

Как известно, виртуализация в привычном ее формате (то есть подразумевающая запуск полноценной операционной системы внутри другой операционной системы) не всегда была такой «бодрой» и эффективной, как сейчас. Первые версии гипервизоров отличались относительной медлительностью и действительно приводили к серьезному снижению производительности по сравнению с тем, как операционные системы и запущенные в них приложения работали на «реальном железе».
Именно поэтому, когда наша компания только начинала работать над продуктом, который называется сегодня Virtuozzo, мы выбрали направление, которое называют сегодня «Контейнерами ОС» или «Легкими ВМ». В чем разница? А разница в том, что наши легкие ВМ не требовали и не требуют запуска отдельного ядра для каждой «сущности», работающей на сервере. Вместо этого мы берем готовое ядро Linux и предлагаем ему разделить все ресурсы между разными пользователями. Речь, конечно, шла не совсем о стандартном дистрибутиве Linux, а о модифицированной версии, которая могла изолировать пользователей между собой, предоставляя им доступ, например, только к отдельным частям дерева процессов, к отдельным сетевым адаптерам и так далее. Все это было очень востребовано, так как работала в десятки раз быстрее, чем полная виртуализация.
Но а пользователь фактически получал свой изолированный дистрибутив Linux: при доступе через SSH он видит определенные ресурсы, разрешенные процессы и не может влиять на других пользователей. Именно так и сложилась модель предоставления виртуального хостинга на базе контейнеров ОС (или «Легких ВМ») – максимум эффективности при минимальной нагрузке на серверы.
Прогресс неизбежен
С тех пор, как первая версия Virtuozzo была представлена в далеком 1999 году, прошло много времени, за которое технологии виртуализации – как контейнерной, так и полной – претерпели серьезные изменения, и наметились основные вектора поиска «Святого Грааля» — оптимального по своим характеристикам решения для современных cloud-native задач.
На протяжении всего этого времени к контейнерной виртуализации предъявлялись в основном требования в сфере безопасности, а схемы полной виртуализации критиковались за недостаточную производительность и плотность размещения ресурсов.
Что же, за это время средства виртуализации, позволяющие запускать полные версии гостевых ОС, сильно шагнули вперед, что в частности, видно на продуктах VMware. Благодаря тому, что современные процессоры поддерживают ряд оптимизаций для работы с виртуальными средами, количество процессов, которые приходится эмулировать, намного уменьшилось. В результате гостевое ядро все чаще обращается напрямую к оборудованию и лишь по требованию запросы проходят через гипервизор.
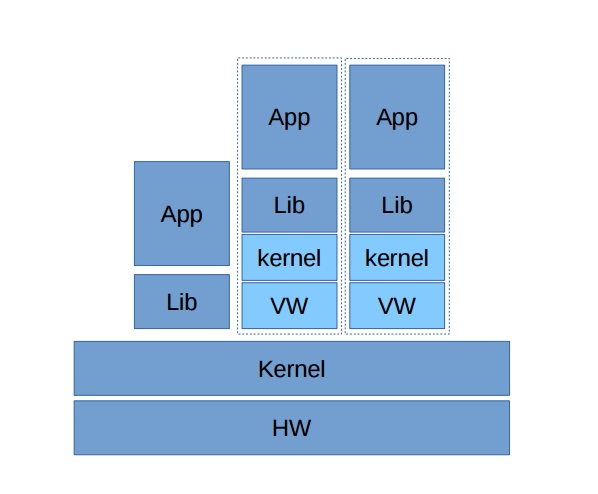
Зачем эмулировать простейшие инструкции? Например, арифметика или перемещение байтов могут выполняться процессором непосредственно. То же самое можно сказать и про функцию ret (возврат результата выполнения процедуры). Благодаря тому, что за данными не нужно каждый раз обращаться к гипервизору, виртуальные среды стали работать быстрее. И сегодня производители процессоров продолжают добавлять виртуальный контекст в свои продукты, делая системы виртуализации еще эффективнее.
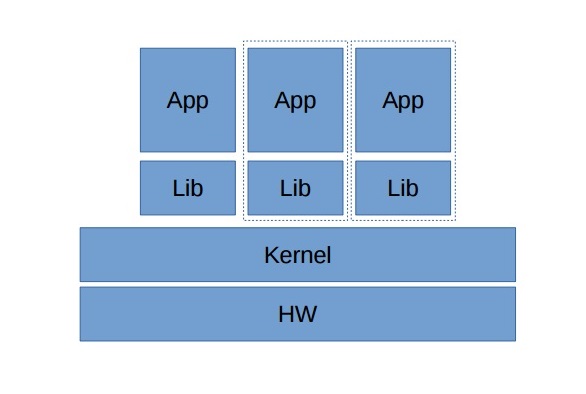
Контейнерные технологии тоже становились все совершеннее. Например, в нашей собственной версии Virtuozzo Linux была реализована технология ReadyKernel, которая позволяет устанавливать обновления безопасности без перезагрузки сервисов, а значит – делать это в любое время, в том числе, моментально после их анонса. Или другой пример – шифрование дисков контейнеров, чтобы избежать возможности кражи данных, когда «Легкая ВМ» находится в неактивном состоянии. Так что пока средства полной виртуализации становились быстрее, их альтернатива в виде контейнеров ОС становилась более защищенной.
Паравиртуализация

С другой стороны, сами производители операционных систем стали помогать в осуществлении виртуальных инициатив. Сегодня и Linux и Windows являются паравиртуализированными системами. Это значит, что, работая в гостевом режиме, ОС «осознанно» обращаются не к реальному оборудованию, а к гипервизору. Таким образом, они могут один раз заявить гипервизору о серии привилегированных операций и сэкономить массу времени, которое раньше уходило на эмуляцию. В частности, управление памятью и работа с системами ввода/вывода стали на порядок лучше и быстрее, ведь фактически из системы был исключен слой «виртуального железа».
Проксирование
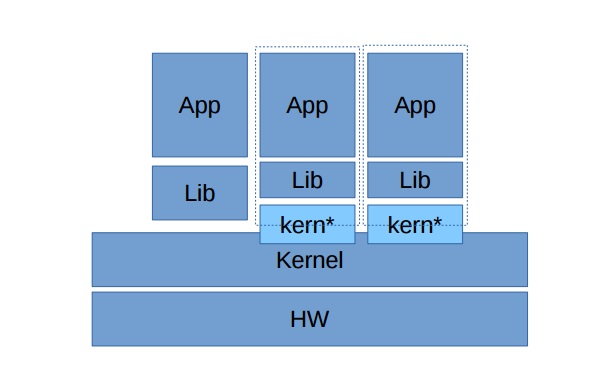
Другая интересная технология, которая сегодня только набирает обороты и может дать большой толчок в развитии именно «Легких ВМ» — это проксирование. Первыми о данном решении заявили в компании Apporeto. Разработчики предложили следующую идею: они проанализировали базу данных уязвимостей и сделали вывод, что уязвимости в файловых системах и сетевом стеке находят всего 1-2 раза в год. Но в интерфейсной части это происходит намного чаще. В результате было предложено использовать всем клиентам один и тот же слой работы с сетью, файлами и другими «глубокими» сервисами ОС, но при этом вынести в гостевые системы все, что связано с интерфейсами. Таким образом, даже если злоумышленник сможет использовать свежую уязвимость, он не сможет пробраться дальше конкретной «Легкой ВМ». На данный момент для реализации подхода необходимо использовать специальный дистрибутив Linux, но учитывая перспективность подхода, в скором времени мы увидим реализацию этого принципа в большинстве стандартных дистрибутивов.
С прицелом на приложения
Впрочем, победоносное шествие Docker определило еще один очень интересный тренд: многим хочется запускать готовые микросервисы – отдельные приложения. И затевать для этого целую виртуальную машину, вроде бы, не имеет смысла. В этом случае можно предоставить владельцу возможность выбирать, какие функции доступны приложению. И этот подход стал весьма популярен за неимением иных готовых решений. Но он подходит только для тех приложений, которым не нужно много функций. В противном случае приходится чем-то жертвовать, а это – не интересно.
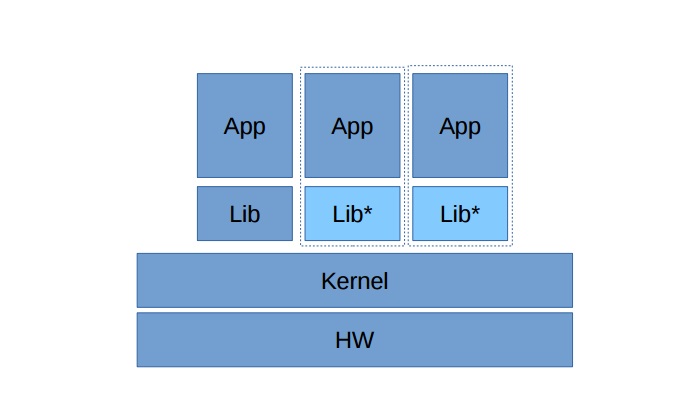
Вместо этого стали появляться возможности запустить приложение в гипервизоре без ядра, но снабдить его нужными библиотеками. Такие решения называются Unikernel. Они включают в себя модифицированные системные библиотеки, которые изначально знают, что работают в гипервизоре. Для гипервизора гостевая ОС представляет собой 1 процесс. Так какая разница? Почему не запустить в виде этого 1 процесса наше приложение?
Отличие состоит лишь в том, что приложение вместе с библиотеками формируется как «монолит», который включает в себя нужные модули. Впрочем, сегодня уже создано достаточно автоматизированных инструментов, которые помогают собирать такие комплекты и запускать их прямо в гипервизоре, обеспечивая одновременно и высокую степень изоляции процессов друг от друга, и высокую производительность.
Перспективы
Подводя итог сказанному выше, мы хотим выразить свою уверенность в том, что технологии виртуализации будут развиваться по обоим направлениям, углубляя специализацию для решения различных задач. Все более глубокая паравиртуализация и новые методы проксирования обеспечат более высокую производительность и эффективность использования ресурсов гостевыми ОС в гипервизоре, а дополнительная защита «легких ВМ» сделает их еще более привлекательными для хостеров и корпоративных сред. Таким образом, полноценная виртуальная экосистема уже в ближайшее время должна будет поддерживать и готовые гостевые ВМ, и «легкие ВМ», и готовые приложения в виде Unikernel или Docker-контейнеров.
Комментарии (8)

amarao
20.01.2017 18:03+3Главная проблема контейнеров как средства multitenant isolation — слишком широкий фронт изоляции. Если на уровне VM точки изоляции можно пересчитать по пальцам, то в ядре — куда не плюнешь — всё shared-ресурс. Иноды, fd, открытые сокеты, энтропия, conntrack, число маршрутов, число виртуальных сетевых интерфейсов, правила iptables, треды, количество нефрагментированных страниц памяти (order>1), пользователи, mountpoint'ы… я всего и не вспомню. На практике контейнеры работают как «полу-изоляция», т.е. от наивного копания в чужом спасают, от ощущения коммуналки shared-хостинга — нет.
Именно потому я смотрю с гигантским скепсисом на попытки принести контейнеры в хостинг как заменую виртуализации. Не получается. Ядро слишком «широкое», чтобы его можно было огородить.
Если для виртуализации (уровня виртуальных машин) уже года два как бегают с NFV, т.е. таким уровнем изоляции, на котором один инстанс никаким образом не может задеть соседний с меньшим QoS, то мечты о гарантированном realtime для контейнера…
Сейчас, закончу oom'ом процессы считать в соседнем namespace, и выдам вашему realtime-приложению положенные ему 200мс… Секунд через 10.
Gummio_7
20.01.2017 21:15Ну так о том и речь, уважаемый, что каждому свое. Контейнеры не идеальны с точки зрения изоляции, но становятся лучше… ВМ не идеальны с точки зрения плотности размещения и эффективности утилизации ресурсов, но они тоже становятся лучше. О том и пост. :)

foxmuldercp
21.01.2017 16:14+1Именно потому я смотрю с гигантским скепсисом на попытки принести контейнеры в хостинг как заменую виртуализации. Не получается. Ядро слишком «широкое», чтобы его можно было огородить.
Я смотрю на это с другой точки зрения:
У меня на каждом сервере хостинга от нескольких сотен до нескольких тысяч сайтов, если брать классический плеск, или те бесплатные панельки типа весты общая идеология — один апач и один нгинкс на все, и ими предоставляется только php и perl.
Плеск научился докеру только в Ониксе, который вышел с месяц назад.
Я общался с некоторыми старыми хостерами, у большинства из которых очень старые очень давно самонаписанные панели управления на перле, или старом питоне или старом же пхп.
В общем, моя идея о докере в шаред хостинге, когда каждый сайт имеет свой отдельный апач, версию php, а так же, что не маловажно, свой отдельный фаервол как на вход, так и на выход, при этом инстансы сайта расположены на нескольких независимых аппаратных серверах и контент клиентских вордпрессиков синхронизируется через ceph, получила одобрение, включая идею сделать свой маленький Хероку, когда клиент загружает свой докерфайл и делает себе все сам.
Так что я сейчас улыбаюсь и фигачу код — как минимум 4 хостинга в моем этом проекте заинтересованы не праздно
amarao
21.01.2017 17:26Для shared hosting коммуналки контейнеры это благо, да. Хотя это не отменяет того, что это коммуналка, только чуть менее коммунальная коммуналка. Без чужих велосипедов в корридоре.
foxmuldercp
21.01.2017 18:03+1Ну вот когда овер 90% сайтов это вордпрессики которые даже гугль ботами забыты — я думаю что самое оно, проломали и фиг с ним, почта с них через свой релей с лимитами — превысил, админу алерт, клиенту алерт, ssh/telnel/ntp/dns порты прикрыты с контейнеров, тоесть, я таким образом прикрываю wild internet от всякого хлама, которое там на этих старых жумлах заводится с регулярностью несколько проломов в день на аппаратный сервер.
Ну а тем, кто знает что такое докер не понаслышке — можно и руби, и питон, и скалу, и гоу с нодами, и жаву с томкатами, за более другой ценник
Gummio_7
21.01.2017 23:57Кстати, мы в Virtuozzo как раз о том речь и ведем — удобно, когда можно выбрать нужную технологию для нужных задач. Что-то доступнее и проще, что-то дороже и value-added. В любом случае хорошо, когда можно использовать стандартные ВМ, легкие ВМ, контейнеры Docker или еще что-нибудь на выбор — в зависимости от задач.
xcore78
Картинка к посту — «Problem of choice».
Gummio_7
Да, это факт. Пожалуй уберем. :)