
Понадобилось мне недавно написать аналог функции strstr(поиск подстроки в строке). Я решил его ускорить. В результате получился алгоритм. Я не нашел его по первым ссылкам в поисковике, зато там куча других алгоритмов, поэтому и написал это.
График сравнения скорости работы моего алгоритма, с функцией strstr на 600 кб тексте русскоязычной книги, при поиске строк размером от 1 до 255 байт:

Идея лежащая в основе алгоритма следующая. Сперва обозначения:
S — Строка в которой будет производится поиск будет называться
P — строка, которую ищем будет называться
sl — длина строки S
pl — длина строки P
PInd — табличка составляемая на первом этапе.
Итак идея такая: Если в строке S выбирать элементы с индексами равными: pl1, pl2,..., plJ,..., pl(sl/pl), то если в отрезок pl(J-1)...pl(J+1) входит искомая строка P, то тогда выбранный элемент должен принадлежать строке P. Иначе строка бы не вписывалась по длине.
Картинка, где нарисовано до куда дотягивается P, в pl*3.:
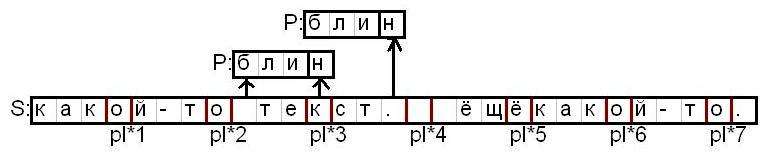
И ещё, так как выбранный элемент входит в строку P обычно маленькое число раз, то можно проверять только эти вхождения, а не весь диапазон.
Итого алгоритм такой:
Этап 1. Сортировка P
Для всех элементов(символов) строки P сортируем индексы этих элементов по значению этих элементов. То есть делаем так, что-бы все номера всех элементов равных какому-то значению, можно было быстро получить. Эта табличка будет дальше называться PInd:
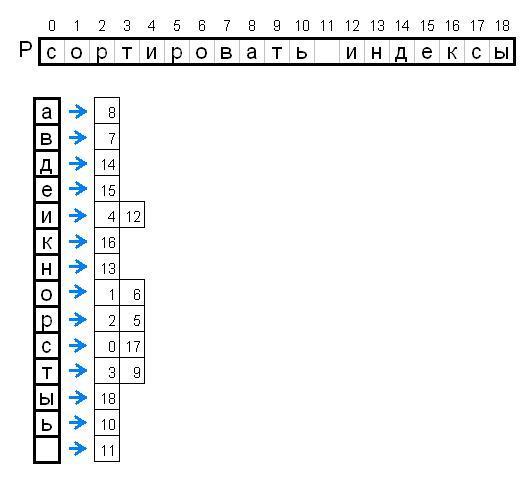
Как видно из этой таблички, при поиске на этапе 2 при искомой строке P равной "сортировать индексы" нам понадобится проверять максимум 2 варианта подстрок в S.
Сначала я для составления этой таблички использовал быструю сортировку и какую-то ещё, а потом я сообразил, что так как элементы строки однобайтовые, то можно использовать поразрядную.
Этап 2. Поиск
Проходим по строке строке S скачками равными pl, выбирая соответствующие элементы. Для каждого выбранного элемента проверяем входит ли он в строку P.
Если входит, то для всех индексов из PInd соответствующего элемента, проверяем совпадает ли подстрока S с началом в соответствующим индексу из PInd смещением относительно выбранного элемента и искомая строка P.
Если совпало, то возвращаем результат, если нет то продолжаем.
Худший вариант для этого алгоритма, зависит от способа сравнения строк во втором этапе. Если простое сравнение, то sl*pl+pl, если какой-то ещё, то другой. Я использовал просто сравнение, как в обычном strstr.
За счёт того, что алгоритм скачет через pl элементов и проверяет только возможные строки он работает быстрее.
Лучший вариант, это когда алгоритм проскачет всю строку S и не найдёт текст или найдёт с первого раза, тогда потратит примерно sl/pl.
Среднюю скорость я не знаю как подсчитать.
Вот одна из моих реализаций этого алгоритма, по которой строился график на языке си. Здесь pl ограничено, то есть таблица PInd строится по префиксу P длины max_len, а не по всей строке. Именно он использовался при построении графика:
char * my_strstr(const char * str1, const char * str2,size_t slen){
unsigned char max_len = 140;
if ( !*str2 )
return((char *)str1);
//Очистка массивов
unsigned char index_header_first[256];
unsigned char index_header_end[256];
unsigned char last_char[256];
unsigned char sorted_index[256];
memset(index_header_first,0x00,sizeof(unsigned char)*256);
memset(index_header_end,0x00,sizeof(unsigned char)*256);
memset(last_char,0x00,sizeof(unsigned char)*256);
memset(sorted_index,0x00,sizeof(unsigned char)*256);
//Этап 1.
char *cp2 = (char*)str2;
unsigned char v;
unsigned int len =0;
unsigned char current_ind = 1;
while((v=*cp2) && (len<max_len)){
if(index_header_first[v] == 0){
index_header_first[v] = current_ind;
index_header_end[v] = current_ind;
sorted_index[current_ind] = len;
}
else{
unsigned char last_ind = index_header_end[v];
last_char[current_ind] = last_ind;
index_header_end[v] = current_ind;
sorted_index[current_ind] = len;
}
current_ind++;
len++;
cp2++;
}
if(len > slen){
return NULL;
}
//Этап 2.
unsigned char *s1, *s2;
//Начинаем проверку с элемента S+pl-1
unsigned char *cp = (unsigned char *) str1+(len-1);
unsigned char *cp_end= cp+slen;
while (cp<cp_end){
unsigned char ind = *cp;
//Если выбранный элемент есть в строке P
if( (ind = index_header_end[ind]) ) {
do{
//Тогда проверяем все возможные варианты с участием этой буквы
unsigned char pos_in_len = sorted_index[ind];
s1 = cp - pos_in_len;
if((char*)s1>=str1)
{
//Сравниваем строки
s2 = (unsigned char*)str2;
while ( *s2 && !(*s1^*s2) )
s1++, s2++;
if (!*s2)
return (char*)(cp-pos_in_len);
}
}
while( (ind = last_char[ind]) );
}
//Прыгаем вперёд на pl
cp+=len;
}
return(NULL);
}Обновление: Это действительно не совсем прямая замена strstr, так как требует дополнительно параметр — длину строки S.
Комментарии (66)

