
Кэш – это комплексная система. Соответственно, под разными углами результат может лежать как в действительной, так и в мнимой области. Очень важно понимать разницу между тем, что мы ждем и тем, что есть на самом деле.
Давайте прокрутим полный оборот ситуаций.
Tl;dr: добавляя в архитектуру кэш важно явно осознавать, что кэш может быть средством дестабилизации системы под нагрузкой. Смотрите конец статьи.
Представим, что у нас есть доступ к базе данных, возвращающей курсы валют. Мы спрашиваем rates.example.com/?currency1=XXX¤cy2=XXX и в ответ получаем plain text значение курса. Каждые 1000 запросов к базе данных для нас, допустим, стоят 1 евроцент.
Итак, теперь мы хотим показывать на нашем сайте курс доллара к евро. Для этого нам нужно получить курс, поэтому на нашем сайте мы создаём API-обёртку для удобного использования:
Например, так:
<?php // побудем немного ближе к народу :)
function get_current_rate($currency1, $currency2) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
return $rate;
} else {
return (float) $rate;
}
}И в шаблонах в нужном месте вставляем что-нибудь вроде:
{{ get_current_rate("USD","EUR")|format(".2f") }} USD/EUR(ну или даже
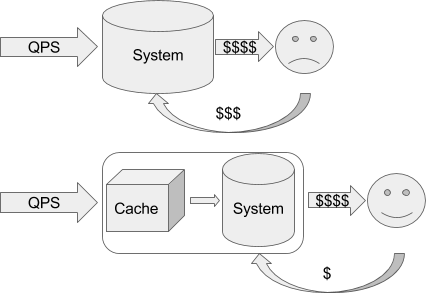
<?=sprintf(".2f", get_current_rate("USD","EUR"))?>, но это прошлый век).Наивная имплементация делает самое простое, что можно придумать: на каждый запрос от пользователя спрашивает удалённую систему и использует ответ напрямую. Это означает, что теперь каждые 1000 просмотров пользователями нашей страницы стоят для нас на копейку больше. Казалось бы – гроши. Но вот проект растёт, у нас уже 1000 постоянных пользователей, которые каждый день заходят на сайт и просматривают по 20 страниц, а это уже 6 евро в месяц, что превращает сайт из бесплатного во вполне уже сопоставимый с платой за самые дешевые выделенные виртуальные серверы.
Вот тут на сцену выходит его величество Кэш
Зачем нам спрашивать курс для каждого пользователя на каждое обновление страницы, если для людей эта информация, в общем-то, не нужна так часто? Давайте просто ограничим частоту обновления до, например, раз в 5 секунд. Пользователи, переходя со страницы на страницу, всё равно будут видеть новое число, а мы платить будем в 1000 раз меньше.
Сказано – сделано! Добавляем несколько строчек:
<?php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
// ссылка на https://cloud.google.com/appengine/docs/php/memcache/
$memcache = new Memcache;
$memcache->addServer("localhost", 11211);
$rate = $memcache->get($cache_key);
if ($rate) {
return $rate;
} else {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
return $rate;
} else {
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
}
}Это самый главный аспект кэша: хранение последнего результата.
И вуаля! Сайт снова становится для нас почти бесплатным… До конца месяца, когда мы обнаруживаем от внешней системы счет на 4 евро. Конечно, не 6, но мы ожидали намного большей экономии!
К счастью, внешняя система позволяет посмотреть начисления, где мы видим всплески по 100 и более запросов каждые ровные 5 секунд в течение пиковой посещаемости.
Так мы познакомились со вторым важным аспектом кэша: дедупликацией запросов. Дело в том, что как только значение устарело, между проверкой наличия результата в кэше и сохранением нового значения, все пришедшие запросы фактически выполняют запрос к внешней системе одновременно.
