

Алексей Еремихин ( alexxz )
Я хочу навести порядок в головах, чтобы люди поняли, что такое Hadoop, и что такое продукты вокруг Hadoop, а также для чего не только Hadoop, но и продукты вокруг него можно использовать на примерах. Именно поэтому тема — «С чего начать внедрение Hadoop в компании?»
Структура доклада следующая. Я расскажу:
- какие задачи я предлагаю решать с помощью Hadoop на начальных этапах,
- что такое Hadoop,
- как он устроен внутри,
- что есть вокруг него,
- как Hadoop применяется в Badoo в рамках решения задач с первого пункта.

Хранение данных. На самом деле, никому не нужно хранить данные, всем нужно их читать, вопрос только — сколько времени вам потребуется для того, чтобы прочитать эти данные, если они были записаны год-два назад. Задача чтения архивов данных. В следующих слайдах буду рассказывать про эти задачи по очереди.

Первая задача — хранение архивов. Данные нужно хранить долго, чтобы уметь их читать. Нужно хранить год, два, три. Нужно предполагать, что за год, два, три откажет железо (может отказать диск, сервер), а данные нельзя потерять.
Объемы данных растут. Вот, по примеру группы BI в компании Badoo я знаю, что у нас данные растут каждый год в два раза. Меня эта цифра пугает просто до ужаса. Я знаю, что через год у нас будет в два раза больше данных. Соответственно, хранилище для этих данных нужно масштабируемое, и нужно предполагать, что оно будет расти. И в качестве объекта, содержащего единицу информации, предполагается файл. Можно использовать и другие способы, но файл — это универсальный способ хранения, обработки и передачи информации, присутствует почти во всех операционных системах. Именно поэтому файл.
На картинке архив министерства обороны. Самое главное отличие их архивов от тех архивов, которые нам нужны, — это то, что их архивы читают единицы, а мы должны читать архивы массово, данные должны читать.

Что хочется получить от читалки архивов? Чтобы она позволяла унифицировано читать разные логи, потому что логи могли собираться в разное время, разными системами и исторические данные менять, как отправил, долго и сложно, альтеры какие-то делать… Т.к. объемы данных большие, нужно предполагать, что данные нужно читать параллельно. Если вы, например, 100 Мб зипа читаете, раззиповываете и данные из них вытаскиваете, то у вас это занимает несколько секунд, а если вам нужно раззиповать несколько Тбайт, то здесь вам придется параллелиться. Либо вы сами будете параллелиться, либо среда это будет делать за вас. И если ваша среда позволяет вам параллелиться — это здорово.
SQL доступ. Для меня язык SQL — самый универсальный язык доступа к данным и решения различных задач с данными. Важно понимать, что SQL — это не только таблицы, это в целом structure query language и все, что можно описать в виде таблиц или чего-то похожего на таблицу, можно описывать запросы к этим объектам на языке SQL. Это не что-то новое, так думают многие.
Задача чтения архивов — это задача распараллелиться, прочитать быстро и уметь быстро обработать. Что значит быстро обработать?

Например, собрать быстро какую-то статистику (сколько данных было), отфильтровать какого-то юзера, какую-то сессию с данными, просто найти нужный кусок в большом архиве, сделать из него маленькую выдержку… Как отдельная подзадача — число уникальных событий, когда к вам приходят 10 млн пользователей с 10-ти млн уникальных айпишников — это тоже нужно уметь делать, и было бы здорово, если бы система это могла делать, т.е. это еще одна задача — именно получение статистики, когда из большого количества данных получается немного таких значимых данных.
Отдельная задача — разбивать по параметрам. Как правило, нужно знать из каких городов события пришли, из каких стран события пришли, все зависит от системы, которую вы проектируете.

