
Вступление
Эта статья про экспериментальный технологический стек общего назначения. Она не просто дублирует мой доклад на конференции ОдессаJS 2016, но содержит все то, что в доклад не поместилось из-за недостатка времени и исключительного масштаба темы. Я даже перезаписал доклад голосом по тексту статьи и это можно послушать, а не читать. С этой темой я уже выступил в Уханьском Университете (Китай), а в Киевском Политехническом Институте провел целую серию семинаров в 2015-2016 годах. Основная идея состоит в том, что проблемы фрагментации технологий могут быть решены, если спроектировать весь технологический стек, сконцентрировавшись на структурах данных, синтаксисе и протоколе взаимодействия компонентов. Большинство вопросов несовместимости, отпадет само собой. Пусть даже этот подход будет альтернативным и экспериментальным, но его задача будет выполнена, если он наметит путь и продемонстрирует принципиальную возможность создания простого и элегантного решения общего назначения. Эта идея является естественным продолжением подхода Node.js, когда мы сокращаем количество языков и технологий в системе, разрабатывая и клиент и сервер на JavaScript. Несмотря на экспериментальность, протокол JSTP уже используется в коммерческих продуктах, например, для интерактивного телевидения компанией SinceTV, где позволяет подключить одновременно десятки миллионов пользователей. Это решение получило приз за инновации в области телевидения на международном конкурсе Golden Panda Awards 2015 в Ченду (Китай). Есть внедрения в сфере управления серверными кластерами, готовятся решения для медицины, интерактивных игр, электронной торговли и услуг.
Выступление
Добрый день, меня зовут Тимур Шемсединов, я архитектор SinceTV, автор Impress Application Server для Node.js, научный сотрудник НИИ Системных Технологий и преподаватель КПИ. Сегодняшняя тема не столько про ноду, а скорее про развитие той идеи, которая легла в основу ноды.
Каждый, кто разрабатывал приложения не только для веба, может легко сравнить стройность технологического стека, объемы возникающих проблем и, в конечном счете, скорость разработки, с аналогичными по сложности проектами для мобильных устройств или оконных приложений для десктопов, для суперкомьпьютеров или встраиваемой техники, программирование для серверов и промышленной автоматизации, обработки данных или другими отраслями применения программирования.
Каждый шаг в вебе — это борьба, каждая минута — боль, каждая строчка — компромисс или заплатка. В интернете множество статей о том, что хаос захлестнул ветхий веб и хорошие специалисты тратят недели на простейшие задачи, как то — подвинуть кнопочку на 3 пикселя вверх или поймать блуждающий баг в зоопарке браузеров. Например статья с Медиума «I’m a web developer and I’ve been stuck with the simplest app for the last 10 days» переведенная на Хабре «Я веб-разработчик и уже 10 дней не могу написать простейшее приложение».
В чем же проблема? Как мы можем ее выявить и осознать? Есть ли другие пути? И можем ли мы двигаться эволюционно, а не революционно, решая проблемы частями? Об этом и пойдет речь дальше, и в целой серии докладов и статей, которые готовлю я и весь наш коллектив, и к обсуждению которых я Вас приглашаю.
Ветхий веб действительно погрузился в состояние, в котором все решения временные, нет ничего стабильного и живущего без исправлений более года. Если просто оставить систему без изменений, то она быстро придет в негодность. Это происходит из-за множества зависимостей, которые разрабатывались в разное время и разными людьми, никогда не предполагавшими, что эти программные модули будут использоваться вместе. Все в ветхом вебе создавалось случайно, без единого плана, а следовать стандартам не собираются доже их авторы. Это глобальная фрагментация технологий, иначе и быть не могло, но сейчас мы уже видим ошибки проектирования, примеры успеха и аналоги во вне веба, и я хочу предложить достаточно простой путь решения. Путь этот не сломает всю Вашу жизнь, но все же достаточно радикален, чтобы быть воспринятым без потрясений.
Представьте, что мы откажемся от HTTP, HTML, CSS, DOM, URL, XMLHttpRequest, AJAX, JSON, JSONP, XML, REST, Server-Sent Events, CORS, Cookie, MIME, WebSocket, localStorage, indexedDB, WebSQL, и всего остального, кроме одной вещи, мы оставим JavaScript и сделаем из него абсолютно все, что необходимо для разработки приложений. На первый взгляд это может показаться странным, но дальше я покажу, как мы это сделаем. Это будет целостный технологический стек на одном лишь JavaScript и вам это понравится. Мы конечно будем привлекать другие технологии для создания среды исполнения приложений, но от разработчика приложений все эти внутренности будут скрыты.
Итак, начнем проектировать экспериментальный технологический стек с того, что очертим широкий круг его применения, который и определит набор технологий и требования к ним. Мы рассмотрим общепринятые пути реализации и выявим их критические недостатки, после чего подумаем над возможными вариантами замены.
Мы хотим разрабатывать прикладное программное обеспечение для информационных систем в таких сферах: бизнес, экономика, образование, медицина, корпоративные информационные системы и организационно-управленческие системы, электронная торговля, персональная и групповая коммуникация, социальные сети, игровые приложения, телевидение и другие средства массовой информации.
Эти системы должны быть:
- распределенными (включающими в себя много клиентских терминальных устройств и много серверов),
- высоконагруженными (потенциально масштабируемыми для работы с миллиардами одновременно подключенных пользовательских устройств),
- интерактивными (поддерживающими двухстороннюю интерактивность, приближенную к реальному времени),
- безопасными (одновременно анонимными и обеспечивающими достаточный уровень идентификации и доверия для отдельных операций),
- гибко изменяющимися (модифицирующими экраны, функции и структуры данных на лету, без переустановки и перезапуска).
При помощи каких технологий мы можем сегодня разрабатывать такие приложения, перечислим:
- оконные и локально установленные приложения (для Linux, MacOS, Windows) с использованием AWT, SWING, WinForms, WPF, Qt и т.д.
- мобильные приложения (iOS, Android, и другие)
- веб-приложения, в том числе и адаптированные для мобильных версий браузеров
- Progressive Web App (полноэкранные приложения запускаемые в скрытом браузере)
- NW.js и Electron
Другими словами, одно и то же приложение приходится реализовывать несколько раз на разном технологическом стеке, для разных операционных систем и мобильных платформ. Один и тот же интерфейс, одни и те же функции нужно не только реализовать несколько раз, но и вносить изменения синхронно, поддерживая все клиентские приложения в актуальном состоянии. Для веба же наоборот, одно приложение, но оно тянет за собой карманный браузер со всем его стеком технологий, протоколами, рендерером и проблемами.
Веб мог бы быть решением для кросплатформенности, но какой набор технологий мы имеем в ветхом вебе:
Начнем с HTTP. Думаю, ни для кого не секрет, что он блокирующий, т.е. через одно соединение, которое браузер установил, может быть одновременно отправлен только один запрос на сервер и соединение ждет, пока сервер ответит. Потому, что в HTTP нет нумерации запросов, просто обычной, примитивной, самой простой нумерации нет и открытое соединение ожидает. Ведь если послать второй запрос, то получив ответ, будет не ясно, это ответ на первый запрос или на второй. Не говоря уже про передачу ответа частями, которые смешались бы. Но при загрузке приложения нужно сделать много запросов и браузер устанавливает второе соединение для второго запроса, потом третье… В большинстве браузеров это число ограничено 6 одновременными соединениями, т.е. сделать больше параллельных запросов нельзя, ни для загрузки статики, ни для AJAX. Если конечно не соорудить костыль, создать множество поддоменов и разбрасывать запросы на поддомены, ведь ограничение на 6 соединений у браузера привязано именно к хосту. Но эти десятки и сотни соединений неэффективно используют сеть.
Вообще TCP предполагает надежную доставку и долгосрочное взаимодействие, но HTTP разрывает связь очень часто, он просто не умеет эффективно переиспользовать уже установленные соединения и постоянно их разрывает и создает новые. Есть конечно Keep Alive, но мало того, чтобы он был специфицирован, его должны поддерживать веб-сервер, браузер, и разработчики должны о нем знать, правильно формировать заголовки и обрабатывать их. Обычно чего-то не хватает, то админ без руки, то разработчики не слышали про такую возможность, да и браузеры имеют особенности, как оказалось, и Keep Alive работает очень не эффективно, из-за отхода от спецификации сервер часто не может договориться с браузером и соединение не переходит в Keep Alive режим. Я об этом уже делал доклад и писал статью год назад "Как исправить ошибку в Node.js и нечаянно поднять производительность в 2 раза" Поведение HTTP можно проследить в средствах для разработчика, которые есть в браузере. Оптимизация в HTTP это отдельная задача, из коробки ее нет да и всем безразлично.
Установление TCP соединения это тяжелая задача, она дольше, чем передача информации по уже открытому сокету. А в добавок к TCP, при установлении новых соединений HTTP повторно присылает заголовки, в том числе cookie. А мы знаем, что заголовки HTTP не жмутся gzip, вместе с cookie в крупных проектах ходят десятки и сотни килобайт заголовков. Каждый раз, а у беззаботных людей еще и статика вся гетается с отправкой cookie в каждом запросе. Всем же безразлично.
