
С одной стороны они являются действительно очень удобным хранилищем информации, позволяющим менять данные на лету, с другой стороны это удобство частично нивелируется скоростью доступа к данным.
Вообще для чего обычно используют составные файлы?
Для всего, что нужно хранить в некоем контейнере (NoSQL подмножество).
К примеру, файлы старых версий Microsoft Office от 97 до 2003 включительно (состоящие на самом деле из нескольких десятков файлов), хранились как раз в составном файле. Сейчас тоже хранятся, только в качестве контейнера используется ZIP.
Инсталляционные пакеты MSI тоже являются составными файлами, и даже файл кэша эскизов папок Thumbs.db использует этот формат.
Правда для того же Word есть целый комплекс утилит (Recovery for Word, Word Recovery Toolbox, Munsoft Easy Word Recovery) восстанавливающих, ну или по крайней мере пытающихся восстановить, поврежденные документы. Выводы можете сделать сами.
Хотя, при должной работе с составными файлами проблему их повреждения можно решить (и я покажу как).
Ну и, конечно же, несомненным плюсом этого формата является то, что внутри хранилища эмулируется полноценная файловая система со своими файлами и папками.
Кстати, нюанс. Перед началом статьи я провел опрос на нескольких форумах, и выяснилось, что подавляющее большинство разработчиков не работают с составными файлами, причем по простой причине — не слышали что это такое.
Вот сейчас и закроем этот пробел.
1. Общие сведения о составных файлах и их создании
С ходу рассказывать структуру и внутренний формат составного файла я не буду, это лишнее.
Для начала нужно его «пощупать» — что он из себя вообще представляет.
Поэтому начнем с того, что создадим новый составной файл вызовом StgCreateDocfile.
В uses подключим эту парочку ActiveX и AxCtrls (пригодятся).
А теперь пишем:
procedure CheckHResult(Code: HRESULT);
begin
if not Succeeded(Code) then
RaiseLastOSError;
end;
var
TestFilePath: string;
WideBuff: WideString;
Root: IStorage;
begin
TestFilePath := ExtractFilePath(ParamStr(0)) + '..\data\simple.bin';
ForceDirectories(ExtractFilePath(TestFilePath));
WideBuff := TestFilePath;
CheckHResult(StgCreateDocfile(@WideBuff[1],
STGM_CREATE or STGM_WRITE or STGM_SHARE_EXCLUSIVE,
0, Root));
Прежде всего, обращу внимание на флаги.
STGM_CREATE и STGM_WRITE — эти два флага используются для создания нового составного файла, причем наличие флага STGM_WRITE в данном случае обязательно (иначе никакого фокуса не получится ©).
ВАЖНО:
А вот с третьим флагом STGM_SHARE_EXCLUSIVE все гораздо хитрее. Его наличие требуется всегда и везде, кроме открытия файла в режиме «только чтение», о чем говорится во второй главе.
Можете проверить самостоятельно в IDA Pro Freeware.
StgCreateDocfile вызывает функцию DfOpenDocfile, из которой происходит вызов VerifyPerms, в которой будет вот такая проверка:
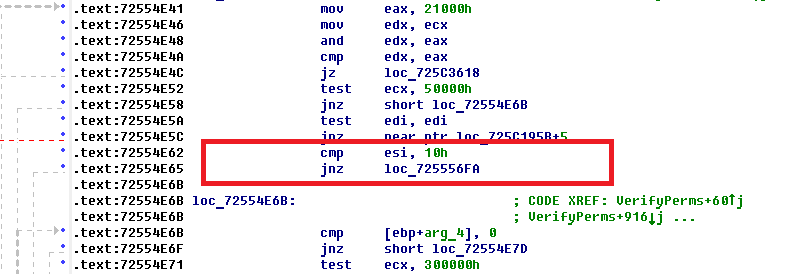
По адресу 72554E62 происходит проверка наличия данного флага, и если его вдруг не будет обнаружено, вернется ошибка открытия. Таким образом, одновременное открытие составного файла на запись более одного раза запрещено.
Для меня было несколько удивительно увидеть такую проверку в третьем кольце и я даже (эксперимента ради) ее занопил, после чего смог открыть файл на запись два раза одновременно. Но — корректно записать в оба файла, естественно, не получилось. :)
На самом деле это достаточно грамотное решение, из-за самого формата хранения данных, но я на нем остановлюсь чуть позже, ближе к концу статьи.
Если все проверки прошли успешно и код возврата StgCreateDocfile равен S_OK, то в четвертом параметре данной функции нам вернется интерфейс IStorage, указывающий на корневой элемент составного файла, с которым и будет происходить вся дальнейшая работа.
Что мы можем сделать далее?
К примеру, создать в корне новый файл (все же у нас файловая система) и записать в него некий блок данных.
Пишем вот такую функцию:
procedure WriteFile(Storage: IStorage; AName: WideString; Data: AnsiString);
var
Stream: IStream;
OS: TOleStream;
begin
CheckHResult(Storage.CreateStream(@AName[1],
STGM_WRITE or STGM_SHARE_EXCLUSIVE, 0, 0, Stream));
OS := TOleStream.Create(Stream);
try
OS.WriteBuffer(Data[1], Length(Data));
finally
OS.Free;
end;
end;
В ней первым делом создаем новый «файл» вызовом функции Storage.CreateStream. Она практически идентична рассмотренной ранее StgCreateDocfile, только в качестве результата возвращает интерфейс IStream, посредством которого будет вестись работа с содержимым файла.
Обратите внимание на флаги: STGM_SHARE_EXCLUSIVE должен быть указан обязательно, а вторым должен идти (в случае создания) либо STGM_WRITE, либо STGM_READWRITE, но т.к. составной файл был создан с использованием флага STGM_WRITE — используется именно он.
Для удобства работа с IStream ведется посредством класса-прослойки TOleStream, который и производит запись данных.
Это, конечно, не принципиальный момент, и можно было воспользоваться вызовом функции Write интерфейса ISequentialStream, наследником которого является IStream, но работать с классом TOleStream проще.
Вызовем реализованную нами ранее функцию:
WriteFile(Root, 'RootFile', 'First file data');
В результате в корне появится файл с именем RootFile и содержимым «First file data».
ВАЖНО:
Здесь есть один нюанс.Имена файлов и папок внутри составного файла не могут превышать длину в 31 юникодных символов (на самом деле не более 32, но нельзя забывать про терминирующий ноль).
Да, именно так, папку или файл можно зазвать «123», но нельзя: «Мое длинное имя файла и еще много цифр». Более того по спецификации есть набор символов, которые нельзя использовать в наименовании (от 0 до 0x1F).
Наверное, вы скажете — зачем такие ограничения, а вдруг я хочу развернуть огромную разветвленную файловую систему с огромной глубиной вложенности?
Так не вопрос, в отличие от стандартных файловых ограничений, на вас не действует константа MAX_PATH.
500 вложенных папок с именем «мое большое имя»?
Это легко, таки работаем с виртуальной файловой системой — творите что хотите. :)
Вернемся к нашим баранам: создадим в корне папку.
CheckHResult(Root.CreateStorage('SubFolder',
STGM_WRITE or STGM_SHARE_EXCLUSIVE, 0, 0, Folder));
Код практически аналогичен вызову Storage.CreateStream, только в этот раз мы получим еще один интерфейс IStorage указывающий на только что созданную папку.
Можем прямо сейчас создать в ней новый файл:
WriteFile(Folder, 'SubFolderFile', 'Second file data');
Для этого первым параметров укажем не Root, который ссылается на корень, а только что созданный Forder.
ВАЖНО:
А теперь нюанс, если прямо сейчас закроем приложение — данные могут не сохраниться.
Тут на самом деле не все так просто, к примеру, на моей домашней машине такое поведение воспроизводится гарантированно, а на рабочей с точностью наоборот.
Чтобы гарантировать сохранение данных нужно выполнить следующий код:
CheckHResult(Root.Commit(STGC_DEFAULT));
После выполнения этого кода все данные будут гарантированно сохранены в файл на диске. Ну а если вы вдруг «внезапно» передумали, можно отменить все изменения, произошедшие с предыдущего коммита, вызвав такой код:
CheckHResult(Root.Revert);
Кстати, по поводу закрытия файла.
Это делается банальным обниливанием рута, после чего при вызове @IntfClear для интерфейса в переменной Root произойдет разрушение всех остальных интерфейсов в иерархическом порядке.
Что у нас еще осталось?
Ага, еще методы CopyTo/MoveElementTo/EnumElements и прочее…
С ними разберемся чуть позже, а пока что можно открыть архив, прилагающийся к статье и посмотреть на реализацию описанного выше кода в файле "..\simple\StorageCreateDemo.dpr"
Теперь пробуем всю эту беду прочитать.
2. Чтение составного файла
Создадим новый проект, опять подключим ActiveX и AxCtrls и напишем код открытия:
var
TestFilePath: string;
WideBuff: WideString;
Root: IStorage;
begin
TestFilePath := ExtractFilePath(ParamStr(0)) + '..\data\simple.bin';
WideBuff := TestFilePath;
CheckHResult(StgOpenStorage(@WideBuff[1], nil,
STGM_READ or STGM_SHARE_DENY_WRITE, nil, 0, Root));
Так как доступ на запись нам не нужен, используем флаг STGM_READ и тут у нас есть выбор, использовать STGM_SHARE_DENY_WRITE или все же оставить STGM_SHARE_EXCLUSIVE (какой-то из двух флагов должен быть обязательно).
