
На старте проекта мы хотели как можно быстрее показать готовый продукт пользователям, поэтому старались упростить приложение всеми способами. Одним из вариантов был отказ от разработки собственного парсера интернет-магазинов и внедрение готового решения.
В целях сокращения объема повествования, упущу сравнение популярных приложений по извлечению данных с сайтов (если хотите увидеть это сравнение, оставьте свой голос в опросе в конце статьи). Достаточно будет сказать, что наиболее подходящим для нашей задачи оказался diffbot — крайне недешёвый сервис, популярный среди крупных компаний и стартапов с приличным финансированием. Его используют многие приложения для создания закладок, ведь качественный парсинг — это трудно.
Во-первых, решение нам было не по карману, а во-вторых, diffbot плохо работал с российскими интернет-магазинами. Пришлось придумывать свою технологию парсинга, которая должна уметь:
- Максимально автоматически определять основные параметры товара;
- Работать с любой валютой и языком;
- Учитывать географическое положение пользователей и особенности работы магазинов с этим регионом (язык, валюта и страна);
- Определять магазины с дискриминационным ценообразованием (версия операционной системы и город в пределах страны).
Нам удалось реализовать все описанные выше принципы. Система обучается на новых данных и умнеет на глазах. Чем больше запросов — тем точнее она становится. Наше желание сделать выборку более разнообразной и стало одной из причин предоставления доступа к Product API сторонним разработчикам, т.к. темпы появления новых данных со стороны пользователей замедлились — 90% покупают в одних и тех же интернет-магазинах.
Итак, встречайте Product API от Fetchee. С его помощью вы сможете, указав любой URL товара в интернет-магазине, получить основные данные о вещи, включая название, изображение, цену и валюту. В случае с нашим API, вам не придется настраивать парсер под каждый сайт, система самостоятельно анализирует страницу и определяет нужные данные.
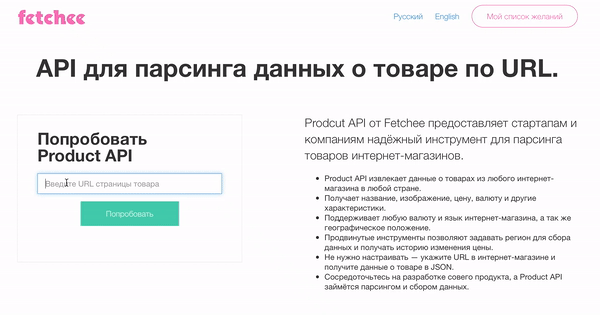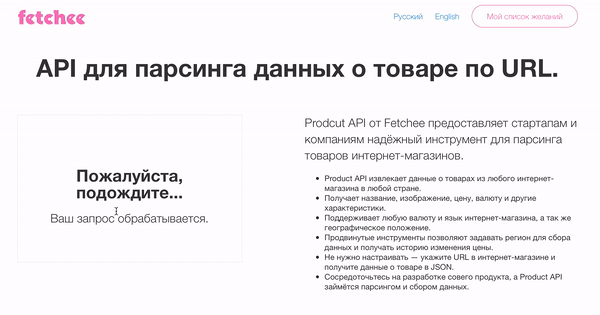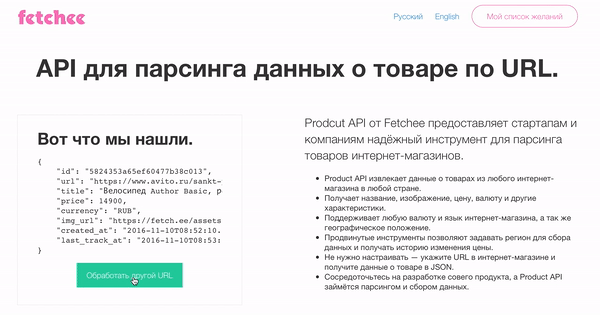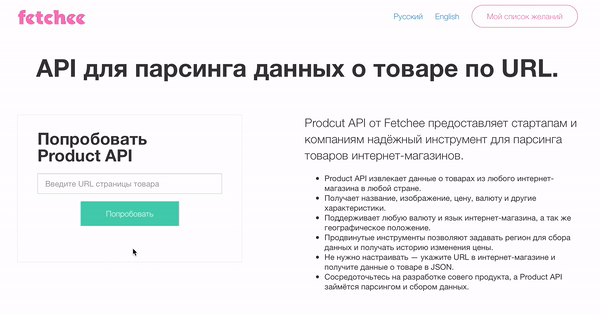
Например, вот результаты парсинга велосипеда с Avito.
{
"id":"58234b6cfd920b507bfd6b1f",
"url":"https://www.avito.ru/sankt-peterburg/velosipedy/velosiped_author_basic_rama_19_i_21_835103333",
"title":"Велосипед Author Basic, рама 19\" и 21\"",
"price":14900,
"currency":"RUB",
"img_url":"https://fetch.ee/assets/item-images/5823/4b78475d39467b4b25eb.jpg",
"created_at":"2016-11-09T16:14:36.542Z",
"last_track_at":"2016-11-09T16:14:48.061Z"
}
Модной сумки с Wildberries.
{
"id":"5824212c65ef60477b38b890",
"url":"https://www.wildberries.ru/catalog/3095060/detail.aspx?targetUrl=GP",
"title":"Сумка, GUESS",
"price":13560,
"currency":"RUB",
"img_url":"https://fetch.ee/assets/item-images/5824/2144475d39467b4b26de.jpg",
"created_at":"2016-11-10T07:26:36.368Z",
"last_track_at":"2016-11-10T07:27:00.544Z"
}
Или внедорожника с автомобильного сайта.
{
"id":"5824219b65ef60477b38b8be",
"url":"https://auto.ru/cars/new/sale/bmw/x6_m/1044423007-94d1a/",
"title":"Продажа BMW X6 M II (F86) в Москве",
"price":8099000,
"currency":"RUB",
"img_url":"https://fetch.ee/assets/item-images/5824/21ad475d39467b4b26df.jpg",
"created_at":"2016-11-10T07:28:27.038Z",
"last_track_at":"2016-11-10T07:28:45.516Z"
}
На любой странице, где есть цена, изображение и название товара — Product API найдёт эти данные и вернёт их вам в JSON для дальнейшей обработки.
Попробовать API можно прямо на странице Beta-программы. Если понравится результат тест-драйва, регистрируйтесь как разработчик — чем больше будет заявок, тем раньше мы предоставим полный доступ к API.
Нам очень интересно увидеть как ваши идеи воплощаются в жизнь с помощью Product API.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Комментарии (41)

nerumb
11.11.2016 11:27Product API извлекает данные о товарах из любого интернет-магазина в любой стране.
Получает название, изображение, цену, валюту и другие характеристики.
Поддерживает любую валюту и язык интернет-магазина, а так же географическое положение.
Попробовал несколько ссылок указать, тот же ссылка. В начале несколько минут было «Ваш запрос обрабатывается..», а потом что превышено время ожидания.nerumb
11.11.2016 11:28Со второй попытки все же нашлось, но без цены, описания и т.п.:
{ "id": "5825801c65ef60477b393545", "url": "http://www.tehnosila.ru/catalog/tovary_dlja_sporta/velosipedy_i_aksessuary/velosipedy/-/284900", "created_at": "2016-11-11T08:23:56.599Z", "last_track_at": "2016-11-11T08:28:20.869Z", "unprocessed": true }
silenzushka
11.11.2016 11:35Хаброэффект, не иначе. Всё-таки API в бете, может и призадуматься. Попробуйте ещё раз, цена Техносиле теперь в норме.
nerumb
11.11.2016 11:46А с сайтами, которые динамически собирают страницу (spa и т.п.), каким образом вы собираете информацию (если не секрет)? На своей стороне полностью рендерите html и потом ее парсите?

