
Введение
Издавна графические ускорители (ГПУ) были созданы для обработки изображения и видео. В какой то момент ГПУ стали использоваться для вычислений общего назначения. Но развитие центральных процессоров тоже не стояло на месте: компания Intel ведет активные разработки в сторону развития векторных расширений (AVX256, AVX512, AVX1024). В итоге, появляются разные процессоры — Core, Xeon, Xeon Phi. Обработку изображений можно отнести к такому классу алгоритмов, которые легко векторизуются.
Но как показывает практика, несмотря на довольно высокий уровень компиляторов и технологичность центральных процессоров и сопроцессоров Xeon Phi, сделать обработку изображения с использованием векторных инструкций не так просто, так как современные компиляторы плохо справляются с автоматической векторизацией, а использовать векторные intrinsic функции достаточно трудоемко. Также возникает вопрос о совмещении векторизованного вручную кода и скалярных участков.
В данной статье было разобрано, как можно использовать векторные расширения для оптимизации медианной фильтрации для центральных процессоров. Для чистоты эксперимента я взял все те же самые условия, что у автора: использовал алгоритм медианной фильтрации квадратом 3х3, данные картинки занимают 8 бит на пиксель, обработка рамки (в зависимости от размера квадрата фильтрации) не делается; и попробовал оптимизировать данное ядро на графическом процессоре. Также был рассмотрен алгоритм медианной фильтрации квадратов 5х5. Суть алгоритма в следующем:
- Для каждой точки исходного изображения берется некоторая окрестность (в нашем случае 3x3 / 5х5).
- Точки данной окрестности сортируются по возрастанию яркости.
- Средняя точка отсортированной окрестности записывается в итоговое изображение.
Первая реализация ядра на ГПУ
Для того, чтобы не заниматься "лишней" оптимизацией, воспользуемся некоторыми выкладками автора упомянутой статьи. И в итоге получится простой код вычислительного ядра:
__device__ __inline__ void Sort(int &a, int &b)
{
const int d = a - b;
const int m = ~(d >> 8);
b += d & m;
a -= d & m;
}
__global__ void mFilter(const int H, const int W, const unsigned char *in, unsigned char *out)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x + 1;
int idy = threadIdx.y + blockIdx.y * blockDim.y + 1;
int a[9] = {};
if (idy < H - 1 && idx < W - 1)
{
for (int z2 = 0; z2 < 3; ++z2)
for (int z1 = 0; z1 < 3; ++z1)
a[3 * z2 + z1] = in[(idy - 1 + z2) * W + idx - 1 + z1];
Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]);
Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[6], a[7]);
Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]);
Sort(a[0], a[3]); Sort(a[5], a[8]); Sort(a[4], a[7]);
Sort(a[3], a[6]); Sort(a[1], a[4]); Sort(a[2], a[5]);
Sort(a[4], a[7]); Sort(a[4], a[2]); Sort(a[6], a[4]);
Sort(a[4], a[2]);
out[idy * W + idx] = (unsigned char)a[4];
}
}Для каждой точки окрестность грузится согласно данной картинке (желтым выделен пиксель изображения, для которого требуется посчитать результат):
В данной реализации есть один минус — картинка хранится в 8 битном формате, а вычисления происходят в 32х битном. Если заглянуть в боевой код векторной реализации на ЦПУ, можно увидеть, что там применено много оптимизаций, в числе которых исключение лишних операций во время сортировки, так как в зависимости от компилятора, оптимизации могут не сработать. Компилятор Nvidia таких недостатков лишен — он с легкостью развернет два цикла по z2 и z1 даже если не будет указано #pragma unroll ( в данном случае компилятор будет принимать решение по разворачиванию цикла сам, и если регистров не хватает, то циклы не будут развернуты), а также будут исключены лишние операции функций Sort после их подстановки (указание inline носит рекомендательный характер, если необходимо подставить функцию вне зависимости от того, как решит компилятор, необходимо использовать forceinline).
Тестировать я буду на ГПУ Nvidia GTX 780 Ti примерно такого же года выпуска, что и центральный процессор в приведенной выше статье (Intel Core-i7 4770 3.4 GHz). Размер изображения — черно-белое 1920 х 1080 пикселей. Если запустить скомпилированную первую версию на ГПУ, то получим следующие времена:
| Время выполнения, ms | Относительно ускорение | ||||
|---|---|---|---|---|---|
| Скалярный ЦПУ | AVX2 ЦПУ | Version1 GPU | Скалярный / AVX2 | Скалярный / Version1 | AVX2 / Version1 |
| 24.814 | 0.424 | 0.372 | 58.5 | 66.7 | 1.13 |
Как видно из приведенных времен, просто "нативно" переписав код и запустив его на ГПУ, получаем неплохое ускорение, причем нет проблем с выравниванием по размеру картинки — код на ГПУ будет одинаково хорошо работать на любых размерах изображения (соответственно начиная с какого-то размера, когда ГПУ будет полностью загружен). Также не приходится думать о выравнивании памяти — все за нас сделает компилятор, достаточно выделить память с помощью специальных функций CUDA RunTime.
Многие, кто сталкивался с графическими ускорителями, сразу скажут, что необходимо загрузить данные и выгрузить их обратно. При скорости PCIe 3.0 в 15 ГБ/с для 2 МБ изображения получается порядка 130 микросекунд для передачи в одну сторону. Тем самым, если происходит потоковая обработка изображений, то загрузка + выгрузка будут занимать около 260 микросекунд, в то время как счет занимает около 372 микросекунды, что означает, что даже в самой "нативной" реализации передачи в ГПУ покрываются. Также можно сделать вывод, что быстрее, чем 260 микросекунд на одно изображение, обрабатывать поток картинок не получится. Но если этот фильтр применяется вместе с другим десятком фильтров во время обработки одной картинки, то дальнейшая оптимизация данного ядра становится полезной.
Вторая реализация ядра на ГПУ
Для того, чтобы повысить эффективность операций сортировки, можно воспользоваться недавно добавленными SIMD инструкциями. Данные инструкции представляют собой intrinsics функции, которые позволяют за одну операцию вычислить некоторую математическую функцию для двух unsigned / signed short или для 4х unsigned / signed char. Список доступных функций можно посмотреть в документации Cuda ToolKit. Нам нужны две функции: vminu4(unsigned a, usnigned b) и vmaxu4(unsigned a, unsigned b); вычисляющие минимум и максимум для 4х без знаковых 8ми битных значений. Для загрузки четырех значений, разделим все изображение на 4 части по горизонтали и каждый блок будет загружать данные из 4х полос, объединяя 4 загруженных точки с помощью побитового сдвига в unsigned int:
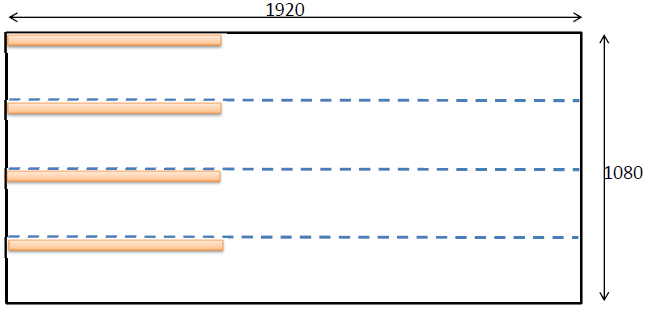
Активная зона обработки — самый верхний квадрат размером 1920 х 270. Соответственно, оранжевым показан блок из 128 х 1 нитей, которые загрузят 128 * 4 элемента. Как известно, размер варпа на ГПУ состоит из 32х нитей. Все нити одного варпа выполняют одну инструкцию за такт одновременно. Так как каждая нить загрузит к себе 4 элемента типа unsigned char, то один варп в общей сложности выполнит обработку 128 элементов за одну инструкцию, то есть получается некая 1024 битная обработка. Для ЦПУ на данный момент доступны 256 битные AVX2 регистры (которые в будущем превратятся в 512 и 1024 битные). С данными оптимизациями код вычислительного ядра преобразуется к следующему виду:
__device__ __inline__ void Sort(unsigned int &a, unsigned int &b)
{
unsigned t = a;
a = __vminu4(t, b);
b = __vmaxu4(t, b);
}
__global__ __launch_bounds__(256, 8)
void mFilter_3(const int H, const int W, const unsigned char * __restrict in, unsigned char *out, const unsigned stride_Y)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x + 1;
int idy = threadIdx.y + blockIdx.y * blockDim.y + 1;
unsigned a[9] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 };
if (idx < W - 1)
{
for (int z3 = 0; z3 < 4; ++z3)
{
if (idy < H - 1)
{
const int shift = 8 * (3 - z3);
for (int z2 = 0; z2 < 3; ++z2)
for (int z1 = 0; z1 < 3; ++z1)
a[3 * z2 + z1] |= in[(idy - 1 + z2) * W + idx - 1 + z1] << shift;
}
idy += stride_Y;
}
Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]);
Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[6], a[7]);
Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]);
Sort(a[0], a[3]); Sort(a[5], a[8]); Sort(a[4], a[7]);
Sort(a[3], a[6]); Sort(a[1], a[4]); Sort(a[2], a[5]);
Sort(a[4], a[7]); Sort(a[4], a[2]); Sort(a[6], a[4]);
Sort(a[4], a[2]);
idy = threadIdx.y + blockIdx.y * blockDim.y + 1;
for (int z = 0; z < 4; ++z)
{
if (idy < H - 1)
out[idy * W + idx] = (unsigned char)((a[4] >> (8 * (3 - z))) & 255);
idy += stride_Y;
}
}
}В результате небольших изменений, мы увеличили количество обрабатываемых элементов до 4х (или 128 элементов за инструкцию). Сложность кода возросла и компилятор генерирует слишком много регистров, что не позволяет загрузить ГПУ на 100%. Так как у нас все-таки простые вычисления, мы скажем компилятору, что хотим запустить максимально возможное количество нитей на каждом потоковом процессоре (максимум для данного ГПУ — 2048 нитей) с помощью __launch_bounds (128, 16), что говорит о том, что будет запущена конфигурация из 16 блоков по 128 нитей в каждой. И еще одно нововведение — добавим ключевое слово restrict для использования текстурного кэша для загрузки повторяющихся данных (если провести анализ, то их достаточно много, большинство точек считывается по 3 раза). Чтобы текстурный кэш был задействован, необходимо также указание const. Все вместе указание будет выглядеть так:
const unsigned char * __restrict in.Соответствующие времена второй версии:
| Время выполнения, ms | Относительно ускорение | ||||||
|---|---|---|---|---|---|---|---|
| Скалярный ЦПУ | AVX2 ЦПУ | Version1 GPU | Version2 GPU | Скалярный / AVX2 | Скалярный / Version2 | AVX2 / Version2 | Version1 / Version2 |
| 24.814 | 0.424 | 0.372 | 0.207 | 58.5 | 119.8 | 2.04 | 1.79 |
Третья реализация ядра на ГПУ
Уже получили не плохое ускорение. Но можно заметить, что загружая 4 элемента с таким расстоянием, происходит слишком много повторных загрузок. Это значительно снижает быстродействие. Можно ли каким то образом использовать то, что мы уже загрузили непосредственно на регистры и улучшить локальность данных? Да, можно! Пусть эти 4 линии теперь располагаются близко друг к другу, а начала блоков будут "размазаны" по всей высоте с расстоянием 4. Таким образом, учитывая размер блока нитей по Y, приходим к следующему коду:
