
Мы продолжаем публиковать лекции Натальи Васильевой, старшего научного сотрудника HP Labs и руководителя HP Labs Russia. Наталья Сергеевна читала курс, посвящённый анализу изображений, в петербургском Computer Science Center, который создан по совместной инициативе Школы анализа данных Яндекса, JetBrains и CS-клуба.
Всего в программе — девять лекций. Первая из них уже была опубликована. В ней рассказывалось о том, в каких областях встречается анализ изображений, его перспективах, а также о том, как устроено наше с вами зрение. Вторая лекция посвящена основам обработки изображений. Речь пойдет о пространственной и частотной области, преобразовании Фурье, построении гистограмм, фильтре Гаусса. Под катом — слайды, план и дословная расшифровка лекции.
Пространственная область:
Частотная область, преобразование Фурье:
Обработка в пространственнои? и частотной области:
Всего в программе — девять лекций. Первая из них уже была опубликована. В ней рассказывалось о том, в каких областях встречается анализ изображений, его перспективах, а также о том, как устроено наше с вами зрение. Вторая лекция посвящена основам обработки изображений. Речь пойдет о пространственной и частотной области, преобразовании Фурье, построении гистограмм, фильтре Гаусса. Под катом — слайды, план и дословная расшифровка лекции.
План лекции
Пространственная область:
- представление цифровых изображении? (recap);
- пространственная область;
- представим «одномерную картинку»;
- 1-D изображение.
Частотная область, преобразование Фурье:
- частотное представление – основная идея;
- преобразование Фурье для изображении? – основная идея;
- преобразование Фурье;
- двумерныи? случаи?;
- визуализация Фурье-спектра;
- примеры.
Обработка в пространственнои? и частотной области:
- гистограммы;
- гистограммы — коррекция;
- результат эквализации гистограммы;
- пороговая бинаризация;
- глобальная бинаризация;
- примеры бинаризации;
- выделение компонент связности;
- компоненты связности;
- фильтрация (свертка изображения с фильтром);
- теорема о свертке;
- сглаживание;
- сглаживание фильтром Гаусса;
- сглаживание фильтром Гаусса: пример;
- выделение деталеи?;
- обнаружение линии?;
- выделение границ: примеры;
- обнаружение границ;
- градиент изображения;
- вычисление градиента изображения;
- пример;
- обнаружение контуров: вычисление производных;
- повышение резкости;
- фильтр Unsharp;
- Mexican hat.
Полная текстовая расшифровка лекции
Сегодня мы будем говорить о классических и простейших методах обработки изображений. Чему мы должны научиться из этой лекции:
Кроме этого, мы познакомимся с тем, что есть представление изображения в пространственной области и что подразумевается под представлением изображения в частотной области.
Невозможно улучшить изображения без понимания того, зачем вы это делаете. Цели могут быть две: поправить его, чтобы оно было таким, каким будет вам больше нравиться, или преобразовать, чтобы компьютеру было проще обсчитывать некоторые его признаки и извлекать полезную информацию.
Вспомним, что картинка представляется в виде функции от x и y. Если мы говорим о полноценном изображении, то каждое значение этой функции – трёхзначное число, которое представляет собой значение для каждого из цветовых каналов.

Представление изображения в пространственной области – это то, как мы привыкли понимать и видеть изображение. Есть x и y, и в каждой точке у нас есть какое-то значение интенсивности или значение цветового канала.
На этом слайде Лена и логотип библиотеки OpenCV разложены на три цветовых канала — красный, зелёный и синий.

