
В этой статье мы рассмотрим базовые техники оптимизации кода, которые могут увеличить производительность вашей программы во много раз. Мы также коснёмся устройства процессора. Понимание как работает процессор необходимо для написания эффективных программ.
На написание этой статьи меня вдохновила пятая глава из книги Computer Systems: A Programmer's Perspective. Моя следующая статья будет называться “Оптимизация кода: память”, где я рассмотрю техники оптимизации для лучшего использования кэша. Все программы написаны на языке C и протестированы на машине с процессором Pentium 2117U. Производительность на вашей машине может быть другая.
Блокировщики оптимизации
Компиляторы сами пытаются оптимизировать код. Когда GCC запущен с параметром -Og, он выполняет базовый уровень оптимизации, с параметром -O1 первый уровень оптимизаици. Существует и более высокие уровни оптимизации: -O2, -O3 и т. д. Чем выше уровень оптимизации, тем более радикальные изменения компилятор вносит в программу. Компиляторы могут применять только безопасные оптимизации. Это значит, что компилятор может изменять программу только так, чтобы это не изменило её поведение для всех входных данных.
Нам, как программистам, нужно понимать, что существуют определённые характеристики кода, которые не позволят компилятору совершить оптимизацию. Мы их называем блокировщиками оптимизации. Рассмотрим два типа блокировщиков оптимизации. Одним из них являются указатели. Компилятор не может точно знать, будут ли два указателя указывать на одну и ту же область памяти, и поэтому не выполняет некоторые оптимизации. Рассмотрим пример:
void twiddle1(long *xp, long *yp) {
*xp += *yp;
*xp += *yp;
}
void twiddle2(long *xp, long *yp) {
*xp += 2*(*yp);
}Функция twiddle2 выглядит более эффективной, она выполняет всего три запроса к памяти (прочитать *xp, прочитать *yp, записать *xp), в то время, как twiddle1 выполняет шесть запросов (четыре чтения и две записи). Можно ожидать, что эти две функции имеют одинаковое поведение. Однако представьте, что xp и yp указывают на одну и ту же ячейку памяти. Тогда twiddle1 увеличит *xp в четыре раза, а twiddle2 – в три раза. Эти функции имеют разное поведение в некотором случае. По этой причине компилятор не посмеет трансформировать менее эффективную функцию в более эффективную.
Другой блокировщик оптимизации – вызов функций. Вообще, вызовы функций влекут накладные расходы, и нам нужно стараться их избегать. Рассмотрим пример:
long f();
long func1() {
return f() + f() + f() + f();
}
long func2() {
return 4*f();
}Первая функция вызывает f четыре раза, когда вторая – только один раз. Мы ожидаем, что компилятор догадается и преобразует первую функцию во вторую. Но функция f может иметь побочные эффекты, она может изменять глобальное состояние, как в этом примере:
long counter = 0;
long f() {
return counter++;
}В этом члучае func1 и func2 вернут разные результаты. Компилятору тяжело определить, имеет вызов функции побочные эффекты или нет. Когда он не может этого сделать, он рассчитывает на худшее и не выполняет оптимизацию.
Демонстрационная программа
Обычно медленные программы выполняют вычисления над большими массивами данных. Разумно будет оценивать эффективность таких программ в среднем количестве тактов, которые процессор тратит на обработку одного элемента. Введём метрику CPE (cycles per element). Если мы говорим, что программа имеет производительность CPE 2.5, значит она в среднем тратит 2.5 такта процессора на обработку одного элемента.
Мы представим простую программу, на примере которой продемонстрируем мощные приёмы оптимизации. Структура vec является вектором элементов типа float. Функция combine0 вычисляет результат перемножения всех элементов вектора. Эту функцию мы и будем оптимизировать. Размер массива сделаем 5000 и инициализируем его случайными числами.
typedef struct {
long len;
float *data;
} vec;
long vec_len(vec *v) {
return v->len;
}
void combine0(vec *v, float *dest)
{
long i;
*dest = 1;
for (i = 0; i < vec_len(v); i++) {
*dest *= v->data[i];
}
}
#define SIZE 5000
float a[SIZE];
vec v = {SIZE, a};
int main() {
float res;
for (i = 0; i < SIZE; i++) // инициализация вектора случайными числами
a[i] = rand();
combine0(&v, &res);
}Все программы в этой статье мы будем компилировать при помощи GCC с параметром -Og (базовый уровень оптимизации). Скомпилировав программу и сделав необходимые замеры, я получаю производительность CPE 11.05.
Для измерения производительности программы можно использовать счётчик тактов процессора (RDTSC). Предупреждаю, что это ненадёжный метод. Нужно сравнить значения счётчика до и после выполнения программы. Можно просто замерять потраченное процессорное время.
Избавляемся от неэффективностей цикла
Обычно самым интенсивным местом программы являются циклы, особенно самый внутренний цикл. Именно там и нужно прежде всего искать возможности для оптимизации. В цикле нашей программы мы постоянно вызываем функцию vec_len, которая возвращает длину вектора. Бессмысленно делать это в каждой итерации, потому что длина вектора на протяжении цикла не меняется. Разумнее будет вызвать эту функцию один раз и сохранить результат в переменную. Поэтому вынесем вызов этой функции за пределы цикла.
void combine1(vec *v, float *dest)
{
long i, len = vec_len(v);
*dest = 1;
for (i = 0; i < len; i++) {
*dest *= v->data[i];
}
}Производительность новой версии не изменилась – CPE 11.05. Видимо, компилятор сам догадался выполнить эту оптимизацию. Давайте запустим GCC без параметра -Og и скомпилируем обе версии функции вообще без оптимизации. Теперь разница заметна: combine0 – CPE 12.7, combine1 – CPE 11.1.
В данном случае компилятор догадался вставить тело функции в место вызова этой функции. Но часто компилятор не будет этого делать, потому что не сможет определить, имеет функция побочные эффекты или нет. Если функция производит какие-то дополнительные действия, подобная трансформация может изменить поведение программы. Как экстремальный пример рассмотрим цикл, который превращает прописные буквы в строчные:
void lower(char *s) {
for (long i = 0; i < strlen(s); i++)
if (s[i] >= 'A' && s[i] <= 'Z')
s[i] -= ('A' - 'a');
}Функция strlen обходит всю строку, пока не встретит нулевой символ, и делает это на каждой итерации. Это катастрофически замедляет программу. Для больших строк цикл будет выполняться в тысячи раз медленнее, чем более эффективный. В идеале компилятор должен распознать, что вызов strlen всегда возвращает то же самое значение, и вынести его за пределы цикла. Но для этого нужно глубоко проанализировать тело цикла и определить, что хотя программа и изменяет символы в строке, никакой символ она не превращает в нулевой. Это за пределами возможностей современных компиляторов.
Избавляемся от лишних обращений к памяти
Многие программы часто обращаются к памяти для чтения или записи. Это занимает много времени. Желательно работать с регистрами процессора, а не с памятью. Для таких программ нужно искать возможность ввести временную локальную переменную, в которую производить запись, и только через какое-то время произвести запись из этой переменной в память.
Подсчитаем сколько раз мы обращаемся к памяти в каждой итерации. Мы читаем элемент из массива, читаем dest, складываем эти значения и записываем результат в dest. Всего три обращения к памяти. Нам не нужно каждый раз читать и писать в dest после обработки очередного элемента. Мы введём временную переменную-аккумулятор, в которой будем хранить результат, и только в самом конце произведём запись в dest. Саму переменную-аккумулятор компилятор разместит в регистре, поэтому мы избавимся от ненужных обращений к памяти.
void combine2(vec *v, float *dest)
{
long i, len = vec_len(v);
float acc = 1;
for (i = 0; i < len; i++) {
acc *= v->data[i];
}
*dest = acc;
}
Теперь мы выполняем только одно обращение к памяти в каждой итерации. Производительность улучшается с CPE 11.05 до CPE 5.02. Если вы ожидаете, что компилятор сам догадается и выполнит эту оптимизацию, то подумайте что будет если dest указывает на какой-либо элемент в векторе. В этом случае версии с аккумулятором и без вычислят разное значение. Компилятор не может знать чему будут равны указатели, поэтому готовится к наихудшему и не выполняет оптимизацию. Вызовы функций и указатели серьёзно блокируют оптимизирующие возможности компилятора.
Развёртывание цикла
Мы достигли CPE 5.02. Это не простое число, мой процессор тратит 5 тактов на выполнение умножения чисел с плавающей точкой. Можно сказать, что мы достигли определённой нижней границы.
Мой процессор тратит один такт на выполнение сложения чисел типа int. Интересно, если вместо перемножения значений типа float, я буду складывать значения типа int, добьюсь ли я производительности CPE 1.0? Я не буду приводить здесь код, но внесу необходимые изменения в свою программу. Я получаю всего CPE 1.58. Откуда такая неэффективность?
Всё дело в том, что при выполнении цикла, процессор выполняет не только инструкции вычисления, в которых мы заинтересованы, но также инструкции, обслуживающие цикл: инкрементирование счётчика, проверка условия, переход в начало цикла. То есть обслуживание цикла имеет свои накладные расходы, и процессор производит много ненужной работы. Если тело цикла маленькое, эти пустые вычисления занимают большую долю процессорного времени.
Техника развёртывания цикла заключается в том, что за одну итерацию обрабатываются не один, а несколько элементов. Мы как бы «разворачиваем» цикл, увеличивая длину его тела и уменьшая количество витков. Таким образом мы выполняем меньше итераций, за одну итерацию совершаем больше полезной работы, и накладные расходы составляют уже не такую большую долю. Давайте немного изменим функции, складывающую целые числа:
void combine_plus(vec *v, int *dest)
{
long i, limit = vec_len(v)-1;
int acc = 0;
for (i = 0; i < limit; i+=2) {
acc = acc + v->data[i] + v->data[i+1];
}
if (i < len) acc += v->data[i];
*dest = acc;
}
Теперь программа добавляет к аккумулятору два элемента за итерацию. Обратите внимание, что последний элемент может быть не обработан в цикле, поэтому его нужно добавить к аккумулятору позже. CPE падает с 1.58 до 1.15. Обрабатывая четыре элемента за итерацию, я получаю CPE 1.03, близко к тому значению, которое хотел получить.
CPE 5.02, который мы получили, равно количеству тактов, которые тратит мой процессор на совершение умножения чисел с плавающей точкой. Для обработки одного элемента мы выполняем одно умножение, и, казалось бы, это предел, ниже которого мы не опустимся. Но на самом деле мы можем достигнуть CPE 1.04 . Чтобы понять более продвинутые техники оптимизации, нужно сперва разобраться, как работает процессор.
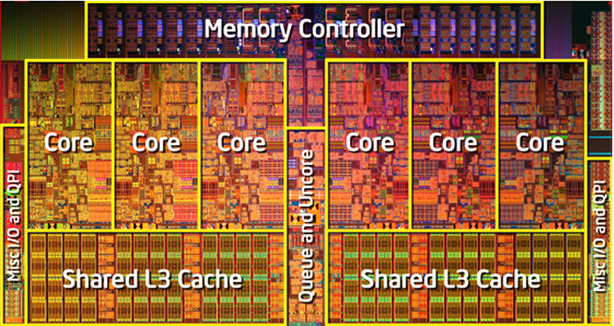
Введение в работу процессора
Современные процессоры очень сложны. Внутреннее устройство процессора называется микроархитектурой, и это отдельный мир, над которым мы не имеем контроля. Когда процессор читает инструкции программы, он разбивает их на примитивы, понятные ему, и обрабатывает их как ему вздумается. Если смотреть на код ассемблера, то кажется, что процессор выполняет инструкции последовательно, одна за одной, как они представлены в коде. На самом деле процессор может выполнять инструкции параллельно и даже в противоположном порядке, если уверен что это не изменит конечный результат. Выполнение процессором инструкций параллельно называется параллелизмом на уровне инструкций.
Процессор разбит на части, которые выполняют разные типы задач, мы их называем функциональными блоками. Каждый блок выполняет определённый ряд задач: чтение из памяти, запись в память, сложение целых чисел, умножение чисел с плавающей точкой и т. д. Мой процессор имеет два блока, которые выполняют сложение целых чисел. Это значит, что он может параллельно выполнять два сложения.
Представьте, что процессору нужно получить данные из памяти и это занимает 100 тактов. Но процессору будет неразумно ждать завершения этой операции, чтобы начать следующую. Ведь чтением данных из памяти занимается отдельный блок, а остальные блоки в это время могут производить другие вычисления. Поэтому процессор наперёд считывает несколько следующих инструкций и пытается нагрузить ими все функциональные блоки, даже если придётся выполнять инструкции в неправильном порядке.
Считывание инструкций наперёд называется предвыборкой. Если во время предвыборки, процессор встречает ветвление (к примеру, конструкция if-else), он пытается угадать, какая ветвь будет взята и считывает инструкции оттуда. Если позже он понимает, что была взята неправильная ветвь, он сбрасывает произведённые вычисления, восстанавливает предыдущее состояние и идёт по другой ветви. Такая ошибка стоит процессору нескольких потерянных тактов. Для многих процессоров это примерно 20 тактов.
Конвейер
Мой процессор имеет один функциональный блок, выполняющий умножения чисел с плавающей точкой, и на одно умножение он тратит пять тактов. И казалось бы, если нам нужно выполнить N умножений, нам придётся потратить 5*N тактов. Но это не так, благодаря такому устройству как конвейер.
В американских фильмах вы наверняка видели как клиент в столовой проходит с подносом нескольких поваров и каждый ковшом накладывает ему что-то своё. Это и есть конвейер. Представим столовую с пятью поварами, и обслужиться у одного из них занимает один такт. Они могли бы обслуживать клиентов так: сначала один клиент проходит всех поваров, потом второй, потом третий и так далее. В этом случае каждые пять тактов от них отходил бы клиент с полным подносом. Но это неэффективно. Лучше если все клиенты выстроятся в очередь, и каждый такт эта очередь будет продвигаться к следующему повару. В этом случае каждый такт от поваров будет отходить клиент с полным подносом. Заметьте, что обслуживание одного клиента всё равно будет занимать пять тактов, но обслуживание N клиентов (если N велико) займёт примерно N тактов.
По принципу конвейера устроены функциональные блоки в процессоре. Они разделяют всю работу на несколько этапов, и на разных этапах могут одновременно обрабатываться разные инструкции. Несмотря на то, что выполнение одной инструкции может занимать несколько тактов, многие блоки могут принимать в конвейер новую инструкцию каждый такт. Такие блоки называются полностью конвейерными. Все операции, кроме деления, выполняются в полностью конвейерном режиме. Деление считается сложной операцией, занимает 3-30 тактов и вообще не имеет конвейера.
