
Теперь немного сосредоточимся на такой вещи, как база данных.
База данных — структурированная совокупность информации, приведённая в форму, достаточную для её обработки электронной вычислительной машиной (а как же квантовые компьютеры? — когда появятся, тогда и сменим определение). За более точным определением обращайтесь к Википедии
Фактически, база данных представляет собой множество таблиц, связанных собой разными способами. В нынешних СУБД используется реляционная математика, описывающая данные, как взаимодействие множеств данных. Грубо говоря, есть множество А, в котором содержится шапка-описание ячеек таблицы и множество В, в котором содержится нумерация строк. Пересечением этих множеств становится множество данных С, в котором определяются хранимые данные.
Таким образом формируется таблица базы. Однако, существует большое количество баз, которые нам нужно между собой стыковать. Каким, скажете вы, образом?
В первых база использовалась так называемая иерархическая система связи. Фактически, у нас имелась сущность «Ёжик», которые имела различные аттрибуты: лапы, хвост, усы, когти и прочее. Эти аттрибуты имели свои свойства: длина, толщина, прочность. Всё это можно было реализовать в числовых величинах. Подобная система управления данными впоследствии привела к созданию таким вещей, как XML.
У этой системы был достаточно существенный недостаток — большое время извлечения данных. Грубо, чтобы выяснить какой-то кусок данных, например, свойство или наименование, требовалось каждый раз расковыривать всю ветку данных. Причём, количество заходов равнялось количеству рассматриваемых данных плюс путь по ветке до каждого из них. Также добавим, что такие базы сжирали много процессорного времени.
По иному работала реляционная модель данных, созданая 1969-1970 годах доктором Эдуардо Франком Коддом из IBM. Фактически, он предложил рассматривать взаимодеиствие данных, как разноуровневое взаимодействие множеств данных и аттрибутов, их описывающих. Он реализовал взаимодействие данных сначала на уровне таблиц, затем, на уровне связей и пересечений.
Помните старую модель базы, которую я выкладывал в ранних статьях? Теперь можно рассмотреть её в рамках реляционной модели:
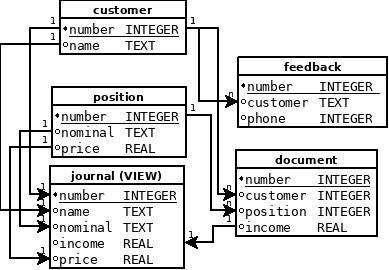
Каждая из таблиц представляет собой произведение двух множеств (точнее, одномерных таблиц), создающих матрицу. Для соединения используется набор столбцов из этих матриц, которые называются "ключами" — набором данных, однозначно определяющих строчный объём в таблице.
По степени упорядоченности использования ключей выделяются так называемые нормальные формы:
Исходя из данных определений, я собрал базу между BSNF и 5NF. Это позволяет мне в единичном запросе забрать тот объём данных, который мне нужени и тратить меньше аппаратных ресурсов для изменение данных.
Стрелки указывают связь данных из индексных таблиц (имеющих индексные ключи и минимальный объём столбцов, им определяемых) в таблицы отношений. Таблицы отношений (например, document или position) содержат в себе как свои ключи, так и ключи для связи с другими таблицами. С помощью этих ключей потом очень удобно извлекать данные, используя элементарное соответствие ключевых значений строк:
Как видите, схема данных достаточно проста и позволяет проводить взаимодействие данных на примитивном уровне, что значительно сокращает количество кода как на стороне скриптов, так и на стороне базы.
P.S. Маленькая просьба — если хотите передать замечание по этому циклу статей, прошу предварительно прочитать статью «Разработка микро-учётной системы на lua, часть вторая. Постановка задачи», в которой я указываю условия разработки программы и функции, которые на неё возлагаются. Учитывайте это.
База данных — структурированная совокупность информации, приведённая в форму, достаточную для её обработки электронной вычислительной машиной (а как же квантовые компьютеры? — когда появятся, тогда и сменим определение). За более точным определением обращайтесь к Википедии
Фактически, база данных представляет собой множество таблиц, связанных собой разными способами. В нынешних СУБД используется реляционная математика, описывающая данные, как взаимодействие множеств данных. Грубо говоря, есть множество А, в котором содержится шапка-описание ячеек таблицы и множество В, в котором содержится нумерация строк. Пересечением этих множеств становится множество данных С, в котором определяются хранимые данные.
Таким образом формируется таблица базы. Однако, существует большое количество баз, которые нам нужно между собой стыковать. Каким, скажете вы, образом?