Результат выполнения кода — переменная Root, класса IStorage, указывающая на корень.
Как бы вы выполнили поиск файлов в указанной папке на диске?
Естественно, рекурсивным обходом каталога, используя FindFirstFile.
В данном случае у нас есть что-то похожее: это метод EnumElements интерфейса IStorage, вызов которого выглядит как-то так:
var
Enum: IEnumStatStg;
begin
CheckHResult(Storage.EnumElements(0, nil, 0, Enum));
Грубо говоря, это аналог вызова FindFirstFile, но тут мы получаем не хэндл, с которым можно работать далее, а интерфейс IEnumStatStg.
Тут есть один интересный момент, на котором стоит заострить ваше внимание.
Данный интерфейс (при его использовании) будет нам возвращать структуру TStatStg, одним из полей которой будет параметр pwcsName тип которого POleStr.
Цимус данной ситуации поняли?
Конечно же, это потенциальный мемлик, ибо OLE никоим разом не знает о существовании нашего родного менеджера памяти и выделяет блок под хранение данной строки своими собственными средствами, через интерфейс IMalloc.
Если мы не будем обрабатывать данную ситуацию — память приложения потечет как водопад Виктория, но зато будет забавно смотреть на счетчики расхода памяти. :)
Поэтому первым делом нужно получить ссылку на экземпляр данного интерфейса:
if (CoGetMalloc(1, ShellMalloc) <> S_OK) or (ShellMalloc = nil) then
raise Exception.Create('CoGetMalloc failed.');
Он нам потребуется для освобождения выделенной не нами памяти.
Примерно вот так:
ShellMalloc.Free(TmpElement.pwcsName);
Далее еще один нюанс:
Тип данных в возвращаемой TStatStg может принимать следующие значения:
- STGTY_STORAGE — это папка
- STGTY_STREAM — это файл
Все остальные варианты чисто служебные и нам не интересны.
Смотрим как это происходит:
procedure Enumerate(const Root: string; Storage: IStorage);
var
Enum: IEnumStatStg;
TmpElement: TStatStg;
ShellMalloc: IMalloc;
Fetched: Int64;
Folder: IStorage;
AFile: IStream;
begin
// т.к. работаем с OLE, сразу получим интерфейс на IMalloc
if (CoGetMalloc(1, ShellMalloc) <> S_OK) or (ShellMalloc = nil) then
raise Exception.Create('CoGetMalloc failed.');
// смотрим что нам доступно в данном сторадже
CheckHResult(Storage.EnumElements(0, nil, 0, Enum));
// перечисляем результаты до пока не упремся
Fetched := 1;
while Fetched > 0 do
if Enum.Next(1, TmpElement, @Fetched) = S_OK then
// проверочка (для подстраховки)
if ShellMalloc.DidAlloc(TmpElement.pwcsName) = 1 then
begin
// пишем что нашли
Write('Found: ', Root, '\', AnsiString(TmpElement.pwcsName));
// смотрим тип найденного
case TmpElement.dwType of
// если файл - выводим его имя и его содержимое
STGTY_STREAM:
begin
Writeln(' - file: ', sLineBreak);
CheckHResult(Storage.OpenStream(TmpElement.pwcsName, nil,
STGM_READ or STGM_SHARE_EXCLUSIVE, 0, AFile));
ShowFileData(AFile);
Writeln;
end;
// если папка - выводим ее имя и стартуем рекурсивный поиск уже в ней
STGTY_STORAGE:
begin
Writeln(' - folder');
CheckHResult(Storage.OpenStorage(TmpElement.pwcsName, nil,
STGM_READ or STGM_SHARE_EXCLUSIVE, nil, 0, Folder));
Enumerate(Root + '\' + string(TmpElement.pwcsName), Folder);
end;
else
Writeln('Unsupported type: ', TmpElement.dwType);
end;
// усе, данные нам уже не нужны - освобождаем выделенную память
ShellMalloc.Free(TmpElement.pwcsName);
end;
end;
И теперь давайте посмотрим, что получится при чтении созданного в первой главе файла:
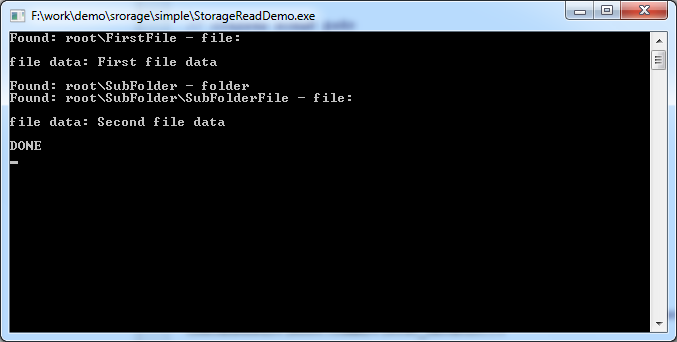
Собственно, это именно те данные, которые мы записали в первой главе.
Код данного примера в архиве к статье, по следующему пути "..\simple\StorageReadDemo.dpr"
А теперь посмотрим, как с этим работать немного удобнее.
3. Класс-обертка
В свое время мной был разработан небольшой модуль (тысяча строчек с комментариями), в котором реализовано несколько классов, учитывающих все нюансы работы с составными файлами и предоставляющих более удобный механизм работы.
Его вы сможете найти в архиве, в папке "..\StorageReader\FWStorage.pas".
В нем есть несколько недочетов. Дело в том, что я забросил его разработку очень давно, поэтому на юникодных версиях Delphi он будет выдавать ворнинги связанные с работой со строками.
[dcc32 Warning] FWStorage.pas(860): W1057 Implicit string cast from 'AnsiString' to 'string'
[dcc32 Warning] uStgReader.pas(102): W1057 Implicit string cast from 'ShortString' to 'string'
Но при этом он вполне функционален и эти ворнинги никак не скажутся на его работоспособности. (Если честно — лень причесывать еще и их).
Данный модуль вы можете использовать по своему усмотрению со следующими оговорками.
Если вы вдруг будете изменять код классов (добавлять рюшечки, править ошибки, если найдете), и потом выкладывать его в интернет, имя автора модуля должно быть сохранено в заголовке.
Я данный модуль уже не сопровождаю (он для меня устарел), поэтому просьбы о его доработке я буду отклонять сразу.
Итак, из данного модуля нас интересует класс TFWStorage, при помощи которого ведется работа с составным файлом, и класс TFWStorageCursor, который является оберткой над IStorage.
Для начала перечислю методы этих классов, а потом дам пример работы с ними.
Итак, класс TFWStorage, он предназначен только для работы с файлом и предоставляет несколько утилитарных методов:
- OpenFile, OpenFileReadOnly — ну тут все понятно, просто открываем составной файл. Оба метода создают и возвращают класс TFWStorageCursor указывающий на корневую директорию файла.
- CloseFile — соответственно закрываем открытый ранее файл.
- ReConnect — переоткрываем открытый ранее файл. Также возвращает TFWStorageCursor.
- Compress — сжимает указанный файл, убирая фрагментированные блоки. Сжимаемый файл не должен быть открыт.
- IsStgValidBinaryFmt — проверяет, все ли в порядке с указанным файлом и не разрушена ли его структура. Указанный файл не должен быть открыт.
- ForceStorage — создает или открывает папку внутри составного файла по указанному пути. Путь должен быть указан от корня, в качестве разделителя используется "\". Пример: «путь к файлу\Subfolder1\subfolder2\subsubfolder». Возвращает TFWStorageCursor.
Т.е. в принципе основная его задача отдать нам экземпляр класса TFWStorageCursor, при помощи которого и будет происходить основная работа с составным файлом.
Методы у него следующие:
- CreateStorage — создает новую папку внутри текущей и возвращает TFWStorageCursor, указывающий на вновь созданную папку.
- OpenStorage — открывает папку внутри текущей. Возвращает TFWStorageCursor, указывающий на открытую папку.
- DeleteStorage — удаляет указанную папку внутри текущей.
- Copy — копирует указанный файл или папку из текущей папки в другую. Папка, в которую производится копирование, передается в виде класса TFWStorageCursor.
- MoveTo — аналогично методу Copy, только копируемый элемент удаляется из текущей папки.
- CreateStream — создает пустой файл в текущей папке.
- ReadStream — читает содержимое указанного файла.
- WriteStream — пишет новые данные в файл. Если файла с таким именем не существует — создает его.
- DeleteStream — удаляет файл в текущей папке.
- FlushBuffer — сохраняет изменения.
- Rename — переименовывает указанный файл или папку в текущей папке.
- Enumerate — перечисляет содержимое текущей папки и возвращает результат в виде массива TFWStorageEnum.
- Backward — возвращает ссылку на родительскую папку, причем сам разрушается (если только не Root).
- Release — разрушает текущий класс.
- IsRoot — показывает, указывает ли текущий класс на корневую папку составного файла.
