

Продолжаем публиковать материалы форума Облачные технологии в России, который наша компания вместе с технологическим партнером HUAWEI провели 23 июня в LOTTE HOTEL MOSCOW. Первые три части вы можете прочитать здесь: часть I, часть II, часть III. Сегодня представляем читателям интересный доклад Дениса Дубинина на тему современных инструментов создания облачных решений.
Денис Дубинин, менеджер по продуктам ИТ, сервера, СХД, виртуализация, HUAWEI
Добрый день! Зовут меня Денис Дубинин, я продакт-менеджер компании HUAWEI по продуктам, серверам СХД и системам виртуализации. Сегодняшняя тема моего доклада называется FusionCube, FusionSphere, инструменты для создания облаков. Кто-нибудь пользовался уже нашим ПО, облачным, скажем так, направлением? FusionSphere, какими-то другими вещами? FusionStorage? То есть вообще никто не сталкивался? Ну сегодня попытаюсь приоткрыть тайну, висящую над этими продуктами, что же они из себя представляют. Начну я сейчас с решения FusionCube, что это такое.

Пару слов о компании HUAWEI. Компания HUAWEI — международный лидер по производству телеком-оборудования для различных операторов связи — сотовой связи, фиксированной связи, магистральных каких-то линий. Вот слышал, тут сегодня были разговоры про оптику Владивосток, Сахалин и прочее, прочее. Собственно, этими вопросами тоже HUAWEI занимается. В принципе, здесь коротко наше портфолио, чем же занимается HUAWEI в направлении энтерпрайз — облачные решения, про которые мы сегодня поговорим, серверы, системы хранения данных, сетевое оборудование, достаточно широкого профиля от, еще раз, магистральной оптики, заканчивая вай-фаем, коммутаторами для центра обработки данных, стандартных кампусных решений. Есть решения по сетевой безопасности, анти-DDOS решения, антивирусные файерволы и прочее, прочее, прочее…спектры трафика и так далее. И инженерная инфраструктура для ЦОД, т.е. HUAWEI также производит бесперебойные источники питания, кондиционеры, модульные ЦОДы, контейнерные ЦОДы и все, что с этим связано.
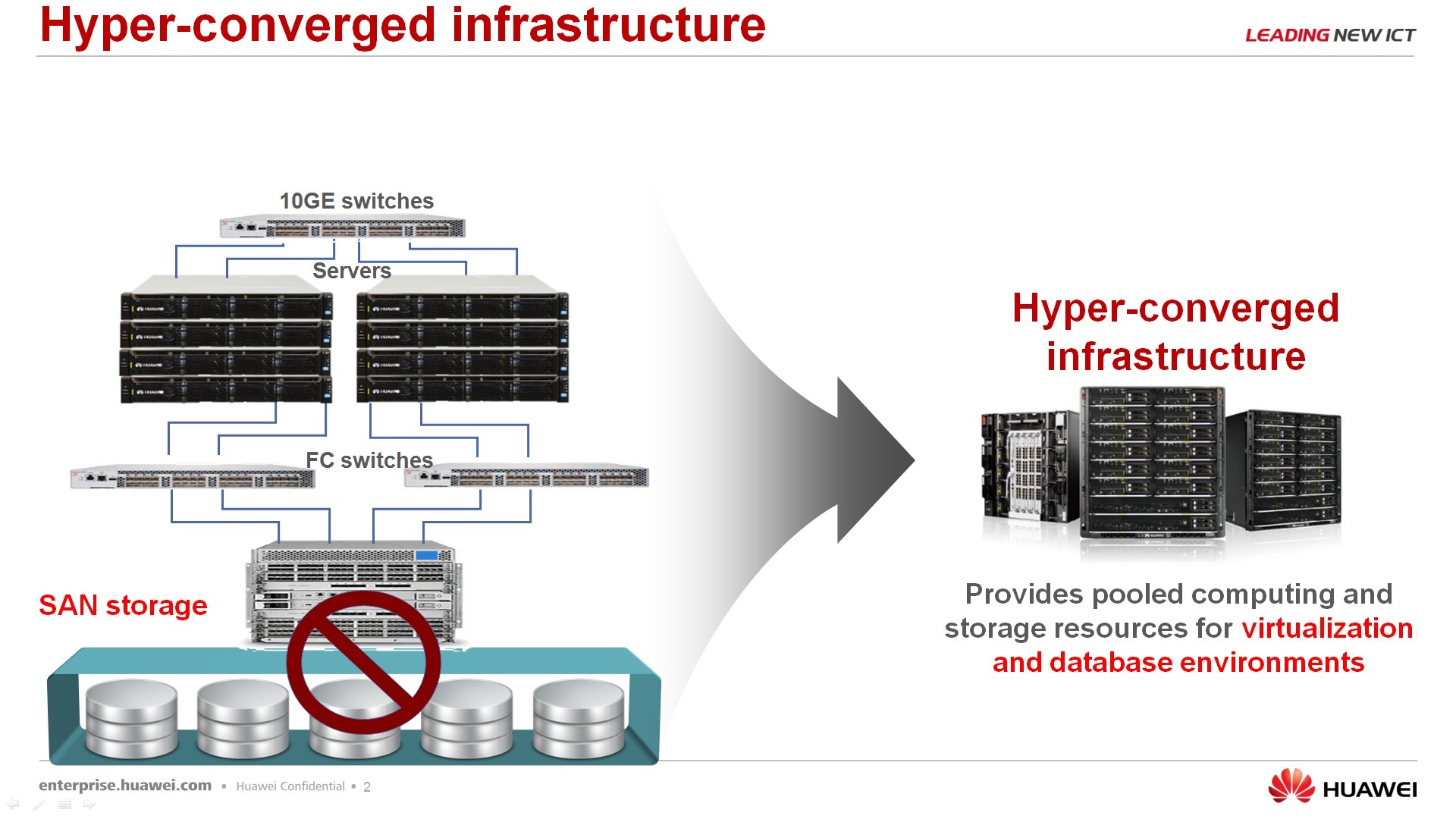
Про решение FusionCube, что же это такое. FusionCube – это гиперконвергентное решение, которое, скажем так, позволяет заказчику сэкономить время, сэкономить ресурсы для того, чтобы развернуть IT-ландшафт для какой-то своей задачи. Почему не просто конвергентное, а именно гиперконвергентное – потому что в едином корпусе, в едином шасси все три компонента, собственно, сервера, сетевое оборудование и система хранения данных. Причем, система хранения данных это не отдельные аппаратные выделенные элементы, а для системы хранения данных используются ресурсы самих серверов, т.е. устанавливается определенный софт, получаем software defined storage, и этот software defined storage презентуем собственно сереверам, которые вращаются на этой же аппаратной платформе. В текущий момент у нас, скажем так, две модели – FusionCube 9000 и FusionCube 6000.

Параметры их здесь приблизительно видны. Значит, старшая модель позволяет в одном шасси получить до 32 процессоров, 12 терабайт оперативной памяти, 172 терабайта под систему хранения данных. FusionCube 6000 – решение полегче, попроще, поменьше – здесь до 8 процессоров, до 2 терабайт оперативной памяти на такой модуль и до 280 терабайт хранения. В принципе, тут уже указаны для младшей модели общие направления, для чего стоит применять, скажем, вот это решение, то есть до виртуализации 60 каких-то серверов, до 280 рабочих мест виртуализированных. Если вам нужно больше параметры, то, наверное, стоит уже рассматривать решение 9000-е.

По поводу применения FusionCube. FusionCube — это не равно облако. FusionCube — это не равно виртуализация. FusionCube, скажем так, это равно некая универсальная структура, некий универсальный IT-ландшафт, который вы вольны распределять, использовать на свое усмотрение.
Для 9000-х систем существуют уже апплайенсы протестированные, готовые, сертифицированные для решений с УБД, баз данных, такие как SAP HANA, ORACLE и прочие. Есть решения гибридные, когда часть нод используется под виртуализацию, часть НОД используется под базы данных, допустим, часть нод используется для узлов SAP HANA.
Для 6000-й системы, как для более младшей системы, все-таки в большем приоритете виртуализация, причем виртуализация достаточно широкого профиля — VDI, облака, серверная виртуализация и так далее.
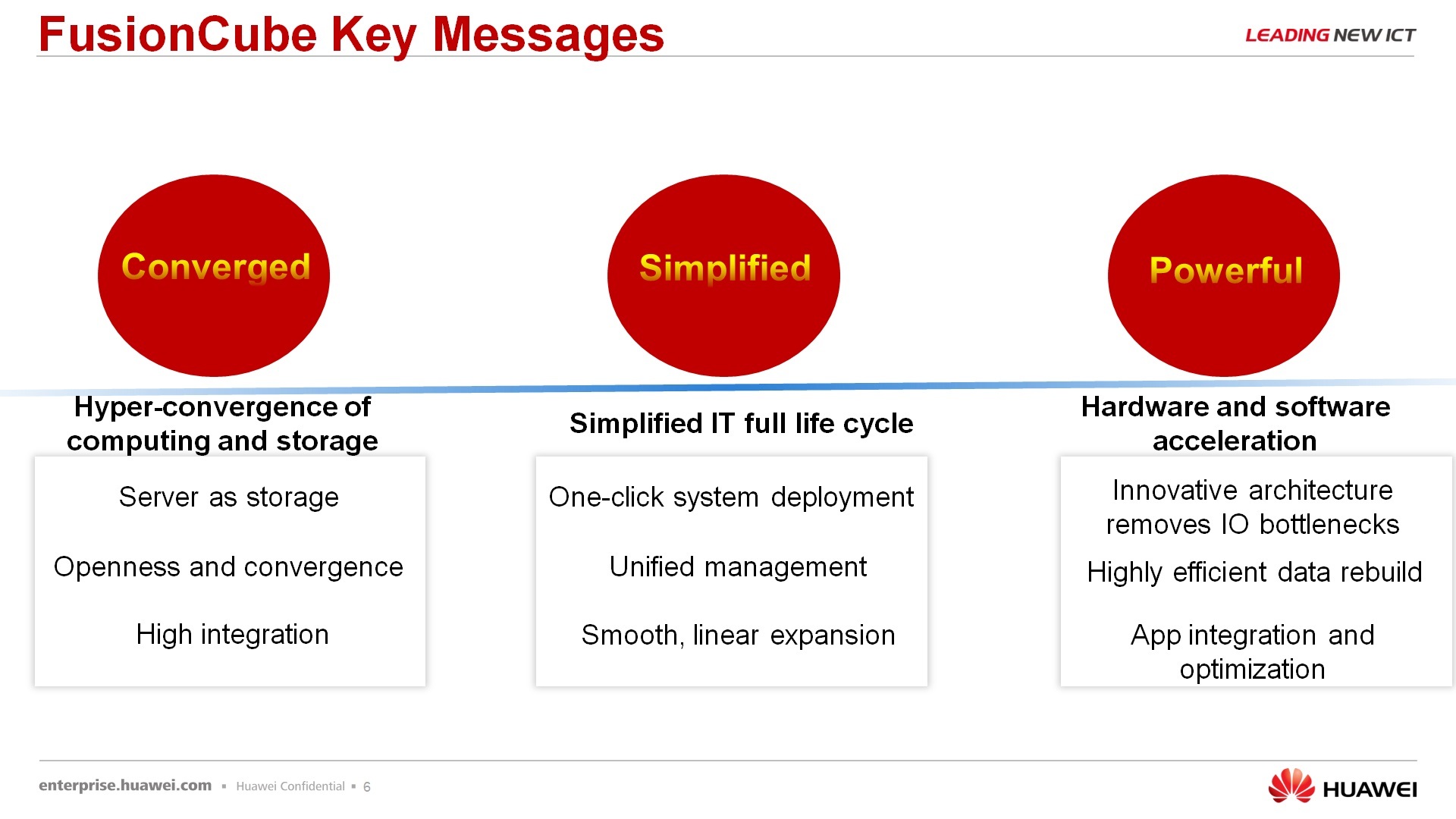
По поводу, из чего же состоит FusionCube и почему мы FusionCube называем определенный набор решений, а не просто любой наш сервер обзываем FusionCube. По решениям, первое – конвергентное. В этом решении отсутствует выделенное СХД. Если мы поставили несколько серверов в один ряд, прикрепили к ним СХД аппаратную, то это уже не FusionCube. Это просто какой-то кластер. Упрощенно, управление вот этим FusionCube происходит из одного окна, то есть менеджмент и управление аппаратным железом, софтверными вещами, которые на нем установлены, производится из одной консоли операторской. Ну и решение достаточно мощное, потому что используется, опять же, распределенное СХД и ряд элементов, которые повышают производительность. Это передача данных по InfiniBand и использование наших SSD PCI-экспрессных карт для хранения данных и для кэширования данных.
Следующий момент – открытость решения, то есть, еще раз говорю, мы не заставляем заказчика или нашего партнера, вот вы приобретаете наш FusionCube, и дальше используется в одном каком-то, не знаю, направлении, в одном сценарии. Вы можете, в принципе, создать этот сценарий сами, т.е. от нас вы получаете вот это железо, от нас вы получаете виртуальную СХД, получаете, допустим, модели управления, ПУ управлением, но всю последующую набивку, как в операционных системах, приложениях, баз данных и так далее остается на ваш выбор.
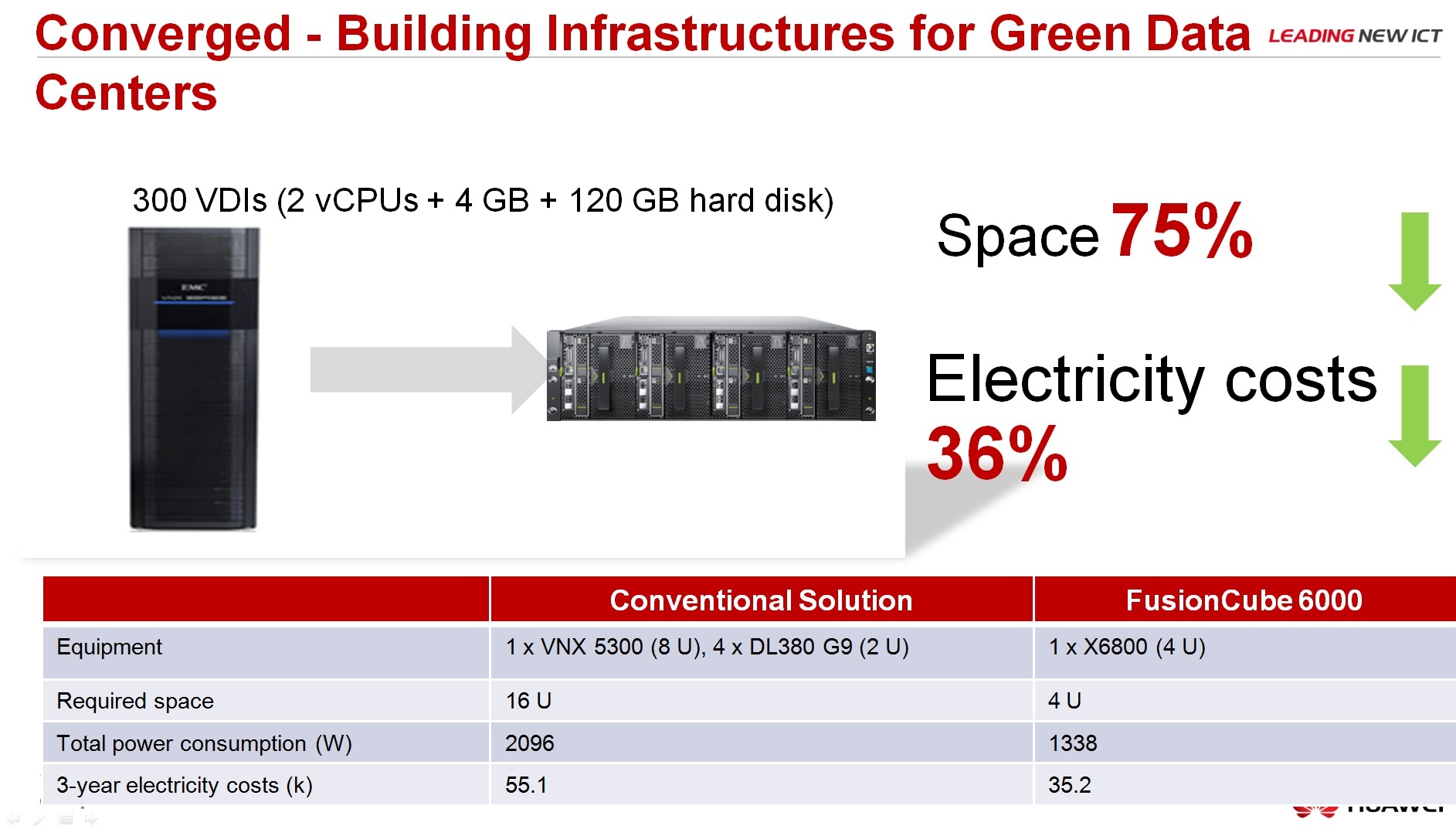
Про сравнение с классической архитектурой, преимущества: меньше занимает места в несколько раз, энергоэффективность, зеленые технологии и так далее.
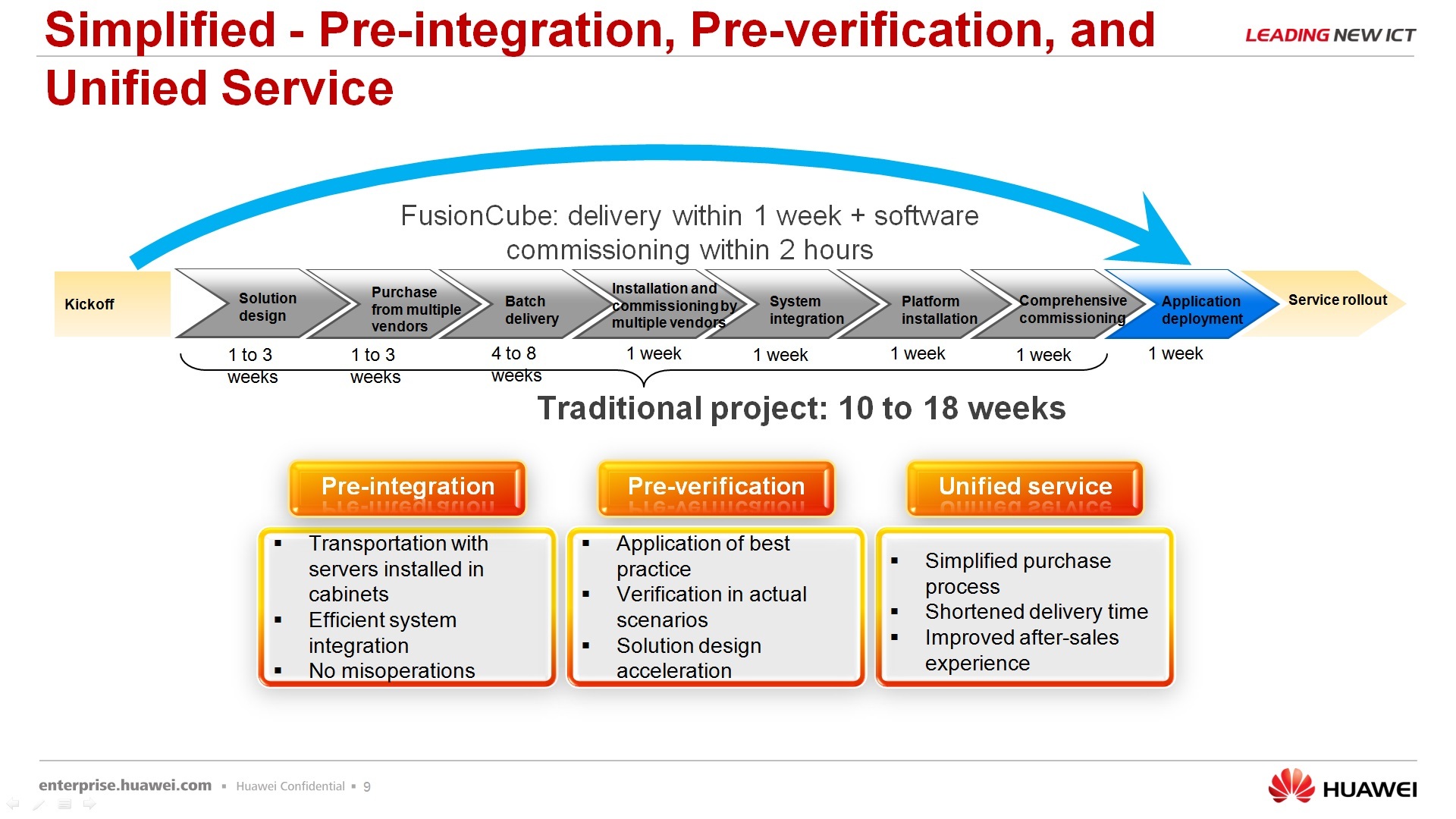
Про еще один плюс этого решения – оно позволяет сократить время на развертывание, то есть вам не нужно получать оборудование от разных вендоров, потом его интегрировать, потом получать ПО от третьего вендора, его тоже интегрировать, запускать все в работу, сдавать заказчику, потом бороться с багами, скажем так, от всех вместе взятых. Наше решение всегда поставляется с единым саппортом, с единой точкой входа, под единое конкретное решение.

