

Мы в Одноклассниках занимаемся поиском узких мест в инфраструктуре, состоящей более чем из 10 тысяч серверов. Когда мы слегка задолбались мониторить 5000 серверов вручную, нам понадобилось автоматизированное решение.
Точнее, не так. Когда в седой древности появился примерно 20-й сервер, стали использовать Big Brother — простейший мониторинг, который просто собирает статистику и показывает её в виде мелких картинок. Всё очень, очень просто. Ни приблизить, ни как-то ввести диапазоны допустимых изменений нельзя. Только смотреть картинки. Вот такие:
Два инженера тратили по одному рабочему дню в неделю, просто отсматривая их и ставя тикеты там, где график показался «не таким». Понимаю, звучит реально странно, но началось это с нескольких машин, и потом как-то неожиданно доросло до 5000 инстансов.
Поэтому мы сделали новую систему мониторинга — и сейчас на работу с 10 тысячами серверов тратим по 1-2 часа в неделю на обработку алертов. Расскажу, как это устроено.
Почему это надо
Инцидент-менеджмент у нас был поставлен задолго до начала работ. В «железной» части серверы работали штатно и хорошо обслуживались. Сложности были с предсказанием узких мест и выявлением нетипичных ошибок. В 2013 году сбой в Одноклассниках привёл к тому, что сайт был недоступен в течение нескольких дней, о чём мы уже писали. Мы извлекли из этого уроки, и уделили очень много внимания именно предотвращению инцидентов.
С ростом числа серверов стало важно не только эффективно управлять всеми ресурсами, мониторить и учитывать их, но и оперативно фиксировать опасные тенденции, которые могут привести к появлению узких мест в инфраструктуре сайта. А также предотвращать эскалацию обнаруженных проблем. Именно о том, как мы анализируем и прогнозируем состояние своих IT-ресурсов, и пойдёт речь.
Немного статистики
В начале 2013 года инфраструктура Одноклассников состояла из 5000 серверов и систем хранения данных. Вот рост за два с половиной года:
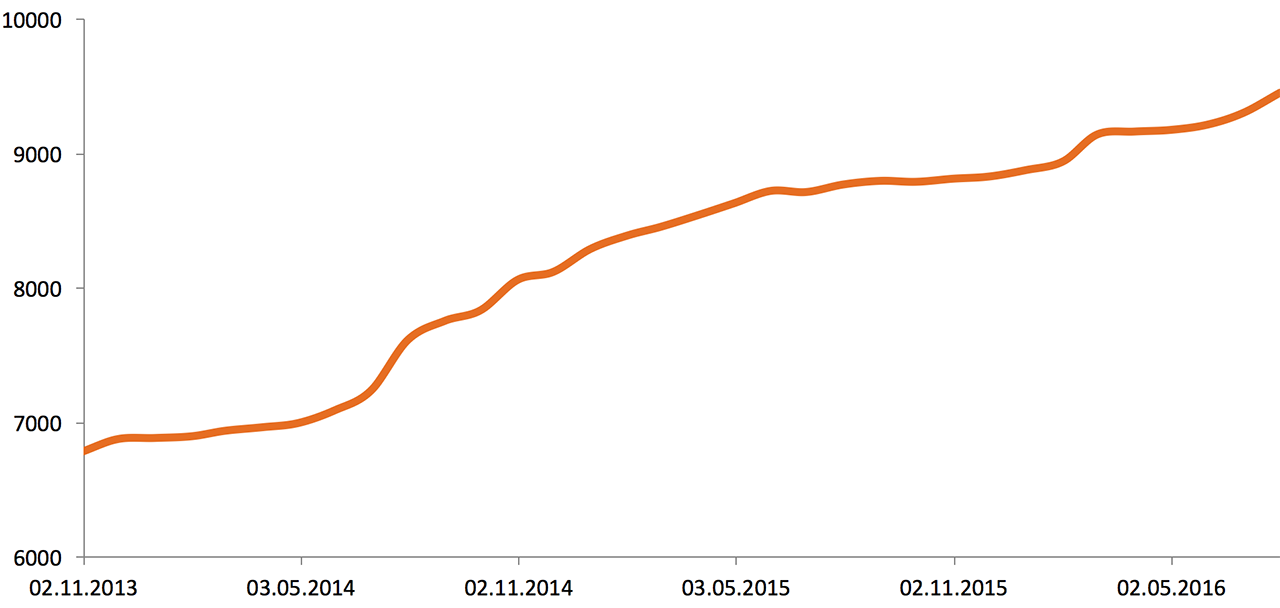
Объём внешнего сетевого трафика (2013—2016), Gbit/s:
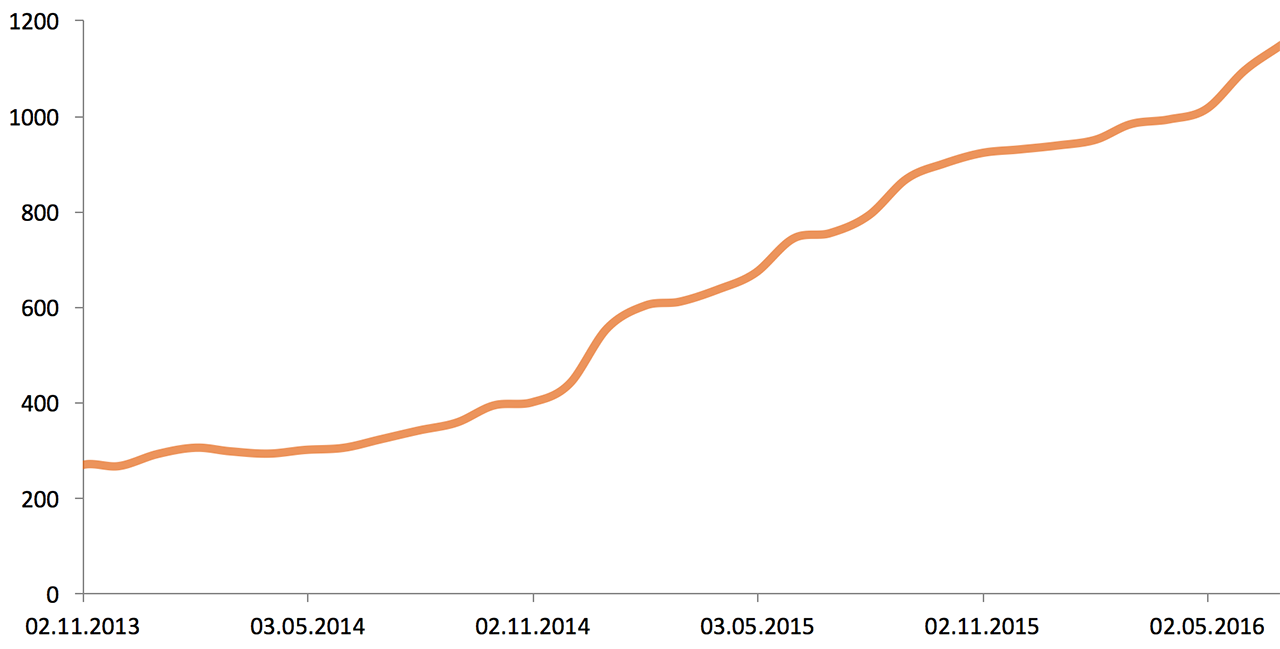
Объём хранимых данных (2013—2016), Tb:
Показатели работы приложений, оборудования и бизнес-метрик отслеживаются командой мониторинга в режиме 24/7. В связи с тем, что и без того большая инфраструктура продолжает активно расти, решение проблем с узкими местами в ней может занять существенное время. Именно поэтому одного оперативного мониторинга недостаточно. Чтобы разобраться с неприятностями максимально быстро, требуется прогнозировать рост нагрузки. Это делается следующим образом: команда мониторинга раз в неделю запускает автоматическую проверку операционных показателей всех серверов, массивов и сетевых устройств, по итогам которой получает список всех возможных проблем с оборудованием. Список передаётся системным администраторам и сетевым специалистам.
