

Предисловие
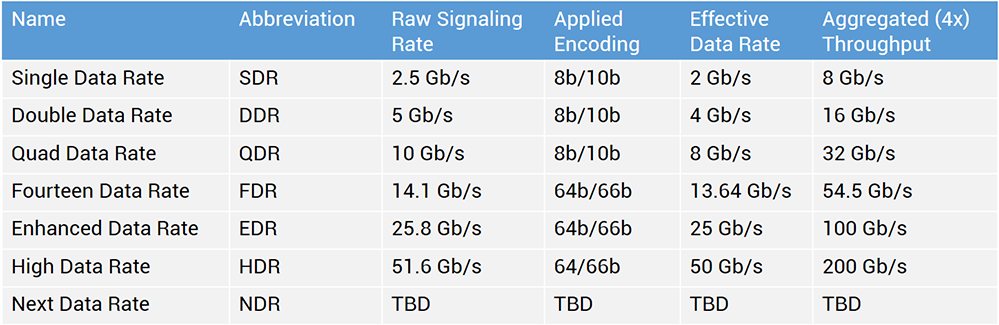
Пропускная способность внутри облака — этот пункт очень важен с технологической точки зрения. Это щепетильный момент, очень многие поставщики неохотно говорят на эту тему. Они не хотят раскрывать структуру своей сети. Но если посмотреть на суть вопроса, то от этого зависит насколько качественную услугу вы купите у провайдера. Это во многом зависит от скорости внутри облака. Как ноды соединены между собой? На каких скоростях? По каким протоколам? Сервисы многих предприятий вполне могут работать на 1 гигабите, но нужно учесть, что большинство провайдеров используют 10G, и только самые продвинутые строят свои облака на 40G или InfiniBand 56G.
Под катом пару мыслей о том, почему для нашего облака мы выбрали именно InfiniBand.
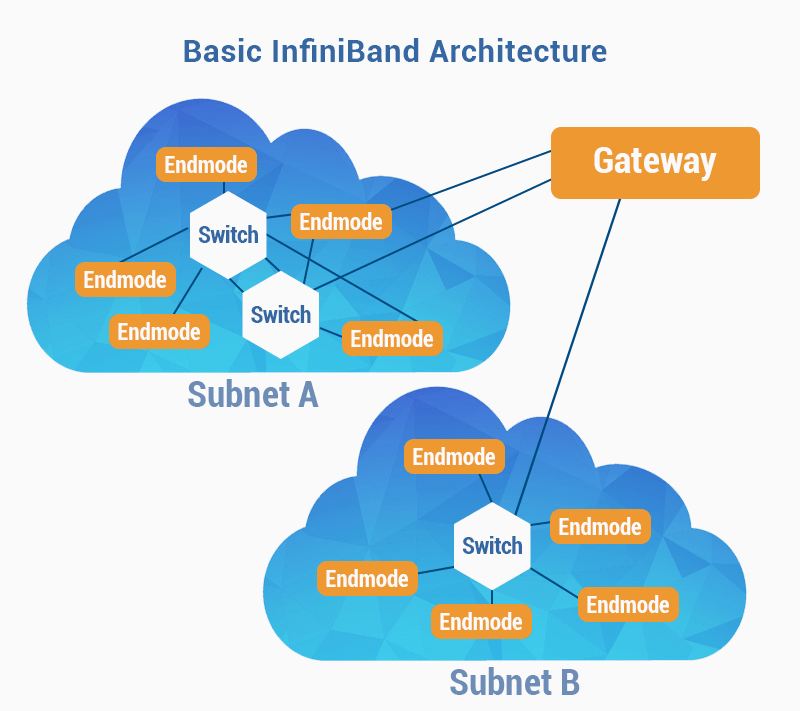
Технология InfiniBand сама по себе существует уже давно, ее разработали и начали применять в среде суперкопьютеров. В среде высокопроизводительных систем, нужно было объединить большие кластеры связующей шиной для быстрого обмена данными.
Задачи InfiniBand в инфраструктуре
Самому инфинибенду столько же лет, сколько и ethernet. Этот протокол разрабатывался в недрах суперсистем, соответственно, его задачи под которые он проектировался, требования к производительности, задержкам и архитектуре диктовались кластерными системами. С дальнейшим развитием интернета, InfiniBand развивался не так бурно, скорее всего по той причине, что этот стандарт достаточно нишевый.
Сейчас, с ростом облачных технологий, которые уже вышли так сказать «к народу», когда облака уже используются не только в высоковычислительных системах, но используются на потребительском уровне – здесь InfiniBand обрел второе дыхание.
Этот протокол не только вырос в производительности, но и стал уже достаточно массовым, ранее даже в высокопроизводительных средах скорость обмена данными была значительно меньше — 4, 8 гигабит. На сегодняший день 56 гигабит – это текущий стандарт, который уже стал распространённым. Сейчас производители InfiniBand оборудования, такие как Mellanox, продают оборудование с пропускной способностью 100 гигабит.
Такими темпами InfiniBand вендоры ближайший год могут выпустить еще более быстрое оборудование. Основные преимущества протокола InfiniBand – это большая пропускная скорость, и, самое главное, — низкие показатели задержки. Сам стандарт и оборудование позволяют передать пакет в 10 быстрее чем ethernet. Для высокопроизводительных компьютеров и современных систем передачи данных это сыграло большую роль.
Следующим важным моментом является то, что эта технология уже усовершенствована в тех средах, где она была разработана. Этот стандарт уже имеет, так сказать «правильную» архитектуру plug-in-play – все достаточно автоматизировано: постройка дерева, инфраструктуры и т.д. Поэтому от инженера не требуется большого количества телодвижений по настройке. Кроме того, в самом протоколе уже заложен запас отказоустойчивости.
Конечно, в Ethernet все эти возможности также присутствуют – но реализуется целым пулом технологий – которые все нужно настраивать отдельно, и которые нужно проверить и оттестировать на совместимость. Инженеру, при работе с Ethernet необходимо учитывать большее количество частей инфраструктуры.
Melanox также позиционируют оборудование InfiniBand как гиперконвергентное — все их оборудование можно использовать как для InfiniBand сети так и для ethernet-сети – Ethernet реализуется поверх InfiniBand сети. Это значит, что не будет необходимости ставить разные коммутаторы для разных сетей – мы ставим одно устройство и выделяем группу портов как san, вторую группу портов будет Ethernet 40 гигабит. Эта тенденция идет из среды рождения протокола — гиперконвергентных инфраструктур. Таким образом в одном устройстве совмещается максимальное количество ролей — оборудование унифицируется. Вместе с тем, нужно сказать, что при всех прочих равных, InfiniBand – как технология, проста, в ней нет множества других функций, которые есть у стандарта ethernet.
Сейчас протокол InfiniBand активно используется на уровне san сети в облачных средах.
