
Конфигурация сервера:
Простой VDS — 1 ядро процессора 2ГГц, 1Гб оперативы, 10Гб SSD.
ОС: Debian 8.6.
Так же произведены базовые настройки ядра, чтобы сервер в принципе мог обрабатывать большое кол-во соединений.
Испытуемые:
— PHP 7.1.1 FPM
— Node.js 7.4.0
Первый этап:
Тут операции, которые в основном использует backend. А именно: склеивание строк, сетевой ввод-вывод, арифметика и работа с массивами.
Код для Node.js:
var fs = require('fs');
var mysql = require('mysql2');
console.time('Node.js ' + process.version + ': склеивание строк 1000000 раз');
var str = '';
for (var i = 0; i < 1000000; i++) {
str += 's';
}
console.timeEnd('Node.js ' + process.version + ': склеивание строк 1000000 раз');
console.time('Node.js ' + process.version + ': сложение чисел 1000000 раз');
var count = 0;
for (var i = 0; i < 1000000; i++) {
count++;
}
console.timeEnd('Node.js ' + process.version + ': сложение чисел 1000000 раз');
console.time('Node.js ' + process.version + ': наполнение простого массива 1000000 раз');
var array = [];
for (var i = 0; i < 1000000; i++) {
array.push('s');
}
console.timeEnd('Node.js ' + process.version + ': наполнение простого массива 1000000 раз');
console.time('Node.js ' + process.version + ': наполнение ассоциативного массива 1000000 раз');
var array = {};
for (var i = 0; i < 1000000; i++) {
array['s' + i] = 's';
}
console.timeEnd('Node.js ' + process.version + ': наполнение ассоциативного массива 1000000 раз');
console.time('Node.js ' + process.version + ': чтение файла 100 раз');
var content;
for (var i = 0; i < 100; i++) {
content = fs.readFileSync('./someFile.txt');
}
console.timeEnd('Node.js ' + process.version + ': чтение файла 100 раз');
console.time('Node.js ' + process.version + ': mysql query (SELECT NOW()) 100 раз');
// create the connection to database
var connection = mysql.createConnection({host:'localhost', user: 'root', database: 'test', password: 'password'});
function promiseQuery(query) {
return new Promise((resolve, reject) => {
connection.query(query, function (err, results, fields) {
resolve({err, results, fields});
});
});
}
for (var i = 0; i < 100; i++) {
var a = promiseQuery('SELECT NOW()');
a.then(({err, results, fields}) => {
//console.log(results);
});
}
console.timeEnd('Node.js ' + process.version + ': mysql query (SELECT NOW()) 100 раз');
connection.end();
Код для PHP:
<?php
$phpVersion = "v" . explode('-', PHP_VERSION)[0];
$start = microtime(1);
$str = '';
for ($i = 0; $i < 1000000; $i++) {
$str .= 's';
}
echo "PHP $phpVersion: склеивание строк 1000000 раз: " . round((microtime(1) - $start) * 1000, 3) . "ms \n";
$start = microtime(1);
$count = 0;
for ($i = 0; $i < 1000000; $i++) {
$count++;
}
echo "PHP $phpVersion: сложение чисел 1000000 раз: " . round((microtime(1) - $start) * 1000, 3) . "ms \n";
$start = microtime(1);
$array = array();
for ($i = 0; $i < 1000000; $i++) {
$array[] = 's';
}
echo "PHP $phpVersion: наполнение простого массива 1000000 раз: " . round((microtime(1) - $start) * 1000, 3) . "ms \n";
$start = microtime(1);
$array = array();
for ($i = 0; $i < 1000000; $i++) {
$array["s" . $i] = 's';
}
echo "PHP $phpVersion: наполнение ассоциативного массива 1000000 раз: " . round((microtime(1) - $start) * 1000, 3) . "ms \n";
$start = microtime(1);
for ($i = 0; $i < 100; $i++) {
$fp = fopen("./someFile.txt", "r");
$content = fread($fp, filesize("./someFile.txt"));
fclose($fp);
}
echo "PHP $phpVersion: чтение файла 100 раз: " . round((microtime(1) - $start) * 1000, 3) . "ms \n";
$start = microtime(1);
$mysql = new mysqli('localhost', 'root', 'password', 'test');
for ($i = 0; $i < 100; $i++) {
$res = $mysql->query("SELECT NOW() as `now`");
$now = $res->fetch_assoc()['now'];
}
echo "PHP $phpVersion: mysql query (SELECT NOW()) 100 раз: " . round((microtime(1) - $start) * 1000, 3) . "ms \n";
Результаты:
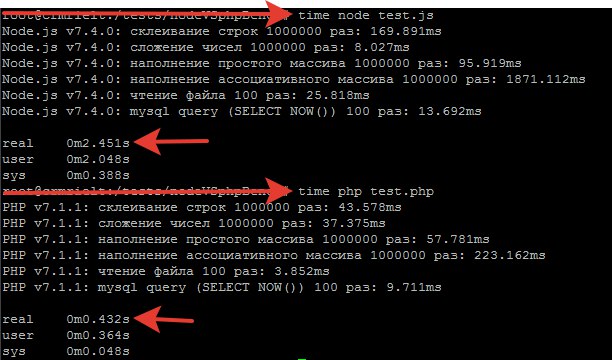
Как видно, PHP выигрывает по всем пунктам, кроме операции сложения.
Второй этап:
Нагрузочное тестирование «Hello world». Nginx 11.7 + PHP 7.1.1 FPM vs Node.js. 1000 запросов в 1000 потоков. #ab -n 1000 -c 1000…
Код PHP:
<?php
echo "Hello world";
?>
Код Node.js:
const http = require('http');
const hostname = '127.0.0.1';
const port = 3000;
const server = http.createServer((req, res) => {
res.statusCode = 200;
res.setHeader('Content-Type', 'text/plain');
res.end('Hello World');
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
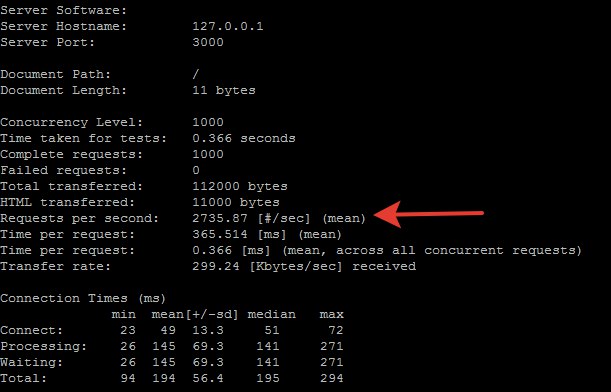
Результаты
Прогнал по 10 тестов для PHP и для Node.js и выбрал лучшие результаты у обоих.
Node.js:
PHP:
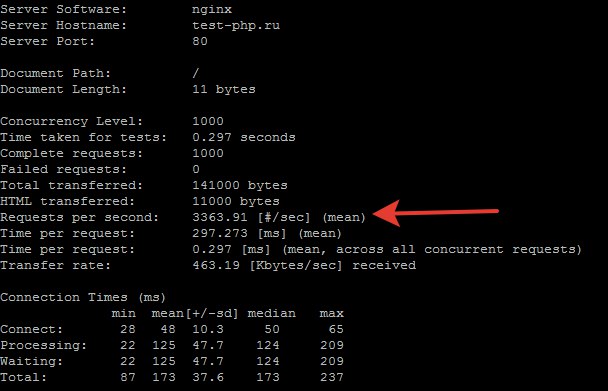
Как видим и тут PHP выигрывает на 23% или на 628 запросов в секунду. Много это или мало судить вам.
