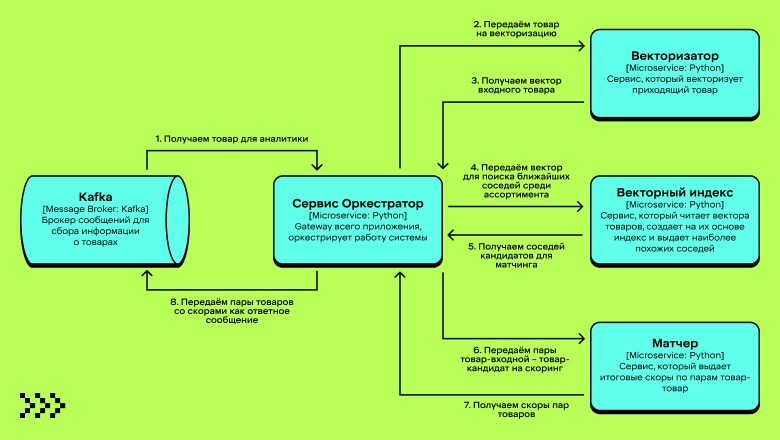
Задача метчинга похожа на задачи поиска и рекомендаций. Чтобы показать это, проведём параллели. В нашем случае пользовательский запрос — это товары на рынке, аналог которых нужно найти среди наших товаров. Пространство поиска — весь активный ассортимент компании. А результат — аналогичный товар, который должен полностью совпадать с товарами на рынке.
Поэтому архитектурно мы решили опираться на принципы поиска и рекомендаций и сделать пайплайн из трёх основных стадий:
Сначала векторизуем товар с рынка, чтобы в дальнейшем искать по этому вектору похожие.
Потом ходим по векторному индексу и выбираем наиболее похожих кандидатов для нашего «запроса».
В конце отправляем пары запрос-кандидат на скоринг, чтобы получить наиболее вероятный метч. Ожидаем, что он будет верным.
Первые эксперименты: выбираем модели и строим векторный индекс
Для модели векторизации мы решили сразу обратиться к нейросетям. Сравнили варианты энкодерных трансформеров: Roberta, BERT, DiBERTa, E5-small.
В качестве метрики оценки выбрали recall@k. Она позволяет сравнить модели между собой и определить оптимальное количество кандидатов.
По итогам экспериментов победила модель E5-small, а оптимальное количество кандидатов составило 10.
Для построения индекса выбрали библиотеку FAISS. С её помощью мы построили HNSW-индекс и добавили ID map с идентификаторами товаров, чтобы на выходе получать именно идентификатор товара, а не вектор.
При выборе классификаторов оценивали метрику ROC-AUC, поскольку она позволяет оценить качество ранжирования двух объектов и интерпретируется как вероятность.
Тут мы выбирали из классических алгоритмов и семейства BERT. Если сравнивать метрики, оба подхода показали схожие результаты:
Catboost - 97%;
BERT - 98%.
Однако если посмотреть на ROC-кривые, то бустинг даёт меньшую способность к разделению. Больше товаров попадёт в диапазон confidence >0.7 и <0.9. В результате мы либо получаем низкое покрытие при высоком confidence, либо теряем точность, если оставляем порог слишком низким. Нейросети разделяют лучше и позволяют «играть» с confidence без сильных просадок по метрикам.
Грабли 1: GPU пока нет
К моменту, когда наши сервисы были готовы, у нас ещё не появились GPU. Но было пора запускаться. Поэтому мы решили деплоить все сервисы на CPU, а затем частично переехать на GPU.
При этом требования по времени работы никто не отменял. Благо, раскатка планировалась плавной, и в нас не сразу приходил весь объём нагрузки. За счёт этого появился запас по времени, когда мы могли работать на «сниженных оборотах». Но это не повод расслабляться, потому что на один метч у нас уходило чуть больше одной секунды, а это очень медленно.
В итоге мы пришли к единственному решению. Если полный пайплайн работает долго, значит, его нужно запускать как можно реже. Понимаю, нужно пояснение. Основное время у нас уходит на скоринг «соседей», если каких-то кандидатов можно не скорить, лучше этого не делать.
Мы будем добиваться этого с помощью эвристических правил. Есть три возможных исхода:
Находим гарантированный метч. И в таком случае можем вообще не запускать модель, а сразу отдавать ответ сервиса.
Находим гарантированный НЕ метч. И тогда убираем этого кандидата из скоринга, экономя время на прогоне всех кандидатов.
Во всех остальных случаях, когда не можем дать уверенный ответ, отправляем пару на скоринг модели.
Подробнее расскажу о правилах, которые мы придумали.