Зависимость данных и несколько аккумуляторов
Но если конвейер позволяет нам тратить один такт на операцию, почему тогда мы получили CPE 5.02, а не CPE 1.02? Всё дело в такой плохой вещи как зависимость данных. Вернёмся к примеру со столовой. Допустим, первый повар в столовой накладывает или рис или гречку, и по странному правилу, каждый клиент, пройдя всех поваров, решает что должен наложить первый повар следующему клиенту. Тогда мы не можем начать обслуживание следующего клиента пока текущий клиент не пройдёт всех поваров. Нам приходится ждать, потому что есть определённая зависимость. Также и в работе процессора, мы говорим, что между данными есть зависимость, если для начала работы над одними данными нам нужны другие данные, и мы должны дождаться завершения работы над ними.
В нашей программе такую зависимость данных создаёт переменная-аккумулятор. Процессор может вычислять инструкции цикла на несколько итераций вперёд. Но в каждой итерации мы вычисляем новое значение аккумулятора, учитывая его значение, вычисленное в предыдущей итерации. Поэтому мы не можем начать умножение в следующей итерации, пока полностью не завершится умножение в предыдущей. То есть каждое умножение должно пройти весь конвейер, прежде чем мы отправим в конвейер следующее. Это и мешает нам загрузить конвейер.
Давайте подумаем, как можно избавиться от этой зависимости. Если нам нужно перемножить последовательность чисел, мы может перемножать их одно на другое последовательно. А можем сначала перемножить все числа с чётным индексом, потом все числа с нечётным, а в конце перемножить два полученных результата. В таком случае перемножение двух последовательностей будут независимы друг от друга, и операции умножения из разных последовательностей смогут находиться в конвейере одновременно.
Для большей наглядности мы упростим код и будем передавать в функцию не векторную структуру, а сразу массив чисел. Такое изменение на производительность не повлияет, зато читать код станет проще. Следующая техника называется развёртывание цикла с несколькими аккумуляторами.
float combine3(float a[], long size)
{
long i, limit = size-1;
float acc0 = 1;
float acc1 = 1;
for (i = 0; i < limit; i+=2) {
acc0 *= a[i];
acc1 *= a[i+1];
}
while (i < size) acc0 *= a[i++];
return acc0 * acc1;
}
Как видите, мы поддерживаем два независимых аккумулятора, которые в конце перемножаются, чтобы дать окончательный результат. CPE падает до с 5.02 до 2.5. Давайте сделаем развёртывание с четырьмя аккумуляторами.
float combine4(float a[], long size)
{
long i, limit = size-3;;
float acc0 = 1;
float acc1 = 1;
float acc2 = 1;
float acc3 = 1;
for (i = 0; i < limit; i+=4) {
acc0 *= a[i];
acc1 *= a[i+1];
acc2 *= a[i+2];
acc3 *= a[i+3];
}
while (i < size) acc0 *= a[i++];
return acc0 * acc1 * acc2 * acc3;
}
CPE падает до 1.28. При восьми аккумуляторах я получаю CPE 1.04, что практически равно тому, что можно выжать из моего процессора. При написании кода таким образом нужно не забывать обрабатывать оставшиеся несколько элементов.
Мой процессор имеет только один функциональный блок, который выполняет умножение чисел с плавающей точкой. Core i7 Haswell имеет два таких блока, на нём наше приложение может достичь CPE 0.5, но пришлось бы использовать больше аккумуляторов. Вообще, если операция занимает C тактов и её выполняют N блоков, необходимое количество аккумуляторов может быть C*N.
Ассоциативность
Как мы уже говорили, компиляторы очень консервативны, боятся навредить и никогда не вносят изменения в программу, которые могут повлиять на конечный результат в каком-то случае. Компиляторы знают о технике развёртывания цикла с несколькими аккумуляторами. GCC применяет эту технику, когда запущен с третьим уровнем оптимизации или выше. Компиляторы будут применять эту оптимизацию для целых чисел, но никогда не применят её для чисел с плавающей точкой. Всё дело в ассоциативности, то есть в том, влияет ли порядок, в котором мы складываем или перемножаем числа, на конечный результат.
Если у нас есть последовательность целых чисел, то неважно в каком порядке мы их будем складывать или перемножать, мы всё равно получим один и тот же результат, даже если будет переполнение. Мы говорим, что операции сложения и умножения для целых чисел являются ассоциативными операциями. Сложение и умножение для чисел с плавающей точкой не являются ассоциативными. Допустим в последовательности чисел типа float есть очень маленькие числа и очень большие. Если мы сначала перемножим очень маленькие, то получим ноль. Умножая все остальные на ноль, мы в итоге получим ноль. Если же изначально очень маленькие мы будем умножать на очень большие, в итоге мы могли бы получить адекватный результат.
Для большинства реальных приложений нет разницы в каком порядке выполнять операции над числами, поэтому мы можем использовать эту технику оптимизации.
Векторизация
Мы ещё можем улучшить производительность. CPE 1.04, который мы достигли – не предел. Современные процессоры поддерживают специальные расширения, называемые SSE или AVX, которые позволяют работать над векторами данных. В процессоре есть специальные векторные регистры, называемые %ymm0-%ymm15, размером 16 или 32 байта. Текущие AVX регистры имеют размер 32 байта и могут содержать четыре 64-битных числа, или восемь 32-битных числа, не важно целых или с плавающей точкой. Можно считать из памяти в один такой регистр сразу 32 байта данных, считать 32 байта данных в другой регистр и выполнить арифметическую операцию сразу над четырьмя или восьмью числами параллельно.
Это железо находится в процессоре неиспользуемое, пока вы явно не задействуете его. GCC поддерживает расширение языка C, которое позволит вам это сделать. Можно, конечно, написать код на ассемблере, но тогда программа перестанет быть переносимой. Используя эти возможности процессора, можно дальше увеличить производительность программы в 4 или 8 раз, в зависимости от размера регистров. В нашем случае, мы могли бы понизить CPE до 0.25 или 0.12.
Итоги оптимизации
Мы начали с программы, которая имела производительность CPE 11.05. Потом мы избавились от лишних вызовов функций и запросов к памяти и улучшили производительность до CPE 5.02. Потом использовали развёртывание цикла с несколькими аккумуляторами. Так смогли избавиться от зависимости данных, смогли полностью загрузить конвейер и получили CPE 1.04.То есть мы увеличили скорость выполнения программы в 11 раз. Используя векторизацию, можно заставить программу выполняться в 44-88 раза быстрее по сравнению с первоначальной версией.
Для компиляции первоначальной версии программы мы использовали базовый уровень оптимизации. Поэтому компилятор не сгенерировал максимально быстрый код. Давайте скомпилируем её с высоким, третьим уровнем оптимизации и посмотрим на что способен компилятор. Я получаю производительность CPE 5.02. Это далеко от CPE 1.04, которое мы получили, вручную трансформируя код. Мы можем также использовать векторизацию, чтобы дальше увеличить производительность в 4-8 раз, компилятор за вас этого не сделает.
Проблемы
Количество функциональных блоков, которые выполняют чтение и запись в память может быть узким местом производительности. Заметим, что эти блоки полностью конвейерные и могут принимать новую инструкцию каждый такт. Мой процессор имеет один блок, выполняющий чтение данных из памяти в процессор. Если для обработки одного элемента, мне нужно будет получить из памяти два числа, я не смогу сделать лучше, чем CPE 2.0, потому что получение двух чисел займёт два такта. Core i7 Haswell имеет четыре блока, которые выполняют сложения целых чисел. Но если вам нужно сложить элементы целочисленного вектора, вы не сможете добиться CPE 0.25. Потому что этот процессор имеет только два блока, выполняющих чтение из памяти – это устанавливает нижнюю границу на CPE 0.5.
Значение каждого аккумулятора хранится в отдельном регистре. x86-64 процессор имеет 16 регистров для целых чисел и 16 YMM регистров для чисел с плавающей точкой. Если мы будем использовать слишком много аккумуляторов, для них может не хватить регистров. Придётся хранить значения некоторых из них в памяти, что ухудшит производительность. Если увеличить количество аккумуляторов в нашей программе с 8 до 20, производительность падает с CPE 1.04 до CPE 1.35.
Оптимизация усложняет код, делает его трудным для понимания. Поэтому, как правило, оптимизируют критически важные части кода, где требуется максимальная производительность. Оптимизация увеличивает число потенциальных багов. Оптимизированный код нужно тщательно тестировать после каждого этапа оптимизации.
Другие техники оптимизации: реассоциация
Существует техника, называемая реассоциацией. Это когда мы в каком-то выражении расставляем скобки по-другому, и это позволяет уменьшить зависимость данных и улучшить производительность. Допустим в нашей программе мы хотим перемножать три элемента за одну итерацию.
for (long i = 0; i < limit; i+=3) {
float x = a[i], y = a[i+1], z = a[i+2];
acc = acc * x * y * z;
}
Этот цикл имеет производительность CPE 5.02. По правилам языка C, когда нет скобок, операции умножения выполняются слева направо. В данном случае, легко увидеть, что все операции умножения зависят от переменной acc. Процессор не может начать умножать в следующей итерации, пока не завершит все умножения в текущей. Расставим скобки по-другому:
acc = acc * ((x * y) * z);
Значение переменных x, y и z в одной итерации не зависят от их значений в любой другой. Поэтому, пока выполняется текущая итерация, процессор может заранее вычислять два последних умножения в следующих итерациях. Производительность улучшается до CPE 1.69.
Другие техники оптимизации: условная передача данных
Как уже было сказано, процессор выполняет предвыборку, то есть считывает инструкции наперед. Если ему встречается ветвление (команды ассемблера je, jg, jl и т. д. ), он пытается угадать по какой ветви пойдёт вычисление. Если он угадывает неправильно, то теряет несколько тактов. Это называется условная передача управления.
Существует команда ассемблера cmov. Выполняя эту команду, процессор проверяет какое-то условие. Если это условие верно, он копирует значение из одного регистра в другой. Это называется условная передача данных. В данном случае не создаётся ветвления и процессору не надо ничего угадывать и рисковать потерей тактов.
Идея заключается в том, чтобы уменьшить количество ветвлений в программе, сделав поток выполнения более прямым. Для этого некоторые передачи управления выгодно заменить на передачу данных. Обычно компилятор транслирует конструкции if-else, используя команды ассемблера je, jg, jl и т. д., но иногда может использовать команду cmov. Рассмотрим такую конструкцию if-else:
if (условие)
v = выражение1;
else
v = выражение2;
Если транслировать этот код, используя передачу управления, то при выполнении программы будет вычислено или одно выражение или другое, но есть вероятность, что процессор совершит ошибку в выборе ветвления и потеряет такты. Компилятор может избежать ветвления, если преобразует этот код следующим образом:
v1 = выражение1;
v2 = выражение2;
v = (условие) ? v1 : v2;
Когда условная инструкция очень простая, в ней только присваивается какое-то значение одной переменной, компилятор транслирует эту инструкцию на язык ассемблера с помощью команды cmov. Поэтому, последняя строка в предыдущем примере будет транслирована, используя передачу данных, не создавая ветвления. Процессору придётся вычислить оба выражения, что занимает больше тактов, но он не выполняет предсказания ветвления, что потенциально экономит такты. Если выражения довольно просты, такое преобразование может быть выгодным.
Иногда компилятор не выполняет эту оптимизацию, потому что считает, что это ухудшит производительность. Мы можем заставить его выполнить её если перепишем код в более функциональном стиле, как представлено в предыдущем примере. Рассмотрим реальную программу.
void minmax1(int a[], int b[], int n)
{
for (int i = 0; i < n; i++) {
if (a[i] > b[i]) {
int t = a[i];
a[i] = b[i];
b[i] = t;
}
}
}
void minmax2(int a[], int b[], int n)
{
for (int i = 0; i < n; i++) {
int min = a[i] < b[i] ? a[i] : b[i];
int max = a[i] < b[i] ? b[i] : a[i];
a[i] = min;
b[i] = max;
}
}
Обе функции делают одно и то же. Они параллельно обходят пары чисел из двух массивов, устанавливая в массив a наименьшее из них, а в массив b наибольшее. Только вторая функция использует хитрую технику: она вычисляет минимальное число, вычисляет максимальное число, записывает каждое из чисел в своё место. Условия в вычислении переменных min и max настолько простые, что компилятор использует для них условную передачу данных. Разница в производительности наибольшая, если выполнить компиляцию с третьим уровнем оптимизации: minmax1 – CPE 15.6, minmax2 – CPE 1.18 (в 13.2 раз быстрее).
Заключение
Современный процессор скрывает огромную вычислительную мощь. Но чтобы получить к ней доступ, нужно писать программы в определённом стиле. Решить какие трансформации и к какой части кода применить есть «чёрная магия» написания быстрого кода. Обычно анализ совмещают с экспериментом: пробуют разные подходы, делают измерения производительности, исследуют код ассемблера для обнаружения узких мест.
Мы предложили базовую стратегию оптимизации кода:
- Высокоуровневый дизайн. Выбирайте эффективные алгоритмы и структуры данных. Никакой компилятор не заменит плохие алгоритмы или структуры данных на хорошие.
- Базовые принципы кодирования. Избегайте блокировщиков оптимизации, чтобы помочь компилятору генерировать эффективный код. Избавьтесь от ненужных вызовов функций. Если возможно, вынесите вычисления за пределы цикла. Избавьтесь от ненужных запросов к памяти. Введите временные переменные для хранения промежуточных результатов.
- Низкоуровневая оптимизация. Применяйте развёртывание циклов, чтобы уменьшить пустые вычисления. Задействуйте параллелизм на уровне инструкций, используя несколько аккумуляторов и реассоциацию. Пишите инструкции if-else в функциональном стиле, чтобы компилятор мог использовать условную передачу данных.
Комментарии (83)

