
Статья посвящена введению в нейронные сети и примеру их реализации. В первой части дано небольшое теоретическое введение в нейронные сети на примере нейронной сети Хопфилда. Показано, как осуществляется обучение сети и как описывается ее динамика. Во второй части показано, как можно реализовать алгоритмы, описанные в первой части при помощи языка С++. Разработанная программа наглядно показывает способность нейронной сети очищать от шума ключевой образ. В конце статьи есть ссылка на исходный код проекта.
Теоретическое описание
Введение
Для начала, необходимо определить, что такое нейрон. В биологии нейрон — специализированная клетка, из которой состоит нервная система. Биологический нейрон имеет строение, показанное на рис.1.
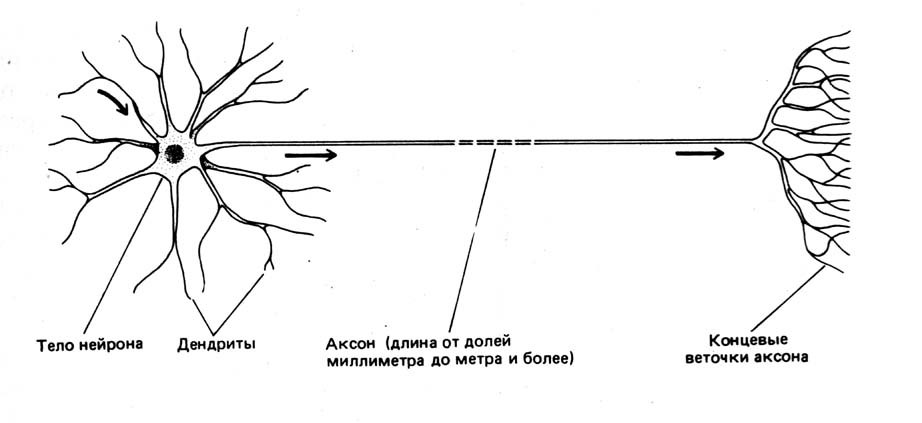
Рис.1 Схема нейрона
Нейронную сеть можно ввести как совокупность нейронов и их взаимосвязей. Следовательно, для того, чтобы определить искусственную (не биологическую) нейронную сеть необходимо:
- Задать архитектуру сети;
- Определить динамику отдельных элементов сети — нейронов;
- Определить правила, по которым нейроны будут взаимодействовать между собой;
- Описать алгоритм обучения, т.е. формирования связей для решения поставленной задачи.
В качестве архитектуры нейронной сети будет использоваться сеть Хопфилда. Данная модель, видимо, является наиболее распространенной математической моделью в нейронауке. Это обусловлено ее простотой и наглядность. Сеть Хопфилда показывает, каким образом может быть организована память в сети из элементов, которые не являются очень надежными. Экспериментальные данные показывают, что при увеличении количества вышедших из строя нейронов до 50%, вероятность правильного ответа крайне близка к 100%. Даже поверхностное сопоставление нейронной сети (например, мозга) и Фон-Неймановской ЭВМ показывает, насколько сильно различаются эти объекты: к примеру, частота изменения состояний нейронов («тактовая частота») не превышает 200Гц, тогда как частота изменения состояния элементов современного процессора может достигать нескольких ГГц (Гц).
Формальное описание сети Хопфилда
Сеть состоит из N искусственных нейронов, аксон каждого нейрона связан с дендритами остальных нейронов, образуя обратную связь. Архитектура сети изображена на рис. 2.