У HTTP очень много проблем, их пробовали решать при помощи Websocket, SSE, SPDY, HTTP/2, QUIC но все они зависят от бесчисленного множества вещей, которые достались в наследство от ветхого веба и ни одна из этих технологий не достигла ни приемлемых характеристик, ни широкой поддержки. Уплотнить уже имеющийся трафик, сделать мультиплексацию внутри другого транспорта можно, но структура трафика не изменится, это будут все те же HTML, AJAX, JSON, ведь задача стояла, починить транспорт так, чтобы ничего не сломалось и чрез него продолжали ходить все те же приложения. А вот не достигнута цель, все сложно, не внедряется это массово и прирост в скорости не очень ощутим при внедрении. Кардинально и комплексно ни кто не пробовал решить проблему.
Для игр, мессенджеров и других интерактивных приложений сейчас есть только один живой вариант — это Websocket, но этот слоеный пирог из протоколов достиг предела. IP пакетный, на его основе TCP потоковый с установлением долгих соединений, сверху HTTP — он опять пакетный с постоянным отключением и поверху Websocket — и он потоковый, с долгими соединениями. А еще все это через SSL может идти. И каждый слой добавляет свои заголовки и преобразовывает данные, особенно при переходе от пакетного к потоковому и от потокового к пакетному. Это похоже на издевательство, честное слово.
Поэтому игры и мессенджеры часто не имеют достаточной интерактивности, оно подглючивают, нет нужной отзывчивости в доставке, много накладных расходов и задержек, да и пропускной способности нужной добиться не так просто. Вот интерактивные приложения и завязли в развитии, особенно благодаря тому, что нет в широком доступе хороших средств прозрачного масштабирования вебсокетов на десятки миллионов одновременных соединений. Каждый, кому нужно выйти за пределы десятков тысяч соединений, уже делает это для себя сам, хорошего рецепта нет.
Пора признать, что HTTP, полон проблем и костылей, он спроектированный полуграмотными в ИТ физиками CERNа, которые полезли не в свою специальность, в прошлом веке для передачи статей, снабженных ссылками, и ни как не подходит для приложений, тем более для интерактивных приложений с интенсивным обменом данными.
HTML это конечно прекрасный язык для разметки страниц, но менее всего приспособленный для сложных пользовательских графических интерфейсов. Скорость работы DOM и отсутствие транзакционности в изменении интерфейсов приводят к залипанию веб-приложений. Сложно придумать что-то более избыточное и медленное для представления пользовательских интерфейсов в памяти и динамической модификации экранов. Это решается в Shadow DOM, React, Angular, Web components но проблем все еще больше, чем решений.
Еще немного про масштабирование. REST, который обещал всем прозрачное решение, вместо этого забрал возможность работать с состоянием, и не сделал обещанного. Мы имеем ситуацию, когда ни кто не использует REST, да ладно, мало кто понимает, что это, но все говорят, что у них REST API. URLы идентифицируют объекты или методы? PUT, PATCH и DELETE используются? Последовательность вызовов API не важна? У кого через REST работают платежи, корзина, чат, напоминания? В основном у всех AJAX API, которое так и нужно называть. А проблема с масштабирование как была, так и решается каждый раз заново.
Проблем слишком много для того, чтобы вдаваться дальше в подробности, давайте кратким списком теперь подытожим основные:
- Платформы для прикладных программных систем фрагментированы
- Архаичные веб технологии уже нас не удовлетворяют
- Фреймворки и инструменты тотально нестабильны и несовместимы
- Протоколы ветхого веба имеют большую избыточность и убивают производительность ваших серверов
- Сплошные проблемы безопасности и заплатки
В результате наше ПО быстро устаревает, мы получаем постоянные проблемы с интеграцией систем. Мы не имеем возможности использовать наши наработки, переиспользование кода крайне усложнено, мы обречены на сизифов труд, постоянно переделывать одно и то же.
Что же нам нужно:
- Среда исполнения приложений для серверов
- Среда исполнения приложений для пользовательских компьютеров
- Среда исполнения приложений для мобильных устройств
- Межпроцессовое взаимодействие по принципам RPC и MQ с поддержкой интроспекции, потоков событий и потоковой передачи двоичных данных
- Система управления базами данных с глобальным пространством адресации, распределенностью и шардингом из коробки
- Новые соглашения по именованию и идентификации данных и пользователей
Это уже не сеть веб-страниц, а сеть приложений и баз данных.
И теперь я покажу, что это возможно. Не утверждаю, что нужно делать именно так, но принципиальную возможность на прототипе наша команда продемонстрирует.
Metarhia — это новый технологический стек, который:
- экспериментальный (только для демонстрации нового подхода),
- альтернативный (не должен заботиться о совместимости),
- в открытом коде (можно свободно распространять и бесплатно применять даже в коммерческих проектах, можно участвовать в разработке и отправлять запросы на доработку в сообщество).
Теперь давайте ближе к JavaScript, у него же есть прекрасный синтаксис описания структур данных, включающий хеши, массивы, скалярные величины, функции и выражения. А нам нужен универсальный сетевой протокол, который бы соответствовал структурам данных языка и исключал бы излишнюю перепаковку данных. Нам нужен сквозной протокол и он же формат сериализации, один на весь стек технологий, в базе данных, в памяти клиента, в памяти сервера и при передаче между процессами. Так зачем же нам JSON, XML, YAML и прочие, если таким форматом может быть подмножество языка JavaScript. При этом мы не выдумываем ни какого стандарта, ни какой формальной граматики, у нас уже есть все. По большому счету, заготовки для парсеров уже реализованы на всех языках и платформах. Более того, если мы возьмем V8 и заставим его быть парсером сетевых пакетов, то получим статистическую оптимизацию, скрытые классы и на порядок более быстрый парсинг, чем JSON. Тесты производительности я опубликую позже, чтобы не перегружать этот, и так объемный, доклад.
Пусть протокол станет центральным стержнем, на который цепляются все компоненты системы. Но протокола мало, нам нужна среда запуска, как клиентская, так и серверная. Развивая идеи Node.js, мы хотим, чтобы не только язык, но и среда запуска была почти идентичной на сервере и на клиенте. Одинаковое API, которое дает возможность обращаться к функциям платформы, например к сети, файловой системе, устройствам ввода/вывода. Конечно же, это API не должно быть бесконтрольно доступным приложениям, а обязано иметь ограничения безопасности. Область памяти и файловая система должны быть виртуальными, замкнутыми песочницами, не имеющими сообщения с остальной средой запуска. Все библиотеки должны подгружаться не самими программами, а внедряться средой запуска как DI через инверсию управления (IOC). Права приложений должны быть контролируемы, но не должна происходить эскалация управления до пользователя, потому, что он не способен принять адекватного решения по правам доступа. Пользователь склонен или запрещать все, руководствуясь паранойей или разрешать все, руководствуясь беспечностью.
Еще нам нужна СУБД, которая будет хранить данные в том же формате JavaScript. Нам нужен язык описания моделей (или схем) данных. Нам нужен язык запросов к структурам данных. В качестве синтаксиса этих двух языков запросов мы можем взять тот же синтаксис JavaScript. И в конце концов нам нужен язык описания интерфейсов двух видов, сетевых интерфейсов API и пользовательских интерфейсов GUI. Подмножество того же JavaScript прекрасно нам подходит для обоих целей.
Теперь можем перечислить компоненты технологического стека Metarhia:
- JSTP — JavaScript Transfer Protocol
- Impress Application Server — сервер приложений, серверная среда исполнения
- GS — Global Storage — глобально распределенная система управления базами данных
- Console — браузер приложений, тонкий клиент или среда исполнения приложений
JavaScript Transfer Protocol это не только формат представления данных, но и протокол, который имеет специальные конструкции, заголовки, пакеты, разделители, в общем, все то, что обеспечивает реализацию прозрачного для приложений взаимодействия по сети. JSTP объединяет клиентскую и серверную часть так, что они становятся одним цельным приложением. Можно расшаривать интерфейсы и делать вызовы функций совершенно так же, как если бы функции находились локально. С единственным ограничением, что локально функции могут быть синхронные и асинхронные, а расшаренные по по сети функции всегда асинхронные, т.е. возвращают данные не через return, а через callback, который принимают последним аргументом, как это принято в JavaScript. Так же JSTP поддерживает трансляцию событий по сети, обернутую в сетевой аналог EventEmitter. У JSTP много возможностей, но сейчас приведу только основные его особенности и преимущества:
- Встроенная поддержка интерактивности (поддержка событийно-ориентированного взаимодействия),
- Простой и понятный известный всем формат (не нужно придумывать еще одного стандарта сериализации),
- Асинхронность вызовов (не блокирующий принцип использования одного соединения с мультиплексацией),
- Двунаправленное взаимодействие, максимально приближенное к реальному времени,
- Реактивный принцип взаимодействия (код в реактивном стиле может быть распределенным),
- Оптимизация парсинга сетевых пакетов при помощи механизма скрытых классов V8,
- Использованием метаданных, моделей (схем данных), интроспекции и скаффолдинга.
