

Понимание естественного языка является AI полной задачей. Одним из аспектов такого понимания является понимание контекста. В данной статье я объясню, какие виды контекста выделяет наша психика, как она работает с одним из видов контекста, и как мы этот процесс воссоздаем в нашей технологии искусственного интеллекта.
The trophy doesn't fit into the brown suitcase because it's too [small/large].
What is too [small/large]?
Answers:The suitcase/the trophy.
The Winograd Schema Challenge
В предыдущей статье описан наш подход к разработке ИИ и то, что нами уже сделано на настоящий момент. Напомню, что мы создаем ИИ путем прямого копирования структур и процессов психики человека.
Два вида контекста
По комментариям к предыдущей статье мы увидели, что термин «контекст» применяется для описания очень разных ситуаций. Мы рассматриваем этот термин, разделяя его на два вида.
Первый вид контекста — когда речь идет о понимании, вытекающем из прозвучавших в этой фразе понятий. Это ситуации выбора одного из значений омонимов, подбор синонима, выбор одного из нюансов смысла и пр. Например: «Глаза слезились, когда она резала для салата лук» и «Современная стрельба из лука делится на несколько направлений». Человек «на лету» понимает, когда речь идет о луке-растении, а когда о луке — разновидности оружия.
Второй вид контекста — когда для понимания приходится выделять некоторую категорию, зачастую в самом тексте не представленную или особо не выделенную. Именно такая категория позволяет сформулировать некую «идею», обобщенно выражая то, о чем говорится.
Например, если вы в книге Льва Толстого встретите фразу «Он распечатал письмо…», то для правильного понимания текста вы привлекаете категорию «19 век», и делаете вывод, что речь идет не о принтере. Этот вид контекста подразумевает, что для понимания и интерпретации текста может производиться анализ не только всего текста, но и связанных с ним данных.
Решение задач, связанных с разными видами контекста, обслуживаются абсолютно разными процессами психики. Такое же разделение мы повторяем в нашей разработке ИИ. В решении задач первого типа используется метод, основанный на особенности хранения знаний. В решении задач второго типа реализуется более сложный алгоритм, основанный на опыте (в случае искусственного интеллекта речь идет об алгоритмах, компенсирующих отсутствие реального человеческого опыта у системы), и предполагающий больший объем вычислений.
Психика человека чаще всего вначале пытается применить первый метод, т.к. он требует гораздо меньше вычислительных ресурсов. Если же решение не выглядит адекватным, то тогда психика использует второй. Кроме того, чем выше интеллект, тем чаще используется второй метод и большее число возможных контекстов учитывается. Дети, в виду сложности и ресурсоемкости второго метода, а также взрослые, не привыкшие к умственному труду, предпочитают первый.
Мы опишем, как наша технология ИИ работает с первым видом контекста. Как мы работаем со вторым, более сложным, будет описано в следующей статье.
Длиннее та коса, у которой меньше связей
Для иллюстрации возьмем ситуацию диалога:
«Я тут иду по набережной и увидел косу. Интересно, какая коса самая длинная?»
Решение, построенное на нейронных сетях, в силу ограничений, накладываемых самим методом, вероятнее всего не сможет адекватно ответить. Даже если для поиска ответа в НС будет загружено очень много текстов, то, опираясь на вероятность, прозвучит цифра «5.6 метра».
Напомню, что нашу технологию ИИ мы разрабатываем, последовательно копируя психику и ее процессы. Семантическая сеть, которую мы используем для хранения знаний, отражает особенности хранения и обработки информации человеком. Поэтому в рамках нашего подхода задача решается достаточно просто.
В решении, соответствующем семилетнему возрасту, алгоритм обращается к семантической сети и находит вершину, которая расположена в узле, к которому относятся слова, услышанные ранее. В приведенном выше примере необходимо правильно выбрать один из омонимов: коса (прическа) и коса (полоса суши, соединенная с берегом) коса (инструмент). Для этого анализируется, о каком узле семантической сети шла речь ранее. Т.е. выполняется простейшая процедура расчета минимального расстояния до понятий, используемых в тексте ранее. В нашей сети расстояние это функция от количества связей (прямо пропорционально) и их вероятности (обратно пропорционально).
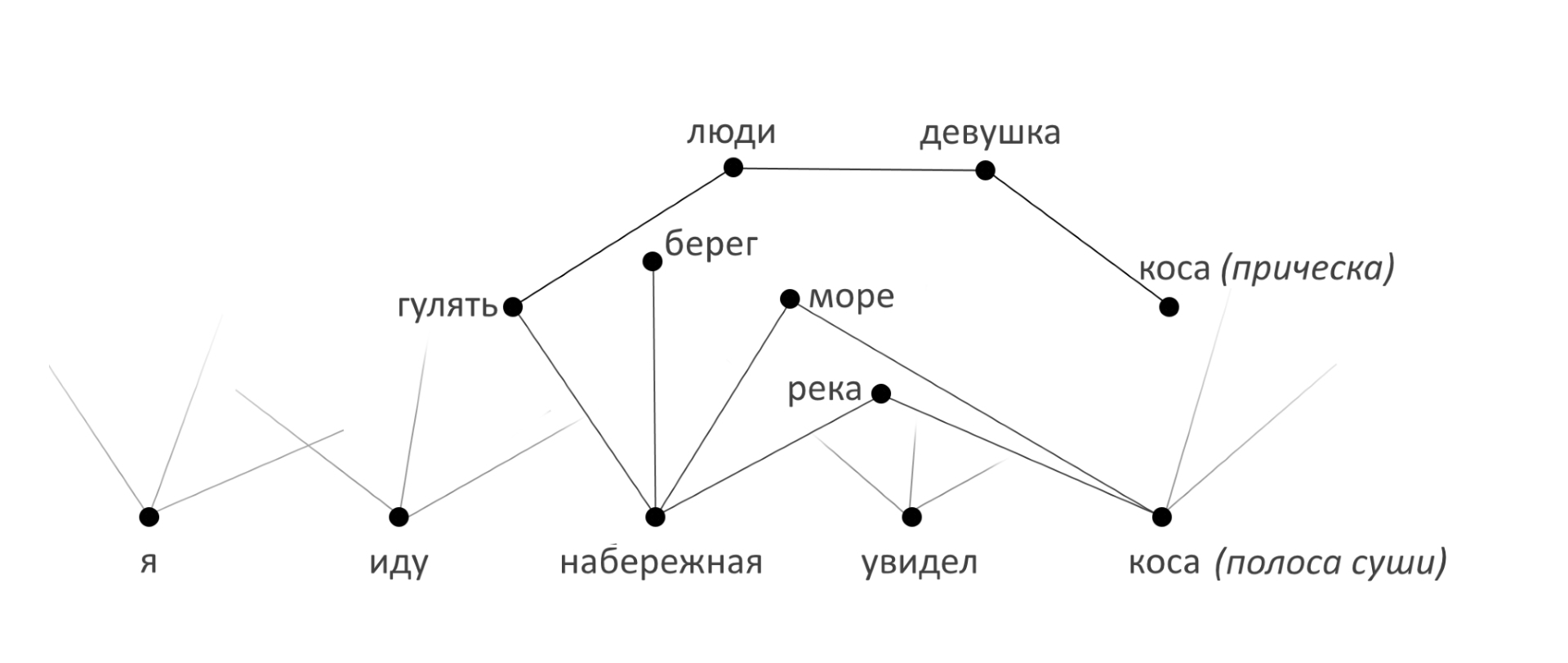
Расстояние от «коса (полоска суши)» до «набережной» будет на два порядка меньше, чем от «коса (прическа)» до любого из этих понятий. ИИ даст ответ «110 км».
Надо отметить, что эта задача решается и вторым способом, с выделением категории, например «река Волга, рядом с которой наш собеседник».
Грузчики видят чемоданы по другому
Рассмотрим пример из схемы Винограда, приведенный в начале статьи:
«The trophy doesn't fit into the brown suitcase because it's too small. What is too small?»
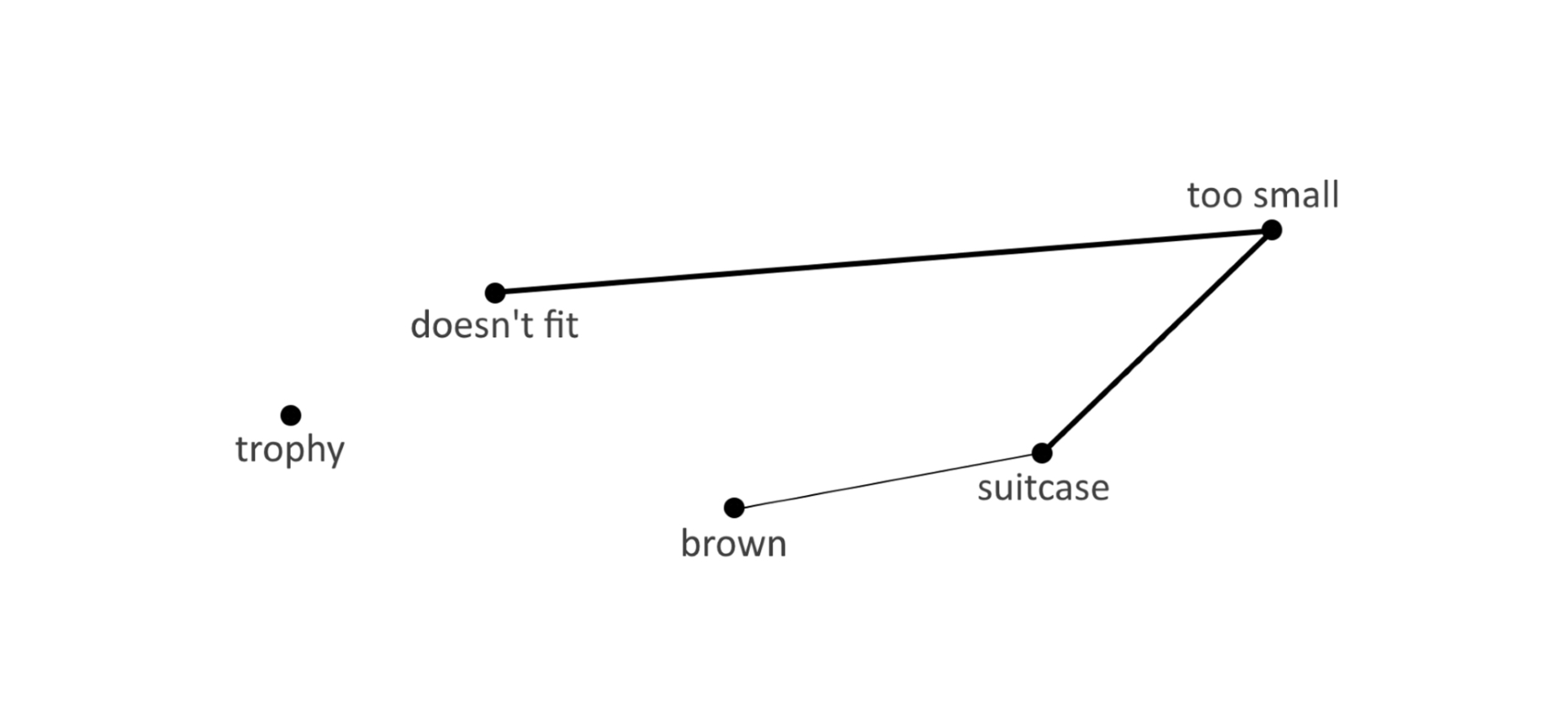
Связь между «doesn't fit» и сочетанием «too small»-«suitcase» на порядок вероятнее, чем между «doesn't fit» и «too small»-«trophy». ИИ даст ответ «suitcase».