- GetName — возвращает имя текущей папки.
- Path — возвращает путь к текущей папке.
- Storages — список всех дочерних подпапок.
Как видите, обертки над IStream нет, работа с этим интерфейсом возложена на методы CreateStream, ReadStream, WriteStream.
В массиве TFWStorageEnum, который возвращает метод Enumerate, не нужно освобождать память, выделенную под pacsName, это уже сделано, и вы работаете с копией данных, которые хранятся в памяти, выделенной родным менеджером памяти.
Единственный вопрос может вызвать метод Backward, как так — почему он разрушает сам себя?
А сейчас покажу, это действительно удобно.
Вот, к примеру, если бы нам нужно было открыть такой путь: «путь к файлу\Subfolder1\subfolder2\subsubfolder», что нужно было сделать при использовании обычных интерфейсов из второй главы:
Открыть сам файл и получить интерфейс IStorage указывающий на корень, потом получить IStorage для первой папки, потом для второй и для третьей, которая «subsubfolder» тоже нужно.
Это целых 4 элемента, которые нужно где-то хранить.
При использовании TFWStorage все становится гораздо проще:
procedure TForm1.Button1Click(Sender: TObject);
var
Path: string;
Storage: TFWStorage;
Root, Folder: TFWStorageCursor;
Data: TStringStream;
begin
Storage := TFWStorage.Create;
try
// запоминаем путь к файлу
Path := ExpandFileName(ExtractFilePath(ParamStr(0)) + '..\data\test.bin');
// открываем составной файл
Storage.OpenFile(Path, True, Root);
// создаем в нем три вложенных друг в друга папки
Storage.ForceStorage(Path + '\Subfolder1\subloder2\subsubfolder', Folder);
Data := TStringStream.Create;
try
// это будут данные для файла
Data.WriteString('new file data.');
// пока не вышли на рут в каждой из папок создаем по файлу
while Folder <> Root do
begin
Folder.WriteStream(Folder.GetName + '_new_file.txt', Data);
// получаем ссылку на папку уровнем выше
Folder.Backward(Folder);
end;
// сохраняем изменения
Root.FlushBuffer;
finally
Data.Free;
end;
finally
Storage.Free;
end;
end;
Вот и все, с точки зрения программирования получилось очень удобно.
Ну а теперь напишем что-то более серьезное, а именно редактор содержимого составного файла.
Откройте новый проект и создайте в нем примерно такую форму:
private
FCurrentFileName: string;
FStorage: TFWStorage;
FRoot: TFWStorageCursor;
procedure TForm1.FormCreate(Sender: TObject);
begin
// указываем текущее имя файла
FCurrentFileName :=
ExpandFileName(ExtractFilePath(ParamStr(0)) + '..\data\simple.bin');
// создаем хранилище
FStorage := TFWStorage.Create;
// открываем файл
OpenFile(False);
end;
Теперь пишем саму процедуру открытия файла, она простая:
procedure TForm1.OpenFile(CreateNew: Boolean);
begin
// закрываем файл, если он был открыт ранее
FStorage.CloseFile;
// открываем новый файл
FStorage.OpenFile(FCurrentFileName,
CreateNew or not FileExists(FCurrentFileName), FRoot);
Caption := FCurrentFileName;
// ну и выводим содержимое его корня
ShowStorageData(FRoot);
end;
Пока все просто, да? В принципе и весь остальной код будет простеньким.
Теперь пишем процедуру вывода содержимого папки на экран:
procedure TForm1.ShowStorageData(AStorage: TFWStorageCursor);
procedure AddItem(const ACaption: string; AIndex: Integer);
begin
with ListView1.Items.Add do
begin
Caption := ACaption;
case AIndex of
-1: ImageIndex := -1;
1:
begin
ImageIndex := 0;
SubItems.Add('Folder');
end
else
ImageIndex := 1;
SubItems.Add('File');
end;
// тип элемента сохраняем в поле Data, где:
// -1 - переход на уровень выше
// 0 - файл
// 1 - папка
// потом будем ориентироваться на это поле
Data := Pointer(AIndex);
end;
end;
var
AData: TFWStorageEnum;
I: Integer;
begin
ListView1.Items.BeginUpdate;
try
ListView1.Items.Clear;
// выводим пункт, через который мы будем переходить на папку выше
// (для корневой директории - избыточно)
if not AStorage.IsRoot then
AddItem('..', -1);
// перечисляем все содержимое папки
AStorage.Enumerate(AData);
// и последовательно выводим в ListView
for I := 0 to AData.Count - 1 do
AddItem(
string(AData.ElementEnum[I].pacsName),
Byte(AData.ElementEnum[I].dwType = STGTY_STORAGE));
finally
ListView1.Items.EndUpdate;
end;
end;
Если все сделали правильно, то запускайте проект, при этом откроется файл "..\data\simple.bin" который мы создавали в первой главе и все должно выглядеть как-то так:

Теперь сделаем навигацию по нашему хранилищу.
Логика ее будет простая:
- двойной клик по папке — открываем папку и показываем ее содержимое.
- двойной клик по файлу — открываем редактор содержимого файла.
- двойной клик по элементу ".." — переходим на уровень выше.
Для этого в обработчике события OnDblClick у ListView пишем такой код:
procedure TForm1.ListView1DblClick(Sender: TObject);
begin
// если элемент не выбран - выходим
if ListView1.Selected = nil then Exit;
// ориентируемся на поле Data выбранного элемента
case Integer(ListView1.Selected.Data) of
-1: // переход на уровень выше
begin
// получаем ссылку на папку уровнем выше
FRoot.Backward(FRoot);
// показываем ее содержимое
ShowStorageData(FRoot);
end;
0: // редактируем файл
EditFile;
1: // открываем папку
begin
// получаем ссылку на выбранную папку
FRoot.OpenStorage(AnsiString(ListView1.Selected.Caption), FRoot);
// показываем ее содержимое
ShowStorageData(FRoot);
end;
end;
end;
Вот теперь можно походить по нашему хранилищу двойными кликами. :)
Редактирование файла сделаем следующим образом. Подключим к проекту новую форму, добавим на нее кнопку сохранения и кнопку отмены, а также TMemo в котором будет выводиться содержимое файла, после чего напишем такой код:
procedure TForm1.EditFile;
var
Buff: TMemoryStream;
Data: AnsiString;
begin
Buff := TMemoryStream.Create;
try
// читаем содержимое файла
FRoot.ReadStream(AnsiString(ListView1.Selected.Caption), Buff);
// перекидываем его в строку
if Buff.Size > 0 then
begin
SetLength(Data, Buff.Size);
Buff.Read(Data[1], Buff.Size);
end;
// создаем окно редактора
frmEdit := TfrmEdit.Create(Self);
try
// передаем в Memo зачитанный текст
frmEdit.Memo1.Text := string(Data);
// отображаем диалог
if frmEdit.ShowModal <> mrOk then Exit;
// читаем содержимое из Memo
Buff.Clear;
Data := AnsiString(frmEdit.Memo1.Text);
if Length(Data) > 0 then
Buff.Write(Data[1], Length(Data));
// пишем его обратно
FRoot.WriteStream(AnsiString(ListView1.Selected.Caption), Buff);
// и сохраняем изменения
FRoot.FlushBuffer;
finally
frmEdit.Release;
end;
finally
Buff.Free;
end;
end;
Ну, вот у нас практически полноценный редактор, осталось добавить функционал для кнопок сверху формы.
procedure TForm1.btnCreateDFaseClick(Sender: TObject);
begin
if SaveDialog1.Execute then
begin
FCurrentFileName := SaveDialog1.FileName;
OpenFile(True);
end;
end;
procedure TForm1.btnOpenDBaseClick(Sender: TObject);
begin
if OpenDialog1.Execute then
begin
FCurrentFileName := OpenDialog1.FileName;
OpenFile(False);
end;
end;
procedure TForm1.btnAddFolderClick(Sender: TObject);
var
NewFolderName: string;
Tmp: TFWStorageCursor;
begin
if InputQuery('New folder', 'Enter folder name', NewFolderName) then
begin
FRoot.CreateStorage(AnsiString(NewFolderName), Tmp);
FRoot.FlushBuffer;
end;
ShowStorageData(FRoot);
end;
procedure TForm1.btnDelFolderClick(Sender: TObject);
begin
if Application.MessageBox(
PChar(Format('Delete folder: "%s"?', [ListView1.Selected.Caption])),
'Delete folder', MB_ICONQUESTION or MB_YESNO) = ID_YES then
begin
FRoot.DeleteStorage(AnsiString(ListView1.Selected.Caption));
FRoot.FlushBuffer;
ShowStorageData(FRoot);
end;
end;
procedure TForm1.btnAddFileClick(Sender: TObject);
var
NewFileName: string;
begin
if InputQuery('New file', 'Enter file name', NewFileName) then
begin
FRoot.CreateStream(AnsiString(NewFileName));
FRoot.FlushBuffer;
end;
ShowStorageData(FRoot);
end;
procedure TForm1.btnDelFileClick(Sender: TObject);
begin
if Application.MessageBox(
PChar(Format('Delete file: "%s"?', [ListView1.Selected.Caption])),
'Delete file', MB_ICONQUESTION or MB_YESNO) = ID_YES then
begin
FRoot.DeleteStream(AnsiString(ListView1.Selected.Caption));
FRoot.FlushBuffer;
ShowStorageData(FRoot);
end;
end;
Ну вот и все, проще по моему уже некуда :)
Теперь можно посмотреть, а что-же хранится внутри DOC файла? :)
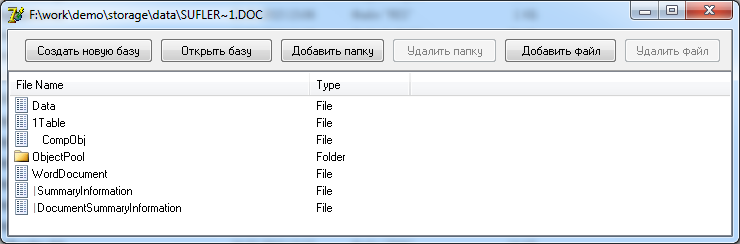
На этом, пожалуй, остановимся и перейдем к описанию различных неприятностей, которые может доставить нам составной файл, а исходный код данного примера вы можете забрать в архиве, по следующему пути: "..\StorageReader\"
4. Минусы Compound File
Так уж получилось, что при всех своих плюсах, составной файл обладает целым рядом существенных минусов, с которыми вы можете столкнуться при работе.
