
Disclaimer практически
При написании сего текста автор руководствовался следующими ключевыми моментами:
0. Большому количеству уважаемых многоопытных коллег всё это покажется мелким и не заслуживающим внимания. Facil omnes, cum valemus, recta consilia aegrotis damus.
1. Какому-то — пусть и небольшому — количеству уважаемых менее опытных коллег будет полезно/нужно/небезынтересно.
2. Намёки на приспособление для поддержания веса тела пациента при стоянии и ходьбе имеют право на существование, поскольку workaround он потому и workaround.
3. Гугль не знает или я плохо искал. Но честно старался.
4. Опыт в написании чего-то подобного первый, отсюда и комки в текстуре.
Приветствую, уважаемое сообщество.
Преамбула
В инфраструктуре нашей компании существует три параллельных ветви серверов Veeam B&R. Ветви, как у нас любят объяснять практически любые казусы, «исторически сложились».
Одна обслуживает backup job'ы медленно сходящей на нет фермы виртуализации, оставшейся после слияния компаний.
Вторая была опытно-промышленным внедрением Veeam B&R, плавно ставшим решением промышленным и на данный момент обслуживает backup и replication job фермы виртуализации vSphere 4.1 (да, всё ещё в эксплуатации, извините) и backup job фермы виртуализации vSphere 5.5.
Третья обслуживает исключительно replication job' и failover plan'ы фермы виртуализации vSphere 5.5.
Всё это находится в процессе живой и непрекращающейся миграции.
Честь и счастье администрировать всё это богатство в течение последних ~5 лет выпала мне, как основному администратору виртуализации VMware vSphere, Veeam B&R и серверов Wintel.
+ Есть коллега на роли администратора запасного.
В ходе недавней подготовки к тестированию DR-решения, основанного на репликации виртуальных серверов средствами Veeam B&R, было выявлено непонятное нам несоответствие между количеством виртуальных серверов, входящих в состав backup и replication job'ов и сведениями о количестве точек восстановления у этих серверов.
Сведения о количестве точек получались через powershell с использованием Veeam Backup & Replication Powershell snapin.
Выборочная проверка количества точек запросом через веб-интерфейс Veeam Backup Enterprise Manager показала аналогичное расхождение с реальностью.
Не то чтобы это очень мешало жить или оказывало существенное влияние. Но в некоторых случаях могло привести к неверным выводам – например, при использовании сценариев Powershell для сбора статистических данных мы бы газифицировали малый водоём и довольно долго могли этого не заметить.
Да и беспокоит, зудит — ну не аккуратненько же. Надо починить.
Запасной администратор в данный момент тренируется с ТП Veeam по открытому кейсу, исследуя проблему в рамках replication job'ов.
Я решил покопаться в части backup job'ов на другой ветви Veeam B&R дабы не искажать картину, исследуемую ТП вендора.
Момент возникновения расхождений и их причины пока для нас неясны. При точном ответе от ТП Veeam внесу апдейт в текст.
Пока я для себя принял рабочую гипотезу, что неоднократные in-place upgrad'ы Veeam B&R начиная с версии 7 до текущей версии 9 update 1, неоднократные изменения настроек существующих job'ов и т.п. процессы не прошли даром и, предположительно, БД Veeam B&R накопила «мусора», дублирующихся записей в таблицах.
В качестве СУБД используется MS SQL, теоретически можно порыться в структуре базы, но, перефразируя Арамиса, "… но, право, я не DBA...".
Выборочная проверка серверов из состава backup job'ов показала, что с данными о точках восстановления всё столь же запущено.
Приведу пример:
Некий виртуальный сервер имярек входит в состав задания Veeam Backup & Replication. Согласно сведениям, отдаваемым Veeam Backup Enterprise Manager’ом, имеет 36 точек восстановления.

При этом свойства backup job'а в части количества хранимых точек не изменялись никогда – т.е. от момента создания job’а ещё в версии Veeam B&R 7 – и всегда было равно 7 для описываемого задания.