В случае с memcache это можно реализовать, например, так:
<?php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
$memcache = new Memcache();
$memcache->addServer("localhost", 11211);
while (true) {
$rate = $memcache->get($cache_key);
if ($rate == "?") {
sleep(0.05);
} else if ($rate) {
return $rate;
} else {
// Создаём запись, только один сможет это сделать, остальные уйдут спать
if ($memcache->add($cache_key, "?", 0, 5)) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
return $rate;
} else {
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
}
}
}
}И вот, наконец, потребление сравнялось с ожидаемым — 1 запрос в 5 секунд, расходы сократились до 2 евро в месяц.
Почему 2? Было 6 без кэширования для тысячи человек, мы же всё закэшировали, а сократилось всего в 3 раза? Да, стоило просчитать пораньше… 1 раз в 5 секунд = 12 в минуту = 72 в час = 576 за рабочий день = 17 тысяч в месяц, а ещё не все ходят по расписанию, есть странные личности заглядывающие поздней ночью… Вот и получается, в пике вместо сотни обращений одно, а в тихое время — по-прежнему запрос почти на каждое обращение проходит. Но всё равно, даже в худшем случае счёт должен быть 31?86400?5 = 5.36 евро.
Так мы познакомились с еще одной гранью: кэш помогает, но не устраняет нагрузку.
Впрочем, в нашем случае люди приходят в проект и уходят и в какой-то момент начинают жаловаться на тормоза: страницы замирают на несколько секунд. А еще бывает под утро сайт не отвечает вообще… Просмотр консоли сайта показывает, что иногда днём запускаются дополнительные инстансы. В это же время скорость выполнения запросов падает до 5-15 секунд на запрос — из-за чего это и происходит.
Упражнение для читателя: посмотреть внимательно предыдущий код и найти причину.
Да-да-да. Конечно же, это в ветке
if ($rate === FALSE). Если внешний сервис вернул ошибку, мы не освободили блокировку… В том смысле, что "?" так и остался записан, и все ждут когда он устареет. Что ж, это легко исправить: if ($rate === FALSE) {
$memcache->delete($cache_key);
return $rate;
} else {Кстати, это грабли отнюдь не только кэша, это общий аспект распределённых блокировок: важно освобождать блокировки и иметь таймауты, во избежание дедлоков. Если бы мы добавляли "?" вообще без времени жизни, всё б замирало при первой же ошибке связи с внешней системой. К сожалению, memcache не предоставляет хороших способов для создания распределённых блокировок, использование полноценной БД с блокировками на уровне строк лучше, но это было просто лирическое отступление, необходимое просто потому, что на эти грабли наступили.
Итак, мы исправили проблему, вот только ничего не изменилось: всё равно изредка начинались тормоза. Что примечательно, они совпадали по времени с информационным бюллетенем от внешней системы о технических работах…
Ну-ка ну-ка… Давайте сделаем краткую передышку и пересчитаем, что мы насобирали уже сейчас, что должен уметь кэш:
- помнить последний известный результат;
- дедуплицировать запросы, когда результат еще или уже не известен;
- обеспечивать корректную разблокировку в случае ошибки.
Заметили? Кэш должен обеспечивать пункты 1-2 и для случая ошибки! Изначально это кажется очевидным: мало ли что случилось, отвалился один запрос, следующий обновит. Вот только что произойдёт, если и следующий тоже вернет ошибку? И следующий? Вот у нас пришло 10 запросов, первый захватил блокировку, попробовал получить результат, отвалился, вышел. Следующий проверяет – так, блокировки нет, значения нет, идём за результатом. Обломался, вышел. И так для каждого. Ну глупость же! По хорошему 10 пришло, один попробовал — все отвалились. А уже следующий пусть попробует заново!
Отсюда: кэш обязан уметь какое-то время хранить отрицательный результат. Наше наивное исходное предположение по сути подразумевает хранение отрицательного результата 0 секунд (но передачу этого самого отрицания всем, кто уже ждёт его). К сожалению, в случае с Memcache реализация нулевого времени ожидания весьма проблематична (оставлю как домашнее задание въедливому читателю; cовет: используйте механизм CAS; и да, в AppEngine можно использовать и Memcache и Memcached).
Мы же просто добавим сохранение отрицательного значения с 1 секундой жизни:
<?php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
$memcache = new Memcache();
$memcache->addServer("localhost", 11211);
while (true) {
$flags = FALSE;
$rate = $memcache->get($cache_key, $flags);
if ($rate == "?") {
sleep(0.05);
} else if ($flags !== FALSE) {
// Если ключа нет, тип не меняется, иначе будет число,
// и мы вернём любое значение из кэша, даже false.
return $rate;
} else {
if ($memcache->add($cache_key, "?", 0, 5)) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
// Здесь мы можем задать отдельный срок жизни отрицательного значения
$memcache->set($cache_key, $rate, 0, 1);
return $rate;
} else {
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
}
}
}
}Казалось бы, ну теперь-то уже всё, и можно успокоиться? Как бы не так. Пока мы росли, наш любимый внешний сервис тоже рос, и в какой-то момент начал иногда тормозить и отвечать аж по секунде… И что примечательно – вместе с ним начал тормозить и наш сайт! Причем снова для всех! Но почему? Мы же всё кэшируем, в случае ошибок запоминаем ошибку и тем самым отпускаем всех ожидающих сразу, разве нет?
…А вот и нет. Внимательно посмотрим на код еще раз: запрос ко внешней системе будет исполняться столько, сколько позволит
file_get_contents(). На время исполнения запроса все остальные ждут, поэтому каждый раз, когда кэш устаревает, все потоки ждут исполнения главного, и получат новые данные только, когда они поступят.Что ж, мы можем вместо ожидания, добавить ветку
else{} у условия вокруг memcache->add… Правда, стоит, наверное, вернуть последнее известное значение, да? Ведь мы кэшируем ровно затем, что мы согласны получить устаревшие сведения, если нет свежих; итак, еще одно требование к кэшу: пусть подтормаживает не более одного запроса.Сказано – сделано:
<?php
function get_current_rate($currency1, $currency2) {
$cache_key = "rate_".$currency1."_".$currency2;
$memcache = new Memcache();
$memcache->addServer("localhost", 11211);
while (true) {
$flags = FALSE;
$rate = $memcache->get($cache_key, $flags);
if ($rate == "?") {
sleep(0.05);
} else if ($flags !== FALSE) {
return $rate;
} else {
if ($memcache->add($cache_key, "?", 0, 5)) {
$api_host = "http://rates.example.com/";
$args = http_build_query(array("currency1"=>$currency1, "currency2"=>$currency2));
$rate = @file_get_contents($api_host."?".$args);
if ($rate === FALSE) {
// Мы не меняем последнее успешное значение, пусть смотрят на
// устарелые сведения. При желании, поведение можно изменить.
$memcache->set($cache_key, $rate, 0, 1);
return $rate;
} else {
// Ставим срок жизни бесконечным для _stale_ ключа, но можем и задать
// какой-нибудь большой: например, минуту, тем самым ограничив
// срок жизни устаревших сведений.
$memcache->set("_stale_".$cache_key, (float) $rate);
$memcache->set($cache_key, (float) $rate, 0, 5);
return (float) $rate;
}
} else {
// Если нет актуальных данных, и не мы их обновляем —
// вернём значение из копии данных, для которых не указан срок жизни.
// Если и их нет, то вернём false, что соответствует обычному поведению.
return $memcache->get("_stale_".$cache_key);
}
}
}
}Итак, мы снова победили: даже если тормозит внешний сервис, подтормаживает не более одной страницы… То есть как бы среднее время ответа сократилось, но пользователи всё равно немного недовольны.
Примечание: обычный PHP по умолчанию пишет сессии в файлы, блокируя параллельные запросы. Чтобы избежать этого поведения, можно передать в session_start параметр read_and_close либо принудительно закрывать через session_close сессию после совершения всех необходимых изменений, иначе тормозить будет не одна страница, а один пользователь: так как скрипт, обновляющий значение, будет блокировать открытие сессии другим запросом от того же пользователя. При исполнении на AppEngine по умолчанию включено хранение сессий в memcache, то есть без блокировок, поэтому будет проблема не так заметна.
