
В этой статье я хочу рассмотреть внутреннее устройство работы памяти СХД NetApp FAS и как она умеет собирать тетрис.

Память СХД любого контроллера NetApp FAS состоит из модулей оперативной памяти, которые используются для кэширования чтения, и записи, и запитаны батарейкой, отсюда приставка «NV» — Non Volatile MEMory / RAM / LOG. ОЗУ делится на следующие функциональные части: NVRAM, буфер MBUF (или системный кэш), о которых подробнее.

* Сброс данных на диски происходит из MBUF, по событию заполненности NVRAM, а не из самого NVRAM`а.
В NVRAM последовательно, наподобие LOG-записей в БД, собирается NVLOG-записи, в их изначальной форме, как они были присланы хостами. Как только данные от хоста попадают в NVRAM, хост получает подтверждение записи. После того, как произойдёт CP событие, которое генерирует сброс данных из MBUF на диски с последующим подтверждением, NVRAM очищается. Таким образом в нормально работающей СХД содержимое NVRAM никогда не читается, а только пишется, а когда место в ней заканчивается, происходит CP и NVRAM очищается. Чтение NVRAM происходит только после сбоя.
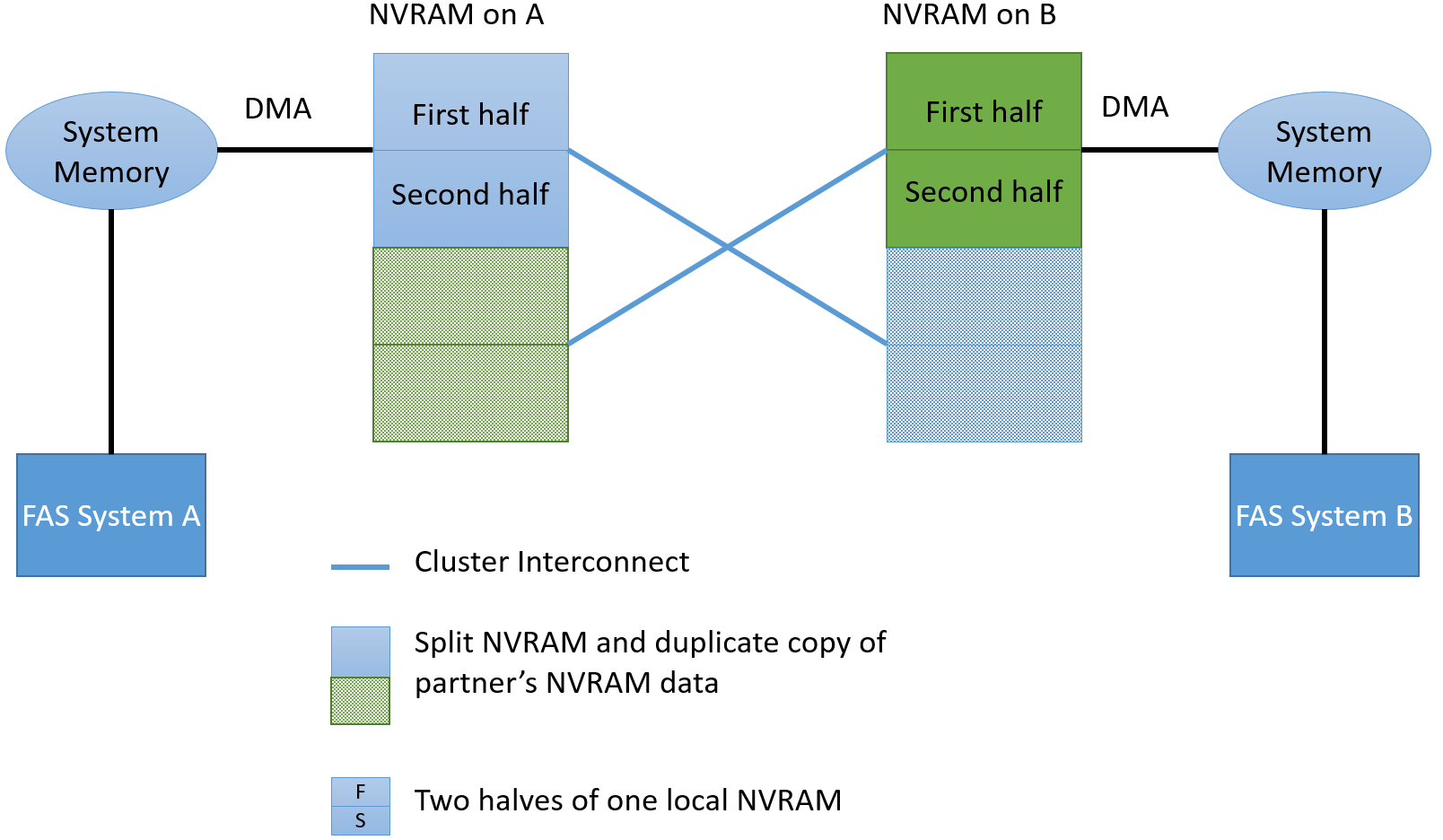
В High Availability (HA) паре, из двух контроллеров NetApp FAS, память NVRAM всегда зазеркалирована, каждый контроллер имеет копию своего соседа. Это позволяет в случае отказа одного контроллера переключить и далее обслуживать все хосты на оставшийся в живых контроллер. После того, как произойдёт CP событие (сброс данных на диск с подтверждением), NVRAM очищается.
