
 В последнее время мы часто слышим о реактивном программировании и видим различные баззворды: message-driven архитектура, event-sourcing, CQRS. К сожалению, на Хабре об этом пишут довольно мало, поэтому я решил исправить ситуацию и поделиться своими знаниями со всеми желающими.
В последнее время мы часто слышим о реактивном программировании и видим различные баззворды: message-driven архитектура, event-sourcing, CQRS. К сожалению, на Хабре об этом пишут довольно мало, поэтому я решил исправить ситуацию и поделиться своими знаниями со всеми желающими. В этой статье мы узнаем об основных особенностях реактивных приложений, рассмотрим, как паттерны CQRS и EventSourcing помогут нам в их создании, а чтобы не было скучно, мы с вами шаг за шагом сделаем свой мессенджер с вебсокетом и акторами, соответствующий всем канонам реактивного программирования. Для реализации всего этого добра, мы будем использовать замечательный язык Scala вместе с не менее превосходной библиотекой Akkа, реализующей модель акторов. Еще, мы будем использовать Play Framework для написания веб-составляющей нашего приложения. Итак, приступим.
Статья предназначена для тех, кто уже знаком со Scala и слышал о модели акторов. Все остальные тоже приглашаются к прочтению, принципы реактивного программирования можно применять вне зависимости от языка и фреймворка.
Что такое реактивное программирование
Идея реактивного программирования описана в реактивном манифесте www.reactivemanifesto.org. Перевод его первой версии уже был на Хабре, а вторая версия незначительно отличается от первой. Давайте рассмотрим краткую вырезку из второй версии. Реактивный манифест гласит, что реактивные приложения имеют несколько важных свойств:
Отзывчивость
Приложение реагирует настолько быстро, насколько это возможно. Отзывчивость — это основа юзабилити и полезности, по той простой причине, что долгие задержки интерфейса не добавляют желания им пользоваться, а так же, отзывчивость означает что проблемы могут быть быстро обнаружены и эффективно решены. Отзывчивые системы фокусируются на предоставлении быстрых и постоянных по времени ожидания ответов, использовании подходящих верхних временных границ для обеспечения стабильного качества обслуживания. Данное постоянное и предсказуемое поведение, в свою очередь упрощает обработку ошибок, укрепляет доверие пользователей, и призывает их к дальнейшему взаимодействию.
Отказоустойчивость
Приложение остается отзывчивым при возникновении сбоя. Это применимо не только к высокодоступным, критически важным системам — любая отказо-неустойчивая система не будет отзывчивой в случае отказа. Устойчивость достигается за счет репликации, локализации, изоляции и делегации. Отказы не выходят за пределы модуля, и посредством изолирования модулей друг от друга можно быть уверенным в том что отдельные части приложения могут отказать и восстановится после сбоя, при этом не приводя к падению всего приложения. Восстановление каждого отказавшего модуля делегируется другому, внешнему модулю, а высокая доступность достигается посредством репликации. Клиенты модуля не имеют головной боли с обработкой отказа модуля.
Эластичность
Приложение остается отзывчивым под различной нагрузкой. Реактивные приложения могут реагировать на изменения нагрузки через увеличение или уменьшение ресурсов предназначенных для ее обработки. Это предполагает архитектуру, не имеющую точек блокировок или центральных узких мест, что выражается в способности к шардингу и репликации модулей, и дальнейшим распределением нагрузки между ними. Результатом этого является масштабируемость при помощи дешевого общеиспользуемого железа (привет, Гугл!).
Ориентированность на передачу сообщений
Реактивные приложения ориентируются на асинхронную передачу сообщений для установки границ между модулями которые обеспечивают слабую связанность, изоляцию, прозрачность местоположения, и предоставляет средства для делегирования ошибок как сообщений. Введение явной передачи сообщений дает возможности для балансировки нагрузки, эластичности и управления потоками данных посредством формирования и мониторинга очереди сообщений, и снижения пропускной способности, когда необходимо. Прозрачность местоположения позволяет использовать одну и ту же логику обработки ошибок как на кластере, так и на одном узле. Неблокирующие коммуникации позволяют получателям сообщений потреблять ресурсы только тогда, когда они активны, что ведет к меньшему оверхеду при работе приложения.

CQRS
CQRS расшифровывается как Command Query Responsibility Segregation (разделение ответственности на команды и запросы). Данный подход к построению архитектуры приложения, в отличие от широко используемого CRUD (Create Retrieve Update Delete) подразумевает то, что возможно использовать разные модели для обновления и чтения информации. Возникает закономерный вопрос, для чего же нам такие извращения? Дело в том, что исходя из того, что модель чтения, и модель записи разделены, мы можем оптимизировать их для этих задач. Например, если для задач чтения лучше подходит денормализация данных, то никто не мешает нам это сделать. Удобнее читать если данные в графовой базе данных — пожалуйста. Хочется хранить все в Key-Value хранилище — да ради бога. Более того, если вы хотите добавить новые фичи в read model, то все что вам нужно после их добавления — перегенерировать модель (стоит сделать оговорку, что если у нас событий на многие гигабайты, то этот процесс не будет таким быстрым, однако мы всегда можем сделать снапшот, который существенно увеличит скорость восстановления).
В принципе, над нормализацией Read-модели можно вообще не заморачиваться, по этой же самой причине. Используя CQRS для оптимизации операций чтения в нашем приложении, мы обеспечиваем отзывчивость нашего приложения. Что нам еще осталось для того чтобы наше приложение было по настоящему реактивным? Правильно, эластичность и отказоустойчивость. Эти черты мы реализуем с помощью паттерна Event Sourcing.