#define BL_X 128
#define BL_Y 1
__device__ __inline__ void Sort(unsigned int &a, unsigned int &b)
{
unsigned t = a;
a = __vminu4(t, b);
b = __vmaxu4(t, b);
}
__global__ __launch_bounds__(256, 8)
void mFilter_3a(const int H, const int W, const unsigned char * __restrict in, unsigned char *out)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x + 1;
int idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1;
unsigned a[9] = { 0, 0, 0, 0, 0, 0, 0, 0, 0 };
if (idx < W - 1)
{
for (int z3 = 0; z3 < 4; ++z3)
{
//if (idy < H - 1) <---- this is barrier for compiler optimization
{
const int shift = 8 * (3 - z3);
for (int z2 = 0; z2 < 3; ++z2)
for (int z1 = 0; z1 < 3; ++z1)
a[3 * z2 + z1] |= in[(idy - 1 + z2) * W + idx - 1 + z1] << shift;
}
idy += BL_Y;
}
Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]);
Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[6], a[7]);
Sort(a[1], a[2]); Sort(a[4], a[5]); Sort(a[7], a[8]);
Sort(a[0], a[3]); Sort(a[5], a[8]); Sort(a[4], a[7]);
Sort(a[3], a[6]); Sort(a[1], a[4]); Sort(a[2], a[5]);
Sort(a[4], a[7]); Sort(a[4], a[2]); Sort(a[6], a[4]);
Sort(a[4], a[2]);
idy = threadIdx.y + blockIdx.y * blockDim.y * 4 + 1;
for (int z = 0; z < 4; ++z)
{
if (idy < H - 1)
out[idy * W + idx] = (unsigned char)((a[4] >> (8 * (3 - z))) & 255);
idy += BL_Y;
}
}
}Оптимизированный код таким образом позволяет компилятору использовать уже загруженный данные. Единственная проблема — проверка условия (idy < H — 1). Для того, чтобы убрать данную проверку, необходимо добавить необходимое количество строк, то есть выровнить картинку по вертикали на 4, и заполнить все дополнительные элементы максимальным числом (255). После преобразования кода к третьему варианту, времена будут следующие:
| Время выполнения, ms | Относительно ускорение | ||||||
|---|---|---|---|---|---|---|---|
| Скалярный ЦПУ | AVX2 ЦПУ | Version1 GPU | Version2 GPU | Version2 GPU | Скалярный / AVX2 | Скалярный / Version3 | AVX2 / Version3 |
| 24.814 | 0.424 | 0.372 | 0.207 | 0.130 | 58.5 | 190.8 | 3.26 |
Далее оптимизировать уже довольно сложно, так как все таки вычислений здесь не так много. Здесь не был затронут вопрос использования разделяемой памяти. Были некоторые попытки использовать разделяемую память, но лучшее время я получить не смог. Если связать скорость обработки изображения с его размером, то в не зависимости от того, выровнена ли картинка по размеру или нет, можно получить порядка 15 GigaPixels / second.
Ядро медианного фильтра 5х5 на ГПУ
Применив все оптимизации, можно с небольшими изменениями реализовать фильтр квадратом 5х5. Сложность данного кода состоит в правильной реализации частичной битонической сортировки для 25 элементов. По аналогии можно реализовывать фильтры любого размера (начиная с какого-то размера фильтра, наверняка, будет быстрым общий алгоритм сортировки).
__global__ __launch_bounds__(256, 8)
void mFilter5a(const int H, const int W, const unsigned char * in, unsigned char *out, const unsigned stride_Y)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x + 2;
int idy = 4 * threadIdx.y + blockIdx.y * blockDim.y * 4 + 2;
if (idx < W - 2)
{
unsigned a[25] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
for (int t = 0; t < 4; ++t)
{
const int shift = 8 * (3 - t);
for (int q = 0; q < 5; ++q)
for (int z = 0; z < 5; ++z)
a[q * 5 + z] |= (in[(idy - 2 + q) * W + idx - 2 + z] << shift);
idy++;
}
Sort(a[0], a[1]); Sort(a[3], a[4]); Sort(a[2], a[4]); Sort(a[2], a[3]); Sort(a[6], a[7]);
Sort(a[5], a[7]); Sort(a[5], a[6]); Sort(a[9], a[10]); Sort(a[8], a[10]); Sort(a[8], a[9]);
Sort(a[12], a[13]); Sort(a[11], a[13]); Sort(a[11], a[12]); Sort(a[15], a[16]); Sort(a[14], a[16]);
Sort(a[14], a[15]); Sort(a[18], a[19]); Sort(a[17], a[19]); Sort(a[17], a[18]); Sort(a[21], a[22]);
Sort(a[20], a[22]); Sort(a[20], a[21]); Sort(a[23], a[24]); Sort(a[2], a[5]); Sort(a[3], a[6]);
Sort(a[0], a[6]); Sort(a[0], a[3]); Sort(a[4], a[7]); Sort(a[1], a[7]); Sort(a[1], a[4]);
Sort(a[11], a[14]); Sort(a[8], a[14]); Sort(a[8], a[11]); Sort(a[12], a[15]); Sort(a[9], a[15]);
Sort(a[9], a[12]); Sort(a[13], a[16]); Sort(a[10], a[16]); Sort(a[10], a[13]); Sort(a[20], a[23]);
Sort(a[17], a[23]); Sort(a[17], a[20]); Sort(a[21], a[24]); Sort(a[18], a[24]); Sort(a[18], a[21]);
Sort(a[19], a[22]); Sort(a[9], a[18]); Sort(a[0], a[18]); Sort(a[8], a[17]); Sort(a[0], a[9]);
Sort(a[10], a[19]); Sort(a[1], a[19]); Sort(a[1], a[10]); Sort(a[11], a[20]); Sort(a[2], a[20]);
Sort(a[12], a[21]); Sort(a[2], a[11]); Sort(a[3], a[21]); Sort(a[3], a[12]); Sort(a[13], a[22]);
Sort(a[4], a[22]); Sort(a[4], a[13]); Sort(a[14], a[23]); Sort(a[5], a[23]); Sort(a[5], a[14]);
Sort(a[15], a[24]); Sort(a[6], a[24]); Sort(a[6], a[15]); Sort(a[7], a[16]); Sort(a[7], a[19]);
Sort(a[13], a[21]); Sort(a[15], a[23]); Sort(a[7], a[13]); Sort(a[7], a[15]); Sort(a[1], a[9]);
Sort(a[3], a[11]); Sort(a[5], a[17]); Sort(a[11], a[17]); Sort(a[9], a[17]); Sort(a[4], a[10]);
Sort(a[6], a[12]); Sort(a[7], a[14]); Sort(a[4], a[6]); Sort(a[4], a[7]); Sort(a[12], a[14]);
Sort(a[10], a[14]); Sort(a[6], a[7]); Sort(a[10], a[12]); Sort(a[6], a[10]); Sort(a[6], a[17]);
Sort(a[12], a[17]); Sort(a[7], a[17]); Sort(a[7], a[10]); Sort(a[12], a[18]); Sort(a[7], a[12]);
Sort(a[10], a[18]); Sort(a[12], a[20]); Sort(a[10], a[20]); Sort(a[10], a[12]);
idy = 4 * threadIdx.y + blockIdx.y * blockDim.y * 4 + 2;
for (int z = 0; z < 4; ++z)
{
if (idy < H - 2)
out[idy * W + idx] = (unsigned char)((a[12] >> (8 * (3 - z))) & 255);
idy++;
}
}
}Скорость обработки фильтра данного размера будет примерно в 5.7 раз больше при использовании AVX2, в то время как ГПУ версия замедлится всего в 3.8 раза (порядка 0.5 ms). Итоговое ускорение на ГПУ при медианной фильтрации квадратом 5х5 может достигнуть 5 раз по сравнению с AVX2 версией.
