

Вот уже несколько лет доступна такая возможность, как создание многоуровневого хранилища на базе EMC Isilon. Это подразумевает возможность отправлять данные в конкретные пулы хранения — системы узлов, объединённых по признаку однотипности или плотности размещения. В результате сильно вырастет эффективность хранения данных с точки зрения стоимости.
Можно создать политику, согласно которой все новые данные будут сохраняться в Пуле-1, построенном из быстрых узлов S210.

Время отклика будет очень небольшим, но стоимость окажется выше (более быстрые накопители, процессоры и т.д.). Далее можно создать политику второго уровня, например, «перемещать все данные, к которым не обращались более 30 дней, в Пул-2». Этот комплекс может быть построен из узлов Х410, обладающих большей ёмкостью (36 SATA-дисков) и более высоким временем отклика по сравнению с Пулом-1. Ещё менее востребованные данные можно перемещать уже в Пул-3, построенный из узлов HD400 с очень высокой плотностью хранения — 59 SATA-дисков + по 1 SSD на каждый 4U-модуль, но его время отклика ещё больше, чем у Tier 2. Но поскольку этот уровень предназначен лишь для очень редко востребованных данных, это не сильно повлияет на пользователей.
Перемещение данных на основании политик выполняется в фоновом режиме с помощью движка OneFS. При этом не меняется логическое размещение файлов. То есть можно создать одну папку, файлы в которой находятся в трёх разных хранилищах.
Пулы и уровни хранения
Одни и те же данные могут проходить разные стадии жизненного цикла: сырые данные, необработанные, обработанные, дубликаты, резервная копия, архив. Для каждой стадии характерен свой набор требований по доступности и сохранности данных. В отличие от многих других СХД, в которых разные типы информации хранятся совместно, в Isilon применяются разные уровни хранения (Tier). Для каждого уровня используются определённые политики по разделению, обработке и хранению данных. Такой подход позволяет удешевить хранение информации, находящейся в разных стадиях жизненного цикла, быстрее обрабатывать и эффективнее управлять ею. Эти задачи решаются с помощью уровней хранения, которые, в свою очередь, могут делиться на более узкоспециализированные пулы.
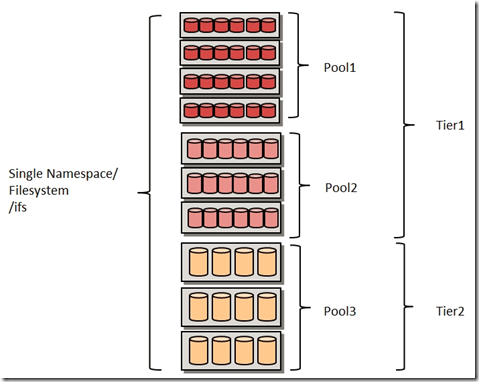
Единая файловая система для всех пулов/уровней хранения.
На сегодняшний день существует несколько видов пулов:
- S — быстрые, предназначены для транзакционных расчетов.
- X — быстрые, предназначены для потоковых задач.
- NL — более медленные, предназначены для создания «тёплых» архивов.
- HD — более медленные, предназначены для создания «холодных» архивов.
Также появился пятый вид — облако (внешнее или внутреннее).
Как уже упоминалось, каждый пул формируется из узлов одинакового типа (на самом деле, они могут слегка различаться, но это уже выходит за рамки поста). Если у вас развёрнут очень большой кластер, то вполне целесообразно разделить его на разные уровни хранения. Каждый уровень содержит один или несколько пулов. Но в ряде случаев нужды в таком делении нет. Вполне может возникнуть ситуация, когда ваши политики не будут подразумевать наличие пулов или уровней хранения.
Политики
Политики распределения данных по уровням хранения можно легко настроить с помощью WebUI, CLI или API. При этом в качестве критериев при создании политики можно использовать не только частоту обращения к файлам, но и типы файлов, их размещение, владельца или любой другой атрибут. В пользовательском интерфейсе уже есть заранее настроенные шаблоны, которыми можно воспользоваться. К примеру, шаблон Archive содержит правила, согласно которым более старые данные перемещаются в соответствующее хранилище. А шаблон ExtraProtect помогает настроить более высокий уровень защиты файлов с определёнными значениями атрибутов (например, n+3 вместо n+2). При этом самим WebUI пользоваться очень просто, он интуитивно понятен.

CloudPools — нововведение в OneFS 8.0
Одним из интересных нововведений, появившихся в OneFS 8.0, стал новый тип пула — облачный (Cloud). Теперь с помощью Object API он поддерживает:
- Amazon S3
- Microsoft Azure
- EMC Elastic Cloud Storage
- EMC Isilon
Последние два продукта, благодаря поддержке ряда API Object REST, могут быть использованы для создания частного облачного архива. Вероятно, можно ожидать внедрения поддержки других поставщиков облачных хранилищ, например, Google и Virtustream.
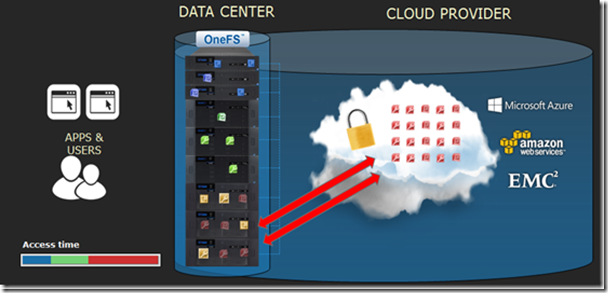
С помощью CloudPools можно использовать единую файловую систему для работы с облачным хранилищем.
Безопасность облачного хранилища
Предположим, что вы настроили политику, которая задаёт требования к файлам, которые должны быть перемещены в облако. Например, нужно переместить:
- Файлы размером больше 5 Мб -> И
- Файлы, расположенные в папке /ifs/data/stefan -> И
- Файлы, которые не запрашивали более трёх месяцев.
Политика будет применять согласно расписанию задач Smartpools. Как и в случае со всеми остальными задачами в OneFS, планирование и контроль исполнения осуществляются движком задач (job engine). Задачам может назначаться приоритетность и время исполнения, а в зависимости от текущей ситуации они могут ставиться на паузу.
Как только запускается Smartpools (например, каждый день в 22:00), он сверяет с текущими политиками все папки и файлы, и перемещает в облако те из них, кто соответствуют прописанным критериям.
В локальной файловой системе хранятся файлы заглушки (stub file), содержащие три типа информации:
- Мета-данные файла (время создания, время последнего обращения, размер и т.д.)
- «Ссылку» на данные в облаке.
- Часть исходных кэшированных данных.
Как уже упоминалось, с точки зрения пользователя или приложения нет никакой разницы между «нормальным» файлом и файлом заглушки. Конечно, при желании можно вычислить, но об этом мы поговорим в другой раз.
Вызов файлов из облачного пула и локального кэша
Когда происходит обращение к файлу заглушки, соответствующий контент извлекается из облака и кэшируется локально, на SSD или HDD. Но эти данные не будут храниться в файловой системе вечно. В противном случае любой пользователь мог бы забить всю локальную файловую систему одними лишь командами просмотра, ведь объём хранилища может в разы превышать объём локальной файловой системы. Поэтому лишь администратор или пользователь с соответствующими привилегиями могут присвоить каким-то данным атрибут постоянного хранения в кэше. Поведение самого кэша можно регулировать с помощью настроек CloudPools. К примеру, можно сказать кластеру, чтобы он:
- Кэшировал или не кэшировал локально вызываемые данные.
- Использовал механизмы Cache Read Ahead только для данных, к которым разрешён доступ, или для полных файлов.
- Хранил данные в кэше в течение определённого времени (от секунды до лет).
- С определённой частотой осуществлял отложенную запись в кэш (то есть насколько часто кластер должен записывать в облако данные, модифицированные в локальном кэше).
Срок хранения
Срок хранения — это сколько времени архивные данные будут сохраняться в облаке после удаления файла заглушки. Этот параметр можно настраивать отдельно для каждой политики. По умолчанию срок хранения равен одной неделе, после чего соответствующие данные удаляются. Кроме того, можно настроить:
- Срок хранения для инкрементального NDMP-бэкапа и SyncIQ. Это параметр определяет, сколько времени будут храниться данные в облаке после синхронизации с другим хранилищем с помощью SyncIQ, либо после бэкапа, выполненного в рамках инкрементальной NDMP-задачи. По умолчанию срок хранения в данном случае равен 5 годам. То есть после удаления локального файла заглушки его можно восстановить с помощью NDMP или SyncIQ, при этом данные будут доступны в течение указанного периода.
- Срок хранения для полного NDMP-бэкапа. Всё то же самое, что и в предыдущем случае, только для полных NDMP-бэкапов.
Заключение
CloudPools — это удобный инструмент, позволяющий создать из горизонтально масштабируемой NAS-системы Isilon прозрачное внешнее многоуровневое хранилище. На данный момент поддерживаются два сторонних облачных сервиса и две внешние системы (Isilon, ECS). Наверняка список поддерживаемых сервисом и систем будет существенно расширен. С точки зрения клиента перемещение данных осуществляется прозрачно, а безопасность обеспечивается благодаря шифрованию с помощью AES-256. Иными словами, с помощью CloudPools можно реализовать масштабируемую мультипротокольную систему с малым временем отклика, пределы роста которой практически не ограничены.
За рамками этой публикации остались ряд важных вопросов. Например, производительность: что будет с файлами заглушки в ходе бэкапа и репликации? Что насчёт аварийного восстановления, доступа к данным в CloudPools со стороны разных сайтов, постепенного создания CloudPools-системы? Об этом мы напишем в одной из следующих публикаций.
Поделиться с друзьями