

Прямо сейчас в Кремниевой долине проходит GPU Technology Conference. Это важнейшее событие для всех тех, кто занимается технологиями параллельных вычислений, нейронными сетями и искусственным интеллектом. Текущий 2016 год особенный для этой конференции. То к чему готовились и шли долгое время именно сейчас приобретает законченные формы. Причем, как и предопределено развитием технологий, прорыв происходит сразу по всем направлениям:
- нейронные сети, построенные на обучении с подкреплением, берут следующую высоту после шахмат и побеждают человека в го, игру, которая превосходит шахматы по своей комбинаторной сложности;
- беспилотные автомобили проходят проверку на дорогах и доказывают свою состоятельность;
- платформы искусственного интеллекта от IBM, Amazon, Google и Microsoft готовы для интеграции в реальный мир;
- виртуальная и дополненная реальность уже реализованы и готовы к масштабному внедрению от Oculus, HTC, Sony и Samsung;
- решения на базе HPC (High Performance Computing) интегрируются практически повсеместно.
Пожалуй, главный из участников прорыва — это компания NVIDIA. Именно на ее железе работает большая часть всех революционных чудес.
Вчера NVIDIA провела презентацию, показала оборудование и озвучила идеи, которые будут определять ход компьютерной революции как минимум ближайший год. Наверняка об этом будет много новостей и обзоров. Мне довелось присутствовать на этом мероприятии, пересказывать его полностью я не буду, но попробую отметить те детали, которые особенно отложились в памяти.
Есть у компании NVIDIA со-основатель и в одном лице ее президент Дженсен Хуанг. Он и вел презентацию. Насколько это хороший оратор и яркий рассказчик вы можете судить по тому, что к концу презентации, я стал искренне переживать, что в моем любимом iMac стоит видеокарта от AMD. Вот она сила слова!
Вообще же, я еще раз убедился в том, что компьютеры стали иными. Центральный процессор, еще недавно сердце компьютера, сейчас отошел на второй план. Навигация в интернете или работа с текстом — практически не требуют системных ресурсов. Даже самый слабый из современных процессоров с легкостью справляется с этим. А вот для всего действительно современного и интересного даже самый мощный процессор оказывается совершенно не пригоден. Создание графики в играх, моделирование виртуальной или дополнительной реальности, обработка изображений в реальном времени — все это возможно только на системах с параллельными вычислениями, когда счет количества параллельных потоков идет не на единицы, а на тысячи.
Почти в самом начале выступления прозвучала фраза, которая сразу запомнилась: “уже никому не нужна реалистичность, нужна реальность”. Чтобы это продемонстрировать NVIDIA применила два козыря: интригующую тему и несомненного авторитета. Они смоделировали с абсолютной достоверностью восемь квадратных миль поверхности Марса с базой NASA и разной техникой поблизости. Опробовать это по прямой видеосвязи пригласили Стива Возняка. Было трогательно и забавно, когда Дженсен поблагодарил Стива за первый компьютер, за SSD и предложил, что дескать если тот и дальше хочет быть впереди, то компания NVIDIA готова устроить ему право быть первым космонавтом в полете на Марс в 2030 году. Стив радостно согласился. Дженсен, правда заметил, что NVIDIA готова оплатить билет только в один конец. Возняк не смутился и сказал, что Марс — это мечта и в один, так в один. Короче, сошлись на том, что ждать 2030 года не стоит и лучше, не откладывая, прямо сейчас опробовать Марс в исполнении NVIDIA, тем более, что обещана была “не реалистичность, а реальность”. Судя по реакции, реальность Марса Возняку понравилась. Он бодро гонял в шлеме Окулус на марсохроде и было видно, как ему хочет попробовать протаранить здания базы, видимо, чтобы проверить обещанную реальность ну уж совсем по полной.

Оправдывая лозунг “не реалистичность, а реальность”, NVIDIA презентовала главного виновника торжества новую архитектуру Pascal. 15 миллиардов транзисторов на одном кристалле — это больше чем у любого другого чипа, созданного людьми ранее. Потрясающие характеристики можно посмотреть по ссылке.
Когда была озвучена сумма, затраченная за три года разработок этой архитектуры, мне почему-то подумалось, что «Роснано» как-раз могло потянуть, но почему-то не потянуло, стало как-то грустно.
Игровые видеокарты на Pascal появятся уже в этом году. Похоже, что их высокая производительность понадобится в первую очередь второму поколению систем виртуальной реальности. Сейчас для всех систем VR разрешение еще достаточно далеко от ретины. И Oculus, и HTC в своем первом релизе при выборе разрешения исходили из производительности существующих на сегодня видеокарт. Возможно Pascal исправит эту ситуацию.
Показали модуль Tesla P100. Это первый продукт на базе новой архитектуры. P100 — ускоритель на базе которого можно строить различные вычислительные системы. Обещали, что в начале следующего года появятся сервера от всех крупных игроков.

Сама NVIDIA показала, то чем заслуженно можно гордиться — суперкомпьютер DGX-1.