Четвертая задача — это подготовка данных. Она более хитрая, тоже связана с обработкой и чтением данных, но главное отличие от предыдущего пункта — если там я предлагал из Тбайта данных доставать Кбайты данных, то здесь я предлагаю из Тбайтов данных доставать Мбайты или Гбайты данных. Т.е. вы храните очень много данных и вам нужно предоставить какую-то систему, которая на выдержках из этих данных может работать. Как пример, решение задач рекомендаций. Вам нужно посмотреть, кто что и с чем покупал, и выдать рекомендации к какому продукту нужно рекомендовать другие продукты. Т.е. у вас есть логи, кто что покупал, но эти самые логи еще бесполезны, потому что нужно сделать связки продуктов. Получается, что для того, чтобы связать продукты между собой, их нужно связать непосредственно через логи покупок. Задача сводится к тому, что нужно взять очень много данных, которые есть (как правило, там еще произойдет декартово произведение этих данных на какую-нибудь ерунду — данных станет еще больше), а потом вы сделаете какую-то выдержку, которую положите в MySQL или PostgreSQL — вообще, в любое хранилище, которое может хорошо обрабатывать не очень большие объемы данных, и будете с ними работать.
Пункт про ETL — это штука из мира BI — Extract, Transform, Load. По большому счету, это просто перекладывание данных, когда вы данные берете из одного места, приводите к нужному виду и кладете в другую базу данных. Как правило, это сбор с нескольких баз данных в одну, изменение форматов, каких-то соглашений. Опять под эту задачу очень хорошо ложиться SQL, но не как язык, который вернет нам немного данных, а как язык, в котором можно create table as select, и там будет уже много данных, т.е. вы создадите себе таблицу.
Собственно, вот четыре задачи: первая — это чтение данных, и три задачи про обработку данных. Эти самые задачи я и предлагаю решить с помощью Hadoop.
Hadoop, наверное, не единственное предложение на рынке, которое позволяет это делать, но из open source, бесплатного и решающего все задачи, наверное единственный.
Конференция называется highload, а Hadoop — из мира big data. Как highload соотносится с big data? По большому счету, когда highload начинает писать логи, то для обработки этих логов уже нужен big data. Вообще, big data — это очень широкая область с машинным обучением, с какими-то семантическими анализами, с кучей всего. По этому поводу проводятся отдельные конференции… И Hadoop –непременный атрибут чуть ли не каждого доклада в области big data.
Проект Hadoop стартовал в 2007-ом году как open source открытая реализация идеи, предложенной Google’ом еще в 2004-ом году, названной MapReduce. MapReduce — это способ организации алгоритмов, когда вы определяете две небольшие процедурки MapReduce для обработки данных, и эти процедурки, по большому счету, запускаются за вас, т.е. это такие callback’и, которые запускаются в куче мест, распараллеленные и обрабатывают большое количество данных. Это способ организации алгоритмов, потому что сам MapReduce — это не алгоритм сортировки, поиска или еще чего-либо, это способ, паттерн проектирования алгоритмов.
Как открытая реализация идеи предложенной в 2004-ом году Google’ом в 2007-ом году появляется Hadoop как MapReduce, и проект развивается-развивается-развивается, обзаводится кучей проектов вокруг себя, сильно и слабо связанных, и в частности, в ядро Hadoop попадает, для Hadoop проектируется и создается распределенная файловая система HDFS.

В этот момент Hadoop начинает подходить для решения задач хранения данных.
HDFS — это распределенная файловая система, которая позволяет хранить очень-очень много данных, но не очень-очень много файлов. Предполагается, что в ней будут лежать большие файлики, и данные будут писаться туда один раз, т.е. перезаписи данных не предусмотрено.
Вторая часть Hadoop изначально называлась MapReduce — обработка данных. Сейчас Hadoop вырос, буквально года полтора назад код, написанный для MapReduce, распался на две части — на YARN и MapReduce.
YARN — это Yet Another Resource Negotiator — это такая штука, которая отвечает за запуск задач на куче машин, управляет вычислительными ресурсами кластера и просто передает задачи на выполнение. Она не знает, какие задачи передает, а MapReduce — уже непосредственно задачи, которые запускаются.
Чуть подробнее про HDFS.
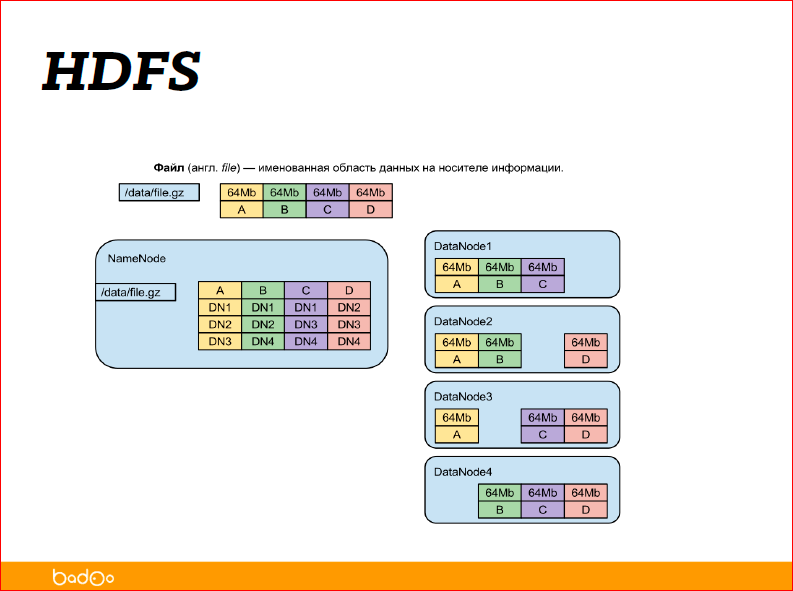
Просто файл — это кусок данных с именем. Это, наверное, самое точное определение файла, и в имени может быть все, что угодно. Если вы добавите слэши, например, в имя файла, вы получите директории.
При проектировании HDFS сразу подходили к идее того, что система должна быть отказоустойчивой, т.е. данные должны храниться на разных серверах, на разных дисках, система должна быть распределенной, чтоб в нее можно было легко добавлять, удалять новые сервера. Устройство очень простое, т.е. файл представляется в виде имени и его содержимого, содержимое разбивается на набор блоков (по умолчанию это 64 Мб, но можете указать свой), и данные получаются в виде списка блоков.
Далее, есть сервис NameNode, который просто помнит, из каких блоков состоит файл, про сами блоки не знает ничего, он просто помнит, что файл — это блоки А, B, C и D и знает, на каких хранилищах DataNode 1,2,3,4 эти самые блоки хранятся.
Как видите на картинке, каждый блок хранится в трех экземплярах — три желтеньких, три зелененьких, три фиолетовых. Это означает, что фактор репликации — 3 (три). Если коротко, то это означает, что можно потерять два любых сервера, и данные, все равно, еще будут доступны, и можно будет их восстановить и добавить еще копии файлов.
Фактор репликации в Hadoop, в отличие от многих файловых систем, пофайловый, т.е. вы можете сказать, что этот файл для меня очень-очень важен, и я хочу, чтобы мы его точно не потеряли, и поэтому я хочу, чтобы его блоки лежали во всех серверах кластера. В этом случае вы выставляете фактор репликации, равный количеству серверов в кластере, и получаете повышенное использование диска и также повышенную отказоустойчивость. А можете сказать, что этих данных у меня очень-очень много и, в принципе, потеряю и потеряю, не так уж часто и теряются данные… Фактор репликации выставить 1 (единицу). Ну, потеряется часть данных, но вроде как выживете. Опять же, зависит от вашей задачи. Hadoop — это не вещь себе, это не галочка, которую надо повесить, это штука, которая нужна для решения задач.