Так вот, пользователи всё равно недовольны (ох уж эти пользователи!). Те, кто проводят времени больше всех на сайте, всё равно замечают эти короткие зависания. И их нисколько не радует осознание факта того, что так случается редко, и им просто не везёт. Придётся для данного случая сделать требование еще более жестким: никакие запросы не должны ждать ответа.
Что же мы можем сделать в такой постановке вопроса? Мы можем:
- Попытаться исполнить трюки «исполнение после ответа», то есть если мы должны обновить значение – регистрируем хендлер, который это сделает после исполнения всего остального скрипта. Вот только это сильно зависит от приложения и окружения исполнения; самый надёжный способ — использование
fastcgi_finish_request(), требующий настройку сервера через php-fpm (соответственно, недоступен для AppEngine).
- Сделать обновление в отдельном потоке (то есть выполнить
pcntl_fork()или запустить скрипт черезsystem()или ещё как-то) – опять же, может сработать для своего сервера, иногда даже работает на некоторых shared-хостингах, где не сильно озаботились безопасностью, но, разумеется, не сработает на сервисах с параноидальной безопасностью, то есть AppEngine не подходит.
- Иметь постоянно работающий фоновый процесс для обновления кэша: процесс должен с заданной периодичностью проверять, не устаревает ли значение в кэше, и если срок жизни подходит к концу, а значение требовалось за время жизни кэша – обновляет его. Мы обсудим этот момент чуть позднее, когда устанем уже от нашего бедного сайта с курсом валюты и перейдём к более весёлым материям.
По сути поддержание данных во всегда горячем состоянии – задача чуть более сложная, чем просто несколько строчек PHP-кода, поэтому для нашего простого случая нам придётся смириться с тем, что какой-то запрос будет регулярно «задумываться» (важно: не случайный, а какой-то; то есть не random, а arbitrary). Применимость этого подхода всегда важно примерять к задаче!
Итак, наш поставщик данных растёт, но не все его клиенты читают хабр, а потому они не используют правильного кэширования (если используют его вообще) и в какой-то момент начинают выдавать огромное количество запросов, из-за чего сервису становится плохо, и эпизодически он начинает отвечать не просто медленно, а очень медленно. До десятков секунд и более. Пользователи, конечно, быстро обнаружили, что можно нажать F5 или иначе перезагрузить страницу, и она появляется моментально – вот только страница снова начала упираться в бесплатные пределы, так как постоянно начали висеть процессы, просто ожидающие внешний ответ, но потребляющие наши ресурсы.
В числе прочих побочных эффектов участились случаи показа устаревшего курса. [Мда… в общем, представьте, что мы сейчас говорим не про наш случай, а про что-нибудь более сложное, где устаревание видно невооруженным глазом :) на самом деле, даже в простом случае обязательно найдётся пользователь, который заметит такие совершенно неочевидные косяки].
Смотрите, что получается:
- Пришел запрос 1, данных в кэше нет, так что добавили маркер '?' на 5 секунд и пошли за курсом.
- Спустя 1 секунду пришел запрос номер 2, увидел маркер '?', вернул данные из stale записи.
- Спустя 3 секунды пришел запрос номер 3, увидел маркер '?', вернул stale.
- Спустя 1 секунду маркер '?' устарел, несмотря на то, что запрос 1 всё еще ждет ответа.
- Спустя еще 2 секунды пришел запрос номер 4, маркера нет, добавляет новый маркер и отправляется за курсом.
- …
- Запрос 1 получил ответ, сохранил результат.
- Пришел запрос X, получил актуальный ответ из кэша 1-го вопроса (а когда пришел тот ответ? На момент запроса, или момент ответа? –, этого никто не знает…).
- Запрос номер 4 получил ответ, сохранил результат – причем снова непонятно, был ли этот ответ более новый или более старый...
