
Теперь немного сосредоточимся на такой вещи, как база данных.
База данных — структурированная совокупность информации, приведённая в форму, достаточную для её обработки электронной вычислительной машиной (а как же квантовые компьютеры? — когда появятся, тогда и сменим определение). За более точным определением обращайтесь к Википедии
Фактически, база данных представляет собой множество таблиц, связанных собой разными способами. В нынешних СУБД используется реляционная математика, описывающая данные, как взаимодействие множеств данных. Грубо говоря, есть множество А, в котором содержится шапка-описание ячеек таблицы и множество В, в котором содержится нумерация строк. Пересечением этих множеств становится множество данных С, в котором определяются хранимые данные.
Таким образом формируется таблица базы. Однако, существует большое количество баз, которые нам нужно между собой стыковать. Каким, скажете вы, образом?
В первых база использовалась так называемая иерархическая система связи. Фактически, у нас имелась сущность «Ёжик», которые имела различные аттрибуты: лапы, хвост, усы, когти и прочее. Эти аттрибуты имели свои свойства: длина, толщина, прочность. Всё это можно было реализовать в числовых величинах. Подобная система управления данными впоследствии привела к созданию таким вещей, как XML.
У этой системы был достаточно существенный недостаток — большое время извлечения данных. Грубо, чтобы выяснить какой-то кусок данных, например, свойство или наименование, требовалось каждый раз расковыривать всю ветку данных. Причём, количество заходов равнялось количеству рассматриваемых данных плюс путь по ветке до каждого из них. Также добавим, что такие базы сжирали много процессорного времени.
По иному работала реляционная модель данных, созданая 1969-1970 годах доктором Эдуардо Франком Коддом из IBM. Фактически, он предложил рассматривать взаимодеиствие данных, как разноуровневое взаимодействие множеств данных и аттрибутов, их описывающих. Он реализовал взаимодействие данных сначала на уровне таблиц, затем, на уровне связей и пересечений.
Помните старую модель базы, которую я выкладывал в ранних статьях? Каждая из таблиц представляет собой произведение двух множеств (точнее, одномерных таблиц), создающих матрицу. Для соединения используется набор столбцов из этих матриц, которые называются "ключами" — набором данных, однозначно определяющих строчный объём в таблице.
По степени упорядоченности использования ключей выделяются так называемые нормальные формы:
Исходя из данных определений, я собрал базу между BSNF и 5NF. Это позволяет мне в единичном запросе забрать тот объём данных, который мне нужен и тратить меньше аппаратных ресурсов для изменение данных.
Стрелки указывают связь данных из индексных таблиц (имеющих индексные ключи и минимальный объём столбцов, им определяемых) в таблицы отношений. Таблицы отношений (например, document или position) содержат в себе как свои ключи, так и ключи для связи с другими таблицами. С помощью этих ключей потом очень удобно извлекать данные, используя элементарное соответствие ключевых значений строк:
Как видите, схема данных достаточно проста и позволяет проводить взаимодействие данных на примитивном уровне, что значительно сокращает количество кода как на стороне скриптов, так и на стороне базы.
Теперь рассмотрим модуль, начиная с самой базы. Она представляет собой набор таблиц с автоинкрементными полями:
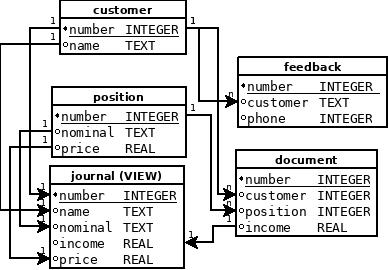
Таблица содержит в себе пересечение следующих сущностей:

Журнал документов здесь — форма дублирования запроса на отображение. Как и все отображения, быстро не обновляется.
На первой схеме стрелками показанны векторы переноса данных из первичных ключей. Каждый из них имеет связь с родительским массивом и создаёт соответствующую схему данных:
Исходя из этой схемы, я принял решение разместить отдельный модуль доступа к базе, заставив исполнительные модули формировать запрос внутри себя. По-хорошему, нужно будет сделать функцию для вызова общих представлений, обновления записей и вставки, но я это сделаю позже, ибо есть риск укрупнения библиотеки и повторения функционала (и fetch, по хорошему, лучше делать в исполнительном модуле):
Модуль database.lua:
Здесь в модуле создаётся экземпляр модуля управления базой luasql.sqlite3, инициализируется драйвер базы, затем ему скармливается сама база. Активация запроса в исполнительном модуле происходит следующим образом:
В связи с высказаным мной предположением в части 3-й и 4-й я решил модифицировать модуль базы. Изменение этого модуля повлекло модификацию всех исполнительных. Но это того стоило. Модификация состоит в том, что для вызова СУБД — зависимых запросов можно настроить однотипные процедуры, принимающие параметры на входе.