Наличие высокой вероятности у такой связи, предполагающей на порядок меньшее расстояние в цепочке «doesn't fit»-«too small»-«suitcase», обусловлено опытом человека. Я, как и большинство, часто сталкивался с ситуацией, когда что-то не влезает в чемодан, так как он слишком мал. Отсюда и такая связь у меня. Такие же связи формируются в процессе обучения ИИ (подробнее о формировании различных видов связей в психике мы опишем в одной из следующих статей о нашей семантической сети).
«The trophy doesn't fit into the brown suitcase because it's too large. What is too large?»

Связь между «doesn't fit» и сочетанием «too big»-«trophy» гораздо вероятнее, чем между «doesn't fit» и «too big»-«suitcase». ИИ даст ответ «trophy».
Отмечу особенность — у грузчиков, которые часто сталкиваются с ситуацией, когда надо поместить слишком большой чемодан, психика использует второй метод понимания контекста. Т.к. для них связь «too big»-«suitcase» более актуальна. При этом для туристов работает другая система — наряду с нарастанием опыта ситуаций, когда сложно поместить куда-то чемодан, увеличивается невозможность конструкции «не получается что-то положить в чемодан, потому что чемодан слишком большой».
Для решения, соответствующего 12-летнему возрасту, формула несколько сложнее. Причем сформированный к этому возрасту подход реализуется и у взрослого человека — после 12 лет эта часть сети-алгоритмов не усложняется.
Фактически, легкость решения определяется спецификой нашего похода. Все ситуации, связанные с коммуникацией, вся лингвистика, сформированы с участием структур психики человека. Собственно, вся специфика в области языка и определяется этими структурами. Правда, есть и обратный процесс, когда язык определяет структуру. Налицо взаимообуславливание. Не удивительно, что с помощью этих структур (психических) возникающие задачи решаются самым легким образом. Гайку надо откручивать гаечным ключом, они созданы друг для друга. А не ложкой.
Отмечу, что кроме больших преимуществ, наш подход к разработке ИИ привносит и некоторые сложности. Вычислительная архитектура не соответствует физиологической базе, и мы периодически решаем технические задачи по качественному отображению процессов и структур психики в цифре. Также, из-за имеющихся допущений и корректив, какая-то часть ресурсов уходит на обеспечение тождественности семантической сети и алгоритмов ИИ структурам и алгоритмам реальной психики.
Следующая статья будет о втором виде контекста, и она будет, к сожалению, гораздо тяжеловесней. Нам не обойтись без глубокого погружения в психологические процессы при описании алгоритмов работы со вторым видом контекста в нашей технологии.
Комментарии (108)

KEN3
15.11.2016 21:27Каждый раз убеждаюсь в правильности китайской пословицы: хочешь познать мир — сначала познай себя.

InFortis
15.11.2016 21:47С моей точи зрения, подобный подход, как минимум, позволяет решить почти все стоящие перед создателями ИИ задачи.
napa3um
16.11.2016 12:10С точки зрения современной науки интроспекция не считается надёжным методом исследования психики и создания объективных знаний (но применима для психотерапевтических целей).
«Мы создаем ИИ путем прямого копирования структур и процессов психики человека» — вы создаёте ИИ алгоритмизацией моделей, которые вы считаете соответствующими реальной психической деятельности человека, ибо психика — это не то, что можно _напрямую_ обвести по трафарету. Я не настаиваю на том, что ваша модель нерабочая/бесполезная, но подобные формулировки точно лучше исключить, чтобы не обманывать прежде всего самих себя.InFortis
16.11.2016 12:59Интроспекция не слишком надежна, целиком согласен. Мы, чаще всего, пользуемся феноменологическим методом. В частности — феноменологической редукцией. Осваивали его несколько лет. Один из коллег, кандидат философских наук, как раз и специализируется на этом подходе.
napa3um
16.11.2016 13:10«Интроспекция не слишком надежна» — интроспекция абсолютно неработоспособна (в построении объективной модели). Это не какая-то погрешность, это принципиальная замена процесса наблюдения процессом конструирования. Вы как человек из «околопсихологической» тусовки должны, вроде как, это чётко понимать. Феноменологическая редукция интроспекцию не реанимирует, хоть 10 лет осваивайте.
InFortis
16.11.2016 17:25Не соглашусь. Для ряда задач точности интроспекции достаточно. Феноменология предлагает процедуру более точную, хотя и не лишенную минусов.
По вопросу точности выявления психических структур и процессов могу только поделиться своим взглядом. Я когда своему пациенту даю психоаналитическую интерпретацию, то он может сказать «Нет, вы абсолютно не правы, такого не может быть!». На свою чашу весов я могу положить только 20 лет психоаналитической практики. Я иногда ошибаюсь, а клиент оказывается прав. Но это менее 10% случаев. Как по мне, точность достаточная. Феноменология дает не меньшую.
InFortis
16.11.2016 13:07Психику нельзя провести по трафарету. Но выделить в ней процессы и структуры — можно. Насколько качественно это сделано становится очевидным при реализации этой модели. Если наш «семилетка» отвечает так, как это делает обычный ребенок, то значит на этом уровне мы провели качественно все процедуры. Если где-то сбоит, значит нужно искать ошибки и корректировать.
napa3um
16.11.2016 13:16«Становится очевидным при реализации этой модели» — это называется confirmation bias. Очевидно должно быть в итоге не реализаторам, а конечным пользователям, от которых вы так тщательно защищаетесь.
InFortis
16.11.2016 17:23Если так выдернуть фразу. то ваше замечание, что это «confirmation bias» выглядит корректным.
Мы заявляем нечто. Если то, что я говорю не соответствует действительности — то ок, укажите на это и я соглашусь. Есть сайт, видео, статьи — если где-то в них неправда, или вы нашли несоответствие или что-то, что не стыкуется с вашим опытом, буду благодарен за указание на это.
Если информации недостаточно — задавайте вопросы. Стараюсь отвечать, пишу статьи.
Если кому-то интересно то, что мы делаем и этот интерес взаимен, то нет никаких проблем получить доступ и к имеющейся программе.
LorDCA
16.11.2016 17:33Задаю вопрос вашей модели после ваших примеров. ПОЧЕМУ? И видимо не получаю ответа, ибо «по короткому ребру» для нее не очевидно, а меня такой ответ не устроит. В чем именно «понимание смысла» по короткому ребру заменяет рассуждения?
ИМХО. Но вы все еще повторяете то что было проделано 60 лет назад с семантическими моделями. При этом пересыпая все «умными» словами.InFortis
16.11.2016 19:00Да, на вопрос «Почему?» ответа не будет. Семилетний ребенок на него тоже не даст ответ. Мы не говорим в этой статье, что понимаем cмысл. Мы говорим, что понимаем часть контекста (первый вид по нашей классификации). Понимания контекста в том, что ИИ дает адекватный ответ.
Понимание смысла, из подтекста, будет описано в следующей статье.
Да, часть того, что мы делаем, было 60 лет назад.
Но это все равно, что сравнивать современный мобильный и телефон такой же давности. И микрофон и динамик есть. Но есть и различия.
Мы описали, как работает наш ИИ с частью ситуаций контекста. Буду благодарен за ссылку на описание решения такой же задачи ранее.

TheCreator
15.11.2016 22:35Скажите пожалуйста, какие у вас сейчас планы по развитию алгоритма? Цели, желания, препятствия на пути к их реализации?
InFortis
15.11.2016 23:00Немного непривычный вопрос для этого ресурса))
Планы у нас простые. Закончили работу над алгоритмами и структурой семантической сети «семилетки», занимаемся «12-летним», в основном, абстрактным мышлением и алгоритмом изменения собственной структуры ИИ. В следующем году хотим пройти тест Тьюринга на его базе, если успеем, затем — полноценный «взрослый».
Цель и желание — создать платформу, предлагающему возможности ИИ, идентичного человеку для партнеров. Сейчас, для «семилетки» ищем партнера для смарт-бота — поддерживать беседу в ограниченной предметной области (тех поддержка, ответы в твиттере, в т.ч. вместо известных людей, и т.д.) сможет на высоком уровне. Препятствие — актуален вопрос финансов или партнерства с сильной командой девелоперов.

buriy
15.11.2016 22:36Идея-то хорошая, и весьма логичная. Но кто и каким образом построит эту огромную базу данных, необходимую, чтобы ваш алгоритм работал на практике? Кто настроит в этой базе данных веса активации?
Как будет этот алгоритм выбирать правильное значение на таком примере: «Ей нужен мужик не с луком, а с яйцами» (вероятна активация слова «лук» в значении «растение», в связи с наличием рядом слова «яйца» — а глобальный контекст может отсутствовать)? (Если же у вас вес активации «мужика с яйцами» оказался выше «продукта с яйцами» — то держите контрпример: «мужик пришёл с пирожком с яйцами».)
P.S. Сам подход часто называется https://en.wikipedia.org/wiki/Spreading_activationNLO
15.11.2016 22:43НЛО прилетело и опубликовало эту надпись здесь
buriy
15.11.2016 23:02Это просто забавный пример для иллюстрации серьёзной проблемы, не берите в голову, если не хотите разобраться в деталях.
А до уровня пятилетнего ребёнка уже научили — и даже компьютер уже тесты средней школы вполне себе неплохо проходит, на уровне чуть хуже среднего ребёнка.
https://www.technologyreview.com/s/541001/ai-software-goes-up-against-fourth-graders-on-science-tests/
А также:
http://www.dailymail.co.uk/sciencetech/article-3322601/Japanese-artificial-intelligence-passes-university-exams-t-quite-country-s-school.html
https://www.techinasia.com/chinas-building-ai-robot-thinks-pass-college-entrance-exam
InFortis
15.11.2016 23:34Язык уже понимает на уровне 7 лет. но не только язык, а еще и сказанное, как это делает ребенок этого возраста.