В данный момент мы проектируем и планируем внедрить вторую архитектуру нашего облака, где будем полностью переходить на гиперконвергентную инфраструктуру – InfiniBand будет и на уровне san-сети и на уровне wan-сети. Если сравнивать это оборудование с обычными коммутаторами – скорость выше с меньшими задержками (что очень актуально для высоконагруженных приложений). Если говорить в цифрах, то при использовании ethernet-протокола задержки идут порядка 20-30-40 миллисекунд, то в InfiniBand – задержка 1-2 миллсекунды.
В своей облачной инфраструктуре, в наших дата-центрах, мы используем оборудование Mellanox 56 гигабит. Пока что мы не рассматриваем перехода на 100 гигабит, так как для наших задач 56 гигабит – хватает с запасом, и есть резерв на будущее. Мы выбрали именно этот протокол по нескольким причинам:
- универсальность;
- гиперконвергентность;
- стоимость;
- возможность роста.
Mellanox, как производить InfiniBand оборудования делает, на наш взгляд, самый большой вклад в развитие этого протокола: внедряет много новых функций, и улучшает сам протокол. Кстати сказать, многие производители или просто брендируют платформу Мellanox, либо берут чипы меланокса, и впаивают их в свое оборудование.
На данный момент на рынке присутствуют системы all-flash, построенные на быстрых flash-дисках. Но для такого рода систем необходима быстрая среда для передачи данных. При недостаточной скорости обмена между хранилищами, потребители услуги не получат данные на хорошей скорости, тогда теряется весь смысл в быстрой флеш-памяти (подобно тому, как для очень быстрой машины, нужна очень хорошая дорога). Часто раздаются мнения о том, что 50% задач ИТ до сих пор не требуют таких сумасшедших скоростей. Флеш-накопители хорошо себя показывают там, где есть большие базы данных, и нужна высокая производительность для быстрой выборки данных, там, где админы чаще всего жалуются – «нужно помощнее процессоры… побыстрее диски…». Также большой скорости высокопроизводительного хранилища требуют решения типа DaaS, VDI, например, когда все виртуальные машины обращаются к хранилищу, что приводит к т.н. бутсторму и зависанию хранилища. Для других задач, как-то: терминальные сервера, почтовые сервера – там хватает скорости дисков SSD и SATA. Поэтому мы считаем, что платить за ненужную скорость – нет необходимости.
Почему мы решили использовать InfiniBand?
У нас стояла задача построить достаточно масштабируемое хранилище – и был вариант классического хранилища – FiberChannal + обычные стореджи. Или же можно было смотреть в сторону новомодных SDS (Sofware Define Storage) – более детально изучая эту технологию стало очевидно, что при этом варианте построения инфраструктуры важна не сколько пропускная способность (в среднем хватает и 15 гигабит на канал), но нужны были очень низкие задержки по передаче пакетов. Да, есть ethernet-коммутаторы, которые умеют делать задержки, как и у InfiniBand – но это такие большие «комбайны» – которые нам ни по цене, ни по нужным задачам не подходили (на наш взгляд это оборудование не совсем подходит для сторедж-сети, а более удобно для использования в van-сети. Было принято решение взять на тест оборудование InfiniBand Mellanox. После успешных тестов, оборудование было установлено в нашей ИТ-инфраструктуре.
Nota Bene: Во время тестов, отметили, что в презентациях Mellanox не было «чистого» маркетинга – все характеристики оборудования полностью соответствовали заявленному функционалу.
Полезный UPD из коммента (спасибо Igor_O):
Забыли вы еще одну очень важную особенность Infiniband, выросшую из его суперкомпьютерного прошлого: возможность построения неблокирующей сети (с топологией толстого дерева). Т.е. такой сети, где если 50% узлов сети одновременно начнут передавать данные другим 50% сети — задержки и скорость передачи данных останутся на том же уровне, как и при общении одного узла с одним узлом.
Полезные ссылки:
» InfiniBand в вопросах и ответах (eng)
» Как мы переводили облако с Ethernet 10G на Infiniband 56G
» Infiniband: матрица для данных
» Про InfiniBand: как мы уменьшали пинг с 7 мкс до 2,4 мкс (и результаты тестов)
SIM-Networks – отказоустойчивое облако в Германии, SSD хостинг и VPS
Поделиться с друзьями
Комментарии (7)