Теперь подробнее о последнем пункте. Метаданные позволят нам не только сделать систему гибче, но и оптимизировать ее еще дополнительно, кроме того, что мы уже используем оптимизацию V8 для парсинга JSTP. В большинстве форматов сериализации имена полей тоже передаются, в JSON они занимают по грубым оценкам от 20% до 40% от всего объема передаваемых данных, в XML этот процент гораздо выше половины. Имена полей нужны только для мнимой человекочитаемости, хотя как часто люди читают XML или JSON? Для JSTP есть два варианта сериализации, это полная форма и сокращенная, построенная на базе массивов с позиционных хранением ключей. Другими словами, мы один раз передаем схему, имена полей, их типы, другие вспомогательные метаданные из которых на клиенте строим прототип. Потом мы получаем множество экземпляров объектов, сериализованных в массивы, т.е. имена полей не передаются, а структура массива позиционно соответствует структуре прототипа, у которого определены геттеры и сеттеры. Мы просто присваиваем массиву прототип, он остается массивом, но мы можем работать с этим экземпляром, через имена полей. Пример концептуального кода тут: metarhia/JSQL/Examples/filterArray.js
Скаффолдинг и интроспекция применяется при построении прозрачного соединения между клиентом и сервером (и вообще между любыми процессами, двумя серверами или двумя клиентами). При подключении мы забираем метаданные, описывающие расшаренные интерфейсы с методами и их параметрами и строим на противоположной стороне прокси, структурно повторяющие удаленное API. Такой прокси можно использовать локально, работая на самом деле с удаленным интерфейсом. Для работы с предметной областью применяется метапрограммирование и динамическая интерпретация метамоделей, о чем я уже делал много статей и докладов (еще за 2014 год и даже за 2012 год), но обязательно подготовлю материалы о метапрограммировании в новом технологическом стеке.
Теперь становятся понятными основные идеи технологического стека Metarhia и JSTP, как его базовой составляющей:
- Фокус на структурах данных, а не на алгоритмах,
- Минимизация трансформации данных: один формат для постоянного хранения данных на диске или в базе данных, представления данных в оперативной памяти на сервере и клиенте, сериализации и протокола для передачи по сети, для описания схем данных, для описания пользовательских интерфейсов, для языка запросов к данным, для интеграции и обмена данными между приложениями и системами.
Как говорит Линус Торвальдс: "Плохие программисты беспокоятся о коде. Хорошие программисты беспокоятся о структурах данных". А Эрик Рэймонд выразил это еще точнее "Умные структуры данных и тупой код работают куда лучше, чем наоборот".
Теперь короткие примеры JSTP:
- Сериализация структуры данных: { name: 'Marcus Aurelius', birth: '1990-02-15' }
- Полная сериализация объекта: { name: 'Marcus Aurelius', birth: '1990-02-15', age: () => {...} }
- Метаданные: { name: 'string', birth: 'Date' }
- Краткая позиционная сериализация: ['Marcus Aurelius','1990-02-15']
- Сетевой пакет: { call: [17, 'interface'], method: ['Marcus Aurelius', '1990-02-15' ] }
Сравним описание одних и тех же данных на XML, CLEAR, JSON и JSTP:
<oilPump name="PT004" displacement="constant" value="63" control= "automatic" status="working">
<flowMeter substance="fluid" recording="off" role="master" period="00:30" dataOutput="Parent.FT002.Verification"/>
<outlet pressure="180" status=working"/>
<failureSensors>
<row><module>Seatings</module><indication>none</indication>
<status>OK</status></row>
<row><module>Flap01</module><indication>open</indication>
<status>OK</status></row>
<row><module>Flap02</module><indication>closed</indication>
<status>overload</status></row>
<row><module>Joint</module><indication>detach</indication>
<status>OK</status></row>
</failureSensors>
</oilPump>1: PT004:OilPump Displacement[constant] Value[63] Control[automatic] Status[working]
2: #FlowMeter Substance[fluid] Recording[off] Role[master] Period[00:30] DataOutput[Parent.FT002.Verification]
2: #Outlet Pressure[180] Status[working]
2: #FailureSensors:Table [Module,Indication,Status]
3: [Seatings,none,OK]
3: [Flap01,open,OK]
3: [Flap02,closed,overload]
3: [Joint,detach,OK]{
"name": "PT004",
"type": "OilPump",
"displacement": "constant",
"value": 63,
"control": "automatic",
"status":"working",
"flowMeter": {
"substance": "fluid",
"recording": "off",
"role": "master",
"period": "00:30",
"dataOutput": "Parent.FT002.Verification"
},
"outlet": {
"pressure": 180,
"status": "working",
"failureSensors": [
["Module", "Indication", "Status"],
["Seatings", "none", "OK"],
["Flap01", "open", "OK"],
["Flap02", "closed", "overload"],
["Joint", "detach", "OK"]
]
}
}{
name: "PT004",
type: "OilPump",
displacement: "constant",
value: 63,
control: "automatic",
status:"working",
flowMeter: {
substance: "fluid",
recording: "off",
role: "master",
period: "00:30",
dataOutput: "Parent.FT002.Verification",
},
outlet: {
pressure: 180,
status: "working",
failureSensors: [
["Module", "Indication", "Status"],
["Seatings", "none", "OK"],
["Flap01", "open", "OK"],
["Flap02", "closed", "overload"],
["Joint", "detach", "OK"]
]
}
}Пример JSTP минимизированный с применением схемы данных:
["PT004","OilPump","constant",63,"automatic","working",
["fluid","off","master","00:30","Parent.FT002.Verification"],
[180,"working",[["Module","Indication","Status"],
["Seatings","none","OK"],["Flap01","open","OK"],
["Flap02","closed","overload"], ["Joint","detach","OK"]]]]А теперь внимание, самый простой парсер JSTP на Node.js выглядит так:
api.jstp.parse = (s) => {
let sandbox = api.vm.createContext({});
let js = api.vm.createScript('(' + s + ')');
return js.runInNewContext(sandbox);
};всего 5 строк, а его использование простое и очевидное:
api.fs.readFile('./person.record', (e, s) => {
let person = api.jstp.parse(s);
console.dir(person);
});Теперь посмотрим более сложный пример JSTP, имеющий функции и выражения:
{
name: ['Marcus', 'Aurelius'].join(' '),
passport: 'AE' + '127095',
birth: {
date: new Date('1990-02-15'),
place: 'Rome'
},
age: () => {
let difference = new Date() - birth.date;
return Math.floor(difference / 31536000000);
},
address: {
country: 'Ukraine',
city: 'Kiev',
zip: '03056',
street: 'Pobedy',
building: '37',
floor: '1',
room: '158'
}
}Как видно, функции могут обращаться к полям самого объекта, но для этого нужно немного модифицировать парсер:
api.jstp.parse = (s) => {
let sandbox = vm.createContext({});
let js = vm.createScript('(' + s + ')');
let exported = js.runInNewContext(sandbox);
for (let key in exported) {
sandbox[key] = exported[key];
}
return exported;
};Моя команда разработчиков и независимые разработчики готовят сейчас JSTP SDK для более чем десятка языков, а для некоторых есть уже несколько альтернативных реализаций. Тестирование функциональности и производительности JSTP мы проведем в ближайшее время. На странице спецификации внизу есть собранные ссылки, но не все, ссылки будут обновляться: https://github.com/metarhia/JSTP
Сейчас есть такие реализации:
- JavaScript для Browserа
- JavaScript для Node.js и Impress Application Server
- C and C++ for STL and Qt
- Swift and Objective-C for iOS
- Java for Android and JavaEE
- C# for .NET
- Python, Haskell, PHP, GoLang
Ссылки
- Metarhia https://github.com/metarhia
- JSTP https://github.com/metarhia/JSTP
- Impress https://github.com/metarhia/Impress
- Global Storage https://github.com/metarhia/GlobalStorage
- Console https://github.com/metarhia/Console
Заключение
А в следующий раз я расскажу про другие компоненты стека технологий. Несмотря на кажущуюся простоту решений, сделать еще нужно очень много. Я обещаю периодически публиковать результаты и проводить тесты по нагрузкам и надежности, сравнение с аналогами по функциональности и эффективности. Пока я не могу рекомендовать все это к массовому внедрению, но зимой 2016-2017 мы выпустим SDK с примерами. Над этим трудится несколько десятков человек в специально созданном R&D центре в Киевском Политехническом Институте при поддержке SinceTV. Если Вы будете следить за проектом, то надеюсь, что он еще Вам пригодится. Даже частичное внедрение уже дало свои результаты. Спасибо за Ваше внимание.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (90)
Scf
23.08.2016 10:31+7Ох уж эти теоретики. Все это уже было — и "прозрачные для приложения сетевые вызовы", и "автогенерация сетевого API по коду приложения", и "передача кода по сети". Красивые идеи, промышленные реализации — все они провалились.
Такого рода система требует упор на инкапсуляцию и обратную совместимость по API и данным. Говоря конкретно:
- сетевое API должно быть контролируемым, чтобы обеспечить обратную совместимость. Предлагаемый подход вносит слишком много факторов, влияющих на API
- то, что локальные вызовы и удаленные — это одно и то же — опасное заблуждение. Удаленные вызовы имеют свойство выполняться произвольное время, не выполняться вообще, требовать повтор запроса, при этом клиент не может знать, выполнен ли предыдущий или нет. Насколько я в курсе, пока никто не придумал унифицированную обработку ошибок, пригодную и для локальных, и для удаленных вызовов.
- передача кода по сети значительно усложняет соблюдение обратной совместимости. Никто же не знает, что этот код, пришедший от клиента, будет вызывать?
- Сетевые запросы имеют свойство "застревать" и доходить до получателя сильно позже того, как их отправили. Основные причины — использование очередей сообщений, хитрые механизмы передоставки, CQRS. Так что подход "сначала шлем модель, потом упакованные данные" — не универсален.
- Сложность. HTTP как основной протокол передачи данных прижился благодаря исключительной простоте, гибкости и расширяемости — его смогли приспособить для решения очень многих задач. Описанная в статье "универсальная платформа" может и не оказаться настолько расширяемой либо может оказаться слишком сложной для понимания массами — и что тогда?

