
В действительности система памяти образует иерархию устройств хранения с разными ёмкостями, стоимостью и временем доступа. Регистры процессора хранят наиболее часто используемые данные. Маленькие быстрые кэш-памяти, расположенные близко к процессору, служат буферными зонами, которые хранят маленькую часть данных, расположеных в относительно медленной оперативной памяти. Оперативная память служит буфером для медленных локальных дисков. А локальные диски служат буфером для данных с удалённых машин, связанных сетью.
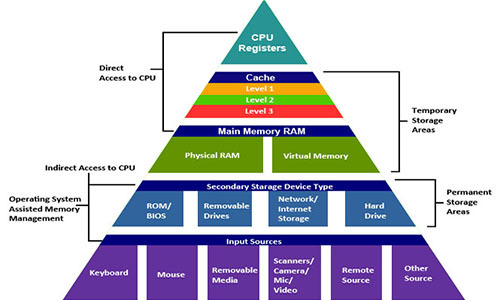
Иерархия памяти работает, потому что хорошо написанные программы имеют тенденцию обращаться к хранилищу на каком-то конкретном уровне более часто, чем к хранилищу на более низком уровне. Так что хранилище на более низком уровне может быть медленнее, больше и дешевле. В итоге мы получаем большой объём памяти, который имеет стоимость хранилища в самом низу иерархии, но доставляет данные программе со скоростью быстрого хранилища в самом верху иерархии.
Как программист, вы должны понимать иерархию памяти, потому что она сильно влияет на производительность ваших программ. Если вы понимаете как система перемещает данные вверх и вниз по иерархии, вы можете писать такие программы, которые размещают свои данные выше в иерархии, так что процессор может получить к ним доступ быстрее.
В этой статье мы исследуем как устройства хранения организованы в иерархию. Мы особенно сконцентрируемся на кэш-памяти, которая служит буферной зоной между процессором и оперативно памятью. Она оказывает наибольшее влияние на производительность программ. Мы введём важное понятие локальности, научимся анализировать программы на локальность, а также изучим техники, которые помогут увеличить локальность ваших программ.
На написание этой статьи меня вдохновила шестая глава из книги Computer Systems: A Programmer's Perspective. В другой статье из этой серии, «Оптимизация кода: процессор», мы также боремся за такты процессора.
Память тоже имеет значение
Рассмотрим две функции, которые суммируют элементы матрицы. Они практически одинаковы, только первая функция обходит элементы матрицы построчно, а вторая — по столбцам.
int matrixsum1(int size, int M[][size])
{
int sum = 0;
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
sum += M[i][j]; // обходим построчно
}
}
return sum;
}
int matrixsum2(int size, int M[][size])
{
int sum = 0;
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
sum += M[j][i]; // обходим по столбцам
}
}
return sum;
}
Обе функции выполняют одно и то же количество инструкций процессора. Но на машине с Core i7 Haswell первая функция выполняется в 25 раз быстрее для больших матриц. Этот пример хорошо демонстрирует, что память тоже имеет значение. Если вы будете оценивать эффективность программ только в терминах количества выполняемых инструкций, вы можете писать очень медленные программы.
Данные имеют важное свойство, которое мы называем локальностью. Когды мы работаем над данными, желательно чтобы они находились в памяти рядом. Обход матрицы по столбцам имеет плохую локальность, потому что матрица хранится в памяти построчно. О локальности мы поговорим ниже.
Иерархия памяти
Современная система памяти образует иерархию от быстрых типов памяти маленького размера до медленных типов памяти большого размера. Мы говорим, что конкретный уровень иерархии кэширует или является кэшем для данных, расположенных на более низком уровне. Это значит, что он содержит копии данных с более низкого уровня. Когда процессор хочет получить какие-то данные, он их сперва ищет на самых быстрых высоких уровнях. И спускается на более низкие, если не может найти.
На вершине иерархии находятся регистры процессора. Доступ к ним занимает 0 тактов, но их всего несколько штук. Далее идёт несколько килобайт кэш-памяти первого уровня, доступ к которой занимает примерно 4 такта. Потом идёт пара сотен килобайт более медленной кэш-памяти второго уровня. Потом несколько мегабайт кэш-памяти третьего уровня. Она гораздо медленней, но всё равно быстрее оперативной памяти. Далее расположена относительно медленная оперативная память.
Оперативную память можно рассматривать как кэш для локального диска. Диски это рабочие лошадки среди устройств хранения. Они большие, медленные и стоят дёшево. Компьютер загружает файлы с диска в оперативную память, когда собирается над ними работать. Разрыв во времени доступа между оперативной памятью и диском колоссальный. Диск медленнее оперативной памяти в десятки тысяч раз, и медленнее кэша первого уровня в миллионы раз. Выгоднее обратиться несколько тысяч раз к оперативной памяти, чем один раз к диску. На это знание опираются такие структуры данных, как B-деревья, которые стараются разместить больше информации в оперативной памяти, пытаясь избежать обращения к диску любой ценой.
Локальный диск сам может рассматриваться как кэш для данных, расположенных на удалённых серверах. Когда вы посещаете веб-сайт, ваш браузер сохраняет изображения с веб-страницы на диске, чтобы при повторном посещении их не нужно было качать. Существуют и более низкие иерархии памяти. Крупные датацентры, типа Google, сохраняют большие объёмы данных на ленточных носителях, которые хранятся где-то на складах, и когда понадобятся, должны быть присоеденены вручную или роботом.
Современная система имеет примерно такие характеристики:
| Тип кэша | Время доступа (тактов) | Размер кэша |
|---|---|---|
| Регистры | 0 | десятки штук |
| L1 кэш | 4 | 32 KB |
| L2 кэш | 10 | 256 KB |
| L3 кэш | 50 | 8 MB |
| Оперативная память | 200 | 8 GB |
| Буфер диска | 100'000 | 64 MB |
| Локальный диск | 10'000'000 | 1000 GB |
| Удалённые сервера | 1'000'000'000 | ? |
Быстрая память стоит очень дорого, а медленная очень дёшево. Это великая идея архитекторов систем совместить большие размеры медленной и дешёвой памяти с маленькими размерами быстрой и дорогой. Таким образом система может работать на скорости быстрой памяти и иметь стоимость медленной. Давайте разберёмся как это удаётся.
Допустим, ваш компьютер имеет 8 ГБ оперативной памяти и диск размером 1000 ГБ. Но подумайте, что вы не работаете со всеми данными на диске в один момент. Вы загружаете операционную систему, открываете веб-браузер, текстовый редактор, пару-тройку других приложений и работаете с ними несколько часов. Все эти приложения помещаются в оперативной памяти, поэтому вашей системе не нужно обращаться к диску. Потом, конечно, вы закрываете одно приложение и открываете другое, которое приходится загрузить с диска в оперативную память. Но это занимает пару секунд, после чего вы несколько часов работаете с этим приложением, не обращаясь к диску. Вы не особо замечаете медленный диск, потому что в один момент вы работаете только с небольшим бъёмом данных, которые кэшируются в оперативной памяти. Вам нет смысла тратить огромные деньги на установку 1024 ГБ оперативной памяти, в которую можно было бы загрузить содержимое всего диска. Если бы вы это сделали, вы бы почти не заметили никакой разницы в работе, это было бы «деньги на ветер».