ishevchuk
03.11.2016 10:22Если говорить в цифрах, то при использовании ethernet-протокола задержки идут порядка 20-30-40 миллисекунд, то в InfiniBand – задержка 1-2 миллсекунды.
А можно более подробно объяснить почему (с точки зрения протокола и интерфейса) задержка меньше в 20 раз?
Как она считалась — от юзерспейса до юзерспейса через 1 (или N) свитчей?

Igor_O
03.11.2016 10:41+3Забыли вы еще одну очень важную особенность Infiniband, выросшую из его суперкомпьютерного прошлого: возможность построения неблокирующей сети (с топологией толстого дерева). Т.е. такой сети, где если 50% узлов сети одновременно начнут передавать данные другим 50% сети — задержки и скорость передачи данных останутся на том же уровне, как и при общении одного узла с одним узлом.


ktotomskru
03.11.2016 10:42+2Если говорить в цифрах, то при использовании ethernet-протокола задержки идут порядка 20-30-40 миллисекунд, то в InfiniBand – задержка 1-2 миллсекунды.
точно миллисекунд?
Igor_O
07.11.2016 22:56Кстати да, ЕМНИП, то в ТЗ на суперкомпьютер фигурировали наносекунды, а в википедиях пишут про 1,3 микросекунды для QDR.

Loxmatiymamont
03.11.2016 12:29А можете немного подробней расписать причину отказа от FC?
Могу ошибаться, но fcoe коммутаторы, с поддержкой дают адекватные задержки и стоили вменяемых денег.
alexyr
Мой брат только что из Mellanox уволился, дальше учиться пошёл. Много хорошего рассказывал про их железки