Раскрываемый список 36 restore point’ов выглядит вполне «рабочим» — никаких fail'ов, unaccessible-частей или чего-то ещё, наводящего на мысли опорче проблемах с точками, не видно:
Восстанавливать виртуальные машины из точек с датами, явно выходящими за обозначенное в свойствах задания количество хранимых, не пробовал. В основном из-за отсутствия времени на эксперименты. Отсутствие времени вообще было решающим фактором при поиске выхода из ситуации — сразу после невозможности останавливать выполнение backup job'ов на неопределённый срок для экспериментов.
КМК, при попытке восстановления был бы fail, поскольку физически в репозитории лежит 1 full backup, 6 incremental backup’ов и файл метаданных — то есть в наличии реально 7 точек, отсчитывая от текущего дня. Для 10 мая самая ранняя хранимая точка была бы создана 3 мая. А всё, что по датам создано раньше, реально не существует и живёт только в БД Veeam B&R.
Вот содержимое репозитория для рассматриваемого backup job'а:
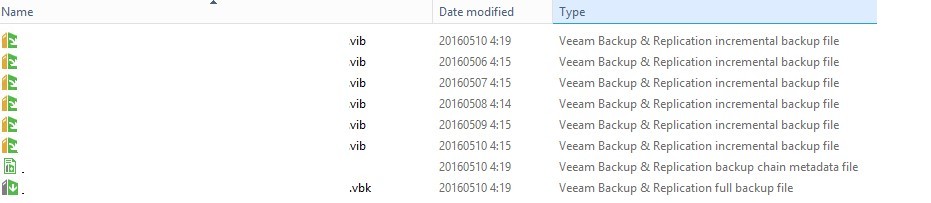
Rescan для репозитория, содержащего файлы бекапа, результатов не давал, метаданные не обновлялись.
Большинство заданий имеют файлы бекапа такого размера, что переносить их просто некуда + N ТБ архивов копироваться будут длительное время, задание на это время нужно остановить, а простой бекапов недопустим. Поэтому вариант с переносом файлов бекапа на другой репозиторий с последующим выполнением rescan repository и map backup в настройках задания не был принят как лучший выход из положения. По той же причине нельзя всё удалить, поставить заново, восстановив настройки Veeam B&R из регулярно создаваемой резервной копии.
Пришлось искать выход, позволяющий решить проблему в, так сказать, довольно узких рамках.
И, пусть не слишком изящный, но он был нащупан.
Алгоритм примерно следующий:
1. В репозитории, содержащем файлы бекапа, меняем расширение в имени файлов
— full backup
— backup chain metadata file
Note. Переименование / перенос на другой репозиторий одного backup chain metadata file с последующим rescan'ом репозитория не помогает.
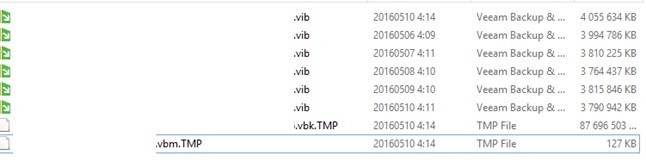
2. Выполняем Rescan для репозитория, содержащего файлы бекапа. Видим, что один бекап был удалён из базы.
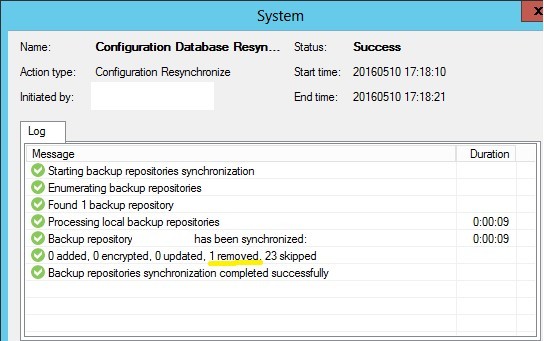
3. Возвращаем расширение в имени файлов full backup и метаданных в репозитории на исходную позицию.