Вспомним, что если нет источника света, мы получаем чёрный цвет. Если же объединить источники всех трёх первичных цветов, то мы получим белый цвет. Это означает, что в более темной области нет схождения данного цветового канала.
Это привычное пространственное представление. Дальше речь пойдет в основном о чёрно-белых картинках, но в принципе все алгоритмы будут применимы и к цветным изображениям.
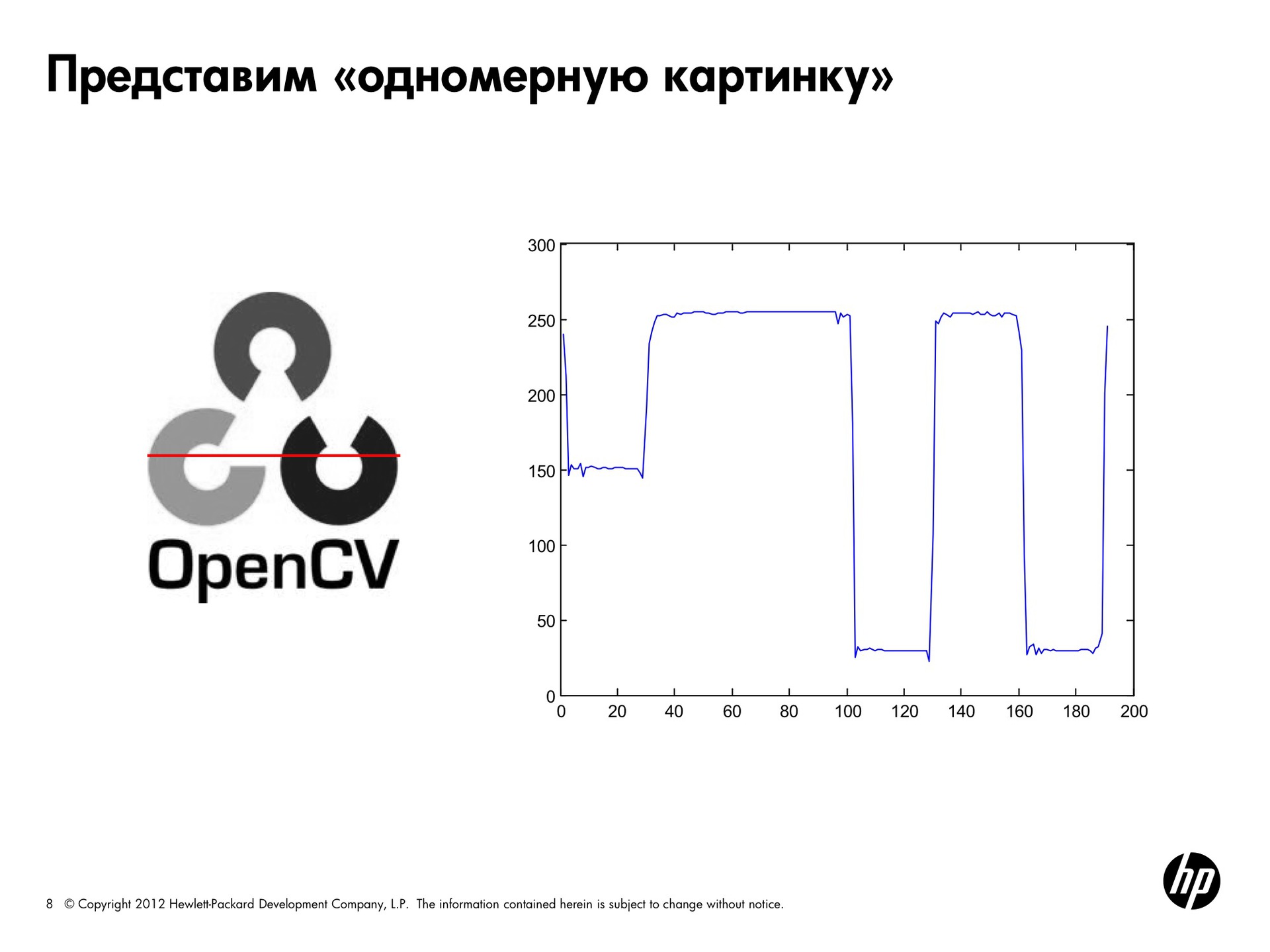
Чтобы упростить задачу, представим, что наше изображение одномерное. Линия, которая идёт слева-направо, отображает все изменения яркости. Всплеск в начале соответствует паре пикселов белого цвета, потом идёт серая область, потом — снова белая. На черном цвете мы проваливаемся вниз. То есть по этой линии можно проследить, как изменяется яркость.
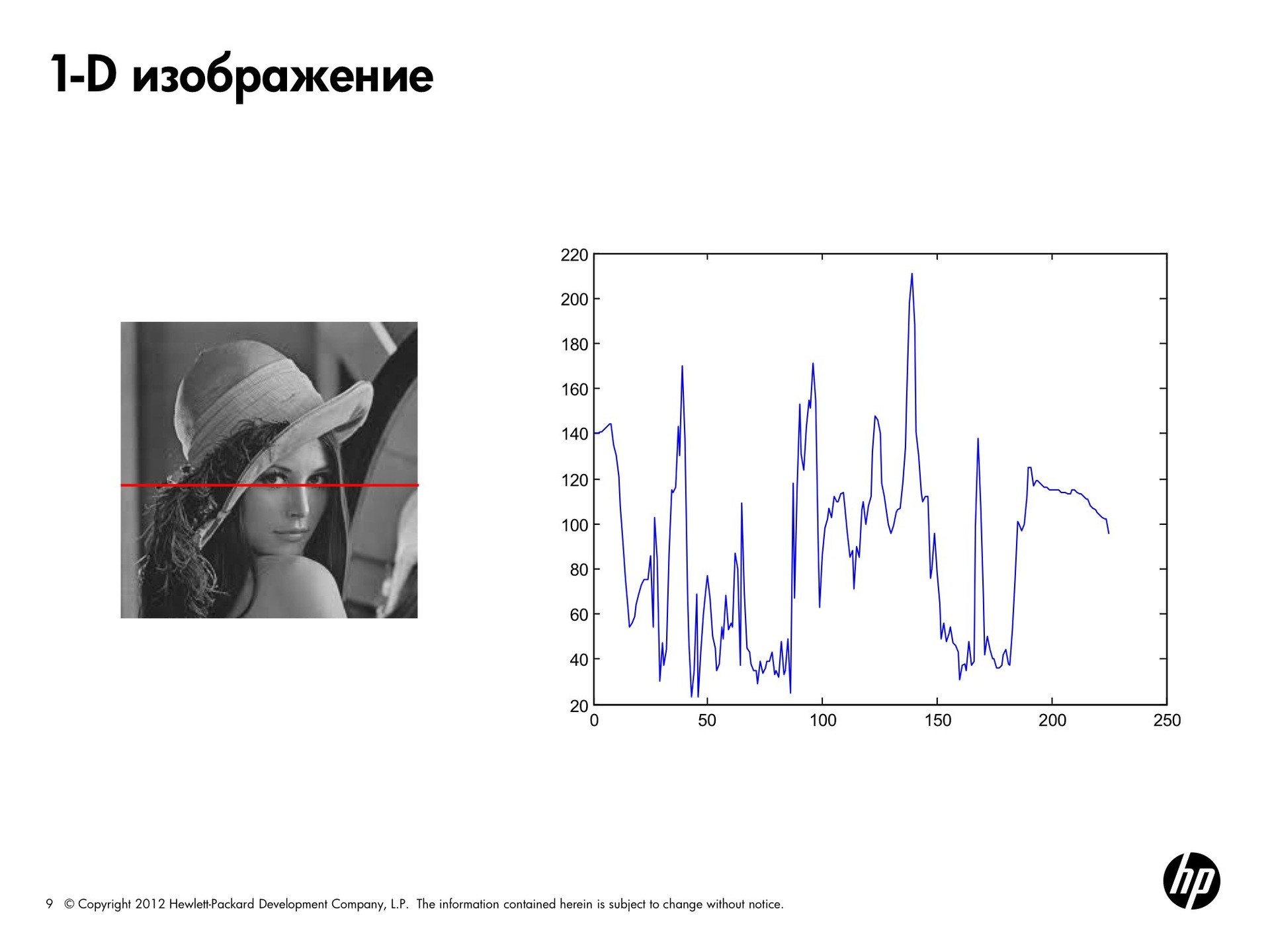
Посмотрим еще один пример.
Как еще можно описать информацию, содержащуюся в нашем сигнале, кроме данных о её яркости? Можно разложить его на компоненты, то есть, например очень сильно сгладить кривую чтобы отследить общий тренд. У нас он идёт сначала вниз, потом вверх, потом опять вниз и опять вверх. Получаем практически асимптотическое приближение к этой штуке.
Дальше можем посмотреть на детали покрупнее, т.е. какие бывают всплески, на детали помельче. К чему я клоню: в принципе можно разложить эту функцию на гармонические составляющие. Для тех, кто помнит что такое ряд Фурье, согласно одноимённой теореме любую функцию (она сказала — периодическую, но это неверно, вообще любую функцию) можно представить как сумму синусов и косинусов различных частот и амплитуд, что здесь и показано. Эта искусственно генерированная функция является суммой этих четырёх функций.
Что мы можем с этим сделать? Представим, что у нас есть некий базис, который задаётся набором этих синусоида и косинусов. Мы знаем частоту каждой базисной функции. Тогда для представления исходной функции нам нужно знать только коэффициенты, скаляр, на которые нужно умножить каждую из базисных функций.
Основная идея преобразования Фурье — это то, что любая картинка может быть представлена в виде суммы синусов и косинусов. Почему любая? Потому что любая периодическая функция может быть всегда представлена в виде суммы синусов и косинусов. Непериодическая же функция, если площадь графика под ней конечна (что всегда будет верно для изображения), тоже может быть представлена как сумма синусоида и косинусов. Чтобы представить такую функцию абсолютно точно, их должно быть бесконечно много, но, тем не менее, это сделать можно.
Частоты таких слагаемых и будут характеризовать изображение. Для каждой картинки мы говорим, какая из базисных частот в ней преобладает.
Что мы можем сказать о коэффициентах базисных функций? Если у нас большой коэффициент перед базисной функцией с высокой частотой, это означает, что яркость изменяется достаточно часто. На картинке очень много перепадов яркости в маленьких локальных регионах. Если картинка описывается плавными синусоидами, с низкой частотой, то это означает, что на картинке много однородных областей, яркость изменяется плавно, или картинка, например, была «забурена».
Таким образом, можно использовать отображение в частотной области для описания изображений.
Берём исходный сигнал, представляем его в виде суммы колебаний одинаковой амплитуды и разных частот, умножаем их на скальные коэффициенты и получаем разложение исходной функции вот по такому новому базису.
Теперь представьте себе, что вы пытаетесь передать кому-то картинку с помощью мобильного телефона. Раньше вам бы потребовалось передать все 230 значений яркости. Но теперь, если приёмная и принимающая сторона «знают», какие у нас базисные функции, то объём посылаемой информации значительно сокращается. Вы можете передать ту же информацию, используя существенно меньше параметров.
Почему преобразование Фурье так популярно при обработке изображений? Оно позволяет существенно сократить объём передаваемой информации, достаточной для восстановления изображения в прежнем виде. Также преобразование Фурье облегчает процесс фильтрации, но об этом позже. Преобразование Фурье хорошо тем, что оно обратимо. Мы разложили нашу функцию на частотные составляющие с коэффициентами, но можем вернуться и обратно из частотного представления в пространственное.
Теоретически мы можем представить функцию в качестве бесконечного набора синусоида, но на практике (поскольку бесконечность недостижима), ограничиваются только несколькими первыми слагаемыми (с самыми большими коэффициентами). Картинка при восстановлении обратно в пространственную область будет чуть-чуть отличаться от оригинала, то есть часть информации будет безвозвратно потеряна. Тем не менее, использование ограниченного количества составляющих позволяет в достаточной степени восстановить изображение.
Как же посчитать значения скаляров для заранее заданного базиса частот? Для преобразования Фурье, когда у нас в качестве базисных функций присутствуют гармоники — синусы и косинусы. И есть обратное преобразование Фурье, которое позволяет по набору коэффициентов, зависящих от частоты, восстановить исходное представление в пространственной области.
Здесь гармоники — это те самые синусы и косинусы, которые нарисованы на предыдущем слайде. Для каждой фиксированной частоты есть некая функция от x.
Надеюсь, что с одноименным случаем более или менее понятно. Теперь посмотрим на двумерный случай, потому что картинка у нас двухмерна.
Здесь мы тоже можем построить двухмерные гармоники, которые уже будут зависеть от четырёх параметров: x, y (от двух направлений) и от двух частот в направлении x и y соответственно.
Возьмём, к примеру, такой квадрат. Здесь нарисован и вид сверху, и в изомеры. Мы видим, как наша гармоника плавно переходит из одного угла в другой. Здесь мы опять можем применить прямое преобразование Фурье, и обратное, где у нас есть коэффициенты уже для двух фиксированных частот, чтобы снова получить пространственное представление.
Теперь посмотрим, что можно понять при визуализации результата прямого преобразования по так называемому спектру Фурье. Хотя мы говорим о преобразовании Фурье, но также можно использовать и любое другое преобразование сигнала, где в качестве базисных функций выберем не гармоники, а какие-то другие функции. Часто в качестве базисных функций используют [вейвлеты]. Они в некотором смысле более удачны, чем синусы и косинусы.
Попробуем рассмотреть град из значений наших скаляров. Тут у нас дискретный случай — как выглядит базисная функция при фиксированных u и v. Расположим их вдоль осей соответственно u и v. На этом гриме спектр Фурье представляет собой отображение значений коэффициентов. Важно понимать, что в центре у нас частота нулевая, а к краям она увеличивается.
Дальше, если каждую ячейку начнём складывать значение параметра F, коэффициента, который мы получили при разложении. Чем больше коэффициент, тем ярче он будет отображаться на спектре. То есть, мы хотим визуализировать спектр Фурье. Если коэффициент F=0, будем отображать его чёрным цветом. Чем он больше, тем светлее цвет.
На двумерном спектре всего один пиксел будет соответствовать u=0, v=0, следующий — U= -1, V=0. Значение пиксела будет равняться коэффициенту, полученному из преобразования. Важно то, что центральные коэффициенты соответствуют важности этой гармоники в представлении изображения, в центре стоят гармоники с нулевыми частотами. То есть, на картинке, если у нас будет очень большой отклик вот здесь, это значит, что картинка практически не меняет своей яркости. Если у картинки будет здесь тёмное пятно, а по периферии — светлое, то она пёстрая — там перепад яркости в каждой точке и в каждом направлении.
Картинка — это не спектр, это визуализация двумерной синусоиды.
Посмотрим на эту картинку. Обычно рисуют логарифм от спектра, иначе он получается очень тёмный. Но для большинства картинок типично светлое пятно в центре, потому что на картинках много однородных областей. Нужно иметь в виду, что когда частота у нас равна нулю, то перепада яркости нет. В случае, если есть перепад яркости, то, в какую точку спектра внесёт вклад этот перепад, будет зависеть от направления контура, от направления перепада. Тут у нас есть края, но они размазаны по периферии, ярких откликов не получается.
Перейдём к тому что можно делать с изображениями. Начнём с простейших, интуитивно понятных преобразований в пространственной области.
Если у нас яркость изменяется от 0 до 255, то для каждого пиксела пишем 255 минус его прежнее значение. Чёрное становится белым, а белое — чёрным.
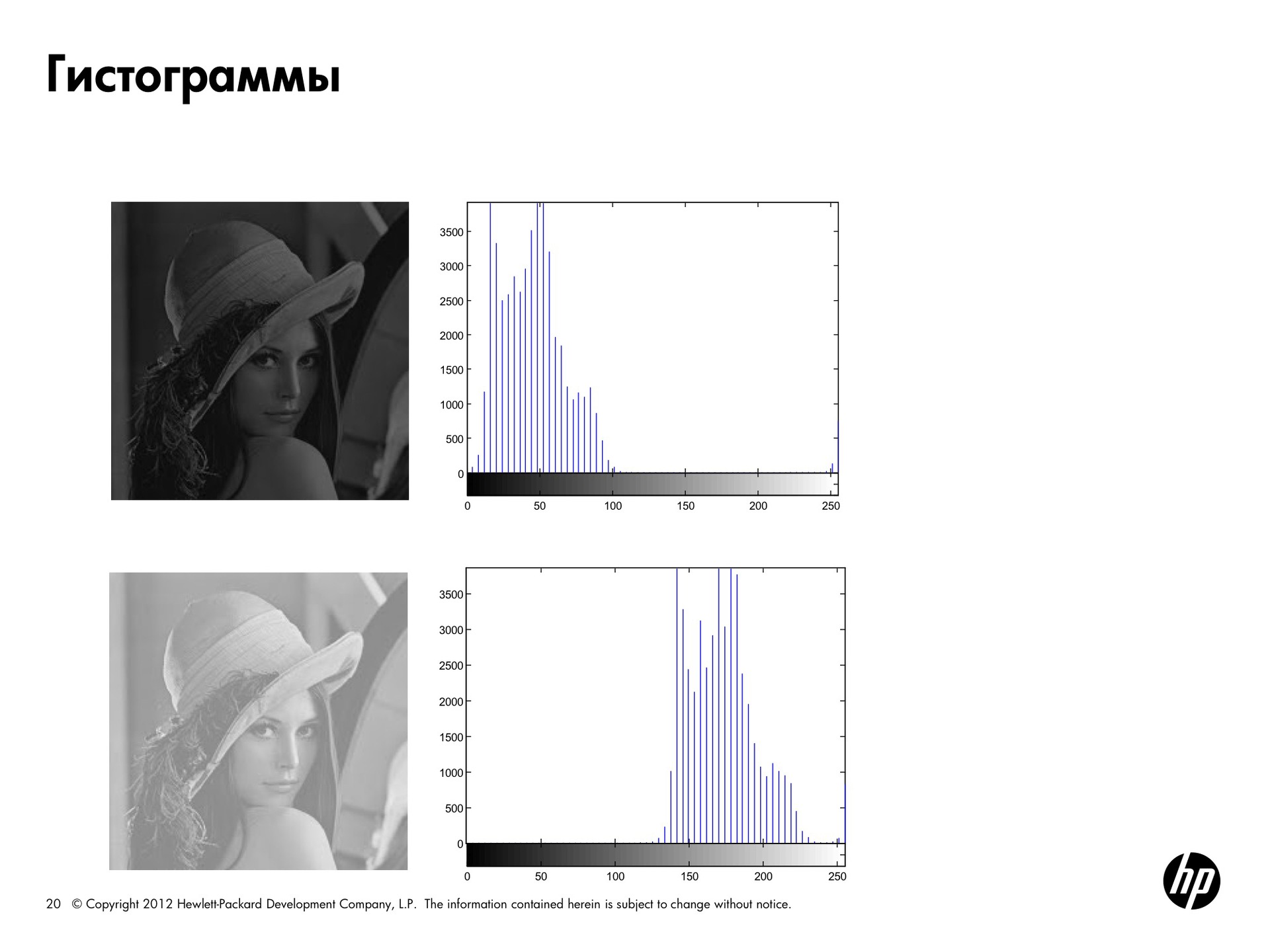
Одним из наиболее простых и практичных видов представления картинки является гистограмма. Для любого изображения можно посчитать, сколько пикселов с нулевой яркостью, сколько с яркостью 50, 100 и так далее, и получить некое распределение частотности.
На этой картинке у Лены отрезаны все точки яркости, которые больше 125. Получаем гистограмму, смещённую влево, и тёмную картинку. На второй картинке все наоборот — есть только светлые пикселы, гистограмма смещена вправо.
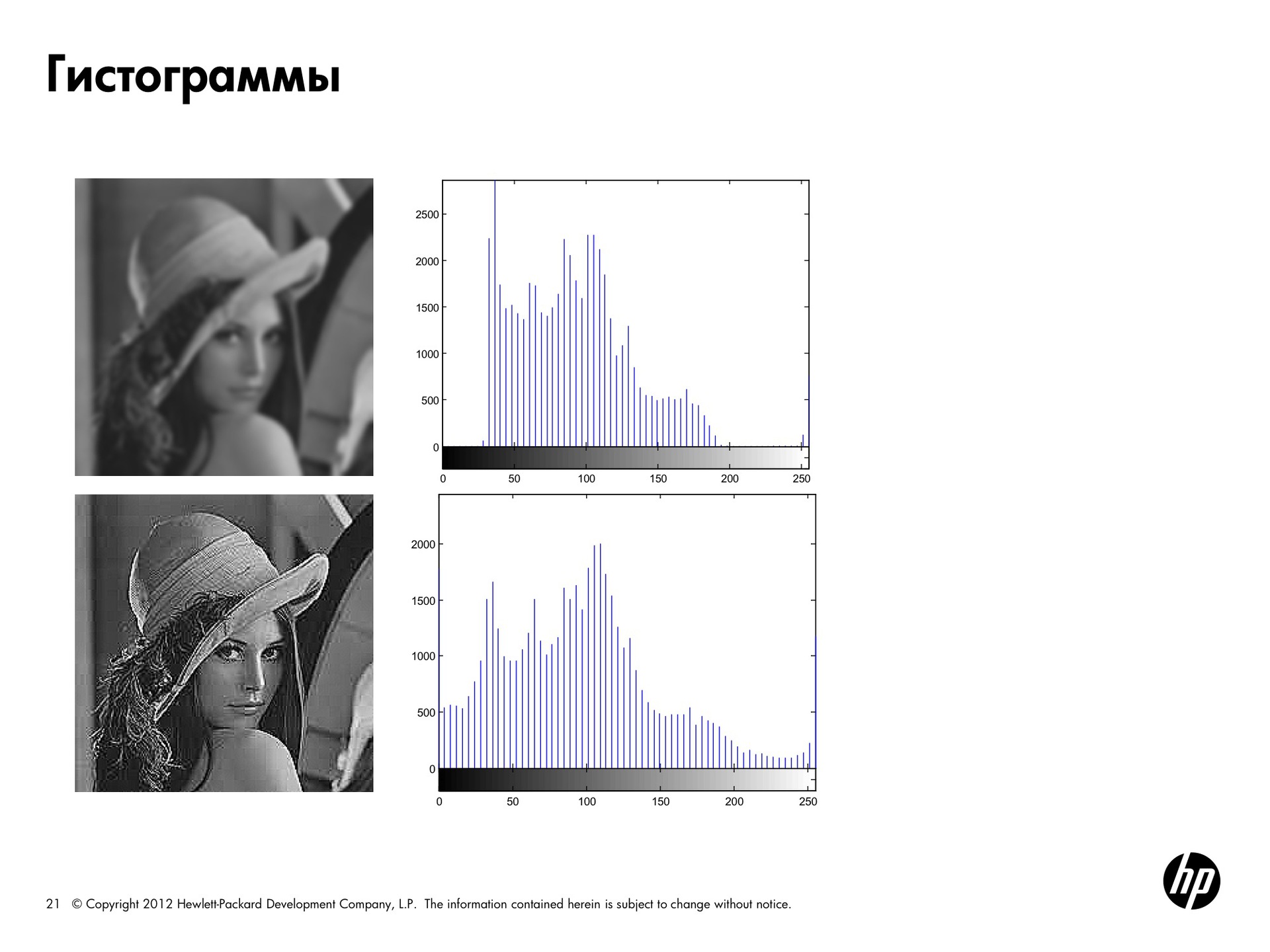
Следующая картинка размазана, у неё нет чётких контуров. Для такой картинки характерен столбик яркости где-то посередине и отсутствие энергии по краям спектра.
Для второй Лены с этого слайда была сделана обработка, чтобы подчеркнуть каждый из контуров, то есть сделать сильнее перепады яркости. Здесь гистограмма занимает весь диапазон яркости.
Что можно делать с гистограммами? По форме гистограммы уже можно многое рассказать о её свойствах. Дальше можно что-то сделать с гистограммой, изменить её форму, чтобы картинка стала выглядеть лучше.
Для тёмной картинки гистограмму можно растянуть вправо, и тогда картинка станет светлее, а для светлой — наоборот. Это верно для любой формы. Если гистограмма картинки не покрывает весь частотный диапазон, то при равномерном растягивании картинка станет более контрастной и будет лучше видно детали.
Только что мы делали линейные преобразования гистограммы. Можно делать нелинейные преобразования, которые называют экранизацией или линеоризацией. Это позволяет из исходной гистограммы получить более равномерную с примерно одинаковым количеством пикселов каждой яркости.
Делается это так. В формуле xk — это некий уровень яркости, nk — количество пикселов такой яркости, n- общее количество пикселов. Мы выбираем какой-то пиксел и получаем вероятность, с которой он будет цвета xk. То есть, количество пикселов nk делить на общее количество пикселов. На самом деле — доля.
Попытаемся получить равномерную плотность вероятности, то есть, чтобы для каждого цвета была одинаковая вероятность его получить. Это достигается следующим преобразованием. Если мы по пикселю цвета xk вычислим новые значения яркости для него yk по формуле, то есть возьмём и пронумеруем все вероятности oт i до этого цвета, гистограмма получится более равномерная. То есть, исходная затемнённая картинка выглядела вот так, а если мы к яркостям этой картинки применим экранизацию, то в результате получим гистограмму вот такой формы. Как вы видите, они гораздо более равномерно распределены по всем возможным значениям, и картинка будет выглядеть вот так.
Сделаем то же самое для светлой картинки. И гистограммы практически совпадают, потому что изначально картинки были получены из одной и той же картинки.
Вот результаты эквализации для резкой и размытой картинок. Видно, что для резкой картинки изображение почти не изменилось, но гистограмма стала немного ровнее.
Мы уже отказались от цветных изображений и говорим только о чёрно-белых, где есть различные градации серого. Бинаризация — это продолжение издевательства над изображением, когда мы отказываемся еще и от них. В итоге получаем картинку, где есть только чёрный и белый. Нам нужно понять, какие пикселы мы хотим сделать чёрными, а какие — белыми.
Это упрощает дальнейший анализ изображения для многих задач. Если есть картинка с текстом, к примеру, то хорошо бы чтобы все буквы на картинке оказались белыми (или чёрными), а фон — наоборот. Последующему алгоритму распознавания символов будет проще работать с таким изображением. То есть, бинаризация хороша тогда, когда мы хотим чётко отделить фот от объекта.
Поговорим о простейшем типе бинаризации — пороговой. Этот тип вообще-то не очень применим для фотографий, но, тем не менее, иногда используется.

Если мы применяем пороговую бинаризацию к гистограмме, то видим, что у нас в изображении есть два типа пикселов: потемнее и посветлее. Обычно предполагают, что большее количество пикселов соответствует фону. Из этого делаем вывод, что вот тут у нас кучка побольше, она тёмная, соответственно у нас фон — тёмный, и на нём есть один или несколько светлых объектов. Объект может быть составной. Здесь у нас два светлых объекта разного цвета.
Это очень красивые гистограммы, в жизни вы вряд ли такие увидите. Но по ним легко понять, где нужно провести порог, чтобы отделить фон от объекта. Здесь, если мы возьмём пороговое значение ровно между ними, и все пикселы, которые ярче порога, сделаем белыми, а те, которые темнее — чёрными, то мы превосходно отделим объект от фона. Выбрав нужный нам диапазон яркости, мы вырезаем из картинки тот или иной объект.
Бинаризация различается по типам на основании того, каким образом вычисляется порог. При глобальной бинаризации порог един для всех точек изображения. При локальной и динамической бинаризации порог зависит от координаты точки. При адаптивной бинаризации порог зависит еще и от значения яркости в этой точке.
Выбор порога при глобальной бинаризации осуществляется следующим образом. Можно это делать вручную, но вручную естественно никто ничего делать не хочет, а можно выбрать порог автоматически.
Простейший алгоритм таков: вначале берём произвольное значение порога и сегментируем картинку по этому порогу на два региона. В один попадают пикселы со значением больше порогового, в а другой — меньше порогового. Для этих регионов вычисляем среднее значение яркостей. После чего новым порогом считаем их полусумму. Алгоритм заканчивает свою работу, когда после некоторого числа итераций итоговая яркость становится меньше еще одного заданного порогового значения.
На этой картинке представлено преимущество локальной бинаризации.

