
Называть статью «Эволюция прикладных информационных систем и перспективы развития их архитектуры» было бы слишком академично, а ведь тут будет очень краткая выжимка из реального практического опыта, возможные варианты развития технологий, вызвавшие их потребности и пути решения. Я надеюсь, что статья поможет обобщить и переосмыслить широкий круг задач, связанных с прикладными ИС, и сразу хочу уточнить, что понимаю под этими терминами. ИС — это системы, обеспечивающие обработку, передачу и хранение данных. Это далеко не все программирование, но сейчас ИС чаще всего ассоциируются с веб и мобильными приложениями, хотя и не совпадают с ними полностью, знак равенства между UI и ИС нельзя ставить тем более. Очень прошу всех посмотреть на вопрос как можно шире и присоединяться к обсуждению в комментариях. И еще, я намеренно не буду использовать названия фреймворков и технологий, чтобы избежать лишних холиваров, ограничившись общепринятыми названиями архитектур, стандартов и протоколов, что и вам рекомендую в комментариях.
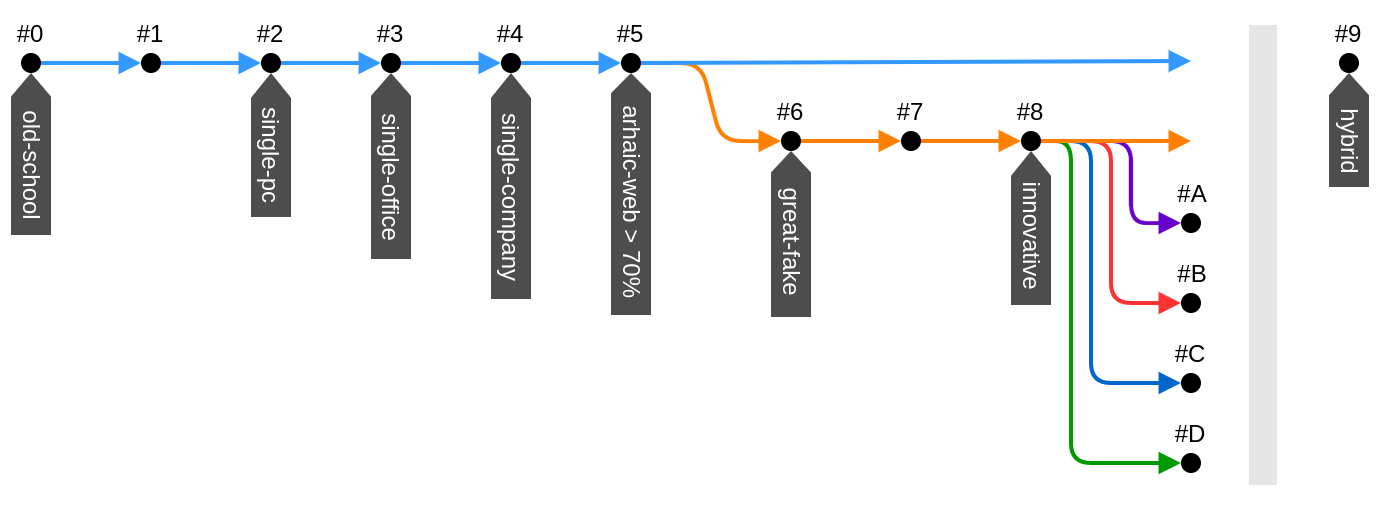
Разветвления в технологиях случались много раз в истории, но за периодом неопределенности всегда следует этап устойчивого развития, когда несущественные ветки уходят в тень, а актуальные особенности объединяются в самый жизнеспособный гибрид. Для начала мы кратко проследим, как ИС развивались с самого их появления. Чтобы воспоминания нахлынули, нам хватит всего 9 строк и картинки.