В первых база использовалась так называемая иерархическая система связи. Фактически, у нас имелась сущность «Ёжик», которые имела различные аттрибуты: лапы, хвост, усы, когти и прочее. Эти аттрибуты имели свои свойства: длина, толщина, прочность. Всё это можно было реализовать в числовых величинах. Подобная система управления данными впоследствии привела к созданию таким вещей, как XML.
У этой системы был достаточно существенный недостаток — большое время извлечения данных. Грубо, чтобы выяснить какой-то кусок данных, например, свойство или наименование, требовалось каждый раз расковыривать всю ветку данных. Причём, количество заходов равнялось количеству рассматриваемых данных плюс путь по ветке до каждого из них. Также добавим, что такие базы сжирали много процессорного времени.
По иному работала реляционная модель данных, созданая 1969-1970 годах доктором Эдуардо Франком Коддом из IBM. Фактически, он предложил рассматривать взаимодеиствие данных, как разноуровневое взаимодействие множеств данных и аттрибутов, их описывающих. Он реализовал взаимодействие данных сначала на уровне таблиц, затем, на уровне связей и пересечений.
Помните старую модель базы, которую я выкладывал в ранних статьях? Теперь можно рассмотреть её в рамках реляционной модели:
Каждая из таблиц представляет собой произведение двух множеств (точнее, одномерных таблиц), создающих матрицу. Для соединения используется набор столбцов из этих матриц, которые называются "ключами" — набором данных, однозначно определяющих строчный объём в таблице.
По степени упорядоченности использования ключей выделяются так называемые нормальные формы:
- 1NF — первая нормальная форма. Все строки таблиц содержат уникальную по отношению к другим совокупность данных
- 2NF — вторая нормальная форма. Уже существует какой-то набор столбцов, однозначно определяющих строку таблицы
- 3NF — третья нормальная форма. В качестве ключевых столбцов используется множество, которое однозначно определяет запись (строку).
- BSNF (Boyce-Codd normal form) — нормальная форма Бойса-Кодда (на студенческом жаргоне: «Бойся кода!»). Всякая зависимость внутри и между таблиц напрямую определяется ключевым значением.
- 5NF — пятая нормальная форма. Каждая зависимость внутри и снаружи точно определена ключом.
- 6NF — шестая нормальная форма. Каждая зависимость внутри и снаружи однозначно определена минимально возможным ключём. Фактически, таблицу в этой форме невозможно преобразовать в более простую или добавить дополнительных связей.
Исходя из данных определений, я собрал базу между BSNF и 5NF. Это позволяет мне в единичном запросе забрать тот объём данных, который мне нужени и тратить меньше аппаратных ресурсов для изменение данных.
Стрелки указывают связь данных из индексных таблиц (имеющих индексные ключи и минимальный объём столбцов, им определяемых) в таблицы отношений. Таблицы отношений (например, document или position) содержат в себе как свои ключи, так и ключи для связи с другими таблицами. С помощью этих ключей потом очень удобно извлекать данные, используя элементарное соответствие ключевых значений строк:
/* Пример: в таблице Customer есть клиент Miku Hatsune Yamaha. Её строка имеет индекс 1. Нам необходимо добавить новый номер телефона в справочник feedback, в котором находится ячейка с индексом клиента-владельца телефона */
SELECT number, name FROM customer WHERE number = 1;
/* Здесь мы удостоверяемся, что Miku стоит первая */
INSERT INTO feedback (customer, phone) VALUES ( 1, 89603347382 );
/* Здесь мы добавляем телефон и тут же устанавливаем связь с таблицой customer, в которой содержится индекс клиента. Теперь можно извлечь и телефон, и клиента следующим образом: */
SELECT customer.number, customer.name, feedback.phone FROM customer, feedback WHERE feedback.customer = customer.number;
Немного забегая вперёд
При работе с SQLite3 вы фактически используете стандарт разработки SQL92. В данных базах отсутствует возможность программного указания связей ключей и их направление ( лево-правые, внутренние-внешние), потому я просто использовал сбор данных по совпадениям ключей. Также в SQLite3 существует такая вещь, как автоинкрементные ключи, которые при добавлении записи вычисляются автоматически и добавляются без участия разработчика. Вариант идеален для маленьких программ с простой предметной областью.
Как видите, схема данных достаточно проста и позволяет проводить взаимодействие данных на примитивном уровне, что значительно сокращает количество кода как на стороне скриптов, так и на стороне базы.
P.S. Маленькая просьба — если хотите передать замечание по этому циклу статей, прошу предварительно прочитать статью «Разработка микро-учётной системы на lua, часть вторая. Постановка задачи», в которой я указываю условия разработки программы и функции, которые на неё возлагаются. Учитывайте это.
Поделиться с друзьями