
Это подробная инструкция по распознаванию образов в R с использованием глубокой сверточной нейронной сети, предоставляемой пакетом MXNet. В этой статье приведен воспроизводимый пример, как получить 97,5% точность в задаче распознавания лиц на R.
Мне кажется, кое-какое предисловие все же нужно. Я пишу эту инструкцию исходя из двух соображений. Первое — предоставить всем полноценно воспроизводимый пример. Второе — дать ответы на уже возникшие ранее вопросы. Пожалуйста, примите во внимание, что это лишь мой способ подойти к решению этой проблемы, он точно не единственный и, определенно, не лучший.
Я собираюсь использовать и Python 3.x (для получения и предварительной обработки данных), и R (собственно, решение задачи), поэтому имеет смысл установить оба. Требования к пакетам R таковы:
Что касается Python 3.x, установите и Numpy, и Scikit-learn. Возможно, стоит также установить и дистрибутив Anaconda, в котором есть ряд предустановленных популярных пакетов для анализа данных и машинного обучения.
Как только у вас все это заработало, можно приступать.
Я собираюсь использовать набор лиц Olivetti. Этот набор данных — коллекция изображений 64 на 64 пикселя, в 0-256 градациях серого.
Набор данных содержит 400 изображений 40 людей. С 10 экземплярами для каждого человека обычно используют неконтролируемые или полуконтролируемые алгоритмы, но я собираюсь постараться и использовать конкретный контролируемый метод.
Для начала нужно масштабировать изображения по шкале от 0 до 1. Это делается автоматически функцией, которую мы собираемся использовать для загрузки набора данных, поэтому не стоит об этом беспокоиться, но нужно знать, что это уже сделано. Если вы собираетесь использовать свои собственные изображения, предварительно масштабируйте их по шкале от 0 до 1 (или по -1;1, хотя первое лучше работает с нейронными сетями, исходя из моего опыта). Ниже — скрипт на Python, который нужно выполнить, чтобы загрузить набор данных. Просто измените пути на ваши значения и выполните из IDE или терминала.
Фактически, этот кусочек кода делает следующее: загружает данные, изменяет размеры картинок по Х и сохраняет массивы numpy в файл .csv.
Массив х является тензором (тензор — красивое название многомерной матрицы) размера (400, 64, 64): это означает, что массив х содержит 400 экземпляров матриц 64 на 64 (считанных изображений). Если сомневаетесь, просто выведите первые элементы тензора и попробуйте разобраться в структуре данных с учетом того, что вы уже знаете. Например, из описания набора данных мы знаем, что у нас есть 400 экземпляров, каждый из которых — изображение 64 на 64 пикселя. Мы сглаживаем тензор х до матрицы размером 400 на 4096. То есть, каждая матрица 64 на 64 (изображение) теперь конвертируется (сглаживается) в горизонтальный вектор длиной 4096.
Что касается у, то это уже вертикальный вектор размером 400. Его не нужно изменять.
Посмотрите на получившийся файл .csv и убедитесь, что все преобразования понятны.
Теперь мы воспользуемся EBImage, чтобы изменить размер изображений до 28 на 28 пикселей, и сгенерируем обучающий и тестовый наборы данных. Вы спросите, зачем я изменяю размеры изображений. По какой-то причине моему компьютеру не нравятся картинки 64 на 64 пикселя, и каждый раз при запуске модели с данными возникает ошибка. Плохо. Но терпимо, поскольку мы можем получить хорошие результаты и с меньшими картинками (но вы, конечно, можете попробовать запустить и с 64 на 64 пикселя, если у вас нет такой проблемы). Итак:
Эта часть должна быть достаточно понятна, если вы не уверены, как выглядят выходные данные, стоит взглянуть на набор данных rs_df. Это должен быть массив данных 400x785, приблизительно такой:
label, pixel1, pixel2, …, pixel784
0, 0.2, 0.3, … ,0.1
Теперь самое интересное, давайте построим модель. Ниже скрипт, который был использован, чтобы обучить и протестировать модель. Ниже будут мои комментарии и пояснения к коду.