Делитесь в комментах своими мыслями по этому поводу.
Комментарии (128)
amaksr
28.01.2017 03:33+7У меня из командной строки получился обратный результат:
>c:\php\php test.php
PHP v7.0.4: concatenation 1000000 times: 132.97ms
PHP v7.0.4: addition 1000000 times: 174.055ms
PHP v7.0.4: adding to array 1000000 times: 154.771ms
PHP v7.0.4: adding to hash 1000000 times: 249.67ms
>node test.js
Node.js v6.9.4: concatenation 1000000 times: 50.109ms
Node.js v6.9.4: addition 1000000 times: 2.692ms
Node.js v6.9.4: adding to array 1000000 times: 22.845ms
Node.js v6.9.4: adding to array hash 1000000 times: 877.773ms
Частично соглашусь с предыдущим комментарием: ноде нужен только для асинхронности и событийности. А вообще писать для него не самое приятное занятие.amaksr
28.01.2017 03:44В тесте adding to hash если заменить
array['s'+i] = 's';
на
array[''+i] = 's';
то результат улучшается с 877.773ms до 203.794ms, а если на
array[i] = 's';
то до 34.362ms
Интересно почему…
Maiami
28.01.2017 04:52+1Просто v8 сильно оптимизирует работу с обычными, не ассоциативными, массивами

v-derckach
30.01.2017 16:08php7 тоже сильно оптимизирует работу с не ассоциативными массивами. Как раз недавно на хабре была статья о том, как правильно оптимизировать код для php7.
Maiami
31.01.2017 01:37+1Выше спрашивали почему так у js, а то что в php7 примерно похожие оптимизации — это стало понятно еще с выходом первой беты php7
Fortop
28.01.2017 04:55Потому что конверсия типов идет в индексе массива.
И операция эта затратнее сложения или присвоения
seokirill
28.01.2017 09:40А разве не играет роли, что процессор оьноядерный оО?!

Fesor
28.01.2017 22:09+1есть еще такая штука как конвейеризация. Если вы работаете с циклом и у вас нет зависимостей между итерациями, специальные алгоритмы пересортируют поток инструкций таким образом что бы минимизировать задержки по памяти.
Это я к тому что не только количество ядер процессора имеет значение. Если вы хотите пример — развертка циклов. Это когда за одну итерацию цикла вы делаете не 1 операцию, а инлайните например 4 штуки.
for (let i = 0, length = arr.length; i < length; i += 16) { arr[i+0] = arr[i+0] * 2; // ну или любая другая операция arr[i+1] = arr[i+1] * 2; // ... arr[i+15] = arr[i+15] * 2; }
Такие банальности давали прирост порядка 40% при обходе массива пикселей картинок к примеру. Причем такие приемы работают в nodejs чуть лучше чем в php.
Maiami
28.01.2017 06:53+5Если добавить немного «логики» в вычисления, и запоминать результат вычислений, то разница уже не в пользу php (кроме ассоциативного массива, с которым в js всегда было не очень хорошо, и на замену сейчас рекомендуется использовать Map там где критична скорость)
node 7.3.0
test1 (str): 67.853ms str len: 1000000 sb test2 (sum): 8.685ms sum: 2500000 test3 (array): 53.455ms array len: 1000000 z test4 (obj): 1036.474ms obj1: b obj2: a test Map: 575.344ms obj1: b obj2: a
php 7.1.1
test1 (str): 83.961ms str len: 1000000 sb test2 (sum): 69.857ms sum: 2500000 test3 (array): 63.453ms array len: 1000000 z test4 (obj): 206.375ms obj1: b obj2: a
для js напримерlet intns = 1000000 console.log(`\n`) console.time('test1'); var str = ''; for (var i = 0; i < intns; i++) { if (str.length % 2 === 0) { str += (i % 2 == 0) ? 's' : 'z'; } else { str += (i % 2 == 0) ? 'a' : 'b'; } } console.timeEnd('test1'); console.log('str len: ' + str.length + ' ' + str[0] + str[intns - 1]) console.log(`\n`) console.time('test2'); var count = 0; for (var i = 0; i < intns; i++) { if (count % 2 == 0) { count += (i % 2 == 0) ? 1 : 2; } else { count += (i % 2 == 0) ? 3 : 4; } } console.timeEnd('test2'); console.log(`sum: ${count}`) console.log(`\n`) console.time('test3'); var array = []; for (var i = 0; i < intns; i++) { array.push((i % 2 == 0) ? 's' : 'z'); } console.timeEnd('test3'); console.log(`array len: ${array.length} ${array[intns - 1]}`) console.log(`\n`) console.time('test4'); var obj = {}; for (var i = 0; i < intns; i++) { obj['s' + i] = (i % 2 == 0) ? 'a' : 'b'; } console.timeEnd('test4'); console.log(`obj1: ${obj['s' + (intns - 1)]}`) console.log(`obj2: ${obj['s' + 0]}`) console.log(`\n`) console.time('test Map'); var objMap = new Map(); for (var i = 0; i < intns; i++) { objMap.set('s' + i, (i % 2 == 0) ? 'a' : 'b'); } console.timeEnd('test Map'); console.log(`obj1: ${objMap.get('s' + (intns - 1))}`) console.log(`obj2: ${objMap.get('s' + 0)}`)
nikitasius
30.01.2017 13:18Я не разбираюсь ни в node.js, ни в php, но уверен, что тесты зависят от реализации.
вот результат на Java (1.8.0_102) с рабочего ноута (Intel® Core(TM) i5-5200U CPU @ 2.20GHz)
test1 (StringBuilder): 39 ms str len: 1000000 sb test2 (sum): 8 ms sum: 2500000 test3 (Stack): 52 ms stack len: 1000000 z test3 (Array): 20 ms array len: 1000000 z test4 (array fill): 21 ms obj1: b obj2: a test Map (hashmap-Integer): 119 ms obj1: b obj2: a test Map (hashmap-String): 402 ms obj1: b obj2: a
И я надеюсь, что на node.js и на php можно улучшить результаты.
- test 1 — на нем при использовании String (как в примере теста) Java просто завалится, ибо будет ад и содомия по созданию строк! Поэтому надо использовать StringBuilder.
- test 2 — без комментариев.
- test 3 — при использовании обычного Array колоссальный выигрышь, если же сделать через пуши (на примере Stack из Java), то падение производительности.
- test 4 — так как map вы выделили в отдельный тест, у меня не хватило логики и знаний, чем заменить массивы с ключем типа Object (хотя бы через String) в Java без map, честное слово хз, поэтому оставил как просто заполнение массива ну и размер на 's' (код символа s) больше (что никак не отразилось на скорости). Тест же
массивамепы со строковым ключем в 5м тесте. - test Map — обычный хешмап (размер равен вашему 1,000,000 при коэффициенте загрузки 0.7f против 0.75f базовых).