Event Sourcing
Смысл ES в том, что мы храним не текущее состояние нашей модели данных, а всю историю изменений, которые меняют состояние нашего приложения (на самом деле не все изменения, а только те что имеют для нас значение). Для получения текущего состояния мы просто суммируем изменений со всех существующих событий. Что мы понимаем под событием, и чем событие отличается от команды? Команда обозначает то, что кто-то хочет от нас, к тому же ее можно проигнорировать. Событие — это что-то произошедшее, неизменяемый факт.
Преимущество данного подхода в том, что мы никогда ничего не удаляем и не изменяем. Как вы уже догадались, этот дает нам широкие возможности для масштабирования нашего приложения, и в качестве базы данных мы можем использовать хорошо зарекомендовавшие себя NoSQL решения такие как Cassandra или HBase. EventSourcing нам дает отказоустойчивость и эластичность.
Хватит разговоров, покажи нам код
Итак, как было сказано ранее, реализовывать все это дело мы будем с использованием Typesafe stack.
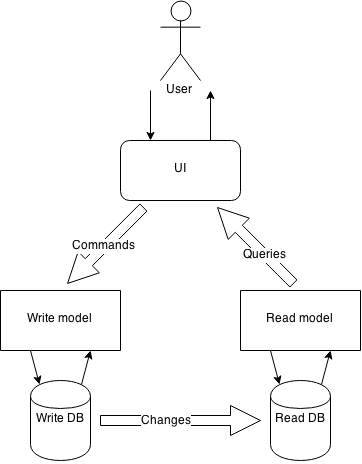
Архитектура нашего приложения будет выглядеть следующим образом:

У пользователя есть возможность читать и отправлять сообщения. Отсылка и принятие сообщений происходит через вебсокет, доступ к которому есть у актора UserConnection. Данный актор отправляет сообщения актору RoomWriter, который помимо записи сообщений в журнал занимается пинанием актора RoomReader, считывающего сообщения из журнала и отправляющего их в обратно актору UserConnection. Кроме всего этого, у нас есть актор Receptionist, который занимается выдачей имен и следит за тем чтобы в приложении не было пользователей с двумя одинаковыми именами. C архитектурой более-менее разобрались, теперь начнем писать код.
RoomWriter
Самым первым мы реализуем тот актор, который занимается записью входящих сообщений в журнал.
class RoomWriter(roomLogId: String) extends PersistentActor {
import RoomWriter._
override def persistenceId = roomLogId
val listeners = mutable.Set.empty[ActorRef]
def receiveRecover = Actor.emptyBehavior
def receiveCommand = {
case msg: Message =>
persistAsync(msg) { _ =>
listeners foreach (_ ! Update)
}
case Listen(ref) => listeners add context.watch(ref)
case Terminated(ref) => listeners remove ref
}
}
Что же тут такое написано? Как можно догадаться, мы объявили класс RoomWriter, который имеет три части:
- идентификатор persistenceId, который необходим для однозначной идентификации событий, которые были произведены данным актором;
- множество listeners, содержащее набор ссылок на акторы, которые должны получать уведомление о том что в журнале что-то изменилось;
- два метода, receiveRecover, который вызывается при реплее сообщений из журнала которое происходит при создании актора, и receiveCommand, который используется для обработки сообщений во время нормального функционирования.
Рассмотрим метод receiveCommand чуть подробнее. Данный метод обрабатывает три разных сообщения:
- при получении сообщения типа Message, происходит асинхронная запись его в журнал, и каждому listener-у отправляется сообщение о том что журнал был обновлен.
- при получении Listen, мы начинаем следить за жизненным циклом актора, ссылка на который лежит в сообщении, ко всему прочему, ссылка на актор добавляется в множество listener-ов
- сообщение Terminated содержащее ссылку на умерший актор мы получим если актор за жизненным циклом которого мы следим, вдруг умрет. Если такое происходит (пользователь закрыл браузер), то мы убираем данный актор из списка рассылки.
Правилом хорошего тона считается объявление всех обрабатываемых сообщений и фабричного метода для создания актора в объекте-компаньоне:
object RoomWriter {
case class Listen(ref: ActorRef)
case class Message(author: String, content: String, time: Long)
case object Update
def props(roomId: String) = Props(new RoomWriter(roomId))
}
С RoomWriter-ом мы разобрались, теперь самое время взглянуть на актор RoomReader, который получает обновления из журнала, и отсылает их по иерархии выше.
RoomReader
class RoomReader(roomLogId: String, roomWriter: ActorRef, userConnection: ActorRef) extends PersistentView {
import RoomWriter._
roomWriter ! Listen(self)
override def persistenceId = roomLogId
override def viewId = roomLogId + "-view"
def receive = {
case msg @ Message(_, _,sendingTime) if currentTime - sendingTime < tenMinutes =>
userConnection ! msg
case msg: Message =>
case Update => self ! akka.persistence.Update()
}
}
RoomReader зависит от идентификатора журнала, в зависимости от которого он будет получать его обновления. В нашем случае, этот идентификатор будет совпадать, с идентификатором актора RoomWriter, что будет означать что все что RoomWriter пишет в журнал, будет приходить в RoomReader. Рассмотрим как происходит обработка сообщений:
- при получении сообщения Message, проверяется время его отправки, и если сообщение старше десяти минут, то оно не будет показано пользователю. Это сделано для того, чтобы к пользователю не приходили тысячи ранее накопленных сообщений.