После загрузки обучающего и тестового набора данных я использую функцию
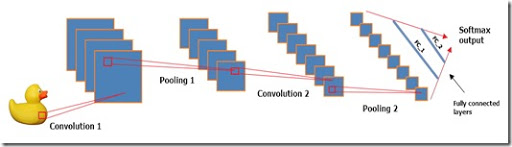
Что касается структуры модели, это вариация модели LeNet, использующей гиперболический тангенс как активационную функцию вместо «Relu» (трансформированный линейный узел), 2 сверточных слоя, 2 слоя подвыборки, 2 полностью связных слоя и стандартный многопеременный логистический вывод.
Каждый сверточный слой использует ядро 5х5 и применяется к фиксированному набору фильтров. Посмотрите это прекрасное видео, чтобы празобраться со сверточными слоями. Слои подвыборки используют классический подход «максимального объединения».
Мои тесты показали, что tanh работает гораздо лучше, чем sigmoid и Relu, но вы можете попробовать и другие функции активации, если есть желание.
Что касается гиперпараметров модели, уровень обучения немного выше обычного, но работает нормально, пока количество периодов — 480. Размер серии, равный 40, тоже хорошо работает. Эти гиперпараметры получены путем проб и ошибок. Можно было сделать поиск по перекрывающимся полосам, но не хотелось переусложнять код, так что я воспользовался проверенным методом — проб и ошибок.
В конце вы должны получить точность 0.975.
В целом, эту модель было достаточно легко настроить и запустить. При запуске на CPU обучение занимает 4-5 минут: немного долго, если вы хотите поэкспериментировать, но все же приемлемо для работы.
Учитывая тот факт, что мы никак не работали с параметрами данных и выполнили только простые и самые обычные шаги предварительной обработки, мне кажется, что полученные результаты весьма неплохи. Конечно, если бы мы хотели добиться более высокой «настоящей» точности, нужно было бы сделать больше перекрестных проверок (что неизбежно заняло бы много времени).
Спасибо, что дочитали, и надеюсь, эта статья помогла вам понять, как настраивать и запускать эту конкретную модель.
Источник набора данных — набор лиц Olivetti, созданный AT&T Laboratories Cambridge.
Предисловие
Мне кажется, кое-какое предисловие все же нужно. Я пишу эту инструкцию исходя из двух соображений. Первое — предоставить всем полноценно воспроизводимый пример. Второе — дать ответы на уже возникшие ранее вопросы. Пожалуйста, примите во внимание, что это лишь мой способ подойти к решению этой проблемы, он точно не единственный и, определенно, не лучший.
Требования
Я собираюсь использовать и Python 3.x (для получения и предварительной обработки данных), и R (собственно, решение задачи), поэтому имеет смысл установить оба. Требования к пакетам R таковы:
- MXNet. Этот пакет предоставит модель, которую мы собираемся использовать в этой статье, собственно, глубокую сверточную нейронную сеть. Вам не понадобится GPU-версия, CPU будет достаточно для этой задачи, хотя она может работать медленнее. Если это произойдет, воспользуйтесь GPU-версией.
- EBImage. Этот пакет имеет множество инструментов для работы с изображениями. С ним работа с изображениями — одно удовольствие, документация предельно понятна и довольно проста.
Что касается Python 3.x, установите и Numpy, и Scikit-learn. Возможно, стоит также установить и дистрибутив Anaconda, в котором есть ряд предустановленных популярных пакетов для анализа данных и машинного обучения.
Как только у вас все это заработало, можно приступать.
Набор данных
Я собираюсь использовать набор лиц Olivetti. Этот набор данных — коллекция изображений 64 на 64 пикселя, в 0-256 градациях серого.
Набор данных содержит 400 изображений 40 людей. С 10 экземплярами для каждого человека обычно используют неконтролируемые или полуконтролируемые алгоритмы, но я собираюсь постараться и использовать конкретный контролируемый метод.
Для начала нужно масштабировать изображения по шкале от 0 до 1. Это делается автоматически функцией, которую мы собираемся использовать для загрузки набора данных, поэтому не стоит об этом беспокоиться, но нужно знать, что это уже сделано. Если вы собираетесь использовать свои собственные изображения, предварительно масштабируйте их по шкале от 0 до 1 (или по -1;1, хотя первое лучше работает с нейронными сетями, исходя из моего опыта). Ниже — скрипт на Python, который нужно выполнить, чтобы загрузить набор данных. Просто измените пути на ваши значения и выполните из IDE или терминала.
# -*- coding: utf-8 -*-
# Импорт
from sklearn.datasets import fetch_olivetti_faces
import numpy as np
# Загрузка набора лиц Olivetti
olivetti = fetch_olivetti_faces()
x = olivetti.images
y = olivetti.target
# Вывод информации о размерах и их изменение при необходимости
print("Original x shape:", x.shape)
X = x.reshape((400, 4096))
print("New x shape:", X.shape)
print("y shape", y.shape)
# Сохранение массивов numpy
np.savetxt("C://olivetti_X.csv", X, delimiter = ",")
np.savetxt("C://olivetti_y.csv", y, delimiter = ",", fmt = '%d')
print("\nDownloading and reshaping done!")
################################################################################
# ВЫВОД
################################################################################
#
# Original x shape: (400, 64, 64)
# New x shape: (400, 4096)
# y shape (400,)
#
# Downloading and reshaping done!Фактически, этот кусочек кода делает следующее: загружает данные, изменяет размеры картинок по Х и сохраняет массивы numpy в файл .csv.
Массив х является тензором (тензор — красивое название многомерной матрицы) размера (400, 64, 64): это означает, что массив х содержит 400 экземпляров матриц 64 на 64 (считанных изображений). Если сомневаетесь, просто выведите первые элементы тензора и попробуйте разобраться в структуре данных с учетом того, что вы уже знаете. Например, из описания набора данных мы знаем, что у нас есть 400 экземпляров, каждый из которых — изображение 64 на 64 пикселя. Мы сглаживаем тензор х до матрицы размером 400 на 4096. То есть, каждая матрица 64 на 64 (изображение) теперь конвертируется (сглаживается) в горизонтальный вектор длиной 4096.
Что касается у, то это уже вертикальный вектор размером 400. Его не нужно изменять.
Посмотрите на получившийся файл .csv и убедитесь, что все преобразования понятны.
Немного предварительной обработки в R
Теперь мы воспользуемся EBImage, чтобы изменить размер изображений до 28 на 28 пикселей, и сгенерируем обучающий и тестовый наборы данных. Вы спросите, зачем я изменяю размеры изображений. По какой-то причине моему компьютеру не нравятся картинки 64 на 64 пикселя, и каждый раз при запуске модели с данными возникает ошибка. Плохо. Но терпимо, поскольку мы можем получить хорошие результаты и с меньшими картинками (но вы, конечно, можете попробовать запустить и с 64 на 64 пикселя, если у вас нет такой проблемы). Итак:
# Этот скрипт нужен для изменения размера картинок с 64 на 64 до 28 на 28 пикселей
# Очистить рабочую среду
rm(list=ls())
# Загрузить библиотеку EBImage
require(EBImage)
# Загрузить данные
X <- read.csv("olivetti_X.csv", header = F)
labels <- read.csv("olivetti_y.csv", header = F)
# Массив данных картинок с измененным размером
rs_df <- data.frame()
# Основной цикл: для каждой картинки изменить размер и перевести в градацию серого
for(i in 1:nrow(X))
{
# Try-catch
result <- tryCatch({
# Изображение (как одномерный вектор)
img <- as.numeric(X[i,])
# Картинка 64x64 (объект EBImage)
img <- Image(img, dim=c(64, 64), colormode = "Grayscale")
# Изменить размер картинки на 28x28 пикселей
img_resized <- resize(img, w = 28, h = 28)
# Получить матрицу картинки (здесь должна быть другая функция, чтобы сделать это быстрее и аккуратнее!)
img_matrix <- img_resized@.Data
# Привести к вектору
img_vector <- as.vector(t(img_matrix))
# Добавить метки
label <- labels[i,]
vec <- c(label, img_vector)
# Поместить в rs_df с помощью rbind
rs_df <- rbind(rs_df, vec)
# Вывести статус
print(paste("Done",i,sep = " "))},
# Функция вывода ошибок (просто выводит ошибку). Но ошибок быть не должно!
error = function(e){print(e)})
}
# Задать имена. Первые столбцы - метки, остальные - пиксели.
names(rs_df) <- c("label", paste("pixel", c(1:784)))
# Разбиение на обучение и тест
#-------------------------------------------------------------------------------
# Простое разбиение на обучение и тест. Никаких перекрестных проверок.
# Установить начальное число для воспроизводимости
set.seed(100)
# Перемешанный df
shuffled <- rs_df[sample(1:400),]
# Разбиение на обучение и тест
train_28 <- shuffled[1:360, ]
test_28 <- shuffled[361:400, ]
# Сохранить обучающий и тестовый наборы данных
write.csv(train_28, "C://train_28.csv", row.names = FALSE)
write.csv(test_28, "C://test_28.csv", row.names = FALSE)
# Готово!
print("Done!")Эта часть должна быть достаточно понятна, если вы не уверены, как выглядят выходные данные, стоит взглянуть на набор данных rs_df. Это должен быть массив данных 400x785, приблизительно такой:
label, pixel1, pixel2, …, pixel784
0, 0.2, 0.3, … ,0.1
Построение модели
Теперь самое интересное, давайте построим модель. Ниже скрипт, который был использован, чтобы обучить и протестировать модель. Ниже будут мои комментарии и пояснения к коду.
# Очистить рабочую область
rm(list=ls())
# Загрузить MXNet
require(mxnet)
# Загрузка данных и настройки
#-------------------------------------------------------------------------------
# Загрузить обучающий и тестовый наборы данных
train <- read.csv("train_28.csv")
test <- read.csv("test_28.csv")
# Определить обучающий и тестовый наборы данных
train <- data.matrix(train)
train_x <- t(train[, -1])
train_y <- train[, 1]
train_array <- train_x
dim(train_array) <- c(28, 28, 1, ncol(train_x))
test_x <- t(test[, -1])
test_y <- test[, 1]
test_array <- test_x
dim(test_array) <- c(28, 28, 1, ncol(test_x))
# Задать символьную модель
#-------------------------------------------------------------------------------
data <- mx.symbol.Variable('data')
# Первый сверточный слой
conv_1 <- mx.symbol.Convolution(data = data, kernel = c(5, 5), num_filter = 20)
tanh_1 <- mx.symbol.Activation(data = conv_1, act_type = "tanh")
pool_1 <- mx.symbol.Pooling(data = tanh_1, pool_type = "max", kernel = c(2, 2), stride = c(2, 2))
# Второй сверточный слой
conv_2 <- mx.symbol.Convolution(data = pool_1, kernel = c(5, 5), num_filter = 50)
tanh_2 <- mx.symbol.Activation(data = conv_2, act_type = "tanh")
pool_2 <- mx.symbol.Pooling(data=tanh_2, pool_type = "max", kernel = c(2, 2), stride = c(2, 2))
# Первый полностью связный слой
flatten <- mx.symbol.Flatten(data = pool_2)
fc_1 <- mx.symbol.FullyConnected(data = flatten, num_hidden = 500)
tanh_3 <- mx.symbol.Activation(data = fc_1, act_type = "tanh")
# Второй полностью связный слой
fc_2 <- mx.symbol.FullyConnected(data = tanh_3, num_hidden = 40)
# Вывод. Многопеременный логистический вывод, т.к. хотим получить какие-то вероятности.
NN_model <- mx.symbol.SoftmaxOutput(data = fc_2)
# Настройки до обучения
#-------------------------------------------------------------------------------
# Установить начальное значение для воспроизводимости
mx.set.seed(100)
# Используемое устройство. В моем случае CPU.
devices <- mx.cpu()
# Обучение
#-------------------------------------------------------------------------------
# Обучить модель
model <- mx.model.FeedForward.create(NN_model,
X = train_array,
y = train_y,
ctx = devices,
num.round = 480,
array.batch.size = 40,
learning.rate = 0.01,
momentum = 0.9,
eval.metric = mx.metric.accuracy,
epoch.end.callback = mx.callback.log.train.metric(100))
# Тестирование
#-------------------------------------------------------------------------------
# Предсказать метки
predicted <- predict(model, test_array)
# Присвоить метки
predicted_labels <- max.col(t(predicted)) - 1
# Получить точность
sum(diag(table(test[, 1], predicted_labels)))/40
################################################################################
# ВЫВОД
################################################################################
#
# 0.975
#После загрузки обучающего и тестового набора данных я использую функцию
data.matrix, чтобы превратить каждый набор данных в числовую матрицу. Помните, первый столбец данных — метки, связанные с каждой картинкой. Убедитесь, что вы удалили метки из train_array и test_array. После разделения меток и зависимых переменных нужно указать MXNet обработать данные. Это я делаю в строке 19 следующим кусочком кода: «dim(train_array) < — c(28, 28, 1, ncol(train_x))» для обучающего набора и в строке 24 для тестового. Таким образом мы фактически говорим модели, что обучающие данные состоят из ncol(train_x) образцов (360 картинок) размером 28x28. Число 1 указывает, что картинки в градации серого, т.е., что у них только 1 канал. Если бы картинки были в RGB, 1 нужно было бы заменить на 3, именно столько каналов имели бы картинки.Что касается структуры модели, это вариация модели LeNet, использующей гиперболический тангенс как активационную функцию вместо «Relu» (трансформированный линейный узел), 2 сверточных слоя, 2 слоя подвыборки, 2 полностью связных слоя и стандартный многопеременный логистический вывод.
Каждый сверточный слой использует ядро 5х5 и применяется к фиксированному набору фильтров. Посмотрите это прекрасное видео, чтобы празобраться со сверточными слоями. Слои подвыборки используют классический подход «максимального объединения».
Мои тесты показали, что tanh работает гораздо лучше, чем sigmoid и Relu, но вы можете попробовать и другие функции активации, если есть желание.
Что касается гиперпараметров модели, уровень обучения немного выше обычного, но работает нормально, пока количество периодов — 480. Размер серии, равный 40, тоже хорошо работает. Эти гиперпараметры получены путем проб и ошибок. Можно было сделать поиск по перекрывающимся полосам, но не хотелось переусложнять код, так что я воспользовался проверенным методом — проб и ошибок.
В конце вы должны получить точность 0.975.
Заключение
В целом, эту модель было достаточно легко настроить и запустить. При запуске на CPU обучение занимает 4-5 минут: немного долго, если вы хотите поэкспериментировать, но все же приемлемо для работы.
Учитывая тот факт, что мы никак не работали с параметрами данных и выполнили только простые и самые обычные шаги предварительной обработки, мне кажется, что полученные результаты весьма неплохи. Конечно, если бы мы хотели добиться более высокой «настоящей» точности, нужно было бы сделать больше перекрестных проверок (что неизбежно заняло бы много времени).
Спасибо, что дочитали, и надеюсь, эта статья помогла вам понять, как настраивать и запускать эту конкретную модель.
Источник набора данных — набор лиц Olivetti, созданный AT&T Laboratories Cambridge.
Поделиться с друзьями
Комментарии (2)

ivodopyanov
09.08.2016 14:28-2Зачем проводить обучение на R, если доступен Python? Неужто на R они тренируются быстрее?
knowhow
Хм… Интересно, чему именно научилась сеть. Я смотрю на фотографии в наборе данных, и они очень похожи для одного и того же человека. Например, они на одном и том же фоне. Некоторые на одинаковом светлом фоне, а другие на одинаковом темном. Это значит, что этих двух людей можно будет различить просто по цвету пикселя в позиции (0,0), не имеющего при этом никакого отношения к лицу.