Что мониторится
На всех серверах и их массивах мы проверяем следующие параметры:
- общую нагрузку на процессор, а также нагрузку на отдельно взятое ядро;
- утилизацию диска (I/O Utilization) и дисковую очередь (I/O Queue). Система автоматически определяет SSD/HDD, так как лимиты на них разные;
- свободное место на каждом дисковом разделе;
- утилизацию памяти, так как разные сервисы используют память по-разному. Есть несколько формул, которые высчитывают использованную/свободную память для каждой серверной группы, учитывая специфику задач, которые надо решать на конкретной группе (формула по дефолту: Free + Buffers + Cached + SReclaimable — Shmem);
- использование swap и tmpfs;
- Load Average;
- трафик на сетевых интерфейсах сервера;
- GC Count, Full GC Count и GC Time (речь о Java Garbage Collection).
На центральных свитчах (core) и маршрутизаторах проверяется использование памяти, нагрузка на процессор и, естественно, трафик. На коммутаторах уровня доступа трафик access-портов не мониторим, так как его мы проверяем непосредственно на уровне сетевых интерфейсов серверов.
Аналитика
Данные собираются со всех хостов при помощи SNMP и затем аккумулируются в систему DWH (Data Warehouse). О DWH мы рассказывали на Хабре ранее — в статье BI в Одноклассниках: сбор данных и их доставка до DWH. В каждом ЦОД стоят свои серверы для сбора этой статистики. Статистика с устройств собирается ежеминутно. Данные выгружаются в DWH каждые 90 минут. Каждый ЦОД генерирует свой комплект данных, их объём — 300—800 Mb за выгрузку, а это 300 Гб в неделю. Данные не аппроксимируются, поэтому есть возможность узнать точное время начала проблемы, что помогает найти её причину.
Все серверы в зависимости от своей роли в инфраструктуре разбиты на группы, на которые навешиваются thresholds (лимиты). После превышения лимита устройство попадёт в отчет. Группировка всех хостов происходит в специально разработанной для этого системе Service Catalog. Так как лимиты навешиваются на группу серверов, то новые серверы в группе автоматически начинают мониториться по таким же лимитам. Если администратор создал новую группу, тогда на неё автоматически навешиваются жёсткие лимиты, и если серверы новой группы попадают в проверку, то принимается решение, нормально это или нет. Если программисты считают, что это нормальное поведение для группы серверов, лимит поднимается. Для удобного управления лимитами создана панель управления, которая выглядит так:
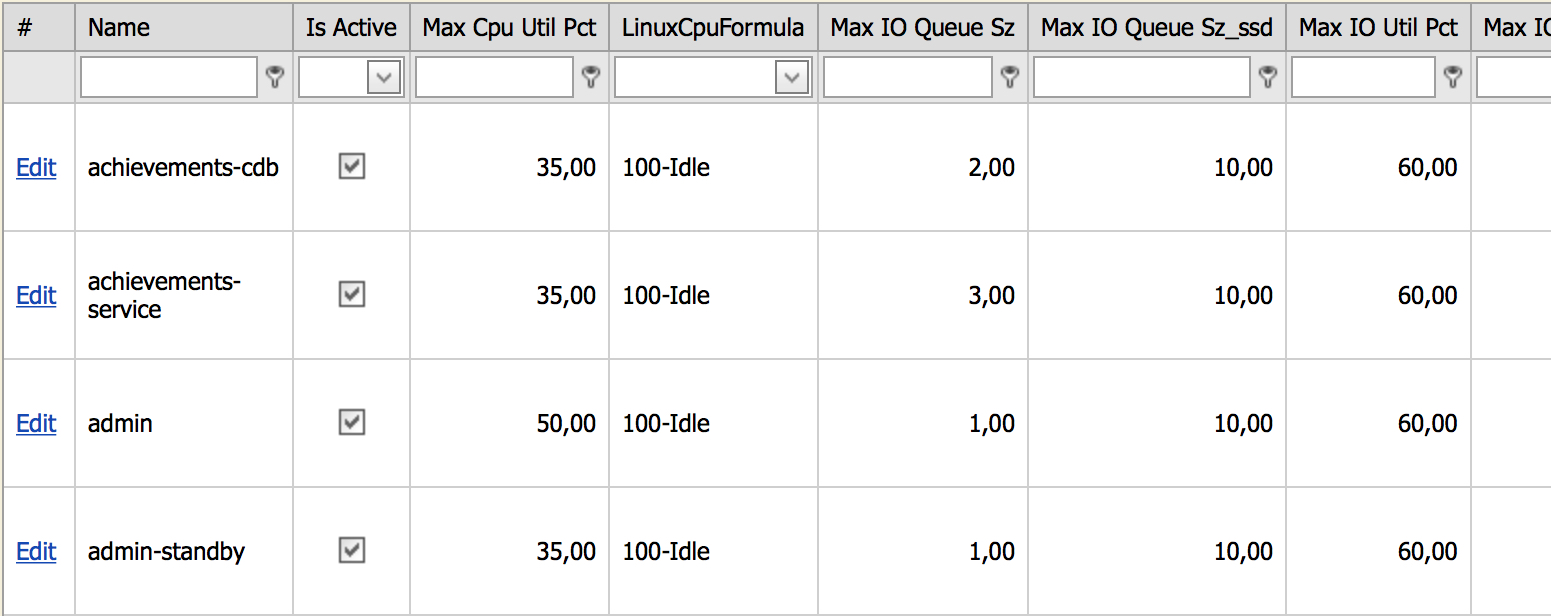
В этой админке можно увидеть все уникальные группы серверов и их лимиты. Например, на скриншоте видны лимиты для группы achievements-cdb:
- максимальная нагрузка на процессор не должна превышать 35 %;
- формула для расчета нагрузки на процессор 100 % — idle;
- лимит на дисковую очередь для HDD-дисков — 2, для SSD — 10.