Так же дело обстоит и с маленькими кэшами процессора. Допустим вам нужно выполнить вычисления над массивом, который содержит 1000 элементов типа int. Такой массив занимает 4 КБ и полностью помещается в кэше первого уровня размером 32 КБ. Система понимает, что вы начали работу с определённым куском оперативной памяти. Она копирует этот кусок в кэш, и процессор быстро выполняет действия над этим массивом, наслаждаясь скоростью кэша. Потом изменённый массив из кэша копируется назад в оперативную память. Увеличение скорости оперативной памяти до скорости кэша не дало бы ощутимого прироста в производительности, но увеличило бы стоимость системы в сотни и тысячи раз. Но всё это верно только если программы имеют хорошую локальность.
Локальность
Локальность — основная концепция этой статьи. Как правило, программы с хорошей локальностью выполняются быстрее, чем программы с плохой локальностью. Локальность бывает двух типов. Когда мы обращаемся к одному и тому же месту в памяти много раз, это временнaя локальность. Когда мы обращаемся к данным, а потом обращаемся к другим данным, которые расположены в памяти рядом с первоначальными, это пространственная локальность.
Рассмотрим, программу, которая суммирует элементы массива:
int sum(int size, int A[])
{
int i, sum = 0;
for (i = 0; i < size; i++)
sum += A[i];
return sum;
}
В этой программе обращение к переменным sum и i происходит на каждой итерации цикла. Они имеют хорошую временную локальность и будут расположены в быстрых регистрах процессора. Элементы массива A имеют плохую временную локальность, потому что к каждому элементу мы обращаемся только по разу. Но зато они имеют хорошую пространственную локальность — тронув один элемент, мы затем трогаем элементы рядом с ним. Все данные в этой программе имеют или хорошую временную локальность или хорошую пространственную локальность, поэтому мы говорим что программа в общем имеет хорошую локальность.
Когда процессор читает данные из памяти, он их копирует в свой кэш, удаляя при этом из кэша другие данные. Какие данные он выбирает для удаления тема сложная. Но результат в том, что если к каким-то данным обращаться часто, они имеют больше шансов оставаться в кэше. В этом выгода от временной локальности. Программе лучше работать с меньшим количеством переменных и обращаться к ним чаще.
Перемещение данных между уровнями иерархии осуществляется блоками определённого размера. К примеру, процессор Core i7 Haswell перемещает данные между своими кэшами блоками размером в 64 байта. Рассмотрим конкретный пример. Мы выполняем программу на машине с вышеупомянутым процессором. У нас есть массив v, содержащий 8-байтовые элементы типа long. И мы последовательно обходим элементы этого массива в цикле. Когда мы читаем v[0], его нет в кэше, процессор считывает его из оперативной памяти в кэш блоком размером 64 байта. То есть в кэш отправляются элементы v[0]–v[7]. Далее мы обходим элементы v[1], v[2], ..., v[7]. Все они будут в кэше и доступ к ним мы получим быстро. Потом мы читаем элемент v[8], которого в кэше нет. Процессор копирует элементы v[8]–v[15] в кэш. Мы быстро обходим эти элементы, но не находим в кэше элемента v[16]. И так далее.
Поэтому если вы читаете какие-то байты из памяти, а потом читаете байты рядом с ними, они наверняка будут в кэше. В этом выгода от пространственной локальности. Нужно стремиться на каждом этапе вычисления работать с данными, которые расположены в памяти рядом.
Желательно обходить массив последовательно, читая его элементы один за другим. Если нужно обойти элементы матрицы, то лучше обходить матрицу построчно, а не по столбцам. Это даёт хорошую пространственную локальность. Теперь вы можете понять, почему функция matrixsum2 работала медленнее функции matrixsum1. Двумерный массив расположен в памяти построчно: сначала расположена первая строка, сразу за ней идёт вторая и так далее. Первая функция читала элементы матрицы построчно и двигалась по памяти последовательно, будто обходила один большой одномерный массив. Эта функция в основном читала данные из кэша. Вторая функция переходила от строки к строке, читая по одному элементу. Она как бы прыгала по памяти слева-направо, потом возвращалась в начало и опять начинала прыгать слева-направо. В конце каждой итерации она забивала кэш последними строками, так что в начале следующей итерации первых строк кэше не находила. Эта функция в основном читала данные из оперативной памяти.
Дружелюбный к кэшу код
Как программисты вы должны стараться писать код, который, как говорят, дружелюбный к кэшу (cache-friendly). Как правило, основной объём вычислений производится лишь в нескольких местах программы. Обычно это несколько ключевых функций и циклов. Если есть вложенные циклы, то внимание нужно сосредоточить на самом внутреннем из циклов, потому что код там выполняется чаще всего. Эти места программы и нужно оптимизировать, стараясь улучшить их локальность.
Вычисления над матрицами очень важны в приложениях анализа сигналов и научных вычислениях. Если перед программистами встанет задача написать функцию перемножения матриц, то 99.9% из них напишут её примерно так:
void matrixmult1(int size, double A[][size], double B[][size], double C[][size])
{
double sum;
for (int i = 0; i < size; i++)
for (int j = 0; j < size; j++) {
sum = 0.0;
for (int k = 0; k < size; k++)
sum += A[i][k]*B[k][j];
C[i][j] = sum;
}
}
Этом код дословно повторяет математическое определение перемножения матриц. Мы обходим все элементы окончательной матрицы построчно, вычисляя каждый из них один за другим. В коде есть одна неэффективность, это выражение B[k][j] в самом внутреннем цикле. Мы обходим матрицу B по стобцам. Казалось бы, ничего с этим не поделаешь и придётся смириться. Но выход есть. Можно переписать то же вычисление по другому:
void matrixmult2(int size, double A[][size], double B[][size], double C[][size])
{
double r;
for (int i = 0; i < size; i++)
for (int k = 0; k < size; k++) {
r = A[i][k];
for (int j = 0; j < size; j++)
C[i][j] += r*B[k][j];
}
}
Теперь функция выглядит очень странно. Но она делает абсолютно то же самое. Только мы не вычисляем каждый элемент окончательной матрицы за раз, мы как бы вычисляем элементы частично на каждой итерации. Но ключевое свойство этого кода в том, что во внутреннем цикле мы обходим обе матрицы построчно. На машине с Core i7 Haswell вторая функция работает в 12 раз быстрее для больших матриц. Нужно быть действительно мудрым программистом, чтобы организовать код таким образом.