Разумеется, тут мы должны задать нужный нам таймаут через
ini_set("default_socket_timeout") или воспользоваться stream_context_create… Так мы приходим к еще одному важному аспекту: кэш должен учитывать время получения значений. Общего решения для поведения нет, но, как правило, время кэширования должно быть больше чем время вычисления. В случае если время вычисления превышает время жизни кэша, кэш неприменим. Это уже не кэш, а предвычисления, которые следует хранить в надежном хранилище.Итак, давайте подведём промежуточный итог. В бытовом понимании кэш:
- заменяет большинство запросов на получение уже известного ответа;
- ограничивает число запросов к получению дорогих данных;
- делает время запросов невидимыми для пользователя.
В реальности же:
- заменяет некоторые запросы из окна жизни кэша на запомненные значения (кэш может потеряться в любой момент, например, из-за нехватки памяти либо экстравагантных запросов);
- пытается ограничить число запросов (но без специальной имплементации ограничения частоты исходящих запросов, реально можно обеспечить только характеристики типа «максимум 1 исходящий запрос в один момент времени»);
- время исполнения запроса видимо только некоторым пользователям (причем распределены «счастливчики» отнюдь не равномерно).
Кэш предполагает «эфемерность» хранящихся данных, в связи с чем системы кэширования вольны обращаться со временем жизни вообще и с самим фактом запроса на сохранение данных:
- кэш может быть потерян в любой момент времени. Даже наши маркеры блокировки исполнения '?' могут быть потеряны, если параллельно еще 10 тысяч пользователей гуляет по сайту, все сохраняя что-то (зачастую время последнего обращения на сайт) в сессию, которая лежит на том же кэш-сервере; после того как маркер потерян («кэш отравлен»), следующий запрос опять начнёт процедуру обновления значения в кэше;
- чем быстрее исполняется запрос в удалённой системе, тем меньше запросов будет дедуплицировано в случае отравления кэша.
Таким образом, просто применяя кэш, мы зачастую закладываем мину отложенного действия, которая обязательно взорвется — но не сейчас, а в будущем, когда решение обойдётся значительно дороже. Рассчитывая производительность системы, важно считать без учета сокращения времени исполнения от кэширования положительных ответов, иначе мы улучшаем поведение системы в спокойное время (когда сache hit ratio максимален), а не во время пиковой нагрузки / перегруженности зависимостей (когда обычно и случается отравления кэша).
Рассмотрим простейший случай:
- Мы смотрим на систему в спокойном состоянии, и видим среднее время исполнения 0.05 сек.
- Вывод: 1 процесс может обслужить 20 запросов в секунду, значит, для 100 запросов в секунду достаточно 5 процессов.
- Вот только если время обновления запроса возрастает до 2 секунд, то получается:
- 1 процесс занят обновлением (в течение 2 секунд);
- в течение этих 2 секунд у нас доступно только 4 процесса = 80 запросов в секунду.
И вот под большой нагрузкой наш кэш отравлен, и запросы кэшируются не на 5 секунд, а на 1 секунду только, а это означает, что у нас постоянно заняты 2 запроса (один исполняет первый запрос, второй начинает обновлять кэш через секунду, пока первый еще работает), и остаточная ёмкость для обслуживания сокращается до 60 запросов в секунду. То есть эффективная ёмкость от (исходя из среднего) 6000 запросов в минуту резко проседает до ~3600. Что означает, что если отравление наступило на 5000 запросах в минуту, до тех пор, пока нагрузка не упадёт с 5000 до 3000 система нестабильна. То есть любой (даже пиковый!) всплеск трафика потенциально может вызвать длительную нестабильность системы.
Особенно прекрасно это смотрится, когда после новостной рассылки с какими-либо новыми функциями практически одновременно приходит волна пользователей. Эдакий маркетологический хабраэффект на регулярной основе.
Всё это не означает, что кэш нельзя или вредно использовать! О том, как правильно применять кэш для улучшения стабильности системы и как восстанавливаться от вышеупомянутой петли гистерезиса, мы поговорим в следующей статье, не переключайтесь.