По поводу быстрого развертывания – для тех, скажем так, протестированных сценариев, которые предлагаем мы с использованием FusionCube, уже готовые есть инструменты, которые позволяют быстро развернуть этот FusionCube под конкретную задачу. Есть ПО, называет FusionCube Builder – это installation tool, т.е. вы его запускаете на своем лэптопе, по сети подключаете к FusionCube, как в визарде делаете – next, next, next, в итоге получаете тот ландшафт, который вы заказывали. И FusionCube Center – это, собственно, менеджмент платформа, которая позволяет интегрировано этим всем, ну не скажу чтобы до конца управлять, но, по крайне мере, мониторить точно на 100%.

Следующий момент – линейный рост. Поскольку нет выделенной СХД, при увеличении количества серверов, линейно растет, как производительность самих серверов, так и производительность СХД, то есть как бы вы количество пользователей, VDI у вас ни росло, ни росло количество серверов, используемых в решении, производительность остается на том же уровне. Повышение количества пользователей не вызовет у вас какого-то уменьшения производительности работы этих пользователей, имеющихся.

Из преимуществ, про software defined storage будет еще дальше рассказано, но собственно, чем оно отличается от классической архитектуры. В классической СХД присутствуют – сеть передачи данных, san сеть, либо 10 Гбит, либо 8 Гбит файбер ченнел, либо 16 Гбит файбер ченнел, дальше стоит контроллер, в классических системах 2-контроллерные машины, сейчас идет развитие мульти-контроллерных систем, но, как правило, количество контроллеров в СХД ограничено. Я, допустим, не знаю ни одной СХД, в которой контроллеров больше восьми. Скажем так, можем повысить эту цифру – больше 16 контроллеров точно нет у СХД. И, собственно, количество дисков, которое может обслужить этот контроллер. Мы все при использовании классической архитектуры СХД можем в любой момент времени упереться в один из этих ограничивающих факторов. Либо san сеть у нас начинает тормозить, не хватает производительности, либо контроллер в СХД, имеющийся, начинает тормозить, не хватает производительности, либо количество дисков – мы дошли до того предела, что дальше диски ставить просто некуда. От всех этих проблем на избавляет, собственно, распределенное хранилище, где каждый сервер, во-первых, является узлом хранения, поэтому при увеличении нагрузки у вас, естественно, растет количество серверов, которое должно переваривать эту нагрузку и автоматически растет количество узлов в виртуальной СХД. Таким образом, мы избавляемся от узкого места по поводу жестких дисков. Больше серверов, больше дисков, если нужно еще больше дисков, мы просто добавляем сервера в нашу инфраструктуру, практически ничем не ограничены.
Передача данных между узлами, служебная информация, я имею в виду, происходит по протоколу InfiniBand с минимальными задержками, с минимальной латентностью, со скоростью 56 Гбит в секунду. Наружу это может отдаваться по гигабитному эзернету, по 10-гигабитному эзернету, ну или, если у вас специфические задачи по тому же InfiniBand-у может отдаваться. Количество кэша, количество портов ввода-вывода, количество процессоров в виртуальном контроллере СХД так же пропорционально количеству узлов. Поэтому при использовании распределенной системы, Вы, в принципе, уткнуться при текущих реалиях в производительность не должны.

Вернусь немножко назад, я говорил, что Fusion Cube – это не значит облако, даже частное, это не значит 100% виртуализация, это значит – какой-то универсальный IT-ландшафт, причем он уже может быть протестирован и существовать рекомендации, сертификации, о том, как этот ландшафт использовать. Вы его можете использовать под Oracle, под IBM DB2, Sybase, под решения SAP HANA, если с такими работаете, под FusionSphere, опять же приложениями sub и под, в принципе, просто виртуализацию на базе VmWare, в принципе можно использовать и с нашей FusionSphere, надо было добавить, наверное, еще седьмую строчку, как бы самый очевидный вариант.
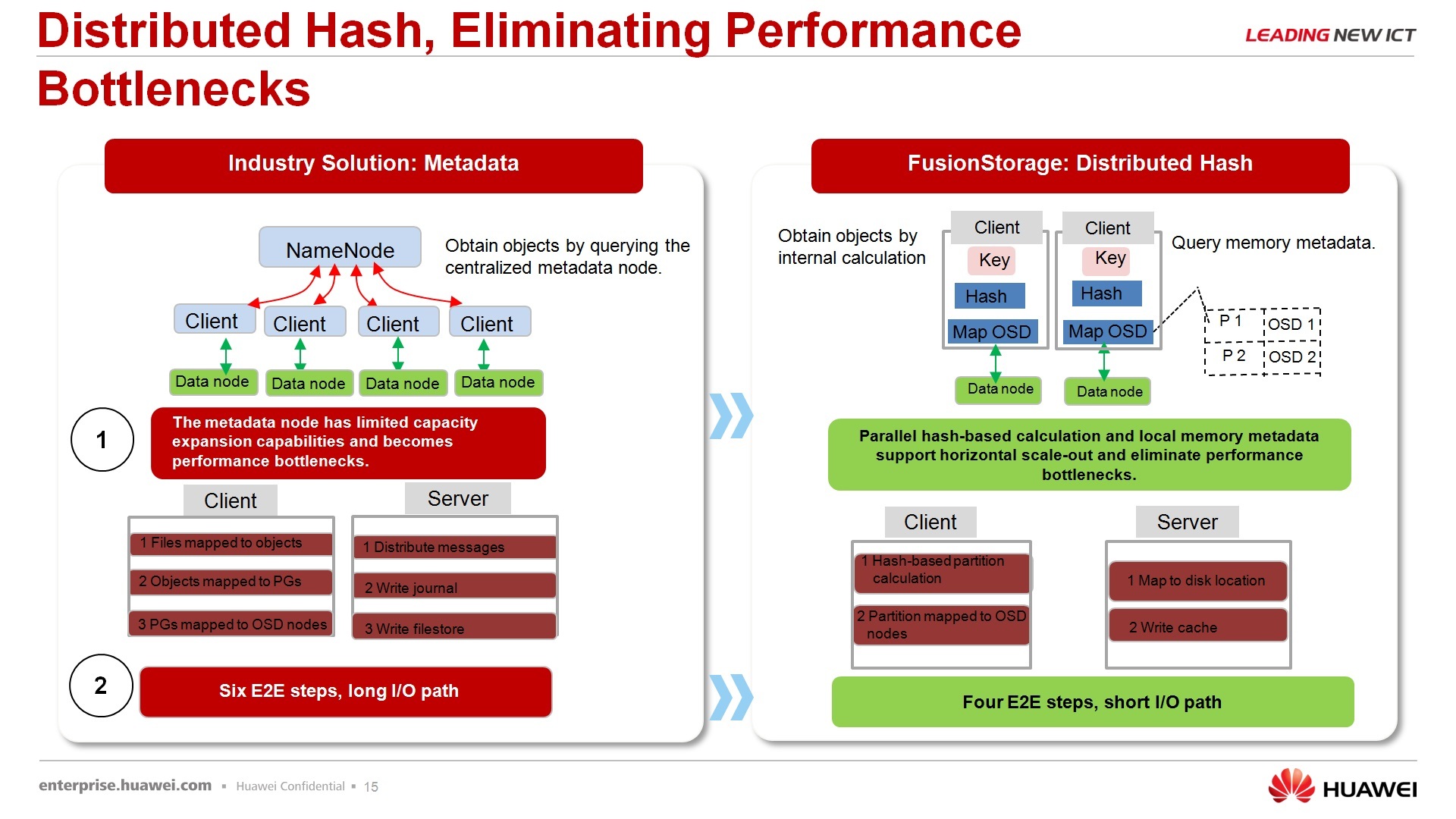
Про распределенное хранилище – распределенные хранилища на рынке предлагаем не только мы. В общем-то есть и другие вендоры, которые только софтверной частью, скажем, занимаются этого вопроса, есть вендоры, которые предлагают одновременно и софтверные и аппаратные решения, но, как правило, все эти решения выполнены по следующей структуре: есть хранилище данных или объектовое хранилище и есть хранилище метаданных. Как правило, узким местом является хранилище метаданных, т.е. это те сервера или выделенные СХД небольшого объема, но достаточно производительное, на которых лежат, грубо говоря, данные о том, где лежат все остальные данные, некоторая такая, если перевести к файловым системам, fat-таблица, т.е. вот этот сервер знает, где лежат все остальные данные. И, в принципе, вот этот вот узел, сервер метаданных, является узким местом.
Почему он не является узким местом для нашего решения – потому что мы не храним метаданные в явном виде, мы храним только хэш-суммы, т.е. когда сервер отсылает запрос за каким-то блоком данных, он не отсылает его в явном виде, т.е. блок такой-то, цилиндр такой-то файл такой-то и т.д., встроенный драйвер, который инсталлирован в систему, высчитывает хэш-сумму от данного запроса и отправляет в сторону нашей виртуальной СХД только вот этот вот запрос, состоящий из хэш-суммы. Запрос этот минимальный, в принципе, объем хэш-таблицы у нас 232, я не знаю сколько это миллиардов, олимпиардов является в десятичном виде, и, в принципе, вся эта таблица занимает 6Мбайт, и каждый узел, участвующий в системе хранения данных, хранит копию вот этой таблицы. Она у нас называется, правда, не таблица, а кольцо, но смысл, что это функционально, что это таблица. То есть весь этот объем 6Мбайт всегда хранится у узла в оперативной памяти, даже скажу больше, он часто хранится в кэше процессора, т.е. в самом быстродействующем месте, и, в принципе, он распределен равномерно между всеми узлами, которые участвуют в хранении. Поэтому за счет этого обращения по хэш-сумме, т.е. сервер обращается «где мои данные», драйвер обрабатывает запрос, говорит «вот по адресу этого хэша», хэш отсылается к хранилке, хранилка обрабатывает этот кэш, говорит «вот этому хэшу соответствует вот тот-то узел хранения», приходит запрос на узел хранения, и уже вот это запрос разбирает узел хранения и он уже знает, где у него что лежит по полочкам. То есть за счет вот этого уменьшения передаваемых данных по адресации и распараллеливание этих запросов, что можно хэш-сумму высчитывать параллельно на нескольких машинах и так далее, и так далее, получается более высокая производительность.