4. Выполняем повторный Rescan для репозитория, содержащего файлы бекапа. Видим, что один бекап был добавлен в базу.
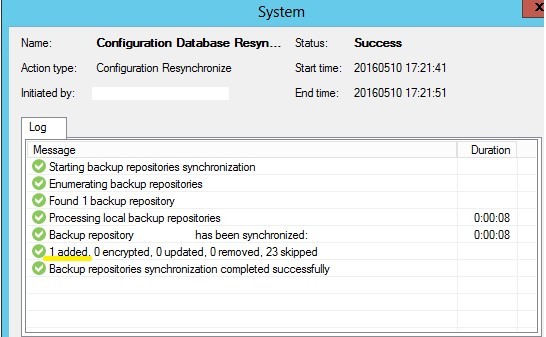
5. Проверяем виртуальный сервер имярек ещё раз и видим количество точек восстановления, соответствующее настройкам задания и количеству файлов в репозитории.
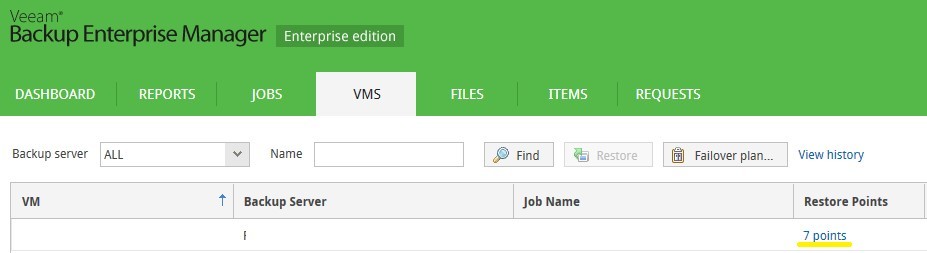
6. В свойствах Job'а выполняем Map backup к импортированной на шаге 4 цепочке.
Повторюсь, что решение далеко от изящества. При количестве job’ов существенно большем от примерно 70 в моём случае пришлось бы искать иной способ — от скриптов до переустановки сервера Veeam B&R.
Приветствуется тыкание носом в не найденные решения, kb, мнения, предложения так далее — fas est et ab hoste doceri.
При написании сего текста автор руководствовался следующими ключевыми моментами:
0. Большому количеству уважаемых многоопытных коллег всё это покажется мелким и не заслуживающим внимания. Facil omnes, cum valemus, recta consilia aegrotis damus.
1. Какому-то — пусть и небольшому — количеству уважаемых менее опытных коллег будет полезно/нужно/небезынтересно.
2. Намёки на приспособление для поддержания веса тела пациента при стоянии и ходьбе имеют право на существование, поскольку workaround он потому и workaround.
3. Гугль не знает или я плохо искал. Но честно старался.
4. Опыт в написании чего-то подобного первый, отсюда и комки в текстуре.
Приветствую, уважаемое сообщество.
Преамбула
В инфраструктуре нашей компании существует три параллельных ветви серверов Veeam B&R. Ветви, как у нас любят объяснять практически любые казусы, «исторически сложились».
Одна обслуживает backup job'ы медленно сходящей на нет фермы виртуализации, оставшейся после слияния компаний.
Вторая была опытно-промышленным внедрением Veeam B&R, плавно ставшим решением промышленным и на данный момент обслуживает backup и replication job фермы виртуализации vSphere 4.1 (да, всё ещё в эксплуатации, извините) и backup job фермы виртуализации vSphere 5.5.
Третья обслуживает исключительно replication job' и failover plan'ы фермы виртуализации vSphere 5.5.
Всё это находится в процессе живой и непрекращающейся миграции.
Честь и счастье администрировать всё это богатство в течение последних ~5 лет выпала мне, как основному администратору виртуализации VMware vSphere, Veeam B&R и серверов Wintel.