Комментарии (33)

yellow79
29.11.2016 11:41-3А почему нельзя создать «демона» который будет обновлять данные в кеше каждые 5, 10, 30 секунд (в зависимости от времени суток или величина нагрузки или по какой-то иной логике), а пользвательские запросы всегда будут брать данные из кеша?

datacompboy
29.11.2016 11:46+2Можно. Про это есть в статье.

uniqm
30.11.2016 16:33Только в статье описано почему это вредно, когда демон на PHP! Как там говорят, «Демон на PHP, Карл!» =)
Конечно он у вас сворует процесс и т.д. А если на Go/C/Crystal и тд демон? Он ни процессов PHP, ни время процессора, ни оперативки, ни сил и времени не будет отнимать.
Человека выше заминусили совсем зазря, ИМХО.datacompboy
30.11.2016 16:36Простите, мы точно говорим об одной и той же статье? Можно циатату?
uniqm
30.11.2016 17:11В конце статьи разбор с простым примером, где часть процессов PHP «висят» и не выполняют полезную работу.
datacompboy
30.11.2016 17:24+1Прочитайте еще раз. Речь идёт не об отдельном обновляющем демоне, а о том, что вместо 100 запросов в секунду мы обрабатываем 1 запрос 2 секунды, и не можем обрабатывать остальные так же быстро.
Это относится к поведению обработчиков при внезапном «утяжелении» запросов к зависямостям. Неважно кто это — php/go/c. Да даже на асме, если мы внезапно начали промахиваться мимо кеша на границе линии (так как злой пользователь загрузил картинку не 800*600 а 799*599), эффективная производительность проседает неожиданно и на порядки.
Ну даже если у нас многопоточный обработчик на Си, у нас точно так же ограниченное число тредов, которые могут обрабатывать запросы, и если один из них становится занят надолго — эффективная пропускная способность падает. И нет, мы не можем просто запустить еще один тред вместо висящего (равно как вредно у PHP cтавить максимум 200 процессов, чтобы «всё равно обрабатывать пока медленные висят», так как дополнительный обработчик занимает ресурсы — он не только «спит, ожидая ответа», он еще занимать память, диск, сокеты, файловые дескрипторы и т.п., и сложно заранее сказать когда и какой из таких ресурсов исчерпается и с какой стороны прилетит по голове.uniqm
30.11.2016 19:51Перечитал =) Я больше говорил о Вашей архитектуре работы с кэшем из PHP. И комментатор выше я думаю так же подумал.
Почему Вы не стали в PHP-приложении ТОЛЬКО ЧИТАТЬ значения из кэша? Ну и добавили бы минимум логики в приложение, мол получили значение из кэша — радуемся, а не получили — не рисуем компонент, вставляем дефолтное значение(если имеет место быть) и тд. А вот отдельный скрипт по крону запускается(или демон на постоянку с засыпанием), идет в чужой сервис и пишет итоги в кэш. PHP-приложение знать не знает, откуда в кэше данные. Поделили ответственность, создали задел на будущее и тд. В такой архитектуре я не вижу причин появления проблем из поста. С моих глаз у Вас борьба с ветряными мельницами: затолкали конкурентную запись с чтением в логику приложения с кучей клиентов/тредов и давай воевать там =)datacompboy
30.11.2016 20:01uniqm
30.11.2016 20:49Можно, автору все можно =) Я походу не осилил замысел статьи и/или не попал в целевую аудиторию статьи.

amarao
29.11.2016 17:28-2У меня к статье есть одна претензия: почему 1000 запросов в БД почему-то начало стоить денег?
datacompboy
29.11.2016 18:39Потому, что все хотят кушать. Заменим запрос курса валют на запрос стоимости билета на самолет, например, и цены изменятся на порядок. Хотя это всё те же запросы в БД…

disc
29.11.2016 23:27+2$args = ["currency1=".urlencode($currency1), "currency2=".urlencode($currency2)]; $rate = @file_get_contents($api_host."?".join("&", $args));
http_build_query в гугл еще не завезли?)