Заключение
В заключении можно подвести некоторые итоги. Оптимизируя последовательную скалярную программу можно получить большие ускорения с помощью графического процессора. Для медианных фильтров в зависимости от радиуса фильтрации значения ускорений могут достигать 1000 раз! Конечно, очень оптимальная версия с использованием AVX2 инструкций резко сокращает разрыв между ГПУ и ЦПУ. Но лично по своему опыту могу сделать заключение, что векторизовывать код вручную не так просто, как на самом деле кажется. Напротив, даже самая "нативная" реализация на ГПУ дает достаточно высокие ускорения. И в большинстве случаев это бывает достаточно. И если учесть, что количество графических плат в одной материнской плате может быть больше одной, общее ускорение обработки потока изображений или видео может линейно возрасти.
Вопрос о том, стоит ли использовать ГПУ или нет, является риторическим. Безусловно, в задачах обработки изображений и видео ГПУ будет показывать лучшую производительность и с увеличением вычислительной нагрузки, разница между скоростью обработки на ЦПУ и ГПУ будет увеличиваться в пользу последнего.
Комментарии (10)

Ivan_83
21.07.2016 08:58Пишу из SIMD огорода :)
Подозреваю что AVX/SSE могло работать быстрее, если не использовать: _mm256_loadu_si256, а использовать хотя бы _mm256_load_si256, или вообще stream версию, аналогично для сохранения обратно в память.
PS: amd_median3 это вин, учитывая что есть процы со встроенным GPU где оно сразу есть.
ALEX_k_s
22.07.2016 11:14а amd_median5 или amd_median7 там есть? И на сколько мощный там ГПУ? + вы не учитываете, что там обращения идут в ЦПУшную память, которая очень медленная.
Ivan_83
22.07.2016 13:44Откуда мне знать что там есть, я вообще с обработкой изображений месяца два как, и то на OpenCV и совсем немного своими силами.
В ZEN обещают HBM память типа для кеша: https://nvworld.ru/news/tags/zen/
Но если сравнивать с SIMD даже на обычной памяти будет не хуже, в том плане что пусть и на медленной памяти (относительно кеша) жевать оно может параллельно больше данных.
vird
22.07.2016 14:43А вот тут спешу разочаровать по поводу волшебности HBM1 памяти.
1. Посмотрите бенчмарки в играх. Поймите, что что-то не так.
2. Загляните в документацию AMD и посмотрите как правильно вынимать нужно с памяти данные, чтобы нормально использовать 4096битную шину.
2.1. Bank conflict'ы там по-жестче чем у nvidia (т.к. их бывает два типа и даже банально по битам получается что нужно разбрасывать массив в памяти сильнее, что для 1920*1080 нереально)
2.2. Вынимать нужно порциями по 16 байт (насколько я помню) (т.е. int4, или char16) это нужно переписать достаточно сильно многие алгоритмы, а если нет — мы не используем мощность HBM на полную)
Ждем HBM2 или Vega, может как-то сгладят недостатки.
vird
22.07.2016 14:30С чего вы взяли, что обращение идет в CPU'шную память?
По умолчанию всё идет на быструю память видеокарты. Это нужно специально включать pinned memory, если нужен массив памяти больше, чем есть на видеокарте.
amd_median5 и median7 нету по понятной причине. Каждая операция работает с максимум 4 аргументами. amd_median3+amd_min3+amd_max3 достаточно, чтобы за 3 операции отсортировать 3 набора по 4 числа (т.к. int4).
По поводу производительности, посчитайте на досуге производительность AMD/$ и nvidia/$, в чистых tflops/$. Я за те же деньги поставлю больше мощности. В моем случае это 100% можно сделать т.к. у меня просто большой поток однотипной работы, которая не зависит друг от друга. (Прим. Да, это не всем подойдет)vird
22.07.2016 14:51А конкретно в случае APU там ситуация еще лучше.