код программыimport java.util.Calendar; import java.util.HashMap; import java.util.Map; import java.util.Stack; public class TestSpeed { TestSpeed() { } public static void main(String[] args) { try { int intns = 1000000; long time1 = Calendar.getInstance().getTimeInMillis(); StringBuilder str = new StringBuilder(""); for (int i = 0; i < intns; i++) { if (str.length() % 2 == 0) { str.append((i % 2 == 0) ? 's' : 'z'); } else { str.append((i % 2 == 0) ? 'a' : 'b'); } } long time11 = Calendar.getInstance().getTimeInMillis(); System.out.printf("test1 (StringBuilder): %d ms\n", (time11 - time1)); System.out.printf("str len: %d %s%s\n\n", str.length(), str.charAt(0), str.charAt(intns - 1)); //------ long time2 = Calendar.getInstance().getTimeInMillis(); int count = 0; for (int i = 0; i < intns; i++) { if (count % 2 == 0) { count += (i % 2 == 0) ? 1 : 2; } else { count += (i % 2 == 0) ? 3 : 4; } } long time22 = Calendar.getInstance().getTimeInMillis(); System.out.printf("test2 (sum): %d ms\n", (time22 - time2)); System.out.printf("sum: %d\n\n", count); //------ long time3 = Calendar.getInstance().getTimeInMillis(); Stack array = new Stack<>(); for (int i = 0; i < intns; i++) { array.push((i % 2 == 0) ? 's' : 'z'); } long time33 = Calendar.getInstance().getTimeInMillis(); System.out.printf("test3 (Stack): %d ms\n", (time33 - time3)); System.out.printf("stack len: %d %s\n\n", array.size(), array.get(intns - 1)); time3 = Calendar.getInstance().getTimeInMillis(); char[] array2 = new char[intns]; for (int i = 0; i < intns; i++) { array2[i] = (i % 2 == 0) ? 's' : 'z'; } time33 = Calendar.getInstance().getTimeInMillis(); System.out.printf("test3 (Array): %d ms\n", (time33 - time3)); System.out.printf("array len: %d %s\n\n", array.size(), array.get(intns - 1)); //------ long time4 = Calendar.getInstance().getTimeInMillis(); char[] obj = new char[intns + 's']; for (int i = 0; i < intns; i++) { obj['s' + i] = ((i % 2 == 0) ? 'a' : 'b'); } long time44 = Calendar.getInstance().getTimeInMillis(); System.out.printf("test4 (array fill): %d ms\n", (time44 - time4)); System.out.printf("obj1: %s\n", obj['s' + (intns - 1)]); System.out.printf("obj2: %s\n\n", obj['s' + 0]); //------ long time5 = Calendar.getInstance().getTimeInMillis(); Map<Integer, String> objMap = new HashMap<>(intns, 0.7f); for (int i = 0; i < intns; i++) { objMap.put('s' + i, (i % 2 == 0) ? "a" : "b"); } long time55 = Calendar.getInstance().getTimeInMillis(); System.out.printf("test Map (hashmap-Integer): %d ms\n", (time55 - time5)); System.out.printf("obj1: %s\n", objMap.get('s' + (intns - 1))); System.out.printf("obj2: %s\n", objMap.get('s' + 0)); time5 = Calendar.getInstance().getTimeInMillis(); Map<String, String> objMap2 = new HashMap<>(intns, 0.7f); for (int i = 0; i < intns; i++) { objMap2.put("s" + i, (i % 2 == 0) ? "a" : "b"); } time55 = Calendar.getInstance().getTimeInMillis(); System.out.printf("test Map (hashmap-String): %d ms\n", (time55 - time5)); System.out.printf("obj1: %s\n", objMap2.get("s" + (intns - 1))); System.out.printf("obj2: %s\n", objMap2.get("s" + 0)); } catch (Throwable t) { t.printStackTrace(System.err); } } }Maiami
30.01.2017 14:05test1
В js по сути тоже самое, вместо resultStr += newStr при большом кол-ве объединений строк лучше использовать
arr.push(newStr); resultStr = arr.join('');
Это и памяти израсходует намного меньше и выполнится быстрее
Результаты вашего теста на той же машине, что и php и js (если вам интересно):
test1 (StringBuilder): 46 ms str len: 1000000 sb test2 (sum): 16 ms sum: 2500000 test3 (Stack): 42 ms stack len: 1000000 z test3 (Array): 17 ms array len: 1000000 z test4 (array fill): 15 ms obj1: b obj2: a test Map (hashmap-Integer): 143 ms obj1: b obj2: a test Map (hashmap-String): 394 ms obj1: b obj2: a
То что java выигрывает по скорости вполне ожидаемо

Source
30.01.2017 14:10+1Обычно при сравнении производительности просто пишут эквивалентный код на разных языках, цели написать его оптимально при этом нет, скорее наоборот. Поэтому StringBuilder применять в данной случае нельзя, т.к. автор поставил задачу замерить именно скорость "ада и содомии по созданию строк".
А то Вы такими темпами второй тест редуцируете до строчкиcount = 1000000и так далее.
В общем, сравнения должны быть честными, вне зависимости от того, что сравнивается.nikitasius
30.01.2017 14:45-1Тогда уж давайте скажем так:
Обычно при сравнении производительности просто пишут эквивалентный код на разных языках с эквивалетной внутренней реализацией, цели написать его оптимально при этом нет, скорее наоборот.
PHP и node.js съедаютstr+="a";, а Java каждый раз создает новую строку.
От таких тестов смысла нет.
А вот в чем есть смысл: наиболее оптимальное и быстрое решение конкретной задачи на том или ином языке. Вот такие тесты покажут перфоманс языка.
А сравнивать сложение строчек, или обычные массивы — глупости и трата. Вот самую эффективкую обработку входных данных на языка А против аналогичного конечного результата на языке Б стоит потраченных ресурсов.Fortop
30.01.2017 14:56-2Вы пошли как бы не на третий заход.
Чуть выше этот вопрос поднимался разными людьми.
Но дети не хотят по вашему, они хотят лепить…
Shannon
30.01.2017 15:07+2Не скажу про php, но js не съедает, а каждый раз создает новую строку, что равносильно тому что в jave
То о чем вы пишите имеет конкретное название «лучшая реализация алгоритма», и там уже важно кто лучше или умнее реализовал тот-то момент, а то и правда можно написать просто «count = 1000000». К производительности в лоб 2х языков это не имеет отношения
Автор глупость сравнивает, но даже в таком случае должно быть разъяснение почему и где ошибки, чтобы на более продуманных тестах такую ошибку не допустить (автором или тем кто читает тему)
Именно с технической точки зрения, а не с «надо/не надо»
Как выше заметили, «сравнения должны быть честными, вне зависимости от того, что сравнивается»
а уже ценность этих сравнений другой вопрос
Source
30.01.2017 16:24+2Смысл есть от любых сравнений. Если сравнивать скорость конкатенации строк, то можно узнать, что в Java она медленная. А перфоманс языка надо уже на более сложных алгоритмах смотреть, но там каждый тест должен эксперт по конкретному языку писать, а не так, как это обычно бывает в интернете )))
Fesor
30.01.2017 18:02Если сравнивать скорость конкатенации строк, то можно узнать, что в Java она медленная.