ioannup
29.11.2016 23:38+1Пусть меня заминусуют, но я в упор не вижу, когда $flags !== FALSE
datacompboy
29.11.2016 23:41При memcache->get() либо:
— возвращает прочитаное значение ключа и возвращает связанные с ними флаги.
— возвращает FALSE в случае ошибки или отсутствия ключа
то есть если значения нет, то флаги не меняются; если значение есть — флаги это число, соответственно тип сменится с boolean на integer, следовательно, $flags станет точно не равно FALSE.
(сравнение !== учитывает типы, то есть 0 == FALSE, но при этом 0 !== FALSE)
akubintsev
30.11.2016 12:27+1Пример мне кажется немного надуманным, действительно правильнее использовать под такую задачу крон. Но с академической точки зрения очень хорошая иллюстрация грабель.
Более уместным был бы пример, как мне кажется, тяжелых запросов в базу данных, которые зависят от данных профиля пользователя (например выдача новостей по интересам)datacompboy
30.11.2016 12:38Это второй виток петли — вам кажется, что это нагляднее только потому, что первый виток уже очевиден.
Могу только апеллировать к грустному опыту наблюдений как народ проходит по этим граблям раз за разом даже для таких простых случаев.
Второй и третий витки в работе. Чукча не писатель, чукча инженер, поэтому это требует много времени, терпение-с плиз.akubintsev
30.11.2016 12:46+1Конечно всегда найдутся еще грабли)
Но я хочу сказать, что если кто-то решает задачу из статьи прямо как написано, то это архитектурно не правильно. Задача веб сервера в том, чтобы как можно быстрее отработать request-response, а не мудрить сложную логику по вытягиванию данных и разруливанию race condition. Зачем множить это на кучи потоков, когда достаточно выделить лишь один, который будет заниматься конкретной задачей по актуализации данных в кеше.datacompboy
30.11.2016 13:17Важно понимать, что это всего лишь паттерн: есть запрос, для него есть внешние данные, которые должны быть актуальны, но допускают некоторое отставание по времени.
Мы легко можем заменить во всей статье веб-фронтенд бэкенд API запросом, которому для вычисления нужна некая оценка курса. Или проверка факта что мы вообще сейчас выполняем эти запросы. Или еще что — миллион случаев, когда это вполне разумно сделать именно кешированием здесь и сейчас.
И несмотря на то, что для простого веб-фронтенда это действительно оверкилл, очень часто это реалии — начиная от shared hosting'ов где нет крона вообще (впрочем, выше уже писали, что я просто не умею настраивать несуществующие вещи), и заканчивая просто синдромом молотка (это когда всё кажется гвоздями, когда в руках молоток) у начинающих.
Собственно, из-за того, что уже несколько раз встречал синдром молотка, я и попытался описать в области максимально близкой для тех, кому это важно понять, принять и начать жить дальше уже иначе.

wispoz
30.11.2016 13:02+1Развивая тему про новостей по интересам.
Сейчас подумал, ведь чисто теоритически можно составить примерную карту заходов пользователя, и на основании этого прогноза подготавливать кэш на данный момент?
Для всех не залогиненных пользователей показывать 'стандартный кэш новостей на даный момент'.datacompboy
30.11.2016 13:21Цитата из статьи:
Иметь постоянно работающий фоновый процесс для обновления кэша: процесс должен с заданной периодичностью проверять, не устаревает ли значение в кэше, и если срок жизни подходит к концу, а значение требовалось за время жизни кэша – обновляет его.
Да, на этом этапе это было перебором, поэтому вопросы организации хранения значений в кеше в принципе за скобками (даже замена LRU на статистические оценки могут дать определённые преимущества, вот только всегда можно создать такую нагрузку на систему, которая отравит и такой кеш, а потому это становится не важно для оценки наихудшего сценария).
wispoz
Это жесть какая то… Зачем каждый раз дергать внешний сервис, когда можно на крон повесить агента который обновлял бы 1 запись в базе, а уже все запросы формирования цены или просто вывода валюты брались из базы, и рядышком писать последнее обновление валюты 1 минуту назад или 3?
savostin
Просто пример выбран неправильно.