Если быть более точным, то каждая из этих двух частей делится ещё на две части, итого 4 для HA пары (т.е. 2 локальные). Сделано это для того, чтобы по заполнении половины локального NVRAM, сброс данных не тормозил новые поступающие команды. То есть пока происходит сброс данных из одной части локального NVRAM, новые уже поступают во вторую половину локального NVRAM.
Для того, чтобы обеспечить защиту данных от Split-Brain в MCC, данные, которые поступают на запись, будут подтверждены хосту только после того, как они попадут в NVRAM одного локального контроллера, его соседа и одного удалённого соседа (если MCC состоит из 4 нод). Синхронизация между локальными контроллерами выполняется через HA Interconnect (это внешнее подключение для двухконтроллерных систем в двух разных шасси), а синхронизация на удалённую ноду выполняется через FC-IV адаптеры (это тоже внешнее подключение). Эта схема позволяет выполнять переключение в рамках сайта, если второй контроллер HA пары уцелел, или переключаться на второй сайт, если все локальные ноды хранилища вышли из строя. Переключение на второй сайт происходит за секунды.

Важно отметить что NVRAM с одной стороны технология которая есть не только на вооружении NetApp, но с другой стороны используется NetApp, для хранения логов (аппаратная реализация журналируемой файловой системы), в то время, как большинство других производителей СХД используют NVRAM на «блочном уровне» (Disk Driver level или Disk Cache) для кэширования данных в NVRAM — в этом большая разница.
Наличие NVLOG позволяет NetApp FAS не переводить в HA-паре, оставшийся в живых один единственный контроллер в режим Pass-Through (запись, без кэша, напрямую на диски) если один из них умер. Давайте немного на этом остановимся и начнём с того, зачем вообще нужен кэш записи? Кэш нужен, чтобы обманывать хосты и ускорять запись, он подтверждает запись данных до, того, как данные, на самом деле, попадают на диски. Зачем вообще переводить контроллер в режим Pass-Through, если у кэша есть батарейка, при том что у всех А-брендов СХД, есть еще и зеркалирование кэша в HA паре? Ответ не совсем просто увидеть с первого взгляда, во-первых, механизм HA заботится о том, чтобы данные были не повреждены и сбрасывались на диски при выходе из строя одного из двух контроллеров в HA-паре, а клиенты прозрачно переключались на партнёра, во-вторых, самое важное, в данном случае, чтобы данные не были повреждены на уровне структуры данных самой СХД, на этом стоит остановиться детальнее. Пересчёт чек-сумм для RAID, в памяти, давно не новинка, так как это ускоряет работу дисковой подсистемы, многие если не все А-бренды освоили этот трюк, но именно сброс данных из кэша в уже обработанном на уровне RAID виде оставляет вероятность повреждения данных, которое нельзя будет отследить и восстановить после перезапуска двух контроллеров. Так вот, при выходе из строя первого, а следом ещё и второго контроллера, может оказаться так, что нельзя отследить целостность изначально поступивших данных в следствии обработки, то есть данные могут быть повреждены, в других ситуациях отследить и восстановить повреждения возможно, но для этого необходимо запускать проверку структуры данных СХД. Так как кэш записи становится краеугольным камнем и потенциальной большой проблемой, при выходе из строя одного контроллера в НА паре, большинство СХД нужно переходить в режим PassThrough с прямой записью на диски, выключив кэш записи, чтобы устранить вероятность повреждения своей файловой структуры.
