
Некоторое время назад мне захотелось написать свой небольшой интерпретируемый скриптовый язык, просто ради фана, не ставя перед собой каких-либо серьезных задач. Я тогда активно читал известную волшебную книгу SICP (Структура и интерпретация компьютерных программ), и мне захотелось реализовать описываемые в ней абстракции — функции как объекты первого класса, замыкания, макросы и т.п. Параллельно я интересовался языком Haskell, и решил совместить приятное с приятным, и написать интерпретатор языка на нем. В моем языке должна была быть строгая семантика с вызовом по значению и мутабельные переменные. Получившийся язык Lisp-семейства я в своем локальном окружении связал с именем Liscript, полная реализация которого уместилась в примерно 250 строк, включая парсер, ядро и консольный/файловый ввод-вывод. Этого более чем хватало, чтобы ради интереса решать любые задачки, какими обычно мучают студентов, которых угораздило изучать Lisp по учебной программе.
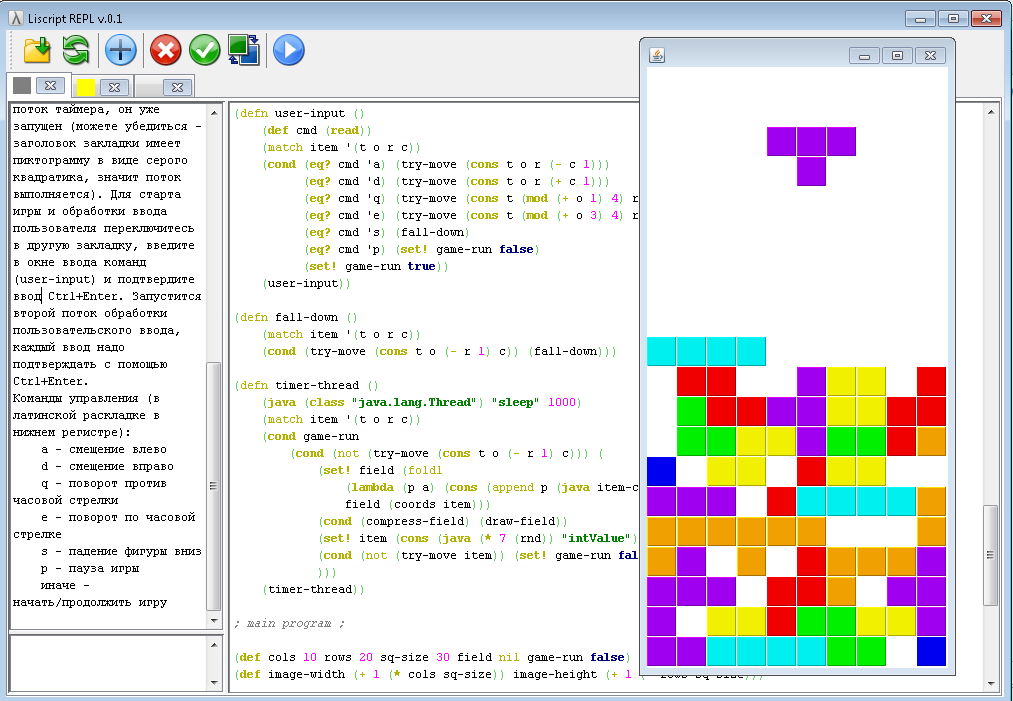
По прошествии времени мне захотелось сделать к интерпретатору кроссплатформенный GUI-интерфейс с перспективой портирования на Android, поэтому я реализовал второй вариант интерпретатора на Java, внешний вид которого вы можете видеть на картинке выше. Да, он поддерживает графический вывод и вообще interoperability с Java, и этот Тетрис написан на Liscript, видна часть его кода. Кому интересны подробности — прошу под кат.
В рамках одной статьи сложно уместить все особенности языка и его реализации, а писать сериал из многих статей, начиная с пространного описания реализации парсера с помощью стандартной библиотеки мне скромность не позволит. (К слову сказать, в обоих реализациях — и на Haskell и на Java я не пользовался никакими библиотеками парсинга, а писал все вручную — на Haskell это заняло аж целых 10 строк кода). Поэтому некоторые вещи буду писать в стиле «пришел, увидел, победил». В общем, написал я парсеры текста в AST типов. Единственно, хочу отметить пару моментов — я не фанат скобочек, но легкость парсинга, гомоиконность кода (код как данные) и отсутствие инфиксных бинарных операторов с необходимостью учета приоритета и ассоциативности и разбора через Польшу или сортировочные станции с лихвой перевешивает все претензии к подобному синтаксису. В результате парсинга я получаю список, который передается функции интерпретации. В Java-реализации я не стал пользоваться библиотечными типами списков, а навеловипедил свой — простой, односвязный, потоконебезопасный и т.п.:
/** тип языка Liscript - односвязный список */
public static class ConsList {
/** объект - значение головы текущего списка */
public Object car;
/** список - значение хвоста текущего списка */
public ConsList cdr;
/** Конструктор со значениями головы и хвоста.
* @param h объект - голова списка
* @param t список - хвост списка
*/
ConsList(Object h, ConsList t) { car = h; cdr = t; }
/** проверяет, является ли список пустым
* @return истина/ложь
*/
public boolean isEmpty() { return this.car == null && this.cdr == null; }
/** возвращает размер списка
* @return размер
*/
public int size() {
int r = 0;
ConsList p = this;
while (!p.isEmpty()) {r += 1; p = p.cdr;}
return r;
}
/** @return строковое представление текущего списка */
@Override
public String toString() { return showVal(this); }
}Подобным же образом реализованы типы-классы для функции, макроса. Пример кода класса-типа функции:
/** тип языка Liscript - функция */
public static class Func {
/** односвязный список имен параметров функции */
public ConsList pars;
/** тело функции */
public Object body;
/** окружение, в котором создана функция */
public Env clojure;
/** Конструктор
* @param p односвязный список имен параметров функции
* @param b тело функции
* @param c окружение, в котором создана функция
*/
Func(ConsList p, Object b, Env c) { pars = p; body = b; clojure = c; }
/** @return строковое представление функции */
@Override
public String toString() { return showVal(this); }
}Окружение
Реализовано в полном соответствии с SICP — иерархическая структура словарей, где каждый словарь — HashMap<String, Object>, класс содержит методы добавления, получения и изменения значения по строковому имени. И тут уже можно проявить творческий подход: например, что делать, если пытаемся получить значение по отсутствующему ключу (имени переменной)? Прервывать исполнение с ошибкой? Или возвращать строковое представление ключа? То же самое, если пытаемся добавить переменную, имя которой уже содержится в словаре текущего кадра окружения — давать ошибку или переопределять переменную? Подобные мелочи в результате определяют особенности языка, и например мне нравится, что я могу сам определять их. Получаем автоцитирование и глубокое связывание, со всеми плюсами и минусами такого подхода.
Также мне захотелось реализовать переменную арность особых форм прямо в ядре языка, а не потом в стандартной библиотеке. Многие из них допускают передачу ряда параметров и/или работают не совсем так, как их одноименные аналоги в других диалектах Lisp — это не усложняет реализацию интерпретатора. Пример работы с окружением (после => идет ответ интерпретатора):
++ "a1 = " a1 ", b1 = " b1 ", c1 = " c1
=> a1 = a1, b1 = b1, c1 = c1
def a1 1 b1 (+ a1 1) (++ "c" a1) (+ a1 b1)
=> OK
++ "a1 = " a1 ", b1 = " b1 ", c1 = " c1
=> a1 = 1, b1 = 2, c1 = 3
set! (++ "a" 1) 5 c1 10
=> OK
++ "a1 = " a1 ", b1 = " (get (++ "b" 1)) ", c1 = " c1
=> a1 = 5, b1 = 2, c1 = 10
Функции
Являются объектами первого класса. При создании функция захватывает текущий контекст. При вызове аргументы вычисляются строго последовательно. Реализована автоматическая оптимизация хвостовых вызовов — ТСО:
defn is-even (n) (cond (= n 0) true (is-odd (- n 1)) )
=> OK
defn is-odd (n) (cond (= n 0) false (is-even (- n 1)) )
=> OK
is-even 10000
=> true
is-even 10001
=> false
Особая форма tray позволяет печатать стек вызовов при применении функции. Вот так, например, происходит вычисление факториала от 3:
defn f (i) (cond (< i 2) 1 (* i (f (- i 1))))
=> OK
tray f 3
=>
1 < (f 3)
2 < f
2 > (lambda (i) (cond (< i 2) 1 (* i (f (- i 1)))))
2 < (cond (< i 2) 1 (* i (f (- i 1))))
3 < (< i 2)
4 < i
4 > 3
3 > false
3 < (* i (f (- i 1)))
4 < i
4 > 3
4 < (f (- i 1))
5 < f
5 > (lambda (i) (cond (< i 2) 1 (* i (f (- i 1)))))
5 < (- i 1)
6 < i
6 > 3
5 > 2
5 < (cond (< i 2) 1 (* i (f (- i 1))))
6 < (< i 2)
7 < i
7 > 2
6 > false
6 < (* i (f (- i 1)))
7 < i
7 > 2
7 < (f (- i 1))
8 < f
8 > (lambda (i) (cond (< i 2) 1 (* i (f (- i 1)))))
8 < (- i 1)
9 < i
9 > 2
8 > 1
8 < (cond (< i 2) 1 (* i (f (- i 1))))
9 < (< i 2)
10 < i
10 > 1
9 > true
8 > 1
7 > 1
6 > 2
5 > 2
4 > 2
3 > 6
2 > 6
1 > 6
6
Если при вызове функции аргументов передано больше, чем количество формальных параметров, то последний формальный параметр свяжется со списком вычисленных оставшихся переданных аргументов. Если меньше — то эти формальные параметры окажутся не связаны в окружении вычисления функции и при вычислении ее тела будут искаться в окружениях верхнего уровня иерархии. Можно было бы выбрать вариант каррирования — возвращать частично примененную функцию, или выдавать ошибку несоответствия количества аргументов.
Макросы
Liscript поддерживает так называемые runtime-макросы, которые являются объектами первого класса языка. Их можно создавать, связывать с именами, возвращать как результат функций и выполнять в процессе работы (интерпретации кода). Полученное из текста исходного кода выражение сразу начинает интерпретироваться, без предварительной стадии раскрытия макросов, поэтому макросы остаются полноправными типами языка и раскрываются и вычисляются в процессе интерпретации по всем правилам вычисления макросов — сначала производится подстановка в тело макроса невычисленных переданных аргументов а затем это тело макроса вычисляется в текущем окружении (в отличие от тела функции, которое всегда вычисляется в отдельном собственном окружении, в котором уже присутствуют предварительно вычисленные значения фактических параметров):
def m (macro (i r) (cond (<= i 0) 'r (m (- i 1) (cons i r))))
=> OK
m 5 nil
=> (cons (- (- (- (- 5 1) 1) 1) 1) (cons (- (- (- 5 1) 1) 1) (cons (- (- 5 1) 1) (cons (- 5 1) (cons 5 nil)))))
eval (m 5 nil)
=> (1 2 3 4 5)
Interoperability с Java
Реализовано через механизм Java Reflection. Всего 2 особые формы: class — определяет класс по полному имени и java — вызывает метод класса с переданными параметрами. Поиск нужного метода среди одноименных перегруженных осуществляется с учетом количества и типов переданных параметров. Для ускорения работы однажды найденный и вызванный в текущем сеансе работы интерпретатора метод класса запоминается в таблице вызванных методов и при вызове любого метода сначала происходит поиск в таблице — мемоизация.
def m (java (class "java.util.HashMap") "new")
=> OK
java m "put" 1 "a"
=> OK
java m "put" "b" 2
=> OK
java m "get" 1
=> a
m
=> {1=a, b=2}
Таким образом мы можем получить доступ ко многим ресурсам языка реализации, в том числе и к графике. Вот такой код открывает отдельное окно с нарисованной красной линией на белом фоне:
(def image (java (class "java.awt.image.BufferedImage") "new" 100 100 1))
(def imageGraphics (java image "createGraphics"))
(java imageGraphics "setBackground" (java (class "java.awt.Color") "new" 255 255 255))
(java imageGraphics "clearRect" 0 0 100 100)
(java imageGraphics "setColor" (java (class "java.awt.Color") "new" 255 0 0))
(java imageGraphics "drawLine" 10 10 90 90)
(def icon (java (class "javax.swing.ImageIcon") "new"))
(java icon "setImage" image)
(def label (java (class "javax.swing.JLabel") "new"))
(java label "setIcon" icon)
(def window (java (class "javax.swing.JFrame") "new"))
(java window "setLayout" (java (class "java.awt.FlowLayout") "new"))
(java window "add" label)
(java window "setVisible" true)
(java window "pack")
Разумеется, можно выделить типичные блоки в отдельные функции или макросы и прописать их один раз в стандартной библиотеке, которая подгружается при старте интерпретатора. А поскольку интерпретатор реализует многопоточное выполнение задач в отдельных закладках с общим мутабельным окружением (да, я знаю, что выбранная в качестве хранилища словаря HashMap не является потокобезопасной и это может создать проблемы при одновременном изменении окружения из параллельных потоков, и лучше было применить HashTable), так вот, это позволяет в одной закладке запустить процедуру, вызывающую саму себя через определенное время ожидания по таймеру, а в другом окне (потоке) — процедуру, запрашивающую пользовательский ввод и выполняющую определенные действия. Так и был реализован Тетрис (с особенностью блокирующего пользовательского ввода — каждую команду надо подтверждать с помощью Ctrl+Enter).
Данный проект доступен на Github по адресу github.com/Ivana-/Liscript-GUI-Java-Swing. В нем содержатся исходные файли интерпретатора и его GUI на Swing (я знаю что уже 21 век на дворе, но на JavaFX пока переписывать не тороплюсь), а также файлы скриптов стандартной библиотеки, описания языка, интерпретатора и достаточное количество демо-примеров. При желании покритиковать прошу учесть, что это мой первый проект на Java и на ООП языке вообще, так что многое может быть реализовано неоптимально. Но мне будет интересны мнения и обратная связь по этому проекту.
Комментарии (13)
IIvana
18.04.2016 16:32Вот как раз на продолжениях остановился. Есть мысль их сделать в перспективе. Изучив детальнее что это такое, для начала :) А вообще, можно развивать сахар (параметры функций по умолчанию и т.п.), фичи (те же продолжения, более полноценное interoperability с Java — создание экшенов по кнокпам или другим событиям) или что-то еще. Но продолжения в планах имеются, и с достаточным приоритетом.

GlukKazan
18.04.2016 18:31К сожалению, тема продолжений, а также макросов в SICP не освещена совершенно. Рекомендую почитать «Lisp in Small Pieces». На Хабре есть перевод.

Mellkor
19.04.2016 23:32+1Стоит упомянуть еще одну книгу www.buildyourownlisp.com.
Это небольшой туториал по реализации интерпретатора лиспа на си.
IIvana
18.04.2016 20:27Спасибо, я читал начало. Судя по всему, имеет смысл прочитать полностью. А макросы я по своим кустарным представлениям сделал, это потом я уже увидел заметку про фёст-класс рантайм-макросы и узнал много нового о себе после употребления этого словосочетания на ЛОРе :) Но они работают, и синтаксис проще стандартных Лисповых макросов. Но не имея опыта с последними, я не могу сказать, мои Уже или шире по возможностям.
GlukKazan
18.04.2016 21:43Я сам не бог весть какой специалист по лисповым макросам. Надо будет глянуть ваши исходники как будет время.
Всё еще не могу за вас проголосовать. Глупый баг.IIvana
18.04.2016 21:56Я видел, что вы посмотрели на гитхабе и мой Haskell-проект реализации этого языка. В мелочах эти 2 реализации отличаются (автоматическое расширение чисел до типа double при арифметических операциях или разная арифметика для разных типов и т.п.), но в плане макросов они вроде эквивалентны. Можно конечно допилить Haskell-реализацию, если бы не лень (каламбурчик, внутренняя хаскельная лень как раз ничуть не мешает :)) Было бы интересно, если кто-нибудь ради забавы наваяет на Liscript решение какой-нибудь задачки, можно с блэкджеком и макросами :)
GlukKazan
18.04.2016 21:59Внимательно ещё не смотрел, пролистал по диагонали.
Очень радует подробное комментирование.
GlukKazan
19.04.2016 09:48Не совсем понял на счёт оптимизации хвостовой рекурсии. В readme к хаскельной реализации написано, что вы не стали её делать.
В Java-версии всё-таки решили сделать?IIvana
19.04.2016 14:50+1Именно. Потому что хаскель сам отлично оптимизирует любые рекурсии, в том числе и хвостовые. А Java не оптимизирует даже хвостовые. И когда я перевел реализацию на Java, я сразу столкнулся с постоянными неприятными переполнениями стека при вычислениях — у меня же нет циклов (на самом деле есть, особая форма while, но это просто ради пробы, можно ее выпилить из языка), все делается через рекурсию, каждое вычисление идет в своем одном потоке, размер стека которого можно задать при старте приложения в параметре. Я потратил некоторое количество сил и времени для полного решения этого вопроса — вынос вычислений со стека в кучу, передача вычисления в дочерний поток и т.п. Но все эти варианты работали медленно и/или ненадежно, поэтому я остановился на общепринятой полумере — оптимизации только хвостовых вызовов, но автоматическом (программисту не надо явным образом указывать что это хвостовой вызов, как в некоторых других языках — интерпретатор определяет это сам). И в результате у меня библиотечная функция левой свертки списка foldl волшебным образом стала не переполнять стек на больших списках, а правая свертка foldr продолжает переполнять. Пришлось и некотороые другие (какие возможно) библиотечные функции переписать через хвостовую рекурсию. Как писал Норвиг в комментариях про lispy2:
there is a potential problem: if every recursive call grows the runtime stack, then the depth of recursion, and hence the ability to loop, will be limited. In some implementations the limit will be as small as a few hundred iterations. This limitation can be lifted by altering eval so that it does not grow the stack on all recursive calls--only when necessary.
http://norvig.com/lispy2.html
Вот и у меня — only when necessary, без лишних указаний со стороны программиста.
Но конечно есть задачи, которые трудно реализовать только через хвостовую рекурсию. В моих демо-примерах есть пример работы с бесконечными потоками (реализованными средствами исключительно самого языка, через макросы и мемоизацию), но они переполняют стек при относительно длинных запросах. Частичное решение — запускать интерпретатор с ключом — указанием размера стека потока побольше, при работе обычно используется максимум несколько потоков (в отдельных закладках), не считая потока событий GUI.GlukKazan
19.04.2016 15:04Думаю, всё это вместе — хорошая тема для следующей статьи
IIvana
19.04.2016 15:17В свою очередь думаю, что по этой паре интерпретаторов можно написать не один десяток полноценных статей, каждая по своей отдельной тематике, где все расписывать уже в деталях. В личной переписке я просил вас (и здесь спрашиваю всех участников) — хотели бы вы видеть статьи, детальнее раскрывающие какие-либо отдельные вопросы, и если да — то какие? Насколько я понял, одно предложение уже есть — реализация TCO. Хорошо, попробую написать нескучно про это. Может кто что еще добавит (хотя обсуждаем тему только мы с вами, а после ухода статьи с первой страницы на второй день вряд-ли кто еще подключится).

Sirikid
19.04.2016 16:45+1Готов читать статью про что угодно, т. к. интересует и lisp и интерпретаторы/компиляторы вообще. И даже плюсовать, если сам сподоблюсь написать.
GlukKazan
Выглядит интересно.
Продолжения делали?