Блокинг
Существует техника, которая называется блокинг. Допустим вам надо выполнить вычисление над большим объёмом данных, которые все не помещаются в кэше высокого уровня. Вы разбиваете эти данные на блоки меньшего размера, каждый из которых помещается в кэше. Выполняете вычисления над этими блоками по отдельности и потом объёдиняете результат.
Можно продемонстрировать это на примере. Допустим у вас есть ориентированный граф, представленный в виде матрицы смежности. Это такая квадратная матрица из нулей и единиц, так что если элемент матрицы с индексом (i, j) равен единице, то существует грань от вершины графа i к вершине j. Вы хотите превратить этот ориентированный граф в неориентированный. То есть, если есть грань (i, j), то должна появиться противоположная грань (j, i). Обратите внимание, что если представить матрицу визуально, то элементы (i, j) и (j, i) являются симметричными относительно диагонали. Эту трансформацию нетрудно осуществить в коде:
void convert1(int size, int G[][size])
{
for (int i = 0; i < size; i++)
for (int j = 0; j < size; j++)
G[i][j] = G[i][j] | G[j][i];
}
Блокинг появляется естественным образом. Представьте перед собой большую квадратную матрицу. Теперь иссеките эту матрицу горизонтальными и вертикальными линиями, чтобы разбить её, скажем, на 16 равных блока (четыре строки и четыре столбца). Выберите два любых симметричных блока. Обратите внимание, что все элементы в одном блоке имеют свои симметричные элементы в другом блоке. Это наводит на мысль, что ту же операцию можно совершать над этими блоками поочерёдно. В этом случае на каждом этапе мы будем работать только с двумя блоками. Если блоки сделать достаточно маленького размера, то они поместятся в кэше высокого уровня. Выразим эту идею в коде:
void convert2(int size, int G[][size])
{
int block_size = size / 12; // разбить на 12*12 блоков
// представим, что делится без остатка
for (int ii = 0; ii < size; ii += block_size) {
for (int jj = 0; jj < size; jj += block_size) {
int i_start = ii; // индекс i для блока принимает значения [ii, ii + block_size)
int i_end = ii + block_size;
int j_start = jj; // индекс j для блока принимает значения [jj, jj + block_size)
int j_end = jj + block_size;
// обходим блок
for (int i = i_start; i < i_end; i++)
for (int j = j_start; j < j_end; j++)
G[i][j] = G[i][j] | G[j][i];
}
}
}
Нужно заметить, что блокинг не улучшает производительность на системах с мощными процессорами, которые хорошо делают предвыборку. На системах, которые не делают предвыборки, блокинг может сильно увеличить производительность.
На машине с процессором Core i7 Haswell вторая функция не выполняется быстрее. На машине с более простым процессором Pentium 2117U вторая функция выполняется в 2 раза быстрее. На машинах, которые не выполняют предвыборку, производительность улучшилась бы ещё сильнее.
Какие алгоритмы быстрее
Все знают из курсов по алгоритмам, что нужно выбирать хорошие алгоритмы с наименьшей сложностью и избегать плохих алгоритмов с высокой сложностью. Но эти сложности оценивают выполнение алгоритма на теоретической машине, созданной нашей мыслью. На реальных машинах теоретически плохой алгоритм может выполнятся быстрее теоретически хорошего. Вспомните, что получить данные из оперативной памяти занимает 200 тактов, а из кэша первого уровня 4 такта — это в 50 раз быстрее. Если хороший алгоритм часто трогает память, а плохой алгоритм размещает свои данные в кэше, хороший алгоритм может выполняться медленнее плохого. Также хороший алгоритм может выполняться на процессоре хуже, чем плохой. К примеру, хороший алгоритм вносит зависимость данных и не может загрузить конвеер процессора. А плохой алгоритм лишён этой проблемы и на каждом такте отправляет в конвеер новую инструкцию. Иными словами, сложность алгоритма это ещё не всё. Как алгоритм будем выполняться на конкретной машине с конкретными данными имеет значение.
Представим, что вам нужно реализовать очередь целых чисел, и новые элементы могут добавляться в любую позицию очереди. Вы выбираете между двумя реализациями: массив и связный список. Чтобы добавить элемент в середину массива, нужно сдвинуть вправо половину массива, что занимает линейное время. Чтобы добавить элемент в середину списка, нужно дойти по списку до середины, что также занимает линейное время. Вы думаете, что раз сложности у них одинаковые, то лучше выбрать список. Тем более у списка есть одно хорошее свойство. Список может расти без ограничения, а массив придётся расширять, когда он заполнится.
Допустим, очередь длиной 1000 элементов мы реализовали обоими способами. И нам нужно вставить элемент в середину очереди. Элементы списка хаотично разбросаны по памяти, поэтому чтобы обойти 500 элементов, нам понадобится 500*200=100'000 тактов. Массив расположен в памяти последовательно, что позволит нам наслаждаться скоростью кэша первого уровня. Используя несколько оптимизаций, мы можем двигать элементы массива, тратя 1-4 такта на элемент. Мы сдвинем половину массива максимум за 500*4=2000 тактов. То есть быстрее в 50 раз.
Если в предыдущем примере все добавления были бы в начало очереди, реализация со связным списком была бы более эффективной. Если какая-то доля добавлений была бы куда-то в середину очереди, реализация в виде массива могла бы стать лучшим выбором. Мы бы тратили такты на одних операциях и экономили такты на других. И в итоге могли бы остаться в выигрыше.
Заключение
Система памяти организована в виде иерархии устройств хранения с маленькими и быстрыми устройствами вверху иерархии и большими и медленными устройствами внизу. Программы с хорошей локальностью работают с данными из кэшей процессора. Программы с плохой локальностью работают с данными из относительно медленной оперативной памяти.
Программисты, которые понимают природу иерархии памяти, могут структурируют свои программы так, чтобы данные располагались как можно выше в иерархии и процессор получал их быстрее.
В частности, рекомендуются следующие техники:
- Сконцентрируйте ваше внимание на внутренних циклах. Именно там происходит наибольший объём вычислений и обращений к памяти.
- Постарайтесь максимизировать пространственную локальность, читая объекты из памяти последовательно, в том порядке, в котором они в ней расположены.
- Постарайтесь максимизировать временную локальность, используя объекты данных как можно чаще после того, как они были прочитаны из памяти.
Комментарии (90)

easyman
10.10.2016 18:59+7Одна кликабельная картинка лучше тысячи слов!


robert_ayrapetyan
10.10.2016 19:22+6Если честно, такая ужасная картинка хуже тысячи слов.
easyman
10.10.2016 19:28На вкус и цвет фломастеры разные, но я очень рекомендую сходить по ссылке и подвигать слайдер. Заодно, к истории компьютеров в очередной раз приобщитесь, на прогноз посмотрите.
robert_ayrapetyan
10.10.2016 19:59+2Аргументирую — вашу «таблица» ужасна с точки зрения дизайна. Ее просто невозможно прочитать, не решив попутно пару головоломок. Пустота в первом ряду третьего и четвертого столбцах — это глюк? Почему 100 ns — это один синий квадрат, а 125 ns — это пустота? А, это оттого что в третьем столбце уже все в зеленых квадратах… Который равен чему? А, нужно посмотреть в конец синего столбца… Это какая-то головоломка, а не дизайн, который призван разложить все по-полочкам.
Прогноз тоже не впечатляет, через 5 лет практически ничего не поменяется, а дальше неизвестность.easyman
10.10.2016 20:24Согласен.
Я, просто, не видел ничего нагляднее.
А тут ведь ещё бонусом «интерактив» и чуть-чуть истории.
Upd: автор этой странички не я. Я только заскриншотил, «мопед не мой. Но мопед хороший, годный!!!»
maydjin
10.10.2016 22:46+1Есть ещё вот такая аналогия, текстовая:
1 CPU cycle: 0.3 ns => to human scale 1s
L1 cache access: 0.9ns => 3s
L2 cache access: 2.8ns => 9s
L3 cache access: 12.9ns => 43s
Main memory access: 120ns => 6 min
SSD Disk: 50-150 us => 2-6 days
Rotational Disk: 1-10ms => 1-12months
Internet: San Francisco to New york: 40ms => 4 years?
И вот такая вот инфографика.
Вообще — тема довольно избитая :)

ifaustrue
10.10.2016 20:00зато подёргав ручку можно оказаться в будущем или прошлом. sarcasm Удобно
easyman
10.10.2016 20:18Зато понятно, в чем разница между аукционными серваками на hеtzner или low cost от kimsufi и более свежим железом

kasperos
10.10.2016 20:53На вскидку, модуль памяти с tRCmin < 50нс.
В данном графике, скорость памяти зависла на отметке в 100 нс, и меняется только скорость SSD, что наталкивает на заказной характер графика со стороны производителей SSD.
Кроме того на скорость работы памяти (кроме непосредственно характеристик модуля памяти) влияет количество каналов памяти в системе, и оптимизации структур хранения данных под канальность.
beeruser
10.10.2016 21:36http://www.anandtech.com/show/10435/assessing-ibms-power8-part-1/8
Пусть будет 50. Добавьте к этому время кеш-миссов L1-L2-L3kasperos
11.10.2016 07:18+1Там все хитрее, получить данные если блок модуля свободен в данный момент можно через 15-25 нс (включая передачу данных из RAM в кэш). Оперативная память на текущий момент оптимально заточена под последовательное чтение, чуть более менее начинается рандом, начинаются сильные задержки на доступ к данным. Насколько помню у интела есть префиксы обращения к памяти мимо кэша. Есть команды предварительного чтения данных в кэш. Если подойти комплексно то можно сильно оптимизировать, но нужно либо довериться компилятору, либо изучать/вспоминать машинные коды, ну и хорошо понимать как работает аппаратная платформа.

perfect_genius
11.10.2016 11:19Хорошая попытка, именно за такими интерактивными презентациями будущее.
Но конкретно эта — полностью провалена =(
Тут даже с текстом не сразу разобрать что имел в виду автор.
Двигаем ползунок по года и лишь видим, как скорость доступа к данным ускорялась со временем. Для этого лучше бы простой график сделали, и то было бы нагляднее.

highlander12rus
10.10.2016 20:03+2Еще есть хорошая книга по оптимизации кода для разных платформ: «Structured Parallel Programming: Patterns for Efficient Computation».
third112
10.10.2016 21:07-13Как программист, вы должны понимать иерархию памяти, потому что она сильно влияет на производительность ваших программ. Если вы понимаете как система перемещает данные вверх и вниз по иерархии, вы можете писать такие программы, которые размещают свои данные выше в иерархии, так что процессор может получить к ним доступ быстрее.
Как программист, я не должен! Это компилятор должен оптимизировать мой код, и часто у современных компиляторов это не плохо получается. Но как программист имею право отказаться от решений компилятора и попробовать сделать код быстрее. В этом случае статья может помочь, но таких случаев небольшой процент от всех решаемых задач.mayorovp
10.10.2016 21:25+9У компиляторов это получается на уровне переменных. Но компилятор не сможет выбрать направление обхода матрицы.
third112
10.10.2016 21:46+3А Вы уверены, что для другого компилятора на другой платформе выбранное направление обхода будет оптимальным. Как быть с переносимостью, если речь не о программах-однодневках?
third112
10.10.2016 21:54Первая функция читала элементы матрицы построчно и двигалась по памяти последовательно, будто обходила один большой одномерный массив.
Это убедительно. Но ведь это тривиальный случай.mayorovp
10.10.2016 22:09Это довольно частый случай.
third112
10.10.2016 22:52Зависит от круга решаемых задач. Может быть для какого-то типа задач этот случай очень частый, но и там, наверное, далеко не всегда этот участок кода оказывается критичным по скорости. Для разреженных матриц и для параллельных вычислений, наверное, нужны другие приемы и т.д. Впрочем я не настаиваю, просто высказал небольшое сомнение в практической полезности. Существует очень много рекомендаций по оптимизации кода, но, к сожалению, очень часто в этих рекомендациях приводят слишком искусственные примеры. Но, как сказал выше, думаю что в некоторых случаях
статья может помочь
.

0xd34df00d
10.10.2016 22:10+4Если вам нужна максимальная производительность, то вам так или иначе придётся затачиваться под конкретную платформу, а иногда даже под конкретную микроархитектуру (выбирать размер блока, количество операций в развёрнутом цикле, и так далее). В ваших силах, однако, сделать так, чтобы изменять эту «заточку» было легче.
third112
10.10.2016 22:29+2Ok. А теперь сравним, автор статьи написал:
Как программист, вы должны
А Вы написали:
Если вам нужна максимальная производительность
Видите разницу? Я только об этом. Если моя программа работает недостаточно быстро, то мне нужно подумать, как ее ускорить. А если быстро, то не стоит тратить время на ненужное ускорение. Иногда авторы используют неподходящую форму и слова, получая нежелательный для автора эффект.MichaelBorisov
11.10.2016 01:12+1Если моя программа работает недостаточно быстро, то мне нужно подумать, как ее ускорить.
Совершенно верно. И это входит в обязанности программиста.third112
11.10.2016 02:15Да. Входит. Только такое бывает нечасто. В моей практике 90% программ ускорять не нужно, а 9% заметному ускорению не поддаются — такие переборные алгоритмы. Остается 1%, где ускоряем.
0xd34df00d
11.10.2016 03:07В моей практике ускорять нужно где-то 75% программ, но не суть.
Суть в том, что даже переборные алгоритмы в моей практике вполне себе поддаются ускорению, особенно если перебор сводится к вычислению некоторой функции на множестве объектов с варьированием параметров этой функции. Тогда всякими хитростями можно выделить либо вообще инварианты из этой функции, либо подфункции, которые можно эффективно и быстро вычислять с учётом всяких локальностей и прочих подобных описанным в статьях финтов. Но это уже надо сидеть и крепко думать.third112
11.10.2016 12:47И ускоряете весь код или только критические участки? Широко известны утверждения типа:
«обычно 90% кода тратят 10% общего времени работы программы». Для Ваших задач это утверждение справедливо? Если справедливо, то должен ли программист думать об иерархии памяти, когда работает над некритическим участком?0xd34df00d
11.10.2016 18:38Если у меня вся программа расчётная, которая загружает данные, потом сутками что-то считает, потом выплёвывает результат, то да. И вычислительный код при этом занимает добрую часть программы.
third112
11.10.2016 18:50-2И параллелится плохо — на CUDA не сделать? Тогда понятно. Спасибо за ответ.
0xd34df00d
11.10.2016 19:05Параллелится хорошо, отлично даже, но на имеющиеся видеокарты не влезет по памяти, например.
DistortNeo
11.10.2016 21:50+2Вообще-то написание эффективного программного кода требует затрат времени, иногда — очень больших затрат.
Поставить индексы в правильном порядке, сгруппировать данные, поставить parallel.for — эти действия практически не увеличивают время написания программы, зато сильно уввеличивают скорость выполнения. Поэтому программист должен уметь всем этим пользоваться, чтобы в случае, когда придётся писать критический участок, действия были доведены до автоматизма.
А вот выжать максимум — задействовать AVX, переписать код на CUDA может увеличить время разработки в несколько раз, что сведёт на нет выгоду от быстрого выполнения вычислительного кода. Я, например, вычислительные алгоритмы вообще пишу на C#, потому что так быстрее. Когда возникает необходимость ускорить — переписываю на C++ с использованием AVX. CUDA — тяжёлая артиллерия, когда CPU уже мало.

smxfem
12.10.2016 19:25сейчас пишу свою вычислительную балалайку (мкэ, мдтт) и есть всего 2 критических участка. 1 — итерационное решение разреженной СЛАУ с предобуславливанием и 2 — вычисление элементов матрицы СЛАУ, где много вещественных операций, от которых никуда не деться. Первый участок сжирает ~93% времени и второй сжирает ~5% времени (для больших матриц). И самое узкое место — умножение матрицы на вектор — 91% всех вычислений — занимает 23 строки:
// A*x -> y (x !=y !!!!)
void Slau::amulx(const double *x, double *y)
{
int i, j, t;
// y = 0
for (i = 0; i < N; i++)
y[i] = 0;
// вне диагонали
for (j = 0; j < N; j++) // строка номер j
{
for (t = ind[j]; t < ind[j + 1]; t++) // t — индекс элемента j-й строки
{
i = ai[t]; // столбец номер i
// a[t] — элемент A(j, i)
y[j] += a[t] * x[i];// нижний треугольник
y[i] += a[t] * x[j];// верхний треугольник
//printf(«A(%d, %d) = %lf\n», j, i, a[t]);
}
}
// диагональ
for (i = 0; i < N; i++)
y[i] += d[i] * x[i];
}
Скопировал как есть, написано года ~3 назад.
А это <1% кода. Только сейчас задумался, как можно это оптимизировать. В boost строчно-столбцового формата для симметричных матриц вроде бы нет (за бугром его не юзают почти), а на ассемблер лома переписывать и ассемблер — это временное решение.DistortNeo
13.10.2016 09:10+3У вас очень много заблуждений.
1. Переписывание на ассмеблере может дать эффект только если вы программируете под компьютеры 25-летней давной. С современными компиляторами и инструкциями процессоров, скорее всего, сделаете только хуже.
2. Использование свойства симметричности матрицы снижает потребление памяти, но ухудшает производительность. Храните матрицу в общем виде, не используя этого свойства.
3. Попробуйте использовать специализированные оптимизированные библиотеки для решения поставленной задачи (например, Intel MKL), если самостоятельная реализация алгоритмов линейной алгебры не являетсяthird112
13.10.2016 11:01Переписывание на ассмеблере может дать эффект только если вы программируете под компьютеры 25-летней давной. С современными компиляторами и инструкциями процессоров, скорее всего, сделаете только хуже.
И я того же мнения, но всего несколько месяцев прошло как в другой теме меня хором уверяли:
А критические участки реализуют на ассемблере по сей день, и если что — я и мои знакомые можем делать на ассемблере код более быстрый, чем на языке высокого уровня :)
Какие противоположные мнения существуют.
Про MKL. Не всегда помогает. У меня был случай, когда надо было решать очень много небольших (в десяток неизвестных) СЛУ. Мой код на языке высокого уровня оказался для такого случая быстрее, чем MKL. Спрашивал разработчиков — подтвердили, что это так для моего специального случая.DistortNeo
13.10.2016 11:14+5Я тоже сначала думал, что от переписывания критических участков на ассемблере есть смысл. И действительно получал ускорение примерно в 2 раза по сравнению с высокоуровневым кодом с использованием intrinsics, плюясь от необходимости писать отдельно 32-битный и 64-битный код. Но когда я сменил компилятор (MSVC на Intel), оказалось, что компилятор от Intel генерирует код даже более быстрый, чем вручную написанный на ассемблере. С тех пор в написание на ассемблере не лезу совсем, только периодически поглядываю на сгенерированный код.
Что касается MKL. Ну да, за универсальность тоже стоит платить. Например, собственная реализация Parallel.For имеет существенно меньший оверхед, чем реализация в Intel TBB, что позволяет вообще не думать о гранулярности параллелизма в задачах обработки изображений.third112
13.10.2016 11:29Да. Это плата за универсальность. Но плата, похоже, меньшая, чем у TBB. Про TBB в Intel отмечали, что там сознательный упор на универсальность, а не на скорость. В MKL же скорости изначально уделяют большое внимание, и действительно, насколько мне известно, MKL в большинстве случаев (кроме специальных, как был у меня) очень хорошо помогает.
0serg
13.10.2016 13:08+1У меня был не особо удачный опыт с MKL. Для тех задач которые в MKL непосредственно реализованы все да, работает быстро. Но вот попытка набрать свой алгоритм из отдельных простых BLAS-функций предоставляемых MKL (типа перемножения матрицы на вектор) работала довольно грустно. С библиотекой Eigen все работало значительно быстрее.
smxfem
14.10.2016 18:22Тот пост был написан к тому, что в вычислительных программах узкие места тоже могут занимать малую часть кода, а не для разбора моих заблуждений.
оффтоп
1. Переписывание на ассемблер в теории (в идеале) даст максимальную производительность, для конкретного множества процессоров, то есть временно, поэтому да, толку от этого мало.
2. Использование свойства симметричности наоборот улучшает производительность, это очевидно из приведенного кэш-френдли кода.
3. Таки да, придется использовать обычное строчное представление CSR и PARDISO (Intel MKL) / Eigen, за неимением лучшего.

saboteur_kiev
11.10.2016 11:48+1Если в вашей практике 90% программ ускорять не нужно, вы можете просто не читать статью.
На моем прошлом проекте (embedded), мы дрались буквально за каждый такт.third112
11.10.2016 12:49-2Embedded системы — это очень специфическая область. Там действительно каждый такт м.б. крайне важен.
DistortNeo
11.10.2016 16:10А у меня научные вычисления. Считать нейросеть 2 дня или 4 дня — разница огромная.
3aicheg
11.10.2016 04:52-1Как, как… ifdef-ы, ifdef-ы, тридцать пять тысяч одних ifdef-ов. Под каждую платформу, архитектуру и компилятор, до которых руки дотянулись, вручную прописывается оптимизированное решение. Загляните как-нибудь на досуге в опенсорсную библиотеку, выполняющую много вычислений (линейная алгебра, обработка изображений, видео, вот это вот всё), ужаснитесь сами. Компилятор должен, но не может, как правило.

Gumanoid
10.10.2016 22:02Направление вряд ли поменяет, но может переставить циклы или сделать блокинг: https://software.intel.com/en-us/articles/performance-tools-for-software-developers-loop-blocking
0serg
10.10.2016 23:15+6Направление обхода могут поменять и ICC и GCC и CLang, но в целом да, их возможности сильно ограничены
Отдельная история состоит в том что для FP-вычислений оптимизация может менять результат вычислений, поэтому многие оптимизации подобного рода по умолчанию заблокированы. Интел по-моему единственный кто их по умолчанию включает (и у меня в проекте он дооптимизировал подобным образом один кусок legacy-кода до segfault :) )0xd34df00d
11.10.2016 03:10+3Легаси, легаси… Я с
-ffast-mathдооптимизировался как-то разок до сегфолта на обычномstd::sortмассива из флоатов.
А дело было в отрицательных NaN, которые не очень хорошо сравниваются хорошо с конечными числами, ломая предположения sort'а, и которыеstd::isnanс этим флагом компиляции не распознаёт.0serg
12.10.2016 18:37У меня было забавно
double mul = x * y; double frac = mul - floor(mul);
Безобидный код, правда? И из него совершенно очевидно что frac >= 0. Так собственно всю жизнь и было, пока не пришел Интел и не сказал
r1 = load(x)
r2 = load(y)
r3 = mul(r1,r2)
r4 = floor(r3) // r4 = floor(x*y)
r5 = fmsub(r1, r2, r4) // r5 = x*y - r4
frac = store(r5)
Черт его знает зачем компилятору vfmsub213sd в код захотелось вставить, но из-за того что FMA хранит результат умножения с большей точностью чем регистр то в некоторых случаях получилось что frac < 0 и это крэшило код дальше который предполагал что отрицательного числа в frac никогда не будет.
third112
10.10.2016 23:32-7Во сколько минусов отгреб! А за что? Кто бы объяснил: кому я тут задолжал? У кого 5 рублей до получки занял? :) ИМХО в большинстве случаев не должен программист задумываться о незаметных ускорениях кода, иначе это очень отрицательно скажется на продуктивности работы этого программиста. Но при этом согласен, что бывают не очень частые случаи, когда нужно сделать код быстрее. Автор и согласные с ним видимо считают, что программист всегда в любом случае должен думать про иерархию памяти. Т.к. автор первый это сказал, то пусть он (или кто с ним в этом согласен) приведет подтверждающую статистику. Тогда и только тогда мне придется согласится с тем, что и я должен это делать. Или у меня задачи такие специфические, никак у всех?

homm
11.10.2016 00:53+2незаметных ускорениях кода
А вы читали статью?
third112
11.10.2016 02:10-6Читал. Представьте себе. И даже не придрался, что в графе обычно ребра, а не грани. Грань — это скорее из геометрии. Википедию бы посмотрели:
Объекты представляются как вершины, или узлы графа, а связи — как дуги, или рёбра
Совсем дикие?third112
11.10.2016 12:09-4Поставили минусы за поправку терминологии? Интересно и за следующую правку минусы получу?
если представить матрицу визуально, то элементы (i, j) и (j, i) являются симметричными относительно диагонали.
В квадратной матрице две диагонали. Речь здесь идет о главной диагонали. В литературе по матричной алгебре не пишут, что матрицу нужно представлять визуально, а просто пишут, что матрица симметричная.michael_vostrikov
11.10.2016 12:28+1В литературе по матричной алгебре нет плоской одномерной оперативной памяти.
third112
11.10.2016 13:01-1Думаете в литературе по матричной алгебре не обсуждают алгоритмы? Под рукой книжка из смежной области: А.А. Зыков, Основы теории графов, М.: Вуз. книга, 2004. Посмотрите, например, алгоритм получения двоичного кода матрицы смежности на стр. 33.
mayorovp
11.10.2016 13:07Вот именно что из смежной области. Теория графов — она вся про алгоритмы. Разумеется, там и про их реализацию найдется что рассказать.
third112
11.10.2016 13:10И что Вы хотите доказать? Что в матричной алгебре у квадратной матрицы одна диагональ, а в теории графов у этой матрицы две диагонали? Или что еще?
MichaelBorisov
11.10.2016 01:19+1А вам кто задолжал? Почему это все должны бросаться вам что-то доказывать, искать какую-то статистику?
Вы, если программист, можете убеждать недовольное быстродействием вашей программы начальство или клиентов в том, что обеспечить быстродействие программы — это не ваша обязанность, а обязанность компилятора. С некоторыми людьми такое может даже сработать.third112
11.10.2016 02:03-2Потому, что аксиома, что автор должен обосновать то, о чем он пишет. Т.о. задолжал автор — т.к. не доказал. Кто сказал, что клиенты недовольны моими прогами? Срабатывает за десятую секунды, убыстрить на 20% — никто не заметит. Вы читать умеете — впечатление что писать научились, а читать еще нет. М.б. у Вас все задачи экспоненциальной сложности и других не знаете — тогда сочувствую, но описанные в статье методы Вам с экспонентой не помогут.
0xd34df00d
11.10.2016 03:11+10Предполагается, что статью будут читать те, кому интересна тема оптимизации производительности.
Ну, вы же не требуете обосновывать выбор языка C++ в статьях по C++?third112
11.10.2016 13:13-1Не понял сравнения с ЯП.
Очевидно, что мне интересна тема оптимизации, иначе я бы не стал участвовать в данном обсуждении. Не понимаю только реакцию на мои вопросы по статье.

oYASo
12.10.2016 03:08+3Вы, мне кажется, не очень понимаете, про какую оптимизацию идет речь и про какие программы. На плюсах пишется очень много научного и вычислительного кода, которые может работать несколько часов, дней или недель. Получив, скажем, 10% выигрыш в производительности на ядро, коих может использоваться сотня — это офигеть какой прирост в решении задачи.
Чтобы все работало быстро, на плюсах нужно знать довольно много нюансов, начиная от передачи тяжелый объектов по ссылке, move-семантики и префиксного инкремента, и заканчивая специфичными оптимизациями компилятора типа __builtin_expect. К слову, последнее на уже давно написанном и оптимизированным коде выдало 20% прирост производительности на x86 и (sic!) двукратный прирост на VLIW архитектуре.
Наряду с этими оптимизациями, надо еще писать эффективный параллельный код, то есть знать, что переключение контекста процессора — это ОЧЕНЬ плохо и дорого, что нужно использовать барьеры памяти, RW-локеры, атомарные операции, lock-free структуры и кучу другой магии. А еще нужно знать структуры данных, алгоритмы, оценивать сложность разработанных алгоритмов и т.д. Совокупный кругозор по всем этим тематикам делает из конкретного программиста крутого спеца, за которого готовы платить очень серьезные деньги такие компании, как Яндекс, Интел, Гугл, Майкрософт и далее по списку.
Естественно, это нужно не всем. Естественно, не нужно оптимизировать цикл, если он состоит плюс-минус из 5 элементов. Но есть ряд задач, где все эти хаки и знания приносят ощутимую выгоду.
homm
10.10.2016 21:58+1Раз уж пошла такая пьянка, то может быть кто-то знает ответ на мой вопрос:
http://stackoverflow.com/q/39947921/253146
Коротко: почему выделение памяти операционной системой для процесса занимает в 2 раза больше времени, чем очищение страниц в оперативной памяти + очищение страниц в L3 кеше процессора.
mayorovp
10.10.2016 22:20Вы очищаете память два раза. Первый раз вам ее чистит система, перед тем как вернуть чистую страницу — второй раз вы сами чистите ее memset. Отсюда и просадка производительности.
На больших блоках malloc/free начинают запрашивать память напрямую у системы — и так же возвращать обратно.
homm
10.10.2016 23:59Вы очищаете память два раза.
Да, об этом там написано
На больших блоках malloc/free начинают запрашивать память напрямую у системы
Да, об этом там написано
Отсюда и просадка производительности.
Нет, не отсюда. Производительность при выделении памяти у системы все равно в 2 раза хуже, чем очищение памяти не влезающей в кеш процессора + очищение памяти, влезающей в кеш.
0serg
11.10.2016 00:24+4А в чем вопрос-то?
Вы понимаете что память возвращаемая в ОС чистится. Это 2x потеря производительности
Вы понимаете что память полученная от ОСи не замаплена изначально в физическую. Это означает получение PAGE FAULT на каждые 4 Кб памяти и соответствующее прерывание — это отжирает еще приличный кусок производительности.
Вы, по идее, понимаете что выделение блока адресного пространства и каждой из страниц физической памяти требует от операционки поиска свободного пространства / страниц, исправления таблиц трансляции и обновления их в TLB. Это все операции подразумевающие довольно обширные прогулки по памяти и потому — сравнительно медленные и подъедающие еще ощутимый кусок от производительности.
Я правильно понимаю что судя по последнему абзацу SO вопрос, в общем-то, сводится к тому «а почему это все не сделано быстрее»? Потому что ответ на него очень простой: универсального решения в любом случае не существует и создатели операционки просто перекладывают его на разработчика программ. Если Вам внезапно почему-то нужно постоянно аллоцировать и освобождать крупные блоки памяти, то Вы должны использовать подходящий под эту задачу менеджер памяти, а не надеяться что операционка угадает какой именно из (разных возможных) сценариев использования памяти оптимальным образом подойдет к Вашему приложению. Дефолтная реализация в операционке консервативна, экономит физическую память и написана максимально безопасным способом.homm
11.10.2016 00:52PAGE FAULT на каждые 4 Кб памяти и соответствующее прерывание
поиска свободного пространства / страницСпасибо, это уже похоже на возможное объяснение.
«а почему это все не сделано быстрее»
Это такой теоретический подвопрос. Цель у меня сугубо практическая. Мне действительно иногда нужно выделать по 40-100 мегабайт памяти за раз и я хочу знать, можно ли с этим что-то сделать, кроме как тупо не отдавать память обратно. Мне бы сгодилась даже какая-нибудь настройка ядра Линукса, которая магическим образом делала бы все небезопасным но быстрым.
0serg
11.10.2016 08:49+4Я не сталкивался с подобными задачами но думаю что encyclopedist предлагает отличную идею в лице mmap + комбинации флагов. MAP_PRIVATE + MAP_ANONYMOUS + MAP_POPULATE выглядят разумным началом, а дальше я бы попробовал поэкспериментировать с MAP_UNINITIALIZED и MAP_HUGETLB. Но вообще как правило правильное решение — это менеджер памяти. Ибо верно одно из двух: либо Вы делаете подобные операции постоянно (и тогда разумно не возвращать часть памяти), либо занимаетесь экономией на спичках (если эти операции спорадические)
encyclopedist
11.10.2016 01:15+4Я полагаю, это оверхед от переключения контекста между приложением и ядром при pagefault-ах. Можно попробовать использовать
mmapc разными флагами (MAP_POPULATE например).
third112
11.10.2016 02:41-1Интересно! Столько программистов написали восторженные отзывы на эту статью, но никто (может пропустил — поправьте, пожалуйста) не написал: эта статья помогла исправить провальный проект. У меня куча ссылок, статей и книг по оптимизации кода — коллекция аж с того века. Думаю: вдруг пригодится, но пригождается очень мало. Оптимизация — большое искусство, где очень трудно что-то новое и полезное предложить.
mayorovp
11.10.2016 06:53+3Потому что от момента когда статья была прочитана до момента, когда она пригодилась, может пройти довольно много времени. Мне вот не раз пригождались статьи в интернете — но каждый раз я к тому моменту забывал где я это все прочитал.
third112
11.10.2016 13:07-2Если Вы каждый день делаете код, и если может пройти много времени, когда Вам будет нужна статья по оптимизации кода, то видимо Вы не каждый день делаете оптимальный код в понимании этой статьи. И я про это же самое.
mayorovp
11.10.2016 13:14Нет, я просто пишу IO-bound код. В моем масштабе времени процессор работает с памятью мгновенно.

netch80
11.10.2016 16:52Именно эта статья — нет, но аналогичные — да. Cетевой транспорт некоторого специфического протокола (средняя длина сообщения около 200 байт); внутреннее представление сообщения — или разложение в таблицу пар имя=значение, или как две строки (std::string, заголовок и тело) с манипуляцией над строкой с массовыми перемещениями частей при вставлении или удалении тегов. Без проблем медленной RAM — работа с разложенным представлением была бы в разы быстрее, но с учётом медленной памяти и кэширования — работа с цельными строками в ~2 раза быстрее. Ещё процентов 30 получается за счёт предаллокации строк на предполагаемую длину, вместо того, чтобы позволять рантайму несколько раз делать realloc.
DistortNeo
11.10.2016 16:06У меня была такая задача: вычислить среднее значения модуля производной изображения по блоку 3х3.
Варианта написания тут два:
1. Подход наивный — для каждого пикселя 9 раз вычислять производные, не переиспользуя значения.
2. Подход с наименьшим количеством операций — это сначала посчитать модуль производной в каждом пикселей, затем усреднить по столбцам, затем по строкам. Т.е. 3 прохода по изображению с кэш-френдли доступом.
В однопоточном режиме без AVX производительность первого подхода была немного ниже, чем второго. Но когда я переписал код с использованием AVX и параллельности, сразу упёрся в скорость памяти. Второй способ оказался в ~2.5 раза медленнее первого.
Выжать максимум же можно, преобразовав второй метод в однопроходный, используя конвейер. Ну и немного позаморачиваться при параллелизации. Я, правда, не стал заморачиваться, т.к. это привело бы к ускорению максимум на 10%, зато сильно усложнило бы код.
saboteur_kiev
Статья хорошая и полезная, но некоторые утверждения меня смущают.
> «Часто будет выгоднее обратиться 100'000 раз к оперативной памяти, чем 1 раз к диску.»
Но ведь 100.000 обращений к оперативной памяти делается операциями, которые сами по себе займут 100.000 * x тактов? Как часто можно встретить ситуацию, когда 100.000 раз обращений к оперативки выгоднее, чем одно обращение к диску, особенно учитывая существование SSD и PCI-SSD?
> Скорость обращения к удаленному серверу «1'000'000'000 тактов»
Как можно скорость отклика (ping) мерять тактами? Тем более, что сетевой сокет в гигабитной локалке, может быть быстрее, чем обращение к диску. Я могу расшарить на соседнем компе виртуальный ram-диск, и по гигабитной сети это будет совсем не 1.000.000.000 тактов.
horowitz
Учитывается, что оперативная память хорошо кэшируется. 100'000 раз считать из L1 кэша займёт 0.4М тактов, а раз считать с диска 10М тактов.
saboteur_kiev
то есть прокрутить цикл на 100.000 итераций быстрее, чем один раз обратиться к диску?
Мы же не считаем непосредственно доступ к памяти, а учитываем количество обращений со всем прилагаемым — сами операции обращения?
Вот ниже картинка
прочитать 1.000.000 байт из памяти — 6000 нс
прочитать 1.000.000 байт с диска — 1.000.000 нс
Итого, разница в 166 раз, но никак не в миллион.
horowitz
Применив некоторые оптимизации, можно прокрутить этот цикл и за 100,000 тактов. Читайте мою стать на тему оптимизации для процессора.
0serg
Там помимо 1 мс на чтение еще 3 мс нужно затратить на поиск этих данных на диске.
Кроме того Ваш оппонент говорил о кэше L1, который на два порядка быстрее чем память DRAM о которой говорите Вы. Правда мегабайт туда не влезет, но он влезет в L3 который все равно на порядок быстрее.
smxfem
Чтение с диска и запись на диск тоже могут кэшироваться оперативной памятью (и естественно кэшами L1,L2..), а не только буфером диска. Какой режим работы подразумевается установившийся или нет? И как там с ассинхронностью в 2016 для диска? Слишком уж загнули с 100 000 тактов обращения к диску.
Не надо передергивать.
В статье многобукафф, но не заметил инфы про ассоциативность. Есть размер кэша, да, но есть еще другого рода ограничение. Если обрабатывать в разных частях памяти блоки, то для конкретного процессора не более K штук таких блоков одновременно эффективно кэшируются (проверял лично).
horowitz
А по поводу чтения из сети, это же всё приблизительно. Это общая картина.
maydjin
С трудом верится, ибо гигабитная сеть, она про трупут. А цифры из статьи про лэйтенси.
Хотя, мне даже интересно, какое время отклика было бы у такой связки, но нет физически близкой машины такой под рукой :)
splav_asv
Если речь про вычислительные кластеры, то там есть IB, он про latency в том числе.
maydjin
Не знаком с темой — что такое IB? Гуглится что-то странное.
Это 10g сетевухи от melanox и myricom?
grossws
Это InfiniBand, обычно 10+Gb/s (оно с агрегацией) и субмикросекундными latency.
netch80
> Но ведь 100.000 обращений к оперативной памяти делается операциями, которые сами по себе займут 100.000 * x тактов?
64 чтения из областей, не входящих в одну выровненную 64-байтную область (как строка кэша), займут ~64*250 тактов. 64 чтения подряд из одной такой области займут, по описанной таблице, 64*4 такта. Достаточно просить prefetch на одну такую строку в начале чтения предыдущей, чтобы последовательное чтение не задерживало процессор. В реальности ситуацию ещё больше улучшают микросхемы памяти с несколькими одновременно открытыми строками и многоканальные контроллеры памяти.
> Как часто можно встретить ситуацию, когда 100.000 раз обращений к оперативки выгоднее, чем одно обращение к диску, особенно учитывая существование SSD и PCI-SSD?
При хоть сколь-нибудь продуманном доступе к памяти — считаем, практически всегда.
> Тем более, что сетевой сокет в гигабитной локалке, может быть быстрее, чем обращение к диску.
Гигабитный — по сравнению с SATA даже 1-м — уже нет :) Вот 10GB, или Infiniband'овские скорости — да, уже стоит упоминать.
mayorovp
Не важно гигабит или 10. Проблема не в пропускной способности, а в сетевых задержках.
netch80
> Проблема не в пропускной способности, а в сетевых задержках.
Я рассматривал в контексте передачи сравнимого с от «100,000 обращениями к оперативной памяти» и до «1,000,000,000 тактов» объёма передачи, там задержки уровня одного пакета уже не столь существенны, а скорость значительно больше влияет на общую задержку. В контексте коротких передач — да, безусловно, суммарные задержки важнее, и пример «512 байт из iRAM по сети vs. HDD локально, которому надо ещё переместить головки на полный диапазон» — отличная иллюстрация.