Что еще у нас используется из позитивного – это распределенный кэш. Между узлами хранения кэш может распределяться, т.е. отсутствуют выделенные острова кэша, когда отдельный узел обладает своим кэшем и про этот кэш никто не знает. Можно использовать следующий механизм работы, когда кэш вот этого узла будет частично реплицироваться с кэшем другого узла. И когда будет происходить запрос другому узлу, вот эти данные уже будут находиться в горячем кэше, что, в свою очередь, тоже повышает быстродействие.
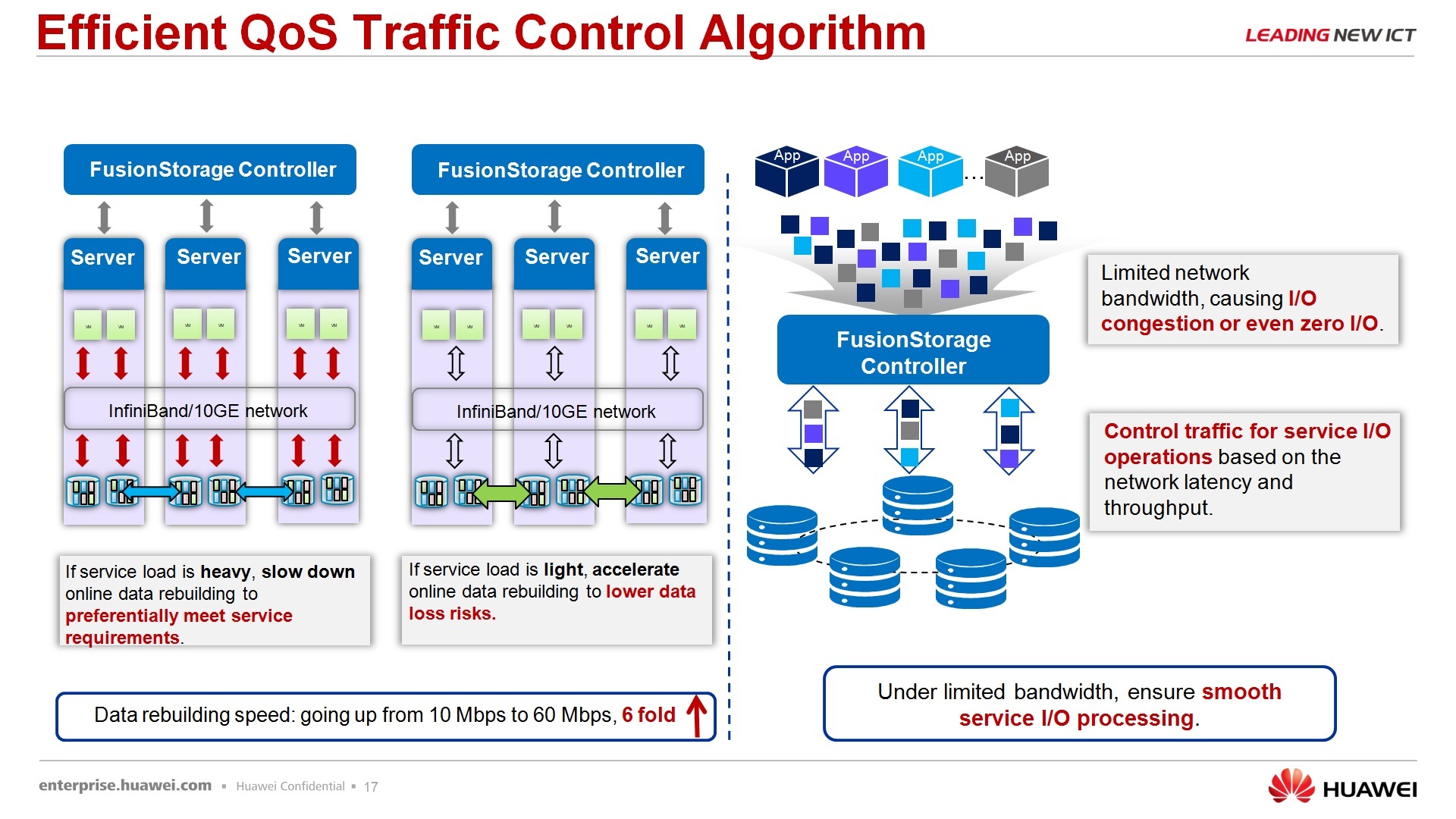
По поводу управления скоростью, тоже уязвимое место для данных систем, но в наших системах встроен, скажем так, вальюти оф сервис интеллектуальный, который, в зависимости от того, какая задача используется, находится ли система в процессе ребилдинга или она в состоянии стабильной работы находится, меняет приоритеты для второстепенных или первоочередных задач.
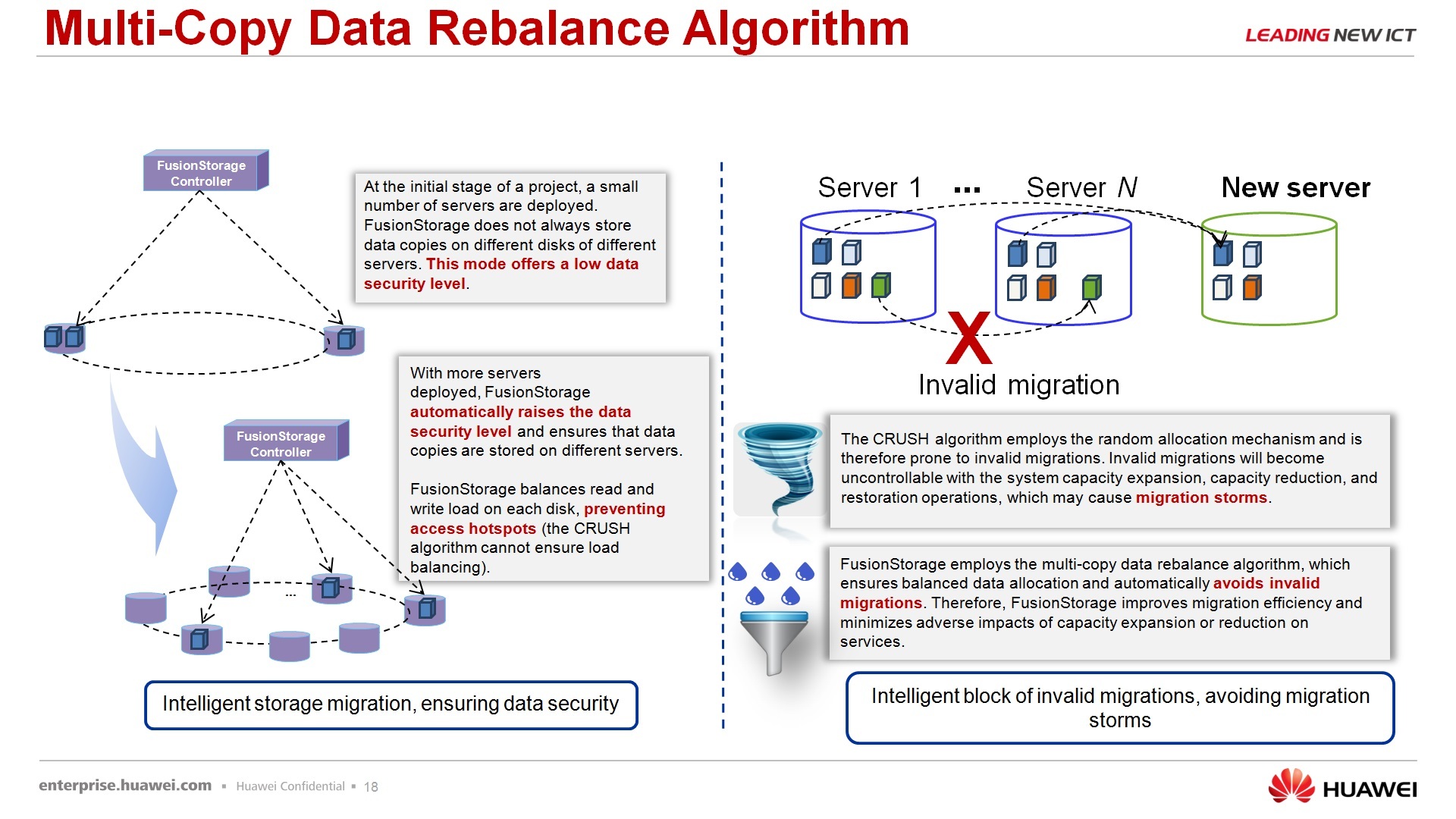
Про алгоритм ребалансировки — казалось бы, очевидная вещь, но почему-то мне часто задают вопрос: «а если вот у нас было 10 узлов в системе хранения, мы добавили еще 20 узлов, перераспределение это для повышения производительности будет происходить?» Да, повышение перераспределения данных по узам происходить будет, собственно, ради этого все и затеялось. Есть отдельный механизм, который занимается этим вопросом.
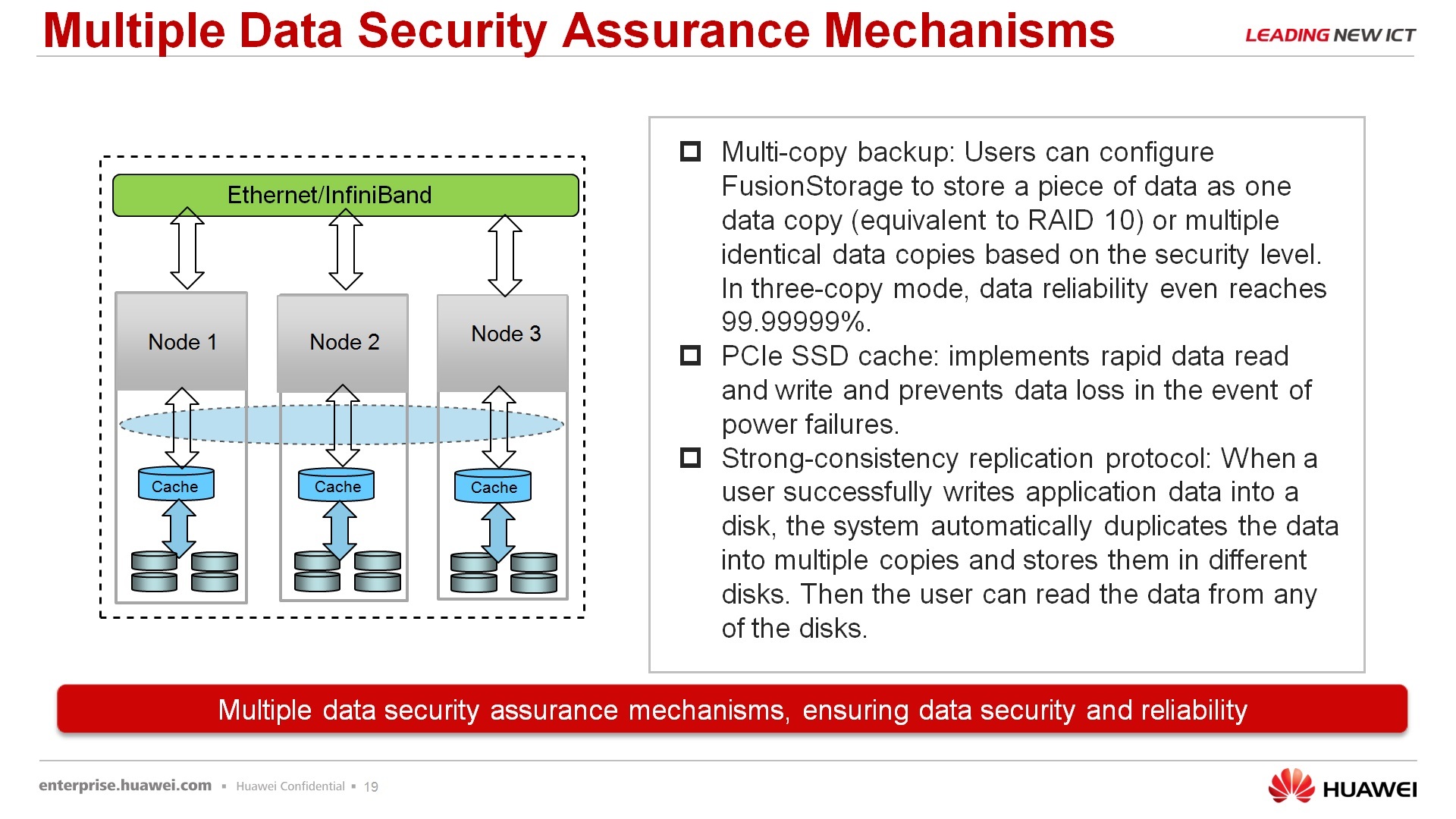
По поводу надежности, отказоустойчивости — у потребителя есть два варианта той защиты, которую он может получить – он может ограничиться двойным дублированием данных, когда есть основная копия данных и ее резервная, которая обязательно должна находиться на другом узле или в режиме повышенной надежности, когда хранится не одна копия, а еще две копии. Такая надежность в количестве девяток получает семь девяток, т.е. если заказчик готов пожертвовать объемом в два раза больше, чем занимает просто информация для повышения надежности, то он может этим воспользоваться. С учетом того, что в серверах используются более дешевые диски, чем в СХД, в принципе, зачастую такая затрата, скажем так, является оправданной. Использование PCI-ного SSD-кэша, в принципе, это не то чтобы наше ноу-хау, эти карты производят многие вендоры, но вот мы их используем, в том числе, для кэширования оптимизации работы нашей виртуальной СХД.
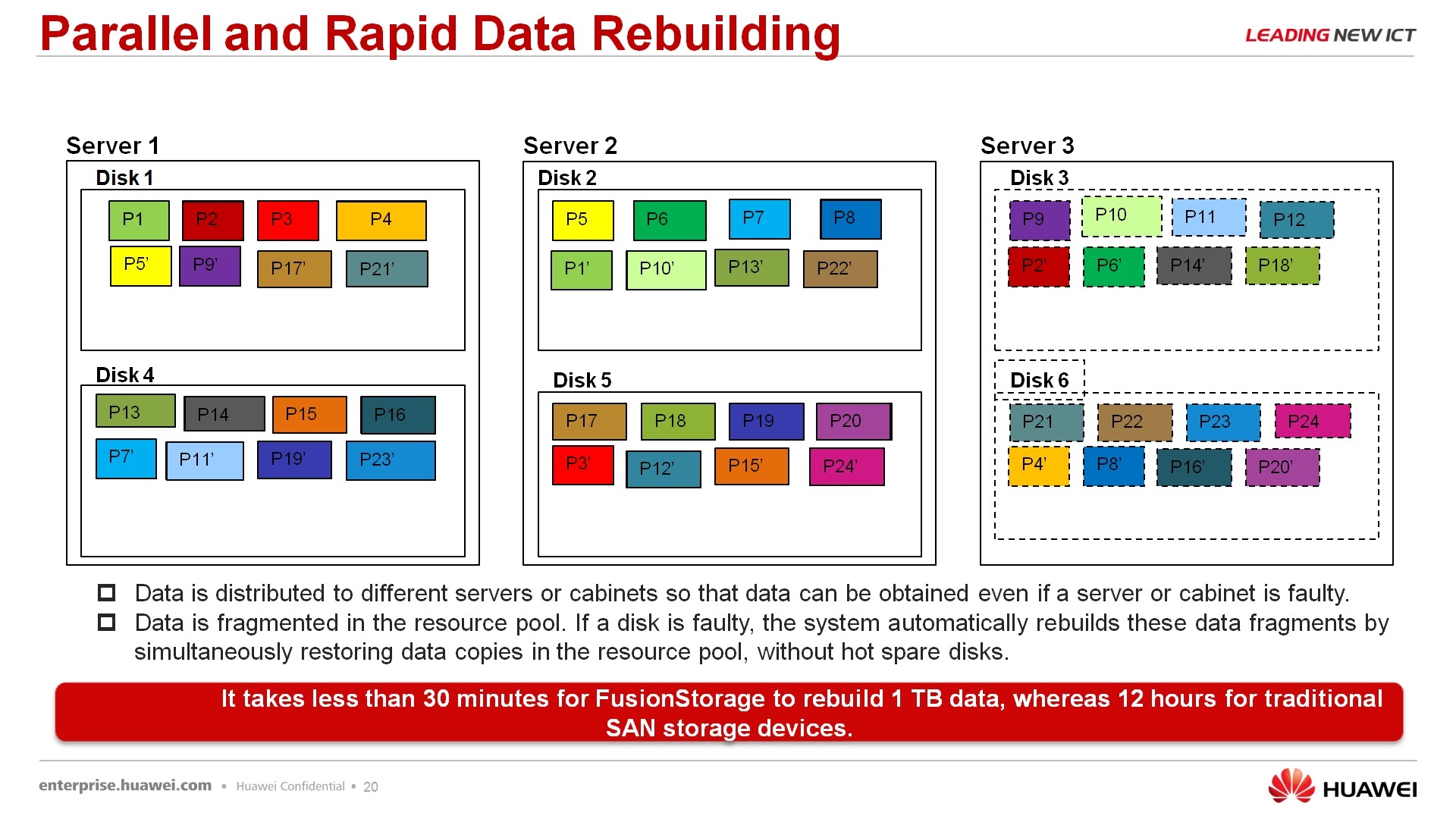
По поводу восстановления данных – за счет того, что отсутствует единый контроллер, через который происходит восстановление, за счет того, что данные все распределены между узлами, как правило, равномерно более менее, процесс ребилдинга в данных системах достаточно быстр, т.е. вам не нужно ждать, вот внизу приведены примеры, за 30 минут ребилдится один терабайт данных, т.е. если у вас рухнул сервак, на котором у вас лежало 4Тбайт данных, то система вернется в исходное устойчивое состояние меньше, чем за два часа. Если вспомнить классические СХД, то они могут неделями восстанавливаться после падения 4-терабайтных систем, 4-терабайтных дисков. Собственно, показывается, демонстрируется, как происходит ребилд. В принципе, ничего космического, непонятного, странного, все то же самое, просто идет это в несколько потоков, параллельно, поэтому этот процесс идет значительно быстрее.