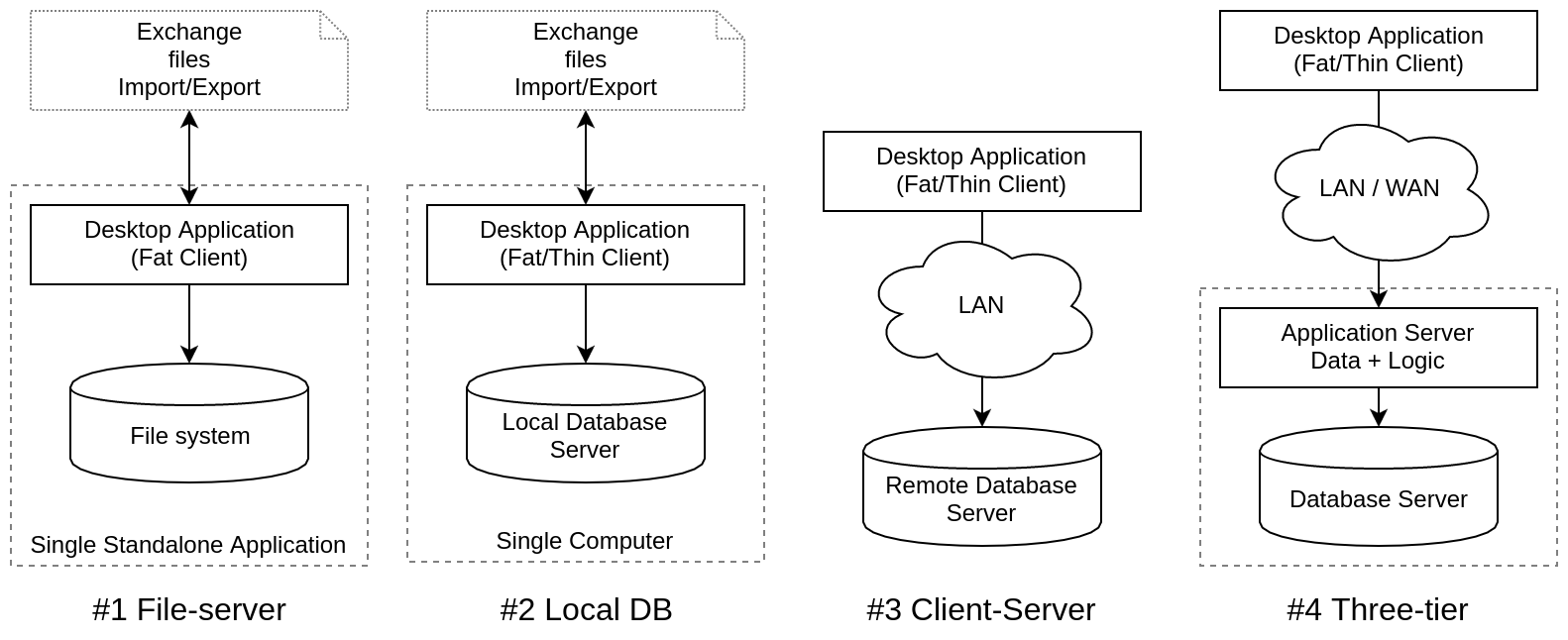
| Архитектура | Основные особенности | Обмен |
|---|---|---|
| #0 Data files | Все хранили свои данные в файлах разных неведомых форматов | файлы |
| #1 File-server | Движки БД, работающие в одном процессе с приложением | файлы |
| #2 Local DB | СУБД выделились в отдельные процессы — сервера СУБД | IPC |
| #3 Client-Server | СУБД доступны по локалке разным типам АРМов (клиентских рабочих мест) | RPC |
| #4 Three-tier | Выделился слой сервера приложений, 3-звенка, работа из удаленных офисов | RPC |
| #5 Web-client | Появились тонкие клиенты для доступа к данным из веб-браузера | HTTP |
| #6 Web 2.0 | Частичная интерактивная перезагрузка элементов через AJAX, Comet, SSE | AJAX |
| #7 SPA/WebApp | Полнофункциональные браузерные приложения без перезагрузки страниц | AJAX |
| #8 PWA & Mobile | Progressive Web Application и мобильные приложения | HTTPS |
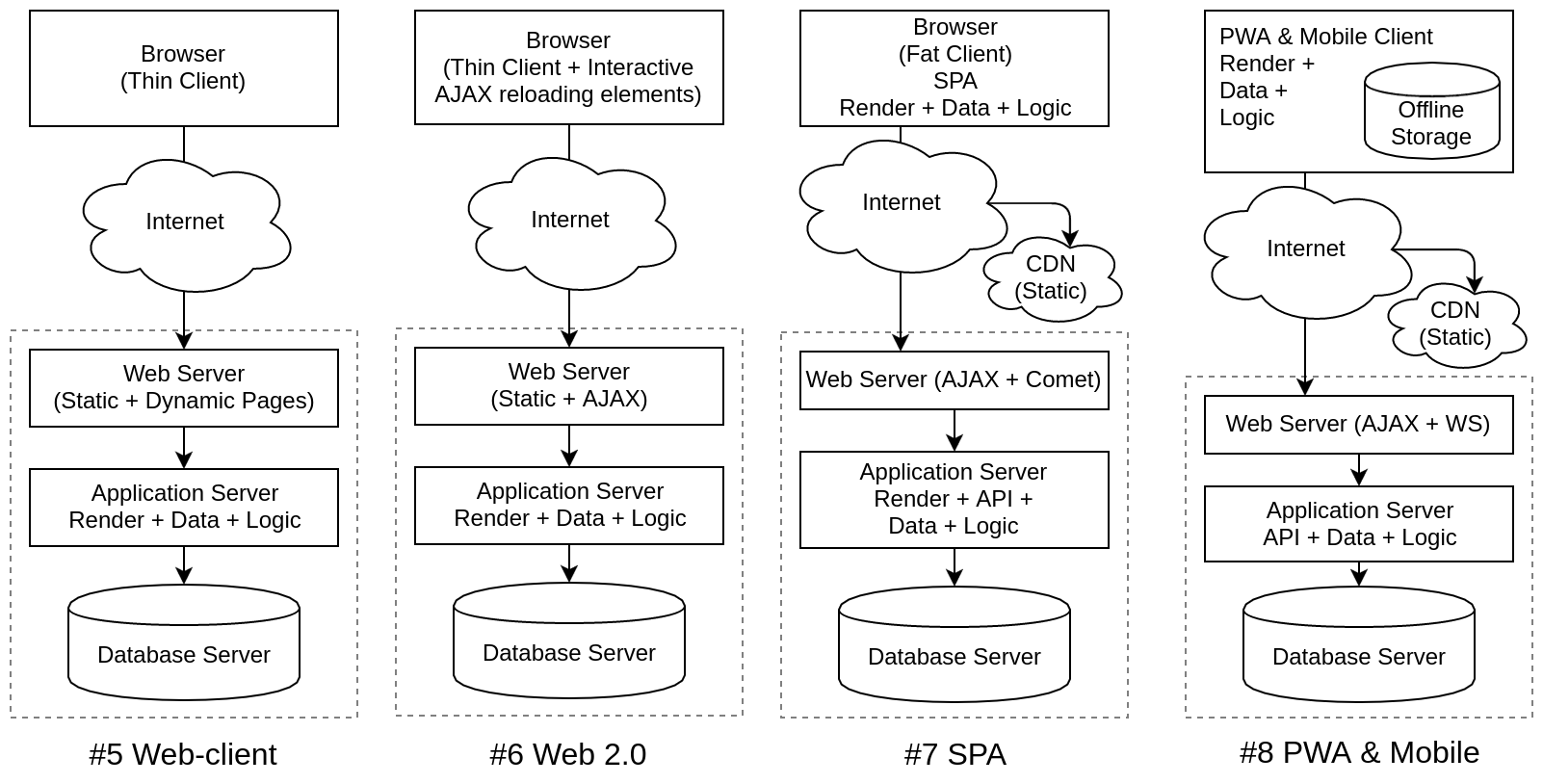
Я не указывал времени существования для архитектур, потому, что и сейчас в своих нишах параллельно существуют почти все из перечисленных решений. Для современных ИС преобладающая технология все еще #5, т.е. обычные веб страницы с перезагрузкой по ссылкам (тонкий клиент) и всей логикой на сервере. Для многих задач большего и не нужно. На переднем краю #8, тут веб-приложения и мобильные приложения слились архитектурно, хоть и имеют множества отличий в технологиях и реализации. Что же дальше? Тенденции уже наметились: сервер это API, базы данных на клиенте, рендеринг на клиенте, богатый GUI, работа в оффлайне, высокие нагрузки и много пользователей. Но технологически эти потребности удовлетворяются настолько разными платформами, что произошло разветвление. Это в равной степени актуально и для веба и для мобильных приложений. Нужно сказать, что для десктопных приложений ситуация тоже совпадает, с некоторыми оговорками, но они сейчас не в тренде и мы будем подразумевать, что следующие 4 варианта развития могут быть применены к прикладным ИС вообще.
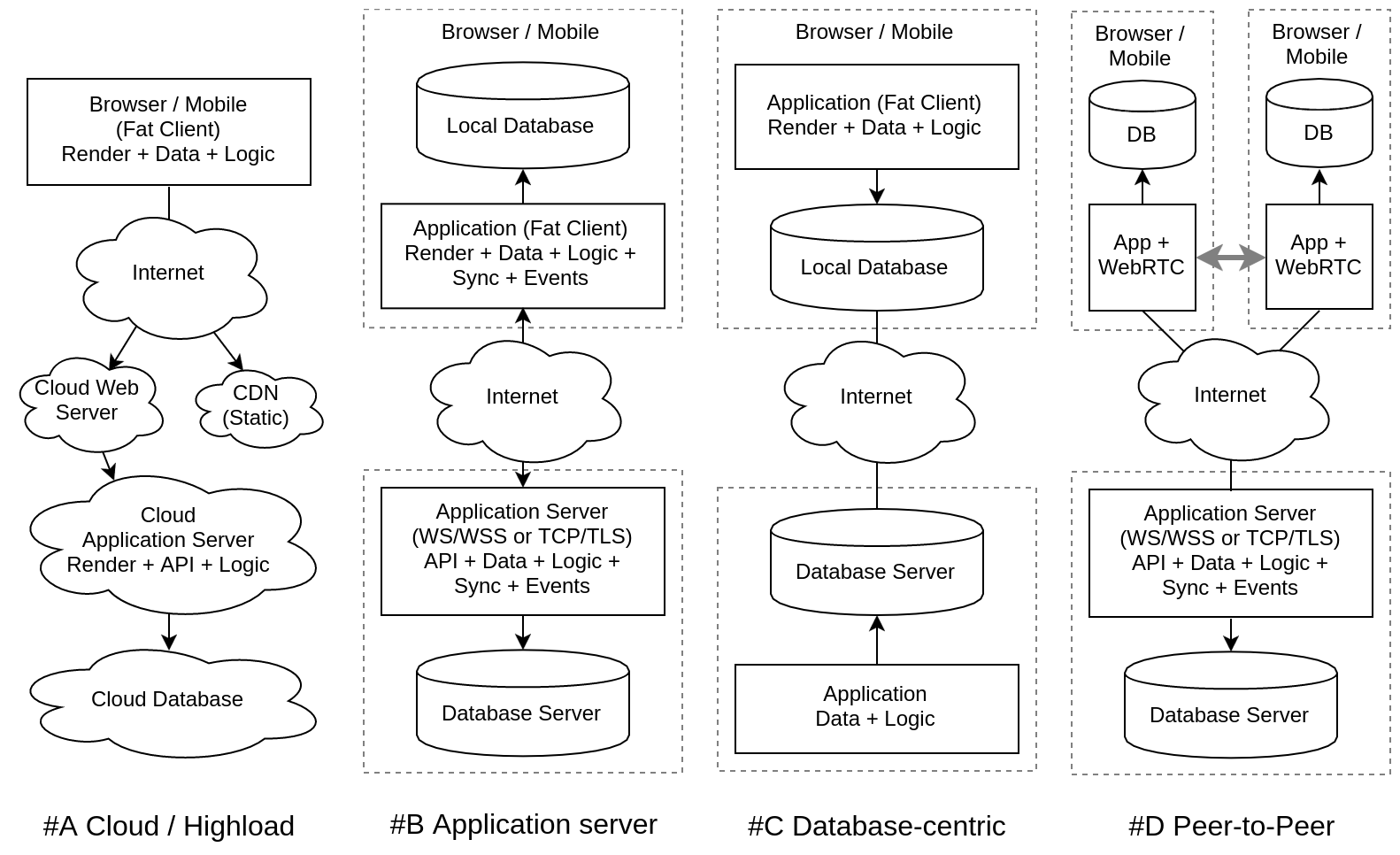
Обслуживание высоких нагрузок облаком (#A Cloud Highload)
Преимущества: Облака прекрасно справляются с масштабированием, используя принцип REST, приложения могут обслуживать десятки миллионов абонентов, если отказываются от состояния, т.е. серверные процессы не хранят состояния в памяти, все сетевые вызовы независимы и не переводят сессию ни в какое состояние.
Недостатки: В реальных приложениях часто отходят от REST именно потому, что для решения задачи нужно состояние. Получается псевдо-REST, не масштабируемый, но с кучей ограничений. А главное, совершенно не подходящий для приложений, интерактивно взаимодействующих с пользователем или обеспечивающих взаимодействие между пользователями.
Вывод: Во многих случаях это оптимальное решение: публикация контента, информационные ресурсы, СМИ, могут быть эффективно построены в облаке, но для сложных приложений с базами данных и интерактивностью, это шаг назад от архитектуры #8.
Сервера приложений (#B Application servers)
Преимущества: Место веб-сервера занимает сервер приложений, т.е. не приложение запускается под управлением веб-сервера, а веб-сервер встраивается в приложение или сервер приложений. Более того, для повышения эффективности, HTTP/HTTPS могут быть заменены специализированными протоколами на базе TCP/TLS. Особенно это актуально для мобильных и десктопных приложений, что дает возможность строить RPC, шину событий, синхронизацию БД.
Недостатки: Такие приложения пока не имеют универсальных облачных решений, но все идет к тому, что они скоро появятся. А до этого, нужно изобретать свой стек технологий и самим строить приватное облако. Это сложно поддерживать и обслуживать. Кроме того, синхронизация БД на сервере и клиенте делается вручную, через приложение, обычно сверхусилями разработчиков, а использовать такие решения повторно обычно не удается.
