
В статье автор пытается проанализировать почему существуют торговые системы написанные на Java. Как может Java соперничать в области высокой производительности с C и C++? Далее размещены небольшие размышления о достоинствах и недостатках использования Java в качестве языка программирования/платформы для разработки систем HFT.
Небольшой дисклеймер: мир Java широк, и в статье я буду подразумевать именно HotSpot реализацию Java, если не сказано обратное.
1. Введение
Хочется намного рассказать про место Java в мире HFT. Для начала, давайте определимся с тем, что же такое HFT (High Frequency Trading). У этого термина существует несколько определений, объясняющих различные его аспекты. В контексте данной статьи я буду придерживаться объяснения, которое дал Питер Лаури (Peter Lawrey), создатель Java Performance User’s Group: «HFT — это торговля, которая быстрее скорости реакции человека (faster than a human can see)».
Торговые платформы HFT могут анализировать различные рынки одновременно и запрограммированы на проведение сделок в наиболее подходящих рыночных условиях. Применяемая прогрессивная технология дает возможность невероятно быстро обрабатывать данные тысячи транзакций в день, при этом извлекая лишь небольшую прибыль с каждой сделки.
Под данное определение подпадает вся электронная автоматической торговли с характерными временами сотни миллисекунд и меньше, вплоть до микросекунд. Но если достигнуты скорости в единицы микросекунд, то зачем в таком случае нужны системы, которые работают на порядок медленнее? И как они могут зарабатывать деньги? Ответ на этот вопрос состоит из двух частей:
- Чем быстрее должна быть система, тем проще должна быть заложенная в нее модель. Т.е. если наша торговая логика реализована на FPGA, то о сложных моделях можно забыть. И наоборот, если мы пишем код не на FPGA или plain assembler, то мы должны закладывать в код более сложные модели.
- Сетевые задержки. Оптимизировать микросекунды имеет смысл только тогда, когда это ощутимо может сократить суммарное время обработки, которое включает сетевые задержки. Одно дело, когда сетевые задержки — это десятки и сотни микросекунд (в случае работы только с одной биржей), и совершенно другое — 20мс в каждую сторону до Лондона (а до Нью-Йорка еще дальше!). Во втором случае оптимизация микросекунд, затраченных на обработку данных, не принесет ощутимого сокращения суммарного времени реакции системы, в которое входит сетевая задержка.
Оптимизация HFT систем в первую очередь преследует сокращение не суммарной скорости обработки информации (throughput), а времени отклика системы на внешнее воздействие (latency). Что это значит на практике?
Для оптимизации по throughput важна результирующая производительность на длительном интервале времени (минуты/часы/дни/…). Т.е. для подобных систем нормально остановить обработку на какой-то ощутимый промежуток времени (миллисекунды/секунды), например на Garbage Collection в Java (привет, Enterprise Java!) если это не влечет существенного снижения производительности на длительном интервале времени.
При оптимизации по latency в первую очередь интересна максимально быстрая реакция на внешнее событие. Подобная оптимизация накладывает свой отпечаток на используемые средства. Например, если для оптимизации по throughput обычно используются примитивы синхронизации уровня ядра ОС (например, мьютексы), то для оптимизации по latency зачастую приходится использовать busy-spin, так как это минимизирует время отклика на событие.
Определив, что такое HFT, будем двигаться дальше. Где же место Java в этом «дивном новом мире»? И как Java может тягаться в скорости с такими титанами, как C, C++?
2. Что входит в понятие «производительность»
В первом приближении, разделим все аспекты производительности на 3 корзины:
- CPU-производительность как таковая, или скорость выполнения сгенерированного кода,
- Производительность подсистемы памяти,
- Сетевая производительность.
Рассмотрим каждую составляющую подробнее.
2.1. CPU-performance
Во-первых, в арсенале Java есть самое важное средство для генерации действительно быстрого кода: реальный профиль приложения, то есть понимание, какие участки кода «горячие», а какие нет. Это критически важно для низкоуровневого планирования расположения кода.
