

В последние дни сентября в Амстердаме проходила конференция по графическим технологиям GTC EUROPE 2016. Профессор Юрген Шмибдхубер представлял свою презентацию, как научный директор IDSIA, швейцарской лаборатории, где он с коллегами занимается исследованиями в области искусственного интеллекта.
Главный тезис выступления — настоящий искусственный интеллект изменит все уже в скором времени. По большей части статья, которую вы сейчас читаете, подготовлена по материалам презентации профессора Шмидхубера.
Самым влиятельным открытием 20-го века считают процесс Габера-Боша: извлечение азота из воздуха для получения удобрения. В результате это привело к взрыву популяции в менее развитых странах. Для сравнения:
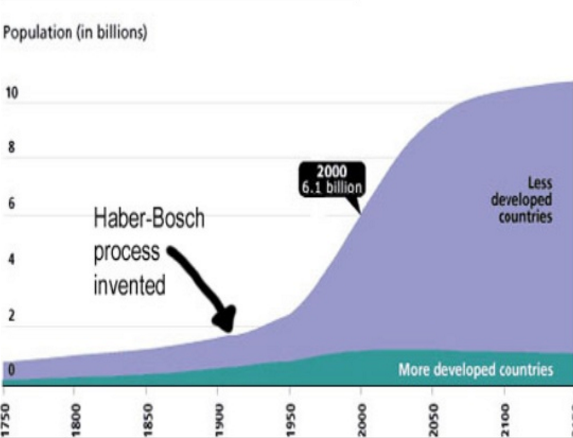
Впечатляющий скачок, а взрыв искусственного интеллекта в 21-м веке будет еще более внушительным по мнению Юргена Шмидхубера
Все началось с того, что Конрад Цузе в 1941-м представил первый работающий на общих микросхемах компьютер. Компьютеры становились все быстрее и дешевле с каждым годом. За 75 лет они подешевели в 1000 000 000 000 000 раз.
В 1987-м тезис дипломной работы Шмидхубера звучал примерно так: «первая конкретная разработка рекурсивного саморазвивающегося ИИ».
История глубинного обучения началась в 1991-м году. Отцом глубинного обучения Шмидхубер заслуженно считает Алексея Григорьевича Ивахненко. Без его методологии и систем управления не было бы и открытий в лаборатории профессора в Швейцарии.
В 1965-м году он опубликовал первые обучающиеся алгоритмы для глубоких сетей. Конечно, то, что мы привыкли сегодня называть «нейросетями», тогда даже не казалось таким. Ивахненко изучал глубинные многослойные перцептроны с функциями полиномиальной активации и прогрессирующее с количеством слоем обучение с регрессионным анализом. В 1971-м была описана сеть глубинного обучения с восемью слоями. Сегодня до сих пор используются находки того времени.
Получая обучающий набор входных векторов с соответствующей целью выходных векторов, слои с узлами дополнительных и мультипликативных нейронов растут с приращением и обучаются с помощью регрессионного анализа. После этого происходит удаление лишней информации с помощью проверочных данных, где используется регуляризация для отсеивания излишних узлов. Числа слоев и узлов в одном слое могут обучаться проблемозависимым способом.
Теперь о контролируемой обратной связи. Работы пионеров области:
- Непрерывная обратная связь вычислениях Эйлера-Лагранжа + Динамическое программирование, Брайсон 1960, Келли 1961;
- Обратная связь через правило цепи, Дрейфус, 1962;
- Современная ОС в редких дискретных похожих на нейросети (включая код Fortran-а) сетях, Линмаинма, 1970;
- Изменение весов контроллеров, Дрейфус, 1973;
- Автоматическая дифференциация могла показать ОС в любом дифференцируемом графе, Спилпеннинг, 1980;
- ОС в применении к нейросетям, Вербос, 1982;
- RNN-примеры, Вильямс, Вербос, Робинсон, 1980;
RNN — это рекурсивные нейронные сети с глубинным обучением. В 1991-м году профессор Шмидхубер создал первую сеть с глубинным обучением. Процесс неконтролируемой подготовки перед обучением для иерархической временной памяти выглядит так: стек RNN&rarrсжатие истории&rarrускорение контролируемого обучения. LSTM — long short-term memory — это разновидность нейросети. LSTM RNN сегодня широко применяются в производстве и исследованиях для распознания последовательностей данных в изображениях или видео. Примерно в 2010-м история повторилась: неконтролируемые FNN повсеместно заменились частично контролируемыми FNN.
На вход в сеть ИИ поступают сигналы разного типа: изображения, звуки, эмоции, возможно, — а на выходе системы получается движение мышц (у человека или робота) и другие действия. Суть работы в том, чтобы улучшать алгоритм — он развивается подобно тому, как тренируют моторику маленькие дети.
Метод LSTM был разработан в Швейцарии. Эти сети более совершенные и универсальные, чем предыдущие, — они готовы к глубинному обучению и разным задачам. Сеть родилась из-за любопытства автора, а теперь широко используется. Например, это функция голосового ввода Google Speech. Использование LSTM улучшило этот сервис на 50 процентов. Процесс обучения сети выглядел в данном случае так: множество людей наговаривали фразы для примера обучения. В начале обучения нейросеть не знает ничего, а потом, после того, как она слушает много отрывков, например, английского, то учится понимать его, запоминая правила языка. Позже сеть может делать переводы с одного языка на другой. Примеры использования — на изображении ниже.

Больше всего LSTM используется в Google, Microsoft, IBM, Samsung, Apple, Baidu. Этим компаниям нужны нейросети для распознания речи, изображений, задач машинного перевода, создания чат ботов и еще много-много чего.
Вернемся снова в прошлое: двадцать лет назад лучшим игроком в шахматы стала машина. Игровые чемпионы нечеловеческого происхождения появились в 1994-м — TD-Gammon в игре Backgammon. Обучающегося победителя создали в IBM. Для шахмат — тоже в IBM — сконструировали необучающегося Deep Blue. Это относится к машинному зрению.
В 1995-м робокар проехал из Мюнхена в Данию и обратно по общественным автобанам со скоростью до 180 км\ч без GPS. В 2014-м году также был 20-летний юбилей появления самоуправляемых машин в потоке на автостраде.
В 2011-м прошел конкурс дорожных знаков в Силиконовой долине. Во время него разработка лаборатории Шмидхубера показала результаты в два раза лучшие, чем человеческие, в три раза выше, чем ближайший искусственный участник соревнований и в шесть раз лучше, чем безнейронная штука FIRST (распознание визуальных паттернов). Такое используется в самоуправляемых автомобилях.
Были и другие победы.
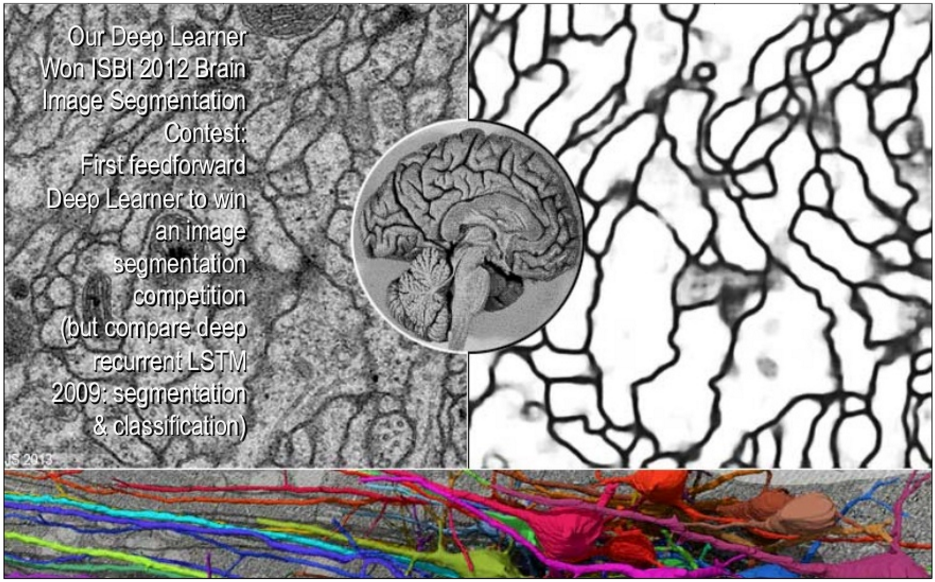
Аналогичная техника применима и в медицинских случаях. Например, распознание опасных предраковых клеток на ранней стадии митоза. Это значит, что один доктор сможет вылечить больше пациентов в единицу времени.
Упреждающая LSTM и магистральные сети — в каждом слое функция х+х, для обучения нейросетей с сотнями слоев.
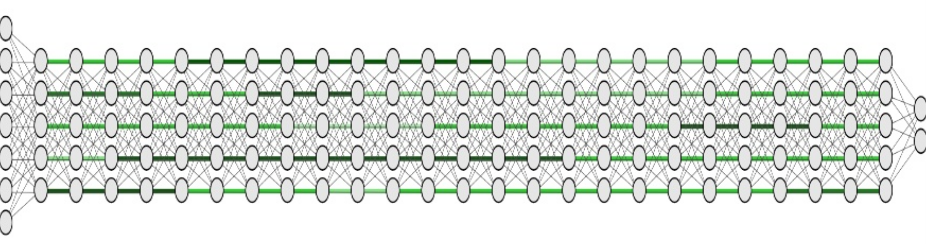
Лучшее сегментирование в сетях LSTM:
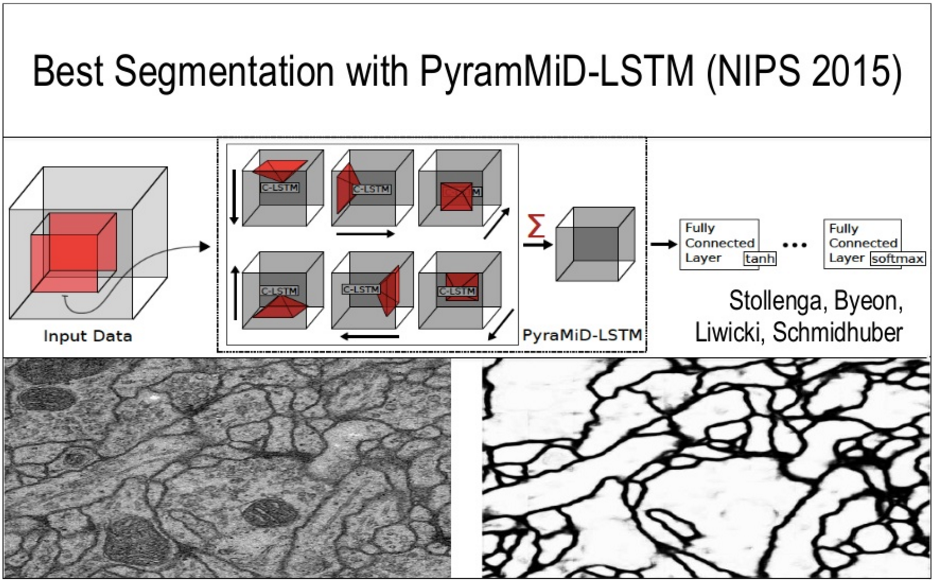
Студенты профессора создали библиотеку нейросетей с открытым кодом Brainstorm.
Тем временем роботы были заняты развитием мелкой моторики. А LSTM-сети научились завязывать узлы.

За чуть более, чем 20 лет, глубинное обучение прошло путь от заданий с, минимум, в 1000 вычислительных этапов (1991-1993) до упреждающих рекурсивных нейросетей с более чем 100 слоями (2015).
Все помнят, как Google купил DeepMind за 600 млн долларов. Теперь у компании целое подразделение, занимающееся задачами машинного обучения и ИИ. Первые сотрудники, основатели, DeepMind были выходцами из лаборатории профессора Шмидхубера. Позже в DeepMind перешло еще два доктора наук из IDSIA.
Еще одна работа профессора Шмидхубера по нахождению сложных нейроконтроллеров с миллионными весами была представлена в 2013-м на GECCO. Относится к поиску по сжатой сети.
В 1990-1991-х годах рекурсивное обучение визуального внимания на медленных компьютерах имело целью получить дополнительный фиксированный вход. В 2015-м — все тоже самое. В 2004-м проходил кубок роботов в лиге самых быстрых со скоростью 5 метров в секунду. В конкурсе было успешно использовано то, что Шмидхубер предлагал еще в 1990 — прогнозирование ожиданий и планирование с использованием нейронных сетей.
«Возрождение» 2014-2015 или как его называют в английском RNNAIssance (Reccurent Neural Networks based Artificial Intelligence), представляло собой уже обучение мышлению: теория алгоритмической информации для новых комбинаций усиленного обучения рекуррентных нейромоделей мира и контроллеров на основе RNN.
Интересную научную теорию приводит профессор в качестве объяснения феномена «веселья». Формально, веселье — это что-то новое, удивительное, привлекающее внимание, креативное, любопытное, сочетает в себе искусство, науку, юмор. Любопытство, например, используется в совершенствовании навыков человекоподобных роботов. Это занимает много времени. В ходе эксперимента робот учится ставить стаканчик на маленькую подставку. Изучается влияние внутренней мотивации и внешней похвалы на процесс обучения.
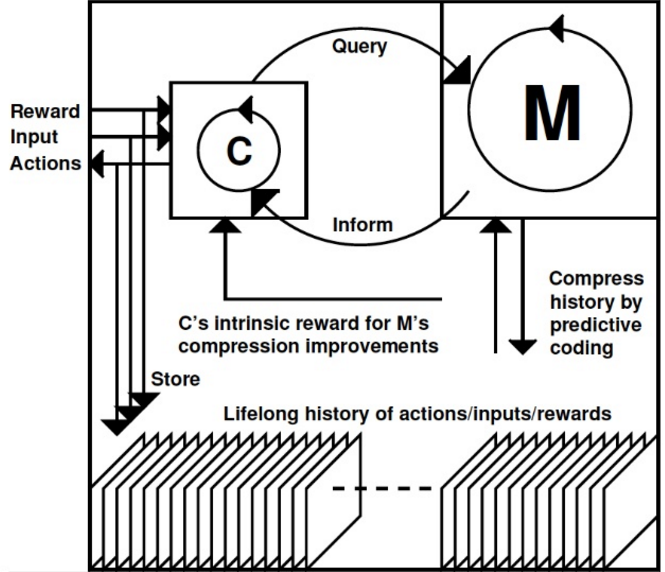
Знаете о PowerPlay? Он не только решает, но и постоянно придумывает проблемы на границе известного и неизвестного. Так, по нарастающей, тренируется решение общих задач путем постоянного поиска простейшей до сих пор нерешенной задачи.
Что будет дальше по мнению Шмидхубера: создание небольшого, похожего на животное (например, мартышку или ворону), ИИ который будет учиться думать и планировать иерархически. Эволюции понадобились миллиарды лет на создание таких животных и намного меньше времени на переход от них к человеческому существу. Технологическая эволюция намного быстрее натуральной.
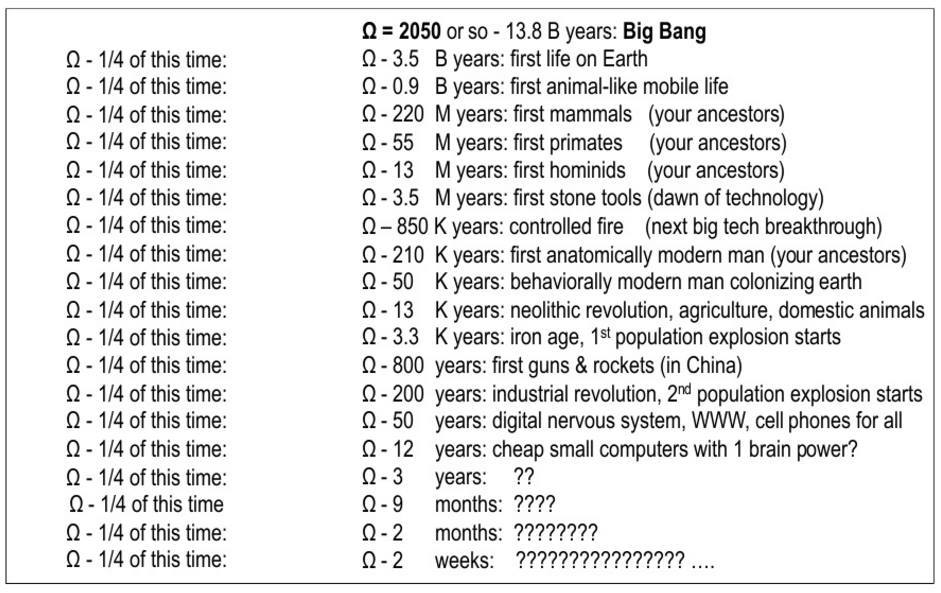
Несколько слов о прекрасном простом паттерне, открытом в 2014-м году. В нем идет речь об экспоненциальном росте в большинстве исторически важных событиях во вселенной с точки зрения человека.
Комментарий профессора по поводу научной фантастики:
Я предпочитаю называть сингулярность Омегой потому, что это как раз то, что Тейяр де Шарден говорил 100 лет назад и потому, что это звучит похоже на «О мой бог» В 2006-м я описал исторический шаблон который подтверждает, что 40 000 лет доминирующего положения Человека приведут к точке Омега за несколько следующих декад. Так, я показываю невероятно точный экспоненциальный рост, который описывает весь путь развития вплоть до Большого Взрыва. В нем — вся история, вероятно, самых важных события с точки зрения человека. Вероятность ошибки менее 10%. Впервые я заговорил об этом в 2014-м году.
Космос не дружественен к человеку в отличие от правильно спроектированных роботов
После презентации в Амстердаме в части вопросов и ответов был затронут момент, связанный с появлением так называемых роботов-журналистов или любых других моделей, способных выполнять работу многих людей. Ведущая интересовалась, стоит ли людям из «текстовой сферы» беспокоиться о присутствии искусственного интеллекта и его развитии. Профессор считает, что роботы не могут заменить человека, они созданы, чтобы помогать ему. И бороться с человеком они не станут, потому что имеют разные с ним цели. Интересно, что популярные фантастические фильмы интерпретируют тему неверно. Войны в реальной жизни ведутся между похожими существами — люди сражаются с другими людьми, а не с медведями, например. А вот, будет ли ИИ использоваться для «плохих военных вещей», это зависит от этики людей — так что это вопрос не про развитие ИИ.
Важно помнить истоки
В прошлом году журнал Nature опубликовал статью, она о том, что глубинное обучение позволяет вычислительным моделям, состоящим из множества слоев обработки, изучать представления данных на многих уровнях абстракции. Такие методы очень сильно улучшили положение вещей в сфере распознания речи, визуальных объектов и других областях, например, открытие лекарств и расшифровка генома. Глубокое обучение раскрывает запутанную структурность в огромных наборах данных. Для этого используются алгоритмы обратной связи — они указывают, как машина должна изменить свои внутренние параметры, которые используются для вычисления представления в каждом слое из представления в предыдущем слое. Глубокие сверточные сети стали прорывом в обработке изображений, видео, речи и звука, а рекуррентные сети пролили свет на последовательные данные такие, как текст и речь.
Вот какой критический комментарий дал Юрген Шмидхубер.
Машинное обучение — это наука о получении доверия. Общество машинного обучения выигрывает от правильных решений по «выдаче ответственности» верным людям. Изобретатель важного метода должен получить одобрение на изобретение этого метода. Далее другой человек, кто популяризует идею метода, также должен получить доверие на это. Это могут быть разные люди. Относительно молодая область исследований машинное обучение должна принять кодекс чести от более зрелых наук — например, математики. Что это значит. К примеру, если вы доказываете новую теорему используя известные уже методы, это должно быть четко и ясно. Ну, а если вы изобретаете что-то, что уже известно и узнали об этом по факту, то вы тоже должны четко упомянуть об этом, даже и позже. Поэтому важно ссылаться на все, что было придумано раньше.
Поделиться с друзьями