Torvald3d
12.09.2016 20:24Прочел на одном дыхании, спасибо за статью. Подскажите, можно ли как-то узнать количество функциональных блоков того или иного назначения и прочие параметры процессора в рантайме?
old_bear
12.09.2016 21:34+1Читайте мануалы производителя процессора — там всё есть.
Ну или нагуглите сайт за авторством Agner-а нашего Fog-а.

SKolotienko
12.09.2016 21:12Последний пример впечатлил. Казалось, что в функции minmax1 операций меньше и она должна работать быстрее, чем в minmax2, где и операций больше и присваивания происходят на каждой итерации.
khim
12.09.2016 22:23Как раз то, что присваивания происходят на каждой итерации и спасает: можно обойтись без проверок. А это — для процессора самое страшное.
Slbr
14.09.2016 11:55-1Насколько я знаю, minmax2 можно ещё ускорить заменив [ ] на указатели, поскольку выражение a[ i ] воспринимается компилятором как: *(a + i * sizeof(int)), если вместо a[ i ] использовать *( a + i ), то необходимость в умножении отпадает, значит должна возрасти производительность.
void minmax2(int * a, int * b, int n)
{
for (int i = 0; i < n; i++) {
int min = *(a + i) < *(b + i)? *(a + i): *(b + i);
int max = *(a + i) < *(b + i)? *(b + i): *(a + i);
*(a + i) = min;
*(b + i) = max;
}
}