Сравнение чисел
-
Сравниваем числа в названиях продуктов — каждое из первого продукта с каждым из правого продукта.
Выделяем числа из названий продуктов.
-
Обрабатываем числа:
Заменяем запятые на точки, удаляем пробелы.
-
Определяем класс числа:
Number — класс для чисел и единиц измерения, например "300г");
Range — класс для диапазонов, например, "6%-8%";
Amount — класс для товаров с указанием кол-ва, например, "25пак*2г"
-
Инициализируем соответствующий экземпляр класса с помощью данного числа:
под капотом приводятся единицы измерения например, "0.95л" → Number(value=950, unit="мл";
также приводится формат числа — например, "3.0%" → Number(value=3, unit="%"), также как "3%" → Number(value=3, unit="%");
-
также в классах реализована логика сравнения экземпляров классов Number, Range и Amount между собой. Сравнение возвращает одно из трёх значений:
1 — совпадение — например, Number(value=3, unit="%") и Range( start=Number(value=3, unit="%"), end=Number(value=5, unit="%");
0 — значения не сравниваются. Например, Number(value=3, unit="%") и Number(value=100, unit="мл");
-1 — противоречие. Например, Number(value=200, unit="мл") и Number(value=100, unit="мл").
Если есть хотя бы одно противоречие, то возвращаем уверенное предсказание False, в остальных случаях не возвращаем уверенных предсказаний.
Сравнение токенов
-
Проверяем числа продуктов на полное совпадение:
если нет полного совпадения, правило не возвращает уверенных предсказаний.
-
Сравниваем названия продуктов:
удаляем числа и соответствующие единицы измерения из названий;
приводим названия к нижнему регистру;
токенизируем названия;
-
сравниваем токенизированные тексты.
-
Сравниваем каждый токен первого продукта с каждым токенов второго продукта:
если в сравниваемых токенах есть и латиница и кириллица, то конвертируем оба токена в кириллицу;
сравниваем токены на полное совпадение;
сравниваем токены на совпадение с сокращением (например, "молочный" и "мол.");
-
лемматизируем токены:
сравниваем на полное совпадение;
сравниваем на совпадение с сокращением.
Если какое-либо из сравнений дало положительный результат, то остальные сравнения пропускаются.
Если ни одно из сравнений не сработало, то слова считаются разными.
-
Считаем процент совпавших токенов в названиях, сравниваем полученное значение с пороговым значением (в данном случае порог 100%).
Если процент совпавших токенов для обоих названий превышает порог, то правило возвращает уверенное предсказание True, т.е. наличие совпадения.
В результате получили, что правилами отсеиваем примерно 50% трафика на модель. Это позволило получить 13 RPS на одном инстансе с моделью, что приемлемо с учётом горизонтального масштабирования.
Грабли 2: GPU уже есть
И вот счастье на нашей улице — нам дали GPU! Но есть нюанс. И имя ему — NVIDIA MIG.
Вкратце расскажу, что это за зверь. Технология MIG позволяет аппаратно разделить GPU на сеть экземпляров. У каждого из них изолированная память, кэш, пропускная способность и вычислительные ядра. Это упрощает борьбу с «шумными соседями» при совместном использовании GPU.
Однако у такого подхода есть и минус. Если делить GPU на минимальные куски, то на каждый из них можно задеплоить только один под. А в нашем случае один под утилизирует только 30% этого куска, что совсем неэффективно.
В интернете мы не нашли, как решить эту проблему на уровне MIG, поэтому нам остаётся только делить ресурсы на уровне кода. Поскольку мы пишем на Python, то у нас в целом есть только путь в Multiprocessing.
Но просто так впиливать это в боевой сервис — занятие рискованное, поэтому мы решили начать с эксперимента.
Методика эксперимента
Конфигурируем FastAPI сервис моделью e5-small.
Запускаем скрипт нагрузочного тестирования.
-
Собираем и анализируем метрики:
RPS.
Время отклика.
Утилизация ресурсов.
Скорость инференса.
Делаем выводы.
Проводить эксперименты мы будем в двух сетапах, когда поступающая загрузка 100% GPU, а GPU/CPU — 50%/50%. Механизм мультипроцессинга будем обеспечивать через увеличение uvicorn процессов.
Сценарий со 100% GPU-загрузкой
Описание эксперимента
Тестируется сценарий, когда в работе модели/сервиса отсутствует какая-либо обработка входных данных. Фактически 100% GPU-инференс.
Эксперимент 1 — тестируем один uv-процесс с одним пользователем. Результат берём как базисный уровень.
Эксперимент 2 — оставляем один uv-процесс, но ставим четырёх параллельных пользователей.
Эксперимент 3 — увеличиваем число uv-процессов до двух.
