
В конце обзорной статьи про историю и развитие PCI Express Алексей упомянул о нашем собственном адаптере для внешнего подключения PCI Express (далее для краткости — PCIe) устройств посредством кабеля. Сегодня я расскажу, как мы его тестировали и отлаживали для правильной работы с разными типами и длинами кабельных соединений.

Адаптер был разработан для соединения компонентов наших систем между собой по шине PCIe посредством кабеля. На момент разработки существующие для этого готовые решения нас не устраивали по ряду причин – какие-то не поддерживали скорости Gen3, какие-то использовали кабели, которые мы считали бесперспективными и т.п.
Далее я расскажу с какими проблемами мы столкнулись (и до сих пор сталкиваемся) при работе с нашим адаптером. Но для того чтобы лучше понимать смысл — сначала углубимся в теоретические аспекты взаимодействия PCIe устройств.
Сделаю оговорку — описанное ниже относится в целом к PCIe, но в рамках этой статьи для конкретики я использовал терминологию из документации PLX, так как работает наш адаптер именно на чипе этого производителя. У других производителей аналогичные методы и сущности могут называться иначе, что сути не меняет.
Тюнинг
PCIe-устройства имеют эквалайзер в приемном и передающем трактах. Параметры эквалайзеров можно и нужно изменять (тюнинговать) с целью получения надёжного (BER < 10-12) соединения.
Тюнинг передатчика
Передатчики PCIe имеют следующие параметры эквалайзера, которыми можно управлять:
- De-emphasis или post-cursor
- Pre-shoot или pre-cursor
- Main или cursor
Чтобы слово «cursor» не мелькало постоянно — далее я буду использовать первые версии наименования данных параметров.
Эти параметры определяют соотношения между амплитудами сигнала во временной области:
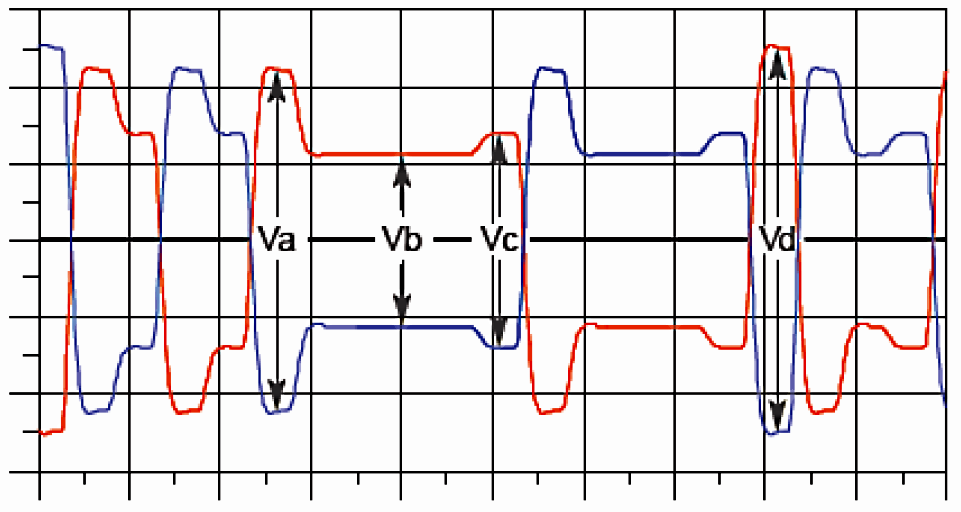
Коэффициент De-emphasis определяет соотношение Vb/Va, коэффициент Pre-shoot отвечает за соотношение Vc/Vb, а Main — это, по большому счёту, размах между максимальным значением с учетом pre-shoot и минимальным с учётом de-emphasis (размах между короткой верхней полкой и длинной нижней) или наоборот.
Если не очень глубоко вдаваться в технические детали — De-emphasis усиливает амплитуду передаваемого бита в зависимости от значения предыдущего бита, а Pre-shoot — делает то же самое в зависимости от значения следующего бита. Main определяет размах сигнала в целом.
Значения Main, De-emphasis и Pre-shoot задаются коэффициентами от 0 до 63. Сумма всех коэффициентов должна быть равна 63. То есть, если задать Pre-shoot = 6 (3.5 dB), а De-emphasis = 13 (-6 dB), то на Main останется только 44. Таким образом происходит перераспределение энергии сигнала между ВЧ (переключение битов) и НЧ (несколько 1 или 0 подряд) составляющими.