С другой стороны, большинство этих СХД позволяет вручную администратору перевести оставшийся в живых контроллер вручную, в режим кэширования записей, но это не безопасно, так как при выходе из строя второго контроллера, данные на уровне файловой структуры СХД могут быть повреждены и их придётся восстанавливать, иногда это может приводить к трагическим последствиям. Благодаря тому, что у FAS систем данные сохраняются в виде логов, а не в обработанном виде после WAFL или RAID виде, а сброс уже обработанных данных происходит в виде накатывания системного снепшота CP, единой транзакцией, это позволяет полностью обойти вероятность повреждения данных. Таким образом, во многих современных конкурирующих системах хранения, когда умирает один контроллер в HA паре, мало того, что на второй падает нагрузка от умершего контроллера, так он ещё и отключает свой кэш для оптимизации записей, что сильно ухудшает скорость работы в таких ситуациях. Делается это для того, чтобы записываемые данные таки точно были записаны в не поврежденном виде на диски, а самое важное — файловая структура СХД осталась не повреждённой. Некоторые вовсе не заморачиваются этим вопросом и просто честно пишут об этом «нюансе» в своей документации. А некоторые пытаются обойти эту проблему при помощи «костыля», предлагая покупать не 2-нодовую, а сразу 4-нодовую систему. Так, к примеру, устроена система HP 3PAR, где в случае выхода из строя одного контроллера, в 4-х нодовой системе, оставшиеся 3 контроллера будут работать в нормальном режиме записи, но в случае выхода из строя 50% нод система таки перейдёт в режим Pass-Through. Иногда бывают забавные ситуации, когда лучше, чтобы уже вся СХД умерла, нежели чтобы она работала с такими жуткими тормозами. Это контрастирует с системами FAS, которые даже в однонодовых конфигурациях никогда не отключают кэш, так как архитектурно защищены от подобных проблем.
Запись, на самом деле, всегда происходит в MBUF (Memory Buffer). А из него при помощи запроса Direct Memory Access (DMA), NVRAM выполняет копию этих данных к себе, что позволяет экономить ресурсы CPU. После чего модуль WAFL выделяет диапазоны блоков, куда будут записаны данные из MBUF, этот процесс называется Write Allocation. Модуль WAFL не просто выделяет бездумно блоки, а сначала собирает тетрис (о да, Тетрис! Вы о нём не слышали?, тогда смотрите на 28-й минуте), и выделяет пустые блоки, так, чтобы мочь записать весь тетрис на диски одним неразрывным куском.
WAFL также выполняет другие оптимизации записи для данных. После того как в модуль WAFL приходит подтверждение записи из NVRAM, данные из MBUF, согласно выделенным блокам, обрабатываются модулем RAID, где высчитывается контрольная сумма для парити дисков и высчитывается контрольная сумма, которая храниться вместе с каждым блоком (Block/Zone checksum). Важно также отметить, что данные из MBUF передаваясь в модуль RAID «распаковываются», к примеру некоторые команды могут запрашивать запись повторяющегося патерна блоков информации или запрос на перемещение блоков, такие команды сами по себе занимают не много места в NVRAM, но при «распаковке» генерируют большое количество новых данных.
Это часть WAFL, которая претерпела значительные изменения от своей изначальной архитектуры устройства, особенно в плане работы новыми носителями информации и паралелизации (новая архитектура начала поставляться в 2011 году) и подготовила плацдарм для использования новых технологий хранения, которые могут появиться в ближайшем будущем. Write Allocation благодаря интеллектуальности своего устройства позволяет гранулярно писать данные разными способами и в разные места дисковой подсистемы. Каждый отдельный поток записываемой информации обрабатывается по-отдельности и может быть обработан, в зависимости от того, как данные пишутся, читаются, от размера блока и характера записи (и др.). Основываясь на характере записуемых данных WAFL, может принимать решение на какой тип носителя стоит его писать и каким именно способом. Примером тому может послужить Flash накопители, где имеет смысл писать с гранулярностью и по границам блока, по которыми происходит очистка ячеек (erase block size). В дополнение мета информация, которая занимает, обычно, на много меньше места по сравнению с самими данными может размещаться отдельно от больших блоков с полезными данными, в некоторых случаях это имеет большую выгоду, что было установленную экспериментальным способом. На самом деле описание внутреннего устройства Write Allocation это отдельная, очень большая тема.
Из модуля WAFL данные передаются в модуль RAID, который обрабатывает и записывает их одной транзакцией, страйпами на диски, в том числе и на диски чётности. А так как данные всегда пишутся страйпами и всегда в новое место, данные для дисков чётности не нужно пересчитывать, они уже заранее были подготовлены для записи RAID модулем. Благодаря чему в системах FAS на практике, парити диски всегда намного меньше нагружены нежели остальные диски, что весьма контрастирует с обычной реализацией RAID 4/6. Также стоит отметить, что просчёт чек-суммы выполняется сразу для всего страйпа записываемых данных, никогда не перезаписывая данные (запись происходит на новое место), меняется только метаинформация (ссылки на новые блоки с данными). Это приводит к тому, что нет необходимости в случае перезаписи на одном из дисков считывать каждый раз информацию из остальных дисков в память и пересчитывать чек-сумму, благодаря чему системная память используется более рационально. Подробнее про устройство RAID-DP.

Тетрис — это механизм оптимизации записи и чтения, который собирает данные, в промежутке между CP (CP Time Frame), в цепочки последовательностей блоков от одного хоста, превращая мелкие блоки в более крупные последовательные записи (IO-reduction). С другой стороны, это позволяет без сложной логики включать упреждающее чтение данных. Так, к примеру, нет разницы — прочитать 5KB, или 8KB, 13KB или 16KB и т.д. Эта логика используется для упреждающего чтения. Упреждающее чтение — это форма кэширования данных, которые потенциально могут быть запрошены в будущем, следом за теми данными которые были только что запрошены. И когда становится вопрос, какие именно «лишние» блоки стоит упреждающе читать для переноса в кэш, с тетрисом, вы автоматически получаете ответ на этот вопрос: те, которые записывались вместе с запрашиваемыми данными.

Системный кэш (MBUF) используется как для операций записи, так и для операций чтения. В кэш попадают все без исключения операции чтения, а также из него читаются только что записанные данные. Когда CPU СХД не может найти данные в системном кэше, он обращается на диски, и первое, что он делает — помещает их в кэш для чтения, а потом отдаёт хосту. Далее эти данные могут быть или просто удалены (это же кэш чтения, всё и так есть на дисках) или перемещены на уровень ниже (II уровень кэша), если таковой имеется: FlashPool (SSD диски, кэш на чтение-запись) или FlashCache (PCIe Flash карта, только кэш на чтение). Во-первых, системный кэш, как первого, так и второго уровня, вытесняется очень гранулярно: т.е. может вытесняться 4 KB блок информации. Во-вторых, системный и кэш II уровня, он deduplication-aware, т.е. если такой блок продедуплицирован или клонирован, он не будет снова копироваться и занимать в памяти пространство. Это существенно улучшает производительность за счёт увеличения попадания в кэш. Так происходит тогда, когда набор лежащих на СХД данных может быть хорошо продедуплицирован или множество раз клонирован, к примеру, в среде VDI.
Как и многие современные файловые системы, WAFL является журналируемой файловой системой. Как и любая журналируемая файловая система, журнал с лог-записями используется для того, чтобы обеспечить консистентность и её неповрежадемость на уровне СХД. В то время как все остальные реализации журналируемых файловых систем устроены таки образом, чтобы при повреждении мочь откатиться к консистентному состоянию (необходимо выполнить проверку и восстановление) и попытаться восстановиться, WAFL устроена таким образом, чтобы при внезапном отказе контроллеров не допустить самого повреждения. Это достигается благодаря, во-первых, атомарности записи Consistency Point, во-вторых благодаря применению системных снепшотов при операциях записи.
Технология снепшотирования NetApp оказалась на столько удачной, что она используется в ONTAP буквально повсюду, как базис, для многих других свойств и функций. Напомню, что в CP — содержатся данные, уже обработанные WAFL и RAID. CP — это тоже снепшот, который перед тем, как происходит сброс содержимого из системной памяти (после обработки модулями WAFL и RAID), СХД снимает системный снепшот с агрегата, и дописывает новые данные на диски, далее СХД ставит пометку, что данные успешно записались, после чего очищает NVLOG записи в NVRAM. Перед тем как происходит сброс новых данных на диски (всегда в новое место), снимается системный снепшот, после чего данные или записываются целиком одной транзакцией или (в случае аварии) используется ранее созданный снепшот (на уровне агрегата) как последняя рабочая версия файловой системы, в случае внезапного перезапуска СХД в середине транзакции. Если произошла авария и оба контроллера перезагрузились или потеряли питание, данные из NVRAM восстановит всю информацию и сбросят данные на диски, как только контроллеры снова включатся. Если выключится или перезагрузится только один контроллер, то второй контроллер из копии NVLOG в NVRAM сразу же восстановит данные и до запишет их, это даже произойдёт прозрачно для приложений. Когда данные таки успешно сбрасываются на диски, последний блок CP на основе старого корневого инода (снепшота) создаёт новый, включая ссылки на старые и новые, только что записанные данные.
CP — это событие, которое автоматически генерируется при одном из нескольких условий:
Кстати, состояние сброса CP, очень часто, может косвенно указывать на то, какие есть проблемы в работе СХД, к примеру когда у вас не хватает шпинделей или они повреждены.
Как уже было сказано ранее, NVRAM используется в FAS системах как хранилище лог записей, а не кэша записи, поэтому его размер, в HDD и гибридных FAS системах, не такой большой как у конкурентов. Просто в увеличении NVRAM нет необходимости. Каждая система спроектирована так, чтобы ей хватало ресурсов, для обслуживания максимального поддерживаемого числа шпинделей.