Рассмотрим функцию database.select_from_where(select, from, where), которая часто используется в процедурах для получения табличной информации:
Вызывается это благолепие командой:
Дальше всё это обрабатывается через цикл и построчно извлекаются данные:
Здесь заполняется первоначальный вызов функции fetch() для последующего снижения дублирования везде, где только возможно. Таким образом мы вырезаем половину кода из модулей исполнения и передаём им массив с данными по запросу.
Следующая функция — database.update_set_where(update, set, where) — используется для обновления данных без индексного удаления. Это ситуации, в которых нам надо изменить данные позиции / пользователя без перелапачивания документов и данные выплат по позиции:
В функцию забивается имя таблицы, имя столбца для изменения и условие обновления. Здесь можно указать ячейку с конкретным значением полей или целую группу. В случае некорректного ввода данных (например, изменилась цена на несколько категорий) информацию можно изменить очень быстро.
Функция database.delete_from_where(from, where) используется для ликвидации данных в таблицах. дабы исключить случайное уничтожение всех данных в таблице, функция создаёт строку с параметром сравнения:
И последняя, часто используемая функция — database.insert_into_values(table, fields, values) — предназначенная для вставки данных:
Как видите, во всех функциях, кроме SELECT'а, используется элементарное исполнение запроса. Прикол в том, что базы SQLite3 по окончании записи / модификации строки не выдают значение индеска, как это делает Firebird. По этой причине приходится запускать поиск индекса добавленной строки при последующем добавлении индекса в связаные таблицы.
Таким образом, все вышеуказаные функции сводят 4-6 строк на исполнение запроса в модулях бизнес-логики до 1-5 строчек на каждую. Такая оптимизация вдогонку улучшила удобочитаемость исполнительных модулей.
За сим откланяюсь. В следующей статье распишу работу управляющего модуля.
P.S. Маленькая просьба — если хотите передать замечание по этому циклу статей, прошу предварительно прочитать статью «Разработка микро-учётной системы на lua, часть вторая. Постановка задачи», в которой я указываю условия разработки программы и функции, которые на неё возлагаются. Учитывайте это.
UPD. В комментариях высказывалось опасение в плане преобразования вещественного числа с плавающей запятой из текста в число. Оказалось, что функция tonumber() преобразует строку формата «целая_часть.дробная» в соответствующий числовой эквивалент, причём можно даже не прибегать к этой функции:
В памяти число сохраняется в виде «34E2».
Для очистки совести я проверил предположение, добавив позицию с дробным значением:

Проверить можно с помощью следующей команды:
Для сомневающихся уточняю — речь идёт о стандартных двух знаках после запятой.
База данных — структурированная совокупность информации, приведённая в форму, достаточную для её обработки электронной вычислительной машиной (а как же квантовые компьютеры? — когда появятся, тогда и сменим определение). За более точным определением обращайтесь к Википедии
Фактически, база данных представляет собой множество таблиц, связанных собой разными способами. В нынешних СУБД используется реляционная математика, описывающая данные, как взаимодействие множеств данных. Грубо говоря, есть множество А, в котором содержится шапка-описание ячеек таблицы и множество В, в котором содержится нумерация строк. Пересечением этих множеств становится множество данных С, в котором определяются хранимые данные.
Таким образом формируется таблица базы. Однако, существует большое количество баз, которые нам нужно между собой стыковать. Каким, скажете вы, образом?
В первых база использовалась так называемая иерархическая система связи. Фактически, у нас имелась сущность «Ёжик», которые имела различные аттрибуты: лапы, хвост, усы, когти и прочее. Эти аттрибуты имели свои свойства: длина, толщина, прочность. Всё это можно было реализовать в числовых величинах. Подобная система управления данными впоследствии привела к созданию таким вещей, как XML.