MarcusAurelius
24.08.2016 03:32-2Предполагается передача кода по сети с сервера на клиент, ни это ли происходит при
Про обратную совместимость и прочее я уже пояснил, это экспериментальный стек.<script src="script.js"></script>Scf
24.08.2016 07:22+1а) имелось в виду взаимодействие сервер-сервер.
б) валить все недостатки архитектуры на экспериментальность стека позиция удобная, но сомнительная.
Вообще если натянуть эту статью на архитектуру клиент-сервер, то она начинает обретать смысл. Но замахиваться на большее не стоит.
qrck13
23.08.2016 10:44+10> Пора признать, что HTTP, полон проблем и костылей, он спроектированный полуграмотными в ИТ физиками CERNа, которые полезли не в свою специальность
— это конечно мощный вброс.
Если бы не эти «полуграмотные в IT физики», то возможно бы у нас вообще не было бы никакого веба. Для своего времени и своих изначальных задач HTTP более чем замечательно подходил. А то, что его стали использовать совсем по другому — это не вина «физиков CERN».MarcusAurelius
23.08.2016 10:55-5Да не их вина конечно, вот позорно, что программисты взяли эти наработки, не поправив их проблемы в самом начале, когда это было еще очень просто.

QuickJoey
23.08.2016 11:23+4непонятно, почему вы называете людей, которые пишут под железо для установок типа Compact Muon Solenoid или Atlas «полуграмотными в ИТ».
ну и момент, когда «грамотные» программисты должны были решить, что вот теперь хватит использовать старые наработки, и пора написать своё тоже удобно выбирать, глядя из будущего. а когда у тебя символьный терминал к машине на VAX/VMS с запущенным браузером lynx со статьёй по физике частиц, в которой некоторые понятия выделены гипертекстовой ссылкой, проблемы протокола не так очевидны, даже не беря в расчёт качество соединения между узлами типа ЦЕРНа, Дубны и Протвино.MarcusAurelius
23.08.2016 11:32-4Не добавить ID запросов это откровенная лажа, инженер лучше добавит лишний ID, чем не будет иметь возможности однозначной идентификации.
qrck13
23.08.2016 18:53-1Во первых HTTP 1.1 — не блокирующий протокол. Ничего не мешает клиенту отправить пачкой кучу запросов через одно и то-же соединение, а потом читать ответы по мере их прихождения. Другое дело, что в большинстве случаев чтобы понять, что нужно еще от сервера — нужно сначала получить и распарсить HTML документ. (Если вас интересует, как клиент определит где заканчивается ответ на один запрос и начинается ответ на другой — «Content-Lenght: <blah-blah>»)
Так-же никто не мешает добавить ID поверх HTTP на уровне приложения, там где оно нужно.
Я не берусь утверждать что HTTP идеален, но те недостатки которые вы ему приписываете — во многом надуманные. А реальные его недостатки должны вполне неплохо исправиться тем-же HTTP 2.0.
iqiaqqivik
23.08.2016 19:00+1никто не мешает добавить ID поверх HTTP на уровне приложения, там где оно нужно
Оно же нужно только в плохой архитектуре, деревянных велосипедах и наколенном счетчике, для защиты от накруток :)
MarcusAurelius
24.08.2016 00:53-1Поверх блокирующего протокола добавить ID, для различения ответов это шикарно. Посылаем запрос 1, ждем ответа 1, посылаем запрос 2, ждем ответ 2, класс просто.
MarcusAurelius
24.08.2016 00:51HTTP 1.1 имеет блокирующие соединения, и ограниченное их число, это одна из причин разработки HTTP/2
https://http2.github.io/faq/#what-are-the-key-differences-to-http1xqrck13
24.08.2016 01:33«ordering and blocking» означает лишь то, что если вдруг какой-то из запросов «задумается», то последующие не будут отданны пока не «продумается» тот медленный. Вы же говорите о принципиальной невозможности послать запрос пока не прочитаешь ответ на предыщий запрос. А это совершенно не так в случае с HTTP/1.1, и такой сценарий более чем возможен, более того, используется всеми современными браузерами (иначе страницы грузились бы минутами даже на гигабитном линке), т.к. разница в производительности между «послать, прочитать, только потом послать второй, прочитать, потом только послать третий...» и «послать, послать, послать, читать, читать, читать» — просто огромная.
Главное преимущество HTTP/2.0 в этом контектсе в его демультиплексировании, по сути он создает множество «индивидуальных каналов», поверх TCP сокета, по одному на каждый запрос. И ответы соответственно могут вообще приходить разными фрагментами, например 100 байт от первого запроса, 200 байт второго, потом снова 100 байт от первого, потом 300 байт от 3-его, итп.MarcusAurelius
24.08.2016 02:29Через то же HTTP 1.1 соединение нельзя послать следующий запрос, пока не вычитаешь предыдущий.
qrck13
24.08.2016 08:38+2Вот вы даже не знаете на что способен HTTP/1.1, но предлагаете его исправить.
А вот если бы вы например потрудились открыть RFC 2616 (т.е. основную спецификацию на протокол HTTP/1.1), то очень быстро бы нашли там такой абзац:
> — HTTP requests and responses can be pipelined on a connection.
> Pipelining allows a client to make multiple requests without
> waiting for each response, allowing a single TCP connection to
> be used much more efficiently, with much lower elapsed time.
Так что «полуграмотные физики CERN»-а сделали не такой уж плохой протокол. Просто современные программисты разучились читать документацию, и каждый лезет со своими костылями «я щас все исправлю». От этого и вышло, что веб — такое месиво из костылейMarcusAurelius
24.08.2016 10:27Так протокол остается блокирующим, проблема называется «head-of-line blocking», это для API совершенно не применимо, это для загрузки статики ускорит. А если через соединение отправить запрос, то до его возврата новый не отправить все равно. Pipelining позволяет отправить пачку запросов разом и так же разом ожидать на них ответ. По сути это отправка одного запроса, склеенного и получение на него одного большого ответа. Как только запрос или пачка отправлены, то соединение заблокировано до получения последнего из них. Смысл API в том, чтобы посылать запросы тогда, когда это нужно, в произвольное время.
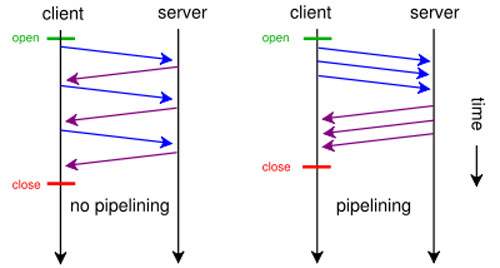