DustCn
12.09.2016 21:20+8Эти оптимизации были актуальны году так в 90.
Через двадцать лет компиляторы таки научились понимать основные паттерны, и правильно генерировать для них код.
Конечно баловаться указателями не стоит и сейчас, это ничуть не поможет производительности. С другой стороны тенденции процессоростроения приводят к тому что циклы, которые 5 лет назад нельзя было векторизовать, сейчас векторизуются.
Кстати про векторизацию в статье я не заметил — как же так?? (Заметил небольшой абзац… Очень странно что такой мелкий — векторизация это ключ к эффективности).
Вообщем мой совет — перестаньте думать о том как написать А+Б. Думаете алгоритмами, О-сложностями. Ручной анролл цикла — самая плохая идея, потому что мне надоело их заанроливать обратно. Компилятор прекрасно делает это сам, причем учитывает количество регистров на целевой архитектуре автоматически, делает вершнинг, если ваша развертка не кратна длинне вектора.
Так что — думайте алгоритмикой, не стесняйтесь пользоваться матбиблиотеками (где цикл вида A=B+C) уже и так вылизан. А такую оптимизацию — бросьте, не нужна она…old_bear
12.09.2016 21:39+3IMHO, вы путаете пример и метод. Всегда найдётся алгоритм, которого нет в стандартных библиотеках. Или он есть, но неизвестно где. Или известно, но эту библиотеку нельзя использовать по причине несовпадения лицензий.
Так или иначе, нужно как минимум иметь представление о базовых методах оптимизации.MichaelBorisov
12.09.2016 23:40+4Или если вы автор матбиблиотеки. Почему-то проповедники подхода «оставьте оптимизацию профессионалам» забывают о самих профессионалах, которые должны делать оптимизацию. Им же тоже надо где-то учиться.
khim
12.09.2016 22:31Эти оптимизации были актуальны году так в 90.
Да ну? А что сейчас произошло? Почему сегодня, сейчас, мы получаем десятикратную оптимизацию от этих техник?
Через двадцать лет компиляторы таки научились понимать основные паттерны, и правильно генерировать для них код.
Тем не менее они остались связаны рамками стандартов C/C++. Пример minmax1 vs minmax2 — очень показателен.
Кстати про векторизацию в статье я не заметил — как же так?? (Заметил небольшой абзац… Очень странно что такой мелкий — векторизация это ключ к эффективности).
В очень ограниченном числе алгоритмов. Подавляющее большинство алгоритмов либо векторизуются плохо (и с этим ничего нельзя поделать), либо, наоборот — векторизуются очень хорошо (и тогда GPGPU — наше всё).
А такую оптимизацию — бросьте, не нужна она…
Разработчики TensorFlow тоже так думали. Потому сделали логику на Питоне и «молотилку» — на C++ (и даже, говорят, специализированные железки есть). В результате на больших серверах больше половины времени уходит на исполнение питоновского скрипта, который «никого тормозить не может».DustCn
12.09.2016 22:44+1Ваша ссылка на TensorFlow лишний раз показывает что вы поверхностно вникаете в тему.
Да будет вам известно, для молотилки было сделано абсолютно ровно то, что я посоветовал ответом выше — «не стесняйтесь пользоваться матбиблиотеками». Для молотилки в TF используется Eigen.
https://www.google.ru/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwiryoftyorPAhXmJJoKHdkNDUMQFggeMAA&url=http%3A%2F%2Feigen.tuxfamily.org%2F&usg=AFQjCNGi0wxMLU4MgkIA4YRyJUH2dkiKCg&sig2=kMAXRZVw6H3HNc_Yw85JRg
Про TF я могу вам много чего рассказать. Главная к нему претензия что distributed версия там написана сыро.
>>В очень ограниченном числе алгоритмов. Подавляющее большинство алгоритмов либо векторизуются плохо (и с этим ничего нельзя поделать), либо, наоборот — векторизуются очень хорошо (и тогда GPGPU — наше всё).
Я бы сначала взглянул на вашу статистику, чтобы понять откуда взялось это странное высказывание.
Особенно в свете того что я выше написал «тенденции процессоростроения приводят к тому что циклы, которые 5 лет назад нельзя было векторизовать, сейчас векторизуются».
Unrul
13.09.2016 08:16+2Ага. Вот как раз сейчас разбираюсь, почему в Eigen процедура умножения RowMajor матрицы на 3d вектор работает в 18 раз медленнее, чем написанная самостоятельно, при компиляции в в VS2015.