medvoodoo
11.11.2016 12:13Я думаю, что таких сайтов-продавцов меньшинство, т.к. большинство продающих сайтов заинтересованы, чтобы в поисковики попадало как можно больше страниц товаров, и spa для магазина — очень неудачное решение
silenzushka
11.11.2016 12:52На западе их очень много. Значение SEO сильно преувеличено для магазинов. Т.е. запросы на конкретную модель, которая через 4-5 месяцев уже уйдёт из продажи, скорее всего будут перехвачены агрегаторами типа Яндекс.Маркет. Магазины сосредотачиваются на привлечении трафика на посадочные страницы. Ну а сделал пререндер и закешировать посадочную на SPA вообще не проблема.
silenzushka
11.11.2016 12:40По необходимости полностью рендрим страницу вместе с JS. По понятным причинам время ожидания обработки для SPA сайтов немного выше.
Jawwal
11.11.2016 12:53Есть интернет магазины, где важна авторизация, что бы видеть цену со скидкой (присвоенной пользователю). У вас есть/в планах решение?
silenzushka
11.11.2016 12:57В рамках Fetchee для пользователей такое решение есть. Оно не во всех случаях работает, правда. Как реализовать его для API пока не знаю, если только в запросе будет указываться логин/пароль или активная авторизационная кука.
netserfer
11.11.2016 13:00странный парсинг.
url:
http://dietjust.ru/products/23748692
Вот что мы нашли.
{ "id": "58258e53b25795f760078d1b", "url": "http://dietjust.ru/products/23748692", "title": "370 руб. нет в наличии", "price": 370, "currency": "RUB", "img_url": "http://i.siteapi.org/G0mzV92ignFZHjq4iNhLNTfk0DE=/113x0:602x377/fit-in/156x120/filters:fill(transparent):format(png)/ea331f79b074863.ru.s.siteapi.org/img/e3d2f43973a2f83ec36641997f935d5f1ae972bc.jpg", "created_at": "2016-11-11T09:24:35.586Z", "last_track_at": "2016-11-11T09:24:47.417Z" }
По какому принципу в данном случае он выбирал title для меня осталось загадкой.silenzushka
11.11.2016 13:01Спасибо, что написали. Новые товары в этого сайта будут определяться верно. Подкрутили алгоритм.
meft
11.11.2016 13:25url:
https://www.computeruniverse.ru/products/90659981/palit-geforce-gtx1060-dual.asp
Как я понял, с двойной валютой парсер не справился:
{ "id": "58259b6740b895da69e0a2d6", "url": "https://www.computeruniverse.ru/products/90659981/palit-geforce-gtx1060-dual.asp", "title": "Palit GeForce GTX1060 Dual 6.0 GB High End видеокарта", "price": 234.37, "currency": "RUB", "img_url": "https://fetch.ee/assets/item-images/5825/9b9322ae47d46976383b.jpg", "created_at": "2016-11-11T10:20:23.492Z", "last_track_at": "2016-11-11T10:21:07.712Z" }silenzushka
11.11.2016 13:53Спасибо за информацию. Сайт не простой, но система ошибается, а потом учится.
Mak_Di
11.11.2016 17:30Имеется ли в планах апи колл, которому можно передать ошибку парсинга, например, url, который не распарсил.
Чтобы инфу не через хабр сообщать, а апишкой?silenzushka
11.11.2016 17:39Я надеюсь, что к моменту запуска полноценного API эта функция не понадобится, ведь это наша забота проверять качество парсинга. Но такой вызов будет, в пользовательском приложении функция жалобы на товар есть.
Mak_Di
11.11.2016 17:46silenzushka
11.11.2016 17:50У Стима блокировка по возрасту. Можно обойти, но проще с ними по API интегрироваться, если кому-то понадобится следить за ценами на игры.
Можете описать ситуацию, когда понадобится получить данные и следить за ценой на бесплатный товар?

mihmig
11.11.2016 18:08Я так понял — данный сервис нужен для автоматического отслеживания цены/наличия на отдельный товар.
Извлечение списка товаров со страницы каталоге не планируется?silenzushka
11.11.2016 18:21Совершенно верно, мы используем технологию для слежения за ценами. Но кто-то может встроить Product API в свой сервис закладок, например. Или любое другое приложение, где пользователи хотят видеть базовую информацию о товаре. Например, модуль предпросмотра ссылок на интернет магазины для форумов или блогов.
Если коллеги-разработчики скажут, что нужна функция по URL списка товаров пройтись и обработать все ссылки на вещи, да ещё принять в учёт пагинацию — сделаем. Главное, чтоб были кейсы, которые упростят жизнь и окажутся востребованными.

peacemakerv
14.11.2016 11:04Ваше API хотелось бы видеть для использования в приложениях, для создания мобильных клиентов сайтов, не имеющих API.
Т.е. не только для одного выбранного товара, а для получения каталога (всех данных товара со страницы) с сайта.silenzushka
14.11.2016 11:30Спасибо за идею! В теории можно так использовать API, но где сейчас движок магазина, который не поддерживает мобильные шаблоны? У нас в приоритете сбор данных о товаре, а не краулинг. Т.е. в принципе, уже сейчас можно использовать Product API совместно с Вашим краулером.
peacemakerv
14.11.2016 12:09Пожалуйста, жду доп. скидку, когда будет API готово :)
Дело не в краулинге (я верно понял — хождение по страницам сайта ?) — а в получении данных о всех товарах с открытой страницы. Хотя по одному товару — согласен, что и сейчас будет работать.silenzushka
14.11.2016 13:36Записал ;-) Выше в комментариях уже просили научить API обрабатывать страницы с со списком товаров. Начали уже тренировать систему.
rankov
14.11.2016 11:33Цена не пришла, описание тоже
http://www.superdrug.com/Bourjois/Bourjois-Healthy-Mix-Foundation-Light-Vanilla-51/p/626461
{
«id»: «5828bfa540b895da69e1e038»,
«url»: «http://www.superdrug.com/Bourjois/Bourjois-Healthy-Mix-Foundation-Light-Vanilla-51/p/626461»,
«title»: «Bourjois Healthy Mix Foundation Light Vanilla 51»,
«img_url»: «http://www.superdrug.com/medias/custom-content/microsites/starbuys/popup/2016/wk46/starbuys_wk46.jpg»,
«created_at»: «2016-11-13T19:31:49.615Z»,
«last_track_at»: «2016-11-13T19:31:59.686Z»,
«unprocessed»: true
}silenzushka
14.11.2016 11:33Спасибо за наводку. Обновили правила парсера, теперь корректно работает с сайтом.

alekciy
19.11.2016 23:38Это же хабр. Хочется немного и технических подробностей. На каком стеке работает, каких сил стоила разработка, какой размер команды. Потому как крутость решения можно оченить только по сумму всех этих показателей.
silenzushka
20.11.2016 00:05В следующей заметке расскажу больше про команду (спасибо, что спросили ;-). И по технике будет чем поделиться, уже тестируем определение бренда производителя.
renardf0x
Цитата с https://fetch.ee/ru/developers/
По факту имеем
url: http://m.finn.no/car/used/ad.html?finnkode=15254566
Вот что мы нашли.