Снэпшоты для данной системы есть, опять же, с учетом архитектуры, это меньше влияет на производительность, как в сравнении с классическими системами. По поводу интеграции с приложениями и прочим, в принципе, на данный момент, пока что открытый, т.е. консистентность снэпшота требует выяснения и не для всех пока приложений она доступна.

Существование ресурсных пулов – мы заказчика не заставляем все узлы объединить в единый пул, и всю его политику по безопасности, политику по хранению, по доступности определять сразу на весь пул. Вы можете ваш большой пул разделить на кусочки и в каждом кусочке будет своя политика безопасности, политика отказа устойчивости, политика репликации, политика по снэпшотам и так далее, и так далее. Ну я не знаю, при сетевых технологиях такие домены коллизий, т.е. что происходит в этом сегменте, меня не волнует, поскольку вот я автономен по отношению к другим сегментам.
В принципе, по софтверной СХД на этом все. Почему она стоит как бы особняком. Дальше буду рассказывать про FusionSphere, она там тоже есть, но, в принципе, там еще раз я рассказывать про нее не буду. Вот Fusion Storage можно приобретать отдельно без нашей виртуализации, это отдельный продукт, маркетинговый, со своим ценником, который можно поставить, в принципе, на любой сервер, любого вендора. Он не жестко привязан к нашему железу, вы можете имеющиеся у вас сервера, если они удовлетворяют требованиям, в общем-то, использовать под вот эту вот систему.

По поводу аппаратной части, из чего же состоят наши FusionCube, что это такое: собственно, 9000-й состоит из нашего блейд-шасси, собственно вот сама корзина, вид спереди, можно поставить 16 половинчатых серверов, либо 8 4-процессорных серверов, либо серверов с системами хранения с жесткими дисками, не системами хранения данных еще раз, с обратной стороны – блоки питания, вентиляция, сетевой интерконнект и модули управления самим шасси, через которые происходит управление аппаратными узлами этого агрегата.

Так, по узлам – это не все узлы, которые у нас есть для наших блейдов, их список значительно шире, больше, есть специфические модели, компактные, когда в один слот вставляется два двух-процессорных сервера, скажем так, популярное решение для high performance компьютинга. Но вот самая типовая набивка именно для FusionCube – двух-процессорный сервер, 24 планки памяти, 2 процессора Xeon Е5, в принципе, поколение Е4, E3 доступно, сервер 222-й в правой части, он аналогичен вот этому серверу, просто у него есть пристежная корзина на 15 жестких дисков, это вот узел хранения, который будет использоваться в Fusion Storage. Здесь есть выделенный RAID контроллер аппаратный от LSI, но как правило, он используется в режиме рейда первого, нулевого, когда все диски доступны индивидуально. Скажу сейчас, что в следующем месяце появляется новый узел, в котором, правда, не 15 дисков, а 12 дисков, и они уже подключены по протоколу NVМe, т.е. они через PCI-express подключаются с минимальными задержками, латентностями и так далее. Есть еще 226-й узел под 3-дюймовые диски, т.е. если нужен узел для медленного хранения 8-10 терабайтников, то он тоже есть для блейдов. 220-я модель –блейд сервера c 6-ю pci-ными слотами, внутрь можно поставить PCI-карточки обычные, причем, две из них можно выкинуть порты наружу, в них включить либо специфические карточки сетевые, которые пробрасывают трафик через себя в выключенном состоянии, либо NVIDIA Cuda поставить, как они там, Intel Fixion и прочие специфические вещи. Из особенностей, кстати, попрошу прощения, вернусь к 121-му узлу – туда можно поставить внутрь блейд-сервера одну PCI-экспрессную карту, обычную с лезвийным разъемом, т.е. не мезонинный, не какой-то проприетарного протокола, а обычного, обычный PCI-express, это может быть наша SSD-шная карточка, это может быть, я не знаю, ключи для 1С юсбишные, это может быть какая-то криптография кастовая, это может быть ограничение доступа к серверу и так далее, т.е. в обычный узел двух-процессорный можно смонтировать такую карту. Ну и, собственно, 242 узел – это 4-процессорник, 1 Тбайт оперативной памяти, 4 процессора Xeon Е7.
Сетевая коммутация, которая используется в FusionCube. 310-й – это 10-гигабитный коммутатор, CX611 – это InfiniBand коммутатор. В принципе, у нас сейчас доступны 40-гигабитные коммутаторы уже как год, даже больше, уже второй год, как доступны для блейдов 40Гбит и в сентябре будет доступен 100Гбит InfiniBand, т.е. если вы боитесь, что упретесь в производительность сетевого интерконнекта, можете не бояться, еще очень нескоро в него упретесь.
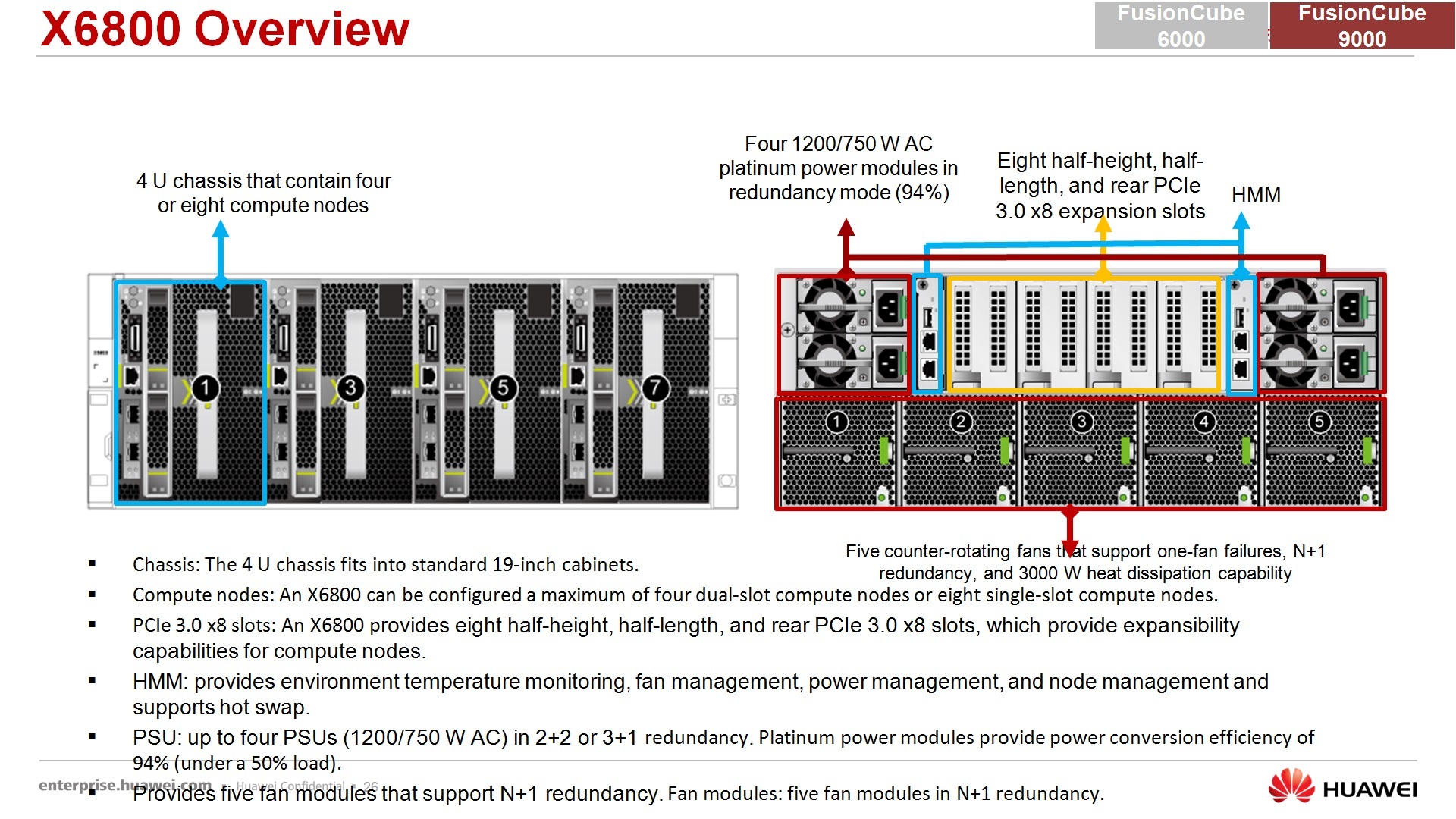
Младшее решение FusionCube 6000, здесь, кстати, ошибка, ну не ошибка, а цветом подсветили неправильно, 6000-я – 4-юнитное шасси, в которое можно поставить до 8 процессорных серверов. Здесь изображено 4 узла, покажу, что дальше за узлы… Сетевой интерконнект доступен с лицевой части, сзади 4 блока питания общие, которые питают всю конструкцию, и система охлаждения, которая также охлаждает всю конструкцию. Сзади есть pci-слоты, которые проброшены прям по каждому серверу в эти сектора.