Рис.2 Архитектура нейронной сети Хопфилда
Каждый нейрон может находиться в одном из 2-х состояний:
где — состояние нейрона в момент
. «Возбуждению» нейрона соответствует
, а «торможению»
. Дискретность состояний нейрона отражает нелинейный, пороговый характер его функционирования и известный в нейрофизиологи как принцип «все или ничего».
Динамика состояния во времени -ого нейрона в сети из
нейронов описывается дискретной динамической системой:
где — матрица весовых коэффициентов, описывающих взаимодействие дендритов
-ого нейрона с аксонами
-ого нейрона.
Стоит отметить, что и случай
не рассматриваются.
Обучение и устойчивость к шуму
Обучение сети Хопфилда выходным образам сводится к вычислению значений элементов матрицы
. Формально можно описать процесс обучения следующим образом: пусть необходимо обучить нейронную сеть распознавать
образов, обозначенных
. Входной образ
представляет собой:
где
— шум, наложенный на исходный образ
.
Фактически, обучение нейронной сети — определение нормы в пространстве образов . Тогда, очистка входного образа от шума можно описать как минимизацию этого выражения.
Важной характеристикой нейронной сети является отношение числа ключевых образов , которые могут быть запомнены, к числу нейронов сети
:
. Для сети Хопфилда значение
не больше 0.14.
Вычисление квадратной матрицы размера для ключевых образов производится по правилу Хебба:
где означает
-ый элемент образа
.
Стоит отметить, что в силу коммутативности операции умножения, соблюдается равенство
Входной образ, который предъявляется для распознавания соответствует начальным данным для системы, служащий начальным условием для динамической системы (2):
Уравнений (1), (2), (3), (4) достаточно для определения искусственной нейронной сети Хопфилда и можно перейти к ее реализации.
Реализация нейронной сети Хопфилда
Реализация нейронной сети Хопфилда, определенной выше будет производиться на языке C++. Для упрощения экспериментов, добавим основные определения типов, напрямую связанных с видом нейрона и его передаточной функции в класс simple_neuron, а производные определим далее.
Самыми основными типами, напрямую связанными с нейроном являются:
- тип весовых коэффициентов (выбран float);
- тип, описывающий состояния нейрона (введен перечислимый тип с 2 допустимыми значениями).
На основе этих типов можно ввести остальные базовые типы:
- тип, описывающий состояние сети в момент
(выбран стандартный контейнер vector);
- тип, описывающий матрицу весовых коэффициентов связей нейронов (выбран контейнер vector контейнеров vector).
struct simple_neuron {
enum state {LOWER_STATE=-1, UPPER_STATE=1};
typedef float coeff_t; <<(1)
typedef state state_t; <<(2)
...
};
typedef simple_neuron neuron_t;
typedef neuron_t::state_t state_t;
typedef vector<state_t> neurons_line; <<(3)
typedef vector<vector<neuron_t::coeff_t>> link_coeffs; <<(4)Обучение сети, или, вычисление элементов матрицы в соответствии с (3) производится функцией learn_neuro_net, принимающей на вход список обучающих образов и возвращающей объект типа link_coeffs_t. Значения
вычисляются только для нижнетреугольных элементов. Значения верхнетреугольных элементов вычисляются в соответствии с (4). Общий вид метода learn_neuro_net показан в листинге 2.
link_coeffs learn_neuro_net(const list<neurons_line> &src_images) {
link_coeffs result_coeffs;
size_t neurons_count = src_images.front().size();
result_coeffs.resize(neurons_count);
for (size_t i = 0; i < neurons_count; ++i) {
result_coeffs[i].resize(neurons_count, 0);
}
for (size_t i = 0; i < neurons_count; ++i) {
for (size_t j = 0; j < i; ++j) {
neuron_t::coeff_t val = 0;
val = std::accumulate(
begin(src_images),
end(src_images),
neuron_t::coeff_t(0.0),
[i, j] (neuron_t::coeff_t old_val, const neurons_line &image) -> neuron_t::coeff_t{
return old_val + (image[i] * image[j]);
});
result_coeffs[i][j] = val;
result_coeffs[j][i] = val;
}
}
return result_coeffs;
}Обновление состояний нейронов реализовано с помощью функтора neuro_net_system. Аргументом метода _do функтора является начальное состояние , являющееся распознаваемых образом (в соответствии с (5)) — ссылка на объект типа neurons_line.
Метод функтора модифицирует передаваемый объект типа neurons_line до состояния нейронной сети в момент времени . Значение жестко не фиксировано и определяется выражением:
т.е., когда состояние каждого нейрона не изменилось за 1 «такт».
Для вычисления (2) применены 2 алгоритма STL:
- std::inner_product для вычисления суммы произведений весовых коэффициентов и состояний нейронов (т.е. вычисление (2) для определенного
);
- std::transform для вычисления новых значений для каждого нейрона (т.е. вычисление пункта выше для каждого возможного
Исходный код функтора neurons_net_system и метода calculate класса simple_neuron показан в листинге 3.
struct simple_neuron {
...
template <typename _Iv, typename _Ic>
static state_t calculate(_Iv val_b, _Iv val_e, _Ic coeff_b) {
auto value = std::inner_product(
val_b,
val_e,
coeff_b,
coeff_t(0)
);
return value > 0 ? UPPER_STATE : LOWER_STATE;
}
};
struct neuro_net_system {
const link_coeffs &_coeffs;
neuro_net_system(const link_coeffs &coeffs): _coeffs(coeffs) {}
bool do_step(neurons_line& line) {
bool value_changed = false;
neurons_line old_values(begin(line), end(line));
link_coeffs::const_iterator it_coeffs = begin(_coeffs);
std::transform(
begin(line),
end(line),
begin(line),
[&old_values, &it_coeffs, &value_changed] (state_t old_value) -> state_t {
auto new_value = neuron_t::calculate(
begin(old_values),
end(old_values),
begin(*it_coeffs++)
);
value_changed = (new_value != old_value) || value_changed;
return new_value;
});
return value_changed;
}
size_t _do(neurons_line& line) {
bool need_continue = true;
size_t steps_done = 0;
while (need_continue) {
need_continue = do_step(line);
++steps_done;
}
return steps_done;
}
};Для вывода в консоль входных и выходных образов создан тип neurons_line_print_descriptor, который хранит ссылку на образ и формат форматирования (ширину и высоту прямоугольника, в который будет вписан образ). Для этого типа переопределен оператор <<. Исходный код типа neurons_line_print_descriptor и оператора вывода в поток показан в листинге 4.
struct neurons_line_print_descriptor {
const neurons_line &_line;
const size_t _width;
const size_t _height;
neurons_line_print_descriptor (
const neurons_line &line,
size_t width,
size_t height
): _line(line),
_width(width),
_height(height)
{}
};
template <typename Ch, typename Tr>
std::basic_ostream<Ch, Tr>&
operator << (std::basic_ostream<Ch, Tr>&stm, const neurons_line_print_descriptor &line) {
neurons_line::const_iterator it = begin(line._line), it_end = end(line._line);
for (size_t i = 0; i < line._height; ++i) {
for (size_t j = 0; j < line._width; ++j) {
stm << neuron_t::write(*it);
++it;
}
stm << endl;
}
return stm;
}Пример работы нейронной сети
Для проверки работоспособности реализации, нейронная сеть была обучена 2 ключевым образам:


Рис.3 Ключевые образы
На вход подавались искаженные образы. Нейронная сеть корректно распознала исходные образы. Искаженные образы и распознанные образы показаны на рис.4, 5


Рис.4 Распознавание образа 1


Рис.5 Распознавание образа 2
Запуск программы производится из командной строки строчкой вида: AppName WIDTH HEIGHT SOURCE_FILE [LEARNE_FILE_N], где:
AppNaame - название исполняемого файла; WIDTH, HEIGHT - ширина и высота прямоугольника, в который будут вписываться выходной и ключевые образы; SOURCE_FILE - исходный файл с начальным образом; [LEARNE_FILE_N] - один или несколько файлов с ключывыми образами (через пробел).
Исходный код выложен на GitHub -> https://github.com/RainM/hopfield_neuro_net
В репозитории проект CMake, из которого можно сгенерировать проект Visual Studio (VS2015 компилирует проект успешно) или обычные Unix Makefile’ы.
Использованная литература
- Г.Г. Малинецкий. Математические основы синергетики. Москва, URSS, 2009.
- Статья «Нейронная_сеть_Хопфилда» на Википедии.
Комментарии (21)

Tutanhomon
30.05.2016 12:14Статья хорошая, но как-то не совсем на пальцах. Я и в универе не понял эти нейронные сети, и сколько уже статей прочитал, которые «на пальцах» их объясняют, но так и не понял, как оно обучается, и как распознает. Вот картинка, вот формула, смотрите — все работает. Ни в коем случае не говорю, что статья плохая, дело, конечно, во мне, просто хочется найти, наконец, статью, в которой действительно на пальцах, без трехэтажных формул, на аналогиях и примерах это все объясняется. Вот это было бы «на пальцах». Другой вопрос, возможно ли эту тему объяснить без формул — не знаю.

RainM
30.05.2016 12:25Если интересно, в книге Малинецкого (в ссылках к статье) есть математическое доказательство, почему образ распознается. Основная мысль, в том, что там вводится некоторый потенциал, характеризующий сеть и сеть стремится к минимизации этого потенциала. А минимумы потенциала — как раз образы, на которых обучали. Т.е. сеть движется в потенциальную яму, которая и есть обученный образ. Основная проблема в сети Хопфилда, что кроме обученных минимумов появляются еще дополнительные «фантомные» локальные минимумы.
Но да, соглашусь, не факт, что можно ввести и объяснить динамику сети совсем без формул.Tutanhomon
30.05.2016 12:27Спасибо, посмотрю.
RainM
30.05.2016 12:33предупреждаю сразу, математики и трехэтажных формул там сильно больше :-)
Tutanhomon
30.05.2016 12:35Могу представить )
Надо же хотя бы к 28 годам эту тему осилить, это же и ИИ, и распознавание образов, а когда ты занимаешься играми — такие вещи знать не помешает )

pilipenok
30.05.2016 12:48Очень рекомендую Вам попытаться осилить хотя бы половину известного курса www.coursera.org/learn/machine-learning#syllabus от Эндрю Ына (кстати 30-я мая старт новой сессии). Почти во всей литературе по теме к нейронкам приходят из анатомии строения мозга, Эндрю же «на пальцах» сначала объяснил регрессию, а потом из нее пришел к нейронкам. Формул немного и на них акцент он не делает.
rkfg
30.05.2016 13:59+1karpathy.github.io/neuralnets — вот самое лучшее объяснение на пальцах, без трёхэтажных формул (есть двухэтажные, но они разжёваны до уровня школьной арифметики), прямо с основ, с примерами из реальности и с кодом. Требуется знание арифметики и понимание JS, ну или любого C-подобного кода, просто примеры на JS. Ничего лучше не читал по теме, жаль, что автор не написал книгу в таком стиле, я бы купил.
Gryphon88
30.05.2016 15:11+3Очень прошу не использовать биологические аналогии. Пока неизвестно, как работает мозг, но не так :) Вообще, очень раздражает, когда физики и математики, обрастя премиями и забронзовев, лезут в нейрофизиологию, и за счёт своего авторитета в несмежной области вводят идиотские понятия и концепции.
«Услыхали физики про митоз,
И решили физики — наш вопрос!
Не пойти ли нам, друзья, в биологию?..»
Стих целиком: http://wwwinfo.jinr.ru/drrr/Timofeeff/auto/blumenfeld.html
vvadzim
01.06.2016 17:44+1>частота изменения состояний нейронов («тактовая частота») не превышает 200Гц, тогда как частота изменения состояния элементов современного процессора может достигать нескольких ГГц (10^9Гц).
Только в одном случае с частотой 200 герц изменяется состояние десятков миллиардов нейронов, а в другом — с частотой 10 млрд герц состояние одного процессора. Обычно по регистру за раз. Ну если без всяких указателей, типа стека и инструкций. Не знаю, если честно, какова разрядность нейрона, но если, как сейчас модно, 64 бита, то мозг раз в 200 мощнее. Вот у видях шанс есть.RainM
01.06.2016 17:47тем не менее на такой частоте в процессоре переключается достаточно много транзисторов. т.е. регистр состоит из значительного числа сначала логических элементов, которые состоят, в свою очередь, из транзисторов.
vvadzim
01.06.2016 17:52А те состоят из атомов, и электроны там бегают. Нейрон же тоже молекулами шевелит. Но я ж про выхлоп чистой информации. Тут как ни крути — у процессора 64 бита.
Ramdeif
05.06.2016 20:23Статья хорошая, вот только о тестировании сети маловато. Получается, что делали, делали, изучали разные формулы, писали код, а до практики не особо дотянули. Интересно было бы посмотреть процент верных ответов или практически установить зависимость между количеством нейронов и возможным количеством запоминаемых образов.
Terranz
релизовывал такую в универе в качестве курсовой по нейросетям на 4-м курсе на делфи
делал по книге Осовского
у вас на графике ошибка, которая, кстати, видна в коде — у сети нет входа, сеть пережёвывает собственный выхлоп, куда и надо положить исходные данные. Вы не закладываете ей на вход данные — вы его укладываете в выход и делаете итерацию
у Осовского правильный график, но в книге довольно туманное описание. На то, чтобы допереть до этого, мне понадобилось 2 дня
RainM
хм… какой график?
Код ровно соответветствует мат.постановке задачи: S(0) — входной образ, + есть определение S(t+1) = f(S(t)). S(t+1) == S(t) — условие окончания.
Terranz
Архитектура сети изображена на рис. 2.
на рисунке есть вход
у нейросети хопфилда нет входа, даже твоё мат описание тому подтверждение
RainM
Это вопрос терминологии, что называть «входом». В статье входом называется начальное состояние сети S(0), ровно то, о чем Вы говорите «у сети нет входа, сеть пережёвывает собственный выхлоп». И да, вход можно представить как S(0) = f(S(-1)), т.е. «вы его укладываете в выход и делаете итерацию»
Terranz
нет, это очень важно! мы тут не детские рисунки обсуждаем, а вполне серьёзную математическую модель
две большие разницы — сеть со входом и сеть без входа
вот правильный график модели
RainM
Это не входы, а стрелки, обозначающие текущее состояние S(t). Но, возможно, Вы правы, и во избежание недопонимания следует это поправить.