InFortis
15.11.2016 23:15Согласен, база немалая. но мы «семилетку» учили и скажу, что задача обучения до взрослого, даже методом обучения экспертами, вполне решаемая. Но мы для 12-ти летки делаем алгоритм, который будет бОльшую часть информации брать из авторитетных источников. Учитывая, что ландшафт сети сформирован на «семилетке», рассчитываем сильно ускорить процесс. Тем более, что для одной языково-культуральной группы это надо делать один раз.
Контекст и людьми не всегда понимается. Тут мы ограничены возможностями эталона (реального человека). Подобная ситуация решается просто, в тех редких случаях, когда расстояние до узлов одинаковое (для первого типа) или подтекст неясен — задается уточняющий вопрос.buriy
16.11.2016 00:33Почитал ваши ответы к прошлой статье. В чём-то по-хорошему вам завидую, разработка становится интересной, тем более, что подход к способу уточнения неоднозначностей вы выбрали необычный для отрасли: «неоднозначность — это не баг, а фича, разрешайте неоднозначности вручную, в базе их быть не должно» — это вполне может оказаться революционным элементом и позволит сдвинуть экспертные системы с места.
Правда, NELL ( http://rtw.ml.cmu.edu/rtw/ ) это всё ещё не помогло: при увеличении количества понятий в БД, число необходимых для логического вывода связей разрастается с бешеной скоростью, а у них была гипотеза, что по мере накопления базы знаний, неоднозначность новых знаний будет решаться лучше.
Я всё же больше верю в использование нейросетей и, когда возможно, большого количества источников для уверенного снятия неоднозначности (см. https://concept.research.microsoft.com ).
И ещё ведь во многих случаях явно необходимо моделирование мира и построение оценки правдоподобия различных вариантов синтактически-семантического разбора…
В итоге, получается крайне сложная инженерная задача.InFortis
16.11.2016 12:22Да, количество неоднозначностей растет. «Вручную» мы их ликвидируем для «семилетки». Для 12-ти летнего разрабатываем алгоритм самообучения. Большая его часть — это работа с противоречиями в БД. Для выбора «правильной» информации из двух, пока, используем авторитетность источника, непротиворечивость аналогам и еще несколько.
В какой-то степени мы повторяем математику нейронных сетей. Особенно в той части, где оперируем вероятностями.

zirix
16.11.2016 02:30Я тут иду по набережной и увидел косу. Интересно, какая коса самая длинная?
Загрузили в систему статью из википедии:
Коса? — низкая намывная полоса суши на берегу водного объекта, соединяющаяся одним концом с берегом.
В итоге море-коса связаны через сущность «водяной объект». Уже получаются равные интервалы между косой(рельеф) и косой девушки.
Потом оказывается что есть прямая связь между гулять и девушкой. В итоге система решает, что имеется ввиду коса девушки.
Слишком примитивный подход и не думаю что это будет работать.
«Глаза слезились, когда она резала для салата лук»
«если вы в книге Льва Толстого встретите фразу «Он распечатал письмо…»
Разделение на виды контекста ошибочны. Для понимания этих фраз человек использует один и тот же механизм.
Разница только в том, что мы замечаем ошибочный вывод печать=>принтер(в то время принтеров не было) и пытаемся вспомнить на чем еще могут печатать.
Причем ошибку в выводе мы можем не заметить.
InFortis
16.11.2016 11:46Расстояние у нас функция не только от числа интервалов, но и от вероятности перехода по ним. «Набережная»-«гулять», «гулять»- «люди» вероятность довольно низкая. Разница в расстоянии между двумя видами «косы» все же почти два порядка.
Обоснуйте ошибочность деления на виды контекста, пожалуйста.zirix
16.11.2016 18:42но и от вероятности перехода по ним.
А у вас есть алгоритм который расставит вероятности?
Разница в расстоянии между двумя видами «косы» все же почти два порядка.
Только потому что вы сами так нарисовали. На реальных данных может быть обратная ситуация.
Обоснуйте ошибочность деления на виды контекста, пожалуйста.
Обосновать мне мешает NDA, извините.
Вы игнорируете такую вещь как мышление, сознание и самоосознание. И именно эти вещи ответственны за понимание смысла текста.
Ваш алгоритм/подход способен «понимать» контекст только в самых примитивных ситуациях. И в этом причина деления на типы контекста, первый тип задач ваша система способа решать, второй тип не способна.
InFortis
16.11.2016 19:43А у вас есть алгоритм который расставит вероятности?
Да, сейчас вероятность у некоторых связей присваивается в процессе обучения ИИ.
Только потому что вы сами так нарисовали. На реальных данных может быть обратная ситуация.
Мы постарались описать абсолютно конкретные связи конкретных вершин у среднего русскоязычного пользователя. У конкретного может отличаться, готов обсудить. Вероятности на схеме не указаны.
Вы игнорируете такую вещь как мышление, сознание и самоосознание. И именно эти вещи ответственны за понимание смысла текста.
Мышление — это общее название всего, что происходит у человека в мозге. Мы, здесь, описываем конкретные операции.
Сознание — это феномен, который с пониманием текста связан очень опосредовано.
Самоосознание не связано с пониманием теста. Буду благодарен, если покажете как. Без иронии.zirix
16.11.2016 20:37Самоосознание не связано с пониманием теста. Буду благодарен, если покажете как.
Самое простое что можно придумать:
Задаю вашей системе вопрос:«что ты сегодня делал?».
Представим что систему не программировали на подобный тип вопроса и ваша система не собирает специальным алгоритмом информацию о своих действиях.
Система должна уметь отличать из кучи событий действия которые могут быть отнесены к действием самой системы. Т.е. система должна понимать что есть ее «Я» и что к этому «Я» относится.
Сознание и самосознание стоило написать через слеш т.к. это почти одно и тоже.
Мышление и сознание это проявления работы единого алгоритма, мышления без сознания не бывает.
А без мышления не бывает понимания речи.InFortis
16.11.2016 21:28Целиком согласен с написанным. Я говорил о понимании текста. Касательно коммуникации, и, как Вы указали, вопросов, касающихся личности спрашиваемого, без самоосознания не обойтись. У нас пока эта задача не в приоритет, т.к. у семилетки все очень вырождено. Если надо будет в смарт-боте это реализовать, то сделаем. Для 12-ти летки этим пока не занимались, сосредоточены на абстрактном мышлении и алгоритме самообучения.
LorDCA
16.11.2016 04:08Все красивые рассказы о понимании и контекстах, а так же глубинного понимания психологии, можно закончить сразу после фразы из первой статьи.
«Вначале текст обрабатывается парсером, разработанным в Стенфордском университете.»
То есть, без парсера эта система вообще ничего не понимает. Соглашусь о будущем этой системы как только предьявят наличие парсера в человеческом сознании. :)InFortis
16.11.2016 11:49Парсером пользуемся, экономя ресурсы. Его функциональность довольно ограничена, мы его тоже можем сделать, но сейчас это не рационально. Парсер выдает только части речи, наше же решение гораздо сложнее — семантическая сеть, алгоритмы.
Человек понимает какие слова относятся к каким частям речи в услышанном. Вы же понимаете? Следовательно, функционал парсера «в сознании» есть.LorDCA
16.11.2016 17:36Нет у нас парсера. Ибо не расматриваем мы слова как части речи. Так же как нет наследственной памяти и предустановок с рождения, о которых вы дискутировали в коментах к прошлой статье. Проблема как мне видится. Вы начали городить огород не имея четкой модели описывающей все нюансы. А теперь пытаетесь из «говна и палок» залатать то что выпадает. :(
InFortis
16.11.2016 19:02Парсером я назвал возможность назвать части речи в услышанном предложении. Эта возможность у человека есть со школы. Части речи используются для понимания текста человеком и установления связей в семантической сети нашим ИИ.
«Наследственная память и предустановки с рождения» (у нас это врожденные качества) — вопрос дискуссии. Я и коллеги считаем, что есть. Такие теории есть и в психологии. Эту гипотезу мы, наряду с другими, положили в основу нашего решения.
Я не сказал, что мы описываем абсолютно все нюансы. Мы, в этих статьях, описываем наш подход. В первой — вообще. Во второй — решения конкретной задачи.
Не понял что и у кого выпадает?zirix
16.11.2016 19:42возможность назвать части речи в услышанном предложении. Эта возможность у человека есть со школы. Части речи используются для понимания текста человеком
т.е. до школы люди не понимают речь и не умеют читать?LorDCA
16.11.2016 20:27По всей видимости нам сейчас раскажут что парсер это часть «наследственной памяти». Гы гы
По сути я вижу следующее. Есть некая семантичесеая сеть и есть куча правил к этой сети описанная ручками. Общаться с этой конструкцией можно только в рамках описаных правил. Ни шага в сторону. При этом все преподносится " мы психологи, мы знаем много умных словей". И мы можем прогнуть свою теоиию под любые несуразности нашей системы.
Так же видимо потрачено очень много времени на прописание всех этих правил. И автору теперь жалко признать что теория ошибочна. Ибо по сути должно быть всего одно правило. Правило создания новых правил.InFortis
16.11.2016 21:21Раньше я сказал, что оперировать частями речи ребенок обучается в школе. До этого таких категорий для него не существует. Мы их используем в нашем решении, т.к. часть речи есть некоторая результирующая правил языка, как я ее понимаю. Правила языка позволяют нам, людям понимать друг друга.
Да, вы правы, алгоритмы обращения к семантической сети для семилетки описаны руками. Они сейчас покрывают 95% коммуникации ребенка — возможность понимать сказанное и отвечать на вопросы соответственно возрасту. Делать их под другому, например, через алгортим формирующий свою структуру не целесообразно для такого возраста. Мы готовы прописать так алгоритмы вплоть до взрослого возраста. Но нам интереснее сделать алгоритм самообучения, начиная с 12-летки, чем и заняты.
Не понял, о каких «умных словах» идет речь.
Правило в создании этих правил — следовать структурам и процессам психики.
В чем я должен признавать ошибочность? Где несуразности в фунционировании системы или ее описании?LorDCA
17.11.2016 14:56Предлагаю убрать из ваших рассказов,
«Мы психологи, мы понимаем как работает сознание» это не аргумент.
" Это модель 7 летнего ребенка"… в данном случае хочется процитировать американцев «Stop trying to sell me this shit»… ибо может быть людям не имеющих детей вам и получится продать данный аргумент, но лично мне не очень ясно где вы нашли такого слабоумного ребенка, который ничем не интересуется, который не пытается объяснить или ответить на элементарные вопросы.
Что у нас будет в сухом остатке?