napa3um
22.06.2016 11:56С Бойером-Муром бы сравнить. В целом, эвристики схожие.
hdfan2
22.06.2016 12:59+3До конца в алгоритм не въехал, но, по-моему, это и есть БМ или его модификация.
Автору: а почему !(*s1^*s2), а не *s1==*s2? Чем ваш вариант лучше?
MyNickFree
22.06.2016 13:24Я пытался так оптимизировать. Возможно это хуже. Я не уверен.

ptyrss
22.06.2016 13:41+2На -O2 разницы нет https://godbolt.org/g/VmtSls и https://godbolt.org/g/GVR4b6 без O2 == выглядит лучше
MyNickFree
22.06.2016 16:03+2Тут скорее всего получатся, что я перемудрил пока ускорял и сделал ошибку.
Да, наверно вы правы.
gaki
22.06.2016 12:13+2Вот только каждый раз, когда вы сохраняете скриншот с текстом и графиками в формате jpeg, Б-г убивает котёнка. Вы не могли бы найти время и перепилить иллюстрации, допустим, в формат PNG? Пожалейте котят!

evil_random
22.06.2016 12:46+13Каждый раз когда Вы пишете «б-г» или «Б-г» вместо «бог» или «Бог» умирает не только котёнок, а ещё пара тигрят и львенок. Пожалейте зверей, блин.
gaki
22.06.2016 12:49+2А как лучше — с большой буквы или с маленькой?
hdfan2
22.06.2016 12:55+15В данном случае с большой, т.к. имеется в виду единое верховное существо в монотеистических религиях, убивающее кошачьих. А если, не дай бог, в составе устойчивых выражениях, употребляемых в разговорной речи вне связи с религией, то с маленькой.
gaki
22.06.2016 16:59+5Я вообще думал, что каждый раз, когда я пишу «Бог» вместо «Б-г», Б-г убивает еврея…