Те, кто работают в системе Linux, как правило, проблем в работе с Hadoop не испытывают, потому что команды для работы с файлами более-менее все те же самые. На слайде вы их видите. Есть специфичные, но тоже очень очевидные команды из серии «положить локальную файловую систему на удаленную файловую систему»; «забрать данные обратно»; setrep — это «установить фактор репликации» и text — это «сказать Hadoop то, что у меня файлики лежат в разных форматах зазипованные, раззипуй мне их, пожалуйста, и отдай просто в виде текста, я не хочу сам по расширению файла догадываться каким архиватором его раззиповывать». Это из командной строки.
Конечно же, при непосредственном внедрении, т.е. из командной строки работают разработчики и админы, когда работают с данными руками. Как правило, работа идет через API. Hadoop написан на Java, поэтому API джавовская, но есть классная штука, называется WebHDFS — это HTTP Rest API, обертки, по-моему, есть уже для всех языков.
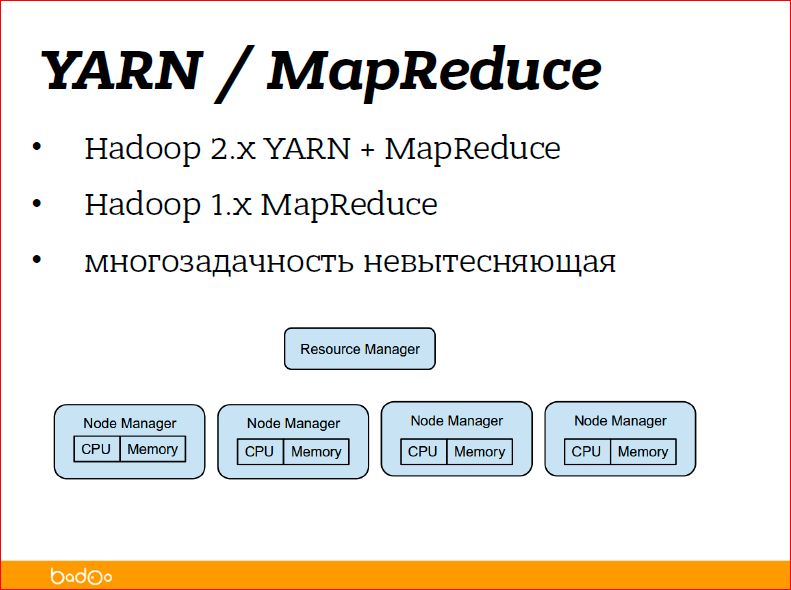
Вторая часть, связанная с обработкой данных, это вторая, третья и четвертая задачи. Как я уже говорил, это Yet Another Resource Negotiator/MapReduce. Принцип строения такой же, как и HDFS — есть мастер нода, которая рулит всем подряд и есть ноды менеджеры — это демоны, запущенные на каждом из серверов, на которых вы ходите обрабатывать данные, и они просто знают сколько ресурсов осталось на данном сервере, и говорят «у меня еще есть ресурсы, может я тебе еще чего-нибудь запущу».
Для внедрения этого всего знать не надо, просто показываю, как устроено.
Здесь закончился центр Hadoop. Т.е. есть такая штука — Hadoop common называется — это распределенная файловая система и MapReduce framework. MapReduce framework предполагает, что вы взяли java и стали писать на java под этот фреймворк и оптимизировать свои задачи. Для тех, кто хочет от Hadoop что-нибудь еще, должны взять что-нибудь еще.