Рассмотрим выполнение kernel'а
1. Скопировать с медленной CPU памяти в быструю GPU.
2. Выполнить на быстрой GPU памяти.
3. Скопировать обратно в медленную CPU память.
Итак. У нас на самом-то деле bottleneck по пропускной способности никуда не делся. Мы не можем выполнять быстрее, чем скорость передачи CPU памяти. А вот задержка стала меньше.
vird
22.07.2016 15:04BTW.
median_5
Сортируем первые 3 элемента. 3 операции
Сортируем последние 3 элемента 2 операции, т.к. max нам не нужен т.к. это глобальный максимум.
Снова сортируем первые 3 элемента. 2 операции т.к. min нам не нужен т.к. это глобальный минимум
Смотрим на 3 центральных элемента и выполняем median3. 1 операция
3+2+2+1 = 8 операций.
Возможно, можно за меньшее количество операций.
Для попарных сравнений операций понадобится явно больше. Плюс я уже писал, что можно захватывать по 4 числа и сортировать их параллельно.
vird
Прим. Пишу из opencl огорода.
У AMD есть специальная инструкция для этого
https://www.khronos.org/registry/cl/extensions/amd/cl_amd_media_ops2.txt
amd_median3
Если не хватит, есть еще amd_min3, amd_max3.
В opencl есть char4. Это векторный тип данных который позволяет параллельно выполнять несколько операций. https://www.khronos.org/files/opencl-1-2-quick-reference-card.pdf судя по этому можно выполнять min(char4, char4), потому не надо помнить о вендорно-зависимой __vminu4.
Про bank conflict'ы ни слова. Хотя в принципе я тоже их игнорирую.
Если уже используется локальный буфер а для предзагрузки, то можно увеличить его в 2 раза и закачивать полностью только на первом такте, а все остальные докачивать только новую линию. Ну и тогда нужен индекс для того, чтобы ходить по такому буферу. На 5*5 это вообще жёстко.
Общие пожелания
Три цикла фиксированного размера. Ну тут просится либо pragma unroll, либо написать свой небольшой кодогенератор, который сгенерирует развёрнутый цикл с подставленными индексами.
if (idy < H — 1)
не рекомендуется использовать в принципе либо использовать тернарные операции, либо
select (который лично мне не нравится за необходимость жёстко задавать определённые типы).
idy * W + idx лишнее умножение
Правильно делать dst_offset = idx
И потом dst_offset += W каждую итерацию.
То же про 3 * z2 + z1 и другие места
Если умножение сильно нужно, но там гарантированно не используется все 32 бита, то есть mul24 и mad24 специально для работы с индексами. Работают в 4 раза быстрее чем честное 32-битное умножение.
Вместо if (idx < W — 1) {} лучше писать if (idx >= W — 1) return; Как минимум код чище, минус одна лесенка.
Дополнительная оптимизация. Убираем const int H, const int W, т.к. скорее всего у нас будет фиксированный размер картинки (не всегда так бывает) и вписываем как константы прямо в код kernel'а получаем еще +5% производительности.
ALEX_k_s
Раз уж я пишу про CUDA, то имею право использовать вендорно зависимые функции. Вы лучше не просто так ссылки пишите, а приведите пример производительности всего того, что упомянули. А так — это голые слова.
На счет буфера А ничего не понял. Может быть имелось в виду то, что повторные загрузки, начиная со второй линии не повторяются — так это и так оптимизируется компилятором и для этого не надо уродовать код.
Про pragma unroll и так было сказано, а описанные вами оптимизации компилятор сделает и так.
Если вы думаете, что тернарная операция сработает быстрее if, то советую обратиться к профилировщику. Видимо для AMD и openCL еще не придумали нормальных инструментов. А вот у Nvidia все по человечески.
Кому нужны ваши 5%? Если бы это были разы, то другое дело.
Если очень интересно реально то показать, то напишите ваш очень оптимизированный код на openCL и запустите на ГПУ Nvidia и посмотрите что получится.