У этой системы был достаточно существенный недостаток — большое время извлечения данных. Грубо, чтобы выяснить какой-то кусок данных, например, свойство или наименование, требовалось каждый раз расковыривать всю ветку данных. Причём, количество заходов равнялось количеству рассматриваемых данных плюс путь по ветке до каждого из них. Также добавим, что такие базы сжирали много процессорного времени.
По иному работала реляционная модель данных, созданая 1969-1970 годах доктором Эдуардо Франком Коддом из IBM. Фактически, он предложил рассматривать взаимодеиствие данных, как разноуровневое взаимодействие множеств данных и аттрибутов, их описывающих. Он реализовал взаимодействие данных сначала на уровне таблиц, затем, на уровне связей и пересечений.
Помните старую модель базы, которую я выкладывал в ранних статьях? Каждая из таблиц представляет собой произведение двух множеств (точнее, одномерных таблиц), создающих матрицу. Для соединения используется набор столбцов из этих матриц, которые называются "ключами" — набором данных, однозначно определяющих строчный объём в таблице.
По степени упорядоченности использования ключей выделяются так называемые нормальные формы:
- 1NF — первая нормальная форма. Все строки таблиц содержат уникальную по отношению к другим совокупность данных
- 2NF — вторая нормальная форма. Уже существует какой-то набор столбцов, однозначно определяющих строку таблицы
- 3NF — третья нормальная форма. В качестве ключевых столбцов используется множество, которое однозначно определяет запись (строку).
- BSNF (Boyce-Codd normal form) — нормальная форма Бойса-Кодда (на студенческом жаргоне: «Бойся кода!»). Всякая зависимость внутри и между таблиц напрямую определяется ключевым значением.
- 5NF — пятая нормальная форма. Каждая зависимость внутри и снаружи точно определена ключом.
- 6NF — шестая нормальная форма. Каждая зависимость внутри и снаружи однозначно определена минимально возможным ключём. Фактически, таблицу в этой форме невозможно преобразовать в более простую или добавить дополнительных связей.
Исходя из данных определений, я собрал базу между BSNF и 5NF. Это позволяет мне в единичном запросе забрать тот объём данных, который мне нужен и тратить меньше аппаратных ресурсов для изменение данных.
Стрелки указывают связь данных из индексных таблиц (имеющих индексные ключи и минимальный объём столбцов, им определяемых) в таблицы отношений. Таблицы отношений (например, document или position) содержат в себе как свои ключи, так и ключи для связи с другими таблицами. С помощью этих ключей потом очень удобно извлекать данные, используя элементарное соответствие ключевых значений строк:
/* Пример: в таблице Customer есть клиент Miku Hatsune Yamaha. Её строка имеет индекс 1. Нам необходимо добавить новый номер телефона в справочник feedback, в котором находится ячейка с индексом клиента-владельца телефона */
SELECT number, name FROM customer WHERE number = 1;
/* Здесь мы удостоверяемся, что Miku стоит первая */
INSERT INTO feedback (customer, phone) VALUES ( 1, 89603347382 );
/* Здесь мы добавляем телефон и тут же устанавливаем связь с таблицой customer, в которой содержится индекс клиента. Теперь можно извлечь и телефон, и клиента следующим образом: */
SELECT customer.number, customer.name, feedback.phone FROM customer, feedback WHERE feedback.customer = customer.number;
Немного забегая вперёд
При работе с SQLite3 вы фактически используете стандарт разработки SQL92. В данных базах отсутствует возможность программного указания связей ключей и их направление ( лево-правые, внутренние-внешние), потому я просто использовал сбор данных по совпадениям ключей. Также в SQLite3 существует такая вещь, как автоинкрементные ключи, которые при добавлении записи вычисляются автоматически и добавляются без участия разработчика. Вариант идеален для маленьких программ с простой предметной областью.
Как видите, схема данных достаточно проста и позволяет проводить взаимодействие данных на примитивном уровне, что значительно сокращает количество кода как на стороне скриптов, так и на стороне базы.
Теперь рассмотрим модуль, начиная с самой базы. Она представляет собой набор таблиц с автоинкрементными полями:
Таблица содержит в себе пересечение следующих сущностей:
Журнал документов здесь — форма дублирования запроса на отображение. Как и все отображения, быстро не обновляется.
На первой схеме стрелками показанны векторы переноса данных из первичных ключей. Каждый из них имеет связь с родительским массивом и создаёт соответствующую схему данных:
- Телефонный справочник имеет три атрибута: порядковый номер, ссылка на клиента и номер телефона;
- Справочник клиентов имеет: порядковый номер и наименование клиента;
- Справочник позиций имеет: порядковый номер, наименование позиции и её стоимость;
- Каталог документов имеет: порядковый номер, ссылку на клиента, ссылку на позицию и входящие средства.
Исходя из этой схемы, я принял решение разместить отдельный модуль доступа к базе, заставив исполнительные модули формировать запрос внутри себя. По-хорошему, нужно будет сделать функцию для вызова общих представлений, обновления записей и вставки, но я это сделаю позже, ибо есть риск укрупнения библиотеки и повторения функционала (и fetch, по хорошему, лучше делать в исполнительном модуле):
Модуль database.lua:
local database = {}
function database.link()
driver = require "luasql.sqlite3"
env = driver.sqlite3()
db = env:connect("standart.sqlite3")
return db
end
return database
Здесь в модуле создаётся экземпляр модуля управления базой luasql.sqlite3, инициализируется драйвер базы, затем ему скармливается сама база. Активация запроса в исполнительном модуле происходит следующим образом:
base = require "database"
query = base.link() --[[ Вызов модуля базы и линковка экземпляра запроса --]]
str = 'SELECT number, name FROM customer;'
thread = query:execute(str)
data = thread:fetch({}, "a") --[[ Формирование запроса, исполнение и парсинг данных --]]
while data do
print("| № " .. data.number .. " | " .. data.name .. " | ")
data = thread:fetch(data, "a") --[[ Получаем данные построчно и выводим также, как из обычной таблицы в Lua --]]
end
В связи с высказаным мной предположением в части 3-й и 4-й я решил модифицировать модуль базы. Изменение этого модуля повлекло модификацию всех исполнительных. Но это того стоило. Модификация состоит в том, что для вызова СУБД — зависимых запросов можно настроить однотипные процедуры, принимающие параметры на входе.
Рассмотрим функцию database.select_from_where(select, from, where), которая часто используется в процедурах для получения табличной информации:
function database.select_from_where(select, from, where)
text = "SELECT " .. select .. " FROM " .. from
if where ~= nil then
text = text .. " WHERE " .. where .. " ;"
else
text = text .. " ;"
end
query = database.link()
thread = query:execute(text)
result = thread:fetch({}, "a")
return result
end
Вызывается это благолепие командой:
base = require "database"
data = base.select_from_where( "number, name" , "customer" , nil )
Дальше всё это обрабатывается через цикл и построчно извлекаются данные:
while data do
print("| № " .. data.number .. " | " .. data.name .. " | " .. data.phone .. " |" )
data = thread:fetch(data, "a")
end
Здесь заполняется первоначальный вызов функции fetch() для последующего снижения дублирования везде, где только возможно. Таким образом мы вырезаем половину кода из модулей исполнения и передаём им массив с данными по запросу.
Следующая функция — database.update_set_where(update, set, where) — используется для обновления данных без индексного удаления. Это ситуации, в которых нам надо изменить данные позиции / пользователя без перелапачивания документов и данные выплат по позиции:
function database.update_set_where(update, set, where)
text = "UPDATE " .. update .. " SET " .. set .. " WHERE " .. where .. " ;"
query = database.link()
thread = query:execute(text)
end
В функцию забивается имя таблицы, имя столбца для изменения и условие обновления. Здесь можно указать ячейку с конкретным значением полей или целую группу. В случае некорректного ввода данных (например, изменилась цена на несколько категорий) информацию можно изменить очень быстро.
Важное замечание при создании процедур, управляющих изменением данных базы:
Когда работаете с базами Вам необходимо корректно обрабатывать следующие аспекты:
Без этих правил запись / чтение данных будет стопориться при каждой ошибке запроса.
- Соблюдение изоляции текстовых аргументов запроса (чаще всего одинарной кавычкой, но зависит от СУБД);
- Соблюдение пространства между ключевыми словами (SELECT, WHERE, FROM и прочих из языка SQL) и данными запроса;
- Соблюдение порядка запроса и изолирующих знаков — сначала идут ключевые слова, заключившие данные в своих блоках, затем завершаем дело точкой с запятой.