И так далее. Поправить какой-либо лимит можно, только ссылаясь на задачу, в которой описаны причины изменения. Окно изменения лимита:
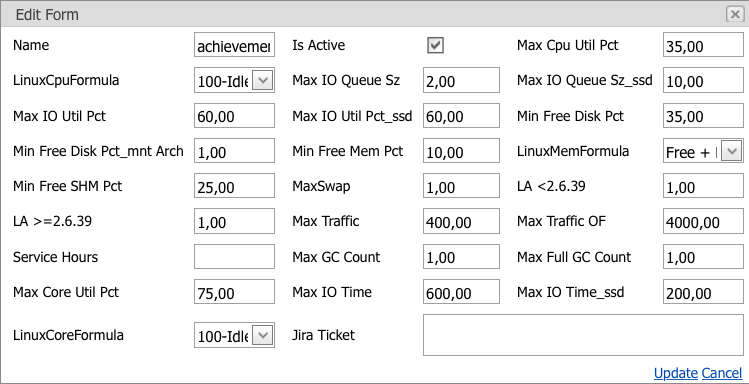
На скриншоте перечислены все текущие лимиты для группы серверов с возможностью их изменения. Применить изменения можно только в том случае, если заполнено поле «Jira Ticket»; в него записывается задача, в рамках которой решалась проблема.
Ночью, когда нагрузка на серверы значительно ниже, выполняются различные служебные и расчетные задачи, создающие дополнительную нагрузку, но они никак не влияют на пользователей или функционал портала, поэтому такие срабатывания мы считаем ложными, и для борьбы с ними был введен дополнительный параметр — сервисное окно. Сервисное окно — это интервал времени, в котором возможно превышение лимита, что не считается проблемой и в отчёт не попадает. Также к ложным срабатываниям относятся кратковременные скачки. Сетевая и серверная проверки разделены, так как серверные и сетевые проблемы решают разные отделы.
Что происходит с отчётом
Отчёт собирается по средам в один клик. Затем один из пяти «дневных» инженеров снимается с обычного «патрулирования» ресурса и работы по управлению тикетами, и начинает читать отчёт. Проверка занимает не более полутора часов. В отчёте — список всех возможных проблем в инфраструктуре, как новых, так и старых, которые ещё не решены. Каждая проблема может стать алертом админу, а сисадмин уже решает — сразу поправить или завести тикет.
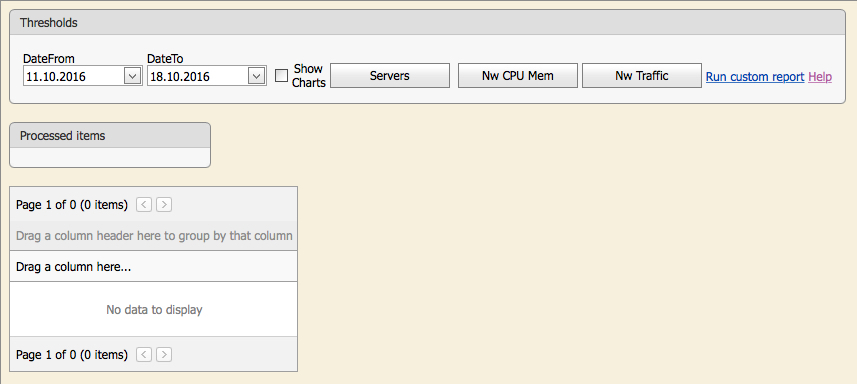
На картинке показано начальное окно проверки. Пользователь может кликнуть на соответствующую кнопку и запустить автоматическую проверку: «Servers» — всех серверов, «Nw CPU Mem» — использования памяти и процессора на сетевых устройствах, «Nw Traffic» — трафика на центральных свитчах (core) и маршрутизаторах.
Система интегрирована с JIRA (система управления задачами). Если проблема (превышен лимит) уже решается, напротив неё находится линк на тикет, в рамках которого ведётся работа над проблемой или которым она вызвана со статусом тикета. Так мы видим, в рамках какой задачи проблема решалась ранее — т.е. будет тикет со статусом Resolve.
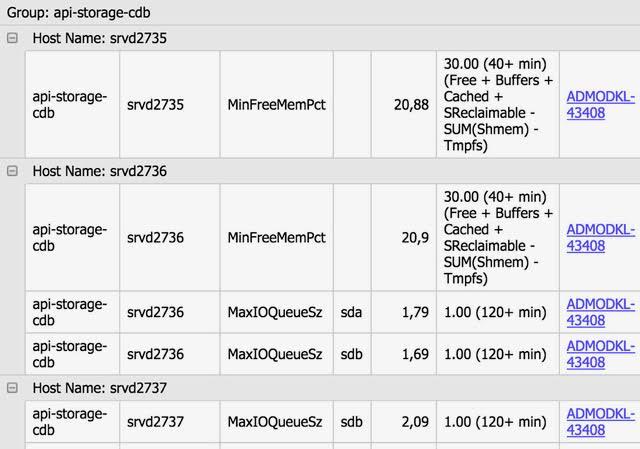
Все новые проблемы передаются старшим системным администраторам и старшим сетевым специалистам, которые создают тикеты в JIRA для решения каждой проблемы в отдельности, затем эти тикеты линкуются к соответствующим проблемам. У системного администратора есть возможность запустить специальную проверку по любому параметру, достаточно указать группу(-ы) серверов, параметр и лимит, а система сама выдаст все серверы, которые превысили лимит. Также можно посмотреть график по любому параметру любого сервера с линией лимита.
Пример попадания сервера на радары:
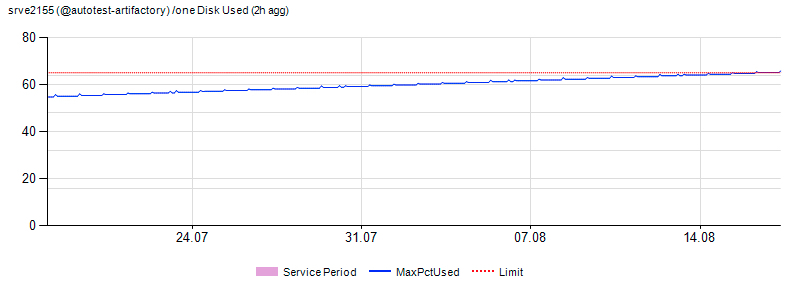
Для самых больших групп серверов (web — front end, уровень бизнес-логики и кеш данных пользователей) помимо обычной проверки производится долгосрочный прогноз, так как для решения проблем с этими группами необходимы значительные ресурсы (оборудование, время).
Долгосрочный прогноз также делает команда мониторинга, на это тратится около пяти минут. В отчёте, генерируемом системой, специалист по мониторингу видит графики основных показателей по подгруппам и в целом по группе с прогнозом на будущее, и если в течение двух-трёх месяцев будет превышен установленный лимит, то в этом случае также создаётся тикет на решение проблемы. Вот пример того, как выглядит прогноз:
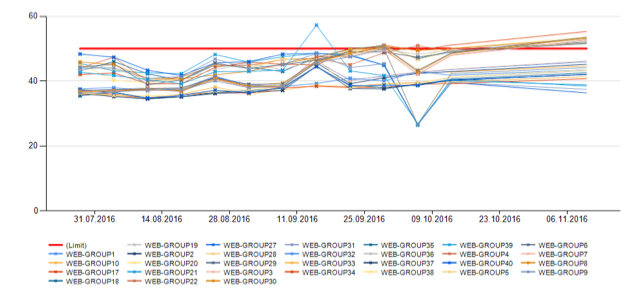
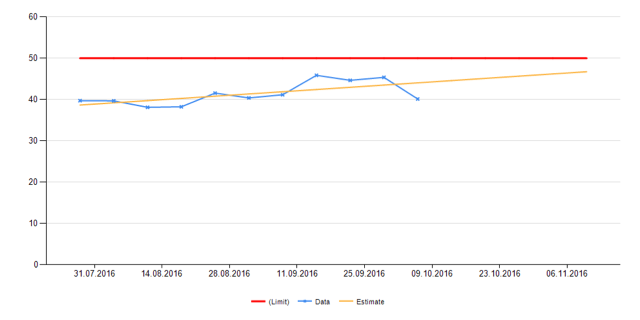
На первой картинке мы видим использование CPU всех групп web-серверов в отдельности, на второй — общее. Красной линией обозначен лимит. Жёлтая — прогноз.
Прогноз строится на основе достаточно простых алгоритмов. Вот пример алгоритма предсказания по нагрузке на CPU.
Для каждой группы серверов с шагом в семь дней строим точки по следующей формуле (пример для группы front end):
?(n — max load — min load)/(n — 2), где:
- n — кол-во серверов в группе;
- max load — максимальное значение нагрузки, которое продержалось более 30 минут на каждом сервере в отдельности за всю неделю. Складываем все значения нагрузок по группе серверов;
- min load — минимальное значение нагрузки, вычисляется аналогично максимальному.
Для получения более точного прогноза убираем один сервер с максимальной нагрузкой и один с минимальной. Этот алгоритм может показаться простым, однако он весьма близок к реалиям, и именно поэтому изобретать сложный анализ не имеет смысла. Таким образом для каждой группы серверов мы получим еженедельные точки, по которым строится аппроксимированная линейная функция.
На полученном графике можно увидеть предположительную дату, когда потребуется расширение или апгрейд группы. Аналогично предсказывается и дата, когда закончится место в больших кластерах. Проверяются кластеры фото, видео и музыки:
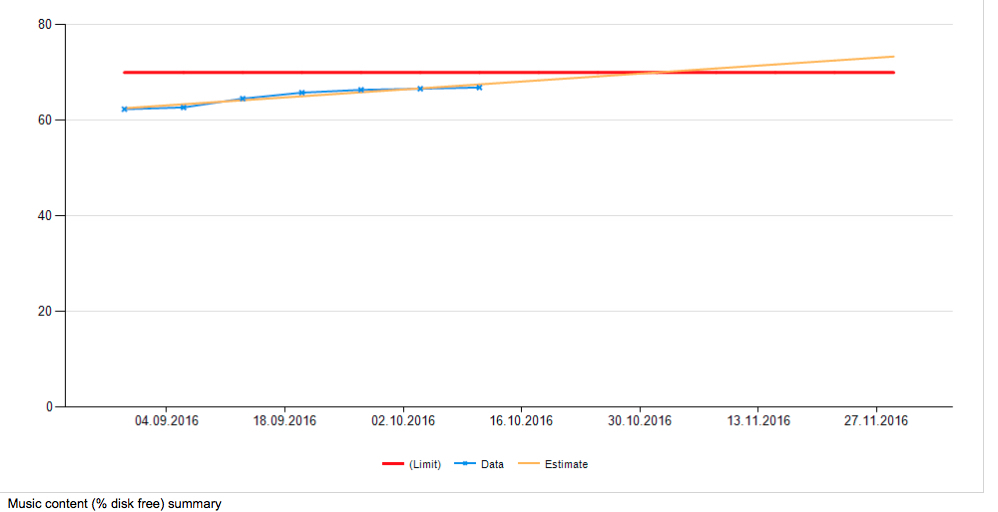
Система отбрасывает spare-диски (запасные диски в массиве), и они не попадают в эту статистику.
В итоге, после того как инженер из команды мониторинга создаст отчёт и оформит все проблемы, руководители возлагают на администраторов следующие задачи:
- расширить кластер photo;
- увеличить диски в group1 и group2;
- решить проблему с очередью на group3;
- разобраться с GC на group4;
- решить проблему с трафиком и нагрузкой на server1 и server2;
- решить проблему со swap на group5 и group6.
Все эти задачи на момент их постановки были не критичны, так как система обнаружила проблемы заранее, что значительно упростило работу системным администраторам: им не пришлось бросать всё, чтобы разрешить проблемы за короткий отрезок времени.
Новые метрики
Иногда нам нужны новые метрики. Это один-два новых показателей в год. Мы заводим их, чаще всего, по инцидентам, предполагая, что если бы чего-то заранее оповестило админа, инцидента могло бы и не быть. Однако иногда бывают нужны своего рода костыли — например, на кластере серверов с хранилищем больших фотографий как-то было утилизировано пространство на 80%. При расширении мы не могли технически перераспределить фотографии, а мониторить хотели на 70% заполнения. Образовалось две группы — почти полные сервера, которые генерировали бы алерт постоянно, и новые, девственно чистые. Вместо отдельных правил пришлось заводить виртуальную «фейковую» группу машин, которая поправила вопрос. Ещё из примеров — при массовом переходе на SSD надо было правильно выстроить мониторинг дисковой очереди, там очень отличается типичное поведение от обычных HDD.
В целом, работа устоялась, эта часть красивая, легко поддерживаемая и легко масштабируемая. Используя систему прогнозирования, мы несколько раз уже избежали нежелательной ситуации, когда сервера надо было бы закупать внезапно. Это очень хорошо прочувствовал бизнес. А админы получили ещё один слой защиты от разных мелких неприятностей.
Поделиться с друзьями
eurypterid
>В итоге, после того как инженер из команды мониторинга создаст отчёт и оформит все проблемы, руководители возлагают на администраторов следующие задачи
zipp3r
Похоже, сегодня это гифка дня. Из каждого утюга и по любому более-менее подходящему поводу. :(
TimsTims
Если не сложно, выложите сюда её. Корпоративный файрволл, он такой)
upd: нашел ниже, спасибо mihver1
cru5ader
Чем не устроили другие системы мониторинга, такие как zabbix или ibm tivoli monitoring?
Sharapoff
Zabbix мы используем как оперативный мониторинг.
Sharapoff
В статье описано решение того, как мы заранее узнаём о возможных проблемах в инфраструктуре. Zabbix для этой задачи не годится, потому что он плохо работает с таким кол-вом исторических данных, мы там храним только короткий (оперативный) промежуток времени.
Хотя Zabbix у нас используется для оперативного мониторинга, причем на срабатывания какого-либо триггера автоматически создаётся инцидент в JIRA.
NickODimm
А вы не пробовали хотя бы посмотреть в триал режиме, как будет справляться IBM Tivloi Monitoring?
Исходя из своего опыта общения с софтом IBM могу сказать, что время вы точно зря не потратите.
Просто у вас уже вырос из разряда «детских» и «юношеских», а инструменты решения задач остались на уровне стартаперских и самописных.
В целом, интересная статья, спасибо.
23derevo
Достаточно почитать статью на забре про Tivoli, и желание использовать сей продукт пропадет само собой. Как говорится, «не читал, но осуждаю»:
Впрочем, это все домыслы — с этим тулом я не работал. А вообще хочется что-то не очень дорогое, свежее и с большим коммьюнити.
NickODimm
Я какое-то время уже с Tivoli не работал, но постараюсь внести пару светлых пятен в ваше мрачное описание:
1. Настоящие пацаны интерфейсом не пользуются :) (шутка). Статья от 2013 года, в последних версиях ПО у IBM были довольно неплохие изменения на сколько я помню.
Что касается локализации, вот тут увы. На данный момент рынок корпоративного ПО довольно небольшой и локализации может не быть. Однако, с IBM всегда можно договориться о сотрудничестве. Они ребята умные и вежливые, может случиться так, что именно вы станете тем заказчиком для которого будет создана локализация.
2. Ядро написано довольно давно, но это не значит, что оно не модифицируется со временем и на мой взгляд задачи мониторинга с тех пор принципиально не изменились. Ньюансы-же настраиваемы.
3. Или как розовый слон :) Или как чугунный мост. Опять-же всё обсуждаемо и зависит от того на каких мощностях вы хотите использовать ПО. Там даже конфигуратор есть и программы типа On Demand. Вообще, на мой взгляд люди боятся IBM, т.к. думают что «оооо, это же IBM, у них всё дорого». Это не правильно. В конечном итоге и них дешевле, но не будем сейчас про TCO.
4. Я извиняюсь, но саппорт IBM был признан лучшим в мире. Сам с ним сталкивался, очень толковые специалисты + отличная система обработки тикетов + возможность привлечь ЛЮБОГО нужного специалиста компании по всему миру. Я не знаю откуда у вас негативная информация.
5. http://www.redbooks.ibm.com/. Вы меня, конечно, простите, но после окончания института пора уже перестать быть «стажёром» и вырасти до настоящего инженера, который знает где лежат руководства, пользуется best practices (которые, к стати тоже не глупые люди пишут) и который понимает, что если к софту есть инструкция, то её надо почитать.
Каюсь, сам из-за лени временами пытаюсь гуглить ответы на сайтах типа segfault и stackoverload, но когда дело касается серьёзного софта, решение в итоге проще и быстрее находится в руководствах.
Ещё boulder никто не отменял:
http://www.ibm.com/support/knowledgecenter/SSTFXA_6.3.0.1/com.ibm.itm.doc_6.3/welcome.htm
отличная библеотека по многим продуктам IBM.
Я за себя скажу: В один прекрасный день я проснулся и обнаружил, что есть мир за гранью командной строки Linux и глубже чем можно залезть мышью в Windows. Что серьёзные системы работают совсем на других ОС и что велосипеды которые придумывают в мире широкого потребления уже летают со сверхсветовыми скоростями где-то в датацентрах.
В общем, что касается Tivoli — стоит попробовать. ;)
sshikov
У меня совсем другие впечатления. Тикет вам конечно заведут — но фикса вы можете ждать много месяцев — и когда дождетесь, получите совсем не то, чего хотели.
navion
Понимаю, что в мире ентерпрайза принято надувать щёки и хвастаться TCO. Но все продукты IBM, с которыми довелось работать, старали от одних и тех же проблем:
1. Неконсистентность. Ядро сделано нормальными инженерами, но плагины и отдельные фичи часто пишут на коленке где-то в Индии.
2. Любой продукт это «вещь в себе» и требует бородатого админа для обслуживания. Особенно забавно смотрятся вакансии интеграторов, где в требованиях перечисляют несколько малосвязанных продуктов или просто Tivoli.
3. Несмотря на формальное наличие всех нужных фичей, их реализация зачастую уступает конкурентам.
4. Отсутствует сообщество и мало информации в доступном виде. Есть курсы, но именно на них попался лектор с нулевой практикой, пересказывавший учебник вперемешку с рекламным булщитом.
А плюс IBM в неплохой поддержке,
бекдорахсертификации ФСБ/ФСТЭК и возможности решить практически любую задачу, пусть дорого и с чудовищным юзабилити.i_shutov
за "бабло", которое уйдет на Tivoli можно в космос слетать. спросите любого, кто внедрял эту "систему".
NickODimm
Сильно сказано. Добавить особо нечего, если не разводить философию на тему того, что идеального софта не бывает.
ITSystemsManagement
Посмотрите в сторону Moogsoft, интересное решение
a2001
По вашей ссылке статья не про Tivoli Monitoring а про другой продукт из линейки Tivoli.
Насчет ваших домыслов, то с какими-то из них соглашусь (продуктом пользовался). А насчет желания это да, всегда хочется дешево, быстро и качественно.
cru5ader
Попробую ответить или опровергнуть.
* Интерфейс и локализация, по сравнению с версией статьи 2013 года стала получше.
Я может сужу со своей колокольни, но читая переводы статей на сайте IBM, понимаешь что работали над ними, именно работали, а не гугл транслейт.
* То что написано чуть ли в не 90-ых есть свои плюсы, в статье более подробно.
* Горы ответов и вправду нет, всю документация только на сайте ibm, и не так такого сообщества как у Zabbix.
Спасибо за интересную статью, тема мониторинга думаю всегда будет интересна.
SchmeL
У нас настроена связка grafana + graphite + collectd. Icinga2 в роли оповещалки, часть метрик берет из графита. Графики можно накладывать друг на друга и анализировать. Сложно было только настраивать icinga2, но после недели чтения документации все прояснилось… Был заббикс по началу, но у него нет такой гибкости как у icinga2.
Tolsty_kot
Тоже от Zabbix когда-то отказались и тоже такую связку используем, только вместо Icinga — sensu и оповещалка через PagerDuty. Функционал Icinga реализуется сенсовыми чеками, а исторические данные храним в графите.
Графана удобна тем, что у нас дежурные сидят и глазами в графики глядят — отклонения и странные тенденции видят лучше всяких анализаторов.
onlinehead
Ребята, а почему не подобное решение:
1. Фреймворк мониторинга а-ля Sensu.
2. Хранение истории чеков в Elastic
3. Сбор метрик коллектором с отправкой в Cassandra, допустим. И Spark для анализа данных, как движок для вычислений.
4. Push метрик, а не pull, потому что исключает необходимость наличия точки опроса (+1 к отказоустойчивости, -1 к сервисам на обслуживании). Правда SNMP тут уже не очень удобно будет, но это всего лишь протокол, благо тысячи их.
То есть, в принципе, получается, как и у вас, раздельный оперативный мониторинг и анализ исторических данных. Кстати, вот Influx обещают скоро таки допилить два в одном, но когда это будет…
Получается, ваша задача отлично сводится к «положить данные в жирное хранилище, которое можно читать чем нибудь для big data analyse», а дальше в принципе выбор есть. Но пара Cassandra+Spark пожалуй самая зрелая и распространенная, есть поддержка python (весьма распространенный язык среди админов), да и real-time опять же есть, можно часть алертов из мониторинга туда утащить, что как раз хорошо, потому что тогда можно stateless системы для оперативных алертов использовать, типа сбоя RAID или просто ухода машины в офлайн.
Тем более 300 гб данных в неделю с ЦОД — это не много. Если в сумме их 1ТБ, допустим, то это ~150Тб в год при репликации х3, или 4 storage-сервера максимум. В масштабах основной инфраструктуры — капля в море.
domas
В Zabbix не все хорошо с историческими данными. А тут довольно много получается и надо регулярно их анализировать.
robert_ayrapetyan
Даже в последнем, где предсказания добавлены как новая фича?
dmitrysamsonov
Даже в последнем всё ещё нет альтернативы MySQL для долговременного хранения данных, нет алтернативы встроенным функциям для триггеров и нет распределённого мониторинга без SPOF.
mihver1
mihver1
Пока модерировали, уже запостили гифку :(
janitor
А для метрик, которые больше связаны с не железом, а с приложениями (например количество запросов на какому-то URL, время ответа, количество 404 и т.п) — используете какое-то другое решение?
m0nstermind
нет, в общем и целом это то же решение. только данные туда попадают чуть по другому.
janitor
А рассматривали возможность использования что-то вроде SignalFX, prometheus.io? Если да — то что не устроило, если не секрет?
dmitrysamsonov
Рассматривали, но оно должно быть способным заменить собой все имеющиеся у нас системы мониторинга (различные in-house и opensource решения). Требований было достаточно много, но ничего сверхестественного по сегодняшним меркам. Тем не менее ни одно решение не подошло настолько, что бы бросится его внедрять (а заменить хорошо настроенный мониторинг в компании никогда не бывает легко). Кроме того у нас уже есть очень мощная по своим возможностям и производительности система, которая работает с различными performance метриками приложений. Именно она и легла в основу будущей системы.
GennPen
Почему у всех графиков ось значений начинаются с 0, а на графике кол-ва серверов с 6000?