Рассмотрим следующий небольшой пример:
int doSmth(int i) {
if (i == 1) {
goo();
} else {
foo();
}
return …;
}При генерации кода у статического компилятора (который работает в compile-time) физически нет никакой возможности определить (если не брать в расчет PGO), какой вариант более частый: i == 1 или нет. Из-за этого, компилятор может лишь догадываться, какой сгенерированный код быстрее: #1, #2, или #3. В лучшем случае статический компилятор будет руководствоваться какой-либо эвристикой. А в худшем просто расположением в исходном коде.
cmpl $1, %edi
je .L7
call goo
NEXT:
...
ret
.L7:
call foo
jmp NEXTcmpl $1, %edi
jne .L9
call foo
NEXT:
...
ret
.L9:
call goo
jmp NEXTcmpl $1, %edi
je/jne .L3
call foo/goo
jmp NEXT:
.L3:
call goo/foo
NEXT:
…
retВ Java же из-за наличия динамического профиля, компилятор всегда знает какой вариант предпочесть и генерирует код, который максимизирует производительность именно для реального профиля нагрузки.
Во-вторых, в Java есть так называемые спекулятивные оптимизации. Поясню на примере. Допустим, у нас есть код:
void doSmth(IMyInterface impl) {
impl.doSmth();
}Вроде бы все понятно: должен сгенерироваться вызов виртуальной функции doSmth. Единственное, что могут сделать статические компиляторы С/С++ в данной ситуации — попытаться выполнить девиртуализацию вызова. Однако на практике данная оптимизация случается относительно редко, так как для ее выполнения необходима полная уверенность в корректности данной оптимизации.
У компилятора Java, работающего в момент работы приложения, есть дополнительная информация:
- Полное дерево загруженных в данный момент классов, на основе которого можно эффективно провести девиртуализацию,
- Статистика о том, какая реализация вызывалась в данном месте.
Даже если в иерархии классов есть другие реализации интерфейса IMyInterface, компилятор выполнит встраивание (inline) кода реализации, что позволит, с одной стороны, избавиться от относительно дорогого виртуального вызова и выполнить дополнительные оптимизации с другой стороны.
В-третьих, компилятор Java оптимизирует программу под конкретное железо, на котором он был запущен.
Статические компиляторы вынуждены использовать только инструкции достаточно древнего железа для обеспечения обратной совместимости. В результате, все современные расширения, доступные в расширениях x86, остаются за бортом. Да, можно компилировать под нескольких наборов инструкций и во время работы программы делать runtime-dispatching (например, с использованием ifunc'ов в LINUX), но кто это делает?
Компилятор Java знает на каком конкретном железе он запущен и может оптимизировать код под данную конкретную систему. Например, если система поддерживает AVX, то будут использоваться новые инструкция, оперирующие новыми векторными регистрами, что значительно ускоряет работу вычислений с плавающей точкой.
2.2. Производительность подсистемы памяти
Выделим несколько аспектов производительности подсистемы памяти: паттерн доступа к памяти, скорость аллокации и деаллокации (освобождения) памяти. Очевидно, что вопрос быстродействия подсистемы памяти крайне обширен и не может быть полностью исчерпан 3 рассматриваемыми аспектами.