{
«id»: «58257ccb65ef60477b39338f»,
«url»: «http://m.finn.no/car/used/ad.html?finnkode=15254566»,
«title»: «Mercedes-Benz C-Klasse»,
«img_url»: «https://images.finncdn.no/dynamic/1280w/6/152/545/66_287309295.jpg»,
«created_at»: «2016-11-11T08:09:47.474Z»,
«last_track_at»: «2016-11-11T08:09:57.440Z»,
«unprocessed»: true
}
И ладно, что отсутствует цена, валюта и другие характеристики. Смешнее всего id взятый с потолка.
ragimovich
ID не с потолка, а, судя по его виду, из MongoDB в которой хранятся результаты парсинга. Посмотрите на примеры в статье, там тоже нет "локальных" ID. Я вообще сомневаюсь в возможности "вытащить" "локальный" ID с помощью "универсального" парсера.
Да и по поводу цены сложно товарищей винить — "89 900,-" это очень необычный формат обозначения валюты.
silenzushka
Про ID из MongoDB Вы правы. В формате, кстати, нет проблем (хотя если глянуть на HTML, дизайнерам можно руки оторвать). А вот валюта подвела для этой страницы.
silenzushka
Спасибо, что решили попробовать. ID в ответе — это идентификатор запроса, к товару он не имеет отношения. Система вернула unprocessed: true, что говорит о невозможности получит все данные. Валюту для этой страницы автоматически определить будет сложно, т.к. нет знака валюты у цены. Именно для таких диковинных сайтов и затеяли публичный API. Цену научимся обрабатывать и дам Вам знать.
renardf0x
На мой взгляд, было бы честнее предоставить список магазинов, где API работает, вместо утверждения о «любых».
Однако, если расчет был на то, что множесто людей ринутся проверять, действительно ли любых, то решение верное =)
Вопрос из любопытства — обучение распознаванию происходит в автоматическом, полуавтоматическом или ручном режиме?
silenzushka
У нас есть автомат по распознаванию паттернов. Он может давать сбои, поэтому ему нужно периодически подкидывать новы сайты. Чем их больше, тем он надёжней срабатывает. Процесс обучения простой: получили автоматический результат, проверили на корректность, если есть ошибка, добавили правило, прогнали тесты не рушит ли правило предыдущие верные срабатывания.
API на самом деле автоматически работает со всеми магазинами, которыми пользуется 95% покупателей в интернете. Но верстальщики самые находчивые люди, иногда пользователи добавляют такие сайты, где в коде идёт борьба бессмысленности с глупостью. В этом случае мы вытираем скупую слезу и делаем ручную настройку. Интересно, что товары из этого магазина интересуют, как правило, только одного пользователя.
Видимо, для полной автоматизации, нужно будет реализовать систему машинного зрения и определения тематических блоков.
renardf0x
Грандиозная работа! Я в восхищении от методов.
Прошу простить любопытство (это неуемная тяга к тестированию всего и вся).
На примере, указанном в одном из комментариев ниже
Насколько я понимаю, парсер не воспринял это как ошибку и, следовательно, не будет самообучаться на данном примере, верно?
silenzushka
Воспринял и обучился. Вот этот URL уже правильный http://dietjust.ru/products/14061117. API закешировало ошибочный ответ. Новые запросы отрабатывают правильно.
P.S. Я ценю Ваше любопытство.
renardf0x
Ниже сказано
Отсюда я сделал выводы, что автоматический режим не сработал, что было бы вполне логично, т.к. парсер извлек эти (некорректные) данные как title, что подразумевает, что с его точки зрения это title и есть. Т.е. причин для парсера искать другой title (срабатывания некого триггера) я не вижу.
Или он подвергает сомнению все собранные данные?
silenzushka
Возможно, я не правильно выразился где-то по тексту. Парсер учится, а указывать на его ошибки — задача человека. Сейчас реализован метод кнута, когда мы не даём систему права на вторую ошибку, принудительно заставляя обрабатывать данные правильно. В идеале, конечно, реализовать полноценную систему машинного обучения, когда от человека будет требоваться только проверка результатов и команды: Верно / Не верно, иди ещё подумай.
renardf0x
Огромное спасибо за содержательные ответы! Весьма и весьма занимательная система. Очень интересно, во что она вырастет и какими возможностями обзаведется. Желаю успехов!