Одним из старых проектов, в то же время стабильных и хороших, является Hive.
Вообще, этот желтый слоник вокруг Hadoop все вьется-вьется-вьется различными способами. Hive в переводе с английского — это улей, поэтому так вот слоник мимикрировал в пчелку.
Идея Hive была в том, чтобы предоставить доступ к файлам, лежащим в HDFS, в виде SQL. Т.е. любой более-менее структурированный лог можно описать каким-то способом, можно сказать, что это json там лежит, можно сказать, что запятыми данные разделены, тогда получается commons, Comma Separated Values (CSV), можно сказать о том, что там пробелом разделены какие-то способы структурирования данных и задать имена для этих частей данных.
SQL доступ к данным осуществляет в первую очередь Hive. Другие проекты тоже есть, но они не единственные. Как я уже сказал, SLQ удобен и с точки зрения вытащить пример данных, и с точки зрения собрать какую-то статистику, потому что у вас есть и count и max, различные агрегирующие функции, есть группировка, а также SQL в виде create table as select подходит для преобразования данных.
Как пример, стянутый с туториалов Hive, как распарсить apache access log:
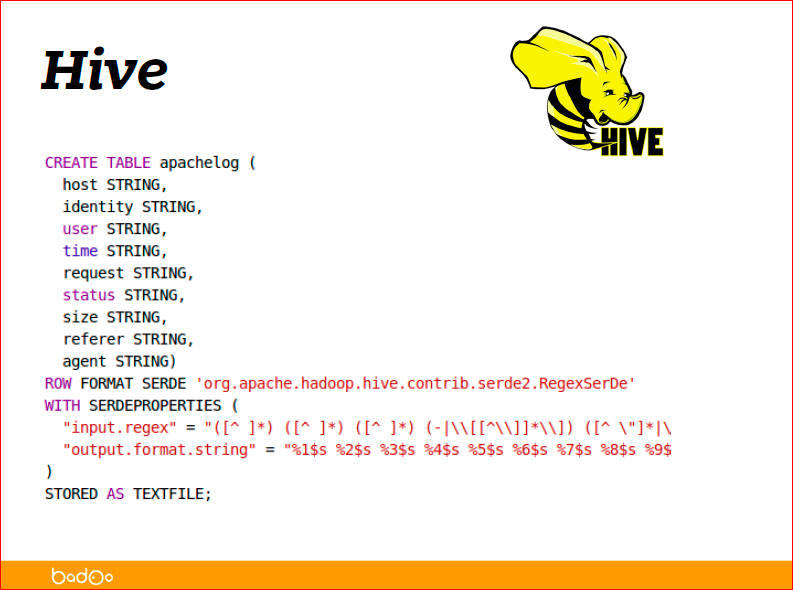
На самом деле, формат, который лежит в логе apache access log называется Combined Log Format, и самый простой способ для Hive его описать в виде регулярки. Вы видите на слайде внизу регулярочка есть. Просто регуляркой описали, что у вас лежит в строке, и сказали, что в первой части лежит host, вторая — это identity, user, time, что записали в логи, что описали в регулярке, то и видно.
Регулярка — это, наверное, самый неэффективный способ описывания данных, потому что регулярное выражение будет применяться к каждой строке и это достаточно накладная операция, но в то же время один из самых гибких способов для доступа, для описания данных. Собственно, пятая строка снизу описывает, что именно регуляркой будет парситься.
В конце видно, что это RegexSerDe, SerDe — это сериалайзер-десериалайзер — это java класс, который для Hive описывает, как распарсить строку в данные, и как из данных снова сделать строку. По большому счету, для доступа к данным вы создаете таблицу виртуальную, говорите, что она лежит по какому-то пути в HDFS, и вы можете делать селект из этой таблицы и получать свою статистику.
Я рассказал сейчас про Hadoop common и про Hive — это два продукта. А, вообще, вокруг Hadoop много различных приложений и систем:
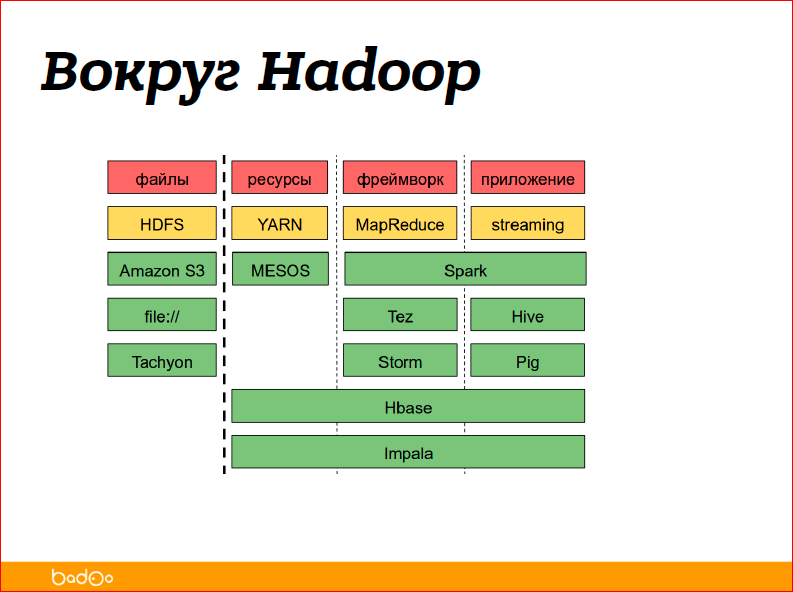
Можно попробовать разбить их по категориям управления данными, т.е. это файлы, ресурсы — то, что распределяет вычислительные ресурсы, фреймворк — это то, что организовывает вам вычисления, то что запускает ваши маперы, редьюсы или другие приложения, и, собственно, приложения — это, когда вы уже как пользователь код не пишете, пишете хотя бы SQL для обработки данных.
Желтеньким отмечено то, про что я вам рассказал, — HDFS, YARN, MapReduce, Streaming (чуть позже про него расскажу). Все остальное зелененькое — это отдельно стоящие продукты. Какие-то продукты предоставляют только фреймворк, какие-то предоставляют управление ресурсами, какие-то являются полноценными, т.е. они просто занимаются обработкой данных. Например, Hbase — это key-value хранилище, которое свои данные, свои файлики может хранить в HDFS. Файловых систем тоже куча, из забавного можно сказать, что не обязательно хранить данные в HDFS, их можно хранить просто на диске, просто среда для организаций вычислений.

