
В настоящий момент OpenBLAS используется в матричных манипуляциях в таких языках как Julia и Python (NumPy). OpenBLAS крайне хорошо оптимизирована и значительная её часть вообще написана на ассемблере.
Однако так ли хорош для вычислений чистый C, как это принято считать?
Встречайте Mir GLAS! Нативная реализация библиотеки линейной алгебры на чисто D без единой вставки на ассемблере!
Для компиляции библиотеки Mir GLAS нам потребуется компилятор LDC (LLVM D Compiler). Компилятор DMD официально не поддерживается т.к. он не поддерживает инструкции AVX и AVX2.
Тестовая конфигурация будет состоять из:
| CPU | 2.2 GHz Core i7 (I7-4770HQ) |
| L3 Cache | 6 MB |
| RAM | 16 GB of 1600 MHz DDR3L SDRAM |
| Model Identifier | MacBookPro11,2 |
| OS | OS X 10.11.6 |
| Mir GLAS | 0.18.0, single thread |
| OpenBLAS | 0.2.18, single thread |
| Eigen | 3.3-rc1, single thread (sequential configurations) |
| Intel MKL | 2017.0.098, single thread (sequential configurations) |
| Apple Accelerate | OS X 10.11.6, single thread (sequential configurations) |
» Код самого теста можно получить тут.
» Mir GLAS базируется на библиотеке mir.ndslice
Mir GLAS может быть легко использован в любом языке поддерживающим C ABI. Делается это элементарно:
// Performs: c := alpha a x b + beta c
// glas is a pointer to a GlasContext
glas.gemm(alpha, a, b, beta, c);
Для сравнения в OpenBLAS потребуется написать следующий код:
void cblas_sgemm (
const CBLAS_LAYOUT layout,
const CBLAS_TRANSPOSE TransA,
const CBLAS_TRANSPOSE TransB,
const int M,
const int N,
const int K,
const float alpha,
const float *A,
const int lda,