- В случае изменения больших объёмов однотипных данных (запрос на внос — вынос данных, создание / изменение документа и прочее, что передаётся в едином логическом блоке) рекомендуется использовать механизм транзакций. Но это в случае превышения суммарного объёма записей свыше 10000 штук.
Без этих правил запись / чтение данных будет стопориться при каждой ошибке запроса.
Функция database.delete_from_where(from, where) используется для ликвидации данных в таблицах. дабы исключить случайное уничтожение всех данных в таблице, функция создаёт строку с параметром сравнения:
function database.delete_from_where(from, where)
text = "DELETE FROM " .. from .. " WHERE " .. where .. " ;"
query = database.link()
thread = query:execute(text)
end
И последняя, часто используемая функция — database.insert_into_values(table, fields, values) — предназначенная для вставки данных:
function database.insert_into_values(table, fields, values)
text = "INSERT INTO " .. table .. " ( " .. fields .. " ) VALUES ( " .. values .. ") ;"
query = database.link()
thread = query:execute(text)
end
Как видите, во всех функциях, кроме SELECT'а, используется элементарное исполнение запроса. Прикол в том, что базы SQLite3 по окончании записи / модификации строки не выдают значение индеска, как это делает Firebird. По этой причине приходится запускать поиск индекса добавленной строки при последующем добавлении индекса в связаные таблицы.
Таким образом, все вышеуказаные функции сводят 4-6 строк на исполнение запроса в модулях бизнес-логики до 1-5 строчек на каждую. Такая оптимизация вдогонку улучшила удобочитаемость исполнительных модулей.
За сим откланяюсь. В следующей статье распишу работу управляющего модуля.
P.S. Маленькая просьба — если хотите передать замечание по этому циклу статей, прошу предварительно прочитать статью «Разработка микро-учётной системы на lua, часть вторая. Постановка задачи», в которой я указываю условия разработки программы и функции, которые на неё возлагаются. Учитывайте это.
UPD. В комментариях высказывалось опасение в плане преобразования вещественного числа с плавающей запятой из текста в число. Оказалось, что функция tonumber() преобразует строку формата «целая_часть.дробная» в соответствующий числовой эквивалент, причём можно даже не прибегать к этой функции:
a = "3.1416" + 6
c = a - 9
print(c)
В памяти число сохраняется в виде «34E2».
Для очистки совести я проверил предположение, добавив позицию с дробным значением:
Проверить можно с помощью следующей команды:
bc -l <<< '(300+33.5+36.9+48.7) - (250+22.5+22.5+22.5)'
Для сомневающихся уточняю — речь идёт о стандартных двух знаках после запятой.
Поделиться с друзьями

impwx
Зря используете
REALдля хранения денежных значений — баланс может случайно не сойтись из-за округлений.hantenellotf
1) Так эта балансовая строчка видна прямо перед носом — если будет несоответствие вычислениях, оно будет видно.
2) Стоимость материнских плат и иных деталей частенько имеет копеечный довесок. Потому REAL здесь и необходим.
impwx
1) В одной строчке вы разницы не заметите, но если будете активно суммировать или умножать на количество, то можно поймать очень неприятный и трудноуловимый баг. Вот пара примеров подобных ситуаций.
2) В таких случаях цену обычно хранят в виде целого числа в копейках, а в рубли переводят уже финальный результат после всех вычислений.
Greendq
Во многих системах деньги хранят в тысячных, десятитысячных и так далее долях мельчайшей денежной единицы (т.е. копеек/центов) и в виде целого числа. Тогда даже за год разницы на округлениях не набегает :)
hantenellotf
tonumber() преобразует числа как с нулевой, так и с плавающей запятой.
Фактически, в интерпретаторе можете ввести:
napa3um
Деньги принято хранить целым типом в копейках или сотых долях копейки (если СУБД не поддерживает денежный тип или тип с фиксированной запятой). При умножении и делении принято применять что-то типа «банковского округления» — https://ru.m.wikipedia.org/wiki/%D0%9E%D0%BA%D1%80%D1%83%D0%B3%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5 (там же объясняется, почему).
hantenellotf
Для данной программы это не имеет смысла. Читайте вторую статью.
napa3um
Попробуйте выполнить print(0.1 + 0.2 == 0.3).
Погуглите слова «sqlite money format» и «ieee 754 round errors».