dimon_durak
24.08.2016 12:34Я тут один в мультиплексировании запросов HTTP/2 вижу костыль?
Ведь если добавить в протокол ID, то необходимости в мультиплексировании нет, зато появляются интересные возможности использования протокола, да ещё и разные, в зависимости от того, кто генерирует ID — клиент или сервер. Так ещё если и делать ID, то этож можно сделать ID функцией например, от времени и/или от uid инициатора соединения...
Мне такие возможности протокола выглядят достаточно перспективненько, в связи с чем возникает вопрос — а неужели это очень сложно — добавить в протокол идентификацию сообщений?
MarcusAurelius
24.08.2016 12:41+1Как из анекдота «чем такого лечить, проще нового сделать». Добавить не очень сложно, но они очень долго не будет поддерживаться всеми, а значит, на нее нельзя будет рассчитывать. Да и ID это только одна проблема, нужно еще объединять мелкие пакеты в один и бить большие пакеты на части, потому, что один большой ответ может забить собой соединение на долго, не пропуская маленькие ответы. Еще нужно возможность отменять долгие запросы, да вообще слишком много чего нужно.
MarcusAurelius
24.08.2016 10:33Сравните диаграммы

qrck13
24.08.2016 10:37Вы сами то поняли, что на этих картинках?
Впрочем я не буду вдаваться в объяснения в чем вы не правы. Чем больше заблуждений у вас в голове, и чем большему количеству студентов вы из внушите, тем больше будет моя ЗП.

slayerhabr
23.08.2016 23:23У Вас определенно большие проблемы в образовании.
MarcusAurelius
24.08.2016 00:37-1Аргумент, че…
slayerhabr
24.08.2016 01:33Исходя из Вашей статьи очевидно, что Вы не знаете и не понимаете принципы HTTP.
Императивные инструкции в протоколе, жестко завязанные на реализацию какого либо языка ??
Почерк архитектора! че…slayerhabr
24.08.2016 01:56+1Очень умно:
{ ... age: () => { let difference = new Date() - birth.date; while(true){new String("jstp is sh*t")}; return Math.floor(difference / 31536000000); }, ...MarcusAurelius
24.08.2016 02:26-2new vm.Script(code, { timeout: <number> });slayerhabr
24.08.2016 02:39+1Вы серьезно??
ДА Вы еще и JS не знаете!!!!111
в данном случае timeout Вам не поможет — зависнет функция в основном потоке, а не в
vm.Script
Я был не прав, у Вас не большие проблемы в образовании, а очень большие.MarcusAurelius
24.08.2016 02:49-3Попробуйте
slayerhabr
24.08.2016 03:21+2Не, Вы серьёзно???????????
/tmp $ cat jstp.js "use strict" const vm = require('vm'); var jstp = {} jstp.parse = (s) => { let sandbox = vm.createContext({}); let js = vm.createScript('(' + s + ')'); let exported = js.runInNewContext(sandbox); for (let key in exported) { sandbox[key] = exported[key]; } return exported; }; let code = "{ a: 1, age: () => { for(var i=0; i<9999999; i++){new String('jstp is sh*t')}; return a; }}" console.time("parse") var o = jstp.parse(code) console.timeEnd("parse") console.dir(o) console.time("call age()") o.age() console.timeEnd("call age()")
node jstp.js
parse: 1ms
{ a: 1, age: [Function] }
call age(): 2703ms
Картинка из Вашего профиля как бы намекает

MarcusAurelius
24.08.2016 03:24-1Где?
new vm.Script(code, { timeout: <number> });slayerhabr
24.08.2016 03:35+1ВОТ:
"use strict" const vm = require('vm'); var jstp = {} jstp.parse = (s) => { let sandbox = vm.createContext({}); let js = new vm.Script('(' + s + ')', { timeout: 1000} ); let exported = js.runInNewContext(sandbox); for (let key in exported) { sandbox[key] = exported[key]; } return exported; }; let code = "{ a: 1, age: () => { for(var i=0; i<9999999; i++){new String('jstp is sh*t')}; return a; }}" console.time("parse") var o = jstp.parse(code) console.timeEnd("parse") console.dir(o) console.time("call age()") o.age() console.timeEnd("call age()") /tmp $ node jstp.js parse: 2ms { a: 1, age: [Function] } call age(): 2782ms
Если Вы до сих пор не уловили в чем прикол — у Вас ни малейшего понимания JSMarcusAurelius
24.08.2016 03:57-2Это таймаут на парсинг, а теперь на исполнение скрипта
let exported = js.runInNewContext(sandbox, { timeout: 1000 });
Доки читайте.slayerhabr
24.08.2016 04:01+1Вы не прошибаемый. Мне жаль Ваших работодателей и Ваших студентов.
MarcusAurelius
24.08.2016 04:01-1Так че, заработало?
slayerhabr
24.08.2016 04:05+1... let exported = js.runInNewContext(sandbox, { timeout: 1000}); ... parse: 1ms { a: 1, age: [Function] } call age(): 2753ms