Как было уже сказано, батарейка запитывает системную память. Но она также запитывает и системный Flash-диск, установленный в контроллере. В случае пропадания электропитания, уже после этого, содержимое памяти будет слито на системный Flash-диск, так СХД может прожить очень долго в выключенном состоянии. Восстановление содержимого в память происходит автоматически при запуске СХД. Батарея выдерживает до 72 часов, в связи с чем, если питание будет восстановлено в течение этого времени, содержимое останется в кэше и восстановление из системного Flash-диска не произойдёт.
Как было сказано ранее, WAFL всегда пишет в новое место, так сделано архитектурно по множеству причин, и одна из них — это работа сброса содержимого MBUF в виде снепшота. Ведь иначе, в случае физической перезаписи блоков — новых, поверх старых, при незавершенной транзакции сброса кэша, это могло бы приводить к повреждению данных. Оказалось, что подход «записи в новое место» очень удачен не только для вращающихся дисков, и механизма снепшотов, но и для Flash технологий, из-за необходимости равномерно утилизировать все ячейки SSD дисков.
ОЗУ NetApp FAS выполняет не просто ускорение операций чтения и операций записи, но и архитектурно устроена так, чтобы обеспечивать высокую надёжность, скорость и оптимизацию для таких операций. Богатый функционал, множественная степень защиты и скорость работы системного кэша качественно отличают системы A-класса, для высоких продуктивных нагрузок и критически важных, задач.
Здесь могут содержаться ссылки на Habra-статьи, которые будут опубликованы позже.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания, дополнения и вопросы по статье напротив, прошу в комментарии.
System Memory
Память СХД любого контроллера NetApp FAS состоит из модулей оперативной памяти, которые используются для кэширования чтения, и записи, и запитаны батарейкой, отсюда приставка «NV» — Non Volatile MEMory / RAM / LOG. ОЗУ делится на следующие функциональные части: NVRAM, буфер MBUF (или системный кэш), о которых подробнее.
* Сброс данных на диски происходит из MBUF, по событию заполненности NVRAM, а не из самого NVRAM`а.
NVRAM & NVLOG
В NVRAM последовательно, наподобие LOG-записей в БД, собирается NVLOG-записи, в их изначальной форме, как они были присланы хостами. Как только данные от хоста попадают в NVRAM, хост получает подтверждение записи. После того, как произойдёт CP событие, которое генерирует сброс данных из MBUF на диски с последующим подтверждением, NVRAM очищается. Таким образом в нормально работающей СХД содержимое NVRAM никогда не читается, а только пишется, а когда место в ней заканчивается, происходит CP и NVRAM очищается. Чтение NVRAM происходит только после сбоя.
NVRAM в HA
В High Availability (HA) паре, из двух контроллеров NetApp FAS, память NVRAM всегда зазеркалирована, каждый контроллер имеет копию своего соседа. Это позволяет в случае отказа одного контроллера переключить и далее обслуживать все хосты на оставшийся в живых контроллер. После того, как произойдёт CP событие (сброс данных на диск с подтверждением), NVRAM очищается.
Если быть более точным, то каждая из этих двух частей делится ещё на две части, итого 4 для HA пары (т.е. 2 локальные). Сделано это для того, чтобы по заполнении половины локального NVRAM, сброс данных не тормозил новые поступающие команды. То есть пока происходит сброс данных из одной части локального NVRAM, новые уже поступают во вторую половину локального NVRAM.
NVRAM в MCC
Для того, чтобы обеспечить защиту данных от Split-Brain в MCC, данные, которые поступают на запись, будут подтверждены хосту только после того, как они попадут в NVRAM одного локального контроллера, его соседа и одного удалённого соседа (если MCC состоит из 4 нод). Синхронизация между локальными контроллерами выполняется через HA Interconnect (это внешнее подключение для двухконтроллерных систем в двух разных шасси), а синхронизация на удалённую ноду выполняется через FC-IV адаптеры (это тоже внешнее подключение). Эта схема позволяет выполнять переключение в рамках сайта, если второй контроллер HA пары уцелел, или переключаться на второй сайт, если все локальные ноды хранилища вышли из строя. Переключение на второй сайт происходит за секунды.
NVRAM & Pass-Through
Важно отметить что NVRAM с одной стороны технология которая есть не только на вооружении NetApp, но с другой стороны используется NetApp, для хранения логов (аппаратная реализация журналируемой файловой системы), в то время, как большинство других производителей СХД используют NVRAM на «блочном уровне» (Disk Driver level или Disk Cache) для кэширования данных в NVRAM — в этом большая разница.