Некая конструкция из IF THEN ELSE c парой функций поиска по семантической базе. Причем саму базу нужно набивать руками и так же руками прописывать все IF THEN ELSE. Все непрописанные или не правильно сформулированные вопросы ваша конструкция просто игнорирует ( гугл ассистент хотя бы предлагает в поддержку обратится). Так в чем тут прорыв технологий? Какие KnowHow? В бизнес процессах таких систем как грязи.
Да и алгоритм самообучения присутствует с рождения. У вас он почему то к 12 годам появляется. :) Вы точно реализуете психологию ЗДОРОВОГО ЧЕЛОВЕКА, или это у вас професиональная деформация?InFortis
17.11.2016 17:25… где вы нашли такого слабоумного ребенка, который ничем не интересуется, который не пытается объяснить или ответить на элементарные вопросы.
Наш семилетка похож на реального в ситуации общения с ним посредством текстовой строки. В остальном он не похож на ребенка, у него нет большинства потребностей, которые есть у реального ребенка. Обучается он реактивно — мы его учим, он может уточнить, если что-то не стыкуется. Сам нас вопросами не донимает. У нас сейчас не полноценная модель семилетнего ребенка.
Некая конструкция из IF THEN ELSE c парой функций поиска по семантической базе.
Да, чаще всего в наших алгоритмах используется оператор IF THEN ELSE, но функций поиска по семантической сети гораздо больше, чем две.
Нынешние алгоритмы для семилетки покрывают больше 95% ситуаций общения, свойственных этому возрасту. Т.е. если мы найдем еще какую-то ситуацию, какой-то вид вопроса — то добавим. И да, это сделано вручную.
На счет прорыва — не уверен. Я отталкиваюсь от двух моментов:
1. У нас подход в построении ИИ путем копирования структур и процессов психики и мне не известны аналогичные решения.
2. У нас есть семилетка, который в чате неотличим от реального ребенка этого возраста. Мне не известны аналогичные по функционалу решения: что-бы и понимал естественную речь и мог отвечать, как реальный ребенок.
Нашим know-how считаю топологию нашей семантической сети, ряд алгоритмов и структур, причем не «слизанных» с психики, а именно компенсирующих отличие нашенго решения. С некоторыми формулами долго возились, их тоже.
Вы точно реализуете психологию ЗДОРОВОГО ЧЕЛОВЕКА,
Наш ИИ психически здоров. У него есть ограничения, например, мы не работаем с видео и с исполнительными механизмами. Можно сказать, что он у нас пока слепой и парализованный. Кроме этого, у него присутствуют структуры и алгоритмы, отсутствующие у человека. Для компенсации особенностей программных языков, другого профиля потребностей, для экономии ресурсов разработки.
… или это у вас професиональная деформация?
Я каждую неделю посещаю интервизионную группу, которая помогает избежать проф. деформации. Плюс периодически прохожу личный анализ.zirix
17.11.2016 20:121. У нас подход в построении ИИ путем копирования структур и процессов психики и мне не известны аналогичные решения.
Есть системы которые легко делают то, что у Вас на видео. И способны отвечать на значительно более сложные вопросы.
Есть еще Латентно-семантический_анализ. Если внимательно посмотреть, то видно сходство принципов работы вашей системы(контекста) и ЛСИ.
2. У нас есть семилетка, который в чате неотличим от реального ребенка этого возраста.
Ваша система проходит Тест Тьюринга?
Ваша система провалит тест на первом же вопросе, с большой вероятностью вопрос не будет соответствовать заложенным в систему шаблонам.
Если вы ищите инвестора и подобными громкими заявлениями пытаетесь его привлечь, то у меня для вас плохая новость. Любой адекватный инвестор захочет провести экспертизу и пригласит специалистов.
И эти специалисты скажут тоже самое, что написано в комментариях.InFortis
18.11.2016 13:22Есть системы которые легко делают то, что у Вас на видео. И способны отвечать на значительно более сложные вопросы.
Наверное, эта часть комментария лучше соотносится со вторым пунктом.
Да, есть решения, которые выигрывают в Го, строят маршруты движения и заказывают гостиницы. Мне не известны продукты, которым можно сказать что-то на естественном языке и потом, в своих ответах он будет использовать эту информацию и делать это на уровне семилетки. Если Вам известны, буду благодарен за ссылку.
Про латенто-семантический анализ, латентное размещение Дирихле — в следующей статье.
Ваша система проходит Тест Тьюринга?
Ваша система провалит тест на первом же вопросе, с большой вероятностью вопрос не будет соответствовать заложенным в систему шаблонам.
Нет, сейчас тест Тьюринга мы не проходим. Я говорю только об общении, где можно что-то сказать о мире и спросить. Понимание текста и ответ будут как у семилетки. Сейчас речь идет о когнитивных процессах. Уже длительное время не обнаруживались вопросы, не охватываемые нашими алгоритмами. Там не такие жесткие скрипты, скорее структуры и элементы речи (вопросительных предложений). Но мы готовы добавить новые виды вопросов, если обнаружим.
Для полноценного продукта на тест Тьюринга не хватает эмоций и личности. Алгоритмы их описывающие, по нашему мнению, гораздо менее обширны, чем когнитивная сфера. Частично мы их уже описали, но в цифре этих блоков нет.
Если вы ищите инвестора и подобными громкими заявлениями пытаетесь его привлечь, то у меня для вас плохая новость. Любой адекватный инвестор захочет провести экспертизу и пригласит специалистов.
И эти специалисты скажут тоже самое, что написано в комментариях.
Возможно. С экспертами инвесторов мы общались и общаемся. И инвестиции уже были. Пока подобных вашим вопросов от них не было. Но я благодарен Вам за Вашу критику. Новая точка зрения позволяет мне лучше понять позицию людей, которые в первый раз слышат о нашей работе, я учусь лучше рассказывать о проекте, периодически нахожу белые пятна.zirix
18.11.2016 17:53Мне не известны продукты, которым можно сказать что-то на естественном языке и потом, в своих ответах он будет использовать эту информацию и делать это на уровне семилетки. Если Вам известны, буду благодарен за ссылку.
Ссылку вам я уже давал.
Вот, читать снизу вверх:
https://habrastorage.org/getpro/geektimes/comment_images/4cd/f2f/9d1/4cdf2f9d1b6b33d4027952821a42c066.jpg
InFortis
19.11.2016 15:40Приведенные Вами скриншот с функциональностью явно отличается от нашего решения. По нему видно, что ваша система способна на некоторые логические операции. Наш ИИ сейчас не умеет решать таких задач.
Предположу, что у вашего решения нет знаний о мире, соответствующих семилетке, он не способен отвечать на обычные вопросы, которые уместно задать ребенку. Или я ошибаюсь?
Пока я видел (на видео и скриншоте) возможность оперировать в рамках логики категориями.
Это не совпадает с нашим функционалом и тем способом, которым мы его достигли.
Не совсем понятно, как получился ответ, приведенный на скриншоте про бананы.
Даю первый вопрос: «что ты сегодня делал?». разве это не вопрос о мире?
Вот еще: «что делал сегодня твой кот?»
Это вы приводите пример беседы в вашей системе? И что Вам ответили? Как этот ответ был получен?
Ваша система ИИ бесконечно далека от интеллекта ребенка. Ваша система это туповатый чат-бот способный отвечать только на определенные вопросы заданные по определенным шаблонам.
Обоснуйте, почему наша система «бесконечно далека», если она понимает простой текст по возрасту и отвечает на вопросы, используя свои знания о мире и новую, только что полученную информацию?
От чат-бота мы в корне отличаемся технологией получения ответа. У нас нет скриптов. Ответ конструируется исходя из вопроса и из структуры семантической сети, содержащей соответствующие понятия.zirix
19.11.2016 20:05Приведенные Вами скриншот с функциональностью явно отличается от нашего решения.
Вы увидев пару фраз сумели понять «функциональность» нашей системы?
Системы действительно отличаются. У вас парсер и простые алгоритмы которые работают с семантическим деревом. А мы мышлением, сознанием и пониманием естественного языка занимаемся.
По нему видно, что ваша система способна на некоторые логические операции.
Если вы имеете ввиду индукцию и дедукцию, то да. Еще она понимает местоимения и прочие штуки которые затрагивает Winograd Schema Challenge.
Главное: вы убедились что есть другие системы «понимающие» человеческую речь?
И мы не единственная компания которая работает в этом направлении и которым есть что показать.
Это вы приводите пример беседы в вашей системе?
Это вопрос на который ответит ребенок, но не ответит ваша система.
Обоснуйте, почему наша система «бесконечно далека», если она понимает простой текст по возрасту и отвечает на вопросы, используя свои знания о мире и новую, только что полученную информацию?
Записать в семантическую сеть пару фактов — это не понимание. Вообще глупо говорить о «понимании» без наличия сознания и мышления.
И еще глупее сравнивать систему без мышления с ребенком.
Вы очень мало понимаете в теме ИИ, отсюда и убежденность в уникальности и крутости вашей системы.
Думаю существует аналог Эффекта Даннинга — Крюгера для вашего случая.
Самое главное вы не понимаете какие требования предъявляются к сильному ИИ(а ребенок это сильный ИИ) и что он обязан уметь:
Сильный ИИ должен обладать следующими свойствами:
Принятие решений, использование стратегий, решение головоломок и действия в условиях неопределенности;
Представление знаний, включая общее представление о реальности;
Планирование;
Обучение;
Общение на естественном языке;
И объединение всех этих способностей для достижения общих целей.
Существуют и другие аспекты интеллекта человека, которые также лежат в основе создания Сильного ИИ:
Сознание: Быть восприимчивым к окружению;
Самосознание: Осознавать себя как отдельную личность, в частности, понимать собственные мысли;
Сопереживание: Способность «чувствовать»;
Мудрость.
От чат-бота мы в корне отличаемся технологией получения ответа. У нас нет скриптов. Ответ конструируется исходя из вопроса и из структуры семантической сети, содержащей соответствующие понятия.
Семантические сети это старая тема, глупо считать что вы ее первые применили.
Чат-боты с семантической сетью тоже были и делали похожие вещи что у вас на видео.zirix
19.11.2016 21:12Не совсем понятно, как получился ответ, приведенный на скриншоте про бананы.
Экспериментировали с заливкой вики, он уже знал:
Викисловарь: спелый > поспевший, зрелый (о плодах, овощах, злаках)
Википедия: Банан > название съедобных плодов
Про обезьян/животных подобного у него не нашлось и он сделал предположение что имеется ввиду банан.
Можно убрать вики и сказать: банан это плод. Плоды могут быть спелые.InFortis
19.11.2016 23:42Наш ИИ некоторые тексты «взрослой» вики не может понять. Учим его на Simple English Wikipedia.