+ Есть коллега на роли администратора запасного.
В ходе недавней подготовки к тестированию DR-решения, основанного на репликации виртуальных серверов средствами Veeam B&R, было выявлено непонятное нам несоответствие между количеством виртуальных серверов, входящих в состав backup и replication job'ов и сведениями о количестве точек восстановления у этих серверов.
Сведения о количестве точек получались через powershell с использованием Veeam Backup & Replication Powershell snapin.
Выборочная проверка количества точек запросом через веб-интерфейс Veeam Backup Enterprise Manager показала аналогичное расхождение с реальностью.
Не то чтобы это очень мешало жить или оказывало существенное влияние. Но в некоторых случаях могло привести к неверным выводам – например, при использовании сценариев Powershell для сбора статистических данных мы бы газифицировали малый водоём и довольно долго могли этого не заметить.
Да и беспокоит, зудит — ну не аккуратненько же. Надо починить.
Запасной администратор в данный момент тренируется с ТП Veeam по открытому кейсу, исследуя проблему в рамках replication job'ов.
Я решил покопаться в части backup job'ов на другой ветви Veeam B&R дабы не искажать картину, исследуемую ТП вендора.
Момент возникновения расхождений и их причины пока для нас неясны. При точном ответе от ТП Veeam внесу апдейт в текст.
Пока я для себя принял рабочую гипотезу, что неоднократные in-place upgrad'ы Veeam B&R начиная с версии 7 до текущей версии 9 update 1, неоднократные изменения настроек существующих job'ов и т.п. процессы не прошли даром и, предположительно, БД Veeam B&R накопила «мусора», дублирующихся записей в таблицах.
В качестве СУБД используется MS SQL, теоретически можно порыться в структуре базы, но, перефразируя Арамиса, "… но, право, я не DBA...".
Выборочная проверка серверов из состава backup job'ов показала, что с данными о точках восстановления всё столь же запущено.
Приведу пример:
Некий виртуальный сервер имярек входит в состав задания Veeam Backup & Replication. Согласно сведениям, отдаваемым Veeam Backup Enterprise Manager’ом, имеет 36 точек восстановления.
При этом свойства backup job'а в части количества хранимых точек не изменялись никогда – т.е. от момента создания job’а ещё в версии Veeam B&R 7 – и всегда было равно 7 для описываемого задания.
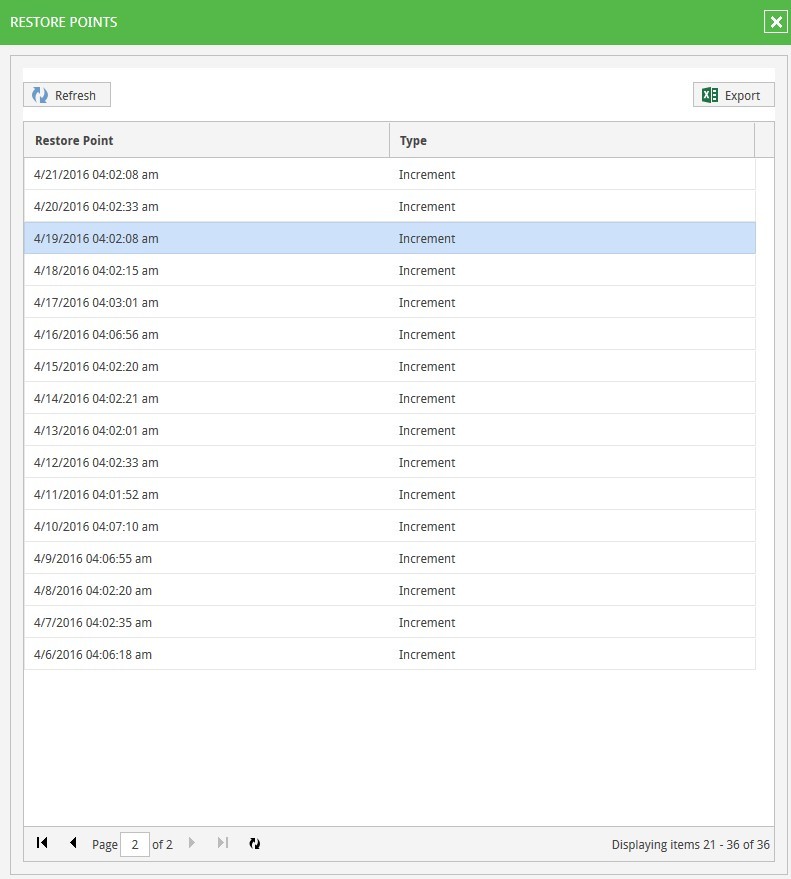
Раскрываемый список 36 restore point’ов выглядит вполне «рабочим» — никаких fail'ов, unaccessible-частей или чего-то ещё, наводящего на мысли о
 |
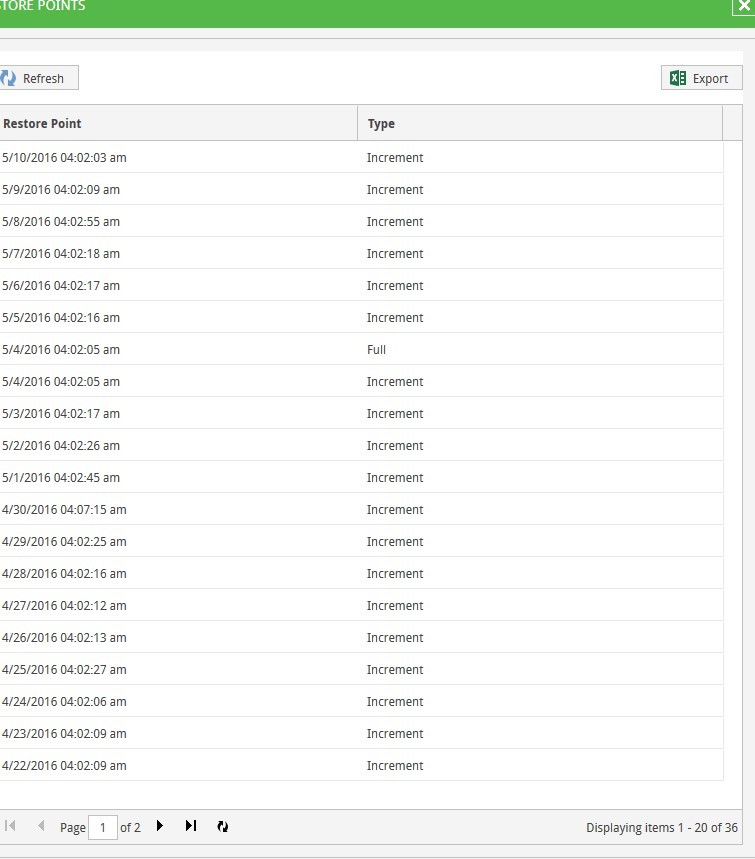 |
Восстанавливать виртуальные машины из точек с датами, явно выходящими за обозначенное в свойствах задания количество хранимых, не пробовал. В основном из-за отсутствия времени на эксперименты. Отсутствие времени вообще было решающим фактором при поиске выхода из ситуации — сразу после невозможности останавливать выполнение backup job'ов на неопределённый срок для экспериментов.
КМК, при попытке восстановления был бы fail, поскольку физически в репозитории лежит 1 full backup, 6 incremental backup’ов и файл метаданных — то есть в наличии реально 7 точек, отсчитывая от текущего дня. Для 10 мая самая ранняя хранимая точка была бы создана 3 мая. А всё, что по датам создано раньше, реально не существует и живёт только в БД Veeam B&R.
Вот содержимое репозитория для рассматриваемого backup job'а:
Rescan для репозитория, содержащего файлы бекапа, результатов не давал, метаданные не обновлялись.
Большинство заданий имеют файлы бекапа такого размера, что переносить их просто некуда + N ТБ архивов копироваться будут длительное время, задание на это время нужно остановить, а простой бекапов недопустим. Поэтому вариант с переносом файлов бекапа на другой репозиторий с последующим выполнением rescan repository и map backup в настройках задания не был принят как лучший выход из положения. По той же причине нельзя всё удалить, поставить заново, восстановив настройки Veeam B&R из регулярно создаваемой резервной копии.
Пришлось искать выход, позволяющий решить проблему в, так сказать, довольно узких рамках.
И, пусть не слишком изящный, но он был нащупан.
Алгоритм примерно следующий:
1. В репозитории, содержащем файлы бекапа, меняем расширение в имени файлов
— full backup
— backup chain metadata file
Note. Переименование / перенос на другой репозиторий одного backup chain metadata file с последующим rescan'ом репозитория не помогает.
2. Выполняем Rescan для репозитория, содержащего файлы бекапа. Видим, что один бекап был удалён из базы.
3. Возвращаем расширение в имени файлов full backup и метаданных в репозитории на исходную позицию.
4. Выполняем повторный Rescan для репозитория, содержащего файлы бекапа. Видим, что один бекап был добавлен в базу.
5. Проверяем виртуальный сервер имярек ещё раз и видим количество точек восстановления, соответствующее настройкам задания и количеству файлов в репозитории.
6. В свойствах Job'а выполняем Map backup к импортированной на шаге 4 цепочке.
Повторюсь, что решение далеко от изящества. При количестве job’ов существенно большем от примерно 70 в моём случае пришлось бы искать иной способ — от скриптов до переустановки сервера Veeam B&R.
Приветствуется тыкание носом в не найденные решения, kb, мнения, предложения так далее — fas est et ab hoste doceri.
Поделиться с друзьями
Комментарии (9)

afoggy
11.05.2016 14:08В целом, ваша рабочая гипотеза про устаревшие данные в БД, скорее всего, верна и в ТП ее оперативно подправят. Можно номер вашего кейса, так сказать, for reference? Спасибо.
BTW, workaround очень даже изящный.
kavramen
А чем не угодил вариант Disk — Backup Job (right click) — Remove From Configuration?
Просто удаляет из БД, без плясок с переименовыванием файлов и рескана (одного из двух)…
Tomas_Torquemada
Ну почему же сразу «чем не угодил». Просто нащупывал с другой стороны.
Попробую и такой, благо ещё не все задания поправил, спасибо.
kavramen
Только этот вариант для реплик не поможет, там надо смотреть в чем дело.
Если с репликами так сделаете — удалятся чекпойнты, скорее всего
Tomas_Torquemada
Реплики я оставил коллеге и ТП Veeam, пусть выясняют :)
Да и потеря чекпойнтов у реплик не так важна — у нас только 1 точка используется, а реплицируются серверы с периодичностью от 35 минут до раз в 24 часа, быстро наверстаем.
По Вашему варианту пока у меня другая странность вылезла: если идти через Disk — Backup Job (right click) — Remove From Configuration — rescan repository + Map backup в свойствах задания (иначе просто рядом делает каталог в репозитории и начинает full писать), то не становится не видна большая часть точек восстановления, остаётся 2-3 из цепочки. При этом физически vib'ы в репозитории есть.
kavramen
А если просто рескан сделать и Disk — Backup Job (right click) — properties, рестор поинты случаем не помечены красным крестом?
Сейчас выглядит так, как будто у Вас цепочка нарушена…
Tomas_Torquemada
Не помечены, все Ok.
Но при этом через Disk — Backup Job (right click) — properties видно, что у сервера есть 7 точек, а через enterprise manager или Powershell показывает 3.
kavramen
Странно. Скорее всего так из-за того что цепочки с 7ки тянутся…
Вероятнее всего в базе не все рестор поинты связаны (или в метадате)