Эксперимент 4 — увеличиваем число uv-процессов до четырёх.
Выводы:
При распараллеливании пользовательских запросов на сервис, уменьшается время отклика, но общий RPS-сервиса останется неизменным.
Увеличение числа uv-процессов позволит повысить утилизацию GPU и общий RPS сервиса, но значительно увеличит потребление RAM и CPU.
Свитспот в этот тесте — 2 uv-процесса.

Сценарий с равномерной загрузкой: 50% GPU 50% CPU
Описание
Тестируется сценарий, когда в работе модели/сервиса присутствует значительный объём обработки входных данных. Симулируем 50% GPU 50% CPU.
Эксперимент 5 — тестируем один uv-процесс с одним пользователем. Результат берём как базисный уровень.
Эксперимент 6 — оставляем один uv-процесс, но ставим четырёх параллельных пользователей.
Эксперимент 7 — увеличиваем число uv-процессов до двух.
Эксперимент 8 — увеличиваем число uv-процессов до трёх.
Эксперимент 9 — увеличиваем число uv-процессов до четырёх.
Эксперимент 10 — увеличиваем число параллельных пользователей до восьми.
Выводы
При распараллеливании пользовательских запросов на сервис, уменьшится время отклика, но общий RPS-сервиса останется неизменным.
Увеличение числа uv-процессов позволит ЗНАЧИТЕЛЬНО повысить утилизацию GPU и общий RPS сервиса относительно исходного сетапа, но значительно увеличит потребление RAM и CPU.
Свитспот в этот тесте — 3 uv-процесса.

Выводы обоих экспериментов
-
Запустить onnx в нескольких процессах через увеличение воркеров uvicorn возможно.
Несколько ONNX-сессий могут работать с одной видеокартой. Явных конфликтов — нет.
Оптимизация утилизации GPU будет, но зависит от того, какие вычисления преобладают — GPU-bound или GPU-bound.
При использовании этого подхода желательно поднимать число воркеров постепенно и мониторить утилизацию ресурсов: в какой-то момент увеличение числа воркеров перестанет давать результат.
-
Требуется увеличить число ресурсов в соответствии с числом воркеров:
Количество ядер = Количество воркеров.
RAM = потребление одного воркера под нагрузкой X Количество воркеров.
-
Часть инференса всё равно будет идти на CPU.
Это зависит от моделей: какие-то более активно задействуют CPU, какие-то — менее.
-
Возможно, потребуется отключить параллелизацию токенизатора флагом TOKENIZERS_PARALLELISM=false
При запуске через uvicorn ошибок нет, но эксперименты проводились с отключенным параллелизмом.
-
Если клиент сервиса использует сессии (HTTP keep-alive), то uvicorn привяжет сессию к воркеру и это может повлиять на загрузку воркеров. Проблему можно решить:
Не используя сессии на клиенте.
Поставить параметр --timeout-keep-alive 0.
Применение данного подхода на боевых сервисах позволяет получить прирост +80% RPS, что в нашем случае даёт возможность достигнуть требуемых 77 RPS в одном инстансе, и при получении дополнительных кусков карты увеличить скорость ещё сильнее. При этом утилизация ресурсов будет максимальной.
Ради чего всё это?
Покрытие ассортимента теперь составляет 70% GMV продаж компании (против 60% у сторонних вендоров). При этом 12% GMV — это уникальные сопоставления.
Появилась возможность автоматически метчить небрендовые товары, что раньше было возможно только после ручной обработки сайтов. Это даёт бизнесу управляемый инструмент для ценообразования и оценки ассортимента.
Вместо послесловия: чему мы научились и что сделали бы иначе
Хотелось бы, чтобы эта статья стала не просто пересказом нашего пути, а чтобы те, кто столкнётся с похожими вводными, не наступили на наши грабли. Поэтому оставлю мысли о том, как оптимально подходить к решению такой задачи:
Начинайте с простого — это истина, высеченная в камне. На мой взгляд, в самом начале не стоит делать полноценные сервисы с моделями. Лучше сначала построить полноценный сервис с правилами и только потом постепенно интегрировать в него модели, усложняя систему шаг за шагом.
Всегда держите в голове, что инфраструктура может прийти с опозданием, и заранее готовьте план отхода. В нашем случае мы не ошиблись, но скорее нам повезло, что поздний приезд GPU в данном кейсе ничего не сломал. В будущем мы дополнительно подумаем об infrastructure agnostic сервисе.
А если вы хотите узнать о работе высоконагруженных систем, приходите на конференцию HighLoad 2026! Вся информация о том, где пройдёт конференция, будет на сайте. Посетить её можно будет и онлайн.