
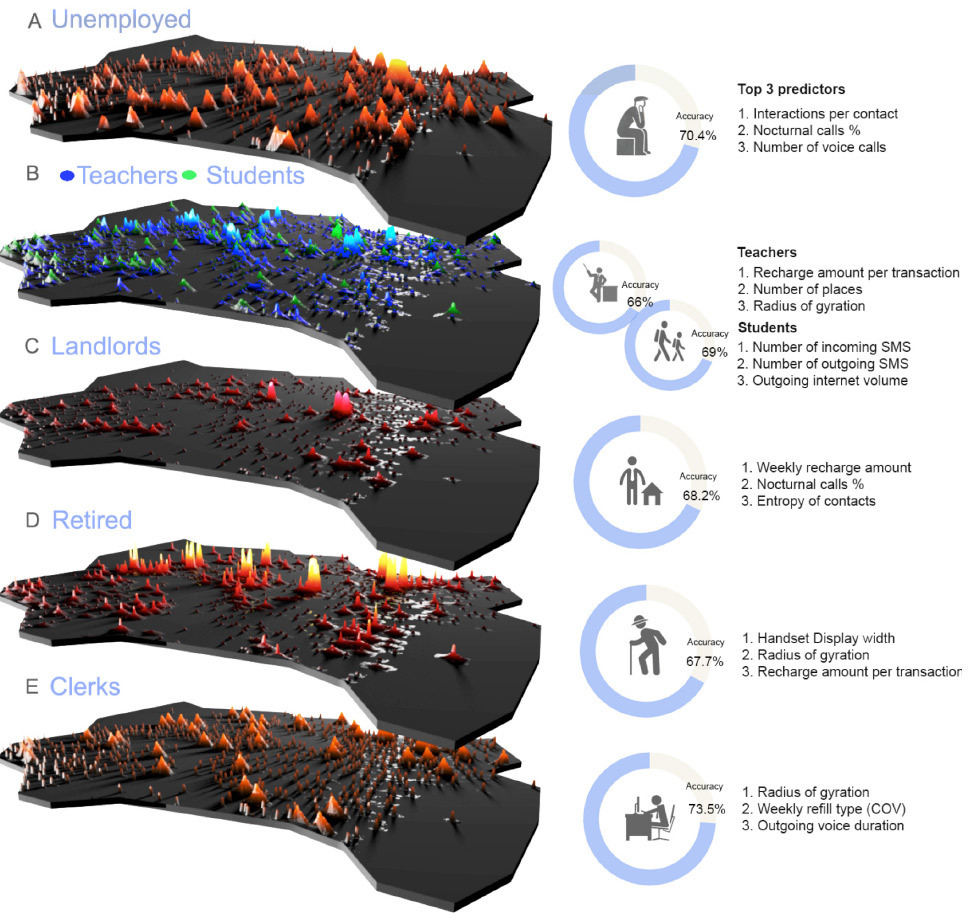
Индикаторы использования сотовой связи офисными сотрудниками, безработными, пенсионерами, учителями и студентами. Например, нейросеть определила для офисных сотрудников такой специфический индикатор, как большая длительность исходящих звонков
Благодаря социальным сетям и метаданным сотовой связи специалисты получили удобный и достаточно точный инструмент для изучения общества. Некоторую информацию люди публикуют в соцсетях сознательно, а часть важных данных выдают непроизвольно. Скажем, анализ анонимных метаданных сотовой связи показывает трафик на дорогах, скорость движения автомобилей, образование пробок, пассажиропотоки общественного транспорта. Это довольно логичные варианты дата-майнинга. А вот группа учёных из Telenor Group Research, MIT Media Lab, Flowminder Foundation и Стокгольмской школы экономики нашла весьма нестандартный вариант. Исследователи доказали, что по логам сотовой связи можно предсказывать… занятость. Довольно точно определяются безработные и представители ещё 17 родов занятий.
По информации учёных, это первое в мире исследование такого рода, когда безработных или профессию человека вычисляют на индивидуальном уровне с помощью глубинного обучения по логам сотовой сети. Раньше исследователи пытались предсказать только общий уровень безработицы по мобильным данным, но не профессии конкретных людей.