Забегая вперед, скажу: для 10-метрового кабеля в нашем случае оптимальные значения — это 63 на Main и по нулям на Pre-shoot и De-emphasis, либо 55—57 на Main с небольшим значением Pre-shoot. То есть на такой длине кабеля сигнал затухает так, что приёмнику уже становится не до фронтов — он просто не может распознать наличие сигнала в линии.
Тюнинг приёмника
При поступлении сигнала в приёмник последовательно задействуются такие инструменты:
- ATT (аттенюатор);
- BOOST или CTLE — усилитель ВЧ составляющей;
- DFE — блок, по сути работающий аналогично de-emphasis/pre-shoot стадиям передатчика (по умолчанию отключен), предназначен для устранения межсимвольной интерференции (ISI).
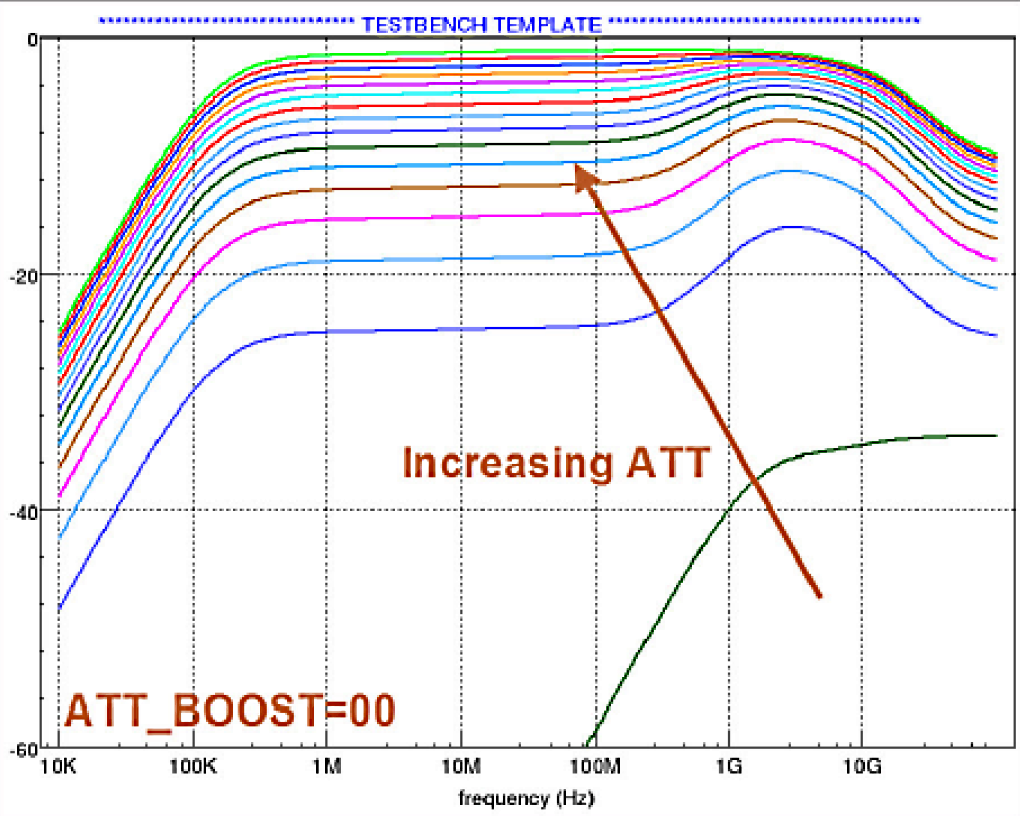
Передаточная функция ATT — практически равномерное ослабление сигнала во всём диапазоне частот:
Передаточная функция CTLE — значительное усиление в ВЧ области:
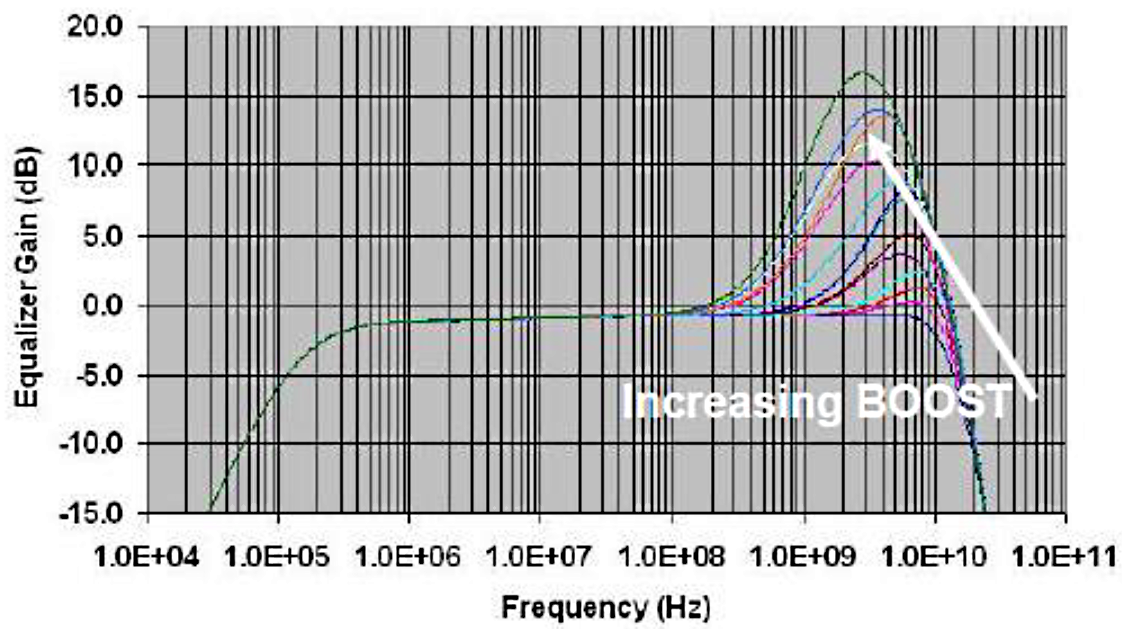
Обычно ATT и CTLE работают в противофазе — низкие значения ATT сопровождаются высокими значениями CTLE. То есть приемник сначала масштабирует входной сигнал до приемлемого уровня, а затем накачивает ВЧ составляющую, которая претерпевает наибольшее ослабление в процессе следования по каналу.
Если приходится настраивать коэффициенты руками, то нужно иметь в виду, что слабая аттенюация (и как следствие – чрезмерно открытый «глаз») может привести к перенасыщению слайсера в приёмном тракте. А слишком большое значение BOOST – приводит и к усилению ВЧ шумов, обусловленных, например, перекрестными помехами. В общем — не нужно выкручивать эти ручки в максимум.