Назначение этого чуда — глубокое обучение нейронных сетей. Суперкомпьютер состоит из восьми модулей P100 и имеет производительность 170 терафлопс. Цифра огромная, но большее впечатление производит не ее астрономическая величина, а сравнение с производительностью аналога предыдущего поколения. Удалось добиться, не предусмотренного никаким законом Мура, рекордного ускорения в 12 раз.
DGX-1 позволяет тренировать нейронные сети, соответственно, в 12 раз быстрее, там где раньше требовалось несколько суток, теперь нужны часы.
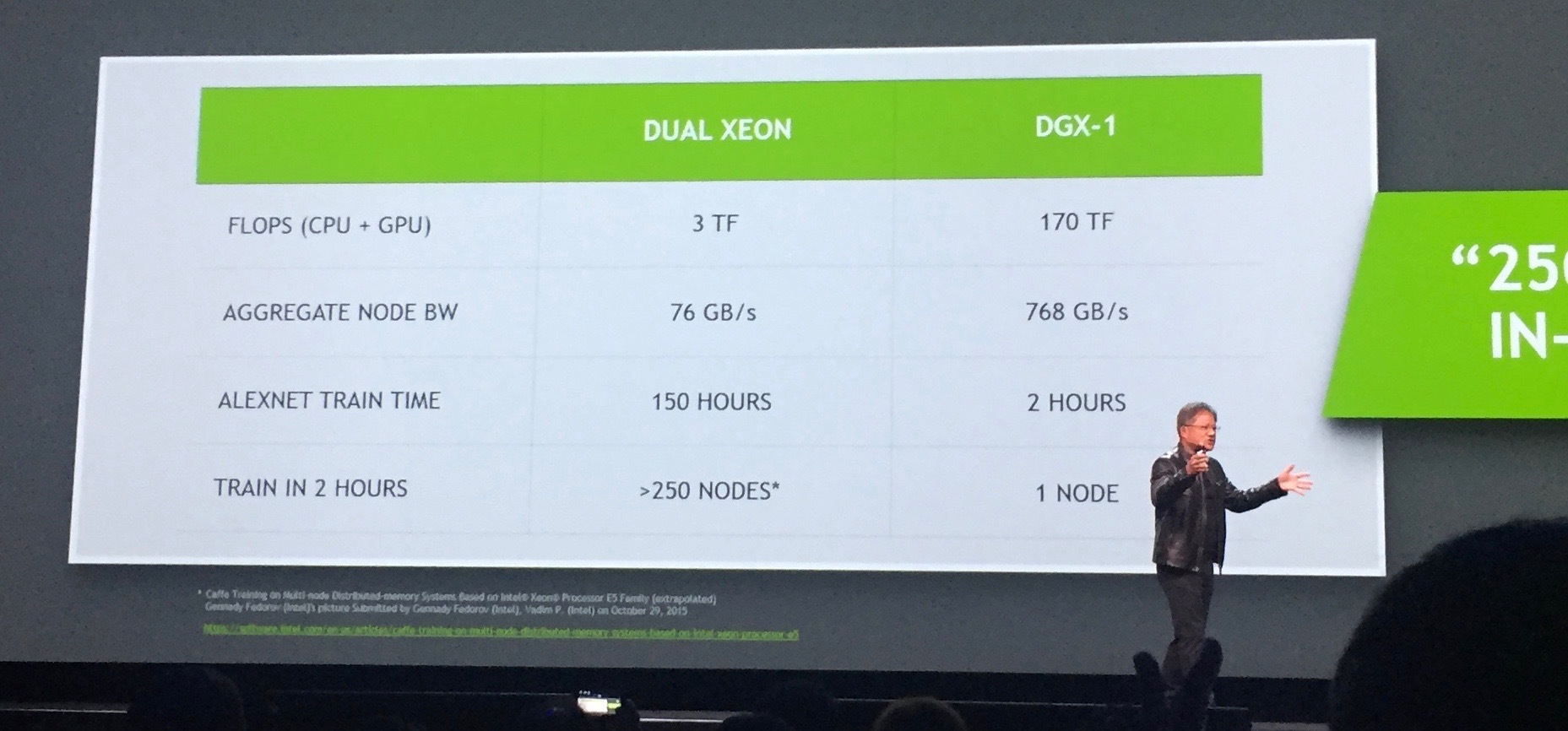
Стоит это чудо 129 000 долларов, но есть ощущение, что оно того стоит. На стенде NVIDIA, где можно было рассмотреть DGX-1 живьем (фото со стенда на КДПВ), вместе со мной был инженер из JP Morgan, который хорошо знает толк в таких вещах, я видел как искренне у него горели глаза.
Но железо — это только пол-дела. Глубокое обучение в сочетании со сверточными сетями начали давать удивительные результаты. Уже сейчас можно говорить не об эволюции, а революции в машинном обучении. Но да я с этого начинал. Однако качественный скачок к сильному искусственному интеллекту еще только предстоит сделать. Что для этого надо и какое изменение вычислительной парадигмы нам предстоит я попробую описать несколько позже.
Комментарии (106)




Raytheon
06.04.2016 17:43+1C каждым годом все быстрее. Сингулярность к 2045 году уже не кажется несбыточной мечтой.

Siper
06.04.2016 20:31+2Лет через 10 к мечтателям-людям присоединятся и мечтатели-машины. Причем последних еще можно понять.

Captain_Sparrow
06.04.2016 23:11+6Через двадцать лет жалкие людишки будут работать на неинтересных монотонных работах, а в это время роботы будут посвящать своё свободное время науке, музыке, философии…

AlexeyR
06.04.2016 23:10+2Ставлю на то, что все будет значительно быстрее. В ближайшее время напишу о своих доводах.

darkfrei
07.04.2016 21:41Называлась ранее дата около 2020 года. Есть даже вероятность что второго или двадцатого февраля.
equand
07.04.2016 23:58Причем принцип работы не будет до конца понятен даже самим создателям еще долгое время.

PupkinVasia
07.04.2016 02:02Ага, между посадкой и сбором картохи. Фрагментация соответствия населения научно-технологическому прогрессу просто огромна. В одной пробке можно увидеть человека на электромобиле и человека на телеге с лошадьми.
Очень сомневаюсь насчет такой скорой сингулярности. Большой процент человечества будет всегда тормозить прогресс, как сейчас можно запросто заметить на примере правительства почти любой страны на планете. Везде постоянно запрещается что-то что иначе заставило бы вывести многих запрещателей из их зоны комфорта. Еще хорошим примером терминального консерватизма головного мозга можно рассматривать использование нефти и угля когда рядом целые пустыни и океаны площади для размещения солнечных ЭС, ГЭС и ветроэлектростанций. Но ведь ветер и солнце не продашь…
grozaman
07.04.2016 02:45Одна из фишек сингулярности в том, что она никого не ждёт. Она будет просто свершившимся фактом, с которым всем придётся смириться.
Raytheon
07.04.2016 08:18-1Очень сомневаюсь насчет такой скорой сингулярности.
Она куда ближе, чем вы думаете. По большому счету, нам осталось алгоритмизировать ТРИЗ, чтобы машины могли совершенствовать сами себя.
Ну а потом остается сделать где-нибудь в Гренландии огромный кластер и автоматический завод по производству процессоров + подвозить сырье. Система будет понемногу становиться умнее, изредка переходя на новый техпроцесс или апгрейдясь, используя технологии от людей.

zedalert
06.04.2016 18:01| Суперкомпьютер состоит из восьми модулей P100
Кхм, ну вот поэтому он и в 12 раз быстрее, чем один Xeon.zedalert
06.04.2016 18:07+1Ошибся, сравнивают один P100 с одним Xeon. Но тут стоит оговориться: Intel не удваивает производительность процессоров каждые 2 года, вот nVidia этот пробел и восполнила.