Экосистема. Когда-то в Hadoop кто-то ввел, использовал слово «экосистема», и так называли все продукты, имеющие отношение к Hadoop. Я нашел список, где перечислены 150 различных продуктов и систем, имеющих отношение к Hadoop, среди них и система сбора данных, и машинное обучение, и SQL, и NoSQL.
Ищите подходящие продукты под ваши задачи, я не знаю, какие у вас задачи, я рассказал самые базовые, которые есть. Кто-то мне говорил, что есть другая классификация, там 300 продуктов существует вокруг Hadoop. Но, как я уже сказал, Hadoop — это такое слово, которое часто описывает всю экосистему, все продукты, все это семейство.

Теперь немножко о Hadoop в Badoo.
Зачем вам эти цифры могут оказаться полезными? Цифры могут оказаться полезными, с той точки зрения, что Hadoop масштабируется достаточно линейно. Т.е. если вы предполагаете объемы данных в два раза больше, вы просто умножаете цифры на два. Если вы планируете объемы данных в два раза меньше, делите эти цифры на два.
Естественно, все это имеет отношение к задачам, потому что в зависимости от задач, которые вы решаете, вы будете упираться в различные вещи. Кто-то будет упираться в сеть, кто-то будет упираться в процессы, кто-то будет упираться в производительность диска. Ничего обещать никто не сможет. Просто прикидывать и смотреть.
Кластер, на самом деле, небольшой — 15 серверов. В общем, все написано.
Почему 2 сервера подготовки данных? Потому что Badoo располагается в двух датацентрах — один находится в Праге, другой — в Майами. В каждом датацентре мы подготавливаем данные — это значит, что собираем со всего датацентра то, что мы хотим положить в Hadoop, зазиповываем и уже между датацентрами передаем в заархивированном виде.
Объемы данных, которые мы собираем:

В принципе, по одному серверу в каждом датацентре стоит, получается, что приходит 1 Гбит трафика, т.е. по большому счету, скоро начнем упираться в сеть, будем, наверное, в каждом датацентре ставить еще по одному серверу.
Что еще интересного — вот файлов и блоков похожее количество. Файлики мы специально делаем не очень большими, потому что большие файлики в зазипованном виде читаются очень плохо.
Средний фактор репликации — 2.75, а не 3, потому что у нас есть большой кусок данных, который мы реально не очень боимся потерять, но просто приятно его иметь и тратить на хранение 20 Тбайт. Вам нужно сохранить 20 Тбайт, у вас фактор репликации 3, значит, вы должны подготовить 60 Тбайт дисков. Если вы решаете поставить фактор репликации 2, у вас тут же появляется лишние 20 Тбайт дисков — это вкусно. Данные обязательно сжаты, потому что у нас самая используемая, самая проблемная вещь — это объемы данных.
Это была первая задача. Т.е. этот слайд — это про хранение данных, про то, как устроены распределенные файловые системы — это первая задача про хранение данных.

Вторая, третья и четвертая задачи — это про обработку данных. Инструменты, которые используем — Hive, Spark и еще используем Streaming. Если нужно просто подготовить какие-то данные, например, раз в день собрать суточные счетчики пользователей или еще что-то, используем Hive. Для ручного доступа, ручного анализа, Hive тоже подходит. Как в любой базе данных написал SQL, получил результат, можете сразу какие-то визуализаторы прикручивать, потому что, по-моему, у него есть JDBC — взяли и прикрутили.
Есть у нас в компании такая система старая, она еще организована на RRD, но суть в том, что хранит т.н. timeseries. Это когда вы храните какое-то значение во времени, и чем ближе к сегодня, тем более детальные данные вы хотите знать, т.е. данные за сегодня вы храните в разбивке по минуте, а данные за три года назад вы храните в разбивке хотя бы по дням. В целом эта штука называется timeseries. Чтобы кормить timeseries хранилище нужно собирать данные, собирать какое-то значение за последний день или за последний час.
У нас два основных окна, в принципе, мы с разными окнами работаем. Для такого онлайн процессинга, его часто называют realtime. Realtime в мире Hadoop — это значит, что вы что-то сделали в течение пяти минут. Это совсем не realtime.
Мы используем Spark. Spark когда-то появился как еще одна реализация MapReduce, потому что Hadoop был отчасти монополистом на рынке и хотели создать ему альтернативу. Сделали Spark, и он отлично вписался в экосистему Hadoop, вошел в семейство. Там SQL доступ есть, там и Streaming есть, там и машинное обучение в Spark’e есть. Это еще один комбайн, который вокруг себя всякой ерундой обрастает. Streaming — это такая маленькая штука, которая входит в Hadoop common и позволяет писать MapReduce задачи, вообще, на любом языке. Вот, хотите на баше, напишите на баше, организация очень простая — вы передаете ему две утилиты, которые на вход принимают то, что было прочитано из HDFS, а на выходе то, что вы хотите получить.
Про организацию MapReduce, я надеюсь, либо вы знаете, либо вы выучите, потому что про MapReduce мне потребуется примерно еще час рассказать, как он устроен.
Форматы, которые мы используем, — json, tab separated. Два основных формата.
Tab separated используем, когда мы точно знаем, какие столбцы и в каких логах мы хотим хранить, и никаких сложных данных в них не предвидится.
Json нужен на тот случай, когда мы хотим хранить абсолютно все в одном логе, но данные нужно как-то структурировать, потому что в зависимости от типа записи, вы хотите видеть разные столбцы, разные типы.

Слайд «Просто советы» — это где-то грабли, на которые мы наступили, где-то то, что нам очень сильно помогло в процессе внедрения Hadoop, и что-то, что может быть вам полезно, когда вы придете к себе в компанию и вдруг начнете внедрять Hadoop. Просто полезный слайд, который вам даст кучу подсказок, как хранить данные.
- Сжимайте данные. Естественно, данные лучше сжимать, нет хорошего или единого универсального алгоритма сжатия, который бы подошел всем, все три алгоритма разные.
Gzip — он жмет средне-быстро, и, вообще, универсальный формат, используется много где. Если bzip2 с ним сравнить, вот bzip2 требует в 10 раз больше процессора, а коэффициент сжатия у него процентов на 10 всего, т.е. на 10% лучше. Очень тяжелая штука, но главное отличие между gzip и bzip — то, что если вы взяли 1 Тбайт, зазиповали его, чтобы его прочитать и обработать, вы на самом деле возьмете его с самого начала этого зазипованного Тбайта и будете его читать. Вы не сможете запустить второй поток, который читает середину. Если взять формат bzip2, его можно читать с середины, и Hadoop, увидев большой файлик, попытается его разбить и читать в несколько потоков.
lzo — эта штука, которая практически не ест процессор, но жмет хуже, чем bzip, есть еще какой-то атрибут у lzo, что он бывает индексит и тогда его тоже можно разбивать как bzip.
- Нарезайте данные на файлы — это связано с архивацией. Если вы все данные за один день положили в один большой файлик, зазиповали его gzip’ом, вы никаких распараллеленных вычислений не получите, вы получите одно ядро, которое раззиповывает, и второе ядро, которое парсит содержимое файла. Это два ядра из 150-ти вы получите. Чем больше файликов, тем больше потоков вы можете запустить.
- Собственно, какого размера файлики? Тут написано, что размер файла — это несколько блоков. Тоже не совсем правильно. Правильно сказать, о том, что если у вас есть минимальный набор данных, с которыми вы хотите работать, например, один день, то файлов в этом одном дне у вас должно быть столько, сколько у вас ядер в процессоре, ядер в кластере — это самое оптимальное описание.
- Нарезайте директории по дням / часам. Многие продукты не смотрят на имена файлов, они достаточно просто их игнорируют, и поэтому сказать, что у меня файлики называются 20150522, т.е. сегодняшнее число, они не могут. Но можно сказать, что данные за 22-ое число у меня лежат в этой директории, данные за 21-ое число — в этой директории, в этом случае вы сможете описать.
- Не храните данных в пути файла. Если вы хотите получить доступ к данным, которые лежат в пути файла, вам часто придется очень сильно велосипедить, проще эти данные положить прямо внутрь файла в каждую строчку.
- Бэкапьте неймноду, неймноду бэкапьте — это не опечатка, это правда. Неймнода — это единственная точка отказа Hadoop кластера, за которой нужно следить, за которой нужно ухаживать, и потеря ее приведет к полной потере данных. Вы, например, записали 150 Тбайт данных — молодцы, у вас есть 150 Тбайт мусора.

Чего не надо делать. Не надо запускать Hadoop на слабом железе — это первые три пункта. Его можно запустить, но вы при этом получите кучу ограничений, т.е. возьмете и запустите все на одном сервере, вы не получите ни избыточности, ни нормальной распараллеливаемости, ничего. Если у вас маленький проект, и вы хотите его поставить, Hadoop не нужен для одного маленького проекта — это иллюзия.
На одном сервере можно поставить все, но тогда вы получите, например, девел или какое-то тестовое окружение. Меньше 1 Гб памяти — да демоны Hadoop просто при старте жрут достаточно прилично, поэтому если у вас есть 1 Гб памяти на сервере — да, вы сможете запустить Hadoop, но какие-то тяжелые вычисления уже, в принципе, не сможете сделать. Если у вас есть сервера с кучей дисков и слабыми процессорами, вы можете организовать хранилище. Но это будет именно хранилище, а не читалище. Т.е. вы по большому счету данные оттуда сможете читать, но эти сервера не будут участвовать в обработке данных.
Маленький проект — невыгодно. Опять же, если у вас маленький проект, то сама идея поставить четыре сервера под Hadoop кластер может показаться кому-то очень странной. В то же время, если в вашей компании много маленьких проектов, вы все данные этих проектов можете объединить в рамках одного Hadoop кластера.
Из того, что надо делать, если ваша компания существует на рынке лет 5. Как правило, остаются какие-то сервера, которые просто стоят в стойках, греют воздух и их надо утилизировать, а утилизировать — это, как правило, еще деньги требуются, бизнес их не утилизирует, зато вы можете утилизировать их ресурсы, добавив в Hadoop. Hadoop достаточно хорошо принимает слабое железо в кластер, выводит из кластера, так что можете продлить жизнь старым серверам. Старые сервера часто отказывают, но как я уже объяснял, Hadoop это просто не важно, потому что Hadoop к этому готов. Hadoop проектировался для систем, где работают тысячи серверов, и поэтому отказ или одновременный простой одного-двух серверов — это абсолютная норма.
Больше всего, наверное, нас расстроило то, что в Hadoop нет разноса по датацентрам, чего бы нам очень хотелось, но, увы, нет, не стоит на это рассчитывать.

Три книжки по Hadoop, все три — на английском, возможно, есть переводы на русский, не знаю. Это реально книги, которые нужно читать вместо мануалов. Потому что мануалы не всегда хорошие, а книжки отвечают на гораздо больше вопросов.
Первая — «Hadoop Definitive Guide» — нужна всем, кто работает с Hadoop так или иначе. Снизу две книжки — «MapReduce Design Patterns» и «Hadoop Operations» — левая книжка для разработчиков, правая — для админов. Если вы занимаетесь и тем и другим, то читайте обе.
Контакты
» alexxz
» a.eremihin@corp.badoo.com
» Блог компании Badoo
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая HighLoad++ Junior. Подключайтесь! Мы действительно поднимем цены сразу после Нового года.
Комментарии (16)