aqrln
24.08.2016 04:04-1Таймаут должен быть в
runInNewContext, и в JSTP он по умолчанию равен тридцати миллисекундам.MarcusAurelius
24.08.2016 04:08-2Тсс… пусть сам делает лабу, а не паленую сдает, я его уже почти обучил.
aqrln
24.08.2016 04:09Это в случае, если будет что-то вроде
(() => { while (true) /* do nothing */ ; })(). А функции с вычислимыми полями, которые вызываются позже, теоретически можно передавать, но на практике это нигде не используется сейчас, а когда будет, то естественно, что всё это будет происходить не таким кустарным способом.
flancer
24.08.2016 13:42+2Запустил код slayerhabr под node v4.2.6, указал timeout как и положено — в
runInNewContext. Имею результат
parse: 2ms { a: 1, age: [Function] } call age(): 2615ms
Никакого отвала по timeout'у не наблюдаю. Складывается впечатление, что timeout отрабатывает как минимум не всегда.
aqrln
24.08.2016 13:51+1Так потому что
age()вызывается уже послеrunInNewContext, смотрите мой комментарий выше.flancer
24.08.2016 14:09+1Т.е., получается, что выставленный timeout никакого отношения к измеренному выводу времени работы
age()не имеет? В одном случае
let js = new vm.Script('(' + s + ')', {timeout: 1000});
timeout выставляется на компиляцию кода, а в другом
let exported = js.runInNewContext(sandbox, { timeout: 1000});
на выполнение кода (т.е. на создание объекта и его метода
age()).
Выполнение же метода
ageпроисходит здесь
console.time("call age()") o.age() console.timeEnd("call age()")
и никакими timeout'ами не ограничено.
В таком случае, непонятно, что имел в виду коллега slayerhabr, демонстрируя свой пример :(
slayerhabr
24.08.2016 20:09flancer
Все очень просто — таймауты по сути ограничивают парсинг JS. выполнение JS кода они не ограничвают, т.к. функции выполняется он уже в основном контексте.
Все потому, что применение императивного кода в протоколе, как это предлагает «архитектор» — чушь и бред. Протокол по определению — декларативное понятие.
MarcusAurelius
24.08.2016 13:55-1Таймауты нужно ставить на: парсинг, исполнение кода и вызовый функций, которые из этого кода экспортируются, но все это скрыто от разработчика, делается рантаймом.
iqiaqqivik
24.08.2016 14:14+4> все это скрыто от разработчика, делается рантаймом
То есть, если мне втемяшится посчитать 100500 знаков числа ? — то я сразу вне игры, да? Потому что умный рантайм? Жгите еще.flancer
24.08.2016 14:23и в JSTP он по умолчанию равен тридцати миллисекундам.
полагаю, раз есть "по умолчанию", значит есть и явный способ задать timeout.
MarcusAurelius
24.08.2016 15:16-2Считать пи на ноде, серьезно?
iqiaqqivik
24.08.2016 15:25+3А, ну я же говорил: вы строите абстрактный инструмент в вакууме, который умеет с грехом пополам решать единственный пример, кропотливо составленный в экологически чистых условиях заботливым разработчиком по принципу «только чтобы не обрушить ни одного костыля».
aqrln
24.08.2016 16:04Почему нет? В отдельном процессе норм.
MarcusAurelius
25.08.2016 01:38-3Так в отдельном процессе на другом языке и по JSTP с ноды высылать запрос или адон на Си сделать, но в js не самая лучшая математика для алгоритмов.
aqrln
24.08.2016 16:01Считать ? в геттере — довольно странное решение, имхо. Да и написано уже выше, что вычислимые поля пока нигде в JSTP не используются, а когда/если это понадобится, это уже отдельный вопрос. Просто теоретически такая возможность заложена и когда будет должным образом реализована, API для всего этого дела останется таким же, как и сейчас. Это ж эксперименты и угар, а не продакшн-реди код, чего вы хотели ?_(?)_/?
iqiaqqivik
24.08.2016 16:14Чего я хотел? Я хотел, чтобы люди перестали использовать те инструменты, которые валялись неподалеку и стали бы использовать те, которые для решения тех или иных задач подходят. Я привел пример с ? просто как иллюстрацию: долгие геттеры родили сначала поллинг, а потом вебсокеты, а если звезды зажигают, то кому-нибудь это обязательно нужно.
Концепция «пока нигде не используются, но теоретически такая возможность заложена» носит звучное имя «premature optimization» и повсеместно — традиционно и оправданно — считается злейшим злом. Код любого проекта должен быть продакшн-реди в любой момент своей биографии, иначе это не эксперименты, и не угар, а сизифов труд. Вы делаете полезное и нужное дело, просто делаете его на базе миллиона ошибочных и вредных допущений. Я про них и рассказываю, причем за счет собственного времени, и собственной возможности комментировать записи.
И да, посмотрите хоть кто-нибудь, чем AST лучше, чем живой код, к тому же намертво привязанный к настолько несуразному языку.aqrln
24.08.2016 16:34+11. Намертво привязать всё к этому несуразному языку — это и есть основная идея, хех. NechaiDO в последнем комментарии отлично это описал копипастом одного известного твита.
2. Это не сизифов труд, а кодинг в своё удовольствие. Кто-то собирает марки, а кто-то пилит ради лулзов свои технологии. Если время и деньги на это есть, то кто может это запретить? В конце-концов, «ради лулзов» — это лучшая мотивация, которая существует в этом мире.
3. AST лучше, спору нет, но посколько JavaScript не гомоиконичен, как Lisp или какой-то Rebol, то это противоречит пункту 1. Вообще, идея передавать функции в объекте мне очень не нравится, но если же разделять данные и метаданные, и сначала передавать один раз схему данных, а затем слать лишь чистые значения без имён полей, то тогда это можно по-человечески реализовать. Методы будут передаваться лишь один раз при передаче, фактически, уже класса, и можно позволить себе такую затратную операцию, как парсинг при помощи Esprima, анализ и валидацию AST на предмет разрешённых операций. Остаётся открытым вопрос о времени исполнения, так как г-н Алан Тьюринг в своё время математически обосновал, почему одна программа в общем случае не может узнать, завершится ли другая программа и если да, то за какое время, не выполняя её, но и эта проблема решаема, если разрешено будет лишь ограниченное подмножество операций над полями и всё. Даже не факт, что циклы нужны, а если и да, то можно банально ограничить количество разрешённых итераций.iqiaqqivik
24.08.2016 17:13Вы только не подумайте, что я что-то имею против любых хобби. Я прекрасно понимаю эту мотивацию, и да, это круто. Я сам операционку пишу (шутка, конечно).
Теперь по существу. Мне кажется, поправьте, если ошибаюсь, что вас ожидают ночные кошмары с биндингами. Или сразу скажем «нет» замыканиям — и тогда сразу джаваскрипт превратится в тыкву. Или я не могу себе пока представить, как вы из песочницы в песочницу предполагаете отдавать statefull объекты.
Но ладно, ваш комментарий вернул мне надежду на то, что проект может и развиться во что-то :)aqrln
24.08.2016 18:02-1Собственно да, замыкания там не нужны. Как по мне, JSTP должен использоваться только для сериализации анемичных структур данных и единственное применения для функций там — это небольшие геттеры, буквально формулы от нескольких полей, ни в коем случае не поведение. MarcusAurelius привёл хороший пример, в котором
person.birth.date— это обычное поле, аperson.ageвозвращает возраст пользователя в момент вызова. Я вижу мало применений такой технике в прикладном коде, но для пока несуществующих GlobalStorage и JSQL это будет довольно полезная вещь.iqiaqqivik
25.08.2016 10:04+1Для реализации этого «хорошего примера» не нужно ничего, кроме тривиального лексера. MySQL все эти функции, типа `CONCAT`, реализует на коленке, и это всех устраивает.
А если выкинуть функции — получится натуральный JSONP, который уже родился, вырос и помер. Может быть, имеет смысл «откопать стюардессу» лучше уж тогда?