Maklaut
Слышал что у вас нет отдельного нагрузочного тестирования. Как обходитесь без него?
hristoforov
Нагрузочное тестирование для новых технических решений проводим обязательно. И не только на синтетических тестах, а так же и на реальной нагрузке, включая систему в параллельном режиме.
23derevo
важно, что не только в параллельном, но и асинхронном. То есть, лаги на тестируемой системе никак не аффектят продакшен.
i_shutov
Вы правду про кухню одноклассников написали?
Жесткие пороги и линейный прогноз — это из 90-х. Так сейчас работают в "Home Office".
Адаптивные бейслайны, нелинейный прогноз для временных рядов…
см., например, продукты Vmware чего-то там, ранее Integrien Alive.
А что делаете с кратковременными нарушениями? В промышленных системах мониторинга есть еще и "окно наблюдения" для снижения шумов.
Сервисный мониторинг, как в ServiceWatch глядели?
==================================
Весьма грустную картину описали.
Посмотрите сюда:"Introducing practical and robust anomaly detection in a time series" или сюда:"Anomaly Detection with Twitter in R", хотя бы.
И сюда: "Anomaly Detection Using Elasticsearch" тоже неплохо бы заглянуть.
Sharapoff
Да, мы действительно описали кухню Одноклассников. Смотрите, в данном случаи нам не нужно детектить аномалии, нам нужно показывать тренды, а с этим хорошо справляется линейный прогноз. Да, это может выглядеть очень примитивно, но в данном случае нет смысла применять какой-то суперсложный алгоритм.
То, что вы советуете, у нас работает в другом месте — на оперативном мониторинге бизнес-логики портала (как будет время напишу про эту систему), там происходит анализ около 100 000 графиков в режиме реального времени.
i_shutov
т.е. вы говорите об автоматизации части процесса "Capacity Management"
Линейный прогноз, конечно, можно использовать на линейном участке, но осторожно.
В целом ИТ система нелинейна, а ряд ресурсов имеет ограничение сверху. При нагрузке выше среднего линейные прогнозы могут очень сильно подвести бизнес.
Упомянутая вторая часть про оперативный мониторинг гораздо интереснее с точки зрения сложности решаемой задачи. Было бы очень хорошо, если у Вас найдется время опубликовать.
m0nstermind
Для абстрактной ИТ системы — возможно. Думаю тут сильно зависит от того, насколько линейно масштабируется система. В случае ок.ру — вполне себе линейно, поэтому линейного прогноза в принципе хватает.
Конечно, и такую систему можно довести нагрузкой до нелинейного деградирования, но этот самый описанный в статье capacity planning и призван своевременно увеличивать мощности, чтобы удержать систему на номинальной нагрузке и, как следствие, линейном участке. Собсно поэтому линейного прогноза вполне хватает.
i_shutov
Работать с загрузкой проца 20-40% ничего интересного. Когда деньги не считают, то можно накупать серверов пока электричества хватит. Когда деньги экономят, то пытаются повысить утилизацию существующего оборудования. И тут как раз и надо красиво выходить в приграничную и граничную области.
m0nstermind
ок вполне считают деньги. Поэтому красотой приграничных областей и с интересом тратить время на сомнительную экономию при эксплуатации системы на режиме без запаса мощности — не занимаемся. Такой подход чреват потерей гораздо большего количества денег изза отказов, вызванных флюктуациями поведения пользователей и партнеров. Для нас более важна отказоустойчивость всей системы и ее доступность, чем экономия десятка серверов.
Все таки практика эксплуатации вполне предсказуемых расчетных задач и большой социальной сети, работающей с реальными людьми — разные вещи.
Над повышением утилизации тоже работаем, но естественно не так. Но это тема отдельной статьи.
i_shutov
тут сильно зависит от архитектуры. речь же не о двух серверах, а о > 10 тыс.
если у вас есть хорошие исторические данные, которые содержат и "флуктуации", грамотный механизм прогнозирования и механизм динамической балансировки, то на время ожидаемого всплеска вы можете ввести в экспуатацию +N виртуальных машин, а потом их загасить вместе с физическими. И нет никаких проблем. А в нормальное время повышать утилизацию активных машин.
Уже не раз сталкивался, когда возможности по расширению упирались в киловатты, которые физически можно подвести к ЦОД\зданию. Особенно в контуре Москвы.
а большой размер социальной сети как раз является плюсом, поскольку обеспечивает сглаживание флуктуаций. если только не будет флеш-моба какого.
23derevo
вам, простите, слово latency знакомо? Вы знаете, что происходит с latency современных серверов при попытке нагрузить машину на 50% и выше?
i_shutov
Да ничего :) Знакомо и не это слово. И закон Амдала и закон Литтла и теория очередей и Марковские процессы и имитационное моделирование и прочее...
Например, у нас были машины, которые постоянно работали на 90% загрузке, таков был стационарный режим конвертации CDR/xDR. И много других кейсов.
Но поскольку ответ с сутевой части перешёл на личности, то дальше можно не продолжать. Ну сделали, ну устраивает, ну не волнуют заданные вопросы — имеете полное право.
Я видел другие решения, более интересные. Что-то реализовывали в проектах.
Поэтому и спросил. Как я сразу отметил, все сильно зависит от задачи и архитектуры решения.
i_shutov
Можно, например, поглядеть OSSblog Netflix. Красивую штуку собрали на опенсорсе. А ещё работы одного из идеологов — Brendan Gregg
23derevo
Тот факт, что чьи-то машины работали на 90% нагрузки, ИМХО, говорит о том, что машин нужно было докупить. Или софт дооптимизировать. В общем, сделать что-нибудь, чтобы их разгрузить. Потому что 90% — это не норма, а хождение по тонкому льду.
Человека, который говорит, что 90% (80%, 70% загрузки машины) для распределенной отказоустойчивой системы — это норма, я бы выгнал ссаными тряпками за некомпетентность и фундаментальное непонимание проблемы.
i_shutov
Алексей, к чему так близко воспринимать альтернативные мнения, читать между строчек и терять человеческое лицо? Реальные ситуации гораздо многообразнее чем жесткий набор правил и догм.
Я полагал, что публикация на хабре является приглашением к дискуссии, а не площадкой корпоративного тщеславия. Формулировку про распределенную отказоустойчивую систему Вы уже сами додумали.
Тем не менее, чтобы не осталось непонимания.