Самый первый минус — ограничение на размер имен для файлов и папок.
Здесь я сделаю небольшое отступление и расскажу вам небольшую историю из собственной практики.
Двенадцатый год я разрабатываю ПО для сметчиков — сметы делаем.
Но у них все хитро, нельзя просто так взять и создать смету. :))
Для начала должна быть указана стройка, у стройки должен быть перечень объектов строительства, а уже непосредственно объекты строительства содержат в себе сметы.
Эта иерархия жесткая, причем есть несколько вариантов, к примеру:
- Стройка > Объект > Смета
- Стройка > Очередь > Объект > Смета
- Группа строек > Стройка > Очередь > Объект > Смета
По факту все эти стройки объекты и прочее (кроме смет) являются не более чем объектами иерархии — по сути папки, но эти папки должны идти в строго определенном порядке, иначе все сломается.
Если представить что мы сделаем эту иерархию при помощи средств файловой системы, а тип папки (к какому уровню иерархии она принадлежит «стройка/объект/очередь») реализуем, к примеру, обычным INI файлом в ее корне (а-ля thumbs.db), то что нам делать с пользователем, у которого излишне шаловливые ручки, который может прямо в проводнике порушить всю эту структуру?
Вот именно из этих соображений много лет назад нами и был выбран составной файл как хранилище данных, в который пользователь не сможет влезть и поломать там все.
Используя этот формат хранения, мы можем контролировать нужную иерархию создания папок и не дать пользователю выстрелить себе в ногу.
Однако вылез нюанс: создавая новую смету в нашем ПО, пользователь почему то старается в названии сметы отобразить полную информацию о том, что она осмечивает.
К примеру: «Капитальный ремонт пути на старогодних материалах. Участок Селэгвож-Чим, 1путь, 142 пк1 — 163 пк10, протяженность 22, 0км».
Вспоминаем — ограничение на длину имени файла у нас всего 31 символ, а это в крайнем случае: «Капитальный ремонт пути на стар».
Нет, чтобы назвать: «Ремонт путёв».
И естественно пользователь страшно обидится, если мы зарежем его имя файла по длине пути, поэтому пришлось что-то с этим делать.
Нами была реализована следующая схема хранения данных:
Что виртуальная папка, что виртуальный файл (виртуальный — отображаемый нашим ПО), в данной схеме на самом деле представлял из себя обычную папку в составном файле. Внутри этой папки лежал файлик «Properties», в котором описывался тип данных с которым мы работаем (если это папка, то, к какому типу в иерархии она принадлежит) а также отображаемое нашим ПО имя (причем ограничение на длину мы сделали аж в 1024 байта — не пожадничали, и с этим будет связана еще одна проблема, на которой я остановлюсь в самом конце).
Если вдруг папка внутри хранилища являлась файлом — то в ней размещался еще один файлик — «Data», где и хранилось содержимое самой сметы.
А выводилось это все пользователю в нормальном виде:
Спросите, что мы использовали в качестве имен физических папок в данном случае?
Да банальные усеченные GUID в строковом представлении с небольшой «эквилибристикой» чтобы их можно было впихнуть в пресловутые 31 байт имени папки. :)
Да и ладно бы с этими 31 байтами имени, через какое-то время работы с данным форматом мы вышли на очередной неприятный минус.
Вот задумайтесь, понравилось бы вам что ваше ПО может запускаться не меньше 5 минут?
Да-да, я не ошибся, ровно 5 минут, а не секунд. Можно сходить попить чай, пиццу заказать, да и вообще отличное начало дня — ждем старта твоего рабочего инструмента. :)
Есть у нас такие клиенты, называются «Проектные Институты» — их много по всей России и там работает огромное количество сметчиков. Они все профи и поэтому работают просто с «ОГРОМЕННЕЙШИМ» набором смет постоянно — работа такая.
И вот однажды нам пришел багрепорт примерно такого плана: «Ребят, мы уже устали ждать запуска вашего ПО, да что ж такое каждый день?».
А часть таких контор еще и работает с данными, которые нельзя отдавать на сторону (осмечивают некоторые госструктуры), поэтому мы никак не могли понять — откуда тормоза то такие дикие лезут?!!!
Но однажды повезло, данные были не секретные и нам их предоставили.
И вот, лежит у меня в папке почти 2 гигабайтный файлик с примерно 200 тысячами смет на борту (твою дивизию). Я конечно офигел от такого объема, но…
Но действительно — хочешь не хочешь, файл такого размера быстрее, чем за пять минут просто не открылся (в следующей главе поймете почему).
Начали тестировать скорость, и опытным путем было установлено: пользователю будет не комфортно работать на объеме составного файла размером уже в 50 мегабайт, ибо проявятся достаточно сильные задержки по две/три секунды на открытии.
Тесты, конечно, тестами, но делать то что-то надо.
В кратчайшие сроки была реализована сетевая служба, работающая с данными, которые хранились уже не в составном файле, а в базе. Причем, сразу добавили поддержку как банального Firebird/Interbase, так и баз посерьезней — MS SQL/Olracle, и до кучи прикрутили ADO. Еще была написана небольшая утилита, которая конвертировала данные из составного файла в базу.
Тестируем — летает, мама не горюй, но есть нюанс.
Нельзя просто так взять и прокинуть все данные из двухгигового файла в базу.
В какой-то момент, при открытии очередной папки посредством OpenStorage, может произойти ошибка открытия, причем в этом случае дальше трепыхаться уже не стоит — любой вызов будет заканчиваться ошибкой.
Вот именно для таких целей в TFWStorage и были добавлены два метода: ReConnect — посредством которого можно переоткрыть составной файл и метод ForceStorage, посредством которого можно сразу открыть ту папку, на которой произошла ошибка.
Впрочем: на тот момент времени мы еще недостаточно набили шишек и использовали составной файл в еще одном нашем продукте. Этот проект был информационно справочной системой (ИСС) предоставляющий сметчику доступ к необходимой для него документации (скажем — местячковый аналог MSDN).
И вот настает момент, ко мне приходит наш технарь, ответственный за наполнение базы и говорит: «база не открывается, я не могу выпустить очередное обновление».
Начинаю проверять.
Да действительно, база, представляющая из себя тотже составной файл с добавленными в него всеми данными не открывается прямо на этапе вызова StgOpenStorage.
Приплыли…
Смотрю размер — что-то в районе 4 гигов, но еще не вылезли за лимит.
Методом проб и ошибок выяснили, что похоже дело с нехваткой памяти на этапе открытия файла. Победили переходом на другой формат хранения.
Кстати, если спросите о времени открытия такого файла — да он открывался за достаточно солидное время, но (как я говорил ранее) — это практически полноценный MSDN для сметчиков и выполнен он был в виде сервиса, постоянно работающего на выделенном сервере. Люди туда стучались по сетке, так что в данном случае это был не сильно принципиальный момент.
Кстати, натыкался еще на такой интересный глюк:
К примеру мы хотим что-то записать в файл(стрим) и пробуем узнать — существует ли такой вообще, вызовом EnumElements. А IEnumStatStg, возвращаемый данным вызовом не видит такого стрима. После чего мы делаем вызов CreateStream с целью создать его, но нам приходит ошибка.
В данном случае обойти этот момент довольно просто. Достаточно вызвать DestroyElement для данного стрима и создать его заново вызовом CreateStream, но это уже офигенный такой звонок: «что-то с нашим составным файлом совсем беда».
А раз с ним вообще очень плохо, то нам нужно научиться вытаскивать из него данные, которые нам еще доступны.
5. Читаем данные в RAW режиме
Я думаю, у вас сейчас сложилось такое мнение: Ну, нифига себе, сколько проблем будет при использовании составных файлов? Зачем автор вообще тогда о них рассказывает?
Это не правильное мнение. Я могу накидать целый ворох ошибок по различным используемым сейчас технологиям, но это не означает что та или иная, изначально была провальна.
К примеру, если бы вы знали что можно сделать принципиально неудаляемую папку в файловой системе NTFS прямо из третьего кольца и без сильных времязатрат, просто некорректными параметрами вызова соответствующего API — вы же не отказались бы от использования файловой системы? :)
А составные файлы действительно хороши, но их нужно просто научиться правильно готовить.
Вообще сейчас хорошее время, MS публикует описание своих технологиий в открытом виде, а когда я начинал работать с данным форматом мне было доступно только описание формата из явовского POIFS, небольшая выдержка из Wiki да еще один файлик с более подробным описанием по структуре POIFS (в частности по министримам), но я его сейчас уже не могу найти (столько лет прошло).
Вот почему они открыли формат не тогда, когда мне это было нужно? :)
Поэтому пришлось все ковырять самому.
Смотрим, что из себя представляет составной файл, а именно его заголовок:
TPoifsFileHeader = packed record
// Идентификатор. Всегда постоянная (0 x E011CFD0, 0 x E11AB1A1)
_abSig: array [0..7] of Byte;
// Class ID. Устанавливается WriteClassStg, считывается GetClassFile/ReadClassStg.
// Для Excel как правило = 0
_clid: TGUID;
// Младшее значение версии формата.
_uMinorVersion: USHORT;
// Старшее значение версии Dll/формата
_uDllVersion: USHORT;
// 0 x FFFE говорит, что используется Intel нотация
_uByteOrder: USHORT;
// Размер сектора. Обычно равно 9, что указывает на размер 512 байт (2 ^ 9)
_uSectorShift: USHORT;
// Размер мини-сектора. Обычно равно 6, что указывает на размер 64 байт (2 ^ 6)
_uMiniSectorShift: USHORT;
// Зарезервировано, должно быть равно 0
_usReserved: USHORT;
// Зарезервировано, должно быть равно 0
_ulReserved1: ULONG;
// Зарезервировано, должно быть равно 0
_ulReserved2: ULONG;
// Число секторов, в которых размещается FAT.
// Если файл менее 7Мб, то равно 1, если больше, то больше 1 и появляется DIF сектор.
_csectFat: ULONG;
// Номер первого сектора, в котором размещается Property Set Storage
// (еще называют FAT Directory или Root Directory Entry)
_sectDirStart: ULONG;
// Подпись для транзакций.
_signature: ULONG;
// Максимальный размер мини-потока. Обычно 4096
_ulMiniSectorCutoff: ULONG;
// Первый сектор мини-FAT.
// Если (-2), то мини-поток отсутствует.
_sectMiniFatStart: ULONG;
// Число секторов в цепочке мини-FAT. 0, если мини-потока нет
_csectMiniFat: ULONG;
// Первый сектор в DIF цепочке.
// Если файл менее 7Мб, то DIF цепочка отсутствует и значение равно (-2)
_sectDifStart: ULONG;
// число секторов в DIF цепочке.0, если файл < 7Мб
_csectDif: ULONG;
// Номера первых 109 секторов, в которых располагается FAT.
// Если файл менее 7Мб, то сектор один, остальные значение заполняются (-1).
_sectFat: array [0..108] of ULONG;
end;
Ну, тут думаю все понятно, все каменты проставлены — эту структуру нам нужно считать в самом начале.
Единственный момент, в полях _uSectorShift и _uMiniSectorShift записаны степени двойки, значит, нужно их привести к нормальному виду.
procedure TPoifsFile.InitHeader;
begin
FStream.ReadBuffer(FHeader, SizeOf(TPoifsFileHeader));
FHeader._uSectorShift := Round(IntPower(2, FHeader._uSectorShift));
FHeader._uMiniSectorShift := Round(IntPower(2, FHeader._uMiniSectorShift));
end;
procedure TPoifsFile.ComposeFAT;
var
I, J, X, FatLength: Integer;
FatBlock: TPoifsFatBlock;
CurrentFat, Offset: Integer;
XFat: array of Integer;
begin
// рассчитываем кол-во элементов FAT (идут блоками по 128 записей)
// если нет DIF сектора, то _csectFat равен единице
FatLength := FHeader._csectFat * 128;
// выделяем память под значение ячеек FAT
SetLength(FFat, FatLength);
// и оффсеты на их значения в файле
SetLength(FFatOffset, FatLength);
// если есть DIF сектор, то FAT располагается только в первых 109 полях
// остальные данные лежат в DIF секторе
for I := 0 to IfThen(FHeader._csectDif > 0, 108, FHeader._csectFat - 1) do
begin
// читаем FAT структуру кусками по 128 записей
FatBlock := TPoifsFatBlock(GetBlock(FHeader._sectFat[I]));
for J := 0 to 127 do
begin
FFat[I * 128 + J] := FatBlock[J];
// не забываем про оффсет каждого блока в файле, пригодится
FFatOffset[I * 128 + J] := FStream.Position - SizeOf(TPoifsBlock);
end;
end;
// смотрим, есть ли DIF сектор
if FHeader._sectDifStart = 0 then Exit;
// если есть, значит надо читать оставшиеся блоки FAT из него
Offset := FHeader._sectDifStart;
// подготавливаем массив XFAT для хранения оффсетов на FAT блоки
SetLength(XFat, 128);
// запоминаем индекс последнего заполненного FAT блока
CurrentFat := 13951; //109 * 128 - 1 BAT
for X := 0 to FHeader._csectDif - 1 do
begin
// ориентируясь на размер сектора (параметр _uSectorShift из заголовка)
// рассчитываем позицию в файле
FStream.Position := GetBlockOffset(Offset);
// читаем смещения оставшихся FAT блоков
FStream.ReadBuffer(XFat[0], 128 * SizeOf(DWORD));
// в самом конце блока оффсетоф
// содержится смещение на начало следующего блока офсетоф
// поэтому крутим цикл без учета последнего блока
for I := 0 to 126 do
begin
// не забываем проверять текущий оффсет, если он отрицателен,
// блоков FAT больше нет
if XFat[I] < 0 then Exit;
// читаем FAT структуру кусками по 128 записей
FatBlock := TPoifsFatBlock(GetBlock(XFat[I]));
for J := 0 to 127 do
begin
Inc(CurrentFat);
FFat[CurrentFat] := FatBlock[J];
FFatOffset[CurrentFat] := FStream.Position - SizeOf(TPoifsBlock);
end;
end;
// новый оффсет берем из последнего элемента
Offset := XFat[127];
end;
end;
Здесь используется структура TPoifsFatBlock, это просто массив из 128 Integer.
А так же функции GetBlockOffset и GetBlock.
function TPoifsFile.GetBlockOffset(BlockIndex: Integer): Int64;
begin
Result := HEADER_SIZE + FHeader._uSectorShift * BlockIndex;
end;
function TPoifsFile.GetBlock(Adress: Integer): TPoifsBlock;
begin
FStream.Position := GetBlockOffset(Adress);
FStream.ReadBuffer(Result, SizeOf(TPoifsBlock));
end;
Следующим этапом нужно считать минифат, хранящий данные о файлах, размер которых меньше значению поля _ulMiniSectorCutoff.
procedure TPoifsFile.ComposeMiniFat;
var
I, CurrChain: Integer;
TmpPosition: int64;
begin
// запоминаем номер первого сектора цепочки блоков минифата
CurrChain := FHeader._sectMiniFatStart;
// выделяем под него память (так-же идет блоками по 128 элементов)
SetLength(FMiniFat, FHeader._csectMiniFat * 128);
I := 0;
while Integer(CurrChain) >= 0 do
begin
// смотрим оффсет сектора
TmpPosition := GetBlockOffset(CurrChain);
// если отрицательный, значит цепочка закончилась
if TmpPosition < 0 then Exit;
//if TmpPosition > FStream.Size then Exit;
FStream.Position := TmpPosition;
// читаем смещения
FStream.ReadBuffer(FMiniFat[I], 512 {128 * SizeOf(DWORD)});
Inc(I, 128);
// индекс нового сектора читаем из FAT
CurrChain := FFat[CurrChain];
end;
end;
Последним этапом нужно зачитать свойства всех файлов и папок.
Они будут храниться в массиве вот таких структур:
TPoifsProperty = packed record // 128 length
// имя файла/папки
Caption: array[0..31] of WChar;
// размер имени
CaptionSize: Word;
// тип элемента STGTY_ХХХ
PropertyType: Byte;
// цвет узла (массив TPoifsProperty представляет из себя Red-Black-Tree)
NodeColor: Byte; // 0 (red) or 1 (black)
// номер предыдущего блока в массиве
PreviousProp: Integer;
// номер следующего блока в массиве
NextProp: Integer;
// номер дочернего блока в массиве
ChildProp: Integer;
Reserved1: TGUID;
UserFlags: DWORD;
// время
ATime: array [0..1] of Int64;
// номер ячейки FAT указывающей на начало блока данных для файла
StartBlock: Integer;
// размер файла
Size: Integer;
Reserved2: DWORD;
end;
TPoifsPropsBlock = array[0..3] of TPoifsProperty;
function TPoifsFile.ReadPropsArray: Boolean;
var
I, J, Len: Integer;
PropsBlock: TPoifsPropsBlock;
begin
Result := True;
// инициализируем размер массива свойств
Len := 0;
// запоминаем номер первого сектора, в котором размещается Property Set Storage
J := FHeader._sectDirStart;
repeat
// читаем свойства блоками по 4 элемента
Inc(Len, 4);
SetLength(FPropsArray, Len);
PropsBlock := TPoifsPropsBlock(GetBlock(J));
for I := 0 to 3 do
FPropsArray[Len - 4 + I] := PropsBlock[I];
// читаем номер следующего сектора из FAT
J := FFat[J];
until J = ENDOFCHAIN;
end;
После этого у нас будет на руках:
- массив значений FAT, каждое из которых содержит в себе номер секции с данными.
- массив смещений на данные в файле
- массив значений MiniFAT
- массив свойств всех файлов
Что есть FAT и MiniFAT?
Грубо говоря составной файл представляет собой заголовок и массив секторов данных размером FHeader._uSectorShift, в которых лежит все остальное.
FAT содержит в себе порядок хранения данных в этих секторах (как содержимого файлов, так и сугубо служебных блоков не доступных пользователю).
К примеру, есть у нас файл размером 1 мегабайт, под него выделится ровно 2048 секторов, каждый из которых будет размером в 512 байт (по умолчанию).
Из-за фрагментации данные этого файла не всегда будут идти последовательно и, вполне возможна такая ситуация, что первые 10 секторов будут содержать в себе конец файла, а оставшиеся — его начало.
Чтобы понять, что за чем идет (порядок последовательности) нужно обратится к FAT и полю StartBlock из структуры TPoifsProperty, скомбинировав значения которых мы поймем, какой сектор содержит начало блока данных, а где его продолжение (просто пробежавшись по цепочке FAT).
Причем с минифатом будет все гораздо интереснее, там придется еще делать некоторые манипуляции, но об этом чуть попозже.
Впрочем, я немного отвлекся.
Для начала нужно решить другую задачу. Все элементы, представленные в массиве TPoifsProperty, связаны друг с другом посредством полей PreviousProp, NextProp и ChildProp, а также NodeColor. Классическое Red-Black-Tree.
Нам нужно из него построить стандартное дерево, восстановив структуру папок и файлов.
А вот когда мы ее построим, тогда и можно вытащить все данные из файла с сохранением их структуры.
Создадим новый проект, примерно вот такой:
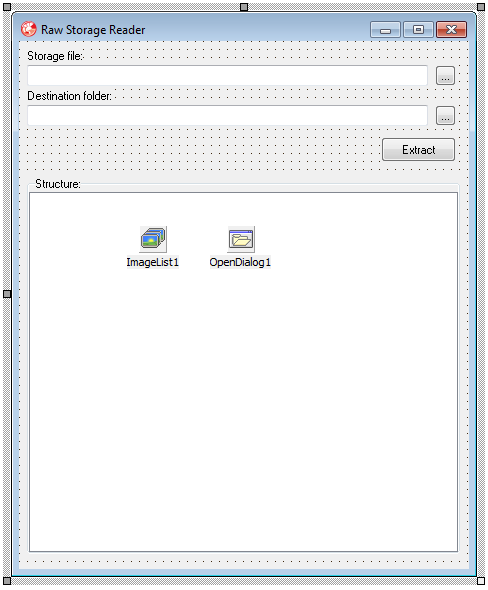
Суть его будет заключаться в следующем: из указанного составного файла он будет извлекать структуру файлов и папок (отобразив ее в TreeView), после чего воспроизведет такую же иерархию папок в указанной директории и вытащит туда же данные всех файлов из хранилища.
Сделаем это в пять этапов, которые наглядно видны в обработчике кнопки Extract:
begin
FileStream := TFileStream.Create(edSrc.Text, fmOpenReadWrite);
try
AFile := TPoifsFile.Create(FileStream);
try
// читаем данные из составного файла
AFile.LoadFromStream;
ATree := TStorageTree.Create;
try
// Заполняем узлы
for I := 0 to AFile.PropertiesCount - 1 do
ATree.AddNode(I).Data := AFile[I];
// строим перекрестные ссылки
FillAllChilds(0, ATree.GetNode(0).Data.ChildProp);
// выводим ввиде дерева
TreeView1.Items.Clear;
FillTree(nil, 0);
// извлекаем все данные
DebugLog := TStringList.Create;
try
Extract(IncludeTrailingPathDelimiter(edDst.Text), 0);
if DebugLog.Count > 0 then
DebugLog.SaveToFile(IncludeTrailingPathDelimiter(edDst.Text) + 'cannotread.log');
finally
DebugLog.Free;
end;
finally
ATree.Free;
end;
finally
AFile.Free;
end;
finally
FileStream.Free;
end;
end;
Первый этап (чтение данных из файла) у нас уже реализован.
Перейдем ко второму и третьему.
Я не стал сильно мудрить и для восстановления структуры дерева взял за основу решения граф.
Идея простая, сначала добавим N узлов к графу, где каждый узел будет отвечать за один из элементов массива TPoifsProperty (собственно это видно в коде, блок «заполняем узлы»).
А следующим шагом нужно построить между узлами перекрестные ссылки, кто и на что ссылается.
Вообще само дерево строится достаточно просто, главное придерживаться нескольких простых правил:
- TPoifsProperty.ChildProp — всегда указывает на первый дочерний элемент в папке (заполнено только у папок)
- TPoifsProperty.PreviousProp — указывает на предыдущий элемент в рамках текущей папки.
- TPoifsProperty.NextProp — указывает на следующий элемент в рамках текущей папки.
Чтобы было нагляднее вот вам картинка:

Стрелка вниз, это ChildProp, вправо — NextProp, влево — PreviousProp.
В итоге сразу становится понятно, что в корне составного файла расположены два файла и одна папка, внутри которой размещены еще три файла.
var
ATree: TStorageTree;
...
procedure FillAllChilds(RootIndex, CurrentIndex: Integer);
var
SubChildIndex: Integer;
RootNode, CurrNode, ChildNode: TStorageElement;
begin
if CurrentIndex < 0 then Exit;
// получаем ссылку на рутовый узел
RootNode := ATree.GetNode(RootIndex);
// получаем ссылку на добавляемый в него узел
CurrNode := ATree.GetNode(CurrentIndex);
if CurrNode = nil then Exit;
// если узел уже обработан - выходим
if CurrNode.Added then Exit;
CurrNode.Added := True;
// добавляем ссылку на него от рута
ATree.AddVector(RootNode, CurrNode);
// и у вновь добавленного вызываем добавление его чайлдов
FillAllChilds(CurrNode.ID, CurrNode.Data.ChildProp);
// теперь смотрим есть ли перед добавленным узлом еще элементы
SubChildIndex := CurrNode.Data.PreviousProp;
while SubChildIndex >= 0 do
begin
// если есть, добавляем их к руту
FillAllChilds(RootIndex, SubChildIndex);
ChildNode := ATree.GetNode(SubChildIndex);
if ChildNode <> nil then
SubChildIndex := ChildNode.Data.PreviousProp
else
SubChildIndex := -1;
end;
// то же самое делаем со всеми элементами, которые идут после текущего узла
SubChildIndex := CurrNode.Data.NextProp;
while SubChildIndex >= 0 do
begin
FillAllChilds(RootIndex, SubChildIndex);
ChildNode := ATree.GetNode(SubChildIndex);
if ChildNode <> nil then
SubChildIndex := ChildNode.Data.NextProp
else
SubChildIndex := -1;
end;
end;
Реализацию класса графа, представленного классом TStorageTree я рассматривать не буду, так как она не относится к теме статьи, код данного класса потом увидите в исходниках.
Сейчас достаточно знать, что у него есть метод GetNode, возвращающий узел графа по его индексу (у которого есть ссылка на элемент массива TPoifsProperty, контролируемый им через свойство Data) и метод AddVector, создающий ссылку между двумя узлами графа.
procedure FillTree(Node: TTreeNode; RootNodeIndex: Integer);
var
W: WideString;
TreeNode: TTreeNode;
I: Integer;
RootStorageNode, ChildStorageNode: TStorageElement;
begin
// получаем узел графа
RootStorageNode := ATree.GetNode(RootNodeIndex);
// добавляем его в дерево (назначаем имя и иконку)
W := RootStorageNode.Data.Caption;
TreeNode := TreeView1.Items.AddChildFirst(Node, W);
case RootStorageNode.Data.PropertyType of
STGTY_STORAGE: TreeNode.ImageIndex := 0;
STGTY_STREAM: TreeNode.ImageIndex := 1;
end;
// бежим по ссылкам от узла
for I := 0 to RootStorageNode.VectorCount - 1 do
begin
// смотрим, есть ли линк на дочерний узел (а вдруг мы папка?)
ChildStorageNode := TStorageElement(RootStorageNode.GetVector(I).SlaveNode);
if ChildStorageNode = nil then
Continue;
// если есть ссылка, и ссылка не на папку выше, то пускаем рекурсию
if ChildStorageNode.ID <> RootNodeIndex then
FillTree(TreeNode, ChildStorageNode.ID);
end;
end;
Банальная рекурсия.
Грубо бежим по узлам графа, начиная от корня, и ссылки на подчиненные узлы (получаемые из ребер графа GetVector(I).SlaveNode) являются тем, что хранится в текущей папке.
Спросите, почему не сделал построение дерева структуры на «Red-Black-Tree» с учетом поля NodeColor?
А шут его знает. Я этот алгоритм писал десяток лет назад и у меня есть золотое правило: «работает — не трогай там ничего». :)
И вот теперь мы подошли к пятому этапу — извлекаем данные во внешнюю папку.
Но для этого нужно прояснить для себя — как именно можно получить весь набор данных, ассоциированных с файлом.
Помните что я говорил про секцию FAT — данные не всегда будут идти последовательно и их нужно получать, ориентируясь на индексы секций, прописанных в FAT.
Смотрите, как можно получить данные «больших файлов» (размер которых больше или равен значению, хранящемуся в поле _ulMiniSectorCutoff заголовка):
procedure TPoifsFile.GetDataFromStream(ChainStart: ULONG;
NeedLength: DWORD; const Stream: TStream);
begin
Stream.Size := 0;
while (Integer(ChainStart) >= 0) and (Stream.Size < NeedLength) do
begin
// получаем смещение на начало стрима
FStream.Position := GetBlockOffset(ChainStart);
// получаем указатель на следующий сектор
ChainStart := FFat[ChainStart];
// читаем часть данных
Stream.CopyFrom(FStream, FHeader._uSectorShift);
end;
// финальная правка
if Stream.Size > NeedLength then
Stream.Size := NeedLength;
end;
Финальная правка нужна из-за того что данные в секторах хранятся блоками, а реальный размер файла не всегда кратен их размеру.
Согласен, стоит переписать немного, чтобы убрать финальную правку, но — оно мне надо? :)
Впрочем, по параметрам, нас больше заинтересует ChainStart, в котором нет ничего секретного. Это значение поля StartBlock из структуры TPoifsProperty.
А вот так получаем данные для файлов меньшего размера, чем _ulMiniSectorCutoff.
procedure TPoifsFile.GetDataFromMiniStream(ChainStart: ULONG;
NeedLength: DWORD; const Stream: TStream);
var
MiniStreamOffset: DWORD;
RealMiniStreamSector, TmpChain: Integer;
begin
Stream.Size := 0;
while (Integer(ChainStart) >= 0) and (Stream.Size < NeedLength) do
begin
// Смотрим в каком секторе должен располагаться данный Ministream
TmpChain := ChainStart;
RealMiniStreamSector := Properties[0].StartBlock;
while TmpChain >= 8 do
begin
Dec(TmpChain, 8);
RealMiniStreamSector := FFat[RealMiniStreamSector];
end;
// Получаем смещение сектора
MiniStreamOffset := GetBlockOffset(RealMiniStreamSector);
// получаем смещение на начало министрима
FStream.Position := MiniStreamOffset +
(ChainStart mod 8) * FHeader._uMiniSectorShift;
// получаем указатель на следующий блок министрима
ChainStart := FMiniFat[ChainStart];
// читаем часть данных
Stream.CopyFrom(FStream, FHeader._uMiniSectorShift);
end;
// финальная правка
if Stream.Size > NeedLength then
Stream.Size := NeedLength;
end;
Немножко хитрее, да?
Правда, если присмотреться, изменения тут только с расчетом офсета через TmpChain и тот же FAT. Если сектор выбивается за рамки дозволенного (восьмерку) то идем по цепочке FAT начиная от рута, пока TmpChain не станет меньше допустимого значения, ибо ссылка на минифат лежит именно в руте.
procedure GetStorageData(ANode: TStorageElement; const Stream: TStream);
begin
if ANode.Data.Size < Integer(AFile.Header._ulMiniSectorCutoff) then
AFile.GetDataFromMiniStream(ANode.Data.StartBlock, ANode.Data.Size, Stream)
else
AFile.GetDataFromStream(ANode.Data.StartBlock, ANode.Data.Size, Stream);
end;
В данную процедуру мы будем передавать узел графа, который извлекается из составного файла в папку, и на основании его размера, вызывать один из реализованных выше методов.
procedure Extract(Path: string; RootNodeIndex: Integer);
var
W: WideString;
I: Integer;
RootStorageNode, ChildStorageNode: TStorageElement;
F: TFileStream;
begin
RootStorageNode := ATree.GetNode(RootNodeIndex);
W := RootStorageNode.Data.Caption;
case RootStorageNode.Data.PropertyType of
STGTY_STORAGE:
Path := Path + W + '\';
STGTY_STREAM:
begin
try
ForceDirectories(Path);
F := TFileStream.Create(Path + W, fmCreate);
try
GetStorageData(RootStorageNode, F);
finally
F.Free;
end;
except
DebugLog.Add(Path + W);
end;
end;
end;
for I := 0 to RootStorageNode.VectorCount - 1 do
begin
ChildStorageNode := TStorageElement(RootStorageNode.GetVector(I).SlaveNode);
if ChildStorageNode = nil then
Continue;
if ChildStorageNode.ID <> RootNodeIndex then
Extract(Path, ChildStorageNode.ID);
end;
end;
Ну, здесь уже без комментариев. Все мы видели ранее — обычный алгоритм.
Если запустить созданный нами проект и натравить его на какой-нибудь вордовский документ, то выглядеть будет вот так:

А в папочке, куда мы это все извлекали, будет такое:

Не все файлы, да?
Ну, тут очень просто, если присмотритесь к именам в дереве, там видны какие-то черточки в виде "|" перед именем файла или непонятные пробелы перед «CompObj».
Это как раз те зарезервированные под OLE символы, о которых я говорил еще в первой главе (от 0 до 0x1F). Создать файлы с такими символами в наименованиях я не могу, поэтому они пропущены, но данные о них записаны в лог: «cannotread.log».
Конечно, это можно легко обработать, но для демки пойдет и так.
Код данного примера в архиве в папке "..\RawStorageReader\".
Впрочем, зачем мы это все написали?
Давайте попробуем при помощи нашего приложения, которое мы написали в предыдущей главе открыть вот такой файл: "..\corrupted\corrupted_storage.bin"
Будет как-то так:

О как, давайте тогда ридером из второй главы, напрямую через API:

Печаль, тогда посмотрим что за беда, и откроем этот файл уже в RAW режиме:

Ага, ошибка чтения, смотрим стек:
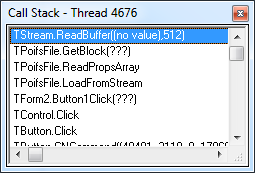
Ошибка на этапе чтения свойств файлов, не смогли выполнить ReadBuffer в функции GetBlock.
Будем решать.
6. Пробуем исправить ошибку в данных и читаем все что доступно.
Еще в самом начале статьи я говорил о целой когорте различных «восстанавливателей» документов от Word. Сейчас будем писать что-то наподобие них. :)
Все эти утилиты работают в двух режимах.
- они знают о формате составного файла.
- они знают о формате данных, которые Word хранит в своих стримах.
Я, конечно, не обладаю информацией о втором пункте, да и не надо оно мне, а вот о первом, после прочтения пятой главы, вы и сами знаете. :)
Вообще ошибок связанных с разрушением составного файла может быть всего четыре:
- убит заголовок (как правило, заполнен нулями)
- разрушен FAT
- не доступны данные TPoifsProperty
- изменены данные файлов в секторах
Первое — не лечится. Нет, ну может и найдется какой фанат и попробует вычислить значения первых секторов для построения FAT, но я таких не встречал.
Второе — практически не лечится.
Зная, что FAT содержат номера секторов, мы можем определить разрушение по следующему условию: следующее значение меньше чем константа ENDOFCHAIN (-2) или больше чем размер FAT массива.
Исправить можно изменением значения сбойного блока на константу ENDOFCHAIN, но, как правило, даже после такого вмешательства сектор минифат считается частично, да и массив свойств файлов будет доступен минимально (и то если повезет).
Третий вариант лечится.
Грубо, смотрим адрес ячейки FAT, где произошла ошибка чтения сектора, и выставляем ей значение ENDOFCHAIN. Этим мы, конечно, отрезаем кусок данных (в 99 процентах случаев убитых), но зато прочитаем то, что реально нам доступно.
Четвертый вариант не лечится, так как эти данные не принадлежат составному файлу, он просто их хранит, но он их не контролирует (только размер — не более).
Начинаем анализировать:
По хорошему мы можем справиться только с третьей проблемой, а именно — определить номер сбойного FAT индекса и поправить его.
Зная как работать с данными в RAW режиме, нам это не составит большого труда.
Для начала изменим процедуру чтения блоков данных:
function TPoifsFile.GetBlock(Adress: Integer): TPoifsBlock;
var
BlockOffset: Integer;
begin
BlockOffset := GetBlockOffset(Adress);
if BlockOffset < FStream.Size then
begin
FStream.Position := BlockOffset;
FStream.ReadBuffer(Result, SizeOf(TPoifsBlock));
end
else
raise Exception.Create('Wrong block offset at addres: ' + IntToStr(Adress));
end;
Пусть теперь она проверяет оффсеты и поднимет исключение, если вдруг что-то не срослось.
Второе изменение сделаем в процедуре ReadPropsArray, где будем более строго контролировать состояние FAT массива:
function TPoifsFile.ReadPropsArray: Boolean;
var
I, J, Len, LastGood: Integer;
PropsBlock: TPoifsPropsBlock;
begin
Result := True;
// инициализируем размер массива свойств
Len := 0;
// запоминаем номер первого сектора, в котором размещается Property Set Storage
J := FHeader._sectDirStart;
LastGood := J;
repeat
if J = FREESECT then
begin
FixFatEntry(LastGood, ENDOFCHAIN);
Break;
end;
// читам свойства блоками по 4 элемента
Inc(Len, 4);
SetLength(FPropsArray, Len);
// читаем с автоматической правкой
try
PropsBlock := TPoifsPropsBlock(GetBlock(J));
except
FixFatEntry(LastGood, ENDOFCHAIN);
Break;
end;
for I := 0 to 3 do
FPropsArray[Len - 4 + I] := PropsBlock[I];
LastGood := J;
// читаем номер следующего сектора из FAT
J := FFat[J];
if J < ENDOFCHAIN then
begin
FixFatEntry(LastGood, ENDOFCHAIN);
Break;
end;
until J = ENDOFCHAIN;
end;
Ну и осталось написать процедуру FixFatEntry:
procedure TPoifsFile.FixFatEntry(FatIndex, NewValue: Integer);
var
J, Offset: Integer;
begin
// Ищем оффсет в FAT цепочке
J := FatIndex mod 128;
Offset := FFatOffset[FatIndex] + J * 4;
// и пишем вместо сбойного значения новое
FStream.Position := Offset;
FStream.WriteBuffer(NewValue, SizeOf(Integer));
end;
Именно при помощи нее мы будем производить изменения FAT цепочки в оригинальном файле.
Теперь давайте посмотрим что получилось:

Ба… да там целая куча данных :)
Некоторые, конечно, слегка поломаны, но большую часть мы вытащили.
Вообще, для данного варианта ошибки, править данные в файле через процедуру FixFatEntry не всегда обязательно и можно пропустить вызов FStream.WriteBuffer.
Дело в том, что даже после такой правки, что утилита из второй главы, что из третьей, откроют такой составной файл, но скажут что он пуст, такая вот закавыка.
Но зато теперь у вас есть весь набор данных о составном файле :)
Код данного класса с поддержкой восстановления найдете в архиве по следуюющему пути: "..\RawStorageReader\PoifsWithRepair.pas".
Пожалуй, будем закругляться.
7. Выводы и статистика
Если честно — я очень сильно боюсь, что своей статьей я вас оттолкнул от использования данной технологии.
Вся проблема в том, что не нужно допускать одной, самой распространенной ошибки — если приложение, открывшее составной файл на запись, будет некорректно завершено, составной файл однажды (не всегда, но) может быть разрушен.
Разрушен будет не просто так — это произойдет на этапе записи в файл, которая может внезапно прерваться.
Как думаете, сколько есть программных продуктов, которые отслеживают такую ситуацию?
Если скажете что много, возражу, да и механизм у них один — транзакции, во время которой я вытащу флэшку, на которую сохраняются данные :)
Хотя, давайте, я вам приведу немного статистики:
Все ошибки, которые я описал в статье, происходили, конечно, не единовременно.
Это накопленная мной база возможных (вероятных) ошибок.
Согласитесь, даже если мы будем использовать обычный текстовый файл, однажды мы сможем записать в него не совсем те данные, которые хотели.
А теперь статистика:
За последние 8 с половиной лет (скажем, дата отсчета реализации инструмента чтения составного файла в RAW режиме) у меня есть в наличии ровно 473 файла разрушенных баз, которые прислали нам наши пользователи.
Если брать за среднее количество пользователей тогда и сейчас, и осреднить — получится грубо 150 тысяч станций, на которых ежедневно запускалось наше ПО.
В течении 24 рабочих дней, ежемесячно и в течении 12 месяцев каждый год.
Считаем: 150000 ежедневных запусков * 24 дня * 12 месяцев * 8 лет = 345 с копейками миллионов запусков (усредненное).
По факту, на руках я имею ровно 473 «поломатых» файла (иногда бывает 1-2 в месяц, иногда месяцами затишье). Из них (этот момент нужно учесть), около сотни были с битым FAT (а как я и говорил — битый фат, крайне плохо).
Так вот, практически вся эта сотня битых на уровне FAT-а файлов — это были удаленные составные файлы, которые потом восстанавливали утилитами типа UnErase и спрашивали: мол что с ним можно сделать?
А с ними делать уже нечего — не мы удаляли, не нам и восстанавливать.
Поэтому, откинув эту сотню, давайте посмотрим: каков шанс поломки составного файла?
Да всего лишь 1 к миллиону — CD при быстрой скорости записи чаще сбоить будет, чем это число :)
Не верите?
Напишите тест открытия такого файла с принудительным завершением процесса в нештатном режиме (к примеру, по разрушению стека) и посчитайте сколько файлов разрушиться?
Думаете это все еще не надежно?
Отлично — скажу следующее: данные файлы работают в рамках транзакционной модели.
Если сможете прямо вот так с ходу набросать код гарантированного «убития» данного файла по некорректному закрытию — с меня печенька :)
Ну а если думаете, что и этот тест не надежен, то скажу — у оставшихся файлов данные были восстановлены практически целиком, обычно не хватало только последнего кусочка (грубо небольшой части данных сметы, которая была не принципиальна).
Поэтому запомните два простых правила, чтобы добавить еще немного страховки:
- Не используйте составные файлы в том случае, если ваше приложение может работать с флэшки — убьете файл при вытаскивании флешки, если в этот момент ваше приложение запущено и лочит данный файл.
- Ставьте векторные исключения через AddVectoredExceptionHandler. Если у вас ошибка связанная со стеком — ваше приложение рухнет не успев добраться до первого обработчика SEH. А в векторном исключении вы, по крайней мере, корректно закроете файл — большего ведь и не нужно. (Потом при необходимости откроете его заново, если вдруг был False Alarm :)
Ну а я заканчиваю свое повествование, а исходный код к статье можно забрать тут.
Как обычно, выражаю Благодарность участникам форума "Мастера Дельфи" за помощь с вычиткой статьи перед публикацией.
ЗЫ: кстати, по поводу поддержки длинных имен файлов (длиной до 1024 символа). Задумайтесь, а как вы будете распаковывать содержимое составного файла в обычную файловую систему, которая может быть даже не NTFS? :)
Удачи :)
— © Александр (Rouse_) Багель
Март, 2015
Комментарии (6)

Error1024
01.04.2015 02:46+1Спасибо за статью, огромный труд!
Благодаря статье, я теперь знаю о составных файлах, думаю применю где-нибудь.

alisichkin
01.04.2015 11:11Добрый день!
В своей статье вы не упомянули методы ReadClassStg/WriteClassStg, позволяющие подписывать файл уникальным GUID. Почему?
Я в своей программе, использующей, OLE хранилища, не использовал метод Commit. И тфу-тьфу, пока не получил битых файлов (конечно, у меня статистика использования программы не такая большая как у Вас). Метод Commit нужно вызывать перед обнуление корневого хранилища или после каждой операции записи?
Например:
<code class="delphi">procedure WriteInt(V: integer; const Name: WideString; var Storage: IStorage); var BytesWritten: Integer; Stream: IStream; begin Olecheck(Storage.CreateStream(PWideChar(Name), STGM_CREATE or STGM_WRITE or STGM_DIRECT or STGM_SHARE_EXCLUSIVE, 0, 0, Stream)); try Olecheck(Stream.Write(@V, sizeof(Integer), @BytesWritten)); // ?? Olecheck(Storage.Commit(STGC_DEFAULT)) finally Stream := nil end end; </code>
Спасибо за статью!
Rouse Автор
01.04.2015 11:55ReadClassStg/WriteClassStg я упомянул в декларации заголовка, но сам их не использую (не было надобности).
А по поводу вызова Commit — к сожалению не на всех машинах происходит автоматическая запись данных, но закономерности я не понял, поэтому всегда вызываю его принудительно, во избежание :)
Ну а вызывать его в принципе нужно один раз, перед закрытием хранилища, вызвав его для рута.alisichkin
01.04.2015 12:12А я использую ReadClassStg/WriteClassStg как уникальный флаг что это это «мои» файлы :)
К сожалению не достаточно кармы что бы проголосовать за статью :\.Rouse Автор
01.04.2015 19:04Данное поле предназначено немного для других вещей:
msdn.microsoft.com/ru-ru/library/windows/desktop/ms862136.aspx
Но, в принципе, если не будете пересекаться по UID с существующими врапперами над стораджем — можно и так вывернуться. Просто там в заголовке есть резервируемые поля, я бы, для данных целей воспользовался хотя-бы _ulReserved2
lam0x86
Спасибо за ссылку на сайт «Мастера Дельфи». Столько полезного в своё время там нашёл! Прям вспомнились школьные годы, дорогущий интернет по-модему, те самые звуки хр-хр-хрх-уиу-уиу-хррр. Эхх…