const float *B,
const int ldb,
const float beta,
float *C,
const int ldc)
При проведении теста установлено следующее значение переменных:
| openBLAS | OPENBLAS_NUM_THREADS=1 |
| Accelerate (Apple) | VECLIB_MAXIMUM_THREADS=1 |
| Intel MKL | MKL_NUM_THREADS=1 |
Eigen собран с флагами `EIGEN_TEST_AVX` и `EIGEN_TEST_FMA`:
mkdir build_dir
cd build_dir
cmake -DCMAKE_BUILD_TYPE=Release -DEIGEN_TEST_AVX=ON -DEIGEN_TEST_FMA=ON ..
make OpenBLASРезультаты (больше — лучше):
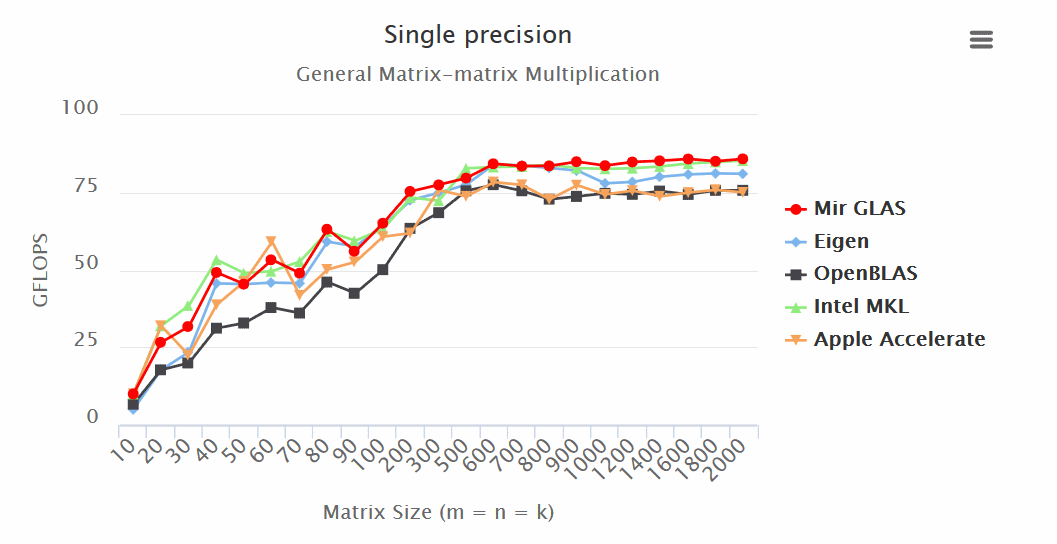
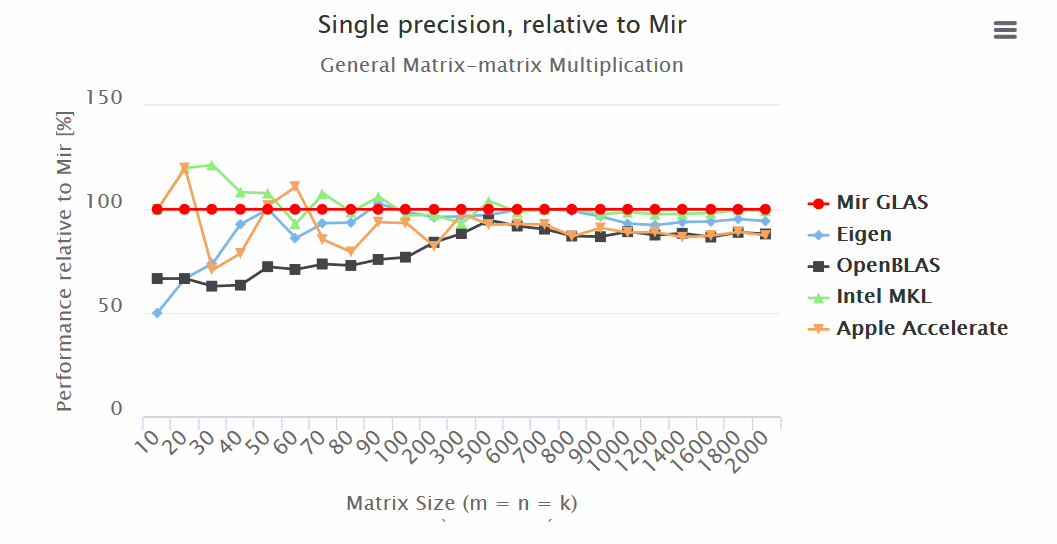

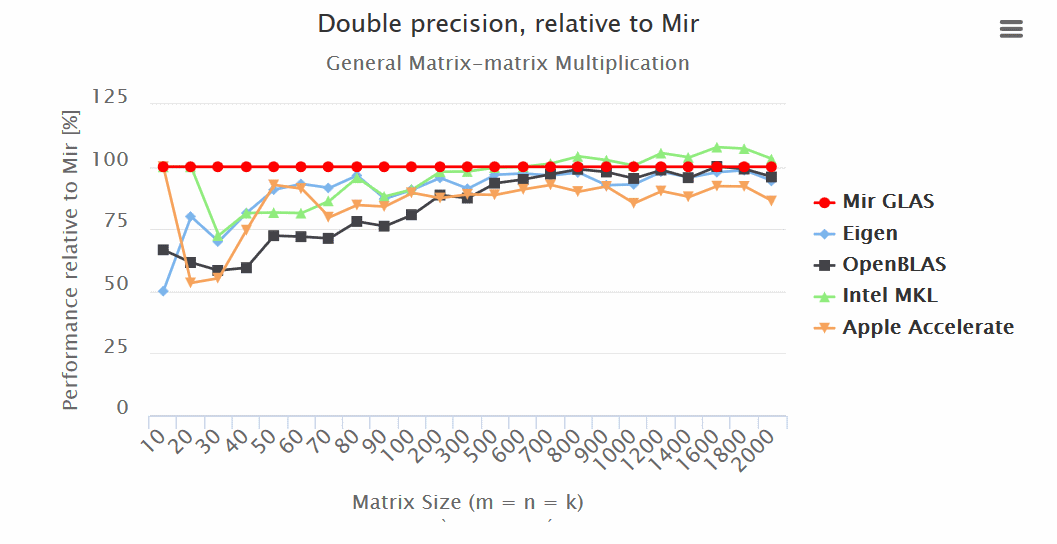

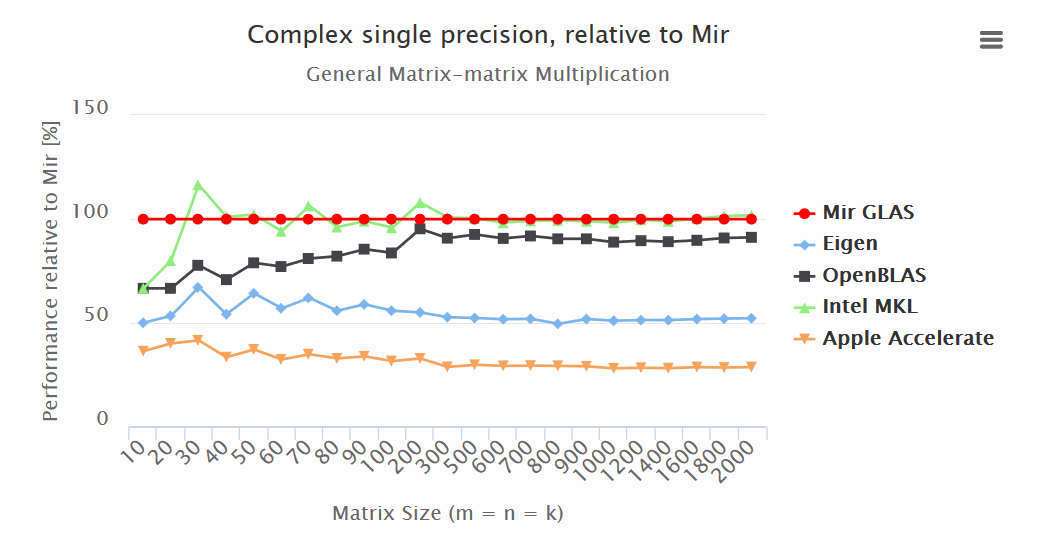
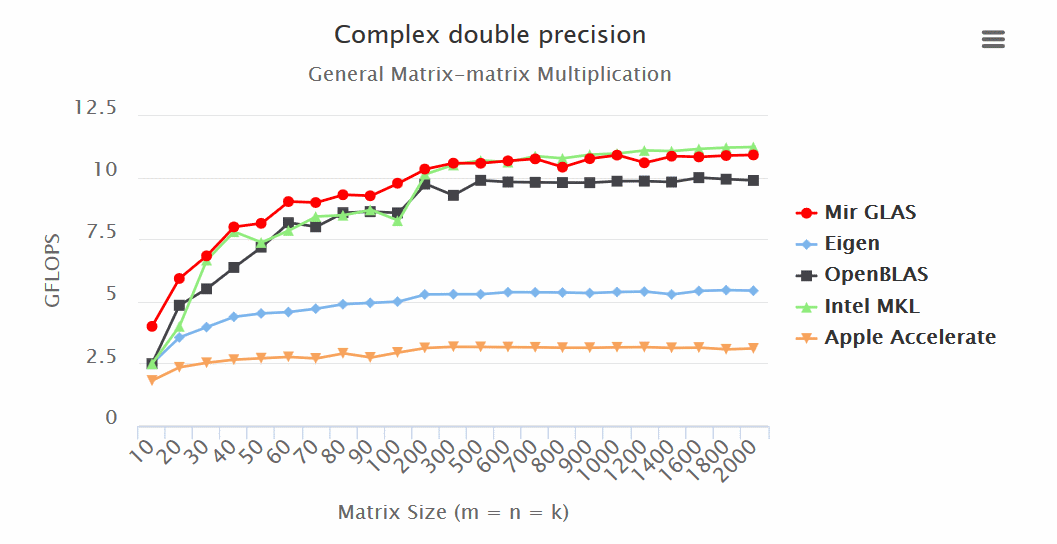
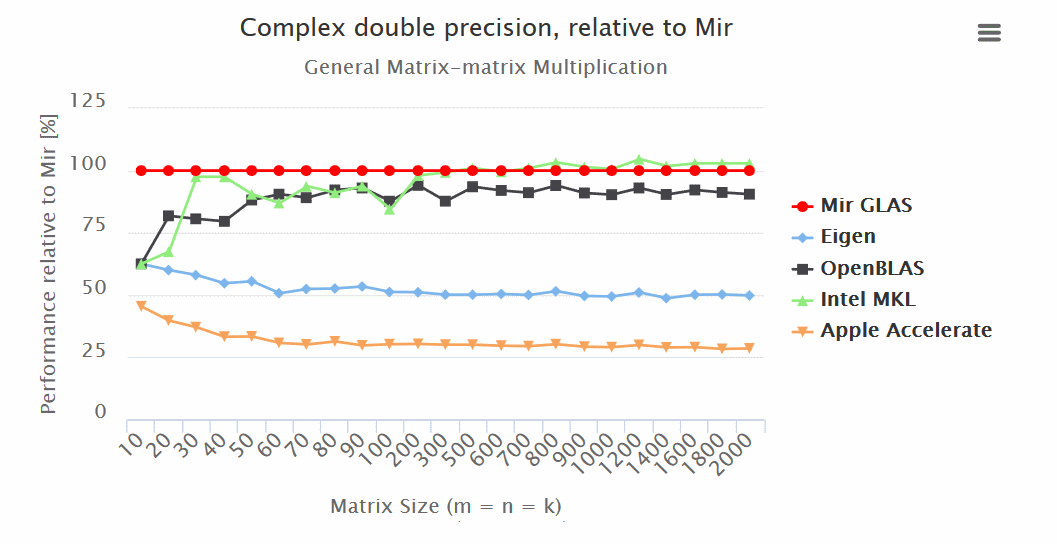
Итоги:
— Mir GLAS значительно опережает OpenBLAS и Apple Accelerate по всем показателям.