Как я неоднократно приписывал, особенности конкретного решения зависят от исходной бизнес-задачи, архитектуры и используемых инструментов. В разных случаях возможны разные режимы функционирования.
В упомянутом мной кейсе про "90%" мы грамотно проанализировали бизнес задачу и допустимые режимы функционирования подсистемы, создали мат.модель, определили допустимые параметры и разработали подсистему конкретно под задачу конвертации CDR. Было это еще а ~2006-7 годах. В итоге, вместо закупки HP Superdome обошлись двумя SunFire 210 (или 240, точно уже не помню, давно было) в режиме Hot-Standy. Моментальный профит в разнице цен на железо! Ну и аптайм нашей подсистемы порядка 5 лет всех полностью устроил. Никого при этом нагрузка системы на 90% не беспокоила, все было промоделировано и рассчитано.
Например, в классе вычислительных задач, недозагрузка отдельного сервера в распределенной отказоустойчивой системы является злом. Есть поток данных, есть распределенные вычислители. При больших N вместо N серверов, работающих на 20% правильно использовать N/4 работающих на 100% + в резерве +1(+2, +3, +N/10) дополнительных вычислителей, готовых принять поток данных на обработку по мере необходимости. А еще и GPU при этом неплохо бы загрузить, чего зря стоять. Умный балансировщик гоняет задания исходя из состояния вычислителей, а не карусельным принципом. Но это уже вопросы архитектуры. Износ оборудования, обогрев воздуха, затраты на электричество — на круг получается совсем не копейка.
Хорошо, когда маржа в 100-300% позволяет покрывать любую неэффективность. Однако, переход к марже в 12-15% заставляет владельцев резко задуматься об оптимизации. Туалетную бумагу начинают под расписку выдавать. Мы все видим, что сейчас происходит на рынке и долгосрочные прогнозы не предсказывают возврата к прошлой модели потребления.
==========================================
Всем, кто интересуется вопросами производительности таких масштабных систем я бы посоветовал, кроме классической математики, почитать блог и книги Brendann Gregg. Труд, заслуживающий внимания и уважения:
А еще можно почитать и поиспользовать:
23derevo
Я ни в коем случае не хотел вас оскорбить или задеть. Если вам мои слова показались не уместными — я приношу свои извинения.
Судя по всему, мы с вами говорим о совершенно разных продуктах и совершенно разных требованиях. Я с вами не знаком и поэтому ничего не могу сказать о вашей компетенции. И ни в коем случае ее не оцениваю.
Одноклассники, как я писал выше, — постоянно растущая система: нагрузка на сервера постоянно растет, трафик растет, количество сервисов растет. Насколько я понимаю, сервисы проектируются с тем расчетом, чтобы в час пик нагрузка на машины не превышала 60% (тут мои данные могли устареть — я давно парней не спрашивал про цифры). Соответственно, не-в-часы-пик нагрузка будет сильно ниже. В эти моменты можно проводить эксперименты, гонять тесты и утилизировать машины всяким другим полезным образом.
Учитывая постоянный рост многих подсистем, пиковая загрузка в 60% дает приемлемое время отклика и некоторый запас по железу.
За ссылки спасибо — кое-что из этого я читал или читаю, большинство — новые для меня вещи. Надеюсь, к новому году будет время что-то из вашего списка прочитать.
Psychosynthesis
«Понимаю, звучит реально странно, но началось это с нескольких машин, и потом как-то неожиданно доросло до 5000 инстансов.»
Да что вы, ничего странного. У вас, походу, всё так. Мы привыкли.
23derevo
а что вы имеете в виду?
Psychosynthesis
Имею ввиду организацию рабочего процесса в мылору.
23derevo
Представьте себе, что вы запускаете некоторый проект. Например, социальную сеть 10 лет назад. Этот проект начинает экспоненциально расти по количеству пользователей, а значит, и по нагрузке. Узким местом становится то одна подсистема, то вторая, то третья. Параллельно с этим вводятся в эксплуатацию новые и новые сервисы. Инструментов толком никаких нет (на дворе 2006ой год, напоминаю).
И вы утверждаете, что Мэйл.Ру (Одноклассники, Яндекс, LinkedIn, MySpace, Facebook, да кто угодно) некомпетентны в этой ситуации? Ахахаха!
Psychosynthesis
Нет, я утверждаю, что все продукты, созданные внутри mail.ru (это важное уточнение, я не имею ввиду продукты, которые мылору купили), в своём бэкграунде традиционно имеют форменный бардак, что подтверждалось десятками историй от самих мылору, личных свидетельств непосредственных участников и вообще отношением мылору к собственным пользователям. Более того, на фоне конкурентов, продукты от мылору долгое время проигрывали по многим показателям, а по некоторым проигрывают до сих.
И да, я понимаю что ОК создавались вроде как не в мылору, но вписались они сюда весьма удачно, а так как запись находится в корпоративном блоге мылору, я и написал что мы тут к подобному подходу привыкли. Думаю мой первый комментарий был неверно истолкован.
23derevo
Я не очень понял, что вы имеете в виду. Да, какие-то продукты проигрывают конкурентам Mail.Ru по одним показателям, а какие-то — выигрывают у конкурентов по другим показателям. Одни продукты растут, другие — наоборот падают. У Mail.Ru огромный портфель продуктов и направлений, так что это совершенно нормально. Это называется «деверсификация бизнеса».
При чем тут «форменный бардак»? Как это связано с постом? Зачем вы это все тут написали? :)
Psychosynthesis
Вы знаете я вам могу ровно тот же вопрос задать. Специально для вас, повторим всё по шагам. В посту написали вот это:
Я на эту фразу ответил, хотя возможно чуть перегнул с сарказмом. Однако комментарии существуют для того чтобы задавать вопросы и выражать своё мнение. Я думаю очевидно, что я выразил своё (и не только) мнение. Далее вам почему-то стало непонятно, что именно я имею ввиду. Я вам разжевал.
Не надеюсь, что вы в состоянии воспринять чужой взгляд на ситуацию, думаю на этом диалог можно закончить. Спасибо.
Scf
А как вы отслеживаете метрики java приложений? Они часто специфичны для приложения и их много.
m0nstermind
Это в принципе тема отдельной статьи. Есть немного информации тут: Распределенные системы в Одноклассниках. Немного, но больше чем можно уместить в коммент.