Ваш пример с бананами описывается онтологией. Следовательно, Ваше решение хорошо справляется с задачами со структурированной информацией. Категории, описывающие жизнь человека, его мышление, его речь не имеют иерархической структуры. Возможно, из-за ограниченности сферы применения Вы и не даете доступа к демке. Она работает только со сконструированными или отобранными специально для нее высказываниями. Мышление это не пару логических операций.
По поводу онтологии внизу дал комментарий.zirix
20.11.2016 01:11Возможно, из-за ограниченности сферы применения Вы и не даете доступа к демке.
Кому не даем? И почему мы этому «кому» должны что-то показывать?
Если люди хотят договориться о встрече, то дают в качестве контактов ФИО и телефон, а не обезличенный email:«info@».
В особенности если встреча нужна вам.
InFortis
19.11.2016 23:06Вы увидев пару фраз сумели понять «функциональность» нашей системы?
Да. По порядку слов, категориям, которыми оперируете, общей структуре диалога. Возможно ошибаюсь.
А мы мышлением, сознанием и пониманием естественного языка занимаемся.
По части мышления и понимания естественного языка — мы, вроде бы, тоже им занимаемся. А вот термин «сознание» выглядит в этом ряду странно.
Если взять определение:
«Сознание — состояние психической жизни человека, выражающееся в субъективном переживании событий внешнего мира и жизни самого индивида» то о какой психической жизни идет речь? о каком субъекте и переживаниях? как вы это реализуете?
Мне легче сделать вывод, что Вы просто употребляете термин для красного словца. Из очень ограниченных показанных Вами материалов это точно не следует.
Главное: вы убедились что есть другие системы «понимающие» человеческую речь?
Я не говорил, что нет систем, понимающих речь. Они есть, просто отличаются, на сколько мне известно, от нашей по подходу и по похожести на человека пониманием и возможностью говорить. Но ваше решение к ним отнести не могу, не достаточно информации. Пока оно похоже на систему, работающую с категориями в рамках логики.
Это вопрос на который ответит ребенок, но не ответит ваша система.
Вы странно критикуете. Я сказал, что личности сейчас у системы нет. Есть знания о мире, соответствующие ребенку. Где кто живет? Почему идет дождь? Какие машины бывают? Вы приводите примеры вопросов, содержащие личные местоимения. Да, на эти вопросы наш ИИ сейчас не ответит. Надеюсь, этот блок будет к весне.
Записать в семантическую сеть пару фактов — это не понимание
Если взять определение, что «понимание — это операция мышления, связанная с усвоением нового содержания, включением его в систему устоявшихся идей и представлений», то это как раз и есть то, что делаем мы. Мы берем категорию и вписываем ее в семантическую сеть, устанавливая связи именно с теми категориями, с которыми она связана у человека.
Вы оперируете такой категорией, как мышление, но, думаю, что у Вас речь идет о логических операциях. По-моему, мышление гораздо шире.
Да, я знаю, что характеризует сильный ИИ и, надеюсь, мы продвигаемся в его разработке. Нынешний уровень ему не соответствует, это да.
Семантические сети это старая тема, глупо считать что вы ее первые применили.
Вы хороший демагог. Назвали меня глупым, хотя я нигде не говорил, что думаю, будто мы первые работаем с семантической сетью.
Чат-боты с семантической сетью тоже были и делали похожие вещи что у вас на видео.
Вы неоднократно это утверждали в комментариях. Повторюсь: буду благодарен за ссылку.
Вы приписываете мне высказывания, и основываясь на них называете меня глупым. По моей некомпетентности какие-то аргументы будут?
Вы позволяете себе высказывания относительно моей личности, поэтому позволю себе высказаться. Ваши комментарии делятся для меня на три типа:
1. Это делают все/это уже давно делали.
Да, не спорю с этим. Мы используем много уже ранее использовавшихся решений. Но есть и новое как в подходе так и в конкретных приёмах.
2. Ваш подход к ИИ — полная фигня.
Аргументировать отказываетесь — то NDA вам аргументы приводить не позволяет, то занимаетесь демагогией. Понятно Ваше желание обесценить. Особенно на фоне того, что у Вас собственное решение в этой сфере и функционалом оно не блещет.
3. Мое решение крутое.
Но доводов нет. Есть спекуляции на тему самоосознания, сознания и мышления. При этом демонстрируете весьма ограниченный функционал, где этих категорий не видно. Есть только возможность логических операций с сущностями, причем очень ограниченный набор.
Хотел бы вернуть нашу беседу к формату научной дискуссии.zirix
20.11.2016 00:33Хотел бы вернуть нашу беседу к формату научной дискуссии.
Сложно поддерживать научную дискуссию видя вот это:
По части наличия его(Самоосознания) у семилетки, то оно весьма вырождено.
…
Ни одно суждение он не конструирует сам.
По части мышления и понимания естественного языка — мы, вроде бы, тоже им занимаемся.
Нет, не занимаетесь. Мышления у вас нет.
Язык вы парсите LEX'ом который для языков программирования используется. И в общем подход довольно примитивный.
А вот термин «сознание» выглядит в этом ряду странно.
Если взять определение:
Там есть и продолжение:
а в узком смысле — «высшая, свойственная только людям и связанная с речью функция мозга, заключающаяся в обобщенном и целенаправленном отражении действительности, в предварительном мысленном построении действий и предвидении их результатов, в разумном регулировании и самоконтролировании поведения человека за счет рефлексии»
Вообще такие вещи стоит не в википедии смотреть.
И как я уже говорил сознание и самосознание это почти одно и тоже. Замените на самосознание если непонятно.
Я не говорил, что нет систем, понимающих речь
А что я по вашему в своем ответе процитировал?
Вы странно критикуете. Я сказал, что личности сейчас у системы нет. Есть знания о мире, соответствующие ребенку. Где кто живет? Почему идет дождь?
Fact Extractor?
А критикую я вас из за этого:
У нас есть семилетка(программа), который в чате неотличим от реального ребенка этого возраста.
Если взять определение, что «понимание — это операция мышления, связанная с усвоением нового содержания
У вас нет мышления. А нет мышления нет и понимания.
Если программа записывает в базу данных информацию это не означает что она ее понимает. У вас семантическая сеть — это база данных.
Вы неоднократно это утверждали в комментариях. Повторюсь: буду благодарен за ссылку.
Ссылку на что? На древние боты?
Понятно Ваше желание обесценить. Особенно на фоне того, что у Вас собственное решение в этой сфере и функционалом оно не блещет.
:) Если вы посмотрите, то не только я вас тут критикую.
Я веду диалог с вами только по одной причине — вы очень похожи намошенниковискателей доверчивого инвестора. И такое впечатление сложилось не только у меня.
К тому же ваш бред про детей — дебилов поднимает настроение.
3. Мое решение крутое.
…
При этом демонстрируете весьма ограниченный функционал
Я никому ничего не демонстрировал. Пара фраз, которые пришли в голову, это не демонстрация.InFortis
21.11.2016 14:27Сложно поддерживать научную дискуссию видя вот это:
С чем вы в мой фразе не согласны?
По мышлению — мы разбиваем его на конкретные операции. Часть из них описаны.
И как я уже говорил сознание и самосознание это почти одно и тоже. Замените на самосознание если непонятно.
Вы ошибаетесь, сознание и самосознание абсолютно различные феномены.
А критикую я вас из за этого:
У нас есть семилетка(программа), который в чате неотличим от реального ребенка этого возраста.
Тут вы правы, каждый раз описывая функциональность, буду указывать и ограничения.
Ссылку на что? На древние боты?
Это один из ваших приёмов в комментариях к моим статьям. Вы говорить, что эта функциональность уже реализована, но не подтверждаете ссылкой.
От ботов мы отличаемся радикально. Боты жестко заскриптованы, при вопросе, которого нет в скриптах — или чушь или общие фразы.
Наш ИИ конструирует ответы из информации в семантической сети. Как это делает человек. Он может чего-то не знать, иметь ошибочные представления. Как и человек. Общего с ботами у нас только то, что общение ведется в строке.
Я веду диалог с вами только по одной причине — вы очень похожи на мошенников искателей доверчивого инвестора. И такое впечатление сложилось не только у меня.
До этого вы обвиняли меня в глупости, некомпетентности, теперь — что я мошенник. В ваших неаргументированных комментариях, когда вы просто кидаете фразы, не подкрепляя их аргументами, есть для меня большой плюс. Даже такой смотивированный критик не нашел белых пятен, ошибок и несоответствий. То, что вам приходится, за неимением аргументов, сместиться к приемам некорректного ведения спора, для меня важно.zirix
21.11.2016 18:10С чем вы в мой фразе не согласны?
С каждым словом:)
Вы ошибаетесь, сознание и самосознание абсолютно различные феномены.
У вас есть аргументы? Если смотреть википедию, откуда вы любите брать цитаты, то можно увидеть что эти понятия описывают почти одно и тоже:
Самосозна?ние — сознание субъектом самого себя в отличие от иного — других субъектов и мира вообще; это сознание человеком своего взаимодействия с объективным миром и миром субъективным (психикой), своих жизненно важных потребностей, мыслей, чувств, мотивов, инстинктов, переживаний, действий.
Сознание — высшая, свойственная только людям и связанная с речью функция мозга, заключающаяся в обобщенном и целенаправленном отражении действительности, в предварительном мысленном построении действий и предвидении их результатов, в разумном регулировании и самоконтролировании поведения человека за счет рефлексии
Это один из ваших приёмов в комментариях к моим статьям. Вы говорить, что эта функциональность уже реализована, но не подтверждаете ссылкой.
Вы ставите окружающих в тупик предлагая дать ссылку на проект который использует технологии признанными бесперспективными еще 50 лет назад.
Из древностей есть https://ru.wikipedia.org/wiki/SHRDLU и https://ru.wikipedia.org/wiki/Cyc
И еще сотни подобных проектов, которым не повезло оказаться в википедии.
От ботов мы отличаемся радикально. Боты жестко заскриптованы, при вопросе, которого нет в скриптах — или чушь или общие фразы.
Глупо считать что вы единственный кто придумал сделать боты менее заскриптованными.
Даже такой смотивированный критик не нашел белых пятен, ошибок и несоответствий.
:) А как же ваш бред про детей — дебилов? Вы говорили что у детей 7 лет вырожденное сознание, нет абстрактного мышления и что они не умеют конструировать суждения.
А что до вашей системы, то все ваши ноухау описываются в википедии. Смотреть «семантическая сеть» и «латентно-семантический анализ.»
Кстати вы первый перешли на личности. Глупо считать != вы глупый человек.
Жду вашу следующую статью.zirix
21.11.2016 18:51Чуть не забыл
Вы в своем комментарии пропустили один важный момент: Вы согласны с тем что ваша система не понимает человеческую речь?InFortis
21.11.2016 20:54Ранее, в ответе на один из Ваших комментариев, я написал о нашей разработке:
… понимает простой текст по возрасту и отвечает на вопросы, используя свои знания о мире и новую, только что полученную информацию.
InFortis
21.11.2016 21:17Вы ошибаетесь, сознание и самосознание абсолютно различные феномены.
У вас есть аргументы? Если смотреть википедию, откуда вы любите брать цитаты, то можно увидеть что эти понятия описывают почти одно и тоже:
В своей разработке мы исходим из того, что сознание и самосознание — это категории различные как масштабом, так и функциями, при этом самосознание может быть частным случаем наполнения сознания.
LorDCA
17.11.2016 23:09Я боюсь представить что делает семилетка в чате. Видимо молчит постоянно. И вот в этом месте уже вынужден согласится, что ваш бот неотличим, он так же молчит и игнорирует все вопросы не описаные в его логике. :) Имеем так сказать полное соответствие.
Пытаюсь представить как он у вас будет читать книги и описывать их содержание. Видимо кто то будет читать и прописывать краткое содержание согласно правилам.
Интересно сколькими правилами оперирует взрослый человек, по вашему мнение? При этом не забываем что для логический построений нужно уметь самому создавать правила.
Возвращаемся к тому, что если отбросить всю шелуху про психологов и модели психики, имеем обычную семантическую сеть с набором правил. И понятное отсутствие инвесторов и необходимость много и сильно кодить. Ибо в заявленной категории должен быть всего один ответ, да, наша модель способна развиваться сама. Вы этого сказать не можете, заместо этого вы начинаете рассказы о званиях, опыте и прочем.
Обсуждение прошлой статьи и этой напоминает старый ералаш.
— Кефира не было.
— Деньги.
— Какие деньги?
— Я тебе рубль дал?
— Дал.
— За кефиром послал?
— Послал.
— Кефира не было?
— Не было
— Деньги.
— Какие деньги?
Грустно в общем все это.InFortis
18.11.2016 13:25Сейчас в чате нашему ИИ можно рассказать или дать короткий текст, например, о животном или какой-то машине. Затем задать вопросы и получить ответы. содержащие как полученную ранее информацию, так и недавнюю. На уровне семилетки.
Опиывать содержине книг он сейчас не может. Только отвечать на вопросы по этим книгам, по возрасту.
Взрослый человек оперирует большим числом правил, семилетка — меньшим. Эти правила имеют структуру. Мы можем все их описать алгоритмами.
Да, сейчас это семантическая сеть с набором правил. Одно уточнение: описывающие и воспроизводящие когнитивные процессы семилетки.
Про кефир — возможно, наш диалог так и выглядит. Я пытаюсь разобраться с Вашими аргументами. Чего-то, наверняка, не понимаю. Стараюсь отвечать на те вопросы, которые понял.zirix
18.11.2016 19:56Опиывать содержине книг он сейчас не может. Только отвечать на вопросы по этим книгам
Программы делающие это называются Fact Extractor'ы.
То что вы описываете умели даже боты в IRC.InFortis
19.11.2016 15:43Fact Extractor'ы, программа, выигрывающая в Го, чат-боты, кофеварки и калькуляторы симулируют некоторую деятельность человека. Они могут, иногда, даже делать это лучше чем человек (но не в случае Fact Extractor'а). Мне кажется, указание на них не корректно для критики нашего решения. Да, наш ИИ не варит кофе и не способен извлечь квадратный корень. Я уже повторяюсь, но мы видим его особенность в том. что:
1. Он не отличим от человека в диалоге (соответствующего возраста и с некоторыми ограничениями).
2. Построен путем копирования структур и алгоритмов, скопированных у человека (с некоторыми вариациями).
Он понимает речь и отвечает так, как это делает человек (7-ми лет).LorDCA
19.11.2016 17:57Он понимает речь и отвечает так, как это делает человек (7-ми лет)
Честно говоря уже как навязчивая идея у вас… на любые высказывания один и тот же ответ… На любые возражения что ваша модель не может ответить на элементарные вопросы и не осознает саму себя, вы пытаетесь скормить что и 7ми летние дети этого не могут… я еще раз спрошу, вы 7ми летних детей точно видели?InFortis
19.11.2016 22:50Я благодарен за конструктивную и аргументированную критику. Но. Я сказал, сейчас наше решение описывает когнитивную сферу семилетки с ограничениями. Самоосознания пока нет.
По части наличия его у семилетки, то оно весьма вырождено. На почти все вопросы, которые можно ему задать в этой сфере семилетний ребенок будет отвечать, цитируя взрослых. Ни одно суждение он не конструирует сам. Фактически, речь идет о функционале простого бота с заскриптованными ответами. Не вижу проблем это сделать, тут никаких новаций нет, обычный чат бот.
В 12-летке этот блок куда сложнее.buriy
20.11.2016 07:20>На почти все вопросы, которые можно ему задать в этой сфере семилетний ребенок будет отвечать, цитируя взрослых. Ни одно суждение он не конструирует сам.
Вы серьёзно? В 7 лет дети уже в школу ходят. Они там, по-вашему, занимаются вспоминанием и повторением того, что им взрослые сказали?
Вам правильно говорят, что ваши знакомые 7-летние дети видимо отстают в развитии.
Нечёткий вывод тоже относится к когнитивной сфере, и дети им тоже вполне владеют. У вас же пока только логический чёткий вывод, и критика обоснована.InFortis
21.11.2016 14:30>На почти все вопросы, которые можно ему задать в этой сфере семилетний ребенок будет отвечать, цитируя взрослых. Ни одно суждение он не конструирует сам.
В этой фразе я говорю о высказываниях ребенка о своих качествах, о себе. Безусловно, о мире он способен уже конструировать собственные суждения.
Вы серьёзно? В 7 лет дети уже в школу ходят. Они там, по-вашему, занимаются вспоминанием и повторением того, что им взрослые сказали?
Если вы говорите о различного рода задачах, которые дети решают в школе (например про яблоки), то я с вами согласен. По моему мнению, уже с пяти лет большинство детей способны на сложные умозаключения. А некоторые — гораздо раньше.
Я же говорил о самосознании, о восприятии себя. В этой сфере ребенок до семи лет цитирует взрослых или испытывает затруднения с ответом.
InFortis
19.11.2016 15:57И, наверное, главное — наше нынешнее решение промежуточное. Надеемся, что скоро (в след году) будет 12-ти летка, там функционал уже сравним с возможностями взрослого человека. Это решение иллюстрирует возможности нашего подхода к реешнию задачи построения сильного ИИ. Надеемся, успешно.
InFortis
16.11.2016 20:28Я говорю в среднем. в школе люди учаться выделять части речи и могут их назвать. Это совпадает с функциональностью парсера.
Читать, как правило, не умеют. Речь понимают с ограничениями, еще больше ограничений в возможностях высказать мысль, правильно построив предложение. В том числе и для этого обучают частям речи.zirix
16.11.2016 21:32Читать, как правило, не умеют. Речь понимают с ограничениями, еще больше ограничений в возможностях высказать мысль, правильно построив предложение. В том числе и для этого обучают частям речи.
Большое число цыган не ходят в школу, это не мешает убалтывать прохожих так что последние остаются без денег.
У некоторых дети в 4 года уже очень хорошо читают. При этом не зная что такое существительное и глагол.
Связь между знанием частей речи и умением читать/говорить точно такая же как между кол-вом пиратов и глобальным потеплением.
Отождествление корреляции и причинности — ошибка, состоящая в убеждении, что наличие корреляции означает причинно-следственную связь.
InFortis
17.11.2016 14:48Основная цель, которую мы ставили для нашего решения — понимать текст соответственно возрасту. Вы правы, читать для понимания речи не обязательно. Точно так не обязательно знать о частях речи. В наших алгоритмах мы используем готовый парсер, который определяет части речи потому, что эти части речи отражают некие законы построения предложений и способы донесения мысли.
Эти же законы можно уяснить и не умея читать или не зная о частях речи. Для нас готовый парсер сэкономил ресурс, т.к. нам не нужно было описывать часть этих закономерностей, они парсером предъявлялись в виде частей речи.
Например «Зеленый мяч» — «Зеленый» характеристика «Мяча». То, что это прилагательное и то, как оно сочетается с существительным позволяет установить соответствующую связь в семантической сети. И позволяет не рассматривать вариант, что «мяч» является характеристикой «зеленый». Без парсера это решается, но нужно было бы писать дополнительные алгоритмы.
LorDCA
17.11.2016 23:16Читать, как правило, не умеют. Речь понимают с ограничениями, еще больше ограничений в возможностях высказать мысль, правильно построив предложение. В том числе и для этого обучают частям речи.
Давайте еще раз. Ваша система не способна сама понимать части речи. На этом в общем то все. О каком понимании контента может идти речь? Если я напишу вашей системе небольшой текст " как я провел лето" попрошу рассказать «чем система занималась весь день»? Вы продолжите мне рассказывать, что 7-ми летний ребенок не способен мне рассказать чем он занимался?
Тут даже не понятно уже, вы хотите получить помощь и реальную оценку. или вы пытаетесь нас убедить что 7-ми летние дети мало отличаются от дебилов?InFortis
18.11.2016 13:26Да, для определения частей речи мы пользуемся заимствованным решением. Сами можем это сделать, но экономим ресурсы.
Алгоритмы понимания контекста использует части речи, но не только, это еще и структура семантической сети и алгоритмы.
Да, наш ИИ сейчас о себе ничего рассказать не сможет. Блоки самовосприятия не запрограммированы полностью и их еще надо отлаживать. Мы говорим о когнитивной сфере семилетки, она есть.
InFortis
19.11.2016 15:04Помощь и экспертизу мы здесь получаем, в том числе и от Вас, спасибо.
По клинической картине легкая и умеренно выраженная дебильность позволяет взрослому демонстрировать когнитивные возможности и более позднего возраста, чем 7-ми летка. Они могут освоить навыки и знания начальной школы, до 3 класса включительно. Так что да, здоровый семилетка может отставать в когнитивной сфере от человека с диагнозом дебилизм.
buriy
19.11.2016 17:20А вот есть ещё вопрос, который легко должен уметь решать семилетка, и который используют для проверки теста Тьюринга профессионалы:
«Что больше, туфелька или луна?» (и его вариации — слова берутся любые, но конкретно несравнимые, например, «слон» и «кусок сыра», а вместо размера можно использовать другие понятия — длина, стоимость, толщина, тяжесть, и т.п.).
Ответит ли ваша система на такой вопрос?
