
Скрапинг бесконечно прокручивающейся страницы
Добро пожаловать в советы по Scrapy от профессионалов! В этом месяце мы поделимся несколькими уловками, чтобы помочь ускорить вашу работу связанную с веб-скрапингом. Как ведущие мэйнтейнеры Scrapy мы сталкиваемся с каждыми препятствием, которое вы можете себе представить. Так что не волнуйтесь — вы в надёжных руках. Не стесняйтесь контактировать с нами в твиттере или фейсбуке с любыми предложениями для будущих статей.

В эру одностраничных приложений и тонн AJAX-запросов на одной странице множество веб-сайтов заменили кнопку навигации "вперёд/назад" на причудливый механизм бесконечной прокрутки страницы. Веб-сайты использующие этот механизм загружают новую сущность каждый раз, когда пользователь достигает конца страницы при вертикальной прокрутке(вспомните Twitter, Facebook, Google Images). Даже несмотря на то, что UX-эксперты утверждают что механизм бесконечной прокрутки предоставляет чрезмерное количество данных для пользователей, мы видим увеличивающееся количество веб-страниц прибегающих к предоставлению бесконечного списка результатов.
Одна из первых вещей которую мы делаем при разработке своего веб-скрапера — мы ищем на сайте компоненты пользовательского интерфейса, которые содержат в себе ссылки ведущие на следующую страницу результатов. К сожалению, такие ссылки не представлены на страницах с бесконечной прокруткой.
Хотя такой сценарий и может показаться классическим случаем для таких JavaScript-фреймворков как Splash или Selenium, это, действительно, легко внедрить. Всё что вам нужно сделать вместо имитации взаимодействия с пользователем через один из тех фреймворков — это исследовать AJAX-запросы вашего браузера при прокрутке страницы и затем воссоздать эти запросы в вашем пауке в Scrapy.
Давайте используем Spidy Quotes в качестве примера и построим паука, который получит все элементы перечисленные на странице.
Инспектирование страницы
Первым делом нам надо понять как работает бесконечная прокрутка на странице. И мы можем сделать это используя панель Network в инструментах разработчика в браузере. Откроем панель и прокрутим страницу, чтобы увидеть запросы отправляемые браузером:
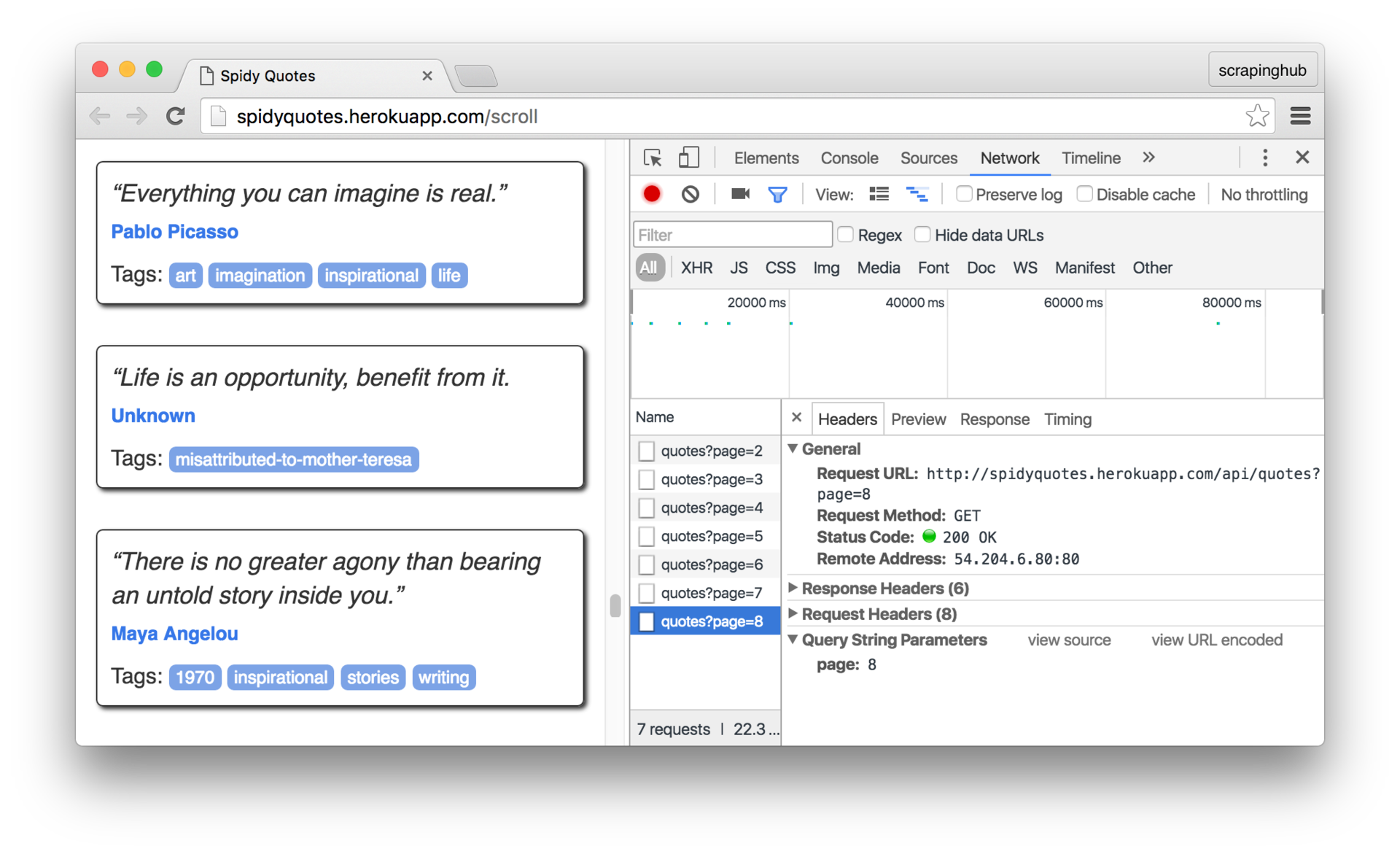
Нажмём на запрос, чтобы рассмотреть его подробнее. Как мы можем видеть, браузер посылает запрос на /api/quotes?page=x и получает в ответе JSON-объект подобный этому:
{
"has_next":true,
"page":8,
"quotes":[
{
"author":{
"goodreads_link":"/author/show/1244.Mark_Twain",
"name":"Mark Twain"
},
"tags":["individuality", "majority", "minority", "wisdom"],
"text":"Whenever you find yourself on the side of the ..."
},
{
"author":{
"goodreads_link":"/author/show/1244.Mark_Twain",
"name":"Mark Twain"
},
"tags":["books", "contentment", "friends"],
"text":"Good friends, good books, and a sleepy ..."
}
],
"tag":null,
"top_ten_tags":[["love", 49], ["inspirational", 43], ...]
}Это информация которая нужна нам для нашего паука. Всё что нужно сделать в нём — это генерировать запросы на /api/quotes?page=x увеличивая x пока значение поля has_next не станет false. Самое прекрасное в этом — что нам даже не надо скрапить содержимое HTML, чтобы получить данные которые нам нужны. Это всё содержится в красивом машиночитаемом формате JSON.
Построение паука
Вот наш паук. Он извлекает целевые данные из содержимого в JSON-формате, которое мы получили в ответе от сервера. Такой подход проще и более надёжен, чем копаться в HTML дереве страницы, надеясь что изменение разметки не сломает наших пауков.
import json
import scrapy
class SpidyQuotesSpider(scrapy.Spider):
name = 'spidyquotes'
quotes_base_url = 'http://spidyquotes.herokuapp.com/api/quotes?page=%s'
start_urls = [quotes_base_url % 1]
download_delay = 1.5
def parse(self, response):
data = json.loads(response.body)
for item in data.get('quotes', []):
yield {
'text': item.get('text'),
'author': item.get('author', {}).get('name'),
'tags': item.get('tags'),
}
if data['has_next']:
next_page = data['page'] + 1
yield scrapy.Request(self.quotes_base_url % next_page)
Если вы захотите сделать что-то ещё, используя полученные знания, то вы можете поэкспериментировать с созданием паука для нашего блога, так как он тоже использует бесконечную прокрутку для загрузки старых постов
Заключение
Если вы чувствовали себя несколько обескураженно относительно перспективы скрапинга веб-сайтов имеющих бесконечную прокрутку, то, надеюсь, теперь вы чувствуете себя более уверенно. В следующий раз, когда вы будете иметь дело со страницей базируемой на вызовах AJAX-запросов в результате действий пользователя, посмотрите какой запрос делает ваш браузер и воспроизведите его в вашем пауке. Ответ на запрос, как правило, имеет формат JSON, что делает вашего паука гораздо проще.
Комментарии (2)

hudson
17.10.2016 14:31Я так и делаю — некоторый «реверс-инжиниринг» страниц, которые надо парсить (порой логика бывает посложнее, чем описано в статье, но ничего невозможного пока не встречал) — после воссоздание запросов в пауке и краулинг по ним.
Что меня больше интересует — так это интерпритация сайтов со сложным фронтэндом «как в браузере». Так как парсить и поддерживать их будет проще. А к примеру сайты, работающие через вебсокеты так и вовсе можно только так будет распарсить.
Планирую внедрять scrapy-splash — не поделитесь кто чем пользуется в продакшене?
ivaaaan
del