Если бы бинаризация была глобальной, был бы выбран глобальный порог для всей картинки, то результат бы выглядел так, на картинке b. Пикселы здесь в одной области примерно одного уровня яркости, поэтому вся эта часть получается белой, засвеченной. В том случае, если мы применим простейший вариант локальной бинаризации — то есть поделим изображение на сегменты и будем выбирать порог для каждого сегмента отдельно, — результат бинаризации уже будет выглядеть получше ©.
Для этой картинки гистограмма, скорее всего, будет красивой. Будут пики, а в долине, может, и не будет нулевого значения. Вот светлая область и тёмная. То есть, мы выбрали порог, но его невозможно выбрать таким образом, чтобы выделить этот объект, потому что если порог один, то критерий, по которому мы делаем пиксел чёрным или белым, один для всех пикселов картинки. При этом цвет одинаковый, при едином пороге мы никогда не сможем отнести их в разные компоненты.
Если хочется бинаризовать сложную картинку, то нужно ее сначала хорошо сегментировать. Простейший способ — наложить фиксированную сетку. Если есть представление о том, как сегментировать, то можно выбирать глобальный порог в каждой области и бинаризация будет работать.
В этих двух областях всё плохо, потому что тут есть совсем чёрные пикселы и есть — посветлее. Для каждого квадратика находим порог и применяем его внутри этого квадратика.
Допустим у нас есть бинарное изображение, состоящее только из чёрный и белых пикселов. Мы хотим пометить принадлежность пикселов к связной области таким образом: все пикселы внутри данной области одного цвета и соединяются друг с другом.

Отделяем все связные белые от всех чёрных. Выделяют четырёх- и восьмисвязные области. В четырёхсвязных соседями считаются только пикселы, расположенные по вертикали и по горизонтали, а в восьмисвязных областях учитываются и диагональные соседи.
Простейший алгоритм — двухпроходный, он работает следующим образом. Мы начинаем из левого верхнего угла и первому пикселу присваиваем номер. Дальше двигаемся направо и смотрим, совпадает ли цвет пиксела с уже размеченным. Если совпадает, то присваиваем ему ту же самую метку. Если этот пиксел был помечен ноликом, то и этот получает тоже метку нолик. И так доходим до конца строки, потому что тут у нас все нолики. Дальше, цвет третьего пиксела на второй строчке не совпадает с цветом уже размеченных соседей. Мы увеличиваем счётчик областей и присваиваем этому пикселу номер следующей области — 1. Переходим сюда, у этого уже ест сосед такого же цвета, у которого есть метка, ему присваиваем такую же метку. Дальше мы увеличиваем увеличиваем счётчик и присваиваем номера 2, 3, 4, 5, 6, 7. Здесь представлен результат первого прохода. На втором проходе нам останется только объединить области, в которых соседи одного цвета носят разные метки. В результате получается изображение такого вида.

Здесь фон одного цвета, одна связная компонента другого, и вторая связная компонента третьего цвета. Красная и белая компоненты на чёрном фоне.
Уже в первом проходе накапливается информация о том, что одной компоненте соответствует несколько меток. Понятно, что все они одного цвета и 1 и 2 относятся к одной компоненте. Эта информация записывается и во второй проход перенумеруется.
Где используется? Это один из способов сегментации картинки. Простейший пример — когда картинка бинарная, можно выделять компоненты связности на цветном изображении. Только там критерием присоединения к одной компоненте будет не полное соответствие цвета, а то, что они отличаются на какое-то пороговое значение.
Это более сложная тема. В двух словах, фильтрация — это применение к изображению некой функции. Операцию фильтрации называют свёрткой. Выполняется она следующим образом.
Представьте себе, что у нас есть картинка в пространственной области и есть фильтр (он же — маска, он же — ядро) — некоторая функция. В дискретном случае это массив со значениями. Мы накладываем эту маску на кусок изображения. Тогда значение пиксела, расположенного под центральным элементом маски, вычисляется как взвешенная сумма значений пикселов, перемноженных на значения маски. То есть, накладываем маску на картинку и значение в пикселе, который под центром, вычисляется как значение пиксела, умноженное на коэффициент маски плюс значение, помноженное на коэффициент в другом месте и так далее.

Маска как бы скользит по картинке, мы должны наложить её на каждый из пикселов. С граничными пикселами при этом происходит следующее. Для того чтобы можно было произвести фильтрацию, мы выбираем два варианта: либо картинка на выходе будет меньшего размера, чем исходная, так как она обрезается по размеру фильтра, то есть отрежется по половинке фильтра сверху, снизу и с боков. Либо мы наращиваем исходное изображение. Чаще всего либо добавляются чёрные пикселы, либо что более оправданно, зеркально отражённые пикселы края картинки.
То есть, если у нас есть вот такая картинка и такой фильтр (3 на 3), и если мы ничего не делаем с картинкой, то получается отфильтрованной только вот эта часть. Теряем по одному пикселу с каждой стороны. Мы можем нарастить исходную картинку еще на один пиксел, вставив по краям чёрные либо белые пикселы, либо зеркально отразив край. Если у нас фильтр большего размера, то мы соответственно увеличиваем наращиваемую по краю область.
Операция свёртки обладает рядом приятных свойств, таких как коммутативность, то есть, не важно, что стоит на первом месте, изображение или фильтр. Ассоциативность, то есть, если у нас есть два фильтра мы можем либо сначала применить а потом второй, либо на основании этих фильтров построить свёртку фильтров, а потом уже применять её к изображению.
Дистрибутивность по сложению — можем сложить два фильтра, просто сложить их веса и получить новый фильтр, или применить сначала один фильтр, потом второй и сложить результаты. Скаляр можем выносить за скобки. То есть если здесь есть коэффициент, можем все веса поделить на какое-то число, применить фильтр, а потом результат умножить на эту константу. Что произойдет, если мы картинку свернём вот с таким фильтром? Сдвиг на один пиксел.
Я обещала рассказать, почему теорема Фурье так хорошо работает в частотной области. Существует теорема свёртки. Что это такое? Теорема свёртки говорит о том, что если мы производим свёртку в пространственной области, это то же самое, что перемножить результаты преобразования Фурье в частотной области. Если есть картинка F и фильтр H, и мы их попытаемся свернуть, это будет то же, как сделать перевод картинки и фильтра в частотную область. То есть найти для картинки и фильтра коэффициенты преобразования Фурье и их между собой перемножить. И в обратную сторону. Если у нас есть перемножение в пространственной области, это то же самое, что и операция свёртки над соответствующими коэффициентами преобразования Фурье.
Мы, конечно, можем взять фильтр для использования на нашей картинке, и двигать его долго по всему изображению, но это довольно сложная вычислительная задача. Гораздо проще произвести быстрое преобразование Фурье фильтра и картинки.
Усредняющий фильтр — один из наиболее известных. Он позволяет удалить случайный шум. Матрица этого фильтра выглядит вот таким образом.
Фильтр сглаживает изображение. Если мы переставим коэффициенты немного иначе, это позволит сделать более яркими контуры по горизонтали и вертикали, то есть оставить перепады яркости.
Когда у нас есть ядро, и оно сворачивается с чем то — это линейные фильтры, там все операции линейны. Есть еще фильтры, основанные на порядковых статистиках. Здесь вместо того чтобы усреднять значения каждого пиксела, берётся медиана.
Этот фильтр уже будет нелинейным. Медианные фильтры более устойчивы к выбросам, сильным отклонениям от средних значений, поэтому медианные фильтры значительно лучше справляются с подавлением шума типа “соль и перец”.
Еще один очень распространённый фильтр — фильтр Гаусса. Это свёртка с функцией Гаусса, которая выглядит таким образом. Здесь есть зависимость от радиуса. Вот представление фильтра в пространственной области и представление его же в частотной области. Можно ли по виду характеристик фильтра определить, что он сделает с картинкой?
Вспомним теорему о свёртке. Мы собираемся перемножать образ нашего изображения вот с таким вот. Что получится? Мы существенно обрезаем высокие частоты, изображение получится более гладким. Вот результат сглаживания.
Исходное изображение, картинка сглаженная фильтром Гаусса с =1,4 размера 5 и =2,8 с размером 10. Чем больше радиус, тем более размытая получается картинка, хотя явно нет зависимости между размером фильтра(количеством отсчётов) и на практике не имеет смысла выбирать большую с малым размером.
Здесь у нас размер фильтра 3х3 (маленький), если большая, это означает, что мы не сможем отразить все значения. Негласное правило — размер должен составлять порядка 5-6. Сглаживание следует использовать, когда есть шум и мы хотим от него избавиться. То есть, пытаемся усреднить значение в каждой точке, посмотрев на значения соседей, и если это какой-то выброс, то мы это значение уберём.
Бывает, что необходимо выделить на изображении какую-то деталь. Это тоже можно сделать с помощью свёртки с ядром другого вида. К примеру, свёртка с таким ядром позволит выделить точечные особенности. К сожалению здесь не очень хорошо видно, но на изображении есть дефект, белая точка. Вот результат свёртки этой картинки с этим фильтром, тут белая точка. А это результат бинаризации, белая точка тоже есть.
Почему тут практически не осталось вот этих контуров? На картинке их очень хорошо видно. На свёртке точка стала хорошо видна, а контуров практически не видно. Потому что точка изолированная и значение в точке над которой расположена маска гораздо выше, чем всё вокруг.
Можно обнаруживать линии, изменив немного вид ядра. Если мы зададим ядро вот такого вида, мы будем хорошо обнаруживать горизонтальные линии, такого вида — под углом 45°, вертикальные и -45°. Здесь пример обработки исходной картинки, ядро на -45° и бинаризация.
Вообще, выделение контуров и линий и точек, это выделение точечных особенностей. Существует множество алгоритмов выделения, сейчас мы поговорим об их основах.
Как найти перепад яркости на изображении. Что есть перепад яркости? Это когда у нас были пикселы одного цвета, а потом стали пикселы другого цвета. Если мы посмотрим на профиль картинки, сначала было всё чёрное, потом — раз, стало серое. Или оно плавно изменялось. То есть, у нас есть скачок или перепад яркости. Для того чтобы его выделить, можно просто взять производную. В плоских значениях (там, где яркость не меняется) производная равна 0. Там где яркость меняется, там чем выше перепад, тем больше будет значение производной. Первая производная позволит выделить участок плавного изменения яркости. Есть такое понятие как zero crossing line. Если мы посчитаем значения производных и их соединим, то можем предположить, что контур расположен где-то вот в этой точке, там, где мнимая прямая пересекает вот этот уровень.
Как можно посчитать производную на картинке и что из себя представляет градиент изображения? Мы смотрим, насколько изменяется вдоль x и y наша яркость.
Подсчитав градиент, мы можем получить направление градиента, которое задаётся углом и величину, которая задаётся изменением по каждому из направлений.
Вычисление градиента. В дискретном случае дискретная производная по x будет выглядеть как-то вот так. Считаем разницу в значении пиксель сдвинутого в одну сторону на 1 по сравнению с текущим пикселям и можно это тоже задать маской. Существуют разные маски для вычисления градиента.
Вот примеры вычисления градиента по картинке и, можно сказать, что выделение контуров по горизонтали и вертикали. Здесь мы смотрим, как изменяется яркость по горизонтали, здесь — по вертикали, здесь прорисованы горизонтальные контуры, здесь — вертикальные, а здесь — сумма этих двух изображений.
С помощью определённых масок можно посчитать вторую производную, по x и по y. Помимо того что мы можем посчитать контуры, иногда нужно повысить резкость. Когда мы сглаживаем картинку, мы теряем детали. Если мы возьмём оригинал и вычтем из него результат сглаживания, то мы получим некие контуры.
Для того чтобы получить более резкую и контрастную картинку, нужно добавить эти контуры. Один из способов повышения контраста — лапласиан Гаусса. Проделаем ровно то, что здесь нарисовано, берём исходное изображение, и прибавляем к нему разность исходного изображения и сглаженного, предположим, что это у нас гуанина. Путём некоторых математических преобразований получаем вот такое выражение, то есть нам нужно свернуть исходное изображение вот с таким вот фильтром, в котором — это константа, e — единичный фильтр, который выглядит вот таким образом, g — это лапласиан.
То есть, из единичного фильтра вычитаем Гаусса и получаем вот такую бяку, называемую лапласиан Гаусса, или иначе — Mexican Hat.
Спектр этой функции выглядит вот так. Если мы перемножим вот это на спектр исходной картинки, то получится, что мы добавим высоких частот, подавим средние и усилим центр. Получится изображение с повышенной контрастностью, резкостью. Мы сделали перепады яркостей более видимыми.
Сегодня мы обсудили представление картинок в пространственной и частотной областях, и поговорили о том, что можно сделать с изображениями, какие фильтры использовать.
- строить гистограммы;
- понимать, что можно сделать с изображением, изменяя его гистограмму;
- подавлять шум, узнаем о его видах.
Кроме этого, мы познакомимся с тем, что есть представление изображения в пространственной области и что подразумевается под представлением изображения в частотной области.
Невозможно улучшить изображения без понимания того, зачем вы это делаете. Цели могут быть две: поправить его, чтобы оно было таким, каким будет вам больше нравиться, или преобразовать, чтобы компьютеру было проще обсчитывать некоторые его признаки и извлекать полезную информацию.
Пространственная область
Вспомним, что картинка представляется в виде функции от x и y. Если мы говорим о полноценном изображении, то каждое значение этой функции – трёхзначное число, которое представляет собой значение для каждого из цветовых каналов.

Представление изображения в пространственной области – это то, как мы привыкли понимать и видеть изображение. Есть x и y, и в каждой точке у нас есть какое-то значение интенсивности или значение цветового канала.
На этом слайде Лена и логотип библиотеки OpenCV разложены на три цветовых канала — красный, зелёный и синий.

Вспомним, что если нет источника света, мы получаем чёрный цвет. Если же объединить источники всех трёх первичных цветов, то мы получим белый цвет. Это означает, что в более темной области нет схождения данного цветового канала.
Это привычное пространственное представление. Дальше речь пойдет в основном о чёрно-белых картинках, но в принципе все алгоритмы будут применимы и к цветным изображениям.
Чтобы упростить задачу, представим, что наше изображение одномерное. Линия, которая идёт слева-направо, отображает все изменения яркости. Всплеск в начале соответствует паре пикселов белого цвета, потом идёт серая область, потом — снова белая. На черном цвете мы проваливаемся вниз. То есть по этой линии можно проследить, как изменяется яркость.

Посмотрим еще один пример.

Как еще можно описать информацию, содержащуюся в нашем сигнале, кроме данных о её яркости? Можно разложить его на компоненты, то есть, например очень сильно сгладить кривую чтобы отследить общий тренд. У нас он идёт сначала вниз, потом вверх, потом опять вниз и опять вверх. Получаем практически асимптотическое приближение к этой штуке.
Дальше можем посмотреть на детали покрупнее, т.е. какие бывают всплески, на детали помельче. К чему я клоню: в принципе можно разложить эту функцию на гармонические составляющие. Для тех, кто помнит что такое ряд Фурье, согласно одноимённой теореме любую функцию (она сказала — периодическую, но это неверно, вообще любую функцию) можно представить как сумму синусов и косинусов различных частот и амплитуд, что здесь и показано. Эта искусственно генерированная функция является суммой этих четырёх функций.
Что мы можем с этим сделать? Представим, что у нас есть некий базис, который задаётся набором этих синусоида и косинусов. Мы знаем частоту каждой базисной функции. Тогда для представления исходной функции нам нужно знать только коэффициенты, скаляр, на которые нужно умножить каждую из базисных функций.
Основная идея преобразования Фурье — это то, что любая картинка может быть представлена в виде суммы синусов и косинусов. Почему любая? Потому что любая периодическая функция может быть всегда представлена в виде суммы синусов и косинусов. Непериодическая же функция, если площадь графика под ней конечна (что всегда будет верно для изображения), тоже может быть представлена как сумма синусоида и косинусов. Чтобы представить такую функцию абсолютно точно, их должно быть бесконечно много, но, тем не менее, это сделать можно.
Частоты таких слагаемых и будут характеризовать изображение. Для каждой картинки мы говорим, какая из базисных частот в ней преобладает.
Что мы можем сказать о коэффициентах базисных функций? Если у нас большой коэффициент перед базисной функцией с высокой частотой, это означает, что яркость изменяется достаточно часто. На картинке очень много перепадов яркости в маленьких локальных регионах. Если картинка описывается плавными синусоидами, с низкой частотой, то это означает, что на картинке много однородных областей, яркость изменяется плавно, или картинка, например, была «забурена».
Таким образом, можно использовать отображение в частотной области для описания изображений.
Берём исходный сигнал, представляем его в виде суммы колебаний одинаковой амплитуды и разных частот, умножаем их на скальные коэффициенты и получаем разложение исходной функции вот по такому новому базису.
Теперь представьте себе, что вы пытаетесь передать кому-то картинку с помощью мобильного телефона. Раньше вам бы потребовалось передать все 230 значений яркости. Но теперь, если приёмная и принимающая сторона «знают», какие у нас базисные функции, то объём посылаемой информации значительно сокращается. Вы можете передать ту же информацию, используя существенно меньше параметров.
Почему преобразование Фурье так популярно при обработке изображений? Оно позволяет существенно сократить объём передаваемой информации, достаточной для восстановления изображения в прежнем виде. Также преобразование Фурье облегчает процесс фильтрации, но об этом позже. Преобразование Фурье хорошо тем, что оно обратимо. Мы разложили нашу функцию на частотные составляющие с коэффициентами, но можем вернуться и обратно из частотного представления в пространственное.
Теоретически мы можем представить функцию в качестве бесконечного набора синусоида, но на практике (поскольку бесконечность недостижима), ограничиваются только несколькими первыми слагаемыми (с самыми большими коэффициентами). Картинка при восстановлении обратно в пространственную область будет чуть-чуть отличаться от оригинала, то есть часть информации будет безвозвратно потеряна. Тем не менее, использование ограниченного количества составляющих позволяет в достаточной степени восстановить изображение.
Как же посчитать значения скаляров для заранее заданного базиса частот? Для преобразования Фурье, когда у нас в качестве базисных функций присутствуют гармоники — синусы и косинусы. И есть обратное преобразование Фурье, которое позволяет по набору коэффициентов, зависящих от частоты, восстановить исходное представление в пространственной области.
Здесь гармоники — это те самые синусы и косинусы, которые нарисованы на предыдущем слайде. Для каждой фиксированной частоты есть некая функция от x.
Надеюсь, что с одноименным случаем более или менее понятно. Теперь посмотрим на двумерный случай, потому что картинка у нас двухмерна.
Здесь мы тоже можем построить двухмерные гармоники, которые уже будут зависеть от четырёх параметров: x, y (от двух направлений) и от двух частот в направлении x и y соответственно.
Возьмём, к примеру, такой квадрат. Здесь нарисован и вид сверху, и в изомеры. Мы видим, как наша гармоника плавно переходит из одного угла в другой. Здесь мы опять можем применить прямое преобразование Фурье, и обратное, где у нас есть коэффициенты уже для двух фиксированных частот, чтобы снова получить пространственное представление.
Теперь посмотрим, что можно понять при визуализации результата прямого преобразования по так называемому спектру Фурье. Хотя мы говорим о преобразовании Фурье, но также можно использовать и любое другое преобразование сигнала, где в качестве базисных функций выберем не гармоники, а какие-то другие функции. Часто в качестве базисных функций используют [вейвлеты]. Они в некотором смысле более удачны, чем синусы и косинусы.
Попробуем рассмотреть град из значений наших скаляров. Тут у нас дискретный случай — как выглядит базисная функция при фиксированных u и v. Расположим их вдоль осей соответственно u и v. На этом гриме спектр Фурье представляет собой отображение значений коэффициентов. Важно понимать, что в центре у нас частота нулевая, а к краям она увеличивается.
Дальше, если каждую ячейку начнём складывать значение параметра F, коэффициента, который мы получили при разложении. Чем больше коэффициент, тем ярче он будет отображаться на спектре. То есть, мы хотим визуализировать спектр Фурье. Если коэффициент F=0, будем отображать его чёрным цветом. Чем он больше, тем светлее цвет.
На двумерном спектре всего один пиксел будет соответствовать u=0, v=0, следующий — U= -1, V=0. Значение пиксела будет равняться коэффициенту, полученному из преобразования. Важно то, что центральные коэффициенты соответствуют важности этой гармоники в представлении изображения, в центре стоят гармоники с нулевыми частотами. То есть, на картинке, если у нас будет очень большой отклик вот здесь, это значит, что картинка практически не меняет своей яркости. Если у картинки будет здесь тёмное пятно, а по периферии — светлое, то она пёстрая — там перепад яркости в каждой точке и в каждом направлении.
Картинка — это не спектр, это визуализация двумерной синусоиды.
Посмотрим на эту картинку. Обычно рисуют логарифм от спектра, иначе он получается очень тёмный. Но для большинства картинок типично светлое пятно в центре, потому что на картинках много однородных областей. Нужно иметь в виду, что когда частота у нас равна нулю, то перепада яркости нет. В случае, если есть перепад яркости, то, в какую точку спектра внесёт вклад этот перепад, будет зависеть от направления контура, от направления перепада. Тут у нас есть края, но они размазаны по периферии, ярких откликов не получается.
Обработка в пространственной области
Перейдём к тому что можно делать с изображениями. Начнём с простейших, интуитивно понятных преобразований в пространственной области.
Инвертирование картинки
Если у нас яркость изменяется от 0 до 255, то для каждого пиксела пишем 255 минус его прежнее значение. Чёрное становится белым, а белое — чёрным.
Одним из наиболее простых и практичных видов представления картинки является гистограмма. Для любого изображения можно посчитать, сколько пикселов с нулевой яркостью, сколько с яркостью 50, 100 и так далее, и получить некое распределение частотности.
На этой картинке у Лены отрезаны все точки яркости, которые больше 125. Получаем гистограмму, смещённую влево, и тёмную картинку. На второй картинке все наоборот — есть только светлые пикселы, гистограмма смещена вправо.

Следующая картинка размазана, у неё нет чётких контуров. Для такой картинки характерен столбик яркости где-то посередине и отсутствие энергии по краям спектра.
Для второй Лены с этого слайда была сделана обработка, чтобы подчеркнуть каждый из контуров, то есть сделать сильнее перепады яркости. Здесь гистограмма занимает весь диапазон яркости.

Что можно делать с гистограммами? По форме гистограммы уже можно многое рассказать о её свойствах. Дальше можно что-то сделать с гистограммой, изменить её форму, чтобы картинка стала выглядеть лучше.
Для тёмной картинки гистограмму можно растянуть вправо, и тогда картинка станет светлее, а для светлой — наоборот. Это верно для любой формы. Если гистограмма картинки не покрывает весь частотный диапазон, то при равномерном растягивании картинка станет более контрастной и будет лучше видно детали.
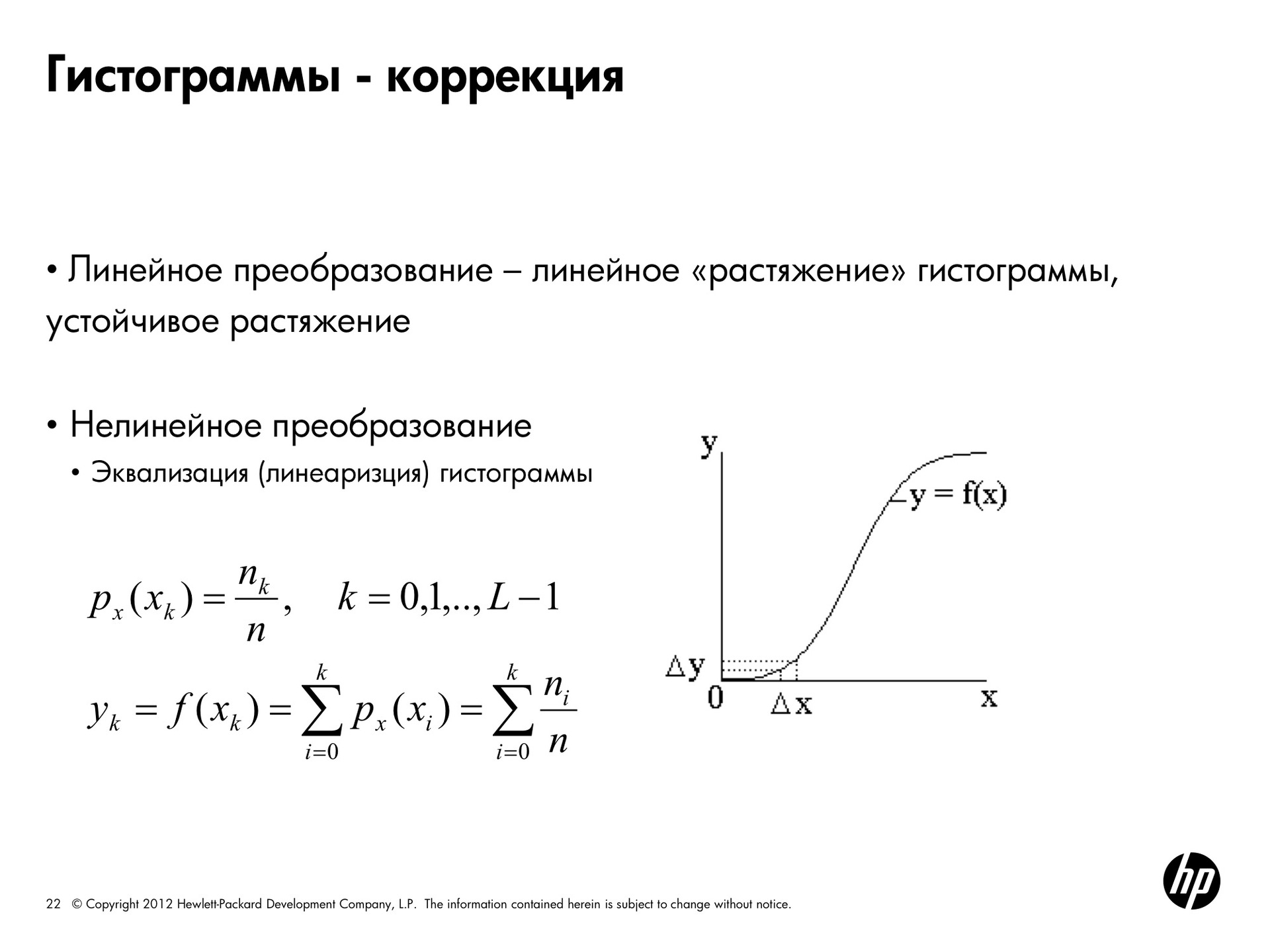
Только что мы делали линейные преобразования гистограммы. Можно делать нелинейные преобразования, которые называют экранизацией или линеоризацией. Это позволяет из исходной гистограммы получить более равномерную с примерно одинаковым количеством пикселов каждой яркости.

Делается это так. В формуле xk — это некий уровень яркости, nk — количество пикселов такой яркости, n- общее количество пикселов. Мы выбираем какой-то пиксел и получаем вероятность, с которой он будет цвета xk. То есть, количество пикселов nk делить на общее количество пикселов. На самом деле — доля.
Попытаемся получить равномерную плотность вероятности, то есть, чтобы для каждого цвета была одинаковая вероятность его получить. Это достигается следующим преобразованием. Если мы по пикселю цвета xk вычислим новые значения яркости для него yk по формуле, то есть возьмём и пронумеруем все вероятности oт i до этого цвета, гистограмма получится более равномерная. То есть, исходная затемнённая картинка выглядела вот так, а если мы к яркостям этой картинки применим экранизацию, то в результате получим гистограмму вот такой формы. Как вы видите, они гораздо более равномерно распределены по всем возможным значениям, и картинка будет выглядеть вот так.
Сделаем то же самое для светлой картинки. И гистограммы практически совпадают, потому что изначально картинки были получены из одной и той же картинки.
Вот результаты эквализации для резкой и размытой картинок. Видно, что для резкой картинки изображение почти не изменилось, но гистограмма стала немного ровнее.
Бинаризация
Мы уже отказались от цветных изображений и говорим только о чёрно-белых, где есть различные градации серого. Бинаризация — это продолжение издевательства над изображением, когда мы отказываемся еще и от них. В итоге получаем картинку, где есть только чёрный и белый. Нам нужно понять, какие пикселы мы хотим сделать чёрными, а какие — белыми.
Это упрощает дальнейший анализ изображения для многих задач. Если есть картинка с текстом, к примеру, то хорошо бы чтобы все буквы на картинке оказались белыми (или чёрными), а фон — наоборот. Последующему алгоритму распознавания символов будет проще работать с таким изображением. То есть, бинаризация хороша тогда, когда мы хотим чётко отделить фот от объекта.
Поговорим о простейшем типе бинаризации — пороговой. Этот тип вообще-то не очень применим для фотографий, но, тем не менее, иногда используется.

Если мы применяем пороговую бинаризацию к гистограмме, то видим, что у нас в изображении есть два типа пикселов: потемнее и посветлее. Обычно предполагают, что большее количество пикселов соответствует фону. Из этого делаем вывод, что вот тут у нас кучка побольше, она тёмная, соответственно у нас фон — тёмный, и на нём есть один или несколько светлых объектов. Объект может быть составной. Здесь у нас два светлых объекта разного цвета.
Это очень красивые гистограммы, в жизни вы вряд ли такие увидите. Но по ним легко понять, где нужно провести порог, чтобы отделить фон от объекта. Здесь, если мы возьмём пороговое значение ровно между ними, и все пикселы, которые ярче порога, сделаем белыми, а те, которые темнее — чёрными, то мы превосходно отделим объект от фона. Выбрав нужный нам диапазон яркости, мы вырезаем из картинки тот или иной объект.
Бинаризация различается по типам на основании того, каким образом вычисляется порог. При глобальной бинаризации порог един для всех точек изображения. При локальной и динамической бинаризации порог зависит от координаты точки. При адаптивной бинаризации порог зависит еще и от значения яркости в этой точке.
Выбор порога при глобальной бинаризации осуществляется следующим образом. Можно это делать вручную, но вручную естественно никто ничего делать не хочет, а можно выбрать порог автоматически.
Простейший алгоритм таков: вначале берём произвольное значение порога и сегментируем картинку по этому порогу на два региона. В один попадают пикселы со значением больше порогового, в а другой — меньше порогового. Для этих регионов вычисляем среднее значение яркостей. После чего новым порогом считаем их полусумму. Алгоритм заканчивает свою работу, когда после некоторого числа итераций итоговая яркость становится меньше еще одного заданного порогового значения.
На этой картинке представлено преимущество локальной бинаризации.

Если бы бинаризация была глобальной, был бы выбран глобальный порог для всей картинки, то результат бы выглядел так, на картинке b. Пикселы здесь в одной области примерно одного уровня яркости, поэтому вся эта часть получается белой, засвеченной. В том случае, если мы применим простейший вариант локальной бинаризации — то есть поделим изображение на сегменты и будем выбирать порог для каждого сегмента отдельно, — результат бинаризации уже будет выглядеть получше ©.
Для этой картинки гистограмма, скорее всего, будет красивой. Будут пики, а в долине, может, и не будет нулевого значения. Вот светлая область и тёмная. То есть, мы выбрали порог, но его невозможно выбрать таким образом, чтобы выделить этот объект, потому что если порог один, то критерий, по которому мы делаем пиксел чёрным или белым, один для всех пикселов картинки. При этом цвет одинаковый, при едином пороге мы никогда не сможем отнести их в разные компоненты.
Если хочется бинаризовать сложную картинку, то нужно ее сначала хорошо сегментировать. Простейший способ — наложить фиксированную сетку. Если есть представление о том, как сегментировать, то можно выбирать глобальный порог в каждой области и бинаризация будет работать.
В этих двух областях всё плохо, потому что тут есть совсем чёрные пикселы и есть — посветлее. Для каждого квадратика находим порог и применяем его внутри этого квадратика.
Выделение компонент связности
Допустим у нас есть бинарное изображение, состоящее только из чёрный и белых пикселов. Мы хотим пометить принадлежность пикселов к связной области таким образом: все пикселы внутри данной области одного цвета и соединяются друг с другом.

Отделяем все связные белые от всех чёрных. Выделяют четырёх- и восьмисвязные области. В четырёхсвязных соседями считаются только пикселы, расположенные по вертикали и по горизонтали, а в восьмисвязных областях учитываются и диагональные соседи.
Простейший алгоритм — двухпроходный, он работает следующим образом. Мы начинаем из левого верхнего угла и первому пикселу присваиваем номер. Дальше двигаемся направо и смотрим, совпадает ли цвет пиксела с уже размеченным. Если совпадает, то присваиваем ему ту же самую метку. Если этот пиксел был помечен ноликом, то и этот получает тоже метку нолик. И так доходим до конца строки, потому что тут у нас все нолики. Дальше, цвет третьего пиксела на второй строчке не совпадает с цветом уже размеченных соседей. Мы увеличиваем счётчик областей и присваиваем этому пикселу номер следующей области — 1. Переходим сюда, у этого уже ест сосед такого же цвета, у которого есть метка, ему присваиваем такую же метку. Дальше мы увеличиваем увеличиваем счётчик и присваиваем номера 2, 3, 4, 5, 6, 7. Здесь представлен результат первого прохода. На втором проходе нам останется только объединить области, в которых соседи одного цвета носят разные метки. В результате получается изображение такого вида.

Здесь фон одного цвета, одна связная компонента другого, и вторая связная компонента третьего цвета. Красная и белая компоненты на чёрном фоне.
Уже в первом проходе накапливается информация о том, что одной компоненте соответствует несколько меток. Понятно, что все они одного цвета и 1 и 2 относятся к одной компоненте. Эта информация записывается и во второй проход перенумеруется.
Где используется? Это один из способов сегментации картинки. Простейший пример — когда картинка бинарная, можно выделять компоненты связности на цветном изображении. Только там критерием присоединения к одной компоненте будет не полное соответствие цвета, а то, что они отличаются на какое-то пороговое значение.
Алгоритмы фильтрации
Это более сложная тема. В двух словах, фильтрация — это применение к изображению некой функции. Операцию фильтрации называют свёрткой. Выполняется она следующим образом.
Представьте себе, что у нас есть картинка в пространственной области и есть фильтр (он же — маска, он же — ядро) — некоторая функция. В дискретном случае это массив со значениями. Мы накладываем эту маску на кусок изображения. Тогда значение пиксела, расположенного под центральным элементом маски, вычисляется как взвешенная сумма значений пикселов, перемноженных на значения маски. То есть, накладываем маску на картинку и значение в пикселе, который под центром, вычисляется как значение пиксела, умноженное на коэффициент маски плюс значение, помноженное на коэффициент в другом месте и так далее.

Маска как бы скользит по картинке, мы должны наложить её на каждый из пикселов. С граничными пикселами при этом происходит следующее. Для того чтобы можно было произвести фильтрацию, мы выбираем два варианта: либо картинка на выходе будет меньшего размера, чем исходная, так как она обрезается по размеру фильтра, то есть отрежется по половинке фильтра сверху, снизу и с боков. Либо мы наращиваем исходное изображение. Чаще всего либо добавляются чёрные пикселы, либо что более оправданно, зеркально отражённые пикселы края картинки.
То есть, если у нас есть вот такая картинка и такой фильтр (3 на 3), и если мы ничего не делаем с картинкой, то получается отфильтрованной только вот эта часть. Теряем по одному пикселу с каждой стороны. Мы можем нарастить исходную картинку еще на один пиксел, вставив по краям чёрные либо белые пикселы, либо зеркально отразив край. Если у нас фильтр большего размера, то мы соответственно увеличиваем наращиваемую по краю область.
Операция свёртки обладает рядом приятных свойств, таких как коммутативность, то есть, не важно, что стоит на первом месте, изображение или фильтр. Ассоциативность, то есть, если у нас есть два фильтра мы можем либо сначала применить а потом второй, либо на основании этих фильтров построить свёртку фильтров, а потом уже применять её к изображению.
Дистрибутивность по сложению — можем сложить два фильтра, просто сложить их веса и получить новый фильтр, или применить сначала один фильтр, потом второй и сложить результаты. Скаляр можем выносить за скобки. То есть если здесь есть коэффициент, можем все веса поделить на какое-то число, применить фильтр, а потом результат умножить на эту константу. Что произойдет, если мы картинку свернём вот с таким фильтром? Сдвиг на один пиксел.
Я обещала рассказать, почему теорема Фурье так хорошо работает в частотной области. Существует теорема свёртки. Что это такое? Теорема свёртки говорит о том, что если мы производим свёртку в пространственной области, это то же самое, что перемножить результаты преобразования Фурье в частотной области. Если есть картинка F и фильтр H, и мы их попытаемся свернуть, это будет то же, как сделать перевод картинки и фильтра в частотную область. То есть найти для картинки и фильтра коэффициенты преобразования Фурье и их между собой перемножить. И в обратную сторону. Если у нас есть перемножение в пространственной области, это то же самое, что и операция свёртки над соответствующими коэффициентами преобразования Фурье.
Мы, конечно, можем взять фильтр для использования на нашей картинке, и двигать его долго по всему изображению, но это довольно сложная вычислительная задача. Гораздо проще произвести быстрое преобразование Фурье фильтра и картинки.
Какие могут быть фильтры/ядра и что они делают с изображением
Усредняющий фильтр — один из наиболее известных. Он позволяет удалить случайный шум. Матрица этого фильтра выглядит вот таким образом.
Фильтр сглаживает изображение. Если мы переставим коэффициенты немного иначе, это позволит сделать более яркими контуры по горизонтали и вертикали, то есть оставить перепады яркости.
Когда у нас есть ядро, и оно сворачивается с чем то — это линейные фильтры, там все операции линейны. Есть еще фильтры, основанные на порядковых статистиках. Здесь вместо того чтобы усреднять значения каждого пиксела, берётся медиана.
Этот фильтр уже будет нелинейным. Медианные фильтры более устойчивы к выбросам, сильным отклонениям от средних значений, поэтому медианные фильтры значительно лучше справляются с подавлением шума типа “соль и перец”.
Еще один очень распространённый фильтр — фильтр Гаусса. Это свёртка с функцией Гаусса, которая выглядит таким образом. Здесь есть зависимость от радиуса. Вот представление фильтра в пространственной области и представление его же в частотной области. Можно ли по виду характеристик фильтра определить, что он сделает с картинкой?
Вспомним теорему о свёртке. Мы собираемся перемножать образ нашего изображения вот с таким вот. Что получится? Мы существенно обрезаем высокие частоты, изображение получится более гладким. Вот результат сглаживания.
Исходное изображение, картинка сглаженная фильтром Гаусса с =1,4 размера 5 и =2,8 с размером 10. Чем больше радиус, тем более размытая получается картинка, хотя явно нет зависимости между размером фильтра(количеством отсчётов) и на практике не имеет смысла выбирать большую с малым размером.
Здесь у нас размер фильтра 3х3 (маленький), если большая, это означает, что мы не сможем отразить все значения. Негласное правило — размер должен составлять порядка 5-6. Сглаживание следует использовать, когда есть шум и мы хотим от него избавиться. То есть, пытаемся усреднить значение в каждой точке, посмотрев на значения соседей, и если это какой-то выброс, то мы это значение уберём.
Бывает, что необходимо выделить на изображении какую-то деталь. Это тоже можно сделать с помощью свёртки с ядром другого вида. К примеру, свёртка с таким ядром позволит выделить точечные особенности. К сожалению здесь не очень хорошо видно, но на изображении есть дефект, белая точка. Вот результат свёртки этой картинки с этим фильтром, тут белая точка. А это результат бинаризации, белая точка тоже есть.
Почему тут практически не осталось вот этих контуров? На картинке их очень хорошо видно. На свёртке точка стала хорошо видна, а контуров практически не видно. Потому что точка изолированная и значение в точке над которой расположена маска гораздо выше, чем всё вокруг.
Можно обнаруживать линии, изменив немного вид ядра. Если мы зададим ядро вот такого вида, мы будем хорошо обнаруживать горизонтальные линии, такого вида — под углом 45°, вертикальные и -45°. Здесь пример обработки исходной картинки, ядро на -45° и бинаризация.
Вообще, выделение контуров и линий и точек, это выделение точечных особенностей. Существует множество алгоритмов выделения, сейчас мы поговорим об их основах.
Как найти перепад яркости на изображении. Что есть перепад яркости? Это когда у нас были пикселы одного цвета, а потом стали пикселы другого цвета. Если мы посмотрим на профиль картинки, сначала было всё чёрное, потом — раз, стало серое. Или оно плавно изменялось. То есть, у нас есть скачок или перепад яркости. Для того чтобы его выделить, можно просто взять производную. В плоских значениях (там, где яркость не меняется) производная равна 0. Там где яркость меняется, там чем выше перепад, тем больше будет значение производной. Первая производная позволит выделить участок плавного изменения яркости. Есть такое понятие как zero crossing line. Если мы посчитаем значения производных и их соединим, то можем предположить, что контур расположен где-то вот в этой точке, там, где мнимая прямая пересекает вот этот уровень.
Как можно посчитать производную на картинке и что из себя представляет градиент изображения? Мы смотрим, насколько изменяется вдоль x и y наша яркость.
Подсчитав градиент, мы можем получить направление градиента, которое задаётся углом и величину, которая задаётся изменением по каждому из направлений.
Вычисление градиента. В дискретном случае дискретная производная по x будет выглядеть как-то вот так. Считаем разницу в значении пиксель сдвинутого в одну сторону на 1 по сравнению с текущим пикселям и можно это тоже задать маской. Существуют разные маски для вычисления градиента.
Вот примеры вычисления градиента по картинке и, можно сказать, что выделение контуров по горизонтали и вертикали. Здесь мы смотрим, как изменяется яркость по горизонтали, здесь — по вертикали, здесь прорисованы горизонтальные контуры, здесь — вертикальные, а здесь — сумма этих двух изображений.
С помощью определённых масок можно посчитать вторую производную, по x и по y. Помимо того что мы можем посчитать контуры, иногда нужно повысить резкость. Когда мы сглаживаем картинку, мы теряем детали. Если мы возьмём оригинал и вычтем из него результат сглаживания, то мы получим некие контуры.
Для того чтобы получить более резкую и контрастную картинку, нужно добавить эти контуры. Один из способов повышения контраста — лапласиан Гаусса. Проделаем ровно то, что здесь нарисовано, берём исходное изображение, и прибавляем к нему разность исходного изображения и сглаженного, предположим, что это у нас гуанина. Путём некоторых математических преобразований получаем вот такое выражение, то есть нам нужно свернуть исходное изображение вот с таким вот фильтром, в котором — это константа, e — единичный фильтр, который выглядит вот таким образом, g — это лапласиан.
То есть, из единичного фильтра вычитаем Гаусса и получаем вот такую бяку, называемую лапласиан Гаусса, или иначе — Mexican Hat.
Спектр этой функции выглядит вот так. Если мы перемножим вот это на спектр исходной картинки, то получится, что мы добавим высоких частот, подавим средние и усилим центр. Получится изображение с повышенной контрастностью, резкостью. Мы сделали перепады яркостей более видимыми.
Сегодня мы обсудили представление картинок в пространственной и частотной областях, и поговорили о том, что можно сделать с изображениями, какие фильтры использовать.