Наличие NVLOG позволяет NetApp FAS не переводить в HA-паре, оставшийся в живых один единственный контроллер в режим Pass-Through (запись, без кэша, напрямую на диски) если один из них умер. Давайте немного на этом остановимся и начнём с того, зачем вообще нужен кэш записи? Кэш нужен, чтобы обманывать хосты и ускорять запись, он подтверждает запись данных до, того, как данные, на самом деле, попадают на диски. Зачем вообще переводить контроллер в режим Pass-Through, если у кэша есть батарейка, при том что у всех А-брендов СХД, есть еще и зеркалирование кэша в HA паре? Ответ не совсем просто увидеть с первого взгляда, во-первых, механизм HA заботится о том, чтобы данные были не повреждены и сбрасывались на диски при выходе из строя одного из двух контроллеров в HA-паре, а клиенты прозрачно переключались на партнёра, во-вторых, самое важное, в данном случае, чтобы данные не были повреждены на уровне структуры данных самой СХД, на этом стоит остановиться детальнее. Пересчёт чек-сумм для RAID, в памяти, давно не новинка, так как это ускоряет работу дисковой подсистемы, многие если не все А-бренды освоили этот трюк, но именно сброс данных из кэша в уже обработанном на уровне RAID виде оставляет вероятность повреждения данных, которое нельзя будет отследить и восстановить после перезапуска двух контроллеров. Так вот, при выходе из строя первого, а следом ещё и второго контроллера, может оказаться так, что нельзя отследить целостность изначально поступивших данных в следствии обработки, то есть данные могут быть повреждены, в других ситуациях отследить и восстановить повреждения возможно, но для этого необходимо запускать проверку структуры данных СХД. Так как кэш записи становится краеугольным камнем и потенциальной большой проблемой, при выходе из строя одного контроллера в НА паре, большинство СХД нужно переходить в режим PassThrough с прямой записью на диски, выключив кэш записи, чтобы устранить вероятность повреждения своей файловой структуры.
С другой стороны, большинство этих СХД позволяет вручную администратору перевести оставшийся в живых контроллер вручную, в режим кэширования записей, но это не безопасно, так как при выходе из строя второго контроллера, данные на уровне файловой структуры СХД могут быть повреждены и их придётся восстанавливать, иногда это может приводить к трагическим последствиям. Благодаря тому, что у FAS систем данные сохраняются в виде логов, а не в обработанном виде после WAFL или RAID виде, а сброс уже обработанных данных происходит в виде накатывания системного снепшота CP, единой транзакцией, это позволяет полностью обойти вероятность повреждения данных. Таким образом, во многих современных конкурирующих системах хранения, когда умирает один контроллер в HA паре, мало того, что на второй падает нагрузка от умершего контроллера, так он ещё и отключает свой кэш для оптимизации записей, что сильно ухудшает скорость работы в таких ситуациях. Делается это для того, чтобы записываемые данные таки точно были записаны в не поврежденном виде на диски, а самое важное — файловая структура СХД осталась не повреждённой. Некоторые вовсе не заморачиваются этим вопросом и просто честно пишут об этом «нюансе» в своей документации. А некоторые пытаются обойти эту проблему при помощи «костыля», предлагая покупать не 2-нодовую, а сразу 4-нодовую систему. Так, к примеру, устроена система HP 3PAR, где в случае выхода из строя одного контроллера, в 4-х нодовой системе, оставшиеся 3 контроллера будут работать в нормальном режиме записи, но в случае выхода из строя 50% нод система таки перейдёт в режим Pass-Through. Иногда бывают забавные ситуации, когда лучше, чтобы уже вся СХД умерла, нежели чтобы она работала с такими жуткими тормозами. Это контрастирует с системами FAS, которые даже в однонодовых конфигурациях никогда не отключают кэш, так как архитектурно защищены от подобных проблем.
Memory Buffer: Запись
Запись, на самом деле, всегда происходит в MBUF (Memory Buffer). А из него при помощи запроса Direct Memory Access (DMA), NVRAM выполняет копию этих данных к себе, что позволяет экономить ресурсы CPU. После чего модуль WAFL выделяет диапазоны блоков, куда будут записаны данные из MBUF, этот процесс называется Write Allocation. Модуль WAFL не просто выделяет бездумно блоки, а сначала собирает тетрис (о да, Тетрис! Вы о нём не слышали?, тогда смотрите на 28-й минуте), и выделяет пустые блоки, так, чтобы мочь записать весь тетрис на диски одним неразрывным куском.
WAFL также выполняет другие оптимизации записи для данных. После того как в модуль WAFL приходит подтверждение записи из NVRAM, данные из MBUF, согласно выделенным блокам, обрабатываются модулем RAID, где высчитывается контрольная сумма для парити дисков и высчитывается контрольная сумма, которая храниться вместе с каждым блоком (Block/Zone checksum). Важно также отметить, что данные из MBUF передаваясь в модуль RAID «распаковываются», к примеру некоторые команды могут запрашивать запись повторяющегося патерна блоков информации или запрос на перемещение блоков, такие команды сами по себе занимают не много места в NVRAM, но при «распаковке» генерируют большое количество новых данных.
Write Allocation
Это часть WAFL, которая претерпела значительные изменения от своей изначальной архитектуры устройства, особенно в плане работы новыми носителями информации и паралелизации (новая архитектура начала поставляться в 2011 году) и подготовила плацдарм для использования новых технологий хранения, которые могут появиться в ближайшем будущем. Write Allocation благодаря интеллектуальности своего устройства позволяет гранулярно писать данные разными способами и в разные места дисковой подсистемы. Каждый отдельный поток записываемой информации обрабатывается по-отдельности и может быть обработан, в зависимости от того, как данные пишутся, читаются, от размера блока и характера записи (и др.). Основываясь на характере записуемых данных WAFL, может принимать решение на какой тип носителя стоит его писать и каким именно способом. Примером тому может послужить Flash накопители, где имеет смысл писать с гранулярностью и по границам блока, по которыми происходит очистка ячеек (erase block size). В дополнение мета информация, которая занимает, обычно, на много меньше места по сравнению с самими данными может размещаться отдельно от больших блоков с полезными данными, в некоторых случаях это имеет большую выгоду, что было установленную экспериментальным способом. На самом деле описание внутреннего устройства Write Allocation это отдельная, очень большая тема.
RAID
Из модуля WAFL данные передаются в модуль RAID, который обрабатывает и записывает их одной транзакцией, страйпами на диски, в том числе и на диски чётности. А так как данные всегда пишутся страйпами и всегда в новое место, данные для дисков чётности не нужно пересчитывать, они уже заранее были подготовлены для записи RAID модулем. Благодаря чему в системах FAS на практике, парити диски всегда намного меньше нагружены нежели остальные диски, что весьма контрастирует с обычной реализацией RAID 4/6. Также стоит отметить, что просчёт чек-суммы выполняется сразу для всего страйпа записываемых данных, никогда не перезаписывая данные (запись происходит на новое место), меняется только метаинформация (ссылки на новые блоки с данными). Это приводит к тому, что нет необходимости в случае перезаписи на одном из дисков считывать каждый раз информацию из остальных дисков в память и пересчитывать чек-сумму, благодаря чему системная память используется более рационально. Подробнее про устройство RAID-DP.
Тетрис выполняет IO-reduction
Тетрис — это механизм оптимизации записи и чтения, который собирает данные, в промежутке между CP (CP Time Frame), в цепочки последовательностей блоков от одного хоста, превращая мелкие блоки в более крупные последовательные записи (IO-reduction). С другой стороны, это позволяет без сложной логики включать упреждающее чтение данных. Так, к примеру, нет разницы — прочитать 5KB, или 8KB, 13KB или 16KB и т.д. Эта логика используется для упреждающего чтения. Упреждающее чтение — это форма кэширования данных, которые потенциально могут быть запрошены в будущем, следом за теми данными которые были только что запрошены. И когда становится вопрос, какие именно «лишние» блоки стоит упреждающе читать для переноса в кэш, с тетрисом, вы автоматически получаете ответ на этот вопрос: те, которые записывались вместе с запрашиваемыми данными.
Кэш для чтения
Системный кэш (MBUF) используется как для операций записи, так и для операций чтения. В кэш попадают все без исключения операции чтения, а также из него читаются только что записанные данные. Когда CPU СХД не может найти данные в системном кэше, он обращается на диски, и первое, что он делает — помещает их в кэш для чтения, а потом отдаёт хосту. Далее эти данные могут быть или просто удалены (это же кэш чтения, всё и так есть на дисках) или перемещены на уровень ниже (II уровень кэша), если таковой имеется: FlashPool (SSD диски, кэш на чтение-запись) или FlashCache (PCIe Flash карта, только кэш на чтение). Во-первых, системный кэш, как первого, так и второго уровня, вытесняется очень гранулярно: т.е. может вытесняться 4 KB блок информации. Во-вторых, системный и кэш II уровня, он deduplication-aware, т.е. если такой блок продедуплицирован или клонирован, он не будет снова копироваться и занимать в памяти пространство. Это существенно улучшает производительность за счёт увеличения попадания в кэш. Так происходит тогда, когда набор лежащих на СХД данных может быть хорошо продедуплицирован или множество раз клонирован, к примеру, в среде VDI.