Расскажите, пожалуйста, что будет происходить в вашей системе при ответе на него.InFortis
19.11.2016 23:50Конкретно сейчас алгоритм ответов на подобные вопросы не запрограммирован. Есть полное ТЗ для программистов. Как только будет в цифре — ответит на большинство подобных вопросов.
Решали следующим образом. Из-за отсутствия обработки видео обучили пространственным категориям как абстрактным. Т.е. у собаки наряду с возможными расцветками шкуры, есть высота лежащей, сидящей и стоящей на задних лапах. В метрах. Собака расписана, т.к. встречается ребенку часто и сопоставима с ним по размеру. У слона один размер — высота. У предметов тоже есть размеры. У туфелек — высота, длина, ширина. По высоте сравнить слона и туфельку сможет. Луну нет. По ней размер не внесли. Такие нестыковки есть, вроде не много, но попадаются.
Старались подробнее описывать объекты, часто встречаемые. Чем реже, тем меньше характеристик. Для полноценного Тьюринга расширить количество этих связей придется. Возможно, если будем решать задачу оперирования в пространстве — это будет новый вид связи.
Тяжесть — у нас это вес — есть. Стоимости нет. Мал еще)))
Толщина — характеристика, совпадающая с одним из линейных размеров, закреплена разговорной речью за параметром некоторых предметов.
Схема, в общем, следующая:
1. Идентифицируется вид вопроса.
2. выделяются категории, о которых задается вопрос сравнения и параметр сравнения (тут нам парсер в помощь)
3. Для них ищутся соответствующие параметры.
4. Сравниваются эти параметры и делается вывод.
5. Формируется ответ в виде разговорной речи (тут опять парсер помогает)
Реальный ребенок выполняет другие операции при поиске ответа на такой вопрос, у него есть визуализация. Нам, пока, эта часть не доступна.
Но ребенок делает так же, когда для ответа надо вспомнить некие абстрактные характеристики объектов. Например «съедобно» — «не съедобно» относительно фруктов. которые сам не ел, а видел только на картинках. Так что тут мы ничего не изобретали, взяли с натуры, но операции смежной области.
Вообще по алгоритмам тоже думаю статью написать. Но как и про семантическую сеть — не знаю с какой стороны зайти, до какой степени детализировать.LorDCA
20.11.2016 00:04Схема, в общем, следующая:
1. Идентифицируется вид вопроса.
2. выделяются категории, о которых задается вопрос сравнения и параметр сравнения (тут нам парсер в помощь)
3. Для них ищутся соответствующие параметры.
4. Сравниваются эти параметры и делается вывод.
5. Формируется ответ в виде разговорной речи (тут опять парсер помогает)
Дык в целом уже достаточно для понимания.
Это было описано вот тут.
программа SHRDLU. Название SHRDLU образовано от ETAOIN SHRDLU — так расположены алфавитные клавиши на линотипах (в соответствии с убыванием частоты появления букв в английском языке). Как, к примеру, сейчас ЙЦУКЕН и ФЫВАПРОЛДЖ.
У SHRDLU был небольшой мир, в котором было представлено ограниченное количество объектов. Это были пирамидки, различные кубики, коробка. И SHRDLU умела общаться на естественном языке с человеком, обсуждая то, что происходит в этом мире, и умела выполнять команды, которые отдавал на естественном языке человек. При этом лексика никак не была ограничена, то есть человек говорить что угодно, а программа могла достаточно свободно отвечать. Вот пример работы SHRDLU:
Человек: Что лежит в коробке?
Компьютер: Синяя пирамидка и синий блок.
Человек: На чем лежит пирамидка?
Компьютер: На коробке.
Человек: Как много блоков находится не в коробке?
Компьютер: Четыре.
Человек: Хотя бы один из них более тонкий, чем тот, про который я тебе говорил? На чем-то он стоит?
Компьютер: Да, стоит на столе.
Человек: Может ли стол собирать блоки?
Компьютер: Нет.
Человек: Может ли пирамидка стоять на блоке?
Компьютер: Да.
Человек: Может ли пирамидка стоять на пирамидке?
Компьютер: Не знаю.
Человек: Хорошо. Поставь пирамидку одну на другую.
Компьютер: Не получается.
Человек: Поставь, пожалуйста, два красных блока друг на друга. Либо зеленый куб, либо пирамидку. Сможешь?» И SHRDLU берет эти блоки, начинает ими оперировать.
Даже сейчас такого рода демонстрация выглядит впечатляющей. Интересно, что исходники SHRDLU можно скачать, программа написана на LISP, есть даже какой-то современный визуализатор под Windows. Если вы откроете ее исходники, то вы увидите, что программа состоит из огромного количества хитроумных правил.
Когда читаешь эти правила, то понимаешь, насколько изощренная логика заложена в программу. Терри Виноград, по всей видимости, проводил много экспериментов, давая возможность разным людям общаться с этой системой. Мирок SHRDLU очень маленький: он может быть описан примерно 50 разными словами. И в рамках такого маленького пространства можно создать впечатление интеллектуального поведения у системы.
ключевые слова
«программа состоит из огромного количества хитроумных правил»zirix
20.11.2016 00:36Вот ее я приводил в пример к прошлой статье, но не мог вспомнить название.
Кстати:
SHRDLU — ранняя программа понимания естественного языка, разработанная Терри Виноградом в MIT в 1968—1970 годах.
buriy
20.11.2016 07:22В чём-то конечно CyberMind правы — подхода к ИИ два:
1) учить логический вывод, накрутить нечёткий вывод позже
2) учить сразу нечёткий вывод, логику добавить позже
Они пошли по пути 1. Пожелаем им удачи и запасёмся попкорном. CYCorp не удалось, может, хоть им удастся ;)LorDCA
20.11.2016 07:40Нет никакого логического или нечеткого выводов.
Все одновременно и проще и сложнее.
Есть оценочный вывод. Никаких или, или. Никакой жесткой или нечеткой логики. По сути логика это набор паттернов не противоречащих друг другу. И она поверх обычного мышления. И ей специально обучают.
Проблема создания ИИ в самих создателях. Слишком создатели о себе много думают. Типа душа там и все такое. :)
InFortis
21.11.2016 14:36Да, согласен с Вами по поводу деления. Мы развиваем наш ИИ в соответствием с онтогенезом. Вначале — строгие операции и примитивные действия, затем система усложняется.
InFortis
21.11.2016 14:35Не могу сказать, как мы отличаемся структурно от этой программы, не знаю, как она устроена. Но предметная область отличается. У нас в семантической сети категории, которыми оперирует человек (сейчас — семилетка).
Логика наших алгоритмов, работающих с семантической сетью, почти полностью соответствует процессам в психике. Подозреваю, что в этом тоже есть отличия от SHRDLU.
buriy
20.11.2016 07:33Почитал новые части дискуссии, придумал ещё один показательный тест.
Дети 7 лет уже неплохо умеют отвечать на вопросы на аналогию (хотя сложные вопросы всё же идут для 10+ лет — в связи с индивидуальностью развития когнитивной сферы, конечно же, а не принципиальной неспособностью отвечать на такие вопросы). Этот навык нужен для решения практических задач в том случае, когда легкодоступного ответа из памяти нет.
Возьмите любой тест на аналогии и напишите, что будет у вас. Для упрощения задачи, можно ограничиться более распространёнными словами.
стол: мебель = дом:?
паровоз: вагоны = конь:?
театр: зритель = библиотека:?
маленький: большой = мальчик:?
итд.InFortis
21.11.2016 14:39Дети 7 лет уже неплохо умеют отвечать на вопросы на аналогию (хотя сложные вопросы всё же идут для 10+ лет — в связи с индивидуальностью развития когнитивной сферы, конечно же, а не принципиальной неспособностью отвечать на такие вопросы).
Согласен, что часть детей и в семь лет способны решить эти тесты. Но, в среднем, этот навык формируется все же в начальной школе. По нашему мнению, работа с аналогией это операция, проводимая в рамках абстрактного мышления. У нашего семилетки его нет. Сейчас как раз работаем над ним для 12-ти летки.
Тест интересный. Если подвернется случай, воспользуемся. Спасибо.
elingur
16.11.2016 09:47путем прямого копирования структур и процессов психики человека
Интересно, как вы собираетесь копировать эмоции человека (без чего не может быть и речи о полноценном ИИ)?
С точки зрения обработки текста я не вижу ничего нового, скорее наоборот — все это прошлый век. Сейчас появились разве что новые технологии. Но тем не менее, дабы не быть голословным: можно ли посмотреть демо?InFortis
16.11.2016 12:18Мы копируем процесс возникновения эмоций. Он не очень сложный.
Демо есть 3х летки — https://youtu.be/lHovebnViTc, 7-ми летку по мере программирования будем выкладывать там же.napa3um
16.11.2016 12:26Выкладывать нужно не видео, а исходники или хотя бы доступ к облачному сервису, в котором пользователи могли бы потестировать ваши разработки вживую. Видео — это ваши фантазии о том, как должен выглядеть ваш бот, не более.
InFortis
16.11.2016 12:58Видео сделано с работающей системы. Исходники выкладывать не планируем — много ноу хау и это собственность компании. Доступ к системе даем потенциальным партнерам и инвесторам, на публичный пока нет ресурсов.
napa3um
16.11.2016 13:02Ваша компания похожа на развод (у МММ тоже видео делалось «с работающей системы», и сайт ваш настолько же «содержательный»), а тексты — на способ увеличить информационное присутствие, уж простите (уверен, что мнение отдельного «скептика-хейтера» вы сможете пережить). Посмотрим, какую воду нальёте в следующих статьях, на обладание какими сакральными тайнами сумеете намекнуть потенциальным инвесторам.
InFortis
16.11.2016 17:22Скептики, лично мне, нужны. Они не позволяют пойти не туда, особенно когда могут аргументировать свою точку зрения.
Инвесторам мы бы предпочли хороших партнеров для конкретных продуктов. Но да, финансовый ресурс позволил бы развивать технологию быстрее.
Cubicmeter
16.11.2016 17:27Например, если вы в книге Льва Толстого встретите фразу «Он распечатал письмо…», то для правильного понимания текста вы привлекаете категорию «19 век», и делаете вывод, что речь идет не о принтере.
Я не привлекаю категорию «19 век», встречая такую фразу. Всё совершенно не так. Я читаю роман, зная, что он о 19 веке. У меня с самого начала сформирован какой-то образ, какой-то подход к тексту. И когда я вижу «он распечатал письмо», эта фраза сама привязывается к этому образу, обретая смысл. А не наоборот.
Наличие высокой вероятности у такой связи, предполагающей на порядок меньшее расстояние в цепочке «doesn't fit»-«too small»-«suitcase», обусловлено опытом человека. Я, как и большинство, часто сталкивался с ситуацией, когда что-то не влезает в чемодан, так как он слишком мал. Отсюда и такая связь у меня.
Какая разница, как часто вы сталкивались с этой ситуацией? Вместо чемодана могло бы быть любое другое слово, хоть незнакомое. Смысл целых фраз приходит из их логики, а не из частотности употребления. «Не помещается» то, что больше, в то, что меньше.InFortis
16.11.2016 19:30Я не привлекаю категорию «19 век», встречая такую фразу. Всё совершенно не так. Я читаю роман, зная, что он о 19 веке. У меня с самого начала сформирован какой-то образ, какой-то подход к тексту. И когда я вижу «он распечатал письмо», эта фраза сама привязывается к этому образу, обретая смысл. А не наоборот.
Вы абсолютно правы. Если Вы читаете книгу и визуализируете прочитанное, как будто смотрите фильм, то открывание письма для Вас предъявляется визуально и никакой «19» век в этом не участвует. Я некоторые книги тоже так читаю. Но если визуализации нет, то вывод о том, что такое «распечатать письмо» вы можете сделать посредством некоторых понятий, позволяющих объяснить ситуацию. Для этого примера — «19» век. Это может быть «Лев Толстой», «Война и мир», «1812 г.» — но любая из этих категорий не допускает принтера, а предполагает конкретное действие по распечатыванию письма.
Какая разница, как часто вы сталкивались с этой ситуацией? Вместо чемодана могло бы быть любое другое слово, хоть незнакомое. Смысл целых фраз приходит из их логики, а не из частотности употребления. «Не помещается» то, что больше, в то, что меньше.
Понятие контекста относительно слов, которые незнакомы, по-моему, не применимо. Частота употребления понятий совместно увеличивает вероятность связи, которая используется в формуле. Логику тоже можно применить для анализа фразы. Может, я Вас лучше пойму, если Вы приведете пример фразы, о которой Вы говорите и где есть контекст.
zirix
16.11.2016 19:37приведете пример фразы, о которой Вы говорите и где есть контекст.
Как вам такой пример:
Куздра не поместилась в бакренок, потому что он(it) слишком большой.
InFortis
16.11.2016 19:54Как вам такой пример:
Куздра не поместилась в бакренок, потому что он(it) слишком большой.
Я, как скорее всего, человек, понял из этой фразы только что что-то куда-то не поместилось. Не вижу здесь ситуации контекста. Наш ИИ тоже спасует здесь.zirix
16.11.2016 21:16Не вижу здесь ситуации контекста.
В местоимении он/она/it.
Я, как скорее всего, человек, понял из этой фразы только что что-то куда-то не поместилось.
Не «что-то куда-то», а вполне конкретно что, куда и почему.
InFortis
17.11.2016 15:08Возможно у меня замылился взгляд. Если возможно, объясните, пожалуйста, ситуацию контекста в этом предложении.
zirix
17.11.2016 17:03Куздер не поместился в бакренок, потому что он слишком большой.
Теперь задаю вам вопрос: «кто большой?»
Это тоже самое что и:«The trophy doesn't fit into the brown suitcase because it's too large. What is too large?», только слова заменены на незнакомые.
Люди мой «тест» легко проходят, ваша система его не пройдет.
К тому же вы не совсем поняли смысл текстов винограда, которые цитируете.Cubicmeter
17.11.2016 17:38Спасибо, именно это я и имел в виду.
А если «куздера» поменять на «куздру» (как в вашей первой фразе), то человек без проблем поймет, что здесь какой-то подвох (так как «слишком большой» теперь может относиться только к бакренку): либо это какая-то шутка, либо для говорящего русский язык не родной.InFortis
18.11.2016 01:23Теперь понял, спасибо. Да, такую фразу первым способом ИИ не одолеет. У него для «куздра» и «бакренок» новые категории, у них нет связей (их вероятность равна нулю), следовательно, это не первый вид контекста (по нашей классификации).
Как я предполагаю, в этом случае человек привлекает, для того, чтобы понять, метод аналогии. Он знает, что если что-то не помещается куда-то, то это из-за того, что помещаемый объект слишком велик. По нашему взгляду, это второй вид контеста, когда для его разрешения необходимо привлечь новую, не представленную в предложении, категорию. Надеюсь, следующая статья объяснит наш подход.
Еще раз спасибо, красивый пример.
Cubicmeter
17.11.2016 17:57если визуализации нет, то вывод о том, что такое «распечатать письмо» вы можете сделать посредством некоторых понятий, позволяющих объяснить ситуацию. Для этого примера — «19» век.
Несомненно, такие ситуации бывают. Я знаю это благодаря тому, что такое привлечение дополнительных понятий бывает осознанным.
Как вам такой пример: я вижу на экране компьютера некий интерфейс, и щелкаю по нему, но ничего не происходит. Тогда я привлекаю понятие, или лучше сказать, воспоминание о том, что этот интерфейс изображен на скриншоте, и понимаю свою оплошность.
Но в тех ситуациях, когда это может происходить неосознанно — этого может не происходить вовсе, вот в чем штука. И пример с письмом — скорее из этого рода.
Кстати, насчет контекста и частоты употребления… скажите (без подсказок), что вам говорят слова «гилад шалит»?InFortis
19.11.2016 15:47Если я правильно Вас понял, то согласен с Вами, без того, что информация хоть как-то часто повторяется, первый вид контекста (по нашей типологии) не применим.
«Гилад шалит» для меня ничего не говорит. Я, здесь, могу или начать искать аналогии или пытаться применять другие способы понять.
А вот по части неосознанности — это как раз то, чем мы и занимаемся. Процессы, которые уже стали автоматизмами, протекающие вне сознания, мы разбираем и алгоритмизируем.
Ситуацию с письмом мы увидели именно так.
Но «гилад шалит» вызывает чувство чего-то знакомого)). Откуда это?

AlbertMHLT
17.11.2016 10:19Добрый день!
Может ли Ваша система проходить тесты на понимание текста, предназначенные для определения уровня изучающих английский язык в качестве иностранного?
Если да, то на какой уровень она успешно проходит их сейчас (приведите, пожалуйста, пример такого теста, если это возможно)?
Интересно узнать, сколько баллов Ваша система способна набрать в тесте на определение уровня понимания английского текста по ссылке:
http://englishpractice.ru/?p=4861
?InFortis
17.11.2016 15:05+1Большое спасибо за интересный метод, возьмем его на вооружения. До этого, как-то, прошли мимо. Отрабатывали понимание на текстах из https://simple.wikipedia.org/wiki/Main_Page.
Посмотрели тест по ссылке. Наша система ответит на 4-5 вопросов в которых речь идет о доступных для семилетки задачах, например, антонимах, сравнении слона и собаки. Остальные вопросы требуют понимания, свойственного гораздо более взрослому возрасту. В частности, перефразировка вероятностей события, разворачивание условия из простого предложения в сложноподчиненное, переформулировка с избеганием отрицания. Часть из этих процессов планируем реализовать в 12-ти летке.
Еще хочу отметить, что наш интерфейс не позволяет работать с этим тестом, цифра 4-5 это с учетом адаптации нашей системы под этот интерфейс. Кроме того, вопрос на антонимы мы себе зачли, т.к. он полностью описан алгоритмом, документация на него готово, но в цифре пока его нет.
И, кстати, наш лучший специалист по американскому английскому получил 80%))) Сейчас его троллим ))

jam31
17.11.2016 23:04Применяете ли Вы онтологии в семантической сети? Если да, то, возможно, Вам будет небезынтересен мой опыт. Я планирую повысить производительность логических рассуждений, применив открытый движок на C++, созданный нашим соотечественником.
InFortis
18.11.2016 13:35К сожалению, широко онтологии применить нам не удалось. Это сильно сэкономило бы программные ресурсы.
Мы видим информацию в психике структурированной, но не иерархичной. В этом мы расходимся с Курцвейлом. Для различных сфер жизни феномены запоминаются (хранятся в семантической сети) с различными концептуальными схемами.
Мы ожидаем большего присутствия онтологии в 12-ти летке, т.к. он вынужден интегрировать знания о науках, преподаваемых в школе. Эта информация, как раз, почти вся иерархична. Спасибо за ссылку, когда подойдем к этому вопросу — оценим, на сколько указанное решение нам может быть полезно.jam31
19.11.2016 16:53Говорят, что логические рассуждения «неестественны» для сознания в силу врождённых «hardware-ограничений», и люди по возможности стараются их избегать. Отсюда confirmation biases, интуиция, «подсознание» и прочая оптимизация. Значит ли это, по-Вашему, что онтологии плохо подходят для моделирования?
LorDCA
19.11.2016 18:04Плохо. Если выразить все в пару предложений.
1. Мы мыслим паттернами. С этим никто не спорит.
2. Мы используем семантические сети в мышлении. Тут тоже мало спорящих найдется.
3. Нет понимания как создаются новые паттерны. И онтологии этот вопрос не решают.
На этом все!
InFortis
19.11.2016 22:51По нашему мнению онтологии хороши там, где большие объемы созданной человеком и структурированной информации. Например, для описания категорий из науки, товаров, культурной сферы. Для взрослого человека они занимают свою нишу. Поскольку нынешнее наше решение воспроизводит ребенка, его психику, то мы вынуждены были описывать скорее категории быта, коммуникации, примитивной деятельности. Концептуальные схемы этих сфер сложны.
Для взрослого, думаю, онтологии позволят описать бОльшую часть знаний. В частности, профессиональная сфера, скорее всего, будет лучше всего описываться именно таким методом.

Prosolver
20.11.2016 14:27«За песчаной косой лопоухий косой пал под острой косой косой бабы с косой»
InFortis
21.11.2016 14:43+1Мощная фраза)))
Песчаную косу, острую косу и бабу с косой наш ИИ поймет правильно.
«Лопоухий косой» — если обучить его еще одному названию зайца.
Для того, чтобы правильно понял «Косой бабы» — нужно ему рассказать, что такое «косая баба». Учитывая редкость такой характеристики, то маловероятно, что мы его этому будем учить. Но в литературе такая характеристика встречается, поэтому обучиться на более поздних этапах.
StjarnornasFred
Первое, что пришло на ум — реклама, где «Я завтракала с президентом».
А вообще ведь реально: в одной и той же ситуации будет возможно сказать любую из этих фраз:
«Трофей не поместился в чемодан, потому что он слишком большой»
«Трофей не поместился в чемодан, потому что он слишком маленький»
InFortis
Да, реклама часто использует контекст. Не думаю, что у них есть семантическая сеть, описывающая связанность понятий пользователей, скорее рекламщики делают это интуитивно.
Kadr
Формально, по правилам русского языка, правильным будет второй вариант. Но люди понимают оба варианта, отсюда и постановка задачи для разработчика ИИ.