- при получении Update, актор читает журнал, и отправляет считанные сообщения пользователю.
Как и в предыдущем случае, наш объект-компаньон:
object RoomReader {
def currentTime = System.currentTimeMillis()
val tenMinutes = Duration(10, MINUTES).toMillis
def props(roomLogId: String, roomWriter: ActorRef, userConnection: ActorRef) = Props(
new RoomReader(roomLogId, roomWriter, userConnection)
)
}
Переходим к самому интересному, актору UserConnection, который отвечает за обработку сообщений из вебсокета.
UserConnection
class UserConnection(receptionist: ActorRef, roomWriter: ActorRef, out: ActorRef, roomLogId: String) extends Actor {
import actors.UserConnection._
def receive = waitingForUsername
def waitingForUsername: Receive = {
case WebSocketInMsg(RegisterMeWithName, username) => receptionist ! UsernameRequest(username)
case Ack(username) =>
context become readyToChat(username)
context actorOf RoomReader.props(roomLogId, roomWriter, self)
out ! WebSocketOutMsg(currentTime, "system", "welcome")
case NAck => out ! WebSocketOutMsg(currentTime, "system", "taken")
}
def readyToChat(username: String): Receive = {
case WebSocketInMsg(SendMessage, message) => roomWriter ! Message(username, message, currentMillis)
case Message(author, content, time) => out ! WebSocketOutMsg(formatTime(time), author, content)
}
}
У данного актора есть одна особенность, отличающего его от других: он может менять свое поведение и состояние. Изначально, он находится в состоянии ожидания получения имени пользователя. В этом состоянии он может принимать запросы клиента на получение имени, и пересылать их актору отвечающему за выдачу имен. При успешном получении имени, актор переходит в состояние готовности к чату, и начинает пересылать сообщения между частями системы.
Объект-компаньон на этот раз получился весьма большим:
object UserConnection {
def props(receptionist: ActorRef, roomWriter: ActorRef, out: ActorRef, roomLogId: String) = Props(
new UserConnection(receptionist, roomWriter, out, roomLogId)
)
case class WebSocketInMsg(messageType: Int, messageText: String)
case class WebSocketOutMsg(time: String, from: String, messageText: String)
case class UsernameRequest(name: String)
case class Ack(username: String)
case object NAck
val RegisterMeWithName = 0
val SendMessage = 1
val formatter = DateTimeFormat.forPattern("HH:mm:ss").withLocale(Locale.US)
def currentTime = DateTime.now().toString(formatter)
def currentMillis = System.currentTimeMillis()
def formatTime(timeStamp: Long) = new DateTime(timeStamp).toString(formatter)
}
Последний актор, который будет удостоен нашего внимания, это Receptionist.
Receptionist
class Receptionist extends Actor {
var takenNames = mutable.Map("system" -> self)
def receive = {
case UsernameRequest(username) =>
if (takenNames contains username) {
sender() ! NAck
} else {
takenNames += (username -> context.watch(sender()))
sender() ! Ack(username)
}
case Terminated(ref) => takenNames collectFirst {
case (name, actor) if actor == ref => name
} foreach takenNames.remove
}
}
В его задачи входит выдача имен пользователям: он содержит ассоциативный массив, отображающий имена на actorRef-ы. Так же как и в RoomWriter, мы следим за жизненным циклом акторов которым мы выдали имена, и в случае их смерти удаляем их имена из списка зарегистрированных имен.
Не забываем про объект-компаньон, выносим туда фабричный метод для создания актора:
object Receptionist {
def props() = Props[Receptionist]
}
Контроллер
На данный момент мы закончили со всеми акторами, которые были у нас планах реализации. Теперь рассмотрим то, каким образом нам связать вебсокет и актор. Для этого, мы воспользуемся теми средствами, которые нам может предложить play framework. Реализуем контроллер нашего приложения следующим образом:
object Application extends Controller {
val logId = "akka-is-awesome"
val roomWriter = Akka.system.actorOf(RoomWriter.props(logId), "writer")
val receptionist = Akka.system.actorOf(Receptionist.props(), "receptionist")
def index = Action { implicit request =>
Ok(views.html.chat())
}
implicit val InMsgFormat = Json.format[WebSocketInMsg]
implicit val InMsgFrameFormatter = FrameFormatter.jsonFrame[WebSocketInMsg]
implicit val OutMsgFormat = Json.format[WebSocketOutMsg]
implicit val OutMsgFrameFormatter = FrameFormatter.jsonFrame[WebSocketOutMsg]
def socket = WebSocket.acceptWithActor[WebSocketInMsg, WebSocketOutMsg] { request => out =>
UserConnection.props(receptionist, roomWriter, out, logId)
}
}
Сначала, мы создаем два актора: roomWriter и receptionist. Они являются зависимостями для актора UserConnection. Далее, мы описываем то, как форматировать сообщения для передачи их через вебоскет. Наконец, мы описываем, каким образом мы обрабатываем входящие подключения к вебсокету. Встроенный в Play Framework хелпер позволяет делать это невероятно просто.