just_vladimir
09.01.2017 16:07У меня вопрос, все таки на какое железо ориентирован hadoop?
Исходя из личного опыта с задачками, где было много (ну или относительно много) данных, то весь затык всегда случался не на стороне сервера, а на стороне СХД. Условно даже на СХД начального уровня (например, IBM Storwise v3700) можно свободно хранить сотни терабайт данных, но скорость с которой современные магнитные диски выдают данные в разы уступает скорости с которой современные процессора способны переваривать эти данные. И собственно здесь у меня возникает непонимание — как мне поможет кластер серверов с хадупом, если СХД не может угнаться даже за одним более-менее мощным сервером?
Или подразумевается, что это кластер средненьких серверов и на каждом из них пара сотен ГБ встроенного стораджа на SSD и уже они собираются в кластер? Но если так, то при объемах в сотни ТБ можно разориться на железе…
facha
09.01.2017 16:23+1Кластеры Hadoop как правило используют локальные диски, расположенные на самих нодах. Внешнее хранилище не используется.

vdmitriyev
09.01.2017 19:21+1В Hadoop-е (или даже в MapReduce-е) активно используется понятие как "locality is a king", то есть данные должны лежать именно там где обрабатываются (в иделале) или точнее "обработка" должна совершаться там где данные расположились. Конкретно касательно СХД и Hadoop можно почитать тут — https://0x0fff.com/hadoop-on-remote-storage/ .

Loxmatiymamont
10.01.2017 13:00Не усмог увидеть ответ на главный вопрос, обозначенный в названии доклада: где заканчивается просто большая бд и начинается хадуп? Я понимаю, что вопрос довольно абстрактный, но слишком часто слышу истории про использование hadoop только ради hadoop, без какой либо выгодны.
just_vladimir
10.01.2017 19:24Пока у меня сложилось впечатление, что хадуп начинается там, где есть куча серверов с DAS , при этом суммарный объем обрабатываемых данных не умещается на один такой сервер и по какой то причине нельзя все затолкать в нормальный NAS .
Loxmatiymamont
10.01.2017 19:30Базы данных совершенно спокойно могут занимать несколько серверов с DAS, а то и стоек. Так что разделять по такому признаку несколько сомнительно.
vdmitriyev
13.01.2017 21:30Может скажу несколько очевидную вещь, но если вы и дальше можете обрабатывать имеющиеся у вас данные при помощи баз данных, то не нужны вам никакие "hadoop-ы/spark-и".

dm9
Хочу спросить совета. У меня как раз случай маленького проекта. На текущий момент я имею примерно 10 000 000 событий. Храню в TSV-файлах, типа 2017-01-09.txt, обрабатываю через PHP с эпизодическим экспортом в MySQL и последующим исполнением SQL-запросов на получившихся таблицах. Хочется убрать (или минимизировать) вот этот слой про PHP-обработку tsv-файлов и работать сразу в формате SQL. Идея загнать всё в одну таблицу MySQL мне не очень нравится, учитывая, что это должно расширяться хотя бы до 100 млн. событий. Какую систему хранения и обработки вы можете посоветовать для таких масштабов, учитывая, что я явно попадаю в «маленькие проекты», и Hadoop мне, видимо, не нужен?
just_vladimir
10/100 млн событий это всего или в день? Даже если в день, то тоже не проблема, пусть будет одна таблица и партиции в ней (надеюсь MySQL умеет партиции, если не умеет, то просто один день — одна новая таблица с аналогичной структурой), грузим тоже специализированной тулзой (Oracle sql*loader / PostgreSQL COPY, в MySQL наверное тоже что то такое есть) и дальше смело работаете, как вы выразились «в формате SQL». Ну и соответственно никакие хадупы тут не нужны.
dm9
10/100 млн — всего, проект маленький. У меня было ощущение, что 100 млн записей (это 20 ГБ в тексте) — это многовато для MySQL-таблицы. Хотя, сейчас погуглил, народ использует, и всё нормально. Возможно, мне надо побольше поэкспериментировать с настройками памяти. Сейчас как раз буду работать над аналитикой — попробую перевести хранилище на MySQL из текста. У меня был какой-то психологический барьер на единицы миллионов записей в MySQL :-)
(Извините, это я нажал на минус у комментария — промахнулся. Кто может, компенсируйте, пожалуйста.)
just_vladimir
20 ГБ это очень мало, просто для осознания масштабов, это даже меньше, чем объем ОЗУ, который можно получить на современных десктопах.
fuCtor
Если там счётчики и часты именно агрегации/аналитика посмотрите на Clickhouse, а так обычной RDBMS хватит более чем, периодически делайте агрегации и партиционирование.
Lelik13a
А не смотрели в сторону Elasticsearch? Он как раз заточен под хранение данных с привязкой по времени, типа логов. А в связке с logstash и kibana получите парсер данных -> наполнение базы -> представление в удобном виде.