Замените file_get_contents на что-то другое, синхронное, длительное и с ошибками.
Впрочем, и в общем случае лучше такие операции выносить в cron.
datacompboy
Синхронное длительное и с ошибками это следующая часть.
Здесь про легкое быстрое и простое, где не сразу наступаешь на грабли…
Разве что да, стоило сказать что показываются разные пары валют — но это усложняло наглядность расчетов.
datacompboy
Как ни странно, описанная ситуация (правда, не для курсов валют) реальна: я её встречал десятки раз в жизни. И все шаги эволюции кэшестроения тоже.
Да, можно повесить демона в простейшем случае. И в сложнейшем тоже — об этом в следующей части.
Кстати, представьте, что показывается не одна пара, а для каждого пользователя своя. Запросы стоят каждый, таскать все пары получится слишком накладно…
zuborg
Кеширование индивидуальных данных будет малоэффективным, раз ими может пользоваться малое кол-во запросов.
Кроме того, сделать один SELECT на 100к строк, и сделать 100к SELECT-ов по одной строке тоже сильно отличаются по нагрузке.
Статический поллинг горячих (не всех, а именно часто используемых) данных (с последующей записью в кеш) все-таки самый эффективный способ, если критично важно уменьшить нагрузку на источник данных.
Стоит также упомянуть, что блокировки тоже реализуются множеством способом — чем дальше от программы (как с использованием внешнего мемкеша, например) — тем больше задержки и накладные расходы. В пределах сервера все же лучше использовать SysV или хотя бы fcntl. Не говоря уже о разного типа мютексах или, для php, соответствующих модулях, где используется разделяемая память.
datacompboy
— Мы не знаем заранее, какие используются, особенно, когда пользователи могут поменять поведение в любой момент.
Но по закону Парето 80% запросов можно упихать в 20% кеша… Реальное распределение различается от случая к случаю. В случае с валютами, пары USD/RUR и EUR/RUR (+ обратные) скорее всего будут покрывать 80% случаев :)
— Хорошо, когда можно сделать SELECT на 100к строк. А еще лучше просто держать локальную реплику. Вот только при интеграции со внешними системами зачастую надо использовать тот API, какой есть.
— Да, рефреш кеша отдельным демоном это хорошо, об этом я писал в статье, и обязательно разверну в следующей части.
Крайне важно помнить, что если дать человеку сразу сложное решение, он спросит «нафига так сложно?» и сделает как ему кажется — просто и неправильно. И так пока не подорвётся.
Эта статья — ответ на вопрос, всплывавший многократно, почему кеш — не панацея, и вообще делает не то, что вы хотите. Если он применим в конкретном случае — хорошо. Но это совсем не очевидно, и при всей «очевидности» зачастую совсем не так.
— Статья совсем не о блокировках, и потому мы можем обсудить это в комментариях при желании — или вообще, напишете свою статью! Или я могу пройтись по вариантам — но только когда дойдут руки/ноги. Сказать можно много, вот только времени мало.
Напомню, что в статье мягко подразумевалось исполнение на appengine, так что это НЕ один сервер, а потому все способы блокировок, заточенные на single-server не имеют смысла.
wispoz
Тогда плюсую, хотя и не могу) Если бы вы написали это в начале статьи, вопросов бы к вам небыло. А так спасибо.
datacompboy
Не понимаю, если честно. В начале статьи вполне себе сказано, что у нас «есть доступ к базе» и показан API, как именно доступ есть.
Или что, если слова «база» то сразу SQL?
wispoz
Это вы точно мне ?:)
datacompboy
Это я отвечаю тому, кто про «написали в начале стастьи» высказался :)
А уж кто из вас — я не знаю. Мы с моими меня вполне себе решаем такие вопросы единолично ;)
corr256
потому что автор знает только как настроить lamp, cron для него из области фантастики :)
datacompboy
Только и исключительно :)