Настало время создания веб-интерфейса. Для верстки будем использовать фреймворк twitter bootstrap, а angular.js — для реализации бизнес-логики на клиенте.
angular.module('chatApp', [])
.controller('ChatCtrl', ['$scope', function($scope) {
var wsUri = "ws://"+window.location.host+"/ws";
var websocket = new WebSocket(wsUri);
$scope.name = "";
$scope.messages = [];
$scope.registered = false;
$scope.taken = false;
$scope.sendMessage = function () {
websocket.send(angular.toJson({
"messageType": 1,
"messageText":$scope.messageText
}));
$scope.messageText = "";
};
$scope.sendName = function () {
if (!$scope.registered) {
websocket.send(angular.toJson({
"messageType": 0,
"messageText": $scope.name
}));
}
};
websocket.onmessage = function (e) {
var msg = angular.fromJson(e.data);
console.log(e.data);
if (!$scope.registered) {
switch (msg.from) {
case "system":
handleSystemMsg(msg.messageText);
break;
}
} else {
$scope.messages.push(msg);
$scope.$apply();
var chatWindow = $("#chat-window");
chatWindow.scrollTop(chatWindow[0].scrollHeight);
}
};
function handleSystemMsg(msg) {
switch (msg) {
case "welcome":
$scope.registered = true;
break;
case "taken":
$scope.taken = true;
break;
}
}
}]);
Как будет выглядеть наша html-страница:
<!DOCTYPE html>
<html ng-app="chatApp">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="">
<meta name="author" content="">
<title>Akka WebSocket Chat</title>
<!-- Bootstrap core CSS -->
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.1/css/bootstrap.min.css" rel="stylesheet">
<script src="https://ajax.googleapis.com/ajax/libs/angularjs/1.3.5/angular.min.js"></script>
<!-- Custom styles for this template -->
<link href="@routes.Assets.at("stylesheets/main.css")" rel="stylesheet">
<script src="@routes.Assets.at("javascripts/chatApp.js")"></script>
</head>
<body>
<div ng-controller="ChatCtrl">
<nav class="navbar navbar-inverse navbar-fixed-top" role="navigation">
<div class="container">
<div class="navbar-header">
<a class="navbar-brand" href="#">Reactive Messenger</a>
</div>
<form class="navbar-form navbar-left" ng-submit="sendName()" ng-show="!registered">
<div class="form-group">
<input type="text" class="form-control" ng-model="name" placeholder="Username" required>
</div>
<button type="submit" class="btn btn-default">Set name</button>
</form>
</div>
</nav>
<div class="container" >
<div class="chat col-lg-6">
<div id="chat-window">
<ul class="list-group">
<li class="list-group-item" ng-repeat="message in messages">
<span class="label label-info">{{message.time}}</span>
<span class="label label-default">{{message.from}}</span> {{message.messageText}}
</li>
</ul>
</div>
<form ng-submit="sendMessage()">
<div>
<div class="input-group">
<input type="text" ng-model="messageText" class="form-control" required>
<span class="input-group-btn">
<button class="btn btn-default" type="submit">
Send<span class="glyphicon glyphicon-send" aria-hidden="true"></span>
</button>
</span>
</div> <!-- /input-group -->
</div> <!-- /.col-lg-6 -->
</form>
</div>
</div> <!-- /.container -->
</div>
<!-- Bootstrap core JavaScript
================================================== -->
<!-- Placed at the end of the document so the pages load faster -->
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.1/jquery.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.1/js/bootstrap.min.js"></script>
</body>
</html>
Scaling out
У нас есть прототип приложения, однако прежде чем выкатывать его в продакшн, нам стоит немного его прокачать. Прокачивать мы его будем следующим образом:
- Заменим наш эрзац-журнал на что-то по-настоящему хорошее. В данном случае мы возьмем Cassandra, и будем использовать ее для хранения ивентов.
- Дефолтная Java-сериализация не отличается как стабильностью при изменении формата сообщений так и скоростью при их сериализации. Стоит заменить ее на Google Protobuf или Kryo. В данном случае мы воспользуемся Protobuf-ом.
- Пользователи нашего мессенджера хотят оставаться в курсе последних новостей, и не хотят читать сообщения старше получаса. Для этого мы изменим логику работы наших акторов, и будем создавать snapshot каждые полчаса, благодаря чему нам не придется восстанавливать всю историю сообщений каждый раз при подключении пользователя.
- Для того, чтобы приложение могло обработать большое количество пользователей, стоит сделать его распределенным.
При запуске приложения на нескольких серверах его архитектура изменится весьма незначительно. Благодаря тому, что акторы в Akka обладают свойством location transparency, мы можем безболезненно растащить наше приложение на несколько серверов. Более того, наши акторы даже не будут догадываться что теперь они разделены и работают на разных серверах общаясь по сети. Все что нам нужно, это дописать немного кода, и Akka сделает за нас всю остальную работу.
Забегу вперед и предоставлю картинку того, как будет выглядеть наше приложение после всех доработок. В целом, архитектура претерпит незначительные изменения, однако идея останется прежней.

Для использовании cassandra в качестве журнала, нам необходимо
- установить cassandra на ноды,
- воспользоваться плагином для того чтобы журнал хранился в cassandra.
Первый пункт хорошо описан в официальном мануале, так что особого смысла приводить его тут нет. Стоит заметить только то, что не нужно делать все ноды кассанды seed-нодами, для кластера из трех машин будет достаточно одного сида.
По поводу второго, нам нужно указать в конфиге тип журнала, и прописать адреса нод кассандры. Это можно сделать следующим образом:
akka.persistence.journal.plugin = "cassandra-journal"
cassandra-journal.contact-points = ["ip1,ip2,ip3"]
akka.persistence.snapshot-store.plugin = "cassandra-snapshot-store"
cassandra-snapshot-store.contact-points = ["ip1,ip2,ip3"]
После подключения кассандры, напишем свой класс для сериализации и десериализации сообщений: сначала мы воспользуемся кодогенератором протобуфа для генерации необходимых классов, а потом с их помощью сделаем сериализатор.
Вот так будет выглядеть протобуф-файл:
option java_package = "actors.messages";
option optimize_for = SPEED;
message ChatMessage {
optional string author = 1;
optional string content = 2;
optional int64 timestamp = 3;
}
После генерации протобуфом необходимого класса напишем свой сериализатор:
class ChatMessageSerializer extends Serializer {
def identifier: Int = 193823
def includeManifest: Boolean = false
def toBinary(obj: AnyRef): Array[Byte] = obj match {
case ChatMessage(author, content, timestamp) =>
ProtoChatMessage.newBuilder()
.setAuthor(author)
.setContent(content)
.setTimestamp(timestamp)
.build()
.toByteArray
case _ => throw new IllegalArgumentException("unknown type " + obj.getClass)
}
def fromBinary(bytes: Array[Byte], manifest: Option[Class[_]]): AnyRef = {
val proto = ProtoChatMessage.parseFrom(bytes)
ChatMessage(proto.getAuthor, proto.getContent, proto.getTimestamp)
}
}
Итак, у нас теперь есть нормальный журнал, и способ записи в него. Теперь нам нужно придумать способ сохранения сообщений не старше 10 минут. Для этого напишем собственный буфер, который будет сохранять сообщения за последние 10 минут.
class FixedTimeMessageBuffer(duration: Long) extends Traversable[ChatMessage] {
val list = ListBuffer[ChatMessage]()
def now = System.currentTimeMillis()
def old = now - duration
def append(elem: ChatMessage) = {
if (elem.timestamp > old) {
while (list.nonEmpty && list.head.timestamp < old) {
list.remove(0)
}
list.append(elem)
}
}
override def toList = list.toList
def replace(newList: List[ChatMessage]) = {
list.clear()
list ++= newList
}
def foreach[U](f: ChatMessage => U) = list.foreach(f)
}
В качестве структуры данных для хранения сообщений мы выбрали ListBuffer — по той причине, что мы только добавляем элементы в конец и удаляем их из начала. ListBuffer позволяет делать эти операции за постоянное время. В дальнейшем мы применим данный буфер в нашем акторе Reader — для того, чтобы ограничить количество сообщений, отправляемых вновь подключившимся клиентам.
Рассмотрим то, как нам разделить акторы по сети. Для того, чтобы наше приложение не падало при отключении одной ноды, а дожидалось ее включения, нам следует прописать соответствующую логику в акторе. Актор RoomWriter должен оповещать RoomReader о новых сообщениях, поэтому ему будет полезно знать состояние RoomReader-a. Данная логика хорошо описывается введением двух состояний в актор.
...
sendIdentifyRequest()
def sendIdentifyRequest(): Unit = {
log.info(s"Trying connecting to $roomReaderPath")
context.actorSelection(roomReaderPath) ! Identify(roomReaderPath)
context.system.scheduler.scheduleOnce(3.seconds, self, ReceiveTimeout)
}
def receiveRecover = Actor.emptyBehavior
def receiveCommand = identifying
def identifying: Receive = {
case msg: ChatMessage => persistAsync(msg) { m =>
log.info(s"Message $m persisted, but the reader isn't available")
}
case ActorIdentity(`roomReaderPath`, Some(actor)) =>
log.info(s"Successfully connected to $roomReaderPath")
context.watch(actor)
context.become(active(actor))
case ActorIdentity(`roomReaderPath`, None) => log.info(s"Remote actor is not available: $roomReaderPath")
case ReceiveTimeout => sendIdentifyRequest()
case _ => log.info("Not ready yet")
}
def active(reader: ActorRef): Receive = {
case msg: ChatMessage => persistAsync(msg) { _ =>
reader ! Update
}
case "snap" => saveSnapshot("foo")
case Terminated(`reader`) =>
log.info("reader terminated")
sendIdentifyRequest()
context.become(identifying)
case ReceiveTimeout =>
// ignore
}
...
В методе sendIdentifyRequest мы пытаемся получить ActorRef удаленного актора через отправку ему сообщения Identify. Данное сообщение понимают все акторы, и в ответ присылают нужный нам ActorRef. После получения ActorRef мы переходим в обычное состояние, и начинаем работу. Следует заметить, что мы также начинаем следить за жизненным циклом удаленного актора и в случае его недоступности будем пытаться снова до него достучаться.
Для того, чтобы реализовать подобную логику работы для актора UserConnection, мы создадим отдельный актор, который будет выступать в качестве посредника при общении с бэкендом.
class BackendTalker(roomWriterPath: String, roomReaderPath: String) extends Actor with ActorLogging {
import BackendTalker._
val listeners = collection.mutable.Set[ActorRef]()
sendReaderIdentifyRequest()
sendWriterIdentifyRequest()
def sendReaderIdentifyRequest(): Unit = {
log.info("sending identify request to reader")
context.actorSelection(roomReaderPath) ! Identify(roomReaderPath)
import context.dispatcher
context.system.scheduler.scheduleOnce(3.seconds, self, ReaderReceiveTimeout)
}
def sendWriterIdentifyRequest(): Unit = {
log.info("sending identify request to writer")
context.actorSelection(roomWriterPath) ! Identify(roomWriterPath)
import context.dispatcher
context.system.scheduler.scheduleOnce(3.seconds, self, WriterReceiveTimeout)
}
def receive = identifying
def identifying: Receive = {
case ActorIdentity(`roomWriterPath`, Some(actor)) =>
log.info(s"Successfully identified writer at $roomWriterPath")
context.watch(actor)
context.become(waitingForReader(actor))
case ActorIdentity(`roomReaderPath`, Some(actor)) =>
log.info(s"Successfully identified reader at $roomReaderPath")
listeners.foreach(actor ! Listen(_))
context.watch(actor)
context.become(waitingForWriter(actor))
case ActorIdentity(path, None) => log.info(s"Remote actor not available: $path")
case ReaderReceiveTimeout =>
sendReaderIdentifyRequest()
case WriterReceiveTimeout =>
sendWriterIdentifyRequest()
case msg: ChatMessage =>
listeners += context.watch(sender())
sender() ! ChatMessage("system", "Connection problem, try again later", System.currentTimeMillis())
case Terminated(userCon) => listeners -= userCon
case _ => log.info("Not ready yet")
}
def waitingForReader(writer: ActorRef): Receive = {
case ActorIdentity(`roomReaderPath`, Some(reader)) =>
log.info(s"Successfully identified reader at $roomReaderPath")
listeners.foreach(reader ! Listen(_))
context.watch(reader)
context.become(active(reader, writer))
case ActorIdentity(`roomReaderPath`, None) => log.info(s"Reader actor not available: $roomReaderPath")
case ReaderReceiveTimeout =>
sendReaderIdentifyRequest()
case WriterReceiveTimeout =>
sendWriterIdentifyRequest()
case Terminated(`writer`) =>
log.info("writer terminated")
sendWriterIdentifyRequest()
context.become(identifying)
case msg: ChatMessage =>
listeners += context.watch(sender())
sender() ! ChatMessage("system", "Connection problem, try again later", System.currentTimeMillis())
case Terminated(userCon) => listeners -= userCon
case _ => log.info("Not ready yet")
}
def waitingForWriter(reader: ActorRef): Receive = {
case ActorIdentity(`roomWriterPath`, Some(writer)) =>
log.info(s"Successfully identified writer at $roomWriterPath")
context.watch(writer)
context.become(active(reader, writer))
case ActorIdentity(`roomWriterPath`, None) => log.info(s"Reader actor not available: $roomWriterPath")
case ReaderReceiveTimeout =>
sendReaderIdentifyRequest()
case WriterReceiveTimeout =>
sendWriterIdentifyRequest()
case Terminated(`reader`) =>
log.info("reader terminated")
sendReaderIdentifyRequest()
context.become(identifying)
case msg: ChatMessage =>
listeners += context.watch(sender())
sender() ! ChatMessage("system", "Connection problem, try again later", System.currentTimeMillis())
case Terminated(userCon) => listeners -= userCon
case _ => log.info("Not ready yet")
}
def active(reader: ActorRef, writer: ActorRef): Receive = {
case l: Listen => reader ! l
case msg: ChatMessage => writer ! msg
case Terminated(`reader`) =>
log.info("reader terminated")
sendReaderIdentifyRequest()
context.become(waitingForReader(writer))
case Terminated(`writer`) =>
log.info("writer terminated")
sendWriterIdentifyRequest()
context.become(waitingForWriter(reader))
case ReaderReceiveTimeout =>
case WriterReceiveTimeout =>
// ignore
}
}
В нем, мы реализуем логику ожидания удаленных акторов по аналогии с тем, что мы делали в акторе RoomWriter. В данном случае, нам нужно ожидать подключение к двум акторам сразу, поэтому логика работы немного усложняется.
Остался последний штрих: мы немного перепишем RoomReader для того, чтобы ограничить количество сообщений, которое получают пользователи.
Для этого мы допишем в нем пару строчек.
В конструкторе мы определим наш буфер для хранения сообщений, и напишем вспомогательный метод для работы с ним. Помимо этого, мы запустим scheduler, который раз в 10 минут будет отдавать команду на создание снапшота. Стоит заметить, что команда отдается через отправку сообщения актору, и мы не вызываем метод saveSnapshot напрямую. Это сделано специально, для того чтобы не нарушать принцип того, что работа с mutable данными актора должна производиться только актором. Нарушив этот принцип, мы можем получить трудноуловимые баги.
context.system.scheduler.schedule(tenMinutes, tenMinutes, self, Snap)
val state = FixedTimeMessageBuffer(tenMinutes)
def updateState(msg: ChatMessage) = state.append(msg)
В методе receive мы реализуем возможность сохранения снапшотов по приходу специального сообщения. Также мы реализуем корректное восставновление состояния из снапшота.
case msg:ChatMessage =>
updateState(msg)
sendAll(msg)
case Listen(ref) =>
listeners add context.watch(ref)
state.foreach(ref ! _)
case Snap => saveSnapshot(state.toList)
case SnapshotOffer(_, snapshot: List[ChatMessage]) => state.replace(snapshot)
Подводя итог, можно сказать о том, что мы реализовали современное веб-приложение, сделанное в духе реактивного программирования. Оно позволяет быстро отвечать на запросы пользователей и к тому же обладает некоторый степенью устойчивости. Однако, его есть куда улучшать. Для того, чтобы наше приложение работало даже в случае падения отдельных узлов, нам стоит воспользоваться модулем akka-cluster, который позволяет быстро реализовывать децентрализованные приложение, не имеющие единой точки отказа. Помимо этого, нам нужно как-то обрабатывать ситуацию, когда поток сообщений слишком большой и акторы не успевают его обрабатывать. Для работы с этим существует экспериментальный модуль akka-streams. Об этом и многом другом мы узнаем в следующей статье.
Комментарии (31)

Ex3NDR
07.05.2015 15:35Забавно, но именно это мы и делаем, только уже перешли на Akka-Streams и переписали под себя сериализацию протобафа.

meln1k Автор
07.05.2015 22:21А вы не пробовали использовать что-либо еще помимо протобафа для сериализации?

brainsmith
08.05.2015 15:01Отвечу за коллегу. Для персистенса у нас как раз используется Kryo, а переписанный протобаф – на транспортном уровне для общения с клиентами.

kekekeks
07.05.2015 15:46+1Заменим наш эрзац-журнал на что-то по-настоящему хорошее. В данном случае мы возьмем Cassandra, и будем использовать ее для хранения ивентов.
Есть же вроде специально для этих целей EventStore (плугин к Akka в наличии). Умеет хренить как события, так и снапшоты.dborovikov
07.05.2015 16:08Это пукалака какая-то на javascript-е. Cassandra гораздо более матерое решение и вполне себе специализированное; хрнаить в ней эвенты — это то, что доктор прописал.

lair
07.05.2015 17:04Вы бы хоть сначала посмотрели — JS там, конечно, есть, но как внутренний язык для проекций, а само оно написано на C#. А еще полезно посмотреть на автора…
dborovikov
07.05.2015 17:09Тем более :) Под линукс дистрибуция бинарем, нафиг надо.

synchrone
07.05.2015 17:19+1А в чем проблема собрать сорцы?
dborovikov
07.05.2015 17:30+2Зачем вообще с этим связываться? Выбор NET как платформы для Linux крайне не удачнен. Вот представть себя админом, которому дают на выбор Cassandra, которая на Java без всяких so-шек или нечто на .NET портированное под линукс. Что там в вашем EventStore есть такого волшебного? Вот Cassandra — солидная штука с крутыми интсраляциями и так далее.
synchrone
07.05.2015 17:40-1если подходить к вопросу с потребительской позиции то единственный аргумент — adoption в индустрии, да. всякий энтерпрайз действительно руководствуется такими аргументами и тут с вами спорить нет смысла.
EventStore не мой, я сам про него узнал впервые из статьи, просто дал себе труд посмотреть подробнее.
Объективно же, .net ничем не отличается от джавы в вопросе виртуальной машины, (а где-то и лучше её) и необходимости ставить среду выполнения.
Говорить, что .net приложения «портированы» под линукс — ошибка. Нормальные .net приложения пишутся сразу кроссплатформенно, точно также как на джаве.
nehaev
07.05.2015 17:46+3Автор выбрал платформу Java. При наличии подходящего решения внутри платформы, использовать альтернативный кусок на другой платформе просто нерационально.
dborovikov
07.05.2015 17:47+1Как это не отличается? Оффициального .NET под Linux пока нет, тут Mono, Mono — в продакшне, ну его нафиг. Админить виндовый кластер, извольте.
kekekeks
07.05.2015 18:28-2Mono — в продакшне
Использую пятый год, полёт нормальный. С EventStore вообще поставляется специально под их нужды пропатченый билд Mono.dborovikov
07.05.2015 18:33+1У меня есть знакомые которые что только не использует в продакшне. И D, и Rust. Это ваш выбор, который лично я не одобряю. Все это юношеским максимализмом попахивает.
kekekeks
07.05.2015 18:28-2Как бы сказать. Четвёртая ссылка в гугле по запросу «event sourcing» ведёт именно на EventStore.
nehaev
07.05.2015 17:40А что плохого в кассандре-то? Для нее тоже есть плагин, который автор и юзает как раз.
kekekeks
07.05.2015 18:29-1В том, что кассандра — БД общего назначения, EventStore же писалась специально под нужды паттерна event sourcing. Вы с тем же успехом события и снапшоты можете в Postgres хранить, под него тоже плагин есть.
dborovikov
07.05.2015 18:40+2Кассандра ниразу не БД общего назначения, а как раз для таких штук вроде обработки событий и разрабатывалась. C Постгресом вообще сравнение не корректное.

Throwable
11.05.2015 12:11Всегда возникали вопросы по архитектуре реативного приложения. Насколько я понимаю, реактивное программирование и CQRS предназначены для простой бизнес логики и слабо связанных данных. Основными проблемами данного подхода я вижу:
— невозможность свободной выборки данных из разных entity (то, что в ER делают JOIN-ы). Как выход предлагается денормализировать читаемые данные ввиде графа, чтобы выборка происходила по одной entity, которая включала бы в себя все необходимое. Но это далеко не всегда достижимо.
— отсутствие стабильного состояния в любой момент времени. То есть полное состояние — это то, что лежит в базе плюс все event-ы, разбросанные в данный момент по обработчикам. Как быть, если наш запрос — нечто более сложное, нежели атомарное изменение, а например: прочитать данные, проанализировать и в зависимости от этого выполнить ряд изменений разных сущностей? Без локов или транзакций состояние будет «уплывать», что ведет к потере целостности.
— большая сложность групповой обработки событий, например если нужно объединить несколько событий в одно большое. При декомпоновке событий очередность обработки не гарантируется.
Буду рад, если поправите.meln1k Автор
11.05.2015 20:58невозможность свободной выборки данных из разных entity
Как правило для этих целей собирается отдельный денормализованный view, на который прилетают все события относящиеся к одному aggregate root.
отсутствие стабильного состояния в любой момент времени
Да, у нас нет strong consistency всей системы, однако внутри аггрегата у нас поддерживается консистетное состояние в любой момент времени. В большинстве случаев этого достаточно для корректной работы приложения. Если бизнес-логика требует консистентное состояние в любой момент времени, то в данном случае не следует использовать CQRS/ES. Кстати, а вы бы не могли привести пример из реального мира, когда нам нужно иметь консистентное состояние всей системы в любой момент времени?
При декомпоновке событий очередность обработки не гарантируется
Если я ничего не перепутал, то для решения подобных проблем используются conflict-free replicated data types, которые позволяют обработать события даже если они пришли не в том порядке.Throwable
12.05.2015 17:05Насчет примера: любой банк. Каждый день в XX:YY часов открывается окно для межбанковских операций. Нужно посчитать к этому моменту все операции за день и изменения счетов, и выставить суммарный счет каждому из контрагентов. К этому моменту нужно, чтобы все операции были завершены и состояние всей БД было стабильно.
Дугой пример из того же банка. Сделали асинхронные транзакции, по одному актору на один счет. Все шустро и независимо работает: сообщения о денежных переводах роутятся к акторам, каждый актор смотрит баланс своего счета, и если он становится негативным, то операция запрещается. Теперь менеджер захотел, чтобы для определенных клиентов операция разрешалась, если суммарный баланс всех счетов одного клиента был бы неотрицательный, тогда как каждый счет в отдельности может стать негативным. Можно сделать новый тип акторов, который бы пропускал через себя все транзакции к счетам каждого клиента, но это потребует архитектурных изменений и затруднит совмесную работу со старыми акторами. Возвращаемся к блокировкам.
В CQRS моделях набор выполняемых операций ограничен, операции достаточно просты, чтобы быть выполненными внутри одного аггрегатора, а логика их выполнения не зависит от выполнения других операций или данных, лежащих вне аггрегатора. Для многих бизнес задач операция требует синхронного изменения сразу многих объектов. Выделить операции в атомарные акторы не представляется возможным, так как одни и те же данные используются разными операциями. Поэтому приходится искусственно создавать блокировки, либо использовать уже готовые средства, предоставляемые dbms.
Если я ничего не перепутал, то для решения подобных проблем используются conflict-free replicated data types
Необходим конечный автомат с персистентным состоянием, который бы ловил эти события, коррелировал бы их в группы и применял бы какое-нибудь правило типа: если получили A, B, C (в любом порядке), то выкинуть X. Если получили A, C, D, то выкинуть Y, etc…lair
12.05.2015 20:06Насчет примера: любой банк. Каждый день в XX:YY часов открывается окно для межбанковских операций. Нужно посчитать к этому моменту все операции за день и изменения счетов, и выставить суммарный счет каждому из контрагентов. К этому моменту нужно, чтобы все операции были завершены и состояние всей БД было стабильно.
Так это же не «в любой момент», это в конкретный момент. И как раз для этого eventual consistency прекрасно подходят.
meln1k Автор
12.05.2015 20:44-1любой банк
Интересным фактом является то, что исторически, когда письма доставлялись на повозках и кораблях, и время доставки письма могло доходить до нескольких месяцев, банки прекрасно работали, бюджеты сводились, и никто не разорялся. И все это работало без каких-либо транзакций, сплошная eventual consistency.Throwable
13.05.2015 11:09+1Ну, если судить абстрактно, то вообще существует только eventual consistency. Просто транзакционная модель контролирует многие аспекты, среди которых — «поймать» этот момент consistency, гарантировать атомарность, snapshot-чтение данных, etc… Проблема в том, что в распределенной среде синхронизация данных осуществляются медленно (хотя все относительно — игровые серверы живут и процветают), и люди делают выбор в пользу BASE и асинхронной архитектуры. Но это всегда в разы усложняет логику, поскольку контроль над выборочной consistency полностью ложится на разработчика. Поэтому «реактивная» парадигма — это не панацея и не новый модный подход, а вынужденная необходимость. Там, где можно использовать ACID, нужно использовать ACID.
P.S. Да. Но чтобы добиться eventual consistency банки устраивали «учетный день» или даже «учетную неделю», когда денежные операции не принимались, или складывались в очередь, но не выполнялись. В современном мире невозможно, хотя в Европе большинство банков работают с клиентами до 14:00, а дальше, видимо, время eventual consistency :) Говорят, что и рождественские каникулы существуют для того, чтобы спокойно привести годовой баланс в порядок и закрыть бюджет :)
datacompboy
А вы действительно хотите на КДПВ ракету привязанную задом наперёд? То есть птичка реактивно так полетит назад…
ymn
Фраза «выстрелить в ногу» приобретает новые оттенки)
Shersh
Вряд ли полетит. Она же направлена в землю, поэтому её размажет по поверхности. Scale Out =)
impwx
Тот неловкий момент, когда к интересной статье прикрепляют провокационную КДПВ.