Consistency Point
Как и многие современные файловые системы, WAFL является журналируемой файловой системой. Как и любая журналируемая файловая система, журнал с лог-записями используется для того, чтобы обеспечить консистентность и её неповрежадемость на уровне СХД. В то время как все остальные реализации журналируемых файловых систем устроены таки образом, чтобы при повреждении мочь откатиться к консистентному состоянию (необходимо выполнить проверку и восстановление) и попытаться восстановиться, WAFL устроена таким образом, чтобы при внезапном отказе контроллеров не допустить самого повреждения. Это достигается благодаря, во-первых, атомарности записи Consistency Point, во-вторых благодаря применению системных снепшотов при операциях записи.
Технология снепшотирования NetApp оказалась на столько удачной, что она используется в ONTAP буквально повсюду, как базис, для многих других свойств и функций. Напомню, что в CP — содержатся данные, уже обработанные WAFL и RAID. CP — это тоже снепшот, который перед тем, как происходит сброс содержимого из системной памяти (после обработки модулями WAFL и RAID), СХД снимает системный снепшот с агрегата, и дописывает новые данные на диски, далее СХД ставит пометку, что данные успешно записались, после чего очищает NVLOG записи в NVRAM. Перед тем как происходит сброс новых данных на диски (всегда в новое место), снимается системный снепшот, после чего данные или записываются целиком одной транзакцией или (в случае аварии) используется ранее созданный снепшот (на уровне агрегата) как последняя рабочая версия файловой системы, в случае внезапного перезапуска СХД в середине транзакции. Если произошла авария и оба контроллера перезагрузились или потеряли питание, данные из NVRAM восстановит всю информацию и сбросят данные на диски, как только контроллеры снова включатся. Если выключится или перезагрузится только один контроллер, то второй контроллер из копии NVLOG в NVRAM сразу же восстановит данные и до запишет их, это даже произойдёт прозрачно для приложений. Когда данные таки успешно сбрасываются на диски, последний блок CP на основе старого корневого инода (снепшота) создаёт новый, включая ссылки на старые и новые, только что записанные данные.
События генерирующие CP
CP — это событие, которое автоматически генерируется при одном из нескольких условий:
- Прошло 10 секунд
- Заполнилась половина NVRAM
- Запущена команда останова контроллера (Halt)
- Другие.
Кстати, состояние сброса CP, очень часто, может косвенно указывать на то, какие есть проблемы в работе СХД, к примеру когда у вас не хватает шпинделей или они повреждены.
Почему размер NVRAM не всегда важен?
Как уже было сказано ранее, NVRAM используется в FAS системах как хранилище лог записей, а не кэша записи, поэтому его размер, в HDD и гибридных FAS системах, не такой большой как у конкурентов. Просто в увеличении NVRAM нет необходимости. Каждая система спроектирована так, чтобы ей хватало ресурсов, для обслуживания максимального поддерживаемого числа шпинделей.
Батарейка и Flash-диск
Как было уже сказано, батарейка запитывает системную память. Но она также запитывает и системный Flash-диск, установленный в контроллере. В случае пропадания электропитания, уже после этого, содержимое памяти будет слито на системный Flash-диск, так СХД может прожить очень долго в выключенном состоянии. Восстановление содержимого в память происходит автоматически при запуске СХД. Батарея выдерживает до 72 часов, в связи с чем, если питание будет восстановлено в течение этого времени, содержимое останется в кэше и восстановление из системного Flash-диска не произойдёт.
SSD и WAFL
Как было сказано ранее, WAFL всегда пишет в новое место, так сделано архитектурно по множеству причин, и одна из них — это работа сброса содержимого MBUF в виде снепшота. Ведь иначе, в случае физической перезаписи блоков — новых, поверх старых, при незавершенной транзакции сброса кэша, это могло бы приводить к повреждению данных. Оказалось, что подход «записи в новое место» очень удачен не только для вращающихся дисков, и механизма снепшотов, но и для Flash технологий, из-за необходимости равномерно утилизировать все ячейки SSD дисков.
Выводы
ОЗУ NetApp FAS выполняет не просто ускорение операций чтения и операций записи, но и архитектурно устроена так, чтобы обеспечивать высокую надёжность, скорость и оптимизацию для таких операций. Богатый функционал, множественная степень защиты и скорость работы системного кэша качественно отличают системы A-класса, для высоких продуктивных нагрузок и критически важных, задач.
Здесь могут содержаться ссылки на Habra-статьи, которые будут опубликованы позже.
Сообщения по ошибкам в тексте прошу направлять в ЛС.
Замечания, дополнения и вопросы по статье напротив, прошу в комментарии.
Поделиться с друзьями
Комментарии (3)

Pinkkoff
17.08.2016 13:49+2Дмитрий, большое спасибо за статью! В свое время потратил много времени, чтобы все это собрать в своей голове, другим людям теперь можно просто отправлять эту статью=)
Вообще это относится ко всем вашим статьям про NetApp, спасибо за ваш труд!

depdol
Спасибо за статью — интересно!