StarCuriosity
22.06.2016 12:21+8А почему бы не воспользоваться стандартными алгоритмами, которым учат в вузах: Кнут — Моррис — Пратт, z-функция, Укконен, Суффиксный автомат, Ахо-Корасик и т.д.?
Whiteha
22.06.2016 13:06Потому что им нужна предобработка данных из-за которой выигрывать они будут только при условии частого поиска по одной и той же строке?
ptyrss
22.06.2016 13:27+6Сложность этих алгоритмов O(N+M) (в худшем случае), сложность strstr O(N*M), сложность вашего уже на этапе сортировки индексов не меньше чем O(N) + поиск, который будем считать пропорционален максимальному числу символов в 1 ячейке. В худшем случае, на строке вида abababababababa… (600,000 символов) когда мы будем искать к примеру ababa… аa (255 символов) мы сделаем 600,000/2 (начальных позиций) * 255 (длина) сравнений что может быть даже медленее, чем strstr. Пример — http://ideone.com/3Ucg7Z ваш метод — 1.1s, strstr — 0,05.
MyNickFree
22.06.2016 18:27О(M+N*M) — это худший случай, я о нём написал. И в обычных текстах такого не бывает.
Хотя да, вы правы. В худшем случае в текущей реализации съедать намного больше времени, чем обычный strstr. Такое сравнение надо заменить на что-то более адекватное, когда искомый текст повторяющийся.imwode
22.06.2016 21:12Ребят, напишите кто-нить пост человеческий, как сложность алгоритмов считать

zip_zero
22.06.2016 21:48+1Внутренне чувствую, что сложности алгоритмов – ваша любимая тема :)
А вообще, я не знаю, можно ли выразительно пересказать первую главу Макконнелла (ISBN 5-94836-005-9) в одном посте, сохраняя точность и полноту, а потом добавить «парочку» примеров из остальных глав – для закрепления и понимания.imwode
23.06.2016 05:13Она не любимая, она вообще ни разу мне не понятная
Когда курс проходил МИТ-шный, там типа упомянули вскользь, что-то вроде «Зачем вам статья. Это тривиальный материал который изложен в сотнях учебников. „
imwode
23.06.2016 05:14Блин, да почитать комменты к моему тому вопросу. Специалисты схлестнулись в битве.

zviryatko
22.06.2016 22:34+1Мне этот вариант понравился https://habrahabr.ru/company/mailru/blog/266811/
Laney1
22.06.2016 13:34в KMP и z-функции нет предобработки текста. Только строки, которую ищем. Суффиксные деревья, массивы и автоматы — это да.
MyNickFree
22.06.2016 13:20+1Кнут — Моррис — Пратт в моей списанной с интернета реализации получился чуть-чуть медленнее чем сам strstr. Поэтому я его даже на график не стал ставить. Остальные я пока изучаю.
encyclopedist
22.06.2016 13:27Опишите пожалуйста требования к алгоритму: какой алфавит (все 256 значений или намного меньше?) какой образец (длина?), какой текст (длина — порядка 1МБ?) Нужны ли повторные поиски того же образца или поиски разных образцов на том же тексте? Известны ли какие-то особенности текста (текст на естественном языке?) Известно ли что будет часто: образец не будет найден, будет найден, или будет найден в самом начале (образец очень часто встречается в тексте). Ответы на эти вопросы могут сильно повлиять на выбор алгоритма.
MyNickFree
22.06.2016 17:02Например:
Текст — массив любых символов от 1 до 255, заканчивающийся \0
Искомая строка — массив любых символов от 1 до 255, заканчивающийся \0
Поиск по тексту на естественном языке в самый раз.
Алгоритм станет очень медленным, если в строке искомой строке P очень часто встречается какой-то символ и одновременно этот символ очень часто встречается в тексте S. Это легко отследить на этапе составления таблицы с индексами и перекинуть на другой алгоритм. Частота вхождения должна быть действительно большой, но насколько большой я пока не считал. То есть нежелательно что-бы S и P имели вид: «оооооооооz», если символ «о» одинаковый в S и P. Короткие циклические S и P вида: «абвабвабвабв» с одинаковыми символами алгоритм тоже кажется не должен любить, но я не уверен, я не проверял.
Но это не совсем точно, потому что сказано только для текущей реализации, той что в статье.
ptyrss
22.06.2016 13:34Алгоритм КМП покажет себя при поиске подстрок больших чем 256 символов, он чуть медленее сам по себе, зато не содержит внутри сложности размер искомого образца. O(N) против O(N*M).
MyNickFree
22.06.2016 17:29По идее КМП покажет себя, только когда текст будет неудобным для этого алгоритма. Потому что КМП проходит по всем символам, а этот алгоритм может перепрыгивать большие блоки символов.
Хотя если текст неудобный, то в принципе легко заменить N*M из внутренней части алгоритма на тот же КМП, модифицировав его с учётом уже известных индексов начала строк.
drdoc
22.06.2016 13:35+1«длинна» поправьте в самом начале. Причем два раза подряд, врятли опечатка. Статьи рекомендую хотя б через вёрд прогонять :)
encyclopedist
22.06.2016 13:44Если Бойер-Мур кажется сложным, то можно начать с упрощённого варианта Бойера-Мура-Хорспула
ptyrss
22.06.2016 12:21А нельзя было вычислить все значения хешей отрезков длины от 1 до 255 для всей строки (сложность (255*L), памяти такой же порядок). Тогда поиск будет происходить за O(log L) или даже за O(1) (если использовать unordered_*), после чего при хорошей (хороших) хеш-функции можно даже не проверять результат, вероястно коллизии незначительна. Это метод если исходная строка не меняется.
Если длина образца не меняется, то можно считать хеши только от нужной длины, что убирает константу 255 из сложность алгоритма. После чего это будет чистый алгоритм Рабина-Карпа.
Если это разовая операция (каждый раз строка в которой надо искать новая), то существует целый класс алгоритмов: Z-функция, КМП — алгоритм и другие.
На какую из этих областей рассчитан ваш алгоритм и действительно ли он быстрее общеизвестных?

Ivan_83
22.06.2016 13:29strstr() — зло, ибо ищет ещё и ноль которого может не быть.
memmem() — то на что стоит полагаться.
Тупой поиск первого символа на SSE/AVX + последующее сравнение всё равно быстрее.
Вот если бы повторно использовали накопленные данные…
И при длине искомой строки в один символ алгоритм вырождается в memchr().VioletGiraffe
22.06.2016 14:01Можно подробнее про поиск на AVX?
Ivan_83
22.06.2016 16:16Реализация:
https://gist.github.com/vstakhov/99c04d6aa18e47c7950d
Измерения:
http://cebka.blogspot.ru/2015/04/how-fast-is-your-memchr.html
Ещё немного по теме
https://www.strchr.com/strcmp_and_strlen_using_sse_4.2
http://encode.ru/threads/1824-asm-Jumpless-bitcodec
https://www.klittlepage.com/2013/12/10/accelerated-fix-processing-via-avx2-vector-instructions/
Но я вроде что то другое ещё видел, сейчас найти не могу. Может там не поиск был, а сравнение, правда искал я по другой теме тогда и наткнулся случайно. Если найду запостю сюда.VioletGiraffe
22.06.2016 16:31Очень любопытно, спасибо!
Ivan_83
23.06.2016 01:02+1http://0x80.pl/articles/sse4_substring_locate.html
http://0x80.pl/articles/simd-friendly-karp-rabin.html
http://halobates.de/pcmpstr-js/pcmp.html
http://petriconi.net/?p=76
https://mischasan.wordpress.com/2011/06/22/what-the-is-sse2-good-for-char-search-in-long-strings/
http://jasonhcwong.blogspot.nl/2012/03/comparison-of-strlen-implementations.html
и memcmp
http://dpdk.org/dev/patchwork/patch/11156/

jcmvbkbc
22.06.2016 15:32strstr() — зло, ибо ищет ещё и ноль которого может не быть.
Он не ищет 0, он использует 0 в паттерне только для определения его длины.
mbait
22.06.2016 18:48strstr() — зло, ибо ищет ещё и ноль которого может не быть.
The strstr() function finds the first occurrence of the substring needle in the string haystack. The terminating null bytes ('\0') are not compared.
zip_zero
22.06.2016 13:34+1А можно пожалуйста выложить код бенчмарков вместе с тестовым набором данных?
И с какой именно реализацией strstr проводилось сравнение? Внезапно, их тоже много.
Меня смущает два момента:
1. сигнатура не совпадает с библиотечной, т.е. для прямой замены не годится:
char *strstr(const char *s1, const char *s2)
2. понятно, что делает max_len, но непонятно, откуда взялось волшебное число 140.
char * my_strstr(const char * str1, const char * str2,size_t slen){ unsigned char max_len = 140;zip_zero
22.06.2016 14:00+1Еще в тему – есть интересная статья, в которой автор утверждает, что создал самый быстрый вариант поиска подстроки в строке, и в доказательство приводит подробные сравнения алгоритмов.
MyNickFree
22.06.2016 15:461. Сигнатура действительно не совпадает. Там требуется длинна, что-бы он не перескочил через конец строки. Об этом я забыл упомянуть. Это действительно важно, просто забыл написать. Сейчас добавлю.
Да это действительно не прямая замена strstr, размер строки нужен обязательно. Я наверно неправильно выразился.
Это алгоритм, идею которого я почему-то не находил в поисковике(я ещё не во всех алгоритмах разобрался, возможно он где-то там и есть). Хотя идея проверять строку вот такими скачками совсем не очевидна, но очень полезна, и с помощью неё вполне можно сильно ускорить поиск.
Сравнение со strstr тоже скорее исторически обоснованное, потому что именно его я пытался обогнать на маленьких значениях искомой строки. Мне сказали, что у меня не получится именно на маленьких значениях, вот я и пытался.
Правильнее наверно было добавить другие алгоритмы поиска подстроки. Я добавил Кнута-Морисса-Пратта, он оказался медленней чем strstr(возможно из-за плохой реализации) и я его убрал, что-бы не отвлекал.
2. Значение max_len просто часть этой реализации алгоритма, по историческим причинам. Когда-то была кривая зависимости скорости выполнения от размера искомой строки и там около сотни был примерно минимум, поэтому он и сохранился. Вполне возможно он должен иметь другое значение, что-бы работать быстрее.
Большую часть суффикса разбирать на индексы нет смысла, потому что проверяться они будут очень редко. Поэтому ввел такое ограничение max_len. Но значение его в 140 действительно не очень обосновано.
Если бенчмарки — это код, где сравнивается быстродействие, то конечно могу выложить. Но там обычные си функции с не очень качественным кодом и если есть какие-то стандарты, которых нужно придерживаться в бенчмарках, то там их нет. Просто функции сравнения скорости. Выложить их код прямо сюда, в комментарии или на какой-то специальный сервис?
Если тестовый набор набор данных — это тесты, то они тоже в коде на си. И тоже могу выложить
А если тестовый набор данных — это то, на чем строился график, то это по моему текст русскоязычной книги, её я конечно выложить не могу.
strstr брался тот, который из string.h. Я конечно поискал сам исходный код этой функции, но тот код, который я нашел всегда был примерно одинаковым — двойным циклом. И работал примерно с одинаковой скоростью, с тем что появляется при подключении string.h. Возможно там действительно могут быть разные реализации, но я честно говоря не настолько силён в си, что-бы в этом разобраться.

lockywolf
22.06.2016 15:10DC3 для построения суффиксного массива, затем поиск по суффиксному массиву за O(M)?
MyNickFree
22.06.2016 18:01Точно! Суффиксный массив, вот как называется то, что делается на этапе 1.
Остальное описание тоже похоже:
Если в суффиксном массиве существую суффиксы начинающиеся с буквы найденной в тексте на позиции pl*i позиции, то для всех этих суффиксов вычисляется начало строки и начинается сравнение за то самое О(М), правда для обычных текстов почти всегда будет прерываться на первых символах.
А что такое DC3? Поиск не помогает.lockywolf
22.06.2016 18:25+1DC3 — это алгоритм построения суффиксного массива за О(n).
https://www.google.co.uk/search?q=dc3+algorithm+for+suffix+array&ie=utf-8&oe=utf-8&client=firefox-b&gfe_rd=cr&ei=calqV6rTDqnS8Afu0ovwAg
Есть ссылка на статью авторов: https://www.cs.helsinki.fi/u/tpkarkka/publications/jacm05-revised.pdf
(На удивление свежая статья. Там ещё и c++ код есть. 50 строк.)
Мне кажется, у вас поиск за (m log n), я не прав? У вас же посимвольное сравнение в строке?
Алгоритм для поиска за O(m) есть в статье авторов: http://www.zbh.uni-hamburg.de/pubs/pdf/AboKurOhl2004.pdf
Вообще, на хабре уже были статьи про суффиксные массивы: https://habrahabr.ru/post/115346/
MyNickFree
22.06.2016 19:11На плохих данных у меня сейчас поиск за О(M+N*M), а на обычных быстрее чем strstr'шный O(M*N).
Спасибо за ссылки. Сяду читать, на пару дней как минимум хватит.
StarCuriosity
23.06.2016 15:08>> DC3 — это алгоритм построения суффиксного массива за О(n).
Это тот самый алгоритм, о котором обычно рассказывают на лекциях, где идея в том, что мы переходим к новому алфавиту, состоящему из групп символов? Или это что-то новое придумали?StarCuriosity
23.06.2016 15:29Да, почитал — это, действительно известный всем алгоритм, так что те, кто учился по специальности, можете не тратить время — я уже потратил за вас =)
Laney1
23.06.2016 08:11почему, когда говорят о построении суффиксного массива за линейное время, упоминают только DC3? С момента его создания (примерно 15 лет назад) появилась куча алгоритмов, лучших во всех отношениях
Alesso
22.06.2016 19:14-1Друзья, подскажите начинающему программисту.
Хорошую статью про хеши и каким способом лучше всего искать вхождения слов в объемных текстах (>100 000 знаков).
C# медленно работает в этом плане. Запускал в потоках, что ускоряет, но хотелось бы увеличить скорость раз в 10.
Автор,
не совсем понял Вашу методику, но очень интересно. «Цикл с шагом по символам предложения»?
Не понял, что ищем… Символ из ключевого слова?
lockywolf
22.06.2016 20:04>>каким способом лучше всего искать вхождения слов в объемных текстах (>100 000 знаков).
Мне неловко давать ссылку на свой же собственный комментарий, но кажется, там есть то, что вам нужно: https://habrahabr.ru/post/303830/#comment_9669878
Alesso
23.06.2016 09:53lockywolf, спасибо. Видимо, для меня это слишком сложно, что пропустил. Попробую разобраться.Это интересно.

roman_kashitsyn
23.06.2016 12:11Это лишь простая эвристика, которая хорошо работает на подобранных вами данных, но плохо работает в общем случае. Если вы действительно упираетесь в скорость
strstr, Бойер-Мур, использующий похожую эвристику, считается одним из самых быстрых алгоритмов. Хорошая реализация есть в Folly, авторы утверждают о 30-кратном (в среднем) ускорении по сравнению с std::string::find в случае успешного поиска, и в 1,5-кратном ускорении в случае неуспешного поиска.
faustX
А вот и penny аукционы подъехали