QtRoS
12.09.2016 23:32Эх, примкну к меньшинству — согласен с тем, что на одном размышлении о тривиальных операциях много не получишь в скорости. За исключением очень (очень!) специфичных задач с которыми 99.9% процентов программистов не сталкиваются, любая проблема производительности решается тремя основными подходами:
1. Алгоритм (нотация большого О, о чем говорит предыдущий оратор)
2. Локальность данных (вот отличная статья на эту тему)
3. Отсутствие блокировок и узких мест (многопотчность)khim
12.09.2016 23:49+1Эх, примкну к меньшинству — согласен с тем, что на одном размышлении о тривиальных операциях много не получишь в скорости.
Я получал в нескольких случаях ускорение от 3 до 10 раз на вот таких «тривиальных операциях». Да, код становилось сложнее читать и править — но подобное ускорение может быть, в зависимости от задачи, очень полезным.
2. Локальность данных (вот отличная статья на эту тему)
Собственно почти вся описанная тут статья является небольшой частью этого подхода. В данном случае речь идёт о том, что обращение к регистрами — на порядок быстрее, чем даже к кешу L1, а вычисления — на порядок быстрее, чем принятие решений (ветвления) и нужно бы сделать так, чтобы компилятору ничто не мешало их использовать.
xaoc80
13.09.2016 02:06+1Ручной анролл цикла — самая плохая идея, потому что мне надоело их заанроливать обратно
Мой скромный опыт говорит ровно об обратном — развертки цикла очень хорошая техника. Я лично смог ускорить одну из операций (конвертация одного colorspace в другой) в 5 раз (одна из последних версий GCC). И такие примеры мне встречаются постоянно. В данном случае я занимался оптимизацией нашего медиасервера.

beeruser
13.09.2016 03:30-3Ну давайте, скопируйте последний пример в http://gcc.godbolt.org/ и увидите что первый цикл ни один компайлер не смог осилить.
Второй (minmax2) был успешно векторизован, чем и обьясняется ускорение.
>> Думаете алгоритмами, О-сложностями.
Вот это как раз совет из 90х
Это конечно важно, но паттерны работы с памятью важнее.

nnovichOK
13.09.2016 21:00+1Три дня я гналась за Вами — да! — чтобы сказать Вам, как Вы мне безразличны!
Откопал год как пылящийся хабровский пароль только ради выражения своего «фи». У вас получился невероятно самодовольный категоричный комментарий напрочь игнорирующий контр-примеры из статьи. Что забавно, вы продолжили игнорировать их упоминание и в последующих обсуждениях. Можете уже ясно и без экивоков пояснить, как пафосная фраза про
Через двадцать лет компиляторы таки научились понимать основные паттерны, и правильно генерировать для них код
может существовать в мире с оптимизацией minmax1() в minmax2()?
old_bear
12.09.2016 21:29Очень приятная статья. Прочитал с удовольствием, хотя всё это я знаю и применяю. Буду кидать этой ссылкой в начинающих программистов.
martin_wanderer
13.09.2016 11:22+1Статья замечательная, но может не стоит в начинающих-то ей кидаться — многие новички и так норовят все и вся оптимизировать, даже не проверив профайлером, нужна ли оптимизация вообще.
old_bear
13.09.2016 13:19Я подразумевал, что буду использовать эту статью вместо того, чтобы самому придумывать правильные слова и показательные примеры. Понятно, что это всё в контексте нужности оптимизации как таковой будет подаваться.
MichaelBorisov
12.09.2016 23:48+1Насчет ветвлений — я лично столкнулся с проблемой производительности LFSR. Внутренний цикл LFSR Галуа проверяет равенство младшего бита нулю и в зависимости от этого ксорит или не ксорит содержимое регистра с константой. Когда мне удалось (путем написания программы на ассемблере) избавиться от условного перехода во внутреннем цикле — производительность возросла очень ощутимо. Во сколько раз — не измерял, но до оптимизации программа не справлялась с нагрузкой, а после оптимизации стала справляться. А все дело в том, что LFSR — это практически генератор случайных чисел, поэтому процессор, пытаясь предсказать переход на следующем проходе цикла, ошибается в среднем в 50% случаев. Это приводит к частому обнулению конвейера и большим задержкам в работе программы. Поэтому избавление от условного перехода и дает такой прирост производительности.
MichaelBorisov
12.09.2016 23:54Кстати, избавление от условного перехода я делал не на основе cmovcc (хотя это было бы возможно), а на основе старого доброго sbc eax,eax. Это такой красивый трюк, и его можно реализовать на множестве процессоров. Познакомился я с ним на Z80 (SBC A,A). Даже там, без конвейера, он зачастую позволяет сильно оптимизировать программу за счет избавления от условных переходов.
khim
12.09.2016 23:58Дык компилятор делает также — зачем вам ассемблер приспичил?
MichaelBorisov
13.09.2016 02:12+2Если бы мой компилятор (VS2013) такое тогда делал — то я бы ассемблером и не занимался. Компилятор не смог — а какие у меня были основания ожидать, что какой-то другой компилятор это сможет? Плюс время на установку другого компилятора, портирование программы под него, испытания? Вы считаете, что это быстрее, чем написать внутренний цикл на ассемблере?
Если я знаю и умею, как написать на ассемблере быстрый код, и это быстрее, чем найти способ «подшаманить» C-код так, чтобы компилятор его хорошо скомпилировал — то почему не сделать на ассемблере? Если мы начинаем вникать в тонкости процессора с целью оптимизации программ — то логичный шаг писать на ассемблере, где все под контролем. Знание ассемблера в любом случае требуется. Но в первом случае требуется знание только ассемблера и процессора, а во втором — еще и знание тонкостей компилятора и/или библиотек. Что проще?
kosmos89
13.09.2016 14:27+2только MSVC не умеет компилировать ассемблерные вставки для x64 и ARM.
MichaelBorisov
13.09.2016 22:30Я забыл уточнить, что разрабатываемая программа была предназначена для испытаний некоего железа, и она должна была работать именно и только на отдельно взятом компьютере — том, который стоял у меня на столе. Надеюсь, вы не станете утверждать, что при разработке такой программы необходимо обеспечить ее портируемость? Или что мне надо было купить более быстрый комп?
khim
13.09.2016 19:17+1Вы считаете, что это быстрее, чем написать внутренний цикл на ассемблере?
Я считаю что если вас волнует скорость работы вашей программы то первым делом нужно выкинуть никуда негодный интсрумент (MSVC) и взять годный (Intel C++ или Clang). Потом заниматься чем-то ещё.
Если я знаю и умею, как написать на ассемблере быстрый код, и это быстрее, чем найти способ «подшаманить» C-код так, чтобы компилятор его хорошо скомпилировал — то почему не сделать на ассемблере?
Потому что всю программу вы не сможете писать на ассемблере. И «подшаманивать» код не нужно — достаточно сделать так, чтобы его можно выло ускорить хитрыми манипуляциями не меняя семантики — дальнейшее приличные компиляторы сделают за вас. Ещё раз, для тех кто в танке: MSVC приличным компилятором не является и никогда не являлся (хотя потихоньку движется в этом направлении — но качество генерируемого кода для его разработчиков имеет явно не самый высокий приоритет).
P.S. Есть случаи, когда даже clang, gcc и intel compiler не умеют генерировать хороший код (работа с битовыми массивами, например). В этом случае ассемблерные вставки вполне уместны.MichaelBorisov
13.09.2016 22:56первым делом нужно выкинуть никуда негодный интсрумент (MSVC) и взять годный (Intel C++ или Clang)
В общем случае — может быть. Но я решал частную задачу. И я ее решил наиболее быстрым и дешевым из доступных способов. Intel C++ стоит немалых денег. Clang нужно было ставить, портировать программу под него и испытывать. На это нужно время. Значительно большее, чем занимает написание на ассемблере внутреннего цикла LFSR. А что если бы и Clang не смог ускорить программу необходимым образом? Откуда мне было знать, может он это или нет? Вот в данном конкретном случае люди подсказали, что он может. Интересно, в 2014 мог ли? А ведь есть и другие случаи оптимизации, когда и Clang/Intel C++ не поможет. И что тогда? Так что ваше решение даже как общее не всегда годится. Оно затратнее.
Потому что всю программу вы не сможете писать на ассемблере.
Я этого и не делал. Я написал на ассемблере только коротенькую процедуру.
И «подшаманивать» код не нужно — достаточно сделать так, чтобы его можно выло ускорить хитрыми манипуляциями не меняя семантики — дальнейшее приличные компиляторы сделают за вас.
То, что вы описали, я и имел в виду под «подшаманить». Подумайте: чтобы написать C-код таким образом, чтобы компилятор смог его ускорить хитрыми манипуляциями, необходимо: 1) знать ассемблер и тонкости работы процессора; 2) знать, как данный конкретный компилятор компилирует те или иные конструкции языка в ассемблер, особенно те моменты, которые могут повлиять на возможность оптимизации; 3) написать программу, проверить с помощью дизассемблера, как она компилируется, и если не так, как хочется — то продолжать «шаманить»; 4) при необходимости сменить компилятор и вернуться к п. 2).
Это затратнее и по времени на подготовку, и по времени собственно работы. Даже по деньгам затратно (если требуется покупать лицензию на дорогой компилятор). Напротив, для написания нужного фрагмента на ассемблере требуется осуществить только п. 1).
Добавлю, что иногда оптимизация не помогает — код не удается ускорить в достаточной степени ни с помощью компилятора, ни с помощью ассемблера. В таких случаях приходится искать другие решения. Такие, как отказ от обработки данных в реальном времени, покупка вычислительных мощностей и т.д. И если действительно окажется, что оптимизация не помогает — то желательно это выяснить как можно раньше, чтобы избежать лишних затрат на нее времени и денег.

0xd34df00d
16.09.2016 22:30Есть случаи, когда даже clang, gcc и intel compiler не умеют генерировать хороший код (работа с битовыми массивами, например). В этом случае ассемблерные вставки вполне уместны.
Лучше уж интринсики, ИМХО. Больше информации для аллокатора регистров у компилятора, больше типобезопасность, ну и всё такое.electronus
13.01.2017 04:47Как говорится: всегда найдется альтернатива на 555 для проекта на контроллере:
http://www.reuk.co.uk/wordpress/storage/battery-desulfation/
В Вашем случае можно сделать детектор/индикатор пикового напряжения на АЦП, а 555-ку эмулировать цифровым пином.
Хорошего дня
chabapok
13.09.2016 15:00а что за трюк? Если я не забыл, такая команда выставит флаг нуля и сбросит флаг переноса — независимо от того, что было в регистре А. И что дальше? Все равно же нужен переход.
К тому же — в чем смысл? На Z80 каждая команда занимает свое фиксированное кол-во тактов, которое задокументировано. Там надо избавляться от тактов, а не от переходов.MichaelBorisov
14.09.2016 01:19+1Трюк в том, что будет в регистре eax после выполнения этой команды. Поскольку число вычитается само из себя — то результат был бы всегда 0, но команда sbc учитывает значение флага переноса ©. Если C=1, то в регистре после вычитания окажутся все единицы — 0xFFFFFFFF. Если C=0, то будет 0. После этого можно выполнить команду AND с константой. Таким образом, в eax будет либо 0, либо эта константа. Потом с ней ксорим состояние LFSR. Ксор регистра с нулем не изменяет его значение. Вот и получается, что мы либо ксорим регистр с константой, либо не ксорим, что и требовалось. И все без переходов.
Что же касается Z80, то там на переходы тоже требуется время (такты), хоть и фиксированное. Избавление от переходов = экономия тактов. Также облегчается выравнивание веток по количеству тактов, если это требуется для процедур реального времени, таких, как работа с магнитофоном или звуком.
MichaelBorisov
14.09.2016 01:33+1вот пример для Z80 решения задачи: загрузить в аккумулятор число 1 либо число 6 в зависимости от состояния флага C:
SBC A,A AND 7 XOR 1
Выполняется всегда за 18 тактов. С условными переходами было бы что-то вроде:
JP NC,XXX LD A,6 JP YYY XXX: LD A,1 YYY:
Это выполняется за 17 либо за 27 тактов, в среднем 22 (если оба значения флага C при входе в программу равновероятны).
khim
12.09.2016 23:57Внутренний цикл LFSR Галуа проверяет равенство младшего бита нулю и в зависимости от этого ксорит или не ксорит содержимое регистра с константой.
Вы имеете в виду что-то подобное, как я понял:
constexpr int xor_const = 57; int foo(unsigned int a, unsigned int b) { return a ^ ((b & 1) ? 0 : 57); }
Так вроде бы компилятор с этим отлично справляется:
$ g++ -std=c++11 -O3 -S test.c -o- | c++filt .file "test.c" .text .p2align 4,,15 .globl foo(unsigned int, unsigned int) .type foo(unsigned int, unsigned int), @function foo(unsigned int, unsigned int): .LFB0: .cfi_startproc andl $1, %esi cmpl $1, %esi sbbl %eax, %eax andl $57, %eax xorl %edi, %eax ret .cfi_endproc .LFE0: .size foo(unsigned int, unsigned int), .-foo(unsigned int, unsigned int) .ident "GCC: (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4" .section .note.GNU-stack,"",@progbits
Зачем тут ассемблер? Избавление от условного перехода — штука хорошая, но в ассеблер-то сразу зачем ударяться?MichaelBorisov
13.09.2016 02:01Мой компилятор (VS 2013) на момент написания программы (2014г) такого не сумел. Может быть, нужно было написать C-код с какими-то плясками с бубном, чтобы он смог оптимизировать, но я такой вариант не нашел. Может быть, это мог уже тогда GCC или LLVM, но… Скажу честно, мне проще и быстрее написать на ассемблере, чем выяснять, какой компилятор умеет делать такую оптимизацию и как надо писать C-код, чтобы он это сделал.
Я вообще не понимаю стремления «избавиться от ассемблера во что бы то ни стало». Может быть, для тех, кто с ассемблером знаком чисто теоретически, такой совет и полезен. Но не для меня. Я на нем писал большие и сложные программы много лет.khim
13.09.2016 19:19Может быть, для тех, кто с ассемблером знаком чисто теоретически, такой совет и полезен.
Такой совет полезен для тех, кто работает в команде. Где, ужас, да, бывают люди, не знающие x86 ассемблера, а знающие ассемлер SPARC или там PowerPC. А C — у них у всех один.MichaelBorisov
15.09.2016 20:42Вы, случайно, не из тех людей, кто рекомендует писать программу «Hello World» в стиле "Enterprise"?
Упомянутая программа писалась мной единолично и для личного же применения. Вы этого не учли.
KF-121
13.09.2016 00:35+1в функциях combine3 и combine4 переменная i объявляется 2 раза. статья норм.