Про сервер – сервер, опять же, есть в достаточном ассортименте, есть сервера с жесткими дисками, подключаемые по sas-протоколу, есть по pnvme-протоколу, есть, вот здесь изображено, два процессора и 12 трех-дюймовых жестких диска, а внутри салазок трех-дюймовых могут стоять двух-дюймовые жесткие диски. Есть вариант с подключением по sas, есть вариант по NVМe, есть вариант с PCI-express, т.е. стоят pci-экспрессные разъемы, туда можно поставить либо видеокарты NVIDIA Cuda и прочее, либо, допустим, наши PCI-экспрессные карты.
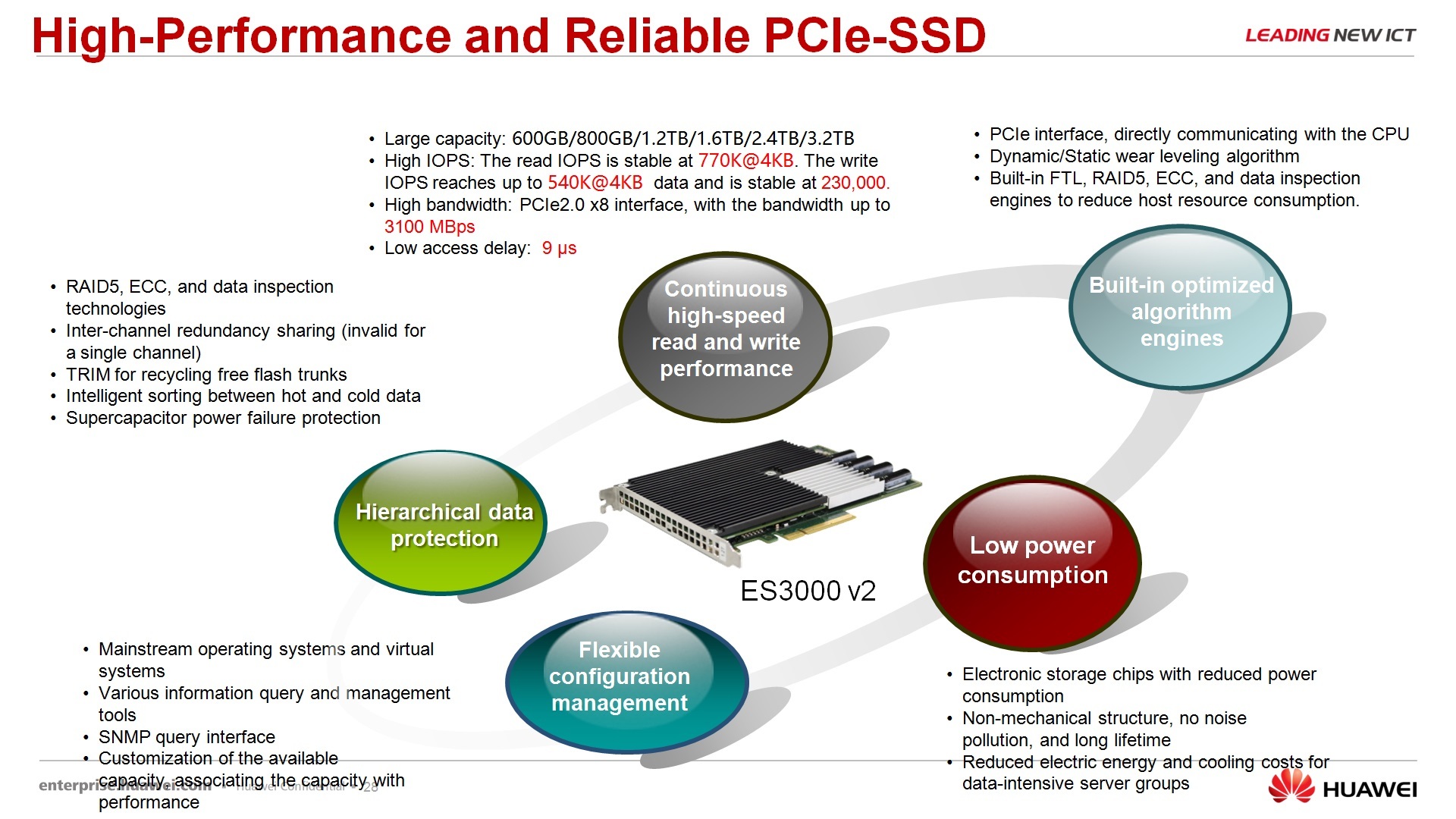
Ну и, собственно, наши PCI-экспрессные карты – внезапно, скажем так, историческая справка: компания HUAWEI является той компанией, которая первая выпустила вот эти вот карты вообще в мире, т.е. они существуют сейчас у многих вендоров, в широком ассортименте, какие-то карты лучше наших, скажем так, больше нравятся заказчикам, какие-то карты мы считаем, что лучше, чем другие, но тем не менее, вот этим вот вопросом, создание PCI-экспрессных SSD-карт HUAWEI начал заниматься достаточно давно и выпустил в промышленную эксплуатацию эти карты одними из первых. Это SSD накопитель, который втыкается в PCI-ный разъем, за счет отсутствия этих sas-протоколов, за счет отсутствия sas-овских RAID контроллеров и пр. его латентность 9 микросекунд, не миллисекунд, а микросекунд, то что, в общем-то, на 1000 порядков меньше, чем параметры классических СХД или классических жестких дисков. Параметры по производительности по IOPS-ам, собственно видите, 770 в пике и до 230 в стабильном режиме. В общем-то инсталляция этих карточек внутрь узлов хранения позволяет нам не беспокоиться о производительность нашей софтверной СХД. Несмотря на то, что там могут использоваться обычные SAS-диски, SATA-шные диски, при наличии вот этих вот карточек, за счет кэширования данных на них, производительность достаточно велика.
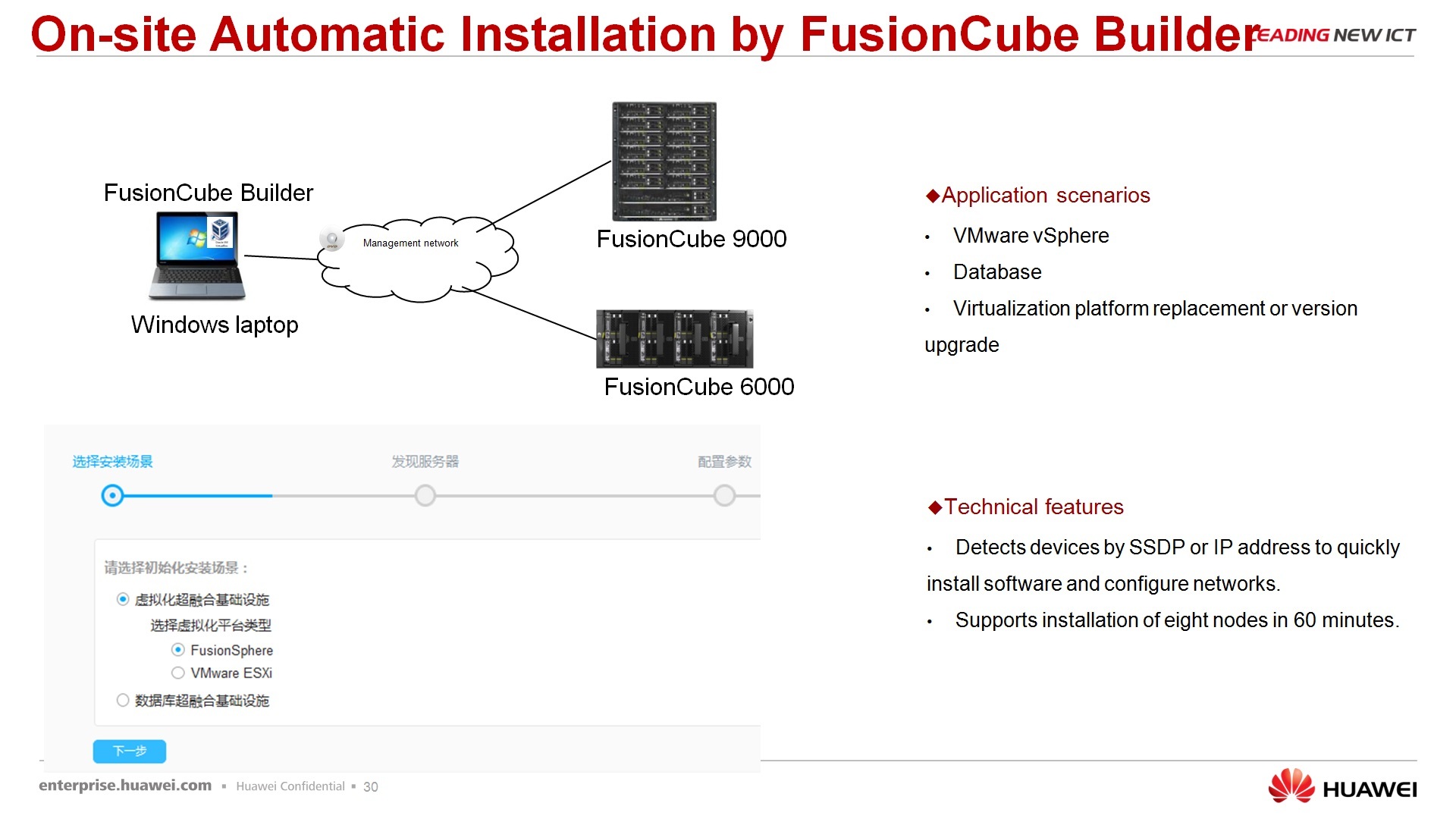
По поводу управления – в принципе, я уже коротко сказал, есть FusionCube Builder, ставите на лэптоп, подключаете FusionCube, делаете next, next, next, к сожалению, слайд на китайском языке. Сразу скажу, это доступно для ограниченного набора ПО, т.е. вы не можете там…визарда для создания лотус нотуса нет, или для 1С, к сожалению, нет пока. Есть для ландшафта FusionSphere или для ландшафта Vmware ESXi. Делаете next, next, next, за один час разворачиваете до 8 узлов, собственно, готовых, сконфигурированных.
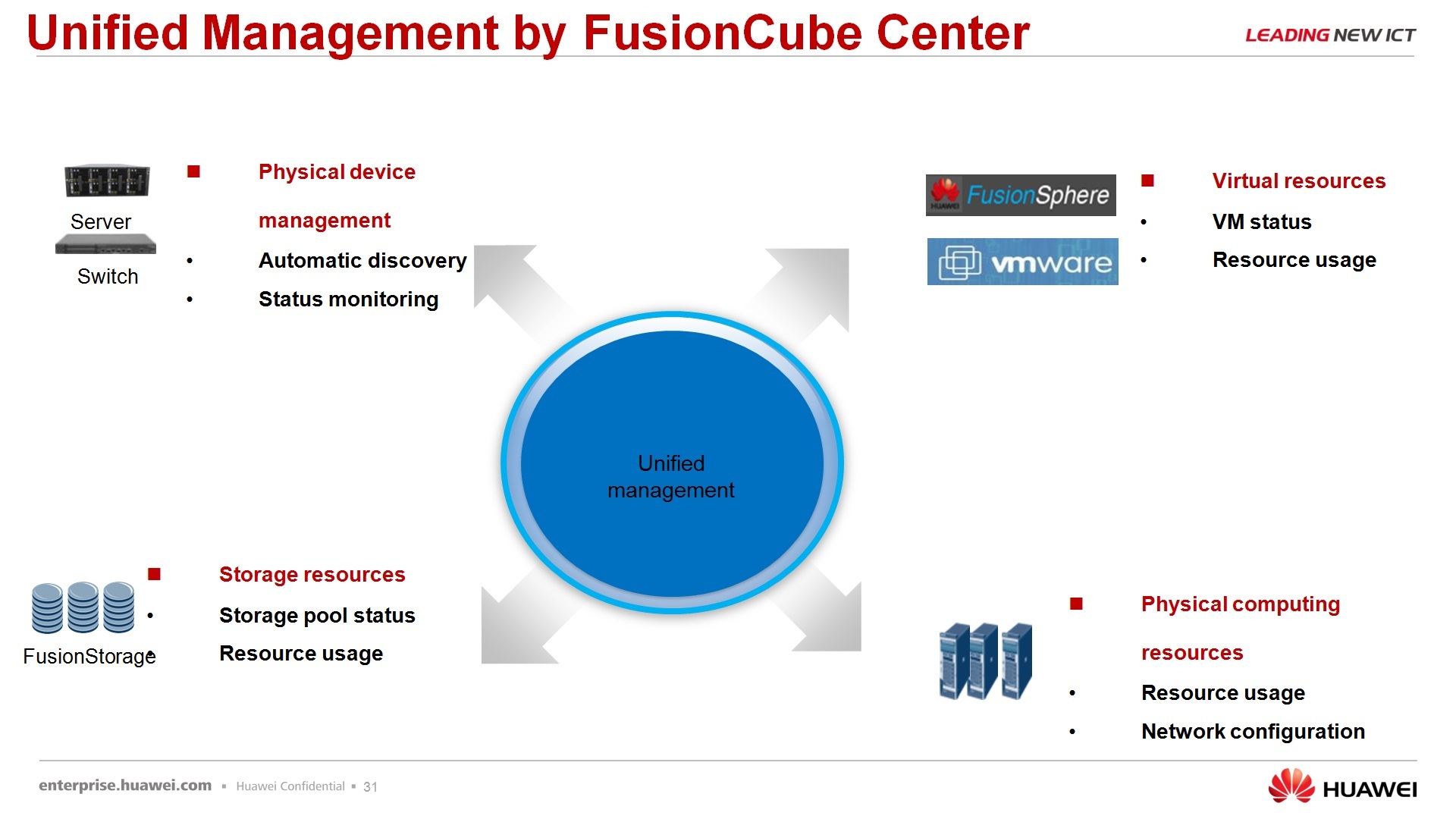
Затем мониторинг. Мониторите сразу через единое окошко физические сервера, физические сетевые компоненты, Fusion Storage, хотел сказать физическую хранилку, но не физическую, а виртуальную и пулы ресурсов виртуальных машин, либо на данный момент доступна FusionSphere и VmWare продукт.
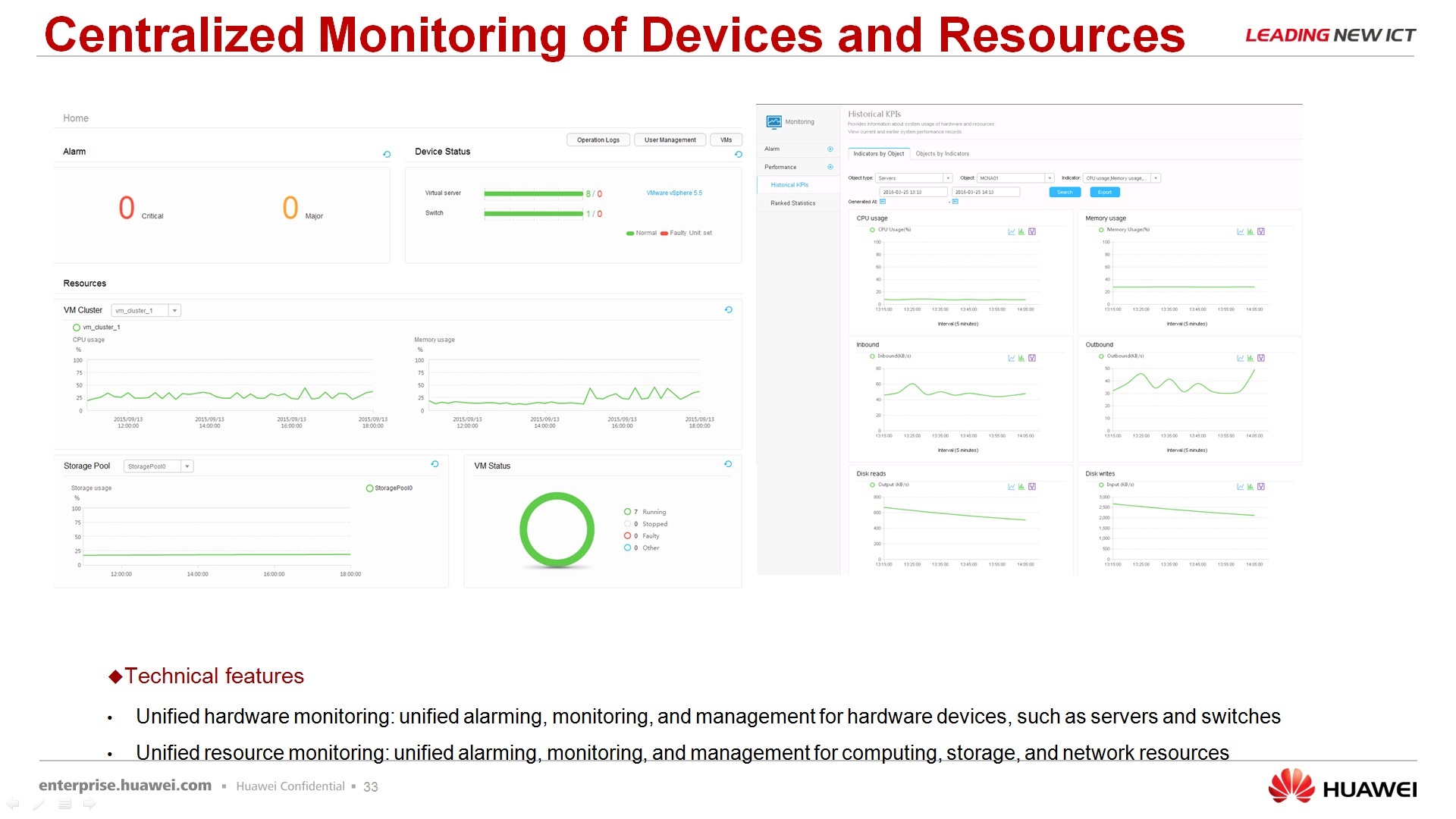
Как выглядит интерфейс – он, на самом деле, на английском языке, пугаться не надо, есть там, конечно, режим переключения, какой язык использовать. Русского языка, сразу говорю, нет. Есть английский, достаточно понятный, достаточно прозрачный, мониторинг выглядит вот следующим образом, никаких там страшных иероглифов больше не попадается, ну и единое логирование данных, что происходит с системой также доступно через этот интерфейс.
Повожу небольшое резюме: FusionCube это аппаратное решение с виртуальной СХД, с software defined storage. Как вы будете использовать в дальнейшем FusionCube, в общем-то, зависит от ваших задач, которые вы собираетесь решать. Еще раз повторюсь, FusionCube это не равно виртуализация, да, это один из вариантов применения, но не обязательно 100%.
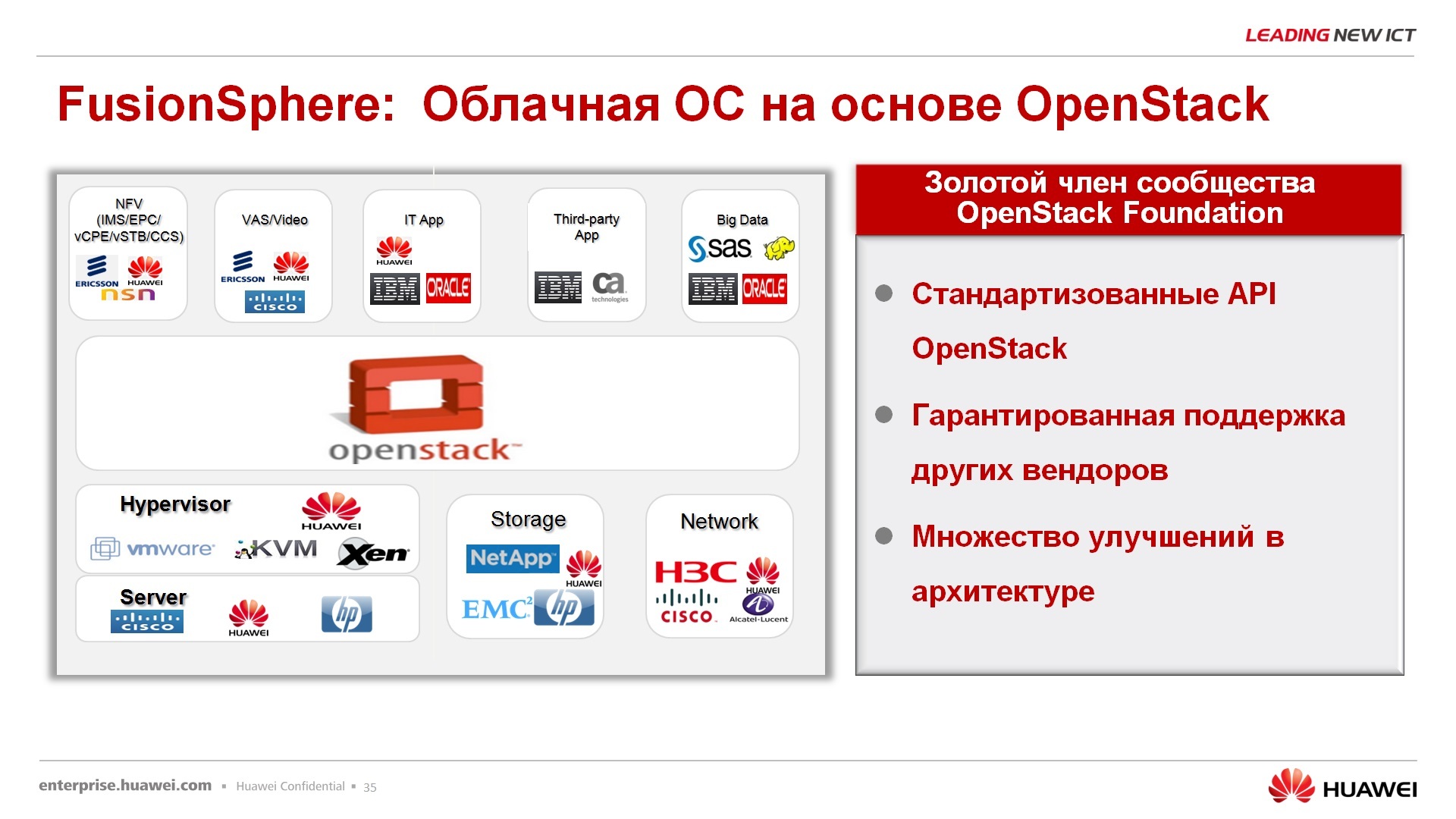
Перехожу к FusionSphere. FusionSphere – называется она у нас облачной операционной системой, развивается она в соответствии со стандартами, не знаю, как это сказать, OpenStack.

Компания HUAWEI участвует в данном мероприятии, вклад в OpenStack Community оценивается следующими параметрами: 23 новшества было привнесено компанией, 63 бага, вот красным цветом это показывает место, которое занимает HUAWEI по величине вклада, программного кода и т.д. В принципе, тут должна быть такая небольшая похвальба, что мы вот участвуем в OpenStack Community, у нас там статус золотой, в общем-то, мы с вами, из этой серии.
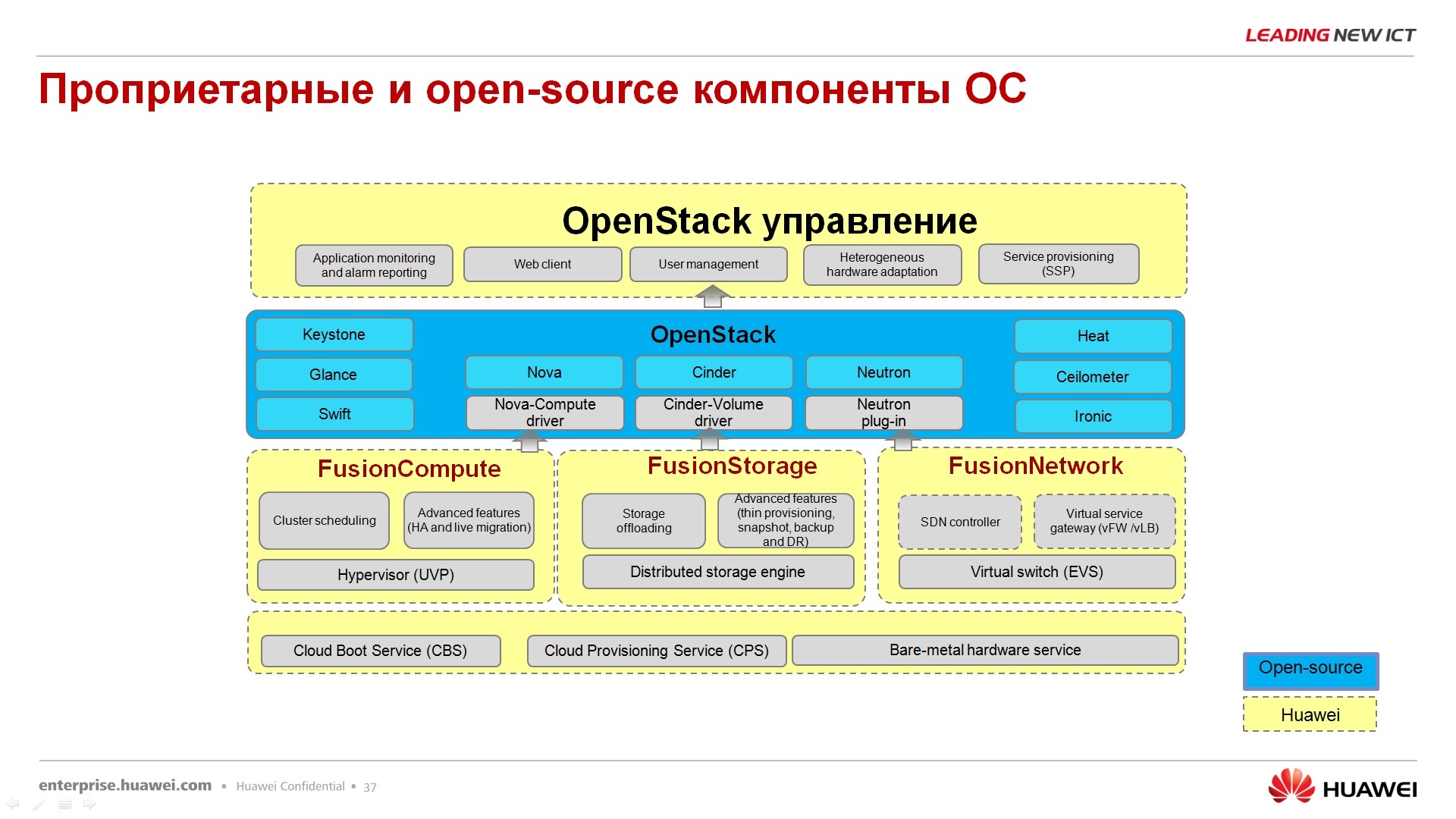
Все-таки из чего же состоит программный продукт, где заканчивается HUAWEI и начинается OpenStack. Собственно, вот про этого героя я вам уже все практически рассказал. FusionStorage является компонентом FusionSphere, но он может покупаться, приобретаться, использоваться отдельно.
Fusion Compute – это серверная виртуализация, это гипервизор и сервер, который управляет гипервизорами. У нас он называется Virtual Resource Manager или VRM сокращенно, это аналог VmWare-вского V-center. Вы через вот этот вот VRM управляете нашими гипервизорами, нашими виртуальными серверами (VPS) и так далее. И, в том числе, есть там закладка для FusionStorage.
Следующий компонент – FusionNetwork. На данный момент он представляет, пока что уверенно можно говорить только про одну инстанцию – это виртуальный свитч, распределенный между гипервизорами, остальные элементы SDN-контроллеры, они пока что таким пунктиром выделены, т.е. они пока что в разработке и для коммерческого использования не доступны. Ключевое слово «для коммерческого». Далее через плагины, через драйвера, это дело интегрируется с контроллерами OpenStack, который сверху управляется, опять же, через наш портал управления, который называется ManageOne, т.е. в комплекте с нашим решением есть еще и портал самообслуживание и административный портал, они на одном сервере крутятся, просто под разные задачи. Здесь можно определить, где заканчивается HUAWEI и начинает OpenStack. Да, за развитие собственных гипервизоров, за развитие СХД, за развитие сети, отвечает компания HUAWEI. За интеграцию с OpenStack отвечают все вместе.
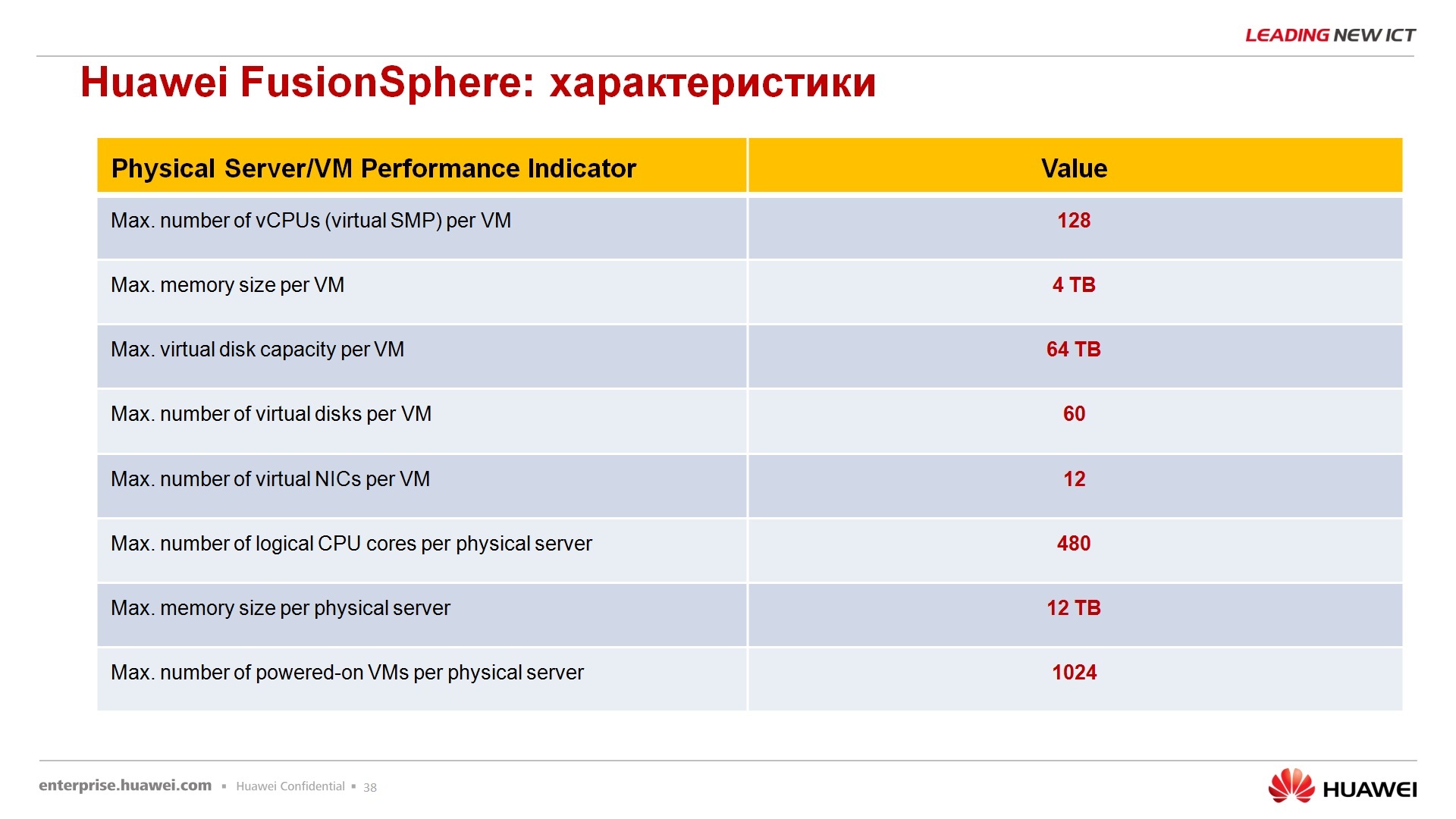
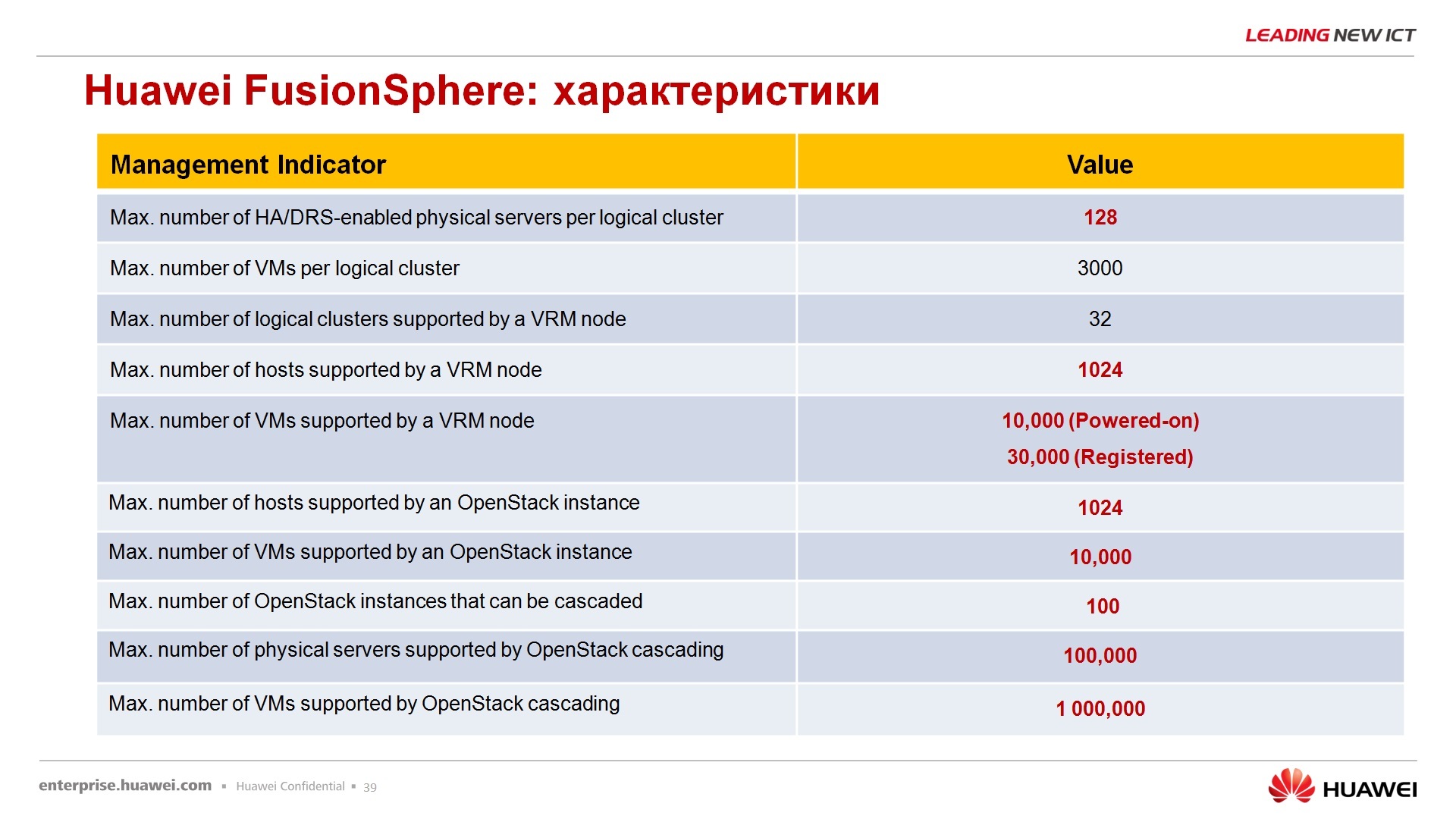
По поводу параметров FusionSphere, параметров виртуализации – хвалиться особо нечем, параметры на самом деле, такие же, как и у всех – 128 виртуальных процессоров на одну виртуальную машину, до 4 Тбайт оперативной памяти, 64 Тбайт максимальный размер жесткого диска, 60 дисков на одну виртуальную машину, 12 сетевых интерфейсов виртуальных на одну виртуалку, количество физических ядер на сервере до 480, оперативной памяти физической, на которой развернута Fusion сфера, до 12 Тбайт, одновременное количество включенных виртуальных машин 1000 на одном кластере. Эти параметры тоже озвучивать не буду, кому-то нравится, кому-то не нравится, в принципе, параметры средние по больнице, средние по отрасли, т.е. у Hyper-V или у ESXi Vmware примерно то же самое.
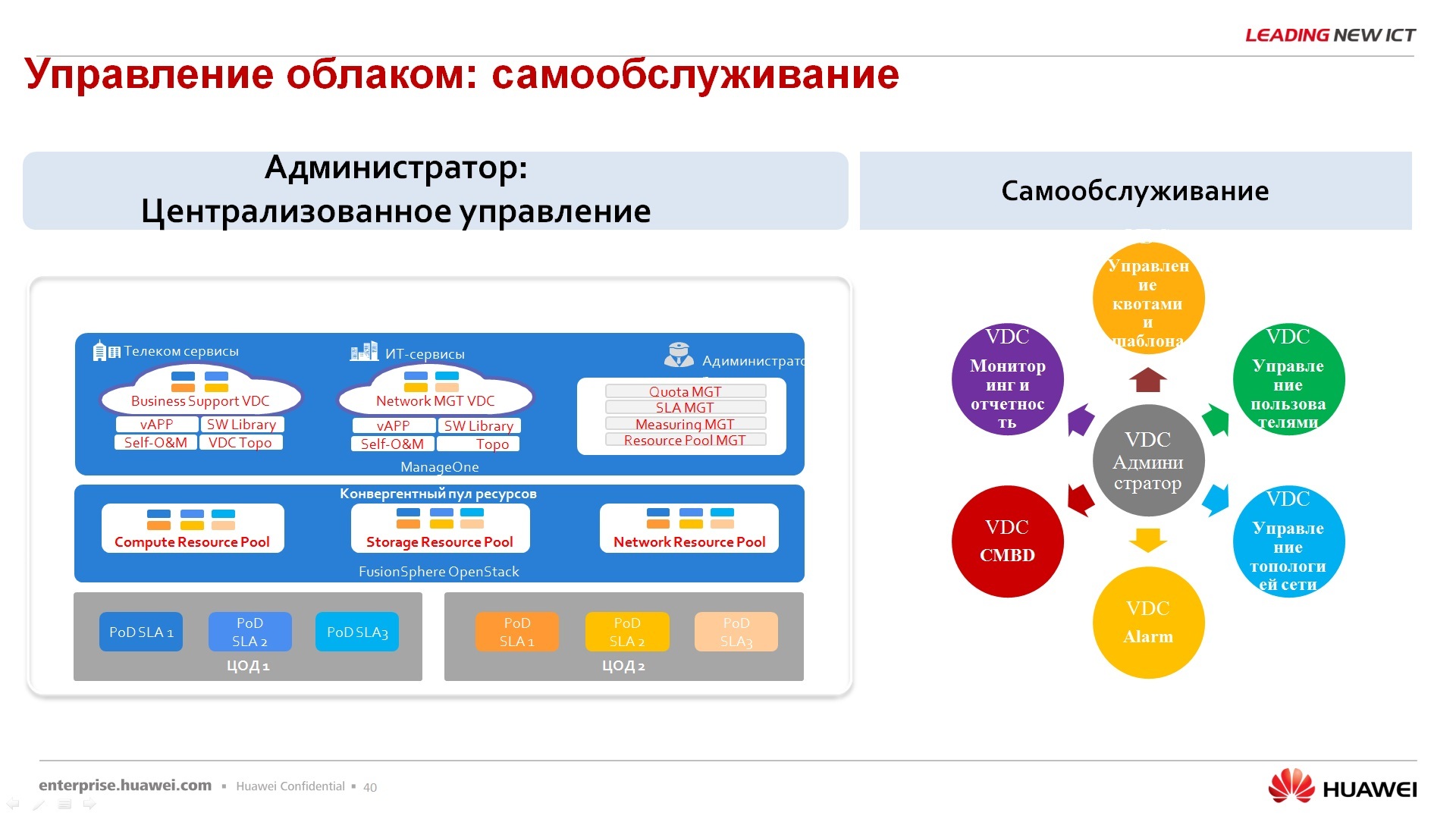
По поводу портала – портал, я сказал, что портал – это отдельное решение, называется ManageOne, ставится на отдельную виртуальную машину, физическую машину и через него происходит обслуживание, администрирование вот этого облачного решения.
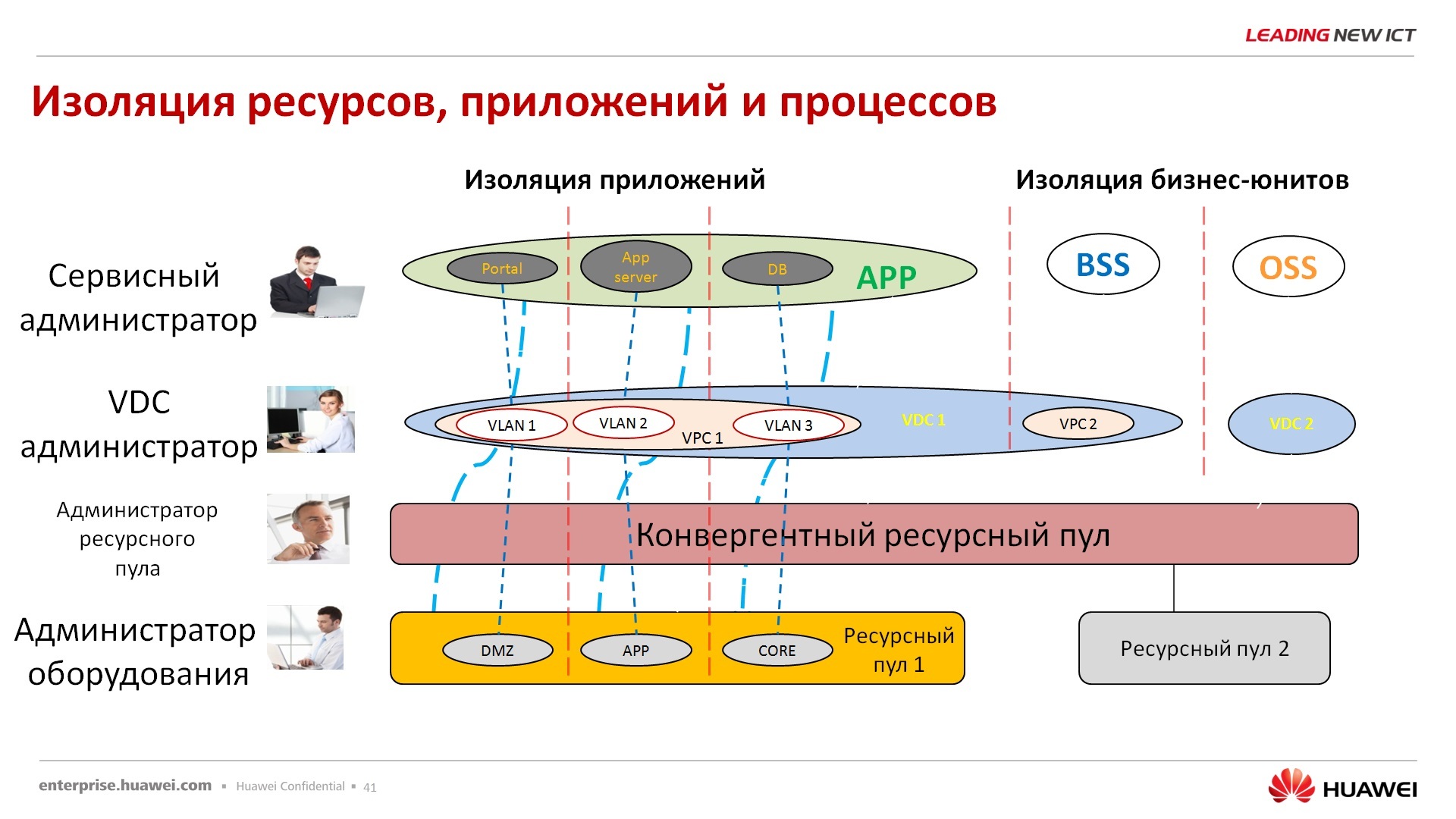
По поводу безопасности пользователей — для каждого пула ресурсов существует свой сисадмин, т.е. у нас нет единого супер-админа, супер-рута, который может настраивать сразу все, и физическое оборудование, и пулы ресурсов, и приложениями, и инфраструктурой виртуальной, нет, это 4 разные инстанции и они должны между собой согласовывать свои действия. В принципе, с вопросом безопасности сюда же отправляю вопрос по ФСТЭКу. В данный момент система находится в процессе обследования, соответственно одобрения, сертификат в ФСТЭК будет получен где-то в сентябре-октябре на данный продукт. Данный продукт на данный момент сертификацией не обладает.

По поводу катастрофоустойчивости и отказоустойчивости – это решается силами самой платформы на базе. Значит, отказоустойчивость внутри ЦОД высокая доступность, full tolerance доступны, создание актив-активных дата-центров, актив-пассивных дата-центров, репликации, политики, прочее доступны и гео-распределенные, гео-удаленные ЦОДы тоже можно решать эти задачи на уровне данного приложения. В принципе, уже удаленные, распределенные географически ландшафты, наверное, лучше получаются, когда используется, в том числе, и наше оборудование сетевое, и системы хранения данных, где происходит аппликация данных не софтверным путем, а за счет аппаратных ресурсов систем хранения данных, например.
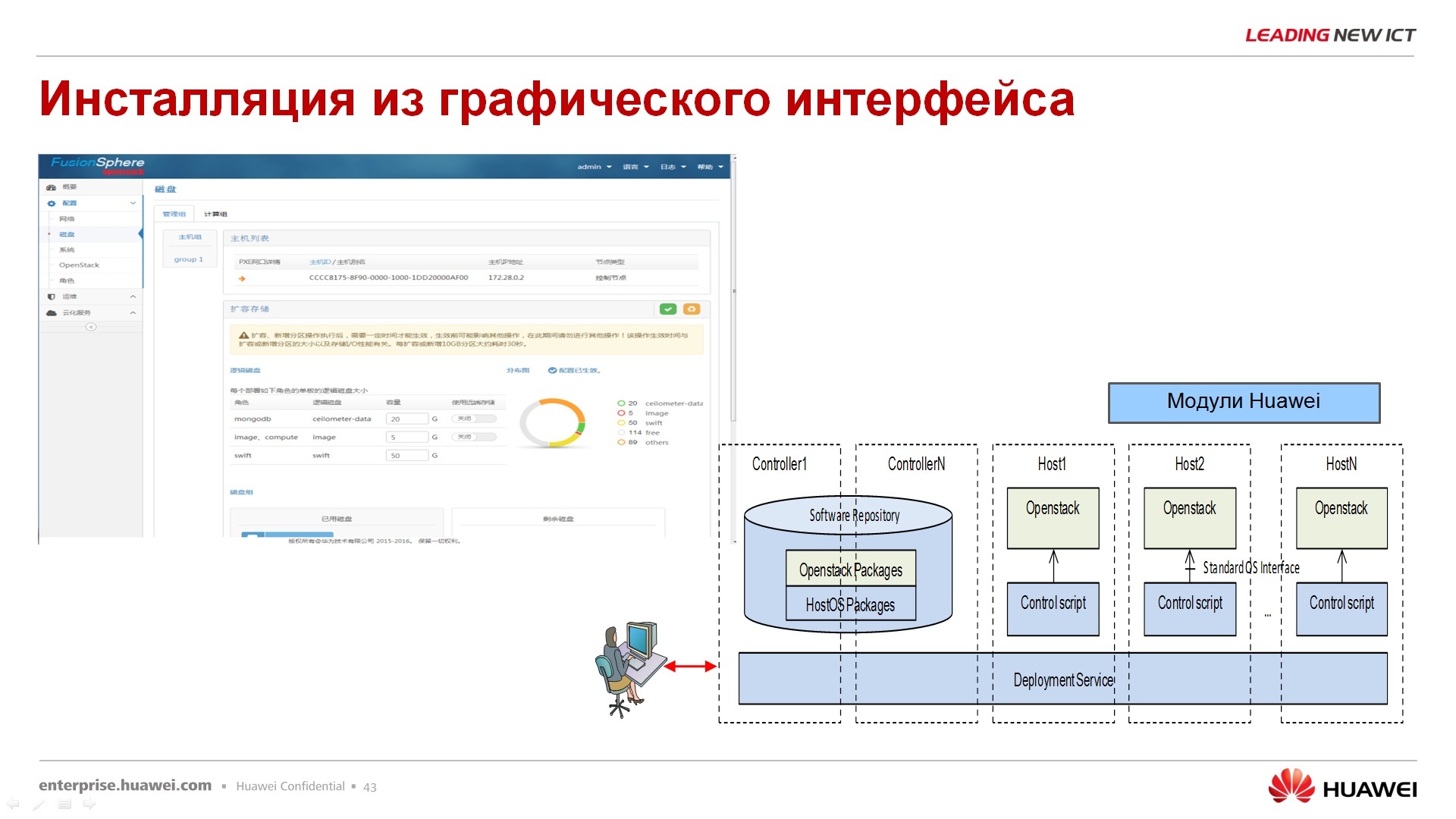
Из преимуществ – инсталляция с графического интерфейса, т.е. с командной строкой ковыряться не нужно, не знаю, насколько это является преимуществом для того или иного заказчика или партнера, но тем не менее инсталляция происходит из графического интерфейса.