kostia256
23.08.2016 11:13Теперь посмотрим более сложный пример JSTP, имеющий функции и выражения:
Зачем так усложнять? Все базовые элементы системы должны быть максимально простыми и независимыми. Что мешает определить 2 класса/метода PersoneSerializer и PersoneUnserializer для вычислимых полей?
GlukKazan
21.12.2016 11:45Пока выложил только в свой репозиторий. В ближайшее время, должна появиться здесь.
Для игры необходима разлоченная Zillions of Games 2-ой версии. Просто запускается zrf-файл.
iqiaqqivik
23.08.2016 11:58+4Метаданные:
{ name: 'string', birth: '[Date]' }— вы сами не видите тут никакой проблемы? Что такого офигенно разного в строке и дате, что синтаксис вдруг напоминает реализацию стандартной библиотеки PHP 1 (кто в лес, кто по дрова)?
Ну и, самый главный вопрос, почему нельзя вот так просто взять и использовать JS? Ну ладно, подмножество JS? Coffee, чтобы из коробки получить препроцессор для построения прокси? Любой язык, кросс-компилируемый в JS? Это если отвлечься от вопроса, зачем в то время, когда все стараются избавляться от состояний везде, где только возможно — плыть против течения?
Я чего-то недопонял?
MarcusAurelius
23.08.2016 13:28-1Скобочки в Date это опечатка, спасибо, поправил. Пример концептуального кода по этому вопросу тут: https://github.com/metarhia/JSQL/blob/master/Examples/filterArray.js
iqiaqqivik
23.08.2016 14:04Скобочки в Date это опечатка, спасибо, поправил.
А capitalized
Dateи camel-/snake-/no-case (из примера неясно)string— это «мы так видим»? Фортрановое наименование переменных? Почему? Зачем?
Пример концептуального кода по этому вопросу тут
По какому вопросу? Какого кода? Отказавшись от идемпотентности вы сразу же принесли undefined behavior (один из самых трудноуловимых багов, если что) в свой пример, который предлагаете в качестве объяснения.
http://ejohn.org/blog/javascript-in-chrome/
TL;DR: This behavior is explicitly left undefined by the ECMAScript specification. In ECMA-262, section 12.6.4: “The mechanics of enumerating the properties … is implementation dependent.”
Это про
for (.. in ..)цикл, если что. Вот я куплюсь, перейду на ваш протокол, запущу стартап, а через год в хроме у меня вдруг (!) все итерируемые списки (!!) иногда (!!!) перестанут работать. Клёво, чё.MarcusAurelius
23.08.2016 14:34-2Потому, что это JavaScript, для отличения скалярных типов от объектов, встроенные типы данных пишутся с маленькой, а встроенные типы объектов в большой.
Второй вопрос: последовательность итерации ключей. Вы невнимательно читали статью, если вообще читали. Хром тут ни при чем, это не для браузеров все. Приложения на базе JSTP не будут работать в браузерах гипертекста, они запускаются в своем рантайме, который имеет встроенный парсер, работающий с порядком ключей так, как нужно нашему стеку. А пока все движки реализуют позиционное итерирование.iqiaqqivik
23.08.2016 15:00+1Не знаю уж, кто из нас поверхностнее ознакомился со статьей, но вот вроде цитата оттуда:
JSTP объединяет клиентскую и серверную часть
Вот еще одна:
среда запуска была почти идентичной на сервере и на клиенте
То ли я недопонимаю, то ли вы собираетесь свой браузер с блекджеком и супернодой внутри сделать, то ли хром имеет все возможности испортить порядок до того, как вы вообще увидите этот массив.
И, наконец, есть уже целых два языка, которые идеально подходят для вашей цели: LISP и Elixir, которые прямо из коробки оперируют AST (пока вы не поймете, что оперировать в таком вопросе можно и нужно AST, а не псевдокодом, вся эта шняга обречена). Гоняйте туда-сюда AST, допишите малюсенький кросс-компилятор в JS и танцуйте. Но нет, давайте возьмем самое убогое, что есть на планете: синтаксис JS и ноду. Есть гипотеза, что вы не очень на самом деле понимаете, чем занимаетесь. Ну или я не понимаю, такое тоже более, чем возможно.
MarcusAurelius
23.08.2016 15:06Представьте, что мы откажемся от HTTP, HTML, CSS, DOM, URL....
Конечно своя среда запуска.
MarcusAurelius
23.08.2016 15:02-1Для справедливости нужно сказать, что JavaScriptCore для iOS не поддерживает позиционного итерирования для числовых ключей.

PaulMaly
23.08.2016 14:40+4> Мы имеем ситуацию, когда ни кто не использует REST, да ладно, мало кто понимает, что это, но все говорят, что у них REST API. URLы идентифицируют объекты или методы? PUT, PATCH и DELETE используются? Последовательность вызовов API не важна? У кого через REST работают платежи, корзина, чат, напоминания? В основном у всех AJAX API, которое так и нужно называть.
Вы ошибаетесь. Много у кого вполне себе Stateless REST API, и ресурсы и методы используются вполне верно. Конечно «чистый» REST API это маловероятный вариант в реальном проекте, но все не так плохо, как вы описали точно. И уж тем более не понятен ваш термин «Ajax API», причем тут вообще AJAX? Вы в курсе, что это вообще чисто браузерная технология? Да и сам термин во многом устарел. Если бы вы назвали JSON API или HTTP API, я бы еще понял.PaulMaly
23.08.2016 17:27Ну а в целом очевидно у вас «javascript головного мозга». Сам много пишу на js, но только сейчас понял какое это все таки зло и насколько это заразно. Удачи вам с лечением!

boblenin
23.08.2016 17:55+2Прочитав заголовок — заинтересовался. Дочитав до JSTP подумал, что видимо пишет какой-то архитектор. Посмотрев на регалии автора — убедился в своей правоте.