2.2.1 Паттерн доступа к памяти
В разрезе паттерна доступа к памяти наиболее интересен вопрос в различии физического расположения объектов в памяти или data layout. И тут у языков С и С++ огромное преимущество — ведь мы можем явно управлять расположением объектов в памяти, а отличии от Java. Для примера рассмотрим следующий код на C++):
class A {
int i;
};
class B {
long l;
};
class C {
A a;
B b;
};
C c;При компиляции данного кода компилятором C/C++, поля полей-подобъектов будут физически расположены последовательно, примерно таким образом (не учитываем возможный паддинг между полями и возможные data-layout трансформации, производимые компилятором):
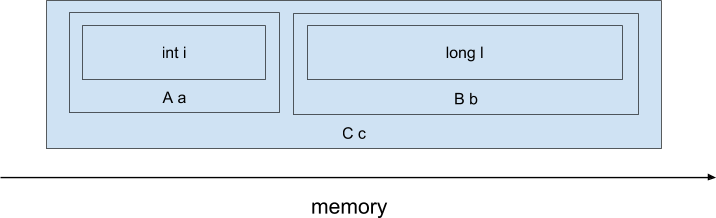
Т.е. выражение виде ‘return c.a.i + c.b.l’ будет скомпилировано в такие инструкции ассемблера x86:
mov (%rdi), %rax ; << чтение c.a.i
add ANY_OFFSET(%rdi), %rax ; << чтение c.b.l и сложение с c.a.i
retТакой простой код был достигнут за счет того, что объект располагается линейно в памяти и компилятор на этапе компиляции смещения требуемых полей от начала объекта. Более того, при обращении к полю c.a.i, процессор загрузит всю кэш-линию длиной 64 байта, в которую, скорее всего, попадут и соседние поля, например c.b.l. Таким образом, доступ к нескольким полям будет относительно быстрый.
Как же будут располагаться данный объект в случае использования Java? В виду того, что объекты не могут быть значениями (в отличии от примитивных типов), а всегда ссылочные, то в процессе выполнения данные будут располагаться в памяти в виде древовидной структуры, а не последовательной области памяти:
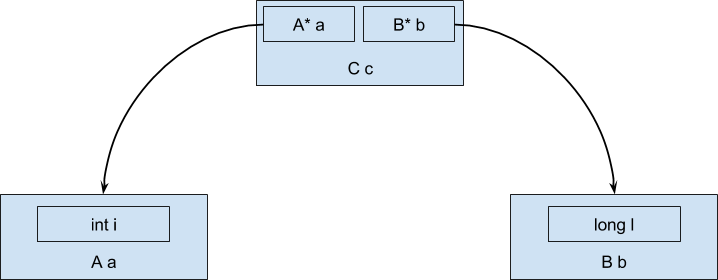
И тогда выражение ‘c.a.i + c.b.l’ будет компилироваться в лучшем случае во что-то похожее на такой код ассемблера x86:
mov (%rdi), %rax ; << загружаем адрес объекта a
mov 8(%rdi), %rdx ; << загружаем адрес объекта b
mov (%rax), %rax ; << загружаем значение поля i объекта a
add (%rdx), %rax ; << загружаем значение поля l объекта bМы получили дополнительный уровень косвенности при обращении к данным внутри объектов-полей, так как в объекте типа С находятся всего лишь ссылки на объекты-поля. Дополнительный уровень косвенности ощутимо увеличивает количество загрузок данных из памяти.
2.2.2. Скорость аллокации (выделения)
Тут у Java значительный перевес относительно традиционных языков с ручным управлением памятью (если не брать искусственный случай, что вся память выделяется на стеке).
Обычно для аллокации в Java используются так называемые TLAB'ы (Thread local allocation buffer), то есть области памяти, уникальные для каждого потока. Аллокация выглядит как уменьшение указателя, указывающего на начало свободной памяти.
Например, указатель на начало свободной памяти в TLAB'е указывает на 0х4000. Для аллокации, скажем, 16 байт нужно изменить значение указателя на 0х4010. Теперь можно пользоваться свежевыделенной памятью в диапазоне 0х4000:0х4010. Более того, так как доступ к TLAB'у возможен только из одного потока (ведь это thread-local buffer, как следует из названия), то нет необходимости в синхронизации!
В языках с ручным управлением памятью, для выделения памяти обычно используются функции operator new/malloc/realloc/calloc. Большинство реализаций содержат ресурсы, разделяемые между потоками, и намного более сложны, чем описанный способ выделения памяти в Java. В некоторых случаях нехватки памяти или фрагментации кучи (heap) операции выделения памяти могут потребовать значительного времени, что ухудшит latency.