неверно. Можно узнать что кривое управление памятью приводит к проблемам с производительностью.
Другой момент что если компилятор вам может сам переделать ваш код в тот, который максимально эффективным способом распоряжается памятью, то это уже другой показатель.
Source
31.01.2017 00:11+1Тут смысл именно сравнить
str += 's'и$str .= 's', как эквивалентные операции. А после того, как выяснили, что конкатенация строк в Java медленная, надо задавать себе правильные вопросы, например: "а почему она медленная?". И разумеется, глупо отвечать "потому что в Java кривое управление памятью"… вообще никогда не списывайте на то, что язык плох. Языки пишут отнюдь не идиоты, кроме того в их разработку вкладываются огромные средства. Поэтому не бывает что-то медленно без причины, это всегда следствие определенных компромиссов, которые дают другие преимущества.Fortop
01.02.2017 11:24-2Там не было сказано, что в Java кривое управление памятью.
Операции += и .= подразумевают инкрементальное увеличение памяти на каждом шаге, что на этапе когда у вас заканчивается непрерывный блок памяти вызывает проблемы, поэтому их просто не стоит выполнять в циклах с большим числом итераций и/или размерами строк.
В большинстве остальных случаев это не вызывает проблем.Source
01.02.2017 12:53+2Вы ветку комментариев то читаете или к чему Ваш комментарий? Про кривое управление памятью Fesor писал двумя сообщениями выше.
Fortop
01.02.2017 13:02-2Чукча не читатель, чукча писатель.
Про кривое управление памятью Fesor писал двумя сообщениями выше.
Именно. И он не писал что в Java кривое управление памятью.
У меня сложилось впечатление, что Fesor имеет представление о том как происходит аллокация памяти. Чего не знают обычно пользователи скриптовых и языков с динамической типизацией.
И именно на это он ссылался, что проблема не в конкатенации, а в управлении памятью со стороны разработчика.Source
01.02.2017 13:49+3У меня сложилось впечатление, что Fesor имеет представление о том как происходит аллокация памяти. Чего не знают обычно пользователи скриптовых и языков с динамической типизацией.
Очень самокритично )
Так и быть, просвещу Вас: в Java строки иммутабельны и вместо конкатенации по факту происходит создание новой строки, поэтому Ваш пассаж про непрерывный блок памяти вообще мимо кассы.Fortop
01.02.2017 14:06-2Так и быть, просвещу Вас: в Java строки иммутабельны
Это может иметь значение в определенных ситуациях.
Формулу стоимости обсуждаемой операции в общем виде можно выразить примерно так
cost = N*CA+BR*CR+BW*CW
где
N — количество вызовов аллокации блока
CA — стоимость аллокации блока.
BR — количество блоков, которые требуется прочитать
CR — стоимость чтения блока.
BW — количество блоков которые требуется записать
CW — стоимость записи блока.
Так вот по вашим словам в Java при каждой конкатенации будет происходить копирование всего блока памяти. В других языках это может происходить только по окончании непрерывного блока памяти, но тоже будет происходить.
И все это не отменяет тот факт, что проблема будет не в самой конкатенации, а в управлении памятью при этом.
Fesor
01.02.2017 23:40в Java строки иммутабельны и вместо конкатенации по факту происходит создание новой строки,
в PHP тоже, да и в javascript-те.
поэтому Ваш пассаж про непрерывный блок памяти вообще мимо кассы.
А еще давайте посмотрим дальше.
у нас есть цикл, на каждую итерацию мы выделяем новый буфер в памяти, копируем и т.д. и т.п. Непрерывные всякие блоки в памяти тут вообще не причем, но что важно так это то что у нас есть прямая зависимость по данным в каждой итерации. На каждой итерации мы используем результат предыдущей. И тут рантайм ничего не сделает. И к тому что нам нужно на каждый чих перевыделять память так еще и с точки зрения конвейеризации все плохо.
Про кривое управление памятью Fesor писал двумя сообщениями выше.
Мое замечание было про то, как памятью управляют разработчики, а не JVM (там внутри все очень даже хорошо с этим). Я лишь говорил что если мы берем два рантайма, и один рантайм учитывает и оптимизирует криворукость разработчика а другой нет — это будет весомый плюс для оного. Но пример с канкатенацией из статьи ни один рантайм не пофиксит.

PaulZi
28.01.2017 11:07+3А ведь недавно, в 5 версии, PHP был жутким тормозом по сравнению с JavaScript.
Результаты, лично для меня, говорят, что теперь не важно, на чём вы пишите, важно как — говнокод можно реализовать на любой платформе и языке.

jehy
28.01.2017 11:18+3Ну сколько же можно сравнивать тёплое и мягкое? При этом путём засовывания молотка в задницу.

youROCK
28.01.2017 13:02В целом, маловероятно, чтобы ванильный PHP был быстрее JavaScript'а для долгоживущих процессов, в которых JIT уже успел всё соптимизировать. Впрочем, если по какой-то причине вы упираетесь в вычисления, можете попробовать HHVM или kPHP, они могут вас удивить.

SamDark
28.01.2017 14:02+2kPHP удивляет, но не производительностью. А HHVM по факту сравнялся с PHP 7.
youROCK
28.01.2017 14:04+2Ну, все же, всё зависит от того, какой код вы будете бенчмаркать. Если это «обычный код на PHP», то да, от HHVM большого толку, скорее всего, не будет. А вот если это вычисления, да ещё и с указанием scalar type hints и прочее, да ещё и с использованием .hhbc формата, разница может быть очень существенной.

xRay
28.01.2017 14:06-2Если уж сравнивать с Node.js так надо сравнивать с ReactPHP.
И вот хороший прогон тестов https://gist.github.com/nkt/e49289321c744155484c#gistcomment-1970430
По итогам теста PHP 7 быстрее.
michael_vostrikov
28.01.2017 16:43Не совсем по теме, но насчет конкатенации строк в PHP была такая мысль.
Насколько я знаю, там сейчас после каждой конкатенации создается новая строка, то есть перевыделяется память. А что если не конкатенировать сразу, а внутри строкового типа хранить список исходных строк. А итоговое значение получать только при некоторых операциях типа поиск/замена. Что-то вроде string builder-а в C# и Java. Мне кажется, производительность в коде наподобие теста из статьи была бы выше.
Вроде недавно для encapsed-строк что-то такое сделали, но там это работает в пределах одного выражения. Никто не в курсе, разработчики что-нибудь думали на эту тему?
dim_s
28.01.2017 23:27Так PHP и делает, по крайней мере, когда идет постоянная работа с оператором ".=" (добавление к строке). На уровне реализации языка включается внутренний StringBuilder.
Fesor
29.01.2017 15:40+1Если вы напишите код вроде такого:
$foo = 'foo'; $foo .= 'bar'; $foo .= 'baz';
то PHP будет выполнять следующее:
line #* E I O op fetch ext return operands ------------------------------------------------------------------------------------- 3 0 E > ASSIGN !0, 'foo' 4 1 ASSIGN_CONCAT 0 !0, 'bar' 5 2 ASSIGN_CONCAT 0 !0, 'baz' 3 > RETURN 1
то есть по сути у нас будет одна операция присвоения и две операции конкатенации. Никаких буферов и прочего.