Исследователи подчёркивают, насколько важно иметь точную статистику безработных в обществе. Это важный экономический индикатор для изучения рынка труда, который помогает строить экономические прогнозы и управлять экономикой. Хотя избыток свободных трудовых ресурсов приятен для работодателей, но государство обычно ставит целью снизить безработицу ниже определённого уровня.
Узнать точную информацию о безработных тяжело. Для этого требуется периодически проводить масштабные социологические опросы. В некоторых странах фактический уровень безработицы сильно превышает показатель официально зарегистрированных в органах служб занятости.
Такие опросы отнимают немало времени и ресурсов. Например, в США действительно постоянно проводят такие опросы в домохозяйствах и публикуют статистику. В менее развитых странах из-за дороговизны опросов их проводят нерегулярно и с недостаточным охватом. Теперь исследователи нашли альтернативный вариант, который кардинально решает проблему.
Сотовые телефоны сейчас есть даже у бомжей, поэтому анализ метаданных обеспечивает практически полный охват трудоспособного населения во многих странах (в целом мобильники есть у более 50% населения Земли). О таком охвате социологи могут только мечтать. Инженеры показали, что метаданные сотовой сети обеспечивают достаточный пространственный охват и точность во времени, чтобы проводить эффективный дата-майнинг.
Беспрецедентный охват и точность метаданных сотовой сети в прошлые годы учёные использовали для вычисления вспомогательных индикаторов уровня бедности, неграмотности, оценки численности населения, миграции и распространения вирусных эпидемий. На индивидуальном уровне метаданные сотовой сети помогают предсказать социально-экономический статус человека, уровень дохода, его демографические характеристики и тип личности. Теперь дошло дело и до статуса занятости.
Исследователи применили модель глубинного обучения на массивном наборе данных, полученных в одной бедной южноазиатской стране. Для обучения программы использовали результаты опроса 200 000 человек в домохозяйствах, проведённого местным оператором сотовой связи. Люди сообщали о своём статусе занятости и профессии, выбирая из 18 видов занятий.
Кроме того, для глубинного обучения взяли мобильные логи за срок шесть месяцев 76 000 из этих 200 000 опрошенных человек. Информацию тщательно анонимизировали, программа не имела доступа к номерам телефонов, именам абонентов, содержимому разговоров и текстовых сообщений. Естественно, имея такой доступ в стиле СОРМ, можно профилировать людей практически со стопроцентной точностью. В данном случае ставилась задача провести научное исследование не нарушая права человека.
Из мобильных логов исследователи выделили переменные трёх типов: финансовые (сумма пополнения счёта, расходы на связь, частота пополнения, соотношение между максимальной и минимальной суммой пополнения счёта и др.), перемещения по местности (домашний район/сота, энтропия мест посещения, радиус инерции сечения, количество посещённых мест и др.) и социальные функции (количество разговоров с контактом, энтропия контактов, продолжительность разговора, количество SMS, объём интернет-трафика, количество MMS, количество и продолжительность видеозвонков, частота использования дополнительных услуг оператора и др.).
Модель со всеми переменными протестировали на нескольких алгоритмах, в том числе GBM (gradient boosted machines), RF (random forest), SVM (support vector machines) и kNN (K-nearest neighbors). По итогу была составлена многослойная нейросеть. Точнее, 18 моделей для каждого вида профессии (включая безработных). Обучение и тестирование осуществлялись с распределением данных 75% и 25%.
