
Проблема
Есть определенная функциональная область приложения: некая экспертная система, анализирующая состояние данных, и выдающая результат — множество рекомендаций на базе набора правил. Компоненты системы покрыты определенным набором юнит-тестов, но основная «магия» заключается в выполнении правил. Набор правил определен заказчиком на стадии проекта, конфигурация выполнена.
Более того, поскольку после первоначальной приемки (это было долго и сложно — потому, что “вручную") в правила экспертной системы регулярно вносятся изменения по требованию заказчика. При этом, очевидно, неплохо — бы проводить регрессионное тестирование системы, чтобы убедиться, что остальные правила все еще работают корректно и никаких побочных эффектов последние изменения не внесли.
Основная сложность заключается даже не в подготовке сценариев — они есть, а в их выполнении. При выполнении сценариев “вручную", примерно 99% времени и усилий уходит на подготовку тестовых данных в приложении. Время исполнения правил экспертной системой и последующего анализа выдаваемого результата — незначительно по сравнению с подготовительной частью. Сложность выполнения тестов, как известно, серьезный негативный фактор, порождающий недоверие со стороны заказчика, и влияющий на развитие системы («Изменишь что-то, а потом тестировать еще прийдется… Ну его...»).
Очевидным техническим решением было бы превратить все сценарии в автоматизированные и запускать их регулярно в рамках тестирования релизов или по мере необходимости. Однако, будем ленивыми, и попробуем найти путь, при котором данные для тестовых сценариев готовятся достаточно просто (в идеале — заказчиком), а автоматические тесты — генерируются на их основе, тоже автоматически.
Под катом будет рассказано об одном подходе, реализующим данную идею — с использованием MS Excel, XML и XSLT преобразований.
Тест — это прежде всего данные
А где проще всего готовить данные, особенно неподготовленному пользователю? В таблицах. Значит, прежде всего — в MS Excel.
Я, лично, электронные таблицы очень не люблю. Но не как таковые (как правило — это эталон юзабилити), а за то, что они насаждают и культивируют в головах непрофессиональных пользователей концепцию «смешивания данных и представления» (и вот уже программисты должны выковыривать данные из бесконечных многоуровневых «простыней», где значение имеет все — и цвет ячейки и шрифт). Но в данном случае — мы о проблеме знаем, и постараемся ее устранить.
Итак, постановка задачи
- обеспечить подготовку данных в MS Excel. Формат должен быть разумным с точки зрения удобства подготовки данных, простым для дальнейшей обработки, доступным для передачи бизнес пользователям (последнее — это факультативно, для начала — сделаем инструмент для себя);
- принять подготовленные данные и преобразовать их в код теста.
Решение
Пара дополнительных вводных:
- Конкретный формат представления данных в Excel пока не ясен и, видимо, будет немного меняться в поисках оптимального представления;
- Код тестового скрипта может со временем меняться (отладка, исправление дефектов, оптимизация).
Оба пункта приводят к мысли, что исходные данные для теста необходимо предельно оделить и от формата, в котором будет осуществляться ввод, и от процесса обработки и превращения в код автотеста, поскольку обе стороны будут меняться.
Известная технология превращения данных в произвольное текстовое представление — шаблонизаторы, и XSLT преобразования, в частности — гибко, просто, удобно, расширяемо. В качестве дополнительного бонуса, использование преобразований открывает путь как к генерации самих тестов (не важно на каком языке программирования), так и к генерации тестовой документации.
Итак, архитектура решения:
- Преобразовать данные из Excel в XML определённого формата
- Преобразовать XML с помощью XSLT в финальный код тестового скрипта на произвольном языке программирования
Конкретная реализация на обеих этапах может быть специфична задаче. Но некоторые общие принципы, которые, как мне кажется, будут полезны в любом случае, приведены ниже:
Этап 1. Ведение данных в Excel
Здесь, честно говоря, я ограничился ведением данных в виде табличных блоков. Фрагмент файла — на картинке.
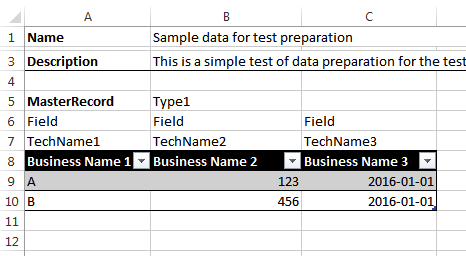
- Блок начинается со строки, содержащей название блока (ячейка “A5"). Оно будет использовано в качестве имени xml-элемента, так что содержание должно соответствовать требованиям. В той же строе может присутствовать необязательный “тип” (ячейка “B5") — он будет использовано в качестве значения атрибута, так что тоже имеет ограничения.