С другой стороны в php7.1 уже добавлена оптимизация для интерполяции строк:
$foo = "{$foo}{$bar}{$baz}";
Вот при таком раскладе будет буфер для записи результата будет создан один раз под итоговый размер. Собственно может быть в 7.2 впилят и оптимизации позволяющие проделывать это и для простых операций конкатенации но увы пока нет.

amakhrov
29.01.2017 00:38console.time('Node.js ' + process.version + ': mysql query (SELECT NOW()) 100 раз'); for (var i = 0; i < 100; i++) { // вызов асинронного кода с промисами } console.timeEnd('Node.js ' + process.version + ': mysql query (SELECT NOW()) 100 раз');
Этот код запускает 100 запросов к БД параллельно, и завершается, не дождавшись их выполнения.
В этой связи очень странно, что время node-кода больше, чем время php-кода, который все запросы выполнил последовательно. Как так вышло вообще?MaZaAa
29.01.2017 10:23-2Создание каждого промиса само по себе достаточно дорого стоит, отсюда и такой результат.
Maiami
29.01.2017 22:29+2Нет, промисы дешево стоят, не сильно дороже callback (особенно если использовать bluebird)
Вы закрыли соединение до того, как промисы успели обратиться к базе. Поэтому они выкидывают сообщения об ошибках, а не тестируют соединение. А вот выкидывать сообщения об ошибках уже более дорогая операция, чем соединениеMaZaAa
29.01.2017 22:46-2Я буквально месяц назад замерял разницу в скорости, между нативными промисами, Bluebird и callback'ами, так вот, callback'и выигрываю в разы… Не верите, убедитесь в этом сами. Это довольно легко.
Maiami
30.01.2017 01:16+2Уже проверяла, разница минимальна, но в данном тесте это не играет роли, по причинам которые выше написала
Fesor
29.01.2017 15:42Приведите код который вы вызываете. Это может быть как стоимость абстракции (у вас же там пул соединений и очередь запросов, а не тупо промисы) а может еще чего. А еще возможно еще не прогрелся код и вы гоняете не оптимизированную версию.
В целом если мы хотим честный бенчмарк и используем язык работающий с JIT, стоит тестируемый код хорошенько прогреть перед тем как делать сам бенчмарк.
amakhrov
29.01.2017 20:56Это не я вызываю, это код автора статьи. И результаты, приведенные в статье: 9ms на php и 13ms на node.
Source
29.01.2017 02:181000 запросов в 1000 потоков через ab в качестве нагрузочного тестирования? Вы серьёзно?
Запустите нормальный нагрузочный тест, что-нибудь типа:
wrk -t 4 -c 100 -d30s --timeout 2000 http://127.0.0.1:8080MaZaAa
29.01.2017 10:43-1# wrk -t 4 -c 100 -d30s --timeout 2000 http://127.0.0.1:3000
# zmalloc: Out of memory trying to allocate 16000000040 bytes
У меня не достаточно памяти на сервере чтобы прогнать этот бенчмарк)Source
29.01.2017 12:20+1Попробуйте поставить -t равным кол-ву ядер на сервере, и плавно снижать -c, пока не влезет.
Главное, время выполнения оставьте, а то ваш вариант теста в течении 300 миллисекунд вообще не отражает реальность.
P.S. И wrk не с сервера запускайте, а с локального компа.
Maiami
29.01.2017 22:23+1Хоть wrk, хоть ab (которые действительно надо запускать не на тестируемой машине, а на удаленной)
Автор всё равно сравнивает 5 тредов php-fpm против 1-го в ноде
Нужно либо ноду в кластере запускать, либо у php-fpm дефолтные настройки снизить
https://habrahabr.ru/post/320670/#comment_10039552MaZaAa
29.01.2017 23:19-2Кластер запускается когда процессор многоядерный. Тоже самое касается и Nginx, где worker_processes рекомендуется ставить = числу ядер. А у меня процессор одноядерный. Тем более, я само собой запускал ноду в кластере и результат — гораздо хуже. Т.к ядро у меня одно.
Maiami
30.01.2017 01:27+1И конечно же в случае кластера вы не ставили nginx перед node…
Чтобы упростить задачу, у php-fpm снизьте до 1 server-start (и 0 чилдов), потому что у вас в 5 раз больше php обработчиков (которые работают как треды, а не как воркеры), а результат всего на 23% лучше, что говорит не в пользу phpFesor
30.01.2017 02:55+1которые работают как треды, а не как воркеры
Вообще-то как воркеры. Ну то есть там поднимаются полноценые процессы-воркеры.
а результат всего на 23% лучше, что говорит не в пользу php
это больше говорит о блокируемых штуках. Вообще весь этот бенчмарк весьма и весьма сомнительный. Как минимум потому что PHP в плане инфраструктуры еще не может тягаться с нодой. А производительности самого языка хватает да.
Maiami
30.01.2017 02:05+2Стенд на виртуалке с 1 ядром:
1 треад:
php-fpm: 1612 req/sec
node.js: 3854 req/sec
5 тредов:
nginx+php-fpm: 5373 req/sec
nginx+node.js: 9845 req/sec
Не знаю уж как вы тестировалиFortop
30.01.2017 04:38Вообще-то придираться к частностям числодробилки малость бессмысленно.
Если сильно хочется что-то проверить, то стоит тестировать конкретное приложение (даже не hello world).
Естественно на двух языках.
В треде уже давали ссылку на коллективный бенчмарк. Нода быстрее пхп примерно в 2-3 раза в среднем.
Но с точки зрения бизнеса совсем не факт, что разработка на ней быстрее и дешевле для получения сопоставимой производительности.Maiami
30.01.2017 05:53+1Числодробилки тоже надо тестировать правильно, раз уж кто-то взялся их сравнивать:
https://www.youtube.com/watch?v=HPFARivHJRYFortop
30.01.2017 05:59-2Уже сравнили
Но в критически важных местах я просто напишу расширение, которое будет быстрее ноды в те же самые 3-5 разMaiami
30.01.2017 06:03+2Эта ссылка уже приводилась, речь не про нее. Речь про то, что те кто хотят сравнить свои сценарии использования, должны учитывать некоторое особенности работы оптимизаторов и по ссылке видео где рассказывается как правильно сравнить (там пример для js, но общий смысл для всех систем один)
Fortop
30.01.2017 06:05-2Если они сравнивают «свои сценарии использования», то о чем вообще речь?
Вот в сценариях топикстартера сравнение такое.
Но вы его критикуете.
Вы предлагаете заменить их сценарий на ваш?Maiami
30.01.2017 06:34+2Я лишь добавила в его сценарий необходимый минимум, чтобы тестирование было объективным. А так же указала, что доступ к mysql сделан с ошибкой, и сравнение веб-серверов сделано не правильно
То что подобное сравнение совершенно бессмысленно, этот вопрос уже в другой ветке обсуждалсяFortop
30.01.2017 06:36-3Давайте будем откровенны и формальны.
Вы на базе его сценария создали свой и настаиваете на его правильности.