Вывод: Это направление сейчас доступно только крупным компаниям, имеющим потребность в обслуживании миллионов пользователей, создании интерактивных приложений или R&D лабораториям, готовящим подобные решения для массового пользователя.
БД-центрический подход (#C Database-centric)
Преимущества: Очень привлекательно поставить БД вперед приложения и настроить синхронизацию (частичную репликацию) между базами данных. Таким образом, мы имеем СУБД встраиваемые в приложения и работаем не с сервером, а с локальной БД. Для этого уже придумано множество методов: optimistic replication, operational transformation, conflict-free replicated data type, ведь СУБД существуют уже достаточно давно и научились масштабироваться.
Недостатки: Общение между приложениями только через данные явно ограничивает наши возможности. Это редукция всего к работе с базой. А как же передача событий, интеграция на уровне API, вызов удаленных процедур? Обо всем этом нужно забыть при БД-центрическом подходе.
Вывод: Для определенного класса задач это шикарное решение, а вместе с интроспекцией и скаффолдингом UI такая архитектура автоматически "раскатает" в очень широкой сфере применения более сложных конкурентов, интегрирующихся при помощи API и требующих все время писать взаимодействие программно.
Одноранговое или пиринговое взаимодействие (#D Peer-to-Peer)
Преимущества: Это разгрузит сервера, которые будут выполнять только функцию связывания/брокера. Локальное взаимодействие между пользователями часто более эффективны, чем через удаленный сервер, особенно при больших потоках данных. Дает надежду на анонимность обмена приватными данными.
Недостатки: Вопрос "доверия" в пиринговых сетях все еще полностью не преодолим. Строить распределенные ИС только на P2P не получится, сервера все равно будут в этой схеме. Пока нет распространенных протоколов, библиотек, фреймворков и других программных средств для реализации в объеме, необходимом для построения прикладных ИС.
Вывод: Элементы одноранговых сетей будут встраиваться в централизованные ИС.
Обобщение тенденций
Какой гибрид выйдет в итоге слияния этих направлений, пока не ясно, но уже можно построить несколько предположений и, как минимум, выделить тенденции.
Уже очевидно, что ветвление архитектур на этом этапе будет происходить, в первую очередь, за счет встраивания системных компонентов в само приложение:
- Встраиваемые в приложение коммуникационного сервера: HTTP/WS, HTTPS/WSS, TCP/TLS и т.д.
- Встраиваемые в приложение СУБД с автоматической синхронизацией.
- По аналогии можно вспомнить и про еще одну функцию ИС, это обработка данных или вычисления. Так что, встраиваемые в приложения систем распределенных вычислений рано или поздно тоже произойдет. Ведь пользовательские устройства в наше время обладают большой вычислительной мощностью и не использовать их для распределенной обработки данных, это непозволительное архитектурное упущение.
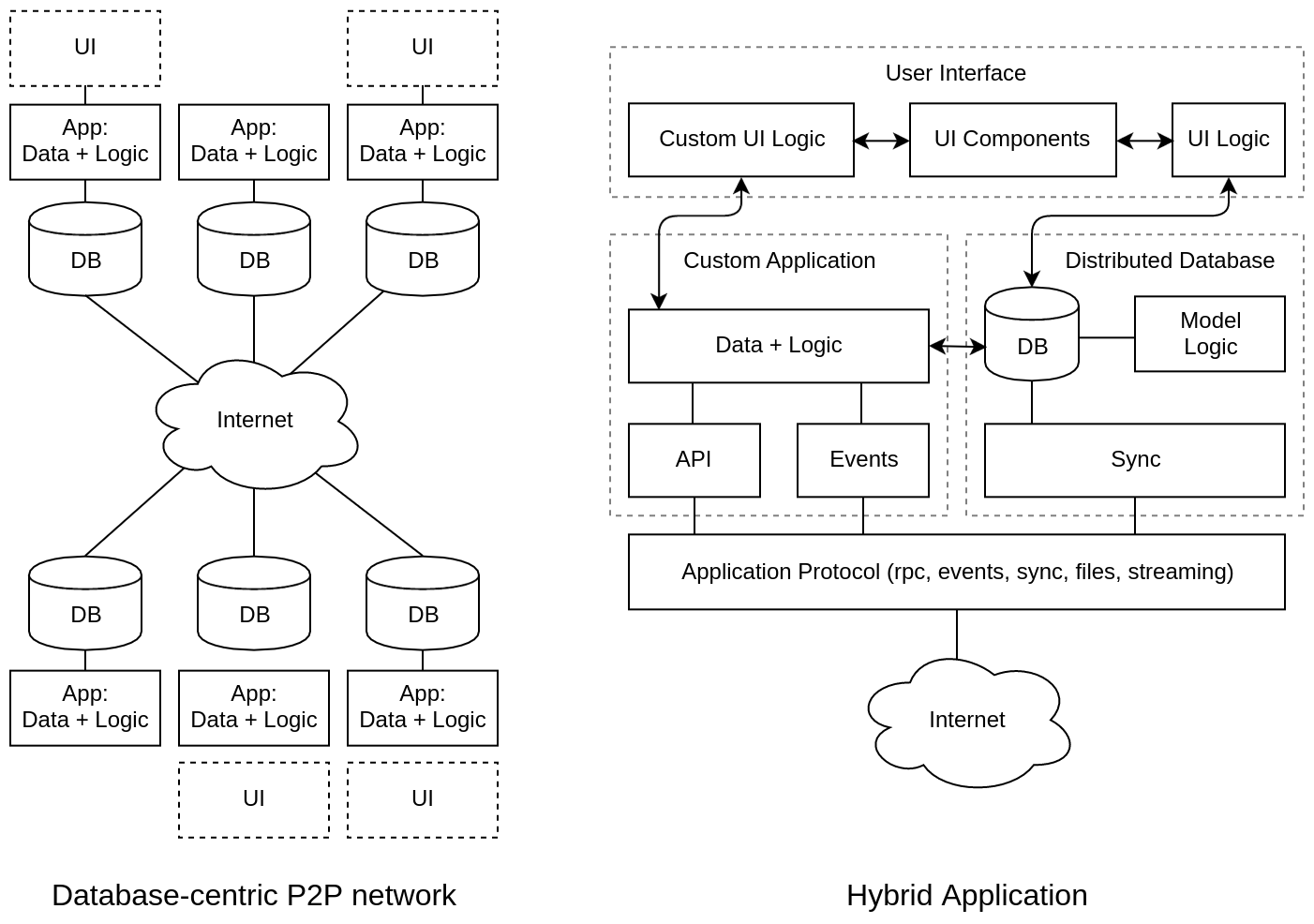
Лично я хочу объединить Data-centric архитектуру (которая, по принципу Парето, накроет 80% потребностей полной автоматизацией) с сервером приложений (который даст возможность сделать интеграцию на уровне API или шины событий для оставшихся 20% случаев). Для этого протокол взаимодействия ИС должен поддерживать одновременно 5 типов взаимодействия: RPC, REST, Event BUS, DB Sync, Binary streaming. Над таким комплексным решением и работает сейчас наша команда.
Кроме четырех крупных архитектур можно строить гибриды из комбинации отдельных возможностей:
- Synchronization — синхронизация структур данных между приложениями в распределенных системах в режиме времени, приближенном к реальному;
- Offline — возможность работать с частью данных, сохраненных в локальном хранилище в браузере или мобильном приложении, а при выходе в онлайн синхронизировать;
- Interactivity — возможность двустороннего обмена событиями с сервером и построение реактивных компонентов: UI, курсоров баз данных, логики приложения, обмена по сети и т.д.;
- Low latency (или High availability) — характеристика готовности обработки запросов и оптимизация времени отклика сервера (не путать с пропускной способностью);
- Highload — обработка интенсивного потока запросов (request per second), что включает их частоту, размер, приоритет, время ожидания в очереди, время жизни и ресурсы для обслуживания;
- High connectivity — большое количество конкурентных (одновременных и долгоживущих) соединений клиентов к серверу с возможностью двустороннего обмена данными по инициативе любой из сторон;
- High interconnection — характеристика интенсивности взаимодействия между конкурентными соединениями, а также размер взаимодействующих групп соединений;
- Scalability — группа характеристик горизонтального и вертикального масштабирования, обеспечивающих прозрачность масштабирования для программных и аппаратных средств (без переписывания кода);
- Big data — возможность обрабатывать большие объемы данных, например потоковая обработка данных или построение запросов к распределенным хранилищам;
- Big memory и in-memory DB — высокая утилизация объемов памяти или перенос баз данных полностью в оперативную память с дополнительными индексами для быстрого исполнения запросов;
- Integration flexibility — характеристика гибкости и простоты интеграции решений, на базе интроспекции, автоматического связывания интерфейсов, скаффолдинга и динамической интерпретации метамоделей.
Для того, чтобы мы все понимали тенденции, предлагаю ответить на вопросы, а так же, буду благодарен за конструктивную критику и комментарии.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (16)
VolCh
12.04.2017 10:24+2Как по мне, то database-centric решения очень нишевые, будущее вижу в event-based распределенных сетях, почти одноранговых, где часть нод берут на себя роль глобальных координаторов и "числодробилок". К событиям, похоже, можно свести и все остальные варианты в рамках, как говорится, "современной элементной базы", разница лишь в том, какие части распределенного приложения будут эмитировать события, а какие слушать и обрабатывать, насколько высоко в иерархии архитектурных сущностей отдельных процессов будут подниматься в виде каких-то абстрактных событий такие реальные события как приход пакета по сети или совершения пользователем действия типа нажатия клавишы.

WizardryIB
12.04.2017 12:40Посмотрите QNX

MarcusAurelius
12.04.2017 12:41Про QNX непонятно, поясните, к чему она тут?
WizardryIB
12.04.2017 14:42Микро-сервисная архитектура ОС и обмен сообщениями, как основной механизм взаимодействия между ними. А вообще: идеальная система — это та, которой физически не существует, а функции её выполняются!

NosovK
12.04.2017 12:59+2На самом деле при повседневной текучке задач не сильно успеваешь задуматься куда мы идем.
Интересно разнести то что мы видим и используем в жизни в такую систему.
№0 Data files
Любимые всеми таблички Excel
№1 File-server
Ранее были очень популярные MS Access, FoxPro — базы данных интегрированные в приложение. Можно сказать что это движок базы данных с интерфейсом вшытым в нее.
№2 Local DB
В этом сегменте прошло мое отрочество — BDE и иже с ним.
№3 Client-Server
Большинство старых бизнес приложений, всё работающее в связке с MS SQL. Собственно большинство приложений работающих с локальной базой при росте количества пользователей мигрировали в этот режим работы.
№4 Three-tier
Большинство современных бизнес приложений (это в том числе и 1С и всевозможные клиенты к разнообразным промышеленным системам). Это просто колосальный по обьемам пулл приложений, обслуживающих заводы, общепит, производства, трубопроводы...
№5 Web-client
тут живет большая часть вэба — всевозможные php с wordpress (с колосальной долей сайтов в интернете)
№6 Web 2.0
мир открытый для меня первыми версиями gmail, с jquery и вереницами ajax запросов. Все сайты из №5 которые научились взаимодействовать с пользователями. Те же форумы, трекеры.
№7 SPA/WebApp
тут мы живем сейчас, Angular 2, React. Весьма уютное место на самом деле.
№8 PWA & Mobile
Сюда мы стремися попасть, добавляя PouchDB, FireBase etc.
Database-centric P2P Network — нечто похожее предсавляет из себя Эфириум с его смарт-контрактами

fastwit
12.04.2017 15:18Спасибо за статью, провел несколько минут в размышлениях.
Вот мое видение эволюции:
1. Одна машина и одна программа, которая и клиент и сервер. При этом приложение вполне может иметь 3-слоя внутри: Presentation, Application logic, Data storage.
2. Появляется, клиент-сервер, как две (с точки зрения взаимодействия) разные машины или программы. Очевидно, что Presentation слой остается на клиенте, а логика может быть распределена между клиентом или сервером, БД в каком-то смысле тоже не обязательно только на сервере. Дальше вариации на тему протоколов общения клиента и сервера. Периодическая смена толстых клиентов тонкими и наоборот.
Я не очень хорош в архитектуре, поэтому дальше двух пунктов эволюций пройти не смог ( Все «облако» можно назвать словом «сервер» и архитектура с высоты птичьего полета останется прежней. Мобилки — такие же клиенты, как и десктопы, поэтому не вижу смысла их как-то выделять особо.


SergeyUstinov
19.04.2017 14:06Много думал.
Попытался «натянуть» варианты #A, #B, #C and #D на ERP системы (ими занимаюсь) — не получилось.
Все варианты не полностью соответствуют задачам.
Больше всего сомнений в месте, где надо располагать логику. Если её писать и на клиенте и на сервере — очень быстро начинаются большие проблемы. В варианте #D вся логика на сервере, но зачем в ERP Peer-to-Peer — не понятно. В остальных вариантах логика и там и там и это может создать сложности.
Хотя если сделать вариант с «синхронизацией» части логики между сервером и клиентом — это может быть интересно. Описываешь всю логику на сервере, но часть из нее (например, первичная проверка данных) автоматом переносится в клиентское приложение и выполняется там…
С локальными DB тоже много вопросов. Выгрузить на клиента тот же справочник номенклатуры, если там сотни тысяч позиций — сомнительный вариант. Выгрузить частично — но тогда что именно выгружать и усложняется логика работы со справочниками.
Можно локально хранить данные об открытом / редактируемом документе, но это обычно небольшой кусок данных, и не очень понятно, насколько хранение таких данных поможет…
Вычисления на клиенте — возможно. Но точно не в самом клиентском приложении, а что то вроде распределенной вычислительной среды вполне можно использовать. Но в ERP потребность в таких вычислениях не очень часто встречается, и при этом обычно надо обрабатывать большие объемы данных — забьется канал.MarcusAurelius
19.04.2017 22:30В варианте #D есть логика и на клиенте и на сервере, он от варианта #B отличается только одноранговым взаимодействием клиентов и дополнительной функцией сервера — быть брокером в одноранговом взаимодействии.
Вообще, конечно, для ERP лучше разделить логику, что и предложено в «Hybrid Application». С разной пропорцией можно выделить:
— Логику модели (она запускается и на клиенте и на сервере, там, где работает модель)
— Логику бизнес-процессов (которую для ERP удобнее реализовывать на сервере)
— Логику интерфейса (которая запускается только на клиенте и абстрагирована от прочей логики)
И эти три вещи не можно так построить, что они не будут пересекаться и «знать» друг о друге.SergeyUstinov
20.04.2017 01:41Уже много раз сталкивался с граблями при разделении логики на разные виды.
Например, описали логику проверки корректности вводимых данных в интерфейсной форме (ведь при ошибке надо выдать пользователю предупреждение — значит логика интерфейса). Потом, например, реализуем загрузку тех же данных в пакетном режиме и тоже пишем ту же логику проверок. И после нескольких модификаций наборы правил проверки не полностью совпадают, и у нас труднодиагностируемый глюк в данных…MarcusAurelius
20.04.2017 04:10Если Вам не удавалось разделить логику, более того, если бы даже это не удавалось ни кому, то это не значило бы, что этого сделать нельзя. Но, поверьте, удавалось. Например, логика корректности разделяется на две части, собственно правила корректности и алгоритм применения правил к данным. Правила пишутся в формате метаданных (не обязательно только декларативные, метаданные могут содержать и функции) и помещается в метамодель (схему) предметной области. Алгоритм же пишется 2 раза (и она действительно разный), один раз для применения правил к UI, второй — для применения правил к данным на сервере приложений для пакетной обработки. Может быть и третья реализация, для применения правил к данным в СУБД. Не вижу тут сложностей, честное слово.
SergeyUstinov
20.04.2017 11:58Сама по себе принципиальная возможность разделения логики сомнения не вызывает. Но хорошей реализации такого разделения я пока не видел.
Причина в том, что логика может быть достаточно сложной. Например, было простое предупреждение, что заказ нельзя отгрузить, так как у клиента недостаточно кредитного лимита. Бралась текущая задолженность, к ней прибавлялась сумма заказа и результат сравнивался с кредитным лимитом. Если меньше или равен — то можно отгружать, если больше кредитного лимита — нельзя. Потом появилась идея для некоторых товаров (которые надо распродать) не учитывать их стоимость при расчете кредитного лимита. И правило должно было выглядеть так: если у клиента кредитный лимит больше нуля и нет просроченной задолженности, то сравниваем с кредитным лимитом только не распродажные товары, а распродажные товары из текущего заказа и предыдущих заказов в сравнении не участвуют. Это тоже можно описать функцией, но это намного более сложная функция получалась… И вообще такую проверку наверно надо не на уровне интерфейса делать, а на сервере. Но в первом варианте все было просто и легко реализовывалось на уровне интерфейса.
Если вы можете привести примеры систем, где удалось удачно реализовать описываемое вами разделение логики — укажите ссылку. Было бы интересно почитать.
И возможно стоит чуть подробнее описать «Hybrid Application». В таком виде, как сейчас, не совсем понятно, что скрывается за некоторыми терминами. Например, чем три вида логики друг от друга отличаются.
excoder
Отличный материал! Как глоток свежего воздуха — уже и не ожидаешь увидеть что-то за пределами Microservices and APIs are web-scale. Вопрос: какие уже существующие продуктовые решения вы могли бы отнести к той или иной категории? Например, где на вашей карте находится платформа SAP HANA. Спасибо!
ggrnd0
Big memory и in-memory DB/OLTP
MarcusAurelius
HANA это очень хороший пример архитектуры, комплексный, состоящий из сервера приложений, СУБД, веб-сервера. Но я не специалист в SAP и глубоко не расскажу, а что точно понятно, что все компоненты там работают отдельно, как разные службы, без встраивания, о котором я пишу в статье, и такое решение застряло в середине нулевых годов, хотя, на то время было очень передовым. Разные процессы требуют постоянного межпроцессового взаимодействия, а это не только существенная потеря ресурсов, но и ограничения, например, сервер приложений должен дублировать в модель предметной области в памяти, а вообще она в БД хранится, так зачем же дублировать и синхронизировать. Все идет к интеграции.