Mithgol
23.08.2016 20:28+3Сразу изменить и протокол, и формат передачи, и серверную часть, и базу данных, и клиент-браузер.
Затея интересная, но трудоёмкая.
Предвижу также неочевидные инфраструктурные издержки (например,где-нибудь перестанет работать такой кэширующий прокси-сервер или такой анализирующий файерволл, которые ожидали видеть протокол HTTP, и в итоге кто-нибудь, например, останется с доступом к WWW, но без доступа к Метархии, или, например, скачает из Метархии вирус, хотя скачивание его из WWW было бы предотвращено файерволлом от антивирусного пакета).
Вообще смотрю на этот широкий замах с умилением. Что-то подобное, причём весьма подобное, я и сам ощущал да испытывал, задумывая гипертекстовый Фидонет. Совершенно так же смотришь на технологии многодесятилетней давности и желаешь всё в них переменить: и разметку фидотекста (устроить гипертекст), и редактор-просмотрщик (поставить фидобраузер), и формат баз фидопочты (обеспечить поддержку хотя бы SQL-подобных запросов, если не Mongo-подобных map+reduce), и эхопроцессор (чтобы он работал с этой новой базой), и фрекопроцессор (чтобы можно было запрашивать не только файлы, но и сообщения фидопочты), и мейлер (чтобы вместо прежних двоичных пакетов в жёстком формате обмениваться каким-нибудь JSON), и так далее. В итоге оказалось, что и одного только фидобраузера хватит надолго повозёхаться.
(Правда, я не располагал отделом R&D размером в десяток человек. Располагая таким отделом, много чего можно достигнуть. Желаю удачи, разумеется.)MarcusAurelius
24.08.2016 02:58+1Спасибо за поддержку, надеюсь, что редукция до одного синтаксиса много что упростит. А JavaScript уже реализован на всех платформах. Мы и язык запросов делаем вот такого толка, см. концептуальный код. Это существенно проще, чем мы делали в конце девяностых на Дэлфи, шлюз между FIDO hydra протоколом и USP over TCP. Тмыл, голдед, UUE, это все было пропитано правильным духом общения людей, но таким же нагромождением стандартов, как и ветхий веб сейчас. Сейчас я год выбирал из более чем 300 студентов политехнического ВУЗа, читал лекции, делал семинары, сидел с ними с 10 утра до 10 вечера, и теперь они сами пишут код именно так, как это делал бы я, теперь они очень эффективны, потому, что одинаково мыслят, тратя минимум времени, чтобы договориться между собой. Мы все сделаем, тов. Mithgol the Webmaster!
iqiaqqivik
24.08.2016 08:26+2Дам, пожалуй, полезный совет на будущее: выбирать в команду нужно людей, которые пишут код _по-разному_, желательно все, и — обязательно — не так, как лидер проекта. Иначе проект обречен, по той простой причине, что лидер — тоже человек, и тоже ошибается.
Выбирать людей, которые пишут так же, как я — гордыня, путь в никуда. Вы и сами законсервируетесь, и ребят законсервируете. Позовите перлиста, лисповика, эрлангиста, обсудите с ними недостатки вашей архитектуры — и тогда можно будет о чем-нибудь говорить всерьез.
MarcusAurelius
24.08.2016 10:37-2У нас: несколько сишников, несколько питонистов, несколько свифтовцев, несколько джавистов, несколько обджективсишников, по одному го и хаскелевцев.
iqiaqqivik
24.08.2016 11:21Джаваскриптовиков нет вовсе, что ли?
Мне кажется, это очень показательно, что ваш список _вообще_ не пересекается с моим. Из вашего только хаскельмена можно было бы слушать, если бы хаскель не был абсолютно академическим языком, разрабатывавшимся явно не для реализации сетевого стека.
Какую пользу в проектировании сетевого стека может принести C/Swift/ObjectiveC? В джаве работа с асинхронностью перестала быть адской болью в шестой версии (в шестой!!!!). Golang — это же COBOL 2.0™, попытка сделать програмирование доступным домохозяйкам. Ладно, питон, хотя что есть архитектурно интересного в питоне? Ну и ортогональный, повторюсь, стеку — хаскель.
А, да, js еще. То, что вы описали же — это JSONP на стероидах. Постарайтесь понять: самой идее сто лет, но вы выбрали худшее, что можно было себе представить для ее реализации. Я уже писал — повторю еще раз. Почитайте про AST и про то, почему кодом можно обмениваться между разными песочницами только через AST. Почитайте Армстронга и Вирдинга, которые сделали в свое время OTP, справляющееся до сих пор с приложениями типа WhatsApp. Сделайте стресс-тест вашего костыля на, ну не знаю, тысячах запросах в секунду (эрланг даже не поперхнется).
Пока что это все очень похоже на «так, люди пользуются очень странной хренью для забивания шурупов, какая-то железяка на палке, а вот у меня есть клевый высокотехнологичный утюг, поэтому мы сейчас приделаем палку к утюгу и станем заколачивать шурупы получившимся инструментом».
Вам хором говорят: вам не хватает знаний. Это не обидно, это нормально, всем их не хватает. Так пока вы не уперлись в то, что ваша штука работает только в тепличных условиях, обрабатывает 1 запрос в секунду и намертво зависит от решений сообщества ноды (которое, мягко говоря, не идеально, не однородно и не очень фундаментально) — оглядитесь вокруг, воспользуйтесь опытом уже ходивших по этим граблям.
А то убийц веба я на своем веку уже миллион повидал. От гораздо более сведущих авторов в том числе. А веб — вот он.

babylon
24.08.2016 16:49-1Дело же не в языке, а в том, что если они признаются, что это велосипед. Причем не лучшей конструкции. Тогда кто же им зарплату платить будет? Такие НИИ надо на корню разгонять. Люди на элементарном уровне в трех понятиях заблудились. На ноду не надо переводить стрелки. С ней всё хорошо. Нет никакого нагромождения стандартов. Наоборот. Наблюдается их дефицит. Стандарт это то, что принято большинством. Если не верите зайдите в соответствующие гугл сообщества. Я доверяю не академическим стандартам, а индустриальным. Даже на уровне идей они их обходят. Если вам с отделом нефик заняться пожалуйста сделайте JSONNET в нотации JSON и внедрите его в Tarantool. Будет песня.
iqiaqqivik
24.08.2016 17:28+1Да нет, дело в том числе и в языке тоже. Правда мне там выше объяснили, что кактус — естественный выбор дуркующего ежика, так что к ребятам вопросы на том и закончились.
Но вот только не надо говорить, что нода пригодна для чего-нибудь поднагрузочного. Не знаю, с кем вы там разговаривали про нагромождение стандартов, мой тезис гораздо проще: обеспечение сетевого стека нода банально не потянет по очень многим причинам. По крайней мере, в том состоянии, в котором она есть сейчас.
babylon
24.08.2016 18:00Я не знаю пригодна нода или нет для этого. Лично я не проверял. Предлагаю не отходить от сабжа.

Rampages
26.08.2016 04:46Это просто «юношеский максимализм» ¬(???)-
Вообще пользуюсь какой-нибудь технологией часто задумаюсь о своём «велосипеде» (? ? ? ).
Mithgol
23.08.2016 20:50+2Вновь подтверждён Закон Этвуда: «Всё, что может быть написано на JavaScript, будет написано на JavaScript».
MarcusAurelius
24.08.2016 03:09-4Кстати, так нечаянно случилось, что именно сегодня, 23 августа, 25 лет назал, другой Тим запустил ветхий веб, о чем нам рассказывает Wired, а 6 лет назад тот же Wired похоронил веб


sentyaev
23.08.2016 21:30+1Удивился даже, почему этой картинки еще нет.

MarcusAurelius
24.08.2016 00:37-3Впервые новый протокол не вводит ни одного нового синтаксиса или нового формата данных, а использует уже стандартизированный EcmaScript.
sentyaev
24.08.2016 02:36+1Да это же просто сарказм. Не принимайте на свой счет.
Я, вот например, считаю, то что вы делаете это бред, но это выглядит очень интересно. Уверен, что потрачу какое-то время на изучение проекта, или хотябы буду следить за его развитием.
Именно за это я и люблю программирование. Ненравится код — взял и переписал. Ненравится как устроен мир — создал свой.
slayerhabr
23.08.2016 23:28> Потому, что в HTTP нет нумерации запросов, просто обычной, примитивной, самой простой нумерации нет и открытое соединение ожидает.
А Вы точно архитектор? Преподаватель?
babylon
23.08.2016 23:49Тимур, ради чего было набирать или копипастить столько текста? Ради двух последних абзацев? Посмотрите в сторону msgpack.
NechaiDO
23.08.2016 23:55+7Не понимаю, почему этого еще нет:
«Один пацан писал все на JavaScript, и клиент, и сервер, говорил что нравится, удобно, читабельно. Потом его в дурку забрали, конечно.»
napa3um
Переархетиктурили, пытаясь свести все свои знания в одну «концепцию», практическая польза которой заключается только в «мне удобнее придумать своё, чем изучать чужое».
В мире существует множество шейперов данных по схемам, для этого не обязательно пытаться пересадить всех на свой протокол. Многие (наверное, большинство) систем разрабатываются не с единого плана, а по частям, разными людьми, в разное время, на разные деньги и с разными целями и ограничениями. Ваш монолит просто «не взлетит» в таких условиях без участия Главного Архитектора (вероятно, вас). Вместо описания стека попробуйте описать процесс создания и долгосрочного развития на нём приложения командой хотя бы из трёх человек, показав, какие процессы в их взаимодействии с вашим протоколом стали «дешевле» (во всех смыслах) относительно общепринятых подходов.
Evolution > revolution.