
Однако у меня есть собственный проект на C#, который развиваю в свободное время. Чтобы не заморачиваться написанием велосипеда когда-то скачал HeatonResearchNeural прикрутил скотчем и спокойно гонял тесты, дорабатывал логику своего кода и т.д. Для максимального ускорения заложил в архитектуру решения параллелизацию выполнения расчетов и глядя на загрузку CPU по 80-90% по телу разливалось приятное хозяйское тепло — все пашут, все при деле!
С другой стороны, объемы у меня большие, ждать приходилось долго, пока она отработает. Подумывал даже о покупке второго сервера, пока меня вдруг не посетила мысль заглянуть под капот этого самого велосипеда при помощи профилировщика. Причем возникла не сама по себе, а под впечатлением данной статьи уважаемого хабробщества.
Изначально в своем коде я был уверен. Понятно, что нейросеть эта такая вещь, которая должна летать, иначе не вытянет серьезных тем. Однако, прямо как после чтения медицинского справочника обнаруживаешь у себя большинство признаков самых чудовищных заболеваний, решил все-таки
Когда профилирование указало на библиотечные функции, в душе затрепетало хладнокровное волнение. Понятно, что разработчики такой хорошей библиотеки подумали про скорость, верно? Или миром все-таки правит не тайная ложа, а явная лажа? Чтобы ответить на этот вопрос давайте рассмотрим внимательнее результат прогона 100 циклов моей программы, почти целиком состоящей из работы нейросетей:
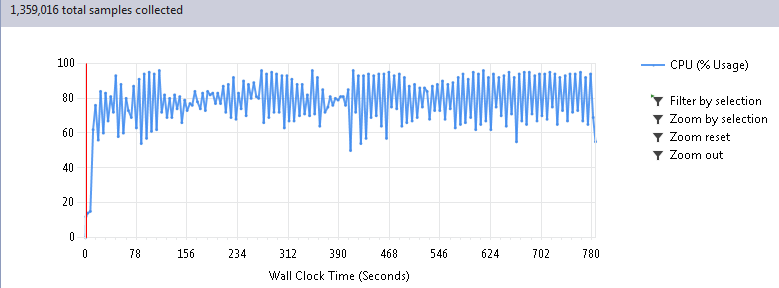
Проваливаемся в Call Tree отчета и находим самые тяжелые функции:
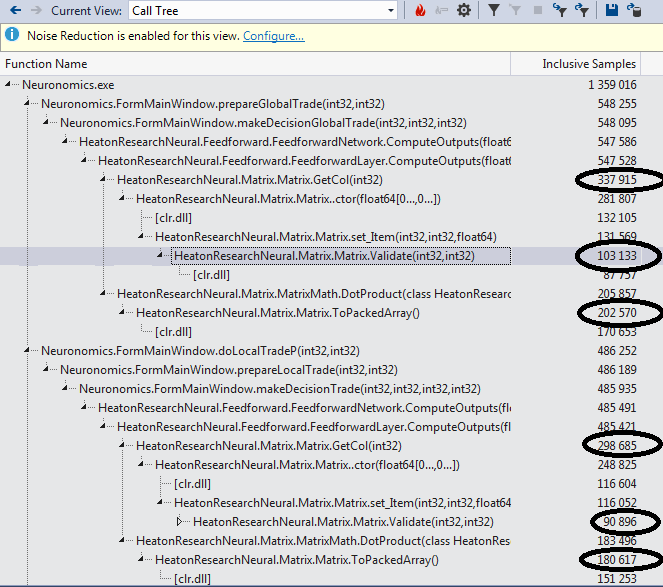
Идем к ним и видим воистину душераздирающее зрелище. Если вы не совершенно уверены в своей психике, возможно имеет смысл отвернуться и не видеть, как функция GetCol занимается богопротивным извлечением вектора из матрицы:
public Matrix GetCol(int col)
{
if (col > this.Cols)
{
throw new MatrixError("Can't get column #" + col
+ " because it does not exist.");
}
double[,] newMatrix = new double[this.Rows, 1];
for (int row = 0; row < this.Rows; row++)
{
newMatrix[row, 0] = this.matrix[row, col];
}
return new Matrix(newMatrix);
}
Лишь для передачи в DotProduct:
for (i = 0; i < this.next.NeuronCount; i++)
{
Matrix.Matrix col = this.matrix.GetCol(i);
double sum = MatrixMath.DotProduct(col, inputMatrix);
this.next.SetFire(i, this.activationFunction.ActivationFunction(sum));
}
Лишаем этого паразита питательных и полных витаминами гигагерц двумя точными ударами прямого слэша и передаем в DotProduct сразу всю матрицу вместе с нужным номером колонки:
//Matrix.Matrix col = this.matrix.GetCol(i);
double sum = MatrixMath.DotProduct(this.matrix, i, inputMatrix);
А уже внутри вместо изящного кружева:
public static double DotProduct(Matrix a, Matrix b)
{
if (!a.IsVector() || !b.IsVector())
{
throw new MatrixError(
"To take the dot product, both matrixes must be vectors.");
}
Double[] aArray = a.ToPackedArray();
Double[] bArray = b.ToPackedArray();
if (aArray.Length != bArray.Length)
{
throw new MatrixError(
"To take the dot product, both matrixes must be of the same length.");
}
double result = 0;
int length = aArray.Length;
for (int i = 0; i < length; i++)
{
result += aArray[i] * bArray[i];
}
return result;
Лепим простой, как топор, быдлокод:
public static double DotProduct(Matrix a, int i, Matrix b)
{
double result = 0;
if (!b.IsVector())
{
throw new MatrixError(
"To take the dot product, both matrixes must be vectors.");
}
if (a.Rows != b.Cols || b.Rows != 1)
{
throw new MatrixError(
"To take the dot product, both matrixes must be of the same length.");
}
int rows = a.Rows; // Так будет гораздо быстрее, чем если указать a.Rows прямо в условии цикла
for (int r = 0; r < rows; r++)
{
result += a[r, i] * b[0, r];
}
return result;
Валидаторы на выход за пределы массива тоже имеет смысл закомментировать, все равно размеры задаются статически при компиляции и тут сложно накосячить, а времени на них убивается столько же, сколько японцев с небоскребов при ослаблении йены на 5%.
public double this[int row, int col]
{
get
{
//Validate(row, col);
return this.matrix[row, col];
}
set
{
//Validate(row, col);
if (double.IsInfinity(value) || double.IsNaN(value))
{
throw new MatrixError("Trying to assign invalud number to matrix: "
+ value);
}
this.matrix[row, col] = value;
}
}
Итак, волнительный момент, запускаем опять 100 циклов программы. Когда я увидел эффект от этих нехитрых действий, мне чуть не поплохело от радости. Такое странное чувство, как будто тебе вот так взяли и подарили 30 серваков (которые, оказывается, стояли у тебя же в шкафу, но ты просто не догадывался туда заглянуть):
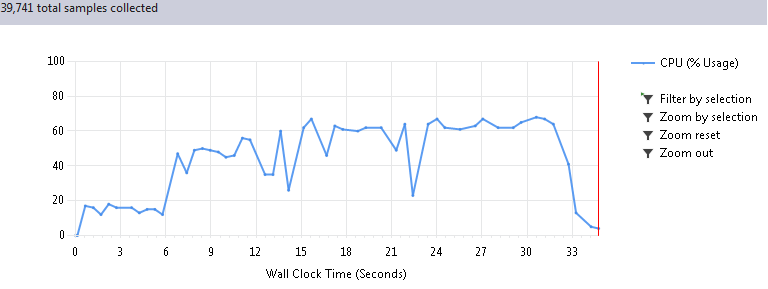
Первые 6 секунд на графике это подготовка данных, поэтому реальное время работы сократилось с 780 до 26 секунд, при абсолютно одинаковом результате, естественно. Таким образом, ускорение получилось в 30 раз!
Таким образом, практика еще показывает, что законы Мерфи вкалывают также стабильно, как афроамериканцы сидят на велфере и если что-то может пойти не так, то можно не сомневаться, так оно и случится. Также стоит отметить, что возможно некоторые виды сетей не будут работать на таком коде, это стоит протестить и учесть при необходимости. Всем спасибо за внимание, надеюсь это кому-нибудь хоть как-то поможет в успешной борьбе с неудержимо разрастающейся энтропией вселенной и кода.
Комментарии (22)

forcewake
27.10.2016 12:33+1Можно было бы еще поэксперементировать с System.Numerics.Vectors. На хабре была неплохая статья на эту тему https://habrahabr.ru/post/274605/.

Danov
27.10.2016 13:10+1Интересно было бы про саму библиотеку прочесть в примерах. А если в двух словах, что в ней можно делать?

pustota_2009
27.10.2016 14:11Кроме классических сетей (с реализацией обучения, отжига и т.д.) есть сети Хопфилда, самоорганизующиеся карты Кохонена. Вот тут куча примеров использования:
https://github.com/jeffheaton/jeffheaton-book-code/tree/master/CSIntroNeuralNetworkEdition2
daiver19
27.10.2016 13:29+1Здорово получилось, конечно. Но что-то мне подсказывает, что переход на GPU обеспечит ускорение еще на порядок :)
pustota_2009
27.10.2016 14:13Да, GPU показывает изумительные результаты. Я пробовал делать расчеты на GPU, оказалось там очень большие затраты на ввод вывод данных (вплоть до проигрыша CPU в сумме). Специфика моего приложения в том, что обмен данными очень интенсивный, такой что смысла юзать GPU не увидел.
Danov
27.10.2016 14:29+1Прежде еще можно задействовать SIMD (System.Numerics.Vectors) и переделать double на float.
old_bear
27.10.2016 17:34+1Этот код у его автора на гитхабе лежит. Почему бы не запилить туда коммит для более всеобщей борьбы с энтропией?

kanikeev
27.10.2016 18:14+1«и глядя на загрузку CPU по 50-60% по телу бежал неприятный холодок — кто-то халтурит!» :)
pustota_2009
27.10.2016 20:41Да это к счастью не проблема, загрузить проц весьма легко увеличив кол-во параллельно выполняющихся потоков в 1,5-2 раза, данный пример был для сравнимости результатов при одинаковом коде приложения (менялась только библиотека).
fedorro
27.10.2016 19:18А статья для которой версии библиотеки? GetCol в текущей есть, но ни разу не используется. DotProduct вызывается в одном месте, не очень часто используемом. Можно попробовать сравнить с результатом, при использовании последней версии.
Danov
31.10.2016 17:31Интересно, какие задачи решаете с помощью этих сетей?
И какие максимальные размеры сеток (сколько слоев)
и входных таблиц (столбцов, строк) получается обрабатывать в этой библиотеке?pustota_2009
04.11.2016 13:10Проект — макроэкономическое моделирование. Надеюсь вскоре будут результаты достойные публикации. Размер сеток на данный момент 200x70x15 (три слоя).
Danov
04.11.2016 19:44Продолжаю любопытствовать. А топология которая используется? MLP?
pustota_2009
05.11.2016 14:41Да, собственно топологии еще не перебирал (даже кол-во слоев не пробовал менять). Пока занимаюсь отладкой общей логики и функциональной обвязки (распределение вычислений по сети на несколько машин и агрегация результатов).
shai_hulud
Я думаю, что замена многомерных массивов double[x,y] на одномерные double[x*y] даст неплохой прирост производительности. Не в 30 раз конечно но даст.
SystemXFiles
Далеко не факт.
Я не работал с C#, но на Java (понимаю что языки совершенно разные) приходилось иногда делать расчеты в многомерных массивах.
Очень и очень редко переход с n-мерных массивов к одномерному приводили к ускорению выполнения. В особо успешных случаях ускорение было, но на грани погрешности.
Смею предположить, что иногда компилятор или VM догадываются о том, что делает код и сами разворачивают его в один цикл.
Вполне возможно, что C# способен на такое.
Вообще лучше всего проверить на практике. У меня жаль под рукой C# нет
shai_hulud
>Вполне возможно, что C# способен на такое.
Не не способен. Печаль в том что в .NET хорошо оптимизированы одномерные массивы, и вообще никак многомерные. К примеру доступ к элементу в одномерном массиве это IL opcode ld.elem, в многомерном это вызов метода на классе Array, который потом транслируется в кишки CLR. Так что разница может быть существенной.
pustota_2009
Думаю вы правы, что это ускорило бы процесс. Только это потребовало бы уже гораздо больше усилий, чтобы перепахать всю внутреннюю логику на поддержку этого.
maaGames
Имеет смысл для маленьких матриц, которые полностью влезут в кэш. Для больших матриц принципиальной разницы не будет ни на каком ЯП.
Flux
Здравый смысл подсказывает что многомерные (которые T[,] а не jugged вариант T[][]) массивы внутри устроены как обычные одномерные с трансляцией индексов вида
(возможно с выравниванием), и вряд ли дадут значительное ускорение при ручном перепиливании.Могут ли товарищи знакомые с кишками компилятора подтвердить или опровергнуть эту догадку?
pustota_2009
Проверил, простое заполнение небольшого двумерного массива x,y проходит несколько медленнее, чем одномерного x*y.
int x, y, z;
int i, j, k;
x = 100;
y = 10;
z = 10000;
double[,] a = new double[x, y];
double[] b = new double[x * y];
Stopwatch stA = new Stopwatch();
stA.Start();
for (k = 0; k < z; k++)
for (i = 0; i < x; i++)
for (j = 0; j < y; j++)
a[i, j] = i * k;
stA.Stop();
Stopwatch stB = new Stopwatch();
stB.Start();
for (k = 0; k < z; k++)
for (i = 0; i < x * y; i++)
b[i] = i * k;
stB.Stop();
Results:
stA.Elapsed.Ticks = 531087
stB.Elapsed.Ticks = 390716