Опять-таки, забегая вперед, в случае 10-метрового кабеля ATT калибруется на 0x0F — максимальное значение, которое означает отсутствие аттенюации. И CTLE в районе 0x09 — достаточно серьезное усиление ВЧ. То есть на этих дистанциях сигнал затухает так, что тут как раз ручки почти в максимум приходится выкручивать.
Тренировка PCIe Gen3
PCIe Gen3 принципиально отличается от Gen2 и Gen1 тем, что в процессе тренировки присутствует итеративная фаза, в ходе которой подстраиваются параметры приёмного и передающего трактов. Очень укрупненно процесс тренировки выглядит следующим образом:
- Все начинается с Gen1. На данном этапе никакого тюнинга нет, все стартуют с стандартными значениями и не меняют их в процессе. В частности, для приемника Gen1 это ATT=0x09, CTLE=0x05.
- DownStream порт сообщает Upstream порту начальные значения для подстройки передатчика (TX PRESETS) для Gen3 и задает стартовые значения для себя самого (обычно они совпадают).
- Upstream порт настраивает свой передатчик, и партнеры переходят в режим Gen3. Если качество соединения при этом не позволяет получить BER ниже чем 10-4 — то все, ничего не работает. То есть стартовые значения параметров зачастую бывают важны.
- Если link-up произошёл — Downstream порт начинает калибровать свой приёмник и советовать Upstream порту новые настройки передатчика до момента достижения BER
10-12. - После этого происходит та же процедура, но наоборот — советует Upstream, а DownStream калибруется. Ну и далее случается link-up.
Механизм такого информационного взаимодействия партнеров соединения называется Backchannel Tuning.
Тестирование и доводка при работе с медными кабелями
На момент первого включения мы, конечно, не проводили никаких тестов (а кто их проводит?). Мы сцепили два адаптера медным кабелем, и увидели замигавшую лампочку. Далее с помощью команды lspci мы проверяли, что удаленно подключенный PCIe-коммутатор виден в дереве PCIe системы, и параметры установленного соединения соответствуют ожидаемым, то есть x4/x8/x16 (в зависимости от конфигурации) на скорости 8 ГТ/с.
Далее мы начали более детально изучать качество соединения. Для полуметровых и трехметровых кабелей BER был нулевой. С 10-метровыми кабелями возникли сложности, и для их решения пришлось основательно поработать.
Link-up на 10 метрах у нас произошел сразу, но сопровождался громадной скоростью нарастания ошибок. Данные можно было передавать, но очень медленно. И сколько бы мы ни игрались с TX PRESETS, сколько бы ни тюнинговали приемник — ничего не помогало. Решили включить DFE. И… ничего не произошло.
Дальнейшие изыскания привели нас к тому, что DFE имеет два режима работы — т.н. EDFE (Edge DFE), целью которого является расширить «глаз» сигнала по оси времени, и тестовый режим CDFE (Central DFE), целью которого является увеличить раскрыв «глаза» по оси амплитуды.
EDFE нам не помог.
CDFE у PLX семейства Capella 1 включается таинственной росписью неизвестных регистров — очень похожей на ввод какой-то кодовой последовательности. Суть ее производителем не раскрывается. Но он нам помог весьма ощутимо — BER из 120k x 10-12 снизился до 1.5k x 10-12. Но это всё равно выше требуемого стандартом уровня, и мы продолжили биться головой об стену, перебирая разные параметры.
Мы играли большим количеством разных параметров, например, чувствительностью приёмника, временем оценки передатчика, количеством итераций — не помогало ничего. Надо сказать, что аппаратные средства коммутатора PLX вместе с специализированным ПО позволяют получить изображение глазковой диаграммы для каждой линии. Но для нас эта функция оказалась бесполезной, так как точка захвата данных, используемых при построении глазковой диаграммы, находится до блока DFE — то есть, мы не видим, что делает DFE с сигналом. А до DFE у нас не просто закрытый «глаз», а буквально 0 в линии (хотя link-up всё-таки получается).
В итоге у нас наступила деморализация. Мы поняли, что авианосец остановить не получится, и решили поискать пуговицу — занялись другой проблемой, которую до этого временно отложили. Проблема заключалась в том, что в общем-то link-up иногда происходил не на всех линиях. Это говорило о том, что присутствовали какие-то проблемы при начальном соединении на скорости Gen1 — так как именно на этом этапе выбраковываются линии.
Мы включили (опять же тестовый) режим калибровки Gen1 (в стандартной работе он не предусмотрен). Gen1 перестал работать совсем (видимо никак не мог выйти на приемлемый уровень BER)— но зато мы увидели, на каких параметрах приёмник пытается сделать link-up, куда он стремится, и внезапно поняли, что они находятся в другой вселенной по отношению к стандартным. Интереса ради мы взяли и перебили стандартные 0x09/0x05 на 0x09/0x0F (выключили аттенюатор для Gen1).
И получили не просто стабильный link-up Gen1, но и гораздо более приятные значения BER для Gen3 — 0.3 x 10-12, что уже укладывается в рамки стандарта. Каким образом приемный тракт Gen1 связан с Gen3 — производитель не говорит. Но так вот оно работает.
Работа с оптическими кабелями
С оптическими кабелями пришлось отдельно повозиться из-за особенностей PCIe, но в сравнении с работой по «пробиванию» 10-метровых медных кабелей это было проще.
Если коротко обозначать ситуацию — с оптикой всё иначе, чем для меди.
В чём отличия от меди
Receiver Detect
После начала работы передатчики PCIe начинают проверять линию на предмет наличия нагрузки. Делают они это, анализируя сигнал, отраженный от противоположного конца линии. Если линия не терминирована приёмником — передатчик это распознаёт и выбраковывает эту линию.
Проблема с оптическими приёмниками заключается в том, что часто их терминация не соответствует спецификации PCIe, они могут быть терминированы на другой импеданс или вообще не быть терминированы на землю. Увидев такое, передатчик может решить, что приёмника у него нет — и не начать процедуру установления соединения. Для корректной работы с оптикой рекомендуется замаскировать сигналы блока Receiver Detect. Иными словами, принудительно заставить передатчик «видеть» приёмник.
Состояние Electrical Idle (далее — IDLE)
Периоды простоя в линии с отсутствием модуляции, вызванные, например, переходом в состояние низкого потребления, могут привести к перенасыщению PIN диода и вызвать проблемы при выходе из этого состояния. Приёмник может ошибочно принять шум, вызванный переходным состоянием оптического приемника, за выход из состояния IDLE и настроиться на ошибочную частоту. Это приведет к выбраковке данной линии при процедуре установления соединения в дальнейшем.
На картинке ниже показано, что получает приёмник PCIe, когда в линии с оптикой случается IDLE:
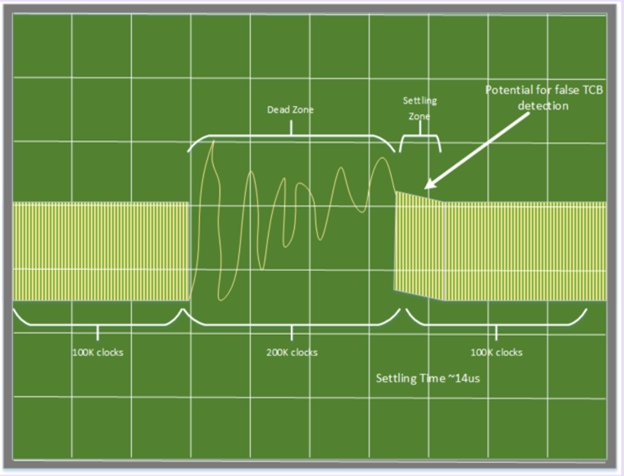
Там, где «Dead Zone» — должен быть постоянный уровень сигнала. А величина «Settling time» может иметь разное значение на разных линиях.
Режим Inferred IDLE
При использовании режима Inferred IDLE приёмник анализирует контекст передаваемых данных и не полагается на уровни сигнала при определении входа в состояние IDLE. Использование данного режима предпочтительно при использовании оптического кабеля, т.к. без него:
- переходные процессы в оптическом приёмнике могут инициировать ошибочный вход в состояние IDLE и последующие стадии автомата состояний LTSSM.
- переход в состояние IDLE одним партнером, может быть не распознан вторым партнером.
В коммутаторах PLX – это режим по умолчанию.
Downtrain Disable
В процессе установления соединения приёмник пытается поймать соединение на самой старшей или самой младшей линии. Как только он это сделает, у остальных линий остаётся ограниченное время на завершение тренировки. В виду описанных выше причин, настройка разных линий может занимать сильно разное время, поэтому после установления соединения по крайней линии остальные могут просто не успеть и будут выбракованы. Рекомендуется запретить приёмнику устанавливать соединение на ширине канала ниже заданной, чтобы он до конца пытался настроить все линии порта.
Тюнинг
Оптические устройства нелинейны, поэтому полагаться на механизм Backchannel Tuning нельзя, так как он рассчитывает на линейное ослабление сигнала при расчете коэффициентов калибровки приёмников и передатчиков. В ряде случаев его лучше отключать, а параметры приёмников и передатчиков калибровать руками.
В общем, существует достаточно много параметров, которыми можно управлять, чтобы заставить оптику работать. Чтобы иметь к ним доступ «на лету», мы поставили на адаптер микросхему CPLD. Начали мы с того, что задействовали сразу все параметры, рекомендованные производителем коммутатора, — и ничего не случилось. Потом мы обнаружили, что один параметр, а именно отключение блока Receiver Detect, мы забыли.
Включили его, и оптика ожила.
Потом всё параметры, кроме Receiver Detect, мы вернули в состояние по умолчанию. Оптика продолжила жить.
Маскирование Receiver Detect никоим образом не мешает работе и по пассивному медному кабелю. Таким образом мы получили работоспособную на обоих типах соединений конфигурацию.
Надо сказать, что в канале иногда появляются ошибки, но частота их возникновения находится в рамках стандарта. А так как тюнингом применительно к оптике мы по сути пока ещё не занимались, то есть стойкое убеждение, что эти ошибки можно победить.
Исследователи данного вопроса сильно и много пугают разработчиков тем, что из-за больших производственных разбросов между кабелями достаточно проблематично собрать соединение x8 из двух кабелей x4, а тем паче x16 — из 4 кабелей x4. Поэтому, задавшись целью минимизировать эти риски, мы выровняли все трассы на плате в 100 пс. Я не знаю, возымело ли это какое-то значение, но проблем со агрегированием четырех линков х4 в x16 на 100-метровой оптике у нас не возникло.
Общие проблемы
В используемом нами кабельном соединении (и оптическом, и медном) есть следующие подводные камни:
- в линии не передается опорный синхросигнал (далее – клок);
- в линии не передается I2C;
- в линии не передается PERST#, PRSNT# и прочий sideband.
Клок
В общем случае PCIe клок необходим для нормальной работоспособности канала. Но используемые нами коммутаторы — SRIS-совместимые. SRIS — Separate Reference Independent Spread. Простыми словами, они не просто могут работать на разных клоках, но эти клоки могут быть SSC.
При этом нормальная работа возможна только при соединении двух SRIS устройств. Работоспособность при прямом безклоковом подключении хост-процессора к чему бы то ни было не гарантируется. Хотя мы наблюдали нормальную работу при безклоковом кабельном соединении x86 процессора с PLX устройством при условии, что используемый на хост-процессоре клок не использует SSC. Это называется SRNS — Separate Reference No Spread.
Наш адаптер имеет собственную подсистему клоков, которая позволяет как тактировать все от системного PCIe клока, так и работать на своём, — который в свою очередь может быть как SSC, так и не SSC.
Работа на системном клоке в результате тестирования нам не понравилась, хотя мы лелеяли надежду работать только на нем, а все остальную схематику, относящуюся к клокам — убрать.
Работа на собственном клоке как nonSSC так и SSC — стабильна и надёжна при использовании пассивных медных кабелей до 4 метров, а так же с оптическим кабелем. Для 10-метрового медного кабеля нормальная работа канала в данный момент достигается только при nonSSC клоке.
I2C
Это опциональный интерфейс, и мы в общем ничего не теряем, не передавая его. Просто нужно было отметить, что мы его не передаём.
Прочий sideband
Отсутствие оного влечёт, например, такие проблемы:
- невозможность синхронного сброса всего PCIe дерева, как это происходит, когда все PCIe устройства в одной коробочке;
- проблемы с внезапным пропаданием и добавлением устройств на шине PCIe;
и прочее подобное, что можно обозвать общим словом — синхронизация.
Данные проблемы требуют более глобального подхода и будут решатся на этапе системной интеграции. В данный момент мы обходимся тем, что включаем хост-систему после таргета, дабы хост-система могла нормально осуществить энумерацию PCIe устройств в стандартном процессе своей загрузки.
Также эта проблема неактуальна при использовании NTB.
Варианты и аналоги
Собственно, как уже упоминал Алексей в прошлой статье, адаптер у нас будет в двух вариантах. Второй вариант не будет оснащён коммутатором PCIe, а будет иметь простой редрайвер. Это более дешёвый вариант, подходящий для тех случаев, когда не нужна бифуркация портов.
Ещё надо сказать, что в используемом нами относительно недорогом чипе PCIe-коммутатора нет контроллера DMA. Поэтому если соединить между собой два этих адаптера, скорость будет невысокой и сильно зависеть от работы процессора – от того, как и какими блоками данных он оперирует. При наличии хотя бы за одним адаптером DMA-контроллера — реальная скорость обычно составляет порядка 50-60% от физически доступного предела – то есть порядка 8-9 ГБ/с в одну сторону. Хотя, конечно, отдельно взятая операция по пересылке данных может случиться и на скорости 16 ГБ/с. PR-щики любят писать 32 ГБ/с — это физический предел в ОБЕ стороны. Но информационное взаимодействие на шине PCIe обычно двустороннее – на каждую транзакцию таргет отсылает Completion Response. Так что работа с производительностью 32 ГБ/с представляется мне весьма сомнительной.
Естественно, такой выбор чипа вполне рационален: в планируемых сценариях использования хотя бы за одним адаптером обязательно будет контроллер DMA. Поэтому переплачивать вдвое за более продвинутый чип PCIe-коммутатора со встроенной поддержкой DMA в нашем случае смысла нет.
Продавать этот адаптер как отдельный продукт не планируем — не наша сфера деятельности, будем ставить только в комплексные решения из собственного оборудования. Если нужен подобный адаптер с DMA-контроллером, то на рынке появились такие решения. Можно посмотреть на Dolphin PXH830 (HBA) или PHX832 (Host/Target), хотя у этих адаптеров немного другие параметры.
У модели 830 заявлена возможность разбиения портов на 2 x8 или 1 x16, нашего режима 4 x4 нет. Модель 832 может работать в режиме 4 x4, но только с пассивными кабелями до 5 м. Для обеих моделей заявлена поддержка оптических кабелей длиной до 100 м.
Что дальше?
В итоге адаптер заработал с медными кабелями до 10 метров и с оптическими до 100 метров, BER в обоих случаях находится в допустимых стандартом границах. Планируем выпустить вторую ревизию с уменьшенным количеством слоёв, улучшить layout, потестировать и поиграться с тонкой настройкой параметров под оптику для дополнительной шлифовки результатов.
Спасибо за внимание.
Комментарии (20)

Kopart
07.11.2016 11:19А какие задачи решает на плате LATTICE?
И чем-то обоснован выбор именно LATTICE?
asmolenskiy
07.11.2016 11:31В данный момент — никаких.
На этапе разработки — мы предполагали (и до сих про предполагаем), что в ряде применений будет необходимость изменять стартовую конфигурацию коммутатора либо изменять какие-то его параметры на лету. Конечно, большинство из этих потребностей может реализовать хост система инбэндно — но для этого потребуется специальный драйвер для этого адаптера.
В частности мы предполагали, что нам нужно будет определять тип внешнего кабеля и модифицировать под него параметры приемников/передатчиков.
Для этого мы внедрили CPLD и небольшой DIP-переключатель для задания режимов.
В данный момент CPLD ничего не делает.
Почему именно Lattice?
Просто этот производитель мне нравится. У него очень вкусные и недорогие CPLD, удобная система разработки и хорошая информационная поддержка.


R6MF49T2
07.11.2016 15:28«Работа на системном клоке в результате тестирования нам не понравилась» — чем именно не понравилось?
asmolenskiy
07.11.2016 15:33Системный клок в используемых нами рабочих станциях — не очень хорош в плане джитттера.
Error Rate при работе от системного клока при тех же настройках коммутатора — значительно выше.
Ну и в целом не хочется зависеть от материнской платы на таких рисковых длинах. Мы же никак не можем на нее повлиять.
В итоге канал хост-адаптер работает на системном клоке, как любая стандартная PCIe карта расширения, а внешние интерфейсы адаптера — на собственном.
Экономия на паре корпусов клоковой подсистемы в данном случае не покрывает возможные риски.
BiosUefi
07.11.2016 16:37работа с производительностью 32 ГБ/с представляется мне весьма сомнительной.
A если на шине висят 100-180 PCIe устройств, которые «отгрызают» 2-3.5 ГБ на I/O?asmolenskiy
07.11.2016 16:41+1Простите, я не понял Ваш вопрос.
В цитируемой Вами фразе я всего лишь имел в виду, что некорректно просто брать физический предел интерфейса, умножать его на 2 и обещать такой troughput. А именно это обычно и делается производителями в буклетах. Те же упомянутые мной Dolphin так и пишут — up to 32GB/s.
BiosUefi
07.11.2016 16:59некорректно просто брать физический предел
даже если мы тупо гоним из одного PCIe устройства в другое(или из списка одних в другие/соседние),
при максимальной памяти и процессорах?
умножать его на 2 и обещать такой troughput
а умножать на 1.2 или 1.5 уже чеснее, или тоже попахивает маркетингом?
ПС не будте излишне строги к моим вопросамasmolenskiy
07.11.2016 17:09Смотрите — если Ваш хост — это FPGA с чем-то рукописным и один абонент. То в принципе Вы можете приблизиться к заветным 16ГБ/с в одну сторону. И даже к суммарному 32 ГБ/с при независимых потоках в обе стороны. Для этого нужно слать максимально большие пакеты. То есть теоретически физика интерфейса и достаточно низкая latency коммутатора (150нс) — позволяют это сделать.
Если перейти к более реальным вещам. То мы видели производительность порядка 60% от физически возможного при соединении x86 системы с PLX PEX9797 — этот коммутатор имеет внутри DMA и виртуальный NIC. Собственно в данном эксперименте мы работали с PEX9797 как обычным сетевым адаптером и проверяли скорость iperf'ом. На сколько этот показатель можно увеличить — гадать не берусь.
Одновременная работа большого количества устройств на одном root комплексе — это предмет исследований. Но на мой взгляд узким горлом тут будет не коммутатор.
asmolenskiy
07.11.2016 17:26даже если мы тупо гоним из одного PCIe устройства в другое
И еще нужно сказать следующее. Указанный Вами сценарий в реальной жизни — это достаточно редкое явление. Обычно PCIe устройства не имеют собственной памяти, и гнать в него ничего нельзя. Как правило работа с PCIe устройством заключается в том, что Вы сообщаете ему где в Вашей системной памяти находится его (PCIe устройства) буфер и далее это PCIe устройство работает с Вашей системной памятью посредством механизма DMA.
BiosUefi
07.11.2016 17:46Указанный Вами сценарий в реальной жизни — это достаточно редкое явление
однозначно,
но (как выше я писал) и наличие 100-180 PCIe устройств ОДНОВРЕМЕННО на одном root комплексе это тоже редко, а именно это(дерево) и нужно было инициализировать.
Вот мне и было интересно, а нах… зачем такого монстра лепить? Не ради ли того, чтобы выжать до последней капли маркетинговую производительность?
asmolenskiy
07.11.2016 17:53Я начинаю думать, что сценарий 100-180 PCIe устройств — это что-то из обсуждения в наших предыдущих публикациях?
Ежели так, то в наших сценариях не предполагается одновременный доступ ко всем устройствам в отдельно взятый момент времени. Нам важно просто иметь к ним доступ в рамках одного PCIe дерева. Но это не значит что мы будем делить полосу пропускания между ними.

urock
09.11.2016 19:18PCIe Slave устройство отсылает PCIe Completion Response не на каждую полученную транзакцию, а только на Non-Posted transactions (транзакции чтения). Для Posted транзакции (записи) на уровне TLP траффик идет в одну сторону.
Эти преусловутые 16 ГБ в одну- конечно, даже теоретически недостижимая скорость даже для posted transactions. В первую очередь это связано с тем, что пакет помимо полезных данных для передачи (payload, размером до 256 байт) имеет еще служебный заголовок около 20 байт. Плюс надо учесть DLLP транзакции.asmolenskiy
09.11.2016 19:31Да, Вы правы.
За одним исключением.
Размер Payload определяется содержимым конфигурационных регистров и может быть намного больше чем 256 байт. В частности в используемом нами коммутаторе — это 2048.
Ну и немного конкретизирую Ваш пост. Posted транзакции — это не все транзакции записи в целом, а только транзакции Memory Write и сообщения.urock
09.11.2016 19:39Не я в курсе, что MAX_PAYLOAD_SIZE может быть до 4096 байт, но на практике никогда не видел, чтобы было больше 256. По спецификации ведь этот параметр должен быть одинаковым для всех устройств в дереве и равен минимальному из поддерживаемых. Вы используете передачи с payload 2048 получается между окончеными устройствами, а не с хостом?
Тоже, кстати, не совсем понятно зачем такой большой payload. Аргументы против
1) Сильно страдает latency. Ведь пакет надо сначала принять, а затем передать дальше. Или у вас cut through pcie switch?
2) Пропускная способность сильно не увеличиться. Ведь уже с payload 256 байт она около 90% от этих 16 ГБ.asmolenskiy
09.11.2016 19:44Cut-trough.
В целом согласен.
Только дополню — при Payload ниже 128 байт на толстых свичах и ниже 64 байт в среднем по больнице — также возникает Deallocation. Это когда перф зависит от того из какого порта в какой кочуют данные и при определенных комбинациях ощутимо дропается.
lelik363
Помимо инструментов, которые предоставляет PLX, использовали ли какое-либо еще оборудование для оценки качества сигнала?
asmolenskiy
Нет.