— Mir GLAS оказывается быстрее почти в два раза чем Eigen и Apple Accelerate при работе с матрицами.
— По скорости Mir GLAS оказывается сопоставим с проприетарным Intel MKL, который является самым быстрым в своем роде.
— Благодаря своему дизайну Mir GLAS легко может быть адаптирован для новых архитектур.
P.S. В настоящий момент на базе GLAS активно развивается система компьютерного зрения DCV.
P.P.S. Оригинальный автор присутствует в комментах под ником 9il
» Оригинальная статья расположена в блоге автора.
Комментарии (26)
mwambanatanga
03.10.2016 10:13+7> Для компиляции библиотеки Mir GLAS нам потребуется компилятор LDC (LLVM D Compiler). Компилятор DMD официально не поддерживается т.к. он не поддерживает инструкции AVX и AVX2.
Следует думать, что и остальные участники теста были скомпилированы из исходников, с поддержкой всех инструкций целевого процессора? А то как бы не оказалось, что чемпион собран со всеми оптимизациями, а остальные пакеты — стоковые, собранные под generic i586.
P.S.: За openBLAS как-то обидно.
grossws
03.10.2016 11:49Ну и не представлен ATLAS (который, опять же, надо собирать на целевой платформе).

9il
03.10.2016 12:01Intel MKL и Accelerate предоставлены только бинарными файлами. Для Eigen указаны ключи для cmake (в статье и переводе: `cmake -DCMAKE_BUILD_TYPE=Release -DEIGEN_TEST_AVX=ON -DEIGEN_TEST_FMA=ON `), clang стандартный. OpenBLAS вообще по сути на ассемблере написан. Чем собирается Mir доступно на Github проекта, ему тоже явно никаких ключей, кроме `-mcpu=native` не пересылается.

sergehog
03.10.2016 10:22+2Что то я солверов не нашел в документации. Cholesky, LU, прочие декомпозиции присутствуют? Солвер с прекондишенером?


Gorthauer87
03.10.2016 11:39+1А не лучше ли использовать что-то такое?
https://github.com/CNugteren/CLBlast
grossws
03.10.2016 11:44Тем, кто занимается системами машинного обучения и компьютерным зрением, хорошо знакома такая библиотека как OpenBLAS (Basic Linear Algebra Subprograms). OpenBLAS написан на C и используется повсеместно там где нужна работа с матрицами. Так же у него есть несколько альтернативных реализаций таких как Eigen и двух закрытых имплементацией от Intel и Apple. Все они написаны на С\С++.
Reference-имплементация — Netlib BLAS — на фортране, альтернативная OpenBLAS — на фортране, ATLAS — на си и фортране (использует reference implementation). На чём написан Intel MKL не знаю, но там упомянуты ручные оптимизации под конкретные камни, так что с большой вероятностью там куски на asm или intrinsics.
9il
03.10.2016 12:03-1OpenBLAS написан на ассемблере и Си. Иммеет Fortran ABI и Level 1 скопированный у Netlib.
grossws
03.10.2016 12:23Посмотрел внимательнее, Netlib BLAS там лежит в двух местах. В корне он собирается только для sanity check'а судя по Makefile.
По openblas был неправ и снимаю свои возражения. Остальное в силе.

Anton_Menshov
03.10.2016 17:24+1Можете прокомментировать по вопросу используемых алгоритмов — удовлетворяют ли они стандартам? Например, не используется ли рекурсивная арифметика в стандартных алгоритмах? (типа Штрассена для gemm)
Насколько проверена стабильность вычислений? ибо скорость — конечно, наше все. Но все же, хотелось бы и шашечки.