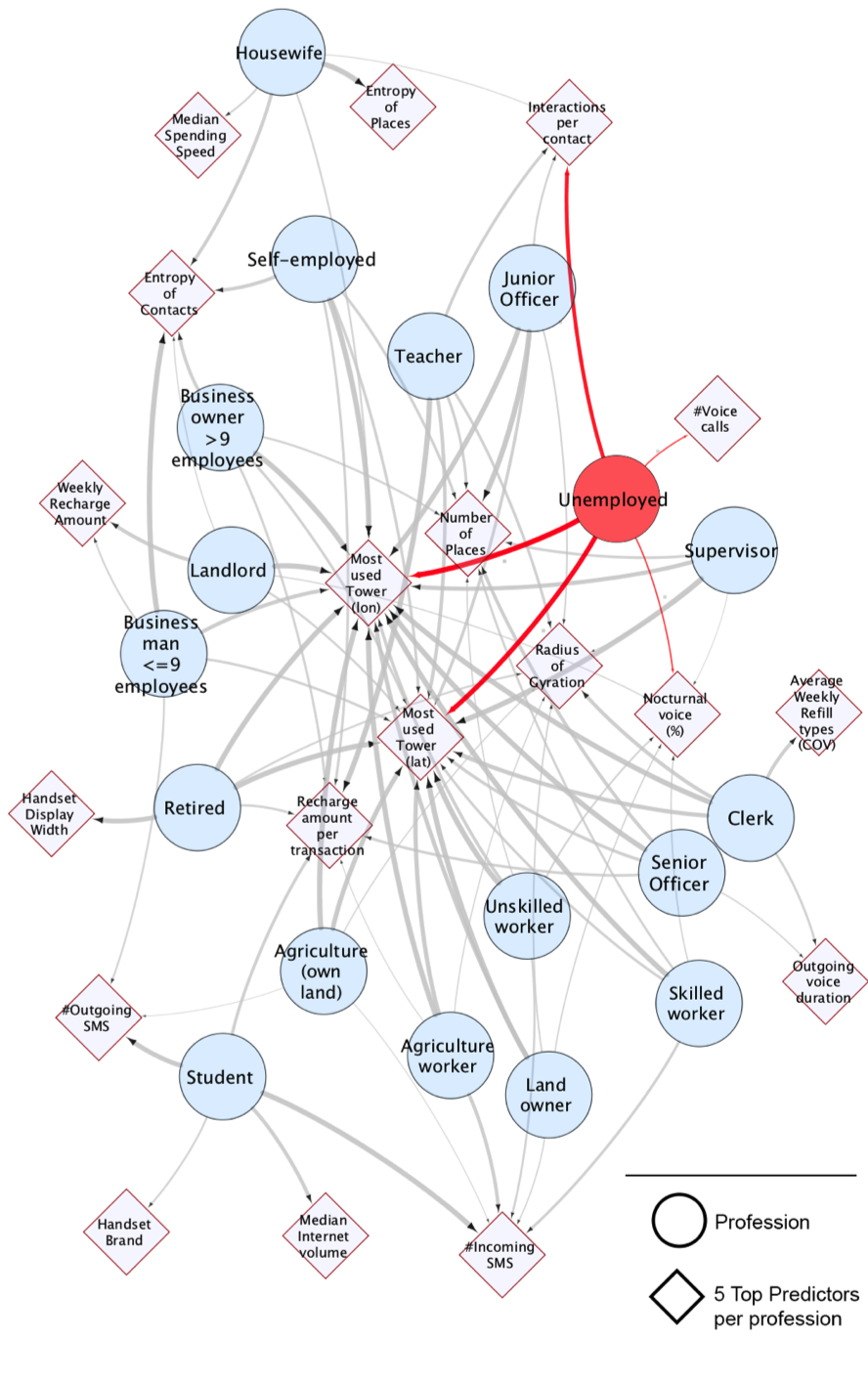
Результаты показали, что нейросеть лучше всего определяет офисных сотрудников (клерков). По использованию мобильной связи они выдают себя с точностью 73,5%. Сложнее всего определить по метаданным сотовой сети квалифицированных сотрудников (61,9%). Средний показатель по всем профессиональным группам составил 67,5%. Как и офисные сотрудники, безработные определяются тоже очень хорошо с вероятностью 70,4%.
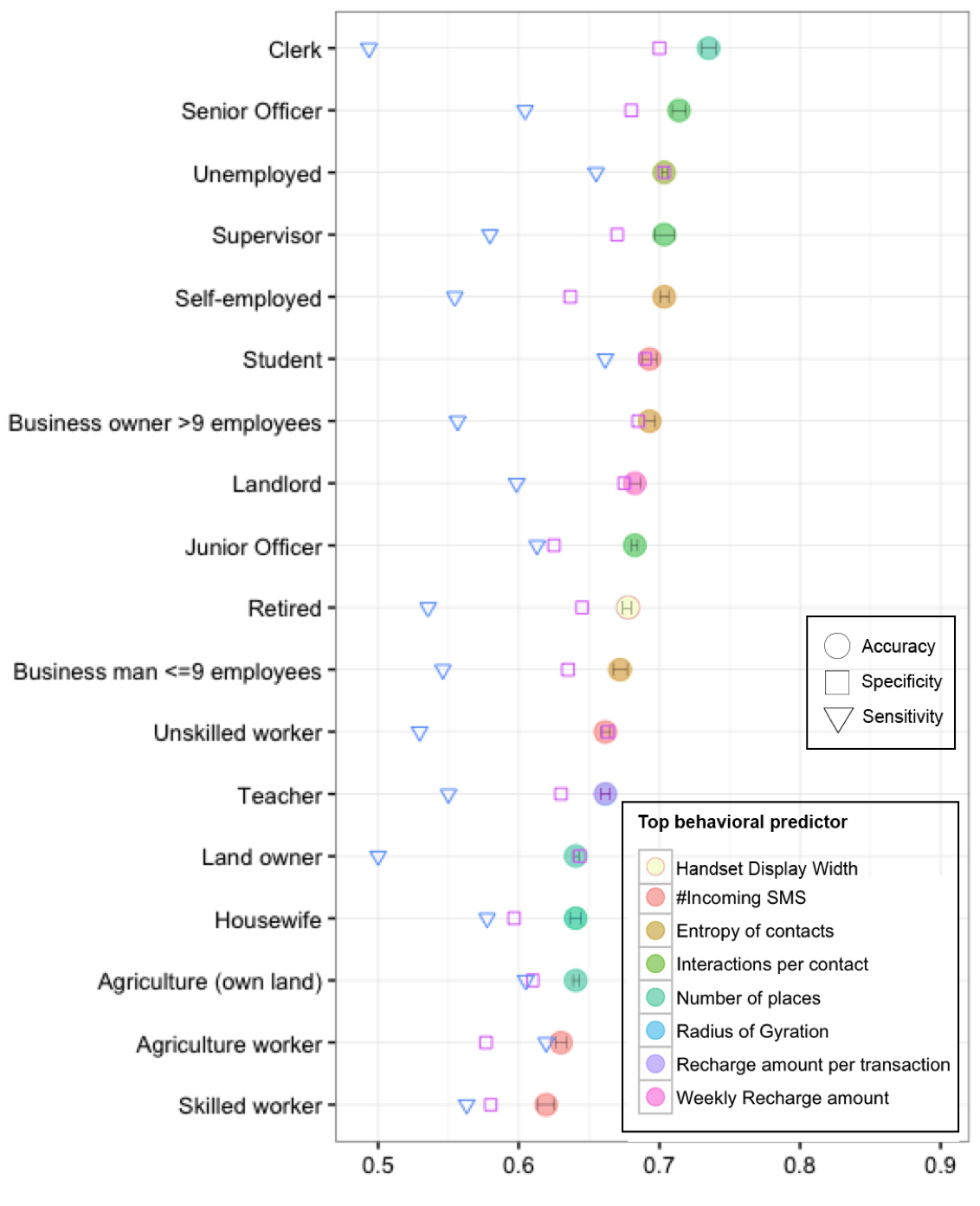
Наверняка эта научная работа найдёт применение в практических программах для дата-майнинга. Кстати говоря, если кто-то получит информацию об изменении уровня занятости за 1?2 недели до появления официальной статистики в США, то может неплохо заработать на бирже. Так что у сотрудников операторов сотовой связи появляется вариант для небольшой «халтурки», если они не боятся сесть в тюрьму за использование инсайдерской информации.
В странах, где ввели или собираются ввести налог на тунеядцев, такая нейросеть поможет пополнять бюджет. Будет выявлять незарегистрированных безработных, которые укрываются от налоговой инспекции. По предполагаемой профессии человека можно ещё таргетировать рекламу.
Научная статья опубликована 12 декабря 2016 года на сайте препринтов arXiv (arXiv:1612.03870) и пока не получила экспертную оценку.
Комментарии (50)

Vnuchok
22.12.2016 16:08«Они следят за мной с помощью своей аппаратуры!»))))






dimkss
22.12.2016 16:09Да все просто. Тут и нейросетей не надо.
Синий — значит студент или учитель. Красный — владелец собственности. И т.д.thatsme
23.12.2016 03:38Наконец-то общество становится цивилизованным. А раньше вот дифференциации
штановтрафика не было! Дикарями были…

AntonSor
23.12.2016 12:46+1Общество, не имеющее цветовой дифференциации метаданных, не имеет цели (с)
fivehouse
22.12.2016 16:53+1Достаточно неважные звонки делать с «грязной» симкой, которую бесплатно раздают на вокзалах всем желающим (и зарегенным фиг знает на кого) и вся эти огромная дата идет туда где и должна быть.

rfvnhy
22.12.2016 17:43+3«запороть» исследования значительно проще, именно поэтому там всего и 70%…
1. Кто-то использует свой сотовый телефон в качестве рабочего. Иногда еще и И-Нет раздает, да еще и всему офису. Ну и вконтакт/… использовать для связи по работе — то же бывает вижу такое…
2. Я вот сейчас (судя по нахождению симок) нахожусь примерно в 3-4 местах одновременно (в тч передвигаюсь), иногда звоню сам себе и тд и тп
А всего лишь для родителей купил сим-карты оформив на себя…
3. И еще множество подобных факторов, влияющих на статистику…
это как с з/п, есть средняя, но медианная дает больше информации…alsii
22.12.2016 19:08+4А всего лишь для родителей купил сим-карты оформив на себя…
Это если смотреть регистрационные данные. А если применить описанные методы, то сразу видно, что это три разных человека.
rfvnhy
22.12.2016 22:19Вы не учитываете, что SIMками можно иногда и обмениваться! =D
В общем там все не так просто. У меня несколько симок. Разных операторов.
Не имея объединенных данных сложно понять почему я то месяцами использую одну только на входящие, вторую на исходящие и не использую еще 3-4.
А через время начинаю иногда использовать «запасные» и совсем перестаю включать или использовать на исходящие основную…
В общем брать таких людей как я в статистику очень опасно. Результат окажется сильно искаженным, причем частично преднамеренно с моей стороны…
stanislavkulikov
23.12.2016 16:08+1Справедливости ради нужно сказать, что таких людей единицы. У подавляющего большинства моих знакомых номера не менялись уже лет 5-7.

sim31r
23.12.2016 17:13Результат окажется сильно искаженным
1% странных пользователей не исказят результат при всем желании, да и это исследование теоретическое, просто показали возможность нейронных сетей. Часто меняют сим карты, по моим наблюдениям, девочки школьницы или студентки, говорят много и могут поменять симку чтобы поболтать пару часиков с подругой на другом операторе. Но это и не важно, так как мгновенно засвечивается IMEI телефона, координаты, телефон вызываемый и еще по мелочам.

DistortNeo
22.12.2016 18:20+2С помощью того же дата-майнинга с очень высокой вероятностью определяется принадлежность двух разных сим-карт одному человеку.
alsii
22.12.2016 19:12+1Угу… и пополнять счет желательно в разных городах. И телефон с левой симкой включать через полчаса после выключения телефона с "не левой" предварительно отъехав в произвольном направлении на несколько км. В общем анализ big data иногда позволяет делать удивительные выводы.

tumikosha
25.12.2016 03:28Смена симок не помогает, сигнатура-телефона постоянныя.
Но даже если будете 2 телефона иметь, все равно вас сматчат по 3-м точкам






unxed
22.12.2016 18:19То есть, на целых 20,4% эффективнее подбрасываемой монетки?
APLe
22.12.2016 19:47+3Монетка позволяет выбрать один вариант из двух.
А тут с вероятностью >50% определяется, к какой из 18 групп принадлежит человек, то есть, в этой ситуации случайный выбор давал бы всего около 5% верных ответов.
(На самом деле, скорее всего, к какой из 19 — думаю, есть ещё большая группа «кто-то непонятный»).
BigBeaver
22.12.2016 20:31+2В статье говорится про 18 моделей. Она точно не просто расставляет вероятность для каждого типа?
dimm_ddr
23.12.2016 11:25Используем softmax от вывода и получаем определение принадлежности к группе. Ну то есть результат тривиально приводится к виду, в котором случайный выбор дает 5% точности. С другой стороны, в предложенном мной варианте могут несколько поменять вероятности, но это не будут кардинальные изменения скорее всего.
BigBeaver
23.12.2016 12:04+1Лично мне совершенно не очевидна эквивалентность 18 бинарных классификаторов одному 18-выходному. Еще, кстати, отдельный вопрос, что у этих 18 на выходе — не равны ли они по отдельности киданию слегка разцентрованной монетки?
p.s. я вполне допускаю, что вы можете быть правы, но без доаолнительных данных и выкладок делать выводы не спешил бы.dimm_ddr
23.12.2016 17:02Я не говорил про эквивалентность 18 бинарных классификаторов одному 18-выходному. Я говорил что ваш вариант:
В статье говорится про 18 моделей. Она точно не просто расставляет вероятность для каждого типа?
тривиально приводится к варианту одной модели возвращающей 1 вариант (или массив отсортированный по вероятностям). А уже для этой модели вероятность угадать случайно кардинально меньше 50%.
BigBeaver
23.12.2016 19:43Для этих утверждений нет данных.
А уже для этой модели вероятность угадать случайно кардинально меньше 50%.
Это верно, но мне не очевидно, что вероятность «не случайной» по указанному методу сильно выше. Вот я кинул 18 монеток (с разной развесовкой) по 100 раз (чтобы получить 18 вероятностей) и отсортировал…
Еще раз: вы вполне можете быть правы, но мне это не очевидно.dimm_ddr
26.12.2016 16:24Это действительно неочевидно, и даже больше — я и сам могу ошибаться. Монетки не сработают из-за бинарности ответа, слишком много будет одинаковых вариантов. Но это обходится если взять например кубик или еще какой-нибудь генератор случайных чисел. Смысл в том, чтобы получить вес для каждого из 18 вариантов. После этого мы можем взять максимум из них и получить генератор одного из 18 вариантов. То есть добавлением простой функции от 18 генераторов получаем генератор на 18 вариантов. Остается только два вопроса — равновероятны ли все 18 вариантов и как распределены правильные ответы. В любом случае генератором случайных чисел получить для 18 вариантов вероятность в 50% выглядит нереальным, разве что в вырожденном случае когда правильные ответы находятся только в двух категориях поровну и мы бросаем монетку только для них.
BigBeaver
26.12.2016 16:36Не уверен, что вы поняли мою мысль.
Есть два варианта:
1 — мы имеем 18 моделей, каждая из которых говорит «этот человек скорее вариант N чем все остальные» и угадывает с вероятностью 70% — это одно. Каждую из 18 моделей можно заменить «монеткой со смещенным весом». далее работает ваш алгоритм.
2 — мы имеем модель которая говорит, что «этот человек — вариант N с вероятностью 70%, а самма вероятностей для остальных вариантов — 30%».
Очевидно, что эти описания не эквивалентны. А вот насколько первая модель эффективнее брасания неравновероятного кубика — вопрос открытый (тк вероятность для каждой модели из 18 не очень высока (по сравнению с 50%), и ни одна из них не выше 50%).
Так вот, я рискну предположить, что обьединение 18 моделей по вашему адгоритму будет лучше кубика не более, чем каждая из моделей в отдельности лучше монетки. При этом я утверждаю, что бинарность монетки не является проблемой, тк можно кинуть ее 10, 100 и более раз, получив вещественную вероятность (которую потом можно подать на вход вашего алгоритма).

nickName0
22.12.2016 21:13+1Теперь тунеядцы будут звонить исключительно через интернет-мессенджеры, чтобы не попасть в статистику.
— Речь не только о звонках, сколько о регистрации местоположения сотового (необходимой для обеспечения абонента связью, в т.ч.).
Использование мессенджеров _никак_ не влияет на собираемую т.о. статистику.
Прочесть статью весьма интересно, т.к. есть и комментарии (в конце статьи), что позволяют взглянуть на описываемое с других ракурсов. И благодаря этому получить общую картину, что будет ближе к действительности.
«Будет выявлять незарегистрированных безработных, которые укрываются от налоговой инспекции»
— Сколько безработных не знал (и сам иногда бываю таковым, кстати), никто из них, по имеющейся у меня информации, и не думал как-то регистрироваться в налоговой.
Задача налоговиков — собирать поборы (называемые «обязательный безвозмездный платёж в пользу гос-ва»).
И как это связано с занятостью?
Пойму, если речь именно о налоге на тунеядство.
У реально безработных (кто не оформлен официально, и не ездит, работая на повременке), м.б. и шабашки.
Зная, что такое мат.статистика, хочется сделать замечание (автору статьи), что позволяет себе весьма вольготно использовать отдельные понятия.
Как пример:
«Обучение и тестирование осуществлялись с распределением данных 75% и 25%.»
Речь, как полагаю, о величинах доверительной вероятности (альфа) и 1-альфа.
Какое распределение используют?
Это — вопрос из числа главных.
Здесь-же — об этом ничего не говорится.
И, технические детали:
есть у меня программа, нетмонитор, что ведёт лог тех БСок (базовых станций), где регится мой сотовый.
Так вот, есть такое событие, как Cell reselection. Это когда сотовый перерегистрируется на другой БСке, сигнал от которой более мощный (т.е. связь с абонентом будет получше).
Этих смен БСок м.б. несколько за 1 минуту (даже когда мобильник неподвижен).
Причём, не всегда это (речь о новых БС) ближайшие.
Так-что, не фиксируя мощность принимаемого сигнала (от сотового), весьма ненадёжно делать заключение о неподвижности мобильной станции.
А если будете фиксировать, это уже будет попыткой, мягко выражаясь, шпионажа (за конкретным лицом).
Попробуйте предъявить ему такие данные, и он (наблюдаемый объект) запросит у вас, например, решение суда, одобрившего такой шпионаж. Сможете эти данные предоставить?
Если нет, то за факт шпионажа, скорее всего, прийдётся отвечать старшему той группы, что проводила такую разведку.
У нас есть такой закон, как конституция. Где есть разные статьи, например, 23, 24,
Ознакомьтесь, и поймёте, кто должен будет
1) идти лесом (культурно выражаясь);
2) платить компенсацию (за нарушение прав и свобод, гарантированных основным законом).
Это — если гражданину попробуют что-то предъявить (например, «охотники за тунеядцами»), основываясь лишь на журналах опСоСа (ОПератора СОтовой Связи).
Regis
22.12.2016 23:35+3Обучение и тестирование осуществлялись с распределением данных 75% и 25%.
Почти наверняка тут речь идет о разбиении набора данных на учебный и тестовый.Vjatcheslav3345
23.12.2016 11:28Вот если рассказать о такой системе депутатам они, ошалев от радости, быстренько «поправят» законы — печальный прецедент уже имеется — это когда им про интернет рассказали:)…
(населению придётся вспоминать — каково это — жить в героическую «эпоху Штирлицев»).

ChiefMate
22.12.2016 21:23+1Использую две сим-карты, одна — корпоративная, на каждом новом месте работы новая, вторая — личная, и ей более десяти лет. Контакты на обеих — не пересекаются.
Судя по первой, я явно клерк-трудоголик. По второй — скорее, пенсионер, а то и, прости господи, housewifedimm_ddr
23.12.2016 11:47Теоретически по метаданным можно связать эти две симки с хорошей вероятностью, если вы используете их в одном телефоне или таскаете оба телефона одновременно.
stanislavkulikov
23.12.2016 16:21Вы телефоны вместе носите? Перемещения входят в стандартные метаданные. Так что по перемещениям можно их связать.
ChiefMate
23.12.2016 23:15Вместе, бывает, ношу, но редко. Скажем так, по выходным и вечерам, когда с супругой, беру личный, а не рабочий. Днём в будние, когда сам — наоборот, обычно только с рабочим.
Это я не беру в расчет третью симку, которая установлена в старом китайфоне, который используется в качестве навигатора и лежит обычно в бардачке машины (но, тоже, бывают исключения) ;)
Ermako
30.12.2016 17:06Для того, чтобы правильно оценивать значимость результатов, стоило начать с описания аудитории. 76 тысяч человек из страны Южной Азии с низким уровнем дохода. Бангладеш или Непал, судя по всему.
proton17
Юрий Владимирович Андропов на том свете прослезился...