- Каждая колонка таблицы содержит помимо “официального” названия, представляющего бизнес-термины (строка 8), еще два поля для “типа” (строка 6) и “технического названия” (строка 7). В процессе подготовки данных технические поля можно скрывать, но во время генерации кода использоваться будут именно они.
- Колонок в таблице может быть сколько угодно. Скрипт завершает обработку колонок как только встретит колонку с пустым значением “тип” (колонка D).
- Колонки со “типом”, начинающимся с нижнего подчеркивания — пропускаются.
- Таблица обрабатывается до тех пор, пока не встретиться строка с пустым значением в первой колонке (ячейка “A11”)
- Скрипт останавливается после 3 пустых строк.
Этап 2. Excel -> XML
Преобразование данных с листов Excel в XML — несложная задача. Преобразование производится с помощью кода на VBA. Тут могут быть варианты, но мне так показалось проще и быстрее всего.
Ниже приведу лишь несколько соображений — как сделать финальный инструмент удобнее в поддержке и использовании.
- Код представлен в виде Excel add-in (.xlam) — для упрощения поддержки кода, когда количество файлов с тестовыми данными более 1 и эти файлы создаются/поддерживаются более чем одним человеком. Кроме того — это соответствует подходу разделения кода и данных;
- XSLT шаблоны размещаются в одном каталоге с файлом add-in — для упрощения поддержки;
- Генерируемые файлы: промежуточный XML и результирующий файл с кодом, — желательно помещать в тот же каталог, что и файл Excel с исходными данными. Людям создающим тестовые скрипты будет удобнее и быстрее работать с результатами;
- Excel файл может содержать несколько листов с данными для тестов — они используются для организации вариативности данных для теста (например, если тестируется процесс, в котором необходимо проверить реакцию системы на каждом шаге): откопировал лист, поменял часть входных данных и ожидаемых результатов — готово. Все в одном файле;
- Поскольку все листы в рабочей книге Excel должны иметь уникальное имя — эту уникальность можно использовать в качестве части имени тестового скрипта. Такой подход дает гарантированную уникальность имен различных подсценариев в рамках сценария. А если включать в имя тестового скрипта название файла, то достичь уникальности названий скриптов становится еще проще — что особенно важно в случае если тестовые данные готовят несколько человек независимо. Кроме того, стандартный подход к именованию поможет в дальнейшем при анализе результатов теста — от результатов исполнения к исходным данным будет добраться очень просто;
- Данные из всех листов книги сохраняются в один XML файл. Для нас это показалось целесообразным в случае генерации тестовой документации, и некоторых случаях генерации тестовых сценариев;
- При генерации файла с данными для теста удобно оказалось иметь возможность не включать в генерацию отдельные листы с исходными данными (по разным причинам; например, данные для одного из пяти сценариев ещё не готовы — а тесты прогонять пора). Для этого мы используем соглашение: листы, где название начинается с символа нижнего подчёркивания — исключаются из генерации;
- В файле удобно держать лист с деталями сценария по которому создаются тестовые данные («Documentation») — туда можно копировать информацию от заказчика, вносить комментарии, держать базовые данные и константы, на которые ссылаются остальные листы с данными, и так далее. Разумеется, данный лист в генерации не участвует;
- Чтобы иметь возможность влиять на некоторые аспекты генерации финального кода тестовых скриптов, оказалось удобным включать в финальный XML дополнительную информацию «опции генерации», которые не являются тестовыми данными, но могут использоваться шаблоном для включения или исключения участков кода (по аналогии с pragma, define, итп.) Для этого мы используем именованные ячейки, размещённые на негенерируемом листе «Options»;
- Каждая строка тестовых данных должна иметь уникальный идентификатор на уровне XML — это здорово поможет при генерации кода и при обработке кросс-ссылок между строками тестовых данных, которые при этом необходимо формулировать в терминах как раз этих уникальных идентификаторов.
Фрагмент XML который получается из данных в Excel с картинки выше
<MasterRecord type="Type1">
<columns>
<column>
<type>Field</type>
<name>TechName1</name>
<caption>Business Name 1</caption>
</column>
<column>
<type>Field</type>
<name>TechName2</name>
<caption>Business Name 2</caption>
</column>
<column>
<type>Field</type>
<name>TechName3</name>
<caption>Business Name 3</caption>
</column>
</columns>
<row id="Type1_1">
<Field name="TechName1">A</Field>
<Field name="TechName2">123</Field>
<Field name="TechName3">2016-01-01</Field>
</row>
<row id="Type1_2">
<Field name="TechName1">B</Field>
<Field name="TechName2">456</Field>
<Field name="TechName3">2016-01-01</Field>
</row>
</MasterRecord>
Этап 3. XML -> Code
Эта часть предельно специфична задачам которые решаются, поэтому ограничусь общими замечаниями.
- Начальная итерация начинается по элементам, представляющим листы (различные тестовые сценарии). Здесь можно размещать блоки setup / teardown, утилит;
- Итерация по элементам данных внутри элемента сценария должна начинаться с элементов ожидаемых результатов. Так можно логично организовать сгенерированные тесты по принципу «один тест — одна проверка»;
- Желательно явно разделить на уровне шаблонов области, где генерируются данные, выполняется проверяемое действие, и контролируется полученный результат. Это возможно путём использования шаблонов с режимами (mode). Такая структура шаблона позволит в дальнейшем делать другие варианты генерации — просто импортируя этот шаблон и перекрывая в новом шаблоне необходимую область;
- Наряду с кодом, в тот же файл будет удобно включить справку по запуску тестов;
- Очень удобным является выделение кода генерации данных в отдельно вызываемый блок (процедуру) — так чтобы его можно было использовать как в рамках теста, так и независимо, для отладки или просто создания набора тестовых данных.
Финальный комментарий
Через какое-то время файлов с тестовыми данными станет много, а отладка и «полировка» шаблонов генерации тестовых скриптов будет все продолжаться. Поэтому, прийдется предусмотреть возможность «массовой» генерации автотестов из набора исходных Excel файлов.
Заключение
Используя описанный подход можно получить весьма гибкий инструмент для подготовки тестовых данных или полностью работоспособных автотестов.
В нашем проекте удалось довольно быстро создать набор тестовых сценариев для интеграционного тестирования сложной функциональной области — всего на данный момент около 60 файлов, генерируемых примерно в 180 тестовых классов tSQLt (фреймворк для тестирования логики на стороне MS SQL Server). В планах — использовать подход для расширения тестирования этой и других функциональных областей проекта.
Формат пользовательского ввода остается как и раньше, а генерация финальных автотестов можно менять по потребностям.
Код VBA для преобразования Excel файлов в XML и запуска преобразования (вместе с примером Excel и XML) можно взять на GitHub github.com/serhit/TestDataGenerator.
Преобразование XSLT не включено в репозиторий, поскольку оно генерит код для конкретной задачи — у вас все равно будет свой. Буду рад комментариям и pull request'ам.
Happy testing!
Поделиться с друзьями
BelyaevAG
Если я правильно понимаю, то вы готовите конкретные данные и переводите их в тесты.
Но вот тут вопрос возникает — почему бы не описать правила и на основе этих правил создавать полный набор данных?
Например, есть таблица, в которой есть поля с типами NVARCHAR2 и NUMBER. Есть ещё какой-нибудь foreign key, primary key и т.д. Ещё поля с Nullable = true/false. Короче, есть спецификация данных. Мы можем на каждое из правил придумать проверки: не уникальное значение, отсутствие соответствующего значения для внешнего ключа и т.д.
Всё, на основе этого мы можем просто подсунуть системе генерации схему данных в БД и сгенерировать наборы данных.
И тогда нам остаётся только поддерживать схему данных в актуальном состоянии.
Думали о таком подходе? Это вообще реально сделать за адекватное время? Или этот подход не взлетит потому что…?
serhit
Дело в том, что задача, которая изначально стояла перед нами — это «проверка корректности работы правил экспертной системы» (поверхностно я обмолвился по этому поводу в начале).
При такой постановке принципиально нужно формулировать тест в терминах «входные данные» + «правильный ответ», причем как-раз «правильный ответ» составляет суть бизнес требований к экспертной системе.
Т.е. если бы даже можно было бы создать довольно полный набор входных данных, их преобразование в «правильный ответ» не может быть сделано автоматически — это как раз задача подсистемы которую мы тестируем.
Что касается полноты тестового покрытия в нашем случае. Я могу только приблизительно оценить количество полных вариантов для одного правила — примерно 400 возможных адекватных бизнес-сценариев (про неадекватные, которые заказчик называет «exception», я даже говорить не хочу). Отдельные нюансы покрываются юнит тестами.
У нас есть на данный момент в среднем 40-50 сценариев на правило, но они покрывают наиболее вероятные сценарии — около 90% бизнес ситуаций.
Так что «техническое» покрытие выглядит незначительным — около 10%, и это не очень хорошо. Но поскольку мы не тестируем полностью «черный ящик», с точки зрения заказчика мы покрываем тестами около 90% ситуаций.
Как-то так…