Necrozyablo
06.04.2016 18:29Очень такое маркетинговое сравнение на картинке.
Взяли один Xenon и сравнили его с DGX-1.
1 А сколько этих Xenon можно купить за 130к$?
2 Я так понимаю там терафлопсы такие же как от видеокарт? Тогда почему там не сравнить c R9 295x2 у неё 11.5 терафлопс.
Стоят они меньше 1к$ так что за 130k$ можно думаю собрать много чего.
vird
06.04.2016 19:11Я так понимаю там терафлопсы такие же как от видеокарт.
Нет. Это на половинной точности. А на видеокартах на обычной.
nvidianews.nvidia.com/news/nvidia-launches-world-s-first-deep-learning-supercomputer
and new half-precision instructions to deliver more than 21 teraflops of peak performance for deep learning

beeruser
07.04.2016 00:36Все свежие видеокарты умеют работать с половинной точностью. intel gen 9, Maxwell, Pascal, GCN1.2
В какой-то момент режим FP16 был удалён из железа десктопного, а в мобильном никуда и не пропадал. Причина в энергоэффективности. Топовые десктопные видяхи также ограничены термально как и мобильные.Mad__Max
07.04.2016 15:08+1Уметь то умееют, но обычно даже опустившиеся маркетологи не доходят до указания скорости в FP16 как основной. В НВ теперь дошли.
beeruser
07.04.2016 20:39А она и есть _основная_ для этой машины.
Если вы не заметили, приведу цитату «Назначение этого чуда — глубокое обучение нейронных сетей.»

edd_k
06.04.2016 20:14Ну а что толку, что за эти деньги можно купить партию из 100 ксеонов?
А во сколько обойдется готовый продукт из связанных между собой 50 ксеонов со сходной суммарной мощьностью и с примерно равными прочими возможностями по пропускной способности обмена данными и доступной памяти? CPU-шные аналоги точно не конкуренты в данном случае. Особенно учитывая расход энергии на единицу вычислений.
beeruser
09.04.2016 23:26Каждый раз, когда кто-то говорит «ксеон», где-то плачет одна маленькая Зена.
edd_k
10.04.2016 01:07Xeon (в отличии от Xena) принято транслитерировать именно как Ксеон. Xena тоже могла бы прижиться как «Ксена», если бы у варианта «Зена» была путаница с другими словами.
Слух это резать не должно и уж тем более доводить Зиночку до слез. Ведь, например, та же «ксенофобия» никого не смущает, верно?

Alaunquirie
06.04.2016 21:21+1R9 295x2 х2 уверенно кладут 1.3-1.5 КВт блоки питания, у каждой из них свой водоблок, кроме того, не сказано, FP32 или FP64 производительность измерялась (думаю, и у Nvidia, и у AMD — FP32, в них числа получаются красивее). В случае с FP64 Nvidia обещала значительно улучшить показатели 1/24 и 1/32 от FP32, которые были у предыдущих поколений их GPU (Кеплер, Максвелл). Представляю, сколько будут потреблять / выделять тепла блоки из GPU R9 295 на 170 Тфлопс.
Если уж и брать AMD, то чипы от R9 Fury / Nano.Mad__Max
07.04.2016 15:05+1Измерялась вообще FP16 (половинная точность) — чтобы «маркетинговых попугаев» побольше написать можно было.
По FP32 скорости это прямой аналог R9 295x2, только энергоэффективнее и лучше приспособлен для построения кластеров/суперкомпьютеров. С десятикратным ценником за это.