Поддержка операционных систем гостевых – поддерживается достаточно широкий ассортимент, начиная с Windows-систем, заканчивая совершенно экзотическими внутри-китайскими, скажем так, линуксами, которые, в общем-то, никого не интересуют за пределами Поднебесной, но тем не менее, они также поддерживаются. Есть еще волшебный вот такой вот сегмент – кастом, т.е. если вам нужна интеграция с нашей Fusion сферой, вам нужны какие-то виртуальные драйвера, обращайтесь, если что наш R&D готов решить и эту задачу.
Про реализованные проекты. Про FusionSphere я закончил, совсем коротко получается, я по времени ограничен, перехожу про те моменты, которые уже реализованы на данный момент.
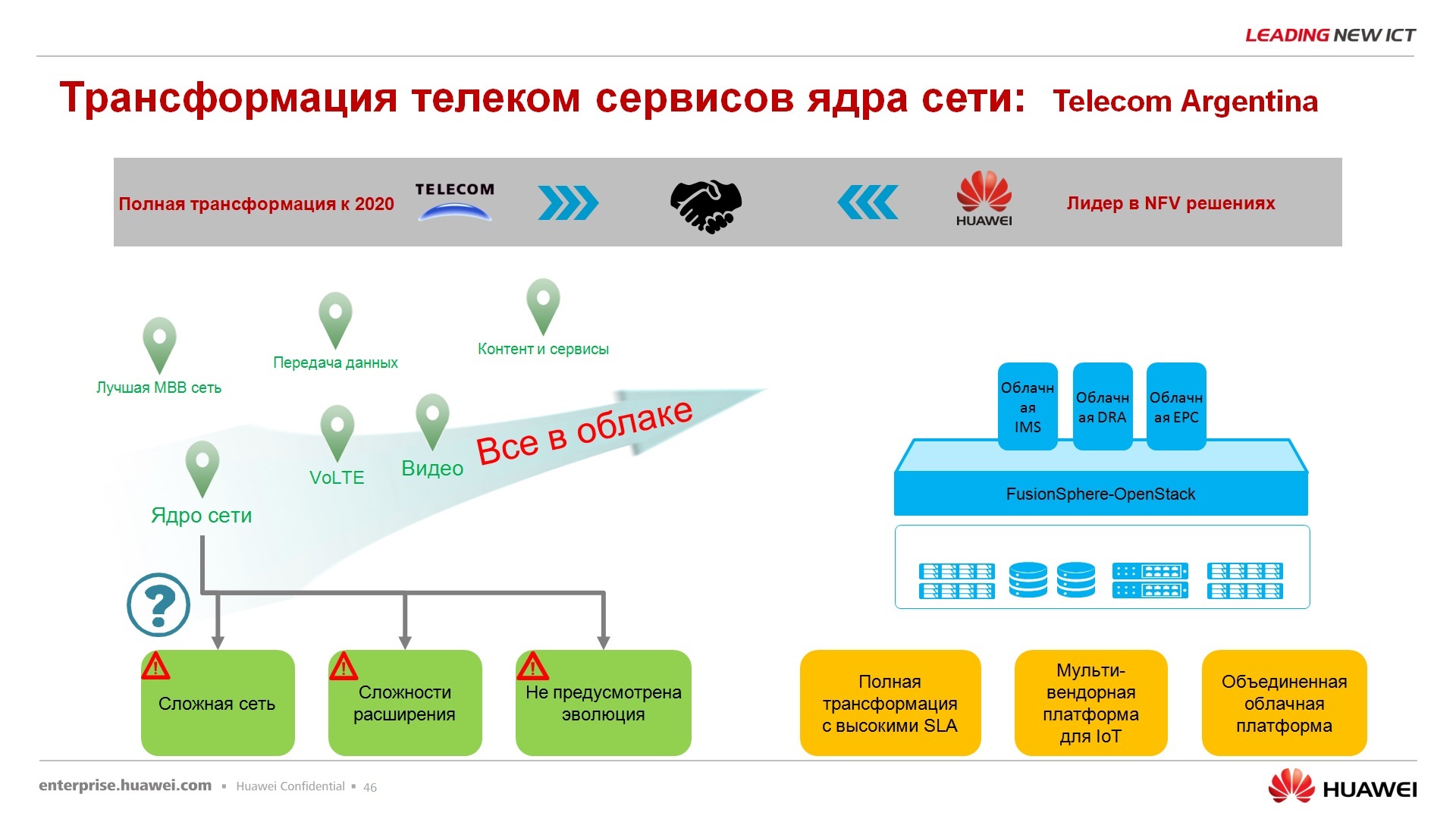
Наверное, первый облачный, ну не первый, наверное, начну с облаков. Аргентина Телеком понятно, что достаточно далеко от нас, другой континент, но все, если я назову ядро сети виртуализовано, то я не уверен, что правильно поймете, ядро сети сотового оператора полностью виртуализовано, т.е. это не сетевой коммутатор, который в дата-центре основным там считается, виртуализировано, а именно все сервисы, все услуги, которые передает и использует данный оператор, они выполняются теперь на виртуальной платформе и эта виртуальная платформа FusionSphere.
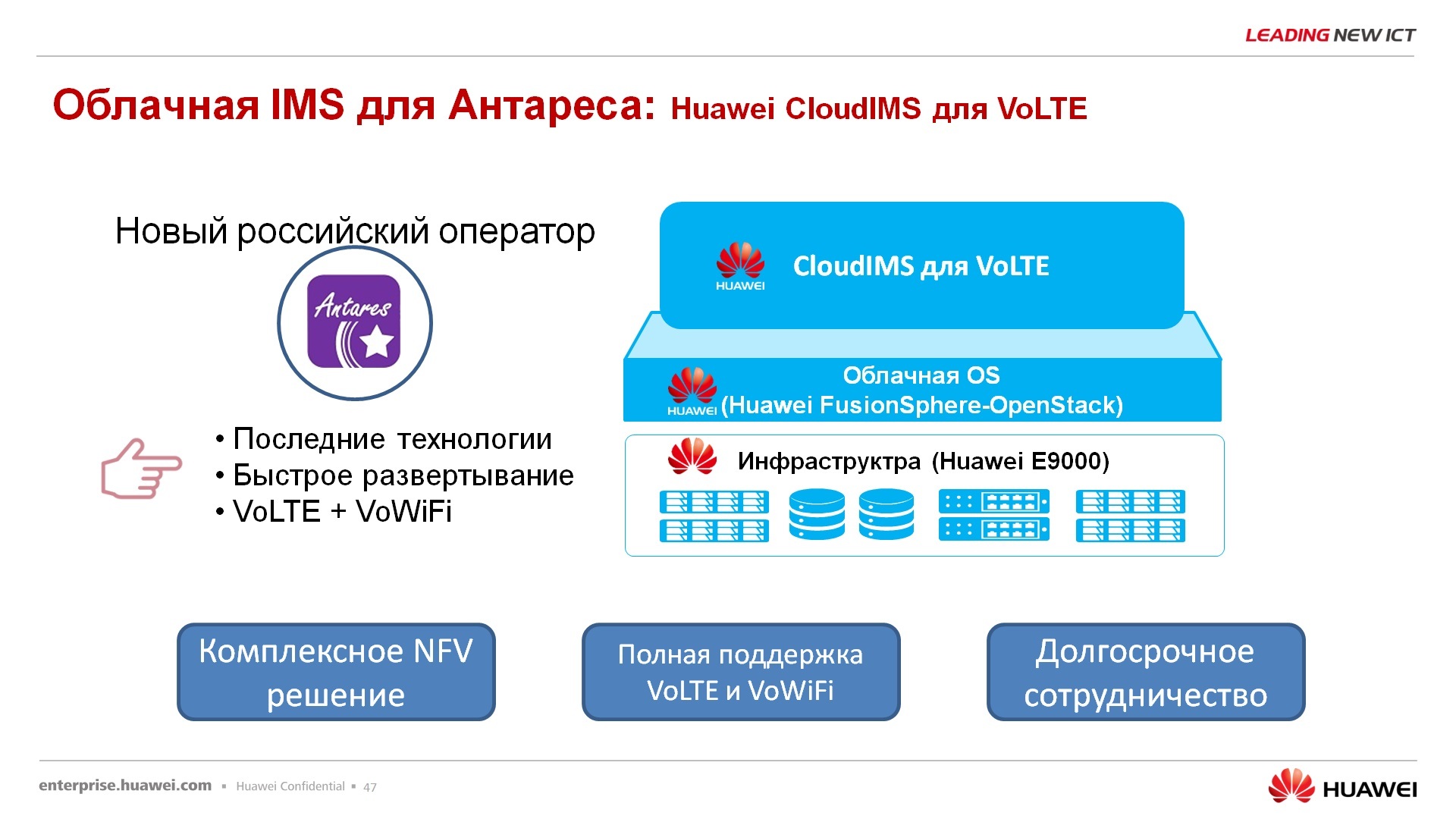
Отечественный заказчик – компания Антарес, специфический у него выбран сегмент бизнеса – это voice over lte, voice over wi-fi, то есть это сотовый оператор связи, но он пользуется либо lte, либо wi-fi для передачи голосового трафика, т.е. он не пользуется ни 2G, ни 3G сетями, как таковыми. Вот у них тоже ядро сети оператора сотовой связи полностью реализовано на нашем решении, в том числе на наших блейдах. В принципе, можно сказать, что это FusionCube с FusionSphere для реализации вот этих задач.
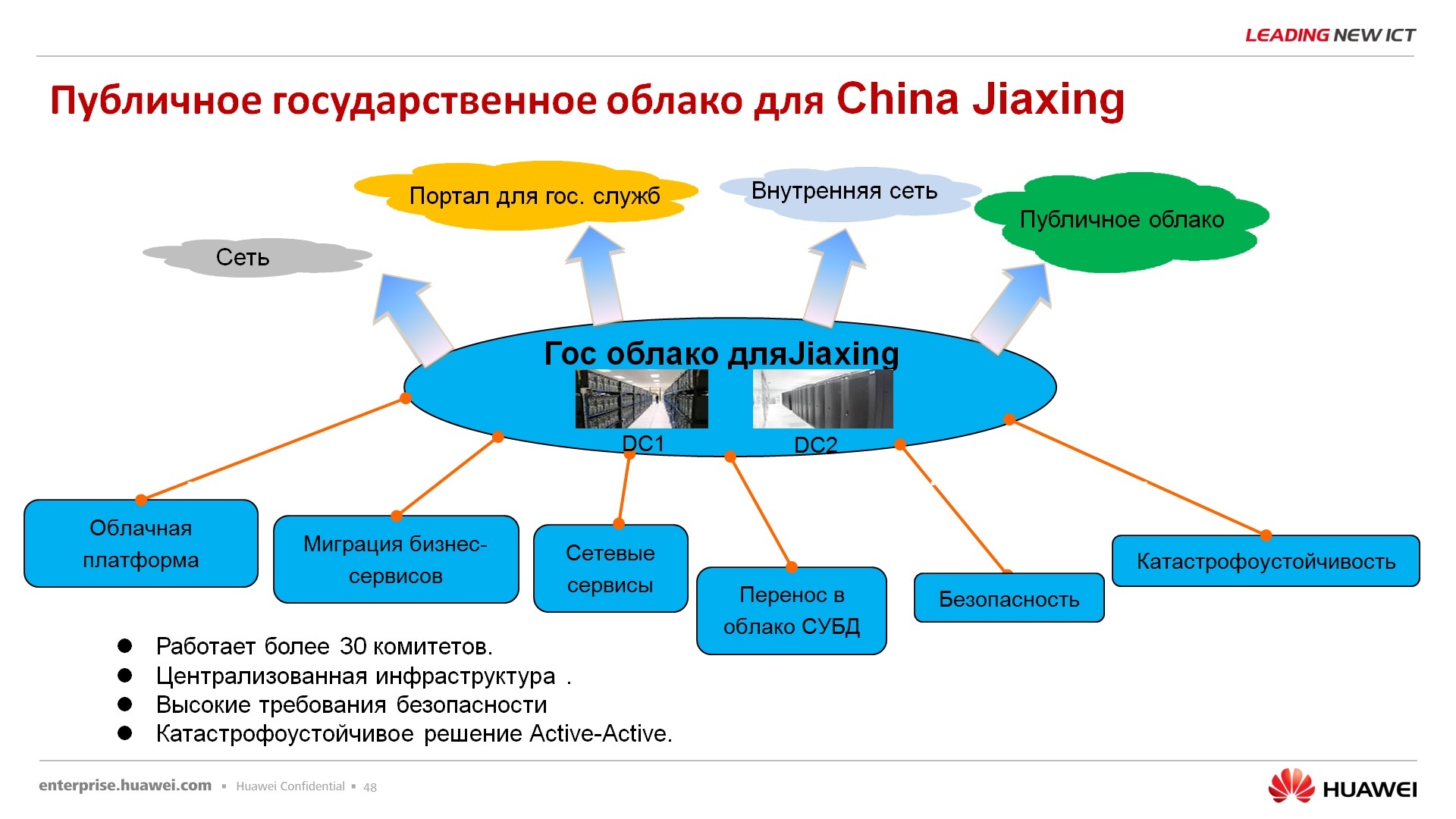
Следующий вариант – китайское публичное облако для использования самим государством. Ну не знаю, хвалиться этим, наверное, в наших широтах бессмысленно, но в целом, само китайское государство пользуется этой платформой OpenStack совместимой, разработанной HUAWEI, для своих государственных нужд, и не испытывает при этом никаких больших проблем.

Еще внезапные потребители вот этого ПО – сама компания HUAWEI. Зачастую бывает, что компании, которые производят тот или иной продукт, ими стараются не пользоваться. Здесь ситуация обратная, все наше R&D сидит на VDI, на виртуальных рабочих столах, все эти виртуальные рабочие столы развернуты в облаке, т.е. у сотрудников нет ни ноутбуков, ни лэптопов никаких, ничего нет, они сидят полностью на этой облачной инфраструктуре. Я не говорю про продавцов, я не говорю про менеджеров, я говорю про R&D, про инженеров, которые занимаются разработкой.

И, собственно, наверное, самый интересный проект – это Deutsche Telecom, T Systems. К вопросу об импортозамещении и хранении личных данных это забава не наших правителей российских, это международная забава вообще. В Германии в один прекрасный момент поняли, что большинство их компаний китайских пользуются ресурсами Amazon, кому принадлежит Amazon – вопрос достаточно темный, он точно не подвластен немецкому правительству, вопрос, кому же он принадлежит, Ирландии или США, в какой юрисдикции находится, остается в воздухе. Этот момент не устроил немецкое правительство, и был выбран отечественный немецкий оператор, прошу прощения, не оператор, а телеком-компания Deutsche Telecom для реализации отечественного облака, чтобы оно находилось на территории Германии, чтобы там хранились все данные, которые принадлежат компаниям, юрисдикция которых попадает под немецкое законодательство, и, собственно, это работало отказо-устойчиво, безотказно, 24/7, с гибкими сервисами, и вообще это был немецкий Amazon, в общем-то, в двух словах. И этот вопрос был успешно закрыт компанией HUAWEI в 2016 году на CeBIT была презентация этого решения, что оно теперь доступно.

В этом решении были вложены не только, решены вопросы софтверные какие-то, облака, безопасность, ресурсы и прочее, в том числе, выполнялась еще постройка нового дата-центра, модульного, на базе продукции компании HUAWEI, новый дата-центр создавался контейнерный на границе между Германией и Голландией, т.е. был такой совместный консорциум, не только Германия участвовала в этом мероприятии, и резервный ЦОД, на котором не хранятся данные, а хранятся вспомогательные вещи, находится в Ирландии. Вот этот вот единый пул из трех дата-центров был закрыт единым ПО FusionSphere.
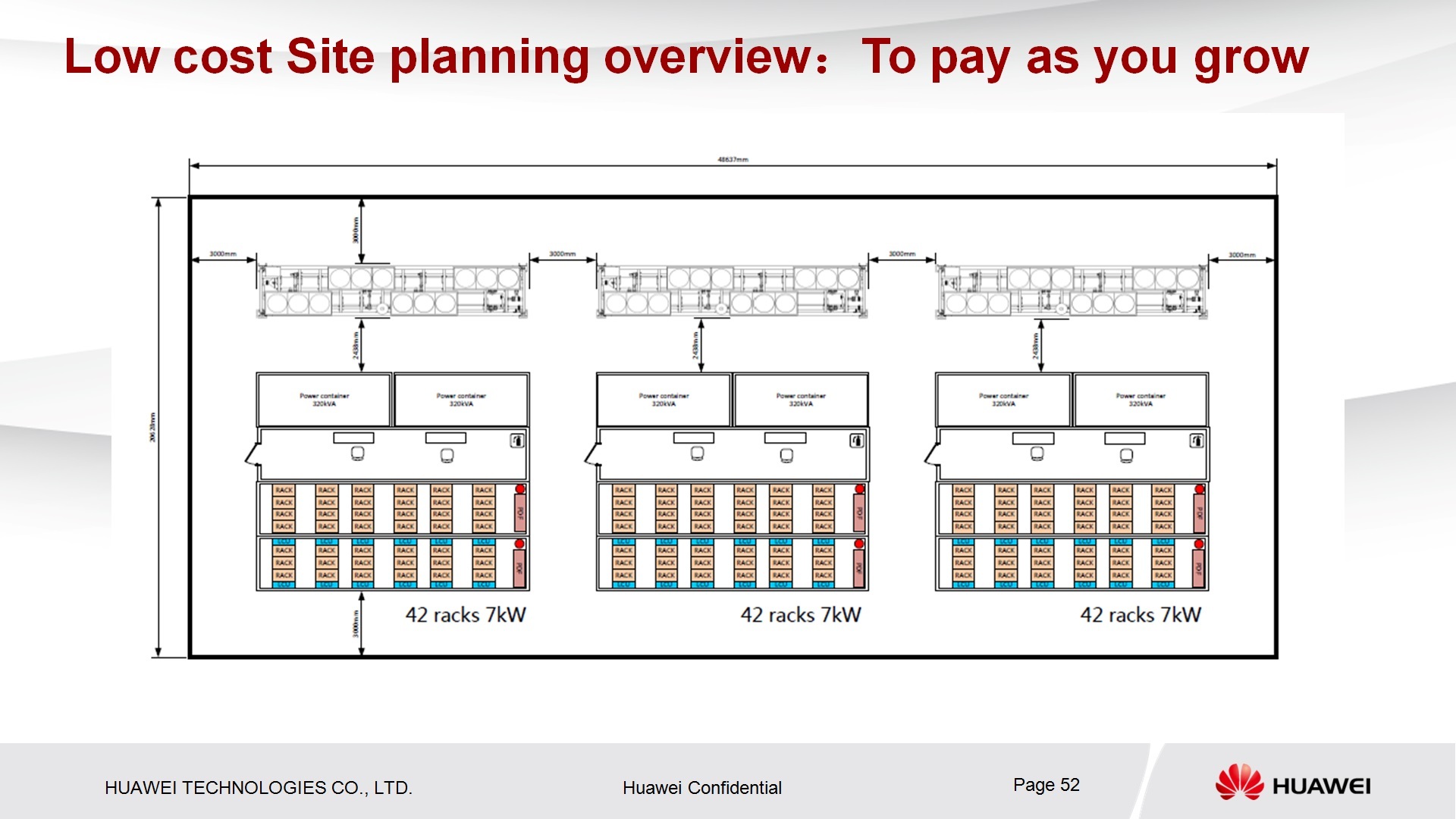
Вот как выглядит схема нового дата-центра контейнерного, вот это 4 контейнера, один из них обитаемый. Это контейнер под климатическое оборудование, чиллеры, это контейнер под ИБП, это контейнер под IT-оборудование. В принципе, видно, что его можно линейно масштабировать это решение до нужных вам объемов, т.е. это не конечное решение.

Ну и самое интересное, я думаю, и вам будет самое приятное, что облако уже публично доступно, вы можете в любой момент туда залогиниться вот по этой ссылке, создать бесплатно тестовую машину VDS и, в принципе, уже сейчас посмотреть, что такое FusionSphere, т.е. вам не нужно ее инсталлировать, вам не нужно где-то железо, ресурсы искать, вот Deutsche Telecom развернул FusionSphere на собственных аппаратных, интеллектуальных ресурсах. Понятно, что это был проект большой, и поддержка со стороны HUAWEI была значительной, тем не менее, это уже готовый ресурс, на котором вы можете потренироваться. Понятно, что может быть в продакшн запускать в соответствие с нашими законодательствами сразу не получится, но по крайней мере, технологические какие-то вопросы разрешить, этот ресурс вам поможет.


Поделиться с друзьями