2.2.3. Скорость освобождения памяти
В Java используется автоматическое управление памятью и разработчик теперь не должен вручную освобождать выделенную ранее память, так как это делает сборщик мусора (Garbage collector). К достоинствам такого подхода следует отнести упрощение написания кода, ведь одним поводом для головной боли меньше.
Однако это приводит к не совсем ожидаемым последствиям. На практике разработчику приходится управлять различными ресурсами, не только памятью: сетевыми соединениями, соединениями с СУБД, открытыми файлами.
И теперь ввиду отсутствия в языке внятных синтаксических средств контроля за жизненным циклом ресурсов приходится использовать достаточно громоздкие конструкции типа try-finally или try-with-resources.
Сравним:
Java:
{
try (Connection c = createConnection()) {
...
}
}или так:
{
Connection c = createConnection();
try {
...
} finally {
c.close();
}
}С тем, что можно написать в С++
{
Connection c = createConnection();
} // деструктор будет автоматически вызван при вызоде из scope'аОднако вернемся к освобождению памяти. Для всех сборщиков мусора, поставляемых с Java, характерна пауза Stop-The-World. Единственный способ минимизации ее влияния на производительность торговой системы (не забываем, что нам нужна оптимизация не по throughput, а по latency) — это уменьшить частоту любых остановок на Garbage Collection.
В настоящий момент наиболее употребимым способом это сделать является «переиспользование» объектов. То есть когда объект нам становится не нужен (в языках C/C++ необходимо вызвать оператор delete), мы записываем объект в некоторый пул объектов. А когда нам необходимо создать объект вместо оператора new, обращаемся к этому пулу. И если в пуле есть ранее созданный объект, то достаем его и используем, как будто он был только что создан. Посмотрим, как это будет выглядеть на уровне исходного кода:
Автоматическое управление памятью:
{
Object obj = new Object();
.....
// Здесь объект уже не нужен, просто забываем про него
}И с переиспользованием объектов:
{
Object obj = Storage.malloc(); // получаем объект из пула
...
Storage.free(obj); // возвращаем объект в пул
}Тематика переиспользования объектов, как мне кажется, не достаточно освещена и, безусловно, заслуживает отдельной статьи.
2.3. Сетевая производительность
Тут позиции Java вполне сравнимы с традиционными языками C и C++. Более того, сетевой стек (уровень 4 модели OSI и ниже), расположенный в ядре ОС, физически один и тот же при использовании любого языка программирования. Все настройки быстродействия сетевого стека, релевантные для C/C++, релевантны и для приложения на Java.
3. Скорость разработки и отладки
Java позволяет намного быстрее развивать логику за счет намного большей скорости написания кода. Не в последнюю очередь, это является следствием отказа от ручного управления памятью и дуализма указатель-число. Действительно, зачастую быстрее и проще настроить Garbage Collection до удовлетворительного уровня, чем вылавливать многочисленные ошибки управления динамической памятью. Вспомним, что ошибки при разработке на C++ зачастую принимают совершенно мистический оборот: воспроизводятся в релизной сборке или только по средам (подсказка: в английском языке “среда” — самый длинный по написанию день недели). Разработка на Java в подавляющем большинстве случаев обходится без подобного оккультизма, и на каждую ошибку можно получить нормальный stack trace (даже с номерами строк!). Использование Java в HFT позволяет тратить на написание корректного кода существенно меньше времени, что влечет за собой увеличение скорости адаптации системы к постоянным изменениям на рынке.
4. Резюме
В мире HFT то, насколько успешна торговая система зависит от суммы двух параметров: скорости самой торговой системы и скорости ее разработки, развития. И если скорость работы торговой системы — критерий относительно простой и понятный (по крайней мере понятно как измерять), то скорость развития системы ощутимо сложнее в оценке. Можно представить скорость развития как сумму бесчисленного множества факторов, среди которых и скорость написания кода и скорость отладки и скорость профилирования и удобство инструментальных средств и порог входа. Также, важными факторами являются скорость интеграции идей, полученный от аналитиков-квантов (Quantitative Researcher’ов), которые, в свою очередь, могут переиспользовать код продуктовой торговой системы для анализа данных. Как мне кажется, Java — разумный компромисс между всеми этими факторами. Этот язык сочетает в себе:
- достаточно хорошее быстродействие;
- относительно низкий порог входа;
- простоту инструментальных средств (К сожаления, для C++ нет сред разработки, сравнимых с IDEA);
- возможность простого переиспользования кода аналитиками;
- простоту работы под большими технически сложными системами.
Суммируя вышеперечисленное, можно резюмировать следующее: у Java в HFT есть своя существенная ниша. Использование Java, а не С++, ощутимо ускоряет развития системы. В вопросе производительности быстродействие Java может быть сравнимо с быстродействием C++ и кроме того, в Java есть набор уникальных, недоступных для С/С++ возможностей по оптимизации.
Комментарии (48)

ksergey01
26.06.2017 16:05+2В-третьих, компилятор Java оптимизирует программу под конкретное железо, на котором он был запущен.
Насколько мне известно — HFT-ники всё собирают там, где запускают. А там -mtune=native -mtune=nativeRainM
26.06.2017 16:07Тогда разработчикам нужно раздавать такие же железяки, как PROD сервера, чтобы микроархитектура была такая же. А если не раздавать, то можно наткнуться, что на PROD сервере все компилируется не совсем так, как должно.

jkotkot
26.06.2017 16:09+3Не обязательно. Напривет, если есть билдсервер, тесты и тимлид, который так или иначе вынуждает все делать правильно, то такие проблемы будут редки.
В любом случае, в этом бизнесе крутятся такие деньги, что купить всем нужные машины для разработки — не проблема.
jkotkot
26.06.2017 16:07+3Для всех сборщиков мусора, поставляемых с Java,
Есть еще и другие не поставляемые с ней. Для успешных торгов, в которых решаются такие проблемы.
Т.е. для подобных систем нормально остановить обработку на какой-то ощутимый промежуток времени (миллисекунды/секунды)
Секунда это довольно дофига даже на больших кучах (у нас десятки гигабайт). Не стоит забывать про всякие доп возможности ускорения GC типа ручного заnullения ссылок. Это помогает:)RainM
26.06.2017 16:13+1Да, согласен. Но тем не менее, длительность задержки напрямую зависит от размера хипа, а он может достигать ощутимых размеров, т.е. это всего лишь вопрос времени, когда время GC также достигнет ощутимых значений.
Если говорить концептуально, то именно управление памятью — та область, где и у Java и у C++ достоинства — продолжение их недостатков.
izzholtik
26.06.2017 16:45это помогает в каком случае и для каких GC?
jkotkot
26.06.2017 17:06В частности для разных generational GC, если объекты окажутся в разных поколениях, то получится быстрее. Подглядел такой трюк с описанием в исходниках JDK.

AndreyRubankov
29.06.2017 22:10С другой стороны, если вероятность попадания в разные поколения низкая — тогда раскидывание по коду обнуления ссылок приводит к выполнению лишних инструкций.
К примеру для young generation проще скопировать малое количество живых объектов и «зачистить» всю область. Если не делать пуллинг — это должно быть дешевле (был на эту тему даже доклад).
lagranzh
26.06.2017 16:14+4про кэширование объектов, все не так однозначно. Тут есть обратная сторона медали, даже две.
Во-первых если объекты пересылаются между потоками, то доступ к пулу надо синхронизировать. Даже без использования мьютексов, все равно получается медленно, т.к. объекту который в кэше процессора доверять нельзя, и значит нужно бегать в общую память.
Во-вторых, хоть объект и не освобождается, но на хипе хранится. Это приводит к тому, что когда объектов много, GC работает долго, и паузы длиннее, т.к. все эти объекты об должен проверить.
Алтернативы я знаю две:
- Использовать действительно парарельный GC без stop-the-world, например Azul C4, но он платный и дорогой.
- Не использовать хип вообще, а хранить объекты в памяти вне хипа.
Что касается JIT, с ним дело обстоит еще печальней. Дело в том, что большую часть времени програма сидит, ничего не делает и только слушает маркет дату. Ордеры она посылает редко, и с т.з. оптимизатора, это не тот path который надо оптимизировать. А с т.з. програмиста — ровно наоборот.
Более того, в самый неподходящий момент програма останавливается и начинает перекомпилироваться, потому что был задействован новый кусок кода (посылка ордера).
RainM
26.06.2017 16:21+2Про переиспользование объектов — возможно мы напишем немного подробнее.
С Azul C4 не все так однозначно :-)
А хранить все в офф-хипе, я думаю, может сильно повлиять на оптимизации в JIT'е: не факт, что компилятор осилит весь alias-анализ.
Про ордера — да, такая проблема есть. Тут есть несколько вещей, которые можно подкрутить в Java: количество вызовой, после которых происходит JIT-компиляция. А вторая возможность ощутимо побороть этот аспект — использовать ReadyNow от AZUL. Эта технология позволяет сохранить информацию динамическом профиле в файл и использовать ее при следующем запуске. Т.е. warm-up сокращается очень ощутимо.
А вообще, спасибо за интересный комментарий!
poxvuibr
26.06.2017 16:40Кстати насчёт Azul, Клифф Клик, помню презентацию делал про современные железки. Вот она, кажется. Там он говорит, что для HFT Java удобна по многим причинам, в том числе потому что память выделяет одним большим куском.
RainM
26.06.2017 16:51Спасибо за ссылку.
Скорость аллокации, действительно, огромная. Но очень неприятно, что вложенные объекты будут скорее всего расположены как дерево ссылок (не берем в рассчет скаляризацию), а не линейная последовательность адресов, что ощутимо влияет на суммарную производительность.

novoselov
26.06.2017 17:52А можно поподробнее что не так с Azul, был опыт в бою?
Сейчас кстати смотрим на ShenandoahRainM
26.06.2017 18:07Некоторый опят был, но с цифрами пока ответить не готов.
P.S. У Zing'а есть вполне официальный триал — можно взять, скачать, установить и пощупать. Рекомендую.
Кроме C4 там есть Falcon — компилятор на базе LLVM.
crea7or
26.06.2017 20:51Да даже c/c++ проигрывают железкам.
RainM
26.06.2017 21:07Да, согласен. Как я и писал, это всегда trade-of. Чем сложнее модель, тем она будет медленнее работать. И, соответственно, чем быстрее модель, тем она должна быть проще.

BalinTomsk
26.06.2017 20:56+1----К сожаления, для C++ нет сред разработки, сравнимых с IDEA
Вы имели ввиду IntelliJ?
Сравнивая с Visual Studio у меня есть глубокие сомнения, может развеете их ссылкой на сравнительные характеристики?RainM
26.06.2017 21:13Ее самую. Тут дело не в сравнительных характеристиках, так как подавляющее большинство разработчиков не используют и десятой части функций современной среды разработки.
Если говорить про мои претензии к VS:
1. VS начинает сильно тормозить на больших проектах
2. Всплывающая подсказка при программировании на C++ работает фундаментально хуже, чем при программровании на Java в виду значительно большей мощности языка (нет в Java даже примерных аналогов метапрограммрования на шаблонах, макросов, перегруженных операторов '->' и '.' и многого другого).
3 VS не работает на линуксе…ElectroGuard
27.06.2017 01:07Delphi + Lazarus, к слову, не имеет всех этих минусов. Имея при том плюс — нативный код.
RainM
27.06.2017 11:34Если я правильно помню, 64-битный компилятор Delphi появился совсем недавно. И я очень сильно не уверен в качестве генерируемого кода.
ElectroGuard
27.06.2017 16:1064 битный компилятор появился уже довольно давно. код генерируется хороший. более того — в новых версиях уже под все основные платформы собирается, правда — с помощью llvm.
ElectroGuard
27.06.2017 16:24Лазарь же + fpc генерирует код сам под где-то 20 платформ. И бинарники и среда работает на линуксе без особых вопросов как по скорости так и по надёжности.
Movimento5Litri
27.06.2017 11:37KDevelop пробовали?
По теме: знакомый как раз занимается HFT и у них как раз всё на Java но сейчас начинают потихоньку переписывать на С++, упёрлись в лимит производительности…RainM
27.06.2017 11:43KDevelop пробовал много лет назад. До VS тогда было еще далеко. Если приходится писать на C++, в основном использую emacs + gud-gdb; никак не соберусь прикрутить всплывающаю подсказку к Emacs'у.
Movimento5Litri
30.06.2017 17:24Попробуйте новую, 5 версию, мы парсер на clang переписали.
https://www.kdevelop.org/

Antervis
27.06.2017 06:58Если я правильно помню, вм java умеет оптимизировать обращения к данным с кучи на стек (как в вашем примере с *int)
В остальном — c++ позволяют переопределять аллокаторы, используя более эффективные алгоритмы управления памятью (всё равно, оптимизировать аллокацию надо в 1-2 местах в программе). И не забывайте про link-time optimization — он позволяет и встраивать функции, и девиртуализироватьRainM
27.06.2017 07:34+1Да, IPO здорово может помочь с inline и versioning'ом. Но на практике девиртуализация случается не так часто, как хочется. Кроме того, если в некоторый момент времени девиртуализация перестанет выполняться, узнать об этом можно будет только при анализе ассемблера или на перф.тестах.
А на счет скаляризации в Java — не самая работающая оптимизация в VM, на мой взгляд. Плют такие же проблемы, что сложно отследить, когда перестает выполняться. Т.е. просто дописали код в метод А, а в методе В, вызывающем А, перестала работать скаляризация, т.к. привышен лимит на inlineAntervis
27.06.2017 11:09+1Для девиртуализации должно выполниться несколько условий, одно из которых можно форсировать помечая класс наследника или вызываемый метод как final.
sasha1024
27.06.2017 10:37-1Что-то в моём восприятии картинка должна быть с точностью до наоборот: C/C++ — простые, но крепкие ножи; Java — сложный с кучей обёрток, C# — как изображён C++.
Ни кого ни в чём не пытаюсь убедить, понимаю, что на одни и те же вещи можно смотреть с разных ракурсов.RainM
27.06.2017 11:28«простой» — это точно не про С++ :-)
sasha1024
27.06.2017 12:08Ну, скажем так, по сравнению с Java/C#, он гораздо более «прозрачный». В том плане, что мы можем работать (при желании) low-level — то, что мы пишем, то и делается. А в Java/C# мы более оторваны от low-level.
(Вообще, я бы привёл скорее такую аналогию: C — лопата; C++ — лопата с кучей усовершенствований (типа попытки сделать эргономичную рукоять) и допфич (в стиле швейцарского ножа), неидеальная и уродливая с теоретической точки зрения, но на практике для умеющего пользоваться оказывающаяся таки удобнее обычной лопаты; Java, C# — трактора (это не плохо, но это другой класс механизмов), — но на выбранной картинке я бы поставил надписи именно так, как написал выше.)
RainM
27.06.2017 12:17Разрешите не согласиться на счет С++ «прозрачный».
Поясню: В Java достаточно строгий контроль типов и нет явно вычурных синтаксических конструкций. В С ++ же даже простое выражение «a || b && c» может выполняться совершенно по разному, если a, b, c — интегральные типы или классы с перегруженными операторами. Плюс, без отладчика, дизассемблера, совершенно не понятно, что будет выполняться, т.е. читать код достаточно сложно (ну, или как минимум, лщутимо сложнее, чем код на Java). Про неявное создание объектов в С++ даже говорить не буду…
Но да, именно С++ позволяет оперировать любым уровнем абстракции: от ассемблера до лямбд. И не смотря ни на что, именно этот язык мне нарвится больше всего.sasha1024
27.06.2017 12:40+1Ну, скажем так: С++ представляет собой (не совсем удачную) попытку расширить низкоуровневое до высокоуровневого (просто добавив «физическому» побольше абстракций). Java/C# же имеют или только высокоуровневое, или плохо связанные островки высокоуровневого и низкоуровневого.
Несмотря на то, что я считаю C++ очень неудачным языком, сама идея «просто добавить нижнему уровню побольше абстракций» мне импонирует гораздо больше. Так язык получается гораздо «осязаемее», ты «чувствуешь» что ты делаешь, что ли (разница как между нажимать кнопочки управления гидравлическими приводами экскаватора и физически «щупать» землю лопатой в руках — первое, может, и эффективнее, но…).
Но Ваш взгляд я тоже понимаю (просто я вижу «прозрачность» в прямой и очевидной связи low-level'а и high-level'а; а хреновый контроль типов и местами дурацкий синтаксис — это, конечно, отстой, но после привычки к ним всё равно имеешь контроль, хоть и сопровождающийся матами; а в случае отсутствия прямой связи между low-level'ом и high-level'ом контроля в принципе нет).
P.S.: Но, да, я Вас понял и во многом согласен.RainM
27.06.2017 12:47Будем считать, пришлит к консенсусу :-)
Мне тоже в С++ очень импонирует, что все можно выразить в терминах инструкций железа и адресов памяти.

rusfearuth
27.06.2017 12:43простоту инструментальных средств (К сожаления, для C++ нет сред разработки, сравнимых с IDEA)
В этом вопросе вы не компетентны ) Сначала исследуйте вопрос CLion от того же JetBrains ;)
RainM
27.06.2017 12:46Как же тогда связать CLion с autotools или plain Makefiles? И может ли работать CLion через ssh + screen/tmux? На сколько понимаю, по обоим пунктам — ответ отрицательный.
poxvuibr
27.06.2017 12:57И может ли работать CLion через ssh + screen/tmux?
Ну это вы хватили :). Это даже идея не умеет.
RainM
27.06.2017 13:02Зашел на сайл CLion. Раздел «What’s New in CLion 2017.1». Пункт — «Disassembly view». о_О чего же еще там нет, раз простой disassembly и тот только что появился…
poxvuibr
27.06.2017 13:09Много чего нет. Но то, что есть, по удобству должно быть сравнимо с Идеей. Мне тут сложно вести осмысленный диалог, для того, что я писал на С++, изрядно хватало CMake и юнит тестов.

fls_welvet
27.06.2017 14:40+1В статье написано «Аллокация выглядит как уменьшение указателя, указывающего на начало свободной памяти.», а затем идет пример с аллокацией 16 байт в диапазоне 0х4000:0х4010. Не должен ли быть диапазон 0х3990:0х4000, если следовать 1му утверждению?

Voila2000
27.06.2017 17:26«В мире HFT то, насколько успешна торговая система зависит от суммы двух параметров: скорости самой торговой системы и скорости ее разработки, развития.»
Мне кажется такой взгляд на вещи немного однобоким :) Хотя я половину статьи не понял, и вообще я не настоящий программист :)
Успешность любой торговой системы, на мой взгляд, это прибыль, которую она приносит с учетом стоимости накладных расходов, при заданном уровне риска.
HFT реализует идею получения преимущества за счет более быстрого доступа на торговую площадку по сравнению с другими участниками. Для успеха HFT системы важна как идея бизнес логики, так и возможность её практической реализации, то есть надежного исполнения ордеров и контроля остатков. Для инструмента программирования важно наличие хорошей библиотеки для подключения по скоростному протоколу к биржевому шлюзу. А основные инфраструктурные расходы, это размещение своего ПО на сервере брокера в дата-центре биржи и выбор скоростных линий связи.
Если же все эти задачи у основных участников решены схожим образом, и поиск конкурентного преимущества сосредоточился на выборе Java/C++, то прошу простить меня за дилетантский взгляд.
Seals
интересно, полезно — плюсую
RainM
Спасибо