Еще очень бы хотелось увидеть другой тип сравнения производительности: log-log график затраченного времени по отношению к размеру матрицы. И тут, кстати, придется идти от 10x10 до 10000x10000 в размерностях — иначе будет слишком куце. Тем самым можно будет посмотреть еще и абсолютное время исполнения (платформа-то — одна) и сравнить курс выхода на асимптотику.9il
03.10.2016 18:31Сложность алгоритма O(m*n*k), рекурсивные алгоритмы не используются. Только кэш-ориентированное разбиение с упаковкой удобной для хранения промежуточных результатов в SIMD регистрах процессора, prefetch. Было бы интересно узнать о каких еще стандартах еще идет речь? В случае с gemm все просто, но в планах trsm и LU, и там уже больше возможностей для маневра, и хотелось бы знать требованиям, если такие есть.
Работает достаточно хорошо, с разным блочным разбиением, транспонированием. Планируется добавить BLAS и CBLAS API и прогнать набор тестов от Netlib с нормальными и пониженными размерами блоков. В 2017 году планируется заменить OpenBLAS в Julia.
Буду рад более детальному обсуждению тестов в новом issue в https://github.com/libmir или по почте ilyayaroshenko на gmail. Знаком с BLIS, работой коллег из вашего университета.
maaGames
У меня только два вопроса:
1. Почему сравнивалась однопоточная реализация? MirGLAS не умеет в многопоточность?
2. Почему такие игрушечные матрицы? 2000*2000 в double = 30,5 мегабайт. Все три матрицы 100 мегабайт занимают. Т.е. данные неплохо закэшированы будут, может этим и объясняются почти одинаковые результаты многих тестов. Хотелось бы тест на матрицах бОльших размеров, хотя бы 10К*10К. А то компьютер с 16ГБ оперативки и используете 100МБ.
iCpu
Сюда же можно добавить, что нет исходников кода тестов для остальных библиотек, нет информации о версиях и ключах компилятора. Да и сравнение только на макбуке выглядит не очень логично, стоило бы добавить хотя бы Федора.
maaGames
Да и производительность IntelMKL зависит от того, лежит ли рядышком нужная dll или используется универсальная реализация, не использующая AVX и прочие специфичные оптимизации.
grossws
Меня удивляют столь низкие результаты accelerate framework'а, т. к., как минимум, на современых MacOS X он внутре дёргает Intel MKL и существенное отличие от последнего алогично.
maaGames
Это ещё больше наталкивает на мысль, что использовалась общая библиотека, вместо специализированной.
9il
Везде использовались специализированные.
9il
Лежит правильная.
9il
Intel MKL и Accelerate предоставлены только бинарными файлами. Для Eigen указаны ключи для cmake (в статье и переводе: `cmake -DCMAKE_BUILD_TYPE=Release -DEIGEN_TEST_AVX=ON -DEIGEN_TEST_FMA=ON `), clang стандартный. OpenBLAS вообще по сути на ассемблере написан. Чем собирается Mir доступно на Github проекта, ему тоже явно никаких ключей, кроме `-mcpu=native` не пересылается.
9il
1. Mir пока только однопоточный.
2. Результаты для больших размеров такие же как и для 2000*2000. Размеры не игрушечные, а достаточные. Мне было бы очень интересно узнать время умножения матриц 10К*10К вашей любимой BLAS библиотекой из используемых в данной статье :-)
maaGames
Абсолютная цифра, выданная «моим любимым MKL» ничего не значит, потому что у меня другой компьютер и, вообще, Windows. Сравнивать-то в одинаковых условиях нужно.
Размер 2К*2К очень скромный, даже для обработки изображений уже могут потребоваться бОльшие размеры.
Я чаще имею дело с разреженными матрицами, правда размером в гигабайты. Mir поддерживает разреженные и/или симметричные матрицы?
Ну и, пожалуй, самое важное: есть функция обращения матрицы?
9il
Да, есть CSR и COO. Обращения пока нет. Это первый анонс результатов работы над Mir GLAS. Размер 2К*2К достаточен для тестов. Это не очевидно, но вытекает из логики кэширования, если она с ошибками, то проблемы начинаются на размерах 900x900.
maaGames
Не обратил внимания, что это только-только зарождающийся проект. Тогда весьма неплохо.
Лично для меня бесполезен, пока не реализуют обращение матрицы. И многопоточность.
Anton_Menshov
Размер 2k на 2k недостаточен для тестирования как минимум по вопросу численной стабильности алгоритмов.
Проблемы с логикой кеширования — зависит от того на каком процессоре выполняется. Возьмем производительный Intel Xeon E5-2650 v3 с 25 Mb кеша — и проблемы могут начаться позже. Плюс, если результаты хороши и выше — то их стоит публиковать. По нынешним стандартам проход до 10k x 10k — стандартен.