Siemargl
13.09.2016 00:35+1Хорошая статья и просто написано. Жаль не указана версия gcc, но с векторизацией что gcc что msvc пока только делают первые робкие шаги.
VaalKIA
13.09.2016 01:32С интересом прочёл про реассоциацию и условное копирование, такие простые вещи я не знал. Но постоянное в статье: «оптимизируем цикл на несколько циклов» это просто жесть, программисты узнают слово такты, раньше чем начинают учить ассемблер и это статья от программиста!?

Jef239
13.09.2016 06:13+1«Поскольку не все наши лентопротяжные устройства были в порядке, я в срочном порядке был призван к порядку, чтобы сортировать данные разных порядков на несколько порядков быстрее.» Если не ошибаюсьэто Хигмана «Сравнительное изучение языков программирования», 1969 год

SergeySib
13.09.2016 06:48+3Автор, спасибо за статью! Хотелось бы добавить небольшое уточнение:
Компилятор не может точно знать, будут ли два указателя указывать на одну и ту же область памяти, и поэтому не выполняет некоторые оптимизации.
Может. Стандарт С99 ввёл ключевое слово restrict, которое сообщает компилятору, что области памяти не могут пересекаться. Разумеется, ответственность за непересечение ложится на программиста, но компилятор может применять оптимизации «как в Фортране». В С++ это ключевое слово так и не попало, но разработчики компиляторов его часто реализуют в виде расширения, например __restrict__ в GCC.
Jef239
13.09.2016 06:51+3> Компиляторы могут применять только безопасные оптимизации. Это значит, что компилятор может изменять программу только так, чтобы это не изменило её поведение для всех входных данных.
Это несколько упрощенно.
1) Поведение может быть изменено для ситуации, не документированной в стандарте. Как пример — gcc 6.1 при -O2 выкидывает проверки this на NULL.
https://habrahabr.ru/company/abbyy/blog/308346/
2) Компилятор может выкинуть memset, используемый для очистки автоматической переменной от чувствительных данных (например, паролей). Ну и вообще плохо понимает, что кроме программы — есть ещё и окружение.
http://www.viva64.com/ru/d/0208/
3) gcc, начиная с -O2 использует strict-aliasing, то есть подразумевает, что в разных параметрах указатели указывают на разную память.
https://habrahabr.ru/post/114117/
4) В оптимизаторе могут быть ошибки. То есть автор оптимизации считает, что она безопасна, а на самом деле — не так. И в некоторых случаях это приводит к катастрофе. Классический пример — FORTRAN OE на OS 360, который выкидывал проверку на делителя на ноль. Точнее сначала делил, а потом уже проверял, не равен ли нуля делитель. Это у него так оптимизация общих подвыражений отработала.
5) -Ofast в gcc включает, например, такую небезопасные оптимизации, как -funsafe-math-optimizations и -fno-math-errno
Так что вариантов, как получить небезопасную оптимизацию — много. Мораль простая — отлаживаться сразу на нужном уровне оптимизации.khim
13.09.2016 19:28+2Поведение может быть изменено для ситуации, не документированной в стандарте.
Не может.
Как пример — gcc 6.1 при -O2 выкидывает проверки this на NULL.
Эта ситуация документирована в стандарте. В правильно написанной программе она возникать не должна.
Компилятор может выкинуть memset, используемый для очистки автоматической переменной от чувствительных данных (например, паролей).
Эта ситуация также документирована, да.
gcc, начиная с -O2 использует strict-aliasing, то есть подразумевает, что в разных параметрах указатели указывают на разную память.
И это — тоже задокументеровано.
В оптимизаторе могут быть ошибки.
И не только в оптимизаторе. В любой программе на сотни тысяч строк могут встречаться ошибки, увы.
Мораль простая — отлаживаться сразу на нужном уровне оптимизации.
Да, причина тут другая: очень много вещей в разных библиотеках C++ рассчитаны на то, что компилятор будет оптимизировать программу. Оптимизируя программу под -O0 вы породите кучу ужаса…Jef239
14.09.2016 04:09-1Опровержение простое — https://habrahabr.ru/post/136283/ — посмотрите на пример 2. Ну и на https://habrahabr.ru/post/216189/ на разделение между undefined, unspecified и implementation-defined. Для undefined — поведение может меняться между неоптимизированным и оптимизированным кодом.
Насчет кучи ужаса — очень спорно. Оптимизируя алгоритм — я иногда получаю выигрыш по скорости в тысячу раз. А оптимизация компилятора — дает процентов 5-10 общего времени выполнения программы. Если у вас медленный кусок исполняется миллион раз в цикле — оптимизация сильно поможет. А если исполняется один раз — вы этого не заметите.
Ну ещё одно. Ориентация на возможности оптимизатора — это привязка к конкретному компилятору. Если нужна переносимость — лучше не закладываться на наличие оптимизаций. А inline — это не оптимизация, это свойство языка такое. Его как раз есть смысл всегда включать.khim
16.09.2016 16:13Для undefined — поведение может меняться между неоптимизированным и оптимизированным кодом.
И любое из них будет корректным. Я уже писал статью про это: неопределённого поведения в программе быть не должно. Точка. Есть разные интсрументы, помогающие это реализовать, но если ваша программа содержит в себе неопределённое поведение, то вы ССЗБ.
А оптимизация компилятора — дает процентов 5-10 общего времени выполнения программы.
Вы это серьёзно? Вы вообще когда-нибудь что-нибудь бенчмаркали? -O2 от -O0 отличается в типичном случае раза в 2-3, а иногда разница может быть и десятикратной.
Ориентация на возможности оптимизатора — это привязка к конкретному компилятору. Если нужна переносимость — лучше не закладываться на наличие оптимизаций.
О как. А ничего что вся стандартная библиотека завязана на предположения о том, что оптимизирующий компилятор сделает с программой? Снизу доверху? Все эти iterator_traits и std::begin без приличного оптимизатора смысла не имеют.
А inline — это не оптимизация, это свойство языка такое.
О как. Ну ладно.
Его как раз есть смысл всегда включать.
А зачем? В соответствии со спецификациями от него одни беды: нужно убеждаться что разные модули включают одно и то же определение, что нет никаких конфликтов и т.д. и т.п. При этом на скорость работы программы это не влияет никак. Компилятор интерпретирующийinlineкакsatic— является полностью соответствующим стандарту, а вы же сами сказали, что завязываться на свойства конкретного компилятора как бы нехорошо.

Tujh
13.09.2016 08:36+2Надеялся почитать в такой же лёгкой манере про «SSE или AVX» — не написали. Жаль. Буду ждать продолжения про векторизацию вычислений.

fishca
13.09.2016 09:41-1Все программы должны быть корректными, но некоторые программы должны быть быстрыми.
Почему собственно некоторые? Если бы все были быстрыми — может наступило бы счастье?Tujh
13.09.2016 11:43+1Встречный вопрос, нужно ли программе быть настолько быстрой, если через такт она ждёт ответа от периферии? Требуется ли быть максимально быстрой программе, которая запускается один раз в день, глубокой ночью, и формирует суточные отчёты о проделанной работе (30 минут или 40 она проработает тут разницы нет).
fishca
13.09.2016 13:46а почему она ждет ответа от периферии?
может потому что драйвер периферии корректный, но медленный ;)?Tujh
13.09.2016 13:56+2А может потому что периферия — это механические детали, сервоприводы и т.п., которые требуют время на выполнение своих действий?
Jef239
13.09.2016 23:44Потому что физические процессы таковы. что скорость не нужна. Можно измерять температуру больного каждую миллисекунду, но чаще раза в минуту это в принципе никому не нужно.
fishca
14.09.2016 15:38Я бы например не отказался в онлайне видеть свою температуру. И в пределах минуты разве не может быть скачков температуры, а вдруг это проявление симптомов какой-то болезни, а мы это пропустим.
Jef239
14.09.2016 16:08Теплоемкость тела слишком велика. И цепи обратной связи медленные.За минуту можно разогреть локально ладошку, но не весь организм. Чуть подробнее http://biofile.ru/chel/1975.html Скачок — это минут за 15. Но пусть медики уточнят.

lazalu68
13.09.2016 14:15Ну тут дело не в том, что надо каждый код вылизывать подобным образом отдельно, а в том что можно (и может быть даже нужно) использовать паттерны эффективного программирования вообще.
То есть вы не оптимизируете алгоритмы в своей программе для отчетов один раз в день глубокой ночью, а просто изначально пишете эту программу с использованием пресловутых паттернов. Ну и вообще, везде их используете)
Jef239
13.09.2016 23:30Потому что скорость многих программ определяется скоростью прокладки между экраном и клавиатурой. Или скоростью прихода данных. И вместо быстроты используется критерий требовательности к ресурсам процессора и памяти. И, если ресурсов хватает, намного важнее требование надежности работы. Или требование не задирать цену разработки.
Мы можем сделать быстро, качественно, дешево — выбирайте два из трех. Как правило — лучше дешево и качественно. Выполнение программы в 10 раз быстрее — это часто экономия 9 миллисекунд раз в минуту.

ivanius
13.09.2016 14:15Спасибо огромное за статью — некоторые вещи делал не задумываясь, а теперь понял что к чему (учителя не объясняли — а говорили:«Так нужно делать и все»). Добавил в свою мини библиотеку полезных вещей. Очень жду следующую часть.
kosmos89
13.09.2016 14:41>Компилятору тяжело определить, имеет вызов функции побочные эффекты или нет.
Ой чёйто? Ему это довольно просто определить. Но в некоторых редких случаях, когда хотя бы часть f() линкуется динамически, ему это сделать вообще невозможно*.
horowitz
13.09.2016 15:32Я верю профессорам Carnegie Mellon, которые написали книгу, которая вдохновила эту статью. Они в своей книге написали, что компилятору часто трудно это сделать (имеется вообще, а не в отношении моего примера).
kosmos89
13.09.2016 15:40Можно ссылку или хотя бы название?
horowitz
13.09.2016 15:55В начале статьи книга упоминается. Computer Systems: A Programmer's Perspective. Пятая глава про оптимизацию.
kosmos89
13.09.2016 17:31+1Извините, читал вступление по диагонали :)
В книге, во всех трех изданиях написано:
>Most compilers do not try to determine whether a function is free of side effects and hence is a candidate for optimizations such as those attempted in func2. Instead, the compiler assumes the worst case and leaves all function calls intact.
Что переводится как «Большинство компиляторов НЕ ПЫТАЮТСЯ определить, имеет ли функция побочные эффекты...». Так что утверждение «тяжело определить» не имеет под собой оснований. Эта цитата кочует из издания к изданию с 2001 года, но разработчики компиляторов не даром свой хлеб едят и за 15 лет таки наверняка этот анализ добавили. Более того, в третьем издании таки сказано, что GCC встраивает f() и поэтому имеет все возможности для оптимизации (хотя вышеприведенный абзац все равно там остался).
kosmos89
13.09.2016 15:32+1>Считывание инструкций наперёд называется предвыборкой. Если во время предвыборки, процессор встречает ветвление (к примеру, конструкция if-else), он пытается угадать, какая ветвь будет взята и считывает инструкции оттуда.
Предвыборка — это считывание [в нашем случае] инструкций в кэш кода. Во время нее никакого анализа на ветвления не производится. А то, что вы назвали «предвыборкой» на самом деле просто «конвейерное исполнение».
А попытка исполнения предсказанной ветви называется спекулятивным исполнением.
kosmos89
13.09.2016 16:38+1>cmove
>тернарный оператор
Да что же у вас за конпелятор такой тупой?! У меня на простом примере обе версии транслировались в ИДЕНТИЧНЫЙ код. Для разных уровней оптимизации он был разный, либо с cmove, либо без, но всегда ОДИНАКОВЫЙ. Вот, смотрите: https://godbolt.org/g/n9kaSN
Более того, переписав кода как вы сказали, вы, скорее всего, заставите компилятор вычислять оба подвыражения ВСЕГДА, хотя это компилятор должен решать, когда ему выгодней вычислить одну ветку, но с условным переходом, а когда обе, но с cmove.horowitz
13.09.2016 18:06gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4
Коммпилятор не всегда решает рравильно. Компилятор может решить не использовать cmov, хотя при использовании программа работала бы чуть быстрее.kosmos89
13.09.2016 18:17Я ссылку привел на онлайн компилятор. Сейчас попробовал выставить там x86-64 gcc 4.8.4, но на нем результат такой же.
>чуть быстрее
Скорее всего только на вашем процессоре. А если ошибка существенная, то это просто недоработка/баг в компиляторе.
Это только Интеловский компилятор может точно* посчитать, что сколько на каком их процессоре будет выполняться. Остальные компиляторы могут только прикидывать. Так же как и вы.
DrSmile
13.09.2016 19:59Просто автор один из тех, кто занимается оптимизацией DEBUG-сборки:
Все программы в этой статье мы будем компилировать при помощи GCC с параметром -Og (базовый уровень оптимизации).
horowitz
14.09.2016 03:56Цель статьи и примеров — продемонстрировать техники оптимизации. Какие из них будут работать на вашей машине с вашим процесором и компилятором смотреть вам.

remirran
13.09.2016 21:05Спасибо за статью! На днях разбирал функцию преобразования картинки с камеры (YUYV -> YV12) и думал почему нельзя было выполнить всё в один проход for, а разбивать на 4 идентичных участка внутри одного цикла. Теперь всё встало на свои места.

bogolt
14.09.2016 10:57Интересно что на моем AMD 8350 функция combine4 с четырьмя аккумуляторами работает значительно медленнее чем та которая все перемножает в один цикл. На интеле же все соответствует ожидаемому результату.
Foolleren
15.09.2016 14:16потому что float, попробуйте что-нибудь целочисленное, результат будет веселее.
Akon32
Спасибо за статью.
Читал, что в суперскалярных процессорах (по крайней мере, начиная с Pentium) число физических регистров существенно превышает число архитектурных (физических несколько сотен, архитектурных 16). Почему ухудшение производительности у вас проявлялось при 20 аккумуляторах? Можете нащупать границу более точно? Возможно, производительность ограничивалась чем-то другим?
khim
Производительность ограничивается именно архитектурными регистрами. Физические регистры компилятор использовать не может, их может только сам процессор использовать для своих внутренних оптимизаций, потому когда счётчиков становится много компилятору ничего не остаётся кроме как сложить их на стек. А дальше — читайте раздел про указатели, но уже применительно к «оптимизирующему» процессору, а не оптимизирующему компилятору.