vird
06.04.2016 19:04+61. Читаем внимательно релиз. 170 TFLOPs на половинной точности.
2.
en.wikipedia.org/wiki/List_of_AMD_graphics_processing_units
Radeon Pro Duo 1500$ (Внимание, это самая дорогая карта, если комплектовать Radeon R9 Nano получится и дешевле и меньше потребления)
16.3 TFLOPs (честных float)
Покупаем 10 шт.
Получаем 163 TFLOPs 15k$
Стоит меньше, по питанию потребляет столько же (на preview там было 3 8pin контроллера, 350-400 вт), пропускной способности гораздо больше, памяти тоже больше.
Обвязку сделать… ну не стоит это дополнительных 100k$
Мое нескромное мнение — расходимся нас обманули.
kahi4
06.04.2016 19:50+2Не все так просто. Эти видеокарты еще как-то нужно между собой объединить. Очень большие накладки у вас будут именно на общении между видеокартами. Вдобавок, полагаю, что для общих вычислительных задач данная архитектура более эффективна, чем видеокарты (все же нужно понимать, что тут сравниваются попугаи, по большому счету).
Добавить сюда систему охлаждения, питания, компактность — вероятно, дешевле все же обойдется DGX-1, чем лепить огород из видеокарт, настраивать чтобы оно все работало, да еще и SKD для этого есть, а там придется писать все ручками.
Хотя не исключаю, что цену они могли задрать уж слишком сильно.vird
06.04.2016 22:02+1Компактность. Каждую видеокарту из AMD мы развернем в профиль и установим по 2 видеокарты в 2U. Получим итого 20U. Вместо 3U. По электричеству ~ одинаково. Стоимость стойки
www.quora.com/Data-Centers-How-do-colocation-companies-price-their-single-server-1U-spots
100$ + 40$ за каждый ампер сверху базовых 0,5 А.
Nvidia
3500/220*40+100*3
936$
AMD
3500/220*40+200*10
2*1636$ т.к. 2U
Разница 2*700$ в месяц = 2*8400$ в год. Сколько нужно лет чтобы окупить аренду+электричество?
Настраивать чтобы оно все работало
Открою большой секрет. Чем более экзотичное оборудование вы покупаете, тем больше его придется настраивать. DGX-1 — экзотика, а видеокарты от AMD — +- обыденность.
Ок. Вы наймете штат из 10 человек и заплатите каждому по 2000$ в месяц и за месяц они настроят вам AMD. Запишите 20k$ в счет. Опять не вижу чем решение NVidia лучше. (Кроме того, что указал снизу)
BelBES
06.04.2016 22:39Если мы говорим об Deep Learning, то не забудьте еще приплюсовать к цене кластера на AMD'шных картах накладные расходы по портированию инструментов на шейдеры/OpenCL, т.к. сейчас большинство кода пишут под CUDA.
Aclz
06.04.2016 22:53+2Откуда инфа про большинство?
BelBES
06.04.2016 23:01Ок, "большинство актуального и публично доступного кода".
Боле-мене живым выглядит только OpenCL'ный бэкенд к torch7...caffe, tensorflow, cntk — де факто с opencl не дружат.
Vespertilio
07.04.2016 18:49+1Разве? Если б передо мной стояла задача разработки приложения для GPGPU вычислений я бы выбрал OpenCL, т.к. это универсальный кроссплатформенный API, не завязанный на вендора, имеет практически аналогичную производительность, поддерживается альянсом куда входит так же и Nvidia. Это даст намного большие возможности для запуска софта на всех платформах при меньших расходов на его поддержку, правда?
Mad__Max
07.04.2016 22:02Вообще правильный подход. Только OpenCL не имеет такого PR и поддержки со стороны AMD какой имеет CUDA со стороны NV.
Причем не чистый PR/маркетинг, а снабжение удобными инструментами разработчика, готовыми библиотеками, проведение обучающих курсов/семинаров и т.д. В результате в производительных GPGPU обычно рулит CUDA и NV, хотя никаких особых технических преимуществ у этой связки нет — все упирается в программирование — умеющих хорошо писать под CUDA намного больше, чем в случае c открытым OpenCL.
Что доказывается HTC РВ проектами — там где «дареному коню в зубы не смотрят» и надо работать с тем железом какое предоставили (добровольцы — волонтеры) иначе его просто потеряешь, то на OpenCL под AMD получают результаты не хуже, а зачастую даже лучше чем на CUDA под NV.
BelBES
08.04.2016 13:16Если писать с нуля, то при прочих равных может быть и имеет смысл смотреть в сторону OpenCL. Но комерчески выгодней использовать уже существующие наработки, которых под CUDA существенно больше, да и в целом инфраструктура выглядит более развитой.
Vespertilio
08.04.2016 15:28И да и нет. Если смотреть так, то не появилось бы C#, кучи новых фреймворков и других технологий. Развивающиеся компании смело инвестируют в новую инфраструктуру и технологии, переобучают специалистов и т.д. Хоть и имеет место некий консерватизм, налаженную инфраструктуру резко никто менять не будет. Тем не менее та же Nvidia выпускает SDK под OpenCL и всевозможные примеры на нем (https://developer.nvidia.com/opencl), хоть свой CUDA пиарит несравненно больше.
И я считаю, имхо, открытые решения типа OpenCL таки коммерчески выгодней на перспективу, привязываться к вендору не лучшая перспектива для бизнеса, который, например, систематически наращивает вычислительные ресурсы, а гарантию что при очередном апгрейде конкуренты не выпустят на голову лучший продукт на выгодных условиях никто не даст.BelBES
08.04.2016 16:10И да и нет. Если смотреть так, то не появилось бы C#, кучи новых фреймворков и других технологий.
Речь идет конкрено про ИИ и смежные дисциплины (Deep Learning etc.), а не IT-индустрия в целом.
- В разработку тех-же caffe/torch уже вложено куча человеко-часов для разработки текущей версии фреймворка с GPU параллелизмом на CUDA. Смысл развивающимся компаниям вкладывать деньги (которых у них не факт что много) на повторение уже кем-то проделаных и выложеных в паблик шагов? Сейчас в DL сосредотачиваются на решении конкретных задач, а не полировке фреймворков и портировании подо все существующие архитектуры. Проще купить пару TitanX'ов, чем написать свой caffe на OpenCL.
И я считаю, имхо, открытые решения типа OpenCL таки коммерчески выгодней на перспективу, привязываться к вендору не лучшая перспектива для бизнеса, который, например, систематически наращивает вычислительные ресурсы, а гарантию что при очередном апгрейде конкуренты не выпустят на голову лучший продукт на выгодных условиях никто не даст.
Нет никаких гарантий, что под прорывное железо сразу выпустят нормально работающий OpenCL (вон под видяхи adreno вроде бы его до сих пор нету, да и в NEON фиг знает как оно транслируется). И придется портировать код с использованием каких-то низкоуровневых API конкретной железяки
- Также для получения лучших X-ов ускорения придется оптимизировать под конкретное железо, а не в целом на обстрактный зоопарк.
Vespertilio
09.04.2016 12:53+1Речь идет конкрено про ИИ и смежные дисциплины (Deep Learning etc.), а не IT-индустрия в целом.
Не смотря на громкий заголовок все же Pascal — это чип общего назначения, никаких специальных инструкций для ИИ они не закладывали кроме поддержки FP16, на что и ставится акцент. Т.е. они по сути порезали точность и логично получили много много флопсов.
В разработку тех-же caffe/torch уже вложено куча человеко-часов для разработки текущей версии фреймворка с GPU параллелизмом на CUDA.
Незачем писать свои велосипеды, выше упомянутые фреймворки вполне обзаводятся поддержкой OpenCL, вот порт от самой AMD для caffe (https://github.com/amd/OpenCL-caffe), есть также и для torch и для остальных.
Нет никаких гарантий, что под прорывное железо сразу выпустят нормально работающий OpenCL
Согласен, но это уже на совести производителя, который реализовывает поддержку оного в своих драйверах. Собственно последние зачастую и подводят во всех аспектах новой железки пока их нормально допилят.BelBES
09.04.2016 13:58+1Незачем писать свои велосипеды, выше упомянутые фреймворки вполне обзаводятся поддержкой OpenCL, вот порт от самой AMD для caffe (https://github.com/amd/OpenCL-caffe), есть также и для torch и для остальных.
Порт слегка мертвый(последние коммиты чуть ли не полгода назад были), и что у него с перформансами — не известно. А мейнстримная ветка caffe активно развивается.
kahi4
06.04.2016 23:24+1а: для российских реалей 2000$ особенно сейчас — еще сойдет. Но в том же США за такие деньги вам вряд ли сайт то сверстают
б: Экзотика то экзотикой, только с готовым sdk. Решение ± коробочное, всяко дешевле, чем штат сотрудников, которые смогут заставить работать кластер из 10 видеокарт без простоев, проблем с синхронизацией и кучу других задач. Так говорить — можно сразу в ASIC свою сеть зашить, и ничего. Максимальная производительность будет, правда обойдется, конечно, дороговато.
в: почти уверен, что производительность видеокарт растет далеко не линейно с увеличением их количества. Даже если удвоив одну видеокарту вы получите х2 по производительности, то удвоив еще раз — уже не будет х4. В лучшем случае, х3. 8 видеокарт не дадут 800% прироста скорости, пальцем в небо — всего лишь 400% (и что-то мне подсказывет, что это еще оптимистичная оценка)
д: нейронные сети имеют специфику доступа в произвольную точку. Пытаясь настроить работу видеокарт таким образом, чтобы обращение от одной к другой не заставляло ждать это время все другие рано или поздно упретесь в канал между ними. Как ни крутите. Если так разобраться — решение не такое уж и плохое для компаний, которые хотят получать результат, а не проводить рискованный эксперимент, нанимать штат на решение уже решенных задач, а потом упереться во что-то, переплатив несколько раз.grozaman
07.04.2016 02:56+1Честно говоря я не особо эксперт в данной области, но прокомментирую как смертный: На мой взгляд гораздо проще взять решение «из коробки» от nvidia, чем городить огород. А еще есть банальная вероятность, что на этапе настройки ко мне подойдёт один из этих 10 программистов и скажет мол сорян, у нас ничего не выходит, слишком сложно. Плати бабло за год нашей работы, может быть и допилим, но не факт.
Другими словами проще отдать эту приличную сумму и практически сразу приступить к работе, имея при этом гарантию и поддержку производителя, обновляемый SDK и другие фишки.
shteyner
08.04.2016 10:06Тогда не стоит забывать еще об одном: работа програмистов это разовая покупка, можно так сказать. И потом можно этих серверов наплодить сотни и больше. А тут ты каждый раз такую сумму будешь выкладывать.
Но все не так и плохо, уверен что за 5 лет стоимость их нового решения упадет раз так в 10, может даже больше. При этом за 5 лет еще и новые версии выйдут и тоже будут несколько дешевле.grozaman
08.04.2016 15:07В этом и суть. Инвестировать можно сейчас и вырваться вперед на неком рынке. Либо инвестировать потом в десять раз меньше, когда рынок будет уже занят более быстрыми и умными.

Foolleren
06.04.2016 20:30-1дело не только в флопсах, но и в том сколько из них вы сможете использовать.
если взять допустим майнинг, там очень долго балом правили видеокарты от амд(я сейчас даже не про биткоин) потом в один прекрасный день появилась реинкарнация скрипт алгоритма, не на sha + salsa, а aes + ещё чёта, уже плохо помню, два дня обсуждений в чате одного пула, и на вторичном рынке пропали 480 и 580 видюхи нвидии, их архетектура оказалась весьма подходящей под такой вот коин.
Надо полагать, что те кто закупают такие дорогие игрушки знают об альтернативах.
edd_k
06.04.2016 20:45Вот вам один из примеров чего могут стоить 8 ТФлопс одинарной точности, если пожалеть денег на готовую для работы платформу (или если не любое решение подходит):
http://evm.vstu.ru/index.php/labs/hpc-lab/about-hpc
Причем, утверждается, что «Стоимость высокопроизводительных кластеров, поставляемых под заказ, обычно в разы или на порядок больше.».
Alex_ME
06.04.2016 21:54Ну, справедливости ради стоит заметить, что у нового кластера производительность 20ТФлопс, а 10 млн руб — потрачено суммарно.
P.S. Был удивлен, встретив упоминание своей кафедры
vird
06.04.2016 21:43Ответ на ряд замечаний в этой ветке.
Для обучения нейросети достаточно 4096 CU и 4 Гб памяти. В разные видеокарты запихиваем разные части обучающей выборки. Раздаем задания, собираем результаты, синхронизируем результаты, на второй такт. При правильной организации накладные расходы на синхронизацию будут меньше 1% времени. Т.к. выполнение kernel'а можно довести до >1 сек. Что нуждается в синхронизации — настроечные веса. Сколько их? 1 мб (скорее всего да)? 10? 100? Да пусть 1 Гб настроечных весов даже будет.
Синхронизация будет занимать меньше 1 Гб/с. По PCI-E это ничто. 10G сеть — тоже не экзотика.
Потому как раз эта задача не нуждается во всякого рода ухищрениях по большому маппингу памяти, NVlink'у и прочему.
В комментариях я не увидел молекулярной симуляции, которая в принципе сейчас на видеокарты не переносится пока не будет 128 Гб памяти. Вот это действительно контрпример. Но NVidia почему-то решила взять тем, что сейчас у всех на слуху.vird
06.04.2016 21:48Бонус. По поводу накладных расходов. Пересылку данных можно делать, когда видеокарта занимается просчетами. Что позволяет снизить накладные расходы до последнего слабого звена — запуск kernel'а, а мы и так уже избавились от этого увеличив время выполнения до 1 сек.
kraidiky
06.04.2016 22:41Так и просится вариант в разные карты складировать разные экземпляры сетки и после каждого цикла одну худшую отстреливать, и на освободившееся место вставлять результат кроссинговера двух лучших. :)
kahi4
06.04.2016 23:27+1Не все сети так обучаются. Скорее, это даже редкий случай обучения генетическим алгоритмом. К слову, почему все забывают, что бывает не только перцептрон? Другие сети с другими требованиями и методами обучения никто не отменял. Вон, fuzzy ART-MAP очень крутая, хотя не очень популярная. (Ради справедливости, перцептрон в ней есть внутри, вроде как, хотя она может быть построена на разных сетях внутри себя).
AlexeyR
06.04.2016 23:40Как раз сижу на встрече с разработчиками, говорят 3500 клиентов уже ждут DGX-1. Это те, кому нужно именно глубокое обучение. Вещи типа «ок google» обучаются на таких системах, а затем уже обученные сети используются в телефонах. Система распределенная по видеокартам хорошо работает на майнинге биткоинов, но в интегрированных задач получается проще и дешевле использовать такие штуки.
AlexeyR
06.04.2016 23:47Разработчики пояснили, главный фокус в том, что все восемь P100 связаны между собой скоростными каналами и могут работать как единая система без искусственной сегментации, которую порой невозможно сделать без ломки алгоритмов. Как они говорят, 8 — оптимальное число совместных модулей, дальше начинается существенное падение скорости обмена между модулями и система начинает терять смысл, превращаясь постепенно в массив видеокарт.
Mad__Max
07.04.2016 15:20Ну это просто исходя из того что у чипа максимум 4 шины для связи с соседями. В результате получается можно создать либо 4х чиповый модуль с полной связанностью(используются 3 шины на каждом) либо 8 чиповый с почти полной (используются все 4 шины). Дальше при дальнейшем масштабировании уже действительно особых преимуществ над классической GPU архитектурой нет и нужны другие «классические» подходя к масштабированию.
В общем сегмент для «микро-суперкопьютеров».
immaculate
06.04.2016 21:22+4Центральный процессор не требуется для просмотра страниц? У меня браузер — самый большой пожиратель CPU. Кривые скрипты и реклама умудряются сожрать все ресурсы CPU, GPU и пропускной способности канала.
darkfrei
06.04.2016 21:59-1Дойдём до квантовых нейронных, а дальше куда всё пойдёт?
vladsabenin
06.04.2016 23:20более сложные архитектуры с производительностью, в дальше — связки с органикой. Не думаю, что если люди смогут эмулировать откружающую среду свзякой пк+человек, что-то пойдет дальше. Сплошная матрица, да и только.
darkfrei
07.04.2016 00:07+1Поразмышлял тут, а ведь невозможно построить нейронку на квантовом компьютере, ведь неизвестно как он «думал», куда именно подкреплять его правильные решения, ведь нельзя записывать ничего до окончательного вывода, иначе вся квантовость теряется. Квантовая нейронка должна самообучаться каждый раз и всегда терять всю информацию где-то перед формированием ответа.
IgorKh
06.04.2016 23:20Поискал в западных источниках про энергопотребление этого чуда техники, но кроме размытого «оно лучше чем было» ничего не нашел. Отсутствие четких цифр меня пугает :) Но с другой стороны вроде во внутренностях DGX-1 огромных радиаторов не видно, или для красивой картинки их убрали?
hombre
07.04.2016 10:12по-моему в спецификации DGX-1 было написано, что потребляемая мощность не более 3.3 кВт
Mad__Max
07.04.2016 15:23+1До 300 Вт на каждый чип (ГПУ + память). А радиаторов огромных не видно, т.к. это серверное/кластерное исполнение. Там небольшие по размеру радиаторы(чтобы впихнуть в узкую и плоскую ячейку стандартной стойки) принято компенсировать бешеным потоком воздуха через них и вентиляторами воющими как пылесос :)
Temtaime
06.04.2016 23:20Что-то на сайте GPU Technology Conference ни слова про AMD. Странно с их стороны пропускать такое крупное мероприятие.
Vespertilio
06.04.2016 23:20+2Прям неделя ИИ на хабре. Но, имхо, «Пожалуй, главный участников прорыва — это компания NVIDIA.» — спорно. Как по мне то это больше IBM с ихними инновациями в виде TrueNorth (https://habrahabr.ru/company/ibm/blog/280844/) и geektimes.ru/company/icover/blog/273490.
Ну и по поводу "… я стал искренне переживать, что в моем любимом iMac стоит видеокарта от AMD.", не холивара ради, а просто разобраться, но разве опыт майнинга криптовалют не показывал до этого преимущество AMD над NVIDIA в вычислениях?
И наконец насчет DGX-1, вообще не понятно что с чем сравнили, какого "… аналога предыдущего поколения"? Двухпроцессорный компьютер на Xeon с GPU? Так это и так понятно что GPU обгонит CPU в флопсах.
Последнее: «Удалось добиться, не предусмотренного никаким законом Мура, рекордного ускорения в 12 раз.». Разве закон Мура не за удвоение числа транзисторов говорит, не понятно причем тут конкретно ускорение (хоть эти параметры и связаны)? И если так, то пройдя по ссылке в статье видно что закон Мура превосходно сработал:
Tesla M40 (GM200 (Maxwell)) — Transistors 8 billion
Tesla P100 (GP100 (Pascal)) — 15.3 billion
buriy
07.04.2016 11:21> а просто разобраться, но разве опыт майнинга криптовалют не показывал до этого преимущество AMD над NVIDIA в вычислениях?
У карт AMD есть инструкция просчёта хеша SHA256, а Nvidia не захотела её добавлять — вот и всё преимущество AMD для криптовалюты Bitcoin (которую давно уже невыгодно считать на обычных GPU — не окупите видеокарту и электроэнергию).
А для deep learning нейросетей, пока что более высокоуровневый AMD OpenCL в два-три раза медленнее низкоуровневого NVidia CUDA. Поэтому даже числовое преимущество теоретически возможных терафлопсов AMD даёт максимум равенство в практических задачах (при большем расходе электроэнергии у AMD — закладывайте в цену для европы и америки). Поэтому 95% специалистов считают нейросети именно на видеокартах от NVidia.
AngusMetall
07.04.2016 11:59А можно кратенько почему OpenCL решили делать высокоуровневым? Какие плюсы от такого решения, раз производительность в минусе?
BelBES
07.04.2016 13:16Потому, что OpenCL работает с абстрактным железом, и один и тот-же OpenCL'ный код теоретически можно запустить как на GPU, так и на CPU в зависимости от использованного при сборке бэкенда. А CUDA C заточен конкретно под железо от Nvidia, соответственно прямыми руками тут можно написать более экономный код.
kahi4
07.04.2016 13:20-1Потому что OpenCL даже на аудиокарте запускаться может. А CUDA — непосредственный драйвер видеокарт (точнее, библиотека, взаимодействующая непосредственно с драйвером)
Vespertilio
07.04.2016 12:21+1OpenCL все же универсальное API вроде как разработанное вообще Apple, а свой API у AMD тоже был, FireStream назывался, насколько он быстрее или медленнее CUDA я не знаю. За разъяснение почему AMD быстрее была в расчетах хешей спасибо, не знал об этой особенности.
Mad__Max
07.04.2016 15:29+1Никаких спец. инструкций у АМД под это не было. В те времена АМД была быстрее в майнинге просто благодаря гораздо большей вычислительной мощности (отставая при этом в таких вещах типа текстурирования или фильтрации — поэтому в играх преимущества не было).
В последующих поколения NV серьезно нарастила вычилительную мощность перейдя на архитектуру шейдеров очень похожую на ту, что первой начала использовать AMD.Foolleren
07.04.2016 19:37+1эмм вообщето была и есть BIT_ALIGN_INT
Mad__Max
07.04.2016 22:12Ну это совсем не «инструкция просчёта хеша SHA256», как например аппаратные реализации шифрования или хэширования. А лишь одна из инструкций используемых в алгоритме расчета хэша.
Насколько помню она позволяла где-то раза в 1.5 расчет конкретно SHA256 ускорить.
И еще в 2-3 раза разница была за счет преимущества в чистой вычислительной мощности: число исполнительных блоков х частоту.Foolleren
07.04.2016 22:14Это настолько специфичная инструкция, что скорее всего никуда кроме криптографии два сдвига и одно сложение вы не прикрутите.
buriy
08.04.2016 17:09+2Ну да, вообще говоря, да, я настолько сильно упростил, что получилась неправда. Спасибо за уточнения.
Я хотел сказать, что была инструкция, ускоряющая просчёт хеша SHA256.
https://en.bitcoin.it/wiki/Why_a_GPU_mines_faster_than_a_CPU#Why_are_AMD_GPUs_faster_than_Nvidia_GPUs.3F
По ссылке ровно что вы и написали, только чуть больше подробностей.

ivan2kh
07.04.2016 00:41Хочется порассуждать немного о сингулярности. Очевидно что С. напрямую связана с развитием ИИ. И
ivan2kh
07.04.2016 01:14Допустим у вас есть техническая возможность для разработки элементной базы и архитектуры чипов для ИИ. Когда появляется первая возможность, вы используйте существующую систему ИИ для оптимизации производства. В итоге находится решение на новой элементной базе со специально подобранноей апхитектурой вычислительных узлов. Но проблема в том, что решение осуществимо технологически и финансово, подготовлено полностью машиной, предполагает ускорение на порядки скорости вычислений в ИИ. То есть вы стоите на пороге сингулярности. Только шаг в сингулярность делает не человек а машина. После этого становится очевидно, что требуется колонизация Марса, только сделать это проще машинами вообще без участия человека. Все игрушки вроде self driving car становятся не нужны. Требуется все усилия направить на научные исследования, но человек здесь уже мало полезен.
Randl
07.04.2016 08:11А что там с нейронными сетями в шахматах? Опять маркетологи выдумывают, или я упустил чего?
Turbo
07.04.2016 10:27Большая часть часто используемых библиотек для вычислений с нейронными сетями написана с поддержкой CUDA (Theano, TensorFlow, MXNet). Крайне редко слышу про похожий софт от AMD. Они не боятся потерять серьезный кусок рынка? По крайней мере когда дело доходит до разговора про расчеты на CNN, все вокруг используют карты семейства GeForce, в частности GTX TITAN.
buriy
07.04.2016 11:32+1Пока что сегмент рынка видюшек для нейросетей маленький по сравнению с геймерами, а вот денег на R&D у AMD есть в 5 раз меньше — а они и так делают сейчас рывок для геймеров, первыми перейдя на HBM память с R9 Fury / Nano и немного обгоняя NVidia в переходе на 16 нм.
Просто нейросети сейчас это очень модно, и, хотя нейросети 100%-качественно ни одну задачу пока решить не могут, а обучаются медленнее, чем могли бы, увеличение качества по сравнению с альтернативными решениями всё же очень заметно.
А в глобальном плане, вообще непонятно, вдруг через пару лет резистивные (мемристорные) архитектуры и специализированное железо типа TrueNorth смогут вытеснить видеокарты для нейросетей.AlexeyR
07.04.2016 17:38На презентации NVIDIA показала оценки рынка, по прогнозам через несколько лет именно сегмент нейросетевого использования будет порядка 100 миллиардов долларов. Сейчас на конференции очень много народу из банков и биржевых контор, все они активно используют нейросети. Сейчас пик моды на глубинное обучение, причем берут не анализом и оптимизацией, а грубой силой.
TrueNorth — по мне, мертвое дитя. Он позиционируется, как аналог работы мозга, но мозг даже близко не похож на то, что там.buriy
08.04.2016 16:59Всем будет наплевать, как TrueNorth позиционируется, если он позволит нейросети считать в 100 раз быстрее.
>по прогнозам через несколько лет именно сегмент нейросетевого использования будет порядка 100 миллиардов долларов
Вот тогда AMD и подтянется. Они почему-то не захотели занимать долю на маленьком рынке в надежде на рост.
>сегмент нейросетевого использования будет порядка 100 миллиардов долларов
Всё может быть. Картинку про экстраполяцию из XKCD помните? https://xkcd.com/605/AlexeyR
09.04.2016 05:06TrueNorth — очень спицифичная штука. Она считает только рекуррентные сети, а в этом направлении пока особых успехов нет.
Mad__Max
10.04.2016 17:15Почему только? Там же не полностью аппаратная реализаций нейронов, а какие-то очень упрощенные, но все-таки достаточно универсальные вычислительные микро-ядра со встроенной локальной памятью и «роутерами» для общения с соседними ядрами. На каждом из ядер обсчитывается большая куча нейронов и синапсов по заданному алгоритму.
Разве нельзя его программировать на любые другие нейронные алгоритмы или близкие к ним?
Мне казалось, что это дальнейшее развитие идей архитектуры наподобие Spinnaker, где вообще используется большое количество стандартных простые ARM ядер, на которых при желании можно считать вообще все что угодно. Но за счет низкой частоты работы + низкого напряжения + локальной памяти + сетевой (а не шинной) структуре связи и оно очень эффективно для обработки нейронных сетей и других алгоритмов требующих гигантского параллелизма, но не критичным к высоким(по меркам классических компьютеров) задержкам. И неэффективно для традиционных вычислительных задач.AlexeyR
10.04.2016 18:05TrueNorth создан под конкретную идею спайковых сетей. Синапсы аппаратно имеют два параметра: веса и время задержки. Вся конструкция заточена только под рекуррентные сети, где исходный сигнал запускает процесс в котором «выход подается обратно на вход». С учетом задержек это моделирует частотную интерференцию, через которую и проявляются свойства обученной сети. Для других применений TrueNorth не пригоден. Это исследовательский проект, пытающийся исходить из своеобразного понимания работы мозга (сейчас очень распространенного). Я считаю, что спайковая модель ошибочна и перспектив у TrueNorth нет.
a5b
10.04.2016 18:08+1Описание TrueNorth — http://paulmerolla.com/merolla_main_som.pdf (см. S1 Neurosynaptic Core Operation с 18-й страницы).
Описание Corelet — концепции программирования TrueNorth — http://www.research.ibm.com/software/IBMResearch/multimedia/IJCNN2013.corelet-language.pdf
Делали симулятор Compass, но исходников не видно — http://www.modha.org/blog/SC12/SC2012_Compass.pdf
http://meseec.ce.rit.edu/722-projects/spring2015/2-1.pdf — Limitations
• No Unsupervised Learning; • Limitation of Connectivity; • Network Scalability; • Low GSOPS
PS: на ARM это ядро совсем не похоже: http://www.research.ibm.com/software/IBMResearch/image/IBMSyNAPSE_core_array.jpg
Mad__Max
10.04.2016 21:35Спасибо за ссылки. Да, на какие-либо универсальные ядра не похоже. Ближе к ASIC чипу с конкретным алгоритмом + совсем небольшие возможности по настройке/программированию.
А про ARM ядра это я про нейроморфные чипы SpiNNaker: https://spinnaker.cs.manchester.ac.uk/tiki-index.php?page=SpiNNaker%20Datasheet
На первый взгляд, структура и подход организации похожи. И даже основное применение — моделирование в ~реалтайме спайковых нейронных сетей. Так что подумал, что TrueNorth дальнейшее развитие подобной архитектуры, только на новых техпроцессах (SpiNNaker еще на древнем 130 нм делался) и с более специализированным и оптимизированным выч. ядром.
Переход от 130 нм на 28 нм + увеличение физических размером (площади) + оптимизация/упрощение ядер, как раз позволило бы вместо 18 больше 1000 простых, но относительно универсальных ядер на каждый чип укладывать.

myxo
07.04.2016 15:37Алексей, а что вы там делаете? =) Ну то есть вы же хоть и в смежной, но все-таки в другой области? Или эти железки можно подстроить и под вашу модель?
AlexeyR
07.04.2016 17:49У NVIDIA есть определенная активность по поддержке нейросетевых разработок. Им интересны любые прорывы в исследованиях, поскольку это создает новые рынки и, соответсвенно, потребности в их железе. Вот меня и пригласили из расчета на всякий случай. У меня сейчас, действительно, готова революционная архитектура, которая очень скоро похоронит и глубинное обучение, и сверточные сети (это мое мнение). Скоро планирую все подробно описать. NVIDIA пообещала поддержать разработчиков, которые рискнут попробовать себя в этой теме.
BelBES
09.04.2016 18:11+1У меня сейчас, действительно, готова революционная архитектура, которая очень скоро похоронит и глубинное обучение, и сверточные сети (это мое мнение).
По каким критериям эта "архитектура" превосходит deep learning?
AlexeyR
09.04.2016 19:24По всем. Удалось качественно перейти на другой уровень по отношеннию к связке глубинное обучение-сверточные сети. Инвариантность не ограничена сверткой по координатам, стабильность-пластичность решается в другой парадигме и позволяет дообучать сети, естественным образом удалось совместить обучение с учителем и без учителя, реализовано автоматическое выделение сущностей, исходя из смыслового подхода. Проще говоря, традиционный подход теряет очень много информации и за счет этого должен брать количеством, ожидая пока проявится статистика. В новом подходе удалось собрать все крупицы информации и избежать загрубления и потерь в процессе обработки, в результате, обучение вышло на новый уровень и по скорости и по точности.
BelBES
09.04.2016 23:45+1А есть практические результаты, где этот некий прорывной подход на реальном железе работает быстрее с хотя бы сравнимым качеством Deep Learning'а на какой-нибудь реальной задаче(путсь хотя бы классификация изображений)?

0xd34df00d
07.04.2016 16:02Искусственный интеллект, искусственный интеллект, нейросети… Вот есть код, который что-то активно считает на CPU. Портировать его под GPU — значит, практически переписать с нуля, причём, жёстко так с нуля, вплоть до ручной реализации всяких разных градиентных спусков.
В свежих clang и их реализации openmp вроде появился оффлоадинг и на CUDA в том числе, да завести его у меня никак не получилось.
Грустно.

{kind=link}

Tufed
07.04.2016 17:25О! да под такой системой можно писать еще менее оптимизированный говнокод.
Mad__Max
07.04.2016 22:07Берите сразу выше — цель подобных систем, чтобы в конце вообще никакой код писать не приходилось. А лишь «скармливать» в некий черный ящик огромные объемы данных «тренируя» его, пока на выходе не начнет получаться примерно нужный результат. Вообще без понимания что именно и как там внутри него (обученной нейронной сети) работает.
tmpvaracc
08.04.2016 16:36+4Это одна из самых желтых статеек из всех что я видел за недавнее время.
Желтизна желтухой погоняет, серьезно.
Тупое перечисление трендов и корпораций. Возвеличивание всех достижений Nvidia, от очень до не очень. Куча эпитетов. «Сам Возняк, создатель „первого“ компьютера с нами поболтал!», «Закон Мура уделали в разы!»
Что вы там уделали? Где ТТХ? Где размеры чипа? Где его особенные фишки, которые делают его интересным именно для ИИ, а не просто хорошей числодробилке? Сколько вообще ватт ест это чудо?
Ни на один из этих вопросов ответов не найти, даже если дочитать до конца этого шедевра маркетолога. Я не хочу казаться занудой конечно, но для «гиковской новости» тут даже этого самого «гика» почти нет — информации 1%, остальное — ярмарка тщеславия компании Nvidia. Тьфу.
DrPass
>… представила новую архитектуру ..., ориентированную на искусственный интеллект
Когда я первый раз встретил в прессе эту фразу, там было написано про Intel и архитектуру 80386.
pehat
Название Pascal вполне себе символизирует.
marvellouz
Фраза похожа, но вот интеллекта новое творении сможет осилить явно больше чем 80386. )