Но ваш сценарий =/= его сценариюMaiami
30.01.2017 06:50+2Нет, не будем формальны, будем логичны
Начало статьи
Всем привет, решил поделиться с вами результатами синтетического теста производительности свежих версий PHP и Node.js.
Эти синтетические тесты сделаны с ошибкой, в видео рассказывается причина таких ошибкой. На ошибки указано, новые результаты приведены. Особо больше тут нечего обсуждатьFortop
30.01.2017 06:59-3Ок. Будем логичны.
Тогда все еще печальнее для вас.
Для определения того что тесты сделаны с ошибками надо знать какая логика закладывалась в них.
Потому что «производительность» там тестируется. То что там тестируется производительность логики работающей с ошибками не делает утверждение ложным
Вместе с тем.
Вы этой информацией (о неправильно реализации логики, которую собирались тестировать) без уточнения у автора, не обладаете.
А значит ваши выводы об ошибках не могут быть сделаны логическим рассуждением без привлечения вашихфантазийдопущений и следовательно не базируются на логике.
Но вы их делаете «до» получения уточнения от автора.
Следовательно вы придумали свой личный сценарий и пытаетесь навязать его.
Так в чем же у вас логика? :)
Пока её отсутствие проявилось
Maiami
30.01.2017 07:09+2Логика в том, что бенчмарки производительности не подразумевают сравнение пустого по смыслу цикла (оптимизатор выкинул всё из него, потому что результат не фиксируется дальше по программе, или заинлайнил весь цикл, потому что понял что ничего особенного в цикле не происходит). Так работают оптимизаторы, именно об этом рассказывается в видео
Но в статье анонсировано сравнение производительности, а не сравнение чем оптимизатор лучше детектит бессмысленные циклы. Поэтому в эти циклы нужно добавить немного «логики» и считывать результат выполнения в этих циклах. Вот это и называется логика
Но если вы продолжаете настаивать, что автор хотел именно сравнить пустые по смыслу циклы, то опять же, обсуждать тут нечегоFortop
30.01.2017 07:18-3Логика в том, что бенчмарки производительности не подразумевают сравнение пустого по смыслу цикла
Это ваши личные фантазии.
Вы мне напоминаете любителей анаши, которые порицают прочих курильщиков.
Более того ваши знания об оптимизаторах как php так и nodejs мною оценены быть не могут, но вы сами признались что в php разбираетесь крайне плохо.
На основании чего вы сделали вывод, что в указанном коде php произведёт удаление неиспользуемого кода?
Дальше все еще интереснее.
Производительность это эффективность выполнения той или иной операции.
Но… Скажите мне, с какого бодуна вы решили, что для сравнения производительности необходимо кастрировать php и nodejs убрав влияние их оптимизаторов?
Вообще-то, они (оптимизаторы) для того и созданы, чтобы улучшить производительность.
Внезапно?
P.S. Я понятия не имею что хотел автор.
На мой вкус его и ваши позиции бредовые.
Но вас не устраивает этот факт :-DMaiami
30.01.2017 07:24+2Да, внезапно. Внезапно стало понятно, что вы видео не смотрели, не понимаете как работают оптимизаторы, вы не поняли о чем статья и к чему были правки, но так как вам скучно, вы захотели тянуть кота за хвост и выдумали себе тему для беседы
Fortop
30.01.2017 07:30-3Девочка, видео я честно просмотрел первые минут 15. Нового ничего для себя не вынес.
Ну не откровение это для меня. А детали V8 меня на данный момент не слишком беспокоят.
Тема беседы в том, что вы дурочки оба. Но одна по какой-то причине считает что права именно она.
Тогда как ошибаетесь вы с автором оба.
Хотите производительности — занимайтесь профилированием конкретных приложений. А не выкидывайте оптимизиторы, opcache, jit-компилятор и прочее.Maiami
30.01.2017 07:41+3Тогда странно, что вы умудряетесь говорить очевидные глупости вроде:
«Скажите мне, с какого бодуна вы решили, что для сравнения производительности необходимо кастрировать php и nodejs убрав влияние их оптимизаторов?»
Впрочем фраза «вы дурочки оба» хорошо вас характеризуетFortop
30.01.2017 08:18-3Ровно потому что это не глупости.
Но до вас это дойдёт позже (а может и никогда), ваш пиетет перед информацией КО из ролика наглядно показывает объем ваших знаний и способности что-то оценивать — для вас это все открытие.
Вы не понимаете простой вещи — ваша идея бенчмарков глупа априори, поскольку к реальной производительности имеет очень слабое отношение.
В реальности же отключать оптимизиторы и намеренно ухудшать будет либо мегагуру, для достижения своих непонятных целей, либо упоротый.
И с этой позиции абсолютно фиолетово, кто из вас двоих глупее.
Доступно?Maiami
30.01.2017 08:25+3То что вы упорно твердите про отключение оптимизатора (хотя даже намека на это нет, и если бы вы разбирались или если были бы внимательнее, то уже поняли бы это), говорит о том, что вы совершенно не понимаете о чем говорите, но при этом оскорбляете других
Fortop
30.01.2017 08:44-3То что вы упорно твердите про отключение оптимизатора (хотя даже намека на это нет, и если бы вы разбирались, то уже поняли бы это)
Девочки такие девочки…
Логика как обычно и рядом не стояла, а за своими словами не следят…
Печалька.
Ну что же цитируем намёки
Если добавить немного «логики» в вычисления, и запоминать результат вычислений, то разница уже не в пользу php
Прямой отсыл на работу оптимизаторов, которые удаляют неиспользуемый код, разворачивают циклы, хвостовые рекурсии сводят к циклам и т.п.
И вы хотите своим советом исключить это влияние оптимизации — читай выключить оптимизатор в данном случае.
Нужно либо ноду в кластере запускать, либо у php-fpm дефолтные настройки снизить
Не про оптимизацию, но последовательность взгляда прослеживается — максимально уйти от реальности.
На ваши ошибки в предположениях указывали в той же нити.
должны учитывать некоторое особенности работы оптимизаторов и по ссылке видео где рассказывается как правильно сравнить
Вот не знаю что после первых 15 минут, может что-то уникальное (но если бы это было так, то эту конкретику вы бы уже привели), а вообще в видео речь идёт о том, как «отключать» оптимизатор. Каким именно образом создавать паразитную нагрузку, чтобы он ваш реальный код не оптимизировал и вы смогли бы атомарно провести бенчмарк для неоптимизированной операции.
Там очень мало информации и не делается акцент на корректных фикстурах для бенчмарков и подходе в их использовании.
Эти синтетические тесты сделаны с ошибкой, в видео рассказывается причина таких ошибкой
Йо? Опять?
Ну откройте же тайну… Чего же надо сделать кроме того о чем говорилось выше — нивелировать влияние оптимизатора…
Ну так что?
Отвечать за свои слова и признавать свою неправоту будем?
Maiami
30.01.2017 08:49+2Понятно, вы не разбираетесь от слова совсем, и не понимаете что в этой теме происходит, и наговорили только что кучу ерунды. Не вижу смысла продолжать
Fortop
30.01.2017 08:51-4ЧТД.
Девочка такая девочка…
P.S. Техника построения микробенчмарков это частный случай реализации юнит-тестов.
Почитайте-ка литературу об этом, судя по вам это будет вашим следующим озарением после видеоролика :-D
michael_vostrikov
30.01.2017 11:12+1Для определения того что тесты сделаны с ошибками надо знать какая логика закладывалась в них. Потому что «производительность» там тестируется. То что там тестируется производительность логики работающей с ошибками не делает утверждение ложным
Насколько я понял из комментов выше:
Есть 2 теста. Один читает из базы, во втором чтения из базы нет, а происходят ошибки. Значит измеряется время разных действий. В статье была заявлена цель сравнить время одинаковых действий. Вывод: тесты сделаны с ошибками, результаты сравнивать бессмысленно.
Извините, но по-моему логики нет у вас.
Fortop
30.01.2017 11:51Насколько я понял из комментов выше:
Вы сейчас об одной и той же ветке рассуждаете?
Проблемы автора, описанные тут
https://habrahabr.ru/post/320670/#comment_10040720
В данной нити не поднимались.
Поэтому попробуйте доказать отсутствие логики в «моих» репликах ещё раз.
Shannon
30.01.2017 13:11+1Вся ветка ни о чем
Логики в ваших репликах не больше чем в смысле тестов из статьи
Автор хотел протестировать производительность
1. чтобы протестировать производительность, нужно совершить какую-то работу
2. чтобы совершить работу нужно чтобы эта работа была сделана, а не выкинута оптимизатором как «результат не используется дальше по коду, можно скипнуть»
3. цикл для того чтобы сэмитировать много работы
4. в цикл добавляется смысл, чтобы оптимизатор попал в более инетерсные условия, чем никому не интересные сложения чисел
5. после цикла работа с результатом
Оптимизатор пускай оптимизирует именно работу, что и интересует в вопросе производительности, тут вообще нечего обсуждать, это азы, даже знаменитый performance.js работает именно так (только чуть сложнее)
Коллеги, не тратье время на тролля, приберегите еду для более интересного случаяFortop
30.01.2017 14:03-2чтобы протестировать производительность, нужно совершить какую-то работу
Не «какую-то», а полезную это ключевой момент, который надо понимать и который похоже не понимаете ни вы, ни юная девочка.
И обладая этим воистину сокровенным знанием попытайтесь теперь оценить корректность и авторских и исправленных тестов.
Даю подсказку — она нулевая.
Те же тесты на debian.org отличаются в лучшую сторону тем, что проверяют производительность на алгоритмахShannon
30.01.2017 14:19+2Нее, так и написал же, «Не «какую-то», а полезную» :D
Оптимизатор такой смотрит на код и думает «а полезная ли это работу, или можно пока на печи поваляться» *и руки в боки у него*
Всё таки наверное можно немного покормить:
С вами бесполезно говорить, вы оперируете терминами «полезная работа, тесты на debian.org отличаются в лучшую сторону», еще чуть чуть и вообще не важно, что в этих комментариях обсуждается конкртено эта статья, и будем мысли Fortop читать, лишь бы знать, что есть полезная работа, а что бесполезная :D
Оптимизатору пофиг что оптимизировать, можно и такой примитив как тут сравнить, лишь бы делать это правильно
Ждем искрометных шуток про то, что мы не понимаем, что такой примитив нельзя сравнивать, надо алгоритмы, алгоритмы надоFortop
30.01.2017 14:28-2Мысли читать не нужно.
Нужно заниматься профилированием.
Если так уж хочется тестирование производительности, то пишете реальное приложение и тестируете его.
Производители бенчмарков типа 3DMark ваши грабли собрали лет десять назад.
Именно поэтому никто особо и не тестирует сейчас сколько полигонов можно отрендерить (читайте выполнить в цикле пачку бесполезных запросов вида SELECT NOW())
Shannon
30.01.2017 14:32+1Нее, у меня столько еды нет, мне работать надо :D
Но последняя порция всё таки:
Ауу, то что тестирование из статьи бесполезное уже абсолютно все поняли, еще до того как вы в этой теме появились. Речь до сих пор идет лишь про то, что даже такой примитив надо тестировать по канонам, начинаешь с малого, доходишь до большего. На простых примерах легче показать, на больших примерах легче реализовать и т.д. и т.п.Fortop
30.01.2017 14:38-2Речь до сих пор идет лишь про то, что даже такой примитив надо тестировать по канонам
Не надо.
Вы пришли к той же позиции, что и девочка выше — «а давайте улучшим пирожок из какашек добавками со вкусом клубники и ванили», и «вы тут его недосолили».Shannon
30.01.2017 14:49+1Да-да-да, а еще кароче единороги существуют, и они пишут идеальный код для тестирования, но к сожалению мы такой никогда не увидим, потому что в реальности ни у кого нет времени 2 полноценных приложения для 2х разных платформ, с учетом особенностей этих платформ, написать
Вот и приходится в вариациях «пирожков из какашек» барахтаться (у кого-то получше-повкуснее, как у debian.org, если верить вашему вкусу), но всё равно они шо то ..., шо то…
Я так понимаю еды у вас уже достаточно, потому что «аууу, то что вы говорите настолько очевидно, что в приличном обществе это даже не обсуждают, это всё и так знают» :DFortop
30.01.2017 14:51-2потому что в реальности ни у кого нет времени 2 полноценных приложения для 2х разных платформ, с учетом особенностей этих платформ, написать
Поэтому пользуйтесь тем, что вам даёт community.
Ссылка тут неоднократно приводилась.Shannon
30.01.2017 14:56+1Ой, йой, только вот по ссылке точно такая же «бесполезная» работа, с которой вы так яростно боритесь :D
А вот в комментариях реальная тема, обучение базовым основам тестирования по канонам, что куда полезнее ваших комментариев, которые настолько очевидны, что прям «аууу»Fortop
30.01.2017 15:08-1несколько более сложные алгоритмы, а не тестирование простейших операций
Вопрос корректности фикстур, прогрева кешей и jit-компиляторов открыт, поскольку не читал их методику измерения детально и там есть странные упоминания о запуске через popen(), но…
можете ознакомиться самостоятельно
Shannon
30.01.2017 15:26+1Блин, у нас в офисе уже ставки делают, будет ли следующий комментарий
2+2=4 :D
И про то, что качественные тесты лучше некачественных :DFortop
30.01.2017 15:46-3Беда в том, что вы и этих 2+2=4 не знаете, и продолжаете настаивать что все перечисленные в треде поправки внезапно сделают тесты правильными.
У вас там что? Полный офис таких же глупых?
michael_vostrikov
30.01.2017 13:48+3Нажмите стрелочку "вверх" несколько раз и найдите фразу "А так же указала, что доступ к mysql сделан с ошибкой, и сравнение веб-серверов сделано не правильно". Пожалуй, соглашусь с комментом выше.
Fortop
30.01.2017 13:55-2Что же вы все такие медленные…
На пальцах поясняю.
Понятия не имею, что хотел протестировать автор статьи. Но…
Даже с исправлениями мадам тесты не станут правильными. От слова вообще.
Слишком велика погрешность оценки для приложений и систем при таком подходе.
iShatokhin
29.01.2017 10:24+3Тест в один прогон? Чтобы включился JIT, нужно хотя бы парочку прогонов для прогрева, и тогда результаты для Node.js улучшаться. А вообще чистейшая синтетика не показатель реальной производительности будущего сервера.
MaZaAa
29.01.2017 10:26-1Я же писал, что было 10 прогонов, после этого были выбраны самые лучшие результаты. Первый прогон для ноды был гораздо хуже само собой, чем результат который я выложил.
iShatokhin
29.01.2017 13:19Как я понял, было выполнено десять запусков тестов по одному прогону, JIT так не работает, т.к. не сохраняет оптимизации между запусками процесса.
В одном запуске нужно сделать хотя бы три прогона теста и результаты первых двух отбросить.
Вы пытаетесь заставить работать Node.js как PHP — поднимаете и убиваете процесс на задачу, это не верно. У них разные парадигмы. Node.js процесс должен жить постоянно.
Maiami
29.01.2017 22:21Автор сравнивает 5 тредов php-fpm против 1-го в ноде
Нужно либо ноду в кластере запускать, либо у php-fpm дефолтные настройки снизить
https://habrahabr.ru/post/320670/#comment_10039552
yeti357
29.01.2017 13:50+1Тащемта, не знаю как в php, но в ноде(да и вообще не только в js, в зависимости от реализации) конкатенацию строк из более чем 10 элементов следует выполнять путём заполнения массива и последующего join-а этого массива. Ну и бывает такое что в ноде некоторые операции проседают в производительности при выходе новой версии(issues можно посмотреть на гитхабе), потом чинят, но осадочек остаётся.
Даже если в целом php стал быстрее, то что с того? Бежатьпереписыватьменять одно не типизированное шило на другое нетипизированное мыло?
mnepohyi
29.01.2017 21:56+1Сравнил с c#. Не стал сравнивать запросы к базе, т.к. нет mysql.
C#
Склеивание строк 1000000 раз: 6
Cложение чисел 1000000 раз: 1
Наполнение простого массива 1000000 раз: 5
Наполнение ассоциативного массива 1000000 раз: 505
Чтение файла 100 раз: 3
Node.js v6.9.2: склеивание строк 1000000 раз: 57.496ms
Node.js v6.9.2: сложение чисел 1000000 раз: 3.266ms
Node.js v6.9.2: наполнение простого массива 1000000 раз: 28.342ms
Node.js v6.9.2: наполнение ассоциативного массива 1000000 раз: 871.787ms
Node.js v6.9.2: чтение файла 100 раз: 6.732ms
Код c#
var timer = new Stopwatch(); timer.Start(); var sb = new StringBuilder(); for (int i = 0; i < 1000000; i++) { sb.Append('s'); } var str = sb.ToString(); timer.Stop(); Console.WriteLine("Склеивание строк 1000000 раз: " + timer.ElapsedMilliseconds); timer.Reset(); timer.Start(); var count = 0; for (int i = 0; i < 1000000; i++) { count++; } timer.Stop(); Console.WriteLine("Cложение чисел 1000000 раз: " + timer.ElapsedMilliseconds); timer.Reset(); timer.Start(); var array = new List<char>(); for (int i = 0; i < 1000000; i++) { array.Add('s'); } timer.Stop(); Console.WriteLine("Наполнение простого массива 1000000 раз: " + timer.ElapsedMilliseconds); timer.Reset(); timer.Start(); var dictionary = new Dictionary<string, char>(); for (int i = 0; i < 1000000; i++) { dictionary["s" + i] = 's'; } timer.Stop(); Console.WriteLine("Наполнение ассоциативного массива 1000000 раз: " + timer.ElapsedMilliseconds); timer.Reset(); timer.Start(); string context; for (int i = 0; i < 100; i++) { context = File.ReadAllText("SomeFile.txt"); } timer.Stop(); Console.WriteLine("Чтение файла 100 раз: " + timer.ElapsedMilliseconds); Console.ReadLine();Maiami
29.01.2017 22:27+1У вас та же проблема что и у автора, вот тут правильное сравнение с теми же тестами, но уже не пользу php:
https://habrahabr.ru/post/320670/#comment_10039552
Тесты в цикле нельзя просто прогнать, нужно еще результат запомнить и прочитать его после цикла, иначе оптимизатор просто выкинет половину из цикла, или вовсе схлопнет цикл
Из статьи видим, что php это делает более агрессивно чем js, достаточно добавить немного «логики» в вычисления и php уже отстаётMaZaAa
29.01.2017 22:52-2Добавил чтение результата после циклов, результат тот же, увы
Maiami
30.01.2017 01:31+1Не вижу в статье добавление чтения результата. Так же нужно хотя бы примитивную логику добавлять в любые микробенчмарки
Вот правильное тестирование (ваш тест только добавлена логика и чтение результата) и результат не в пользу php:
https://habrahabr.ru/post/320670/#comment_10039552
mnepohyi
29.01.2017 22:54+1Да, что-то я не подумал совсем об этом.
Склеивание строк 1000000 раз: 12
Cложение чисел 1000000 раз: 7
count: 3500000
Наполнение простого массива 1000000 раз: 8
array.length: 1000000
Наполнение ассоциативного массива 1000000 раз: 518
dictionary.length: 1000000
a
Чтение файла 100 раз: 3
var timer = new Stopwatch(); timer.Start(); var sb = new StringBuilder(); for (int i = 0; i < 1000000; i++) { if (sb.Length % 2 == 0) sb.Append(i % 2 == 0 ? 's' : 'z'); else sb.Append(i % 2 == 0 ? 'a' : 'b'); } var str = sb.ToString(); timer.Stop(); Console.WriteLine("Склеивание строк 1000000 раз: " + timer.ElapsedMilliseconds); Console.WriteLine(); timer.Reset(); timer.Start(); var count = 0; for (int i = 0; i < 1000000; i++) { if (count % 2 == 0) count += i % 2 == 0 ? 1 : 2; else count += i % 2 == 0 ? 3 : 4; count++; } timer.Stop(); Console.WriteLine("Cложение чисел 1000000 раз: " + timer.ElapsedMilliseconds); Console.WriteLine("count: " + count); Console.WriteLine(); timer.Reset(); timer.Start(); var array = new List<char>(); for (int i = 0; i < 1000000; i++) { array.Add(i % 2 == 0 ? 's' : 'z'); } timer.Stop(); Console.WriteLine("Наполнение простого массива 1000000 раз: " + timer.ElapsedMilliseconds); Console.WriteLine("array.length: " + array.Count); Console.WriteLine(); timer.Reset(); timer.Start(); var dictionary = new Dictionary<string, char>(); for (int i = 0; i < 1000000; i++) { dictionary["s" + i] = i % 2 == 0 ? 'a' : 'b'; } timer.Stop(); Console.WriteLine("Наполнение ассоциативного массива 1000000 раз: " + timer.ElapsedMilliseconds); Console.WriteLine("dictionary.length: " + dictionary.Count); Console.WriteLine(dictionary["s" + (dictionary.Count - 2)]); Console.WriteLine(); timer.Reset(); timer.Start(); string context; for (int i = 0; i < 100; i++) { context = File.ReadAllText("SomeFile.txt"); } timer.Stop(); Console.WriteLine("Чтение файла 100 раз: " + timer.ElapsedMilliseconds); Console.ReadLine();
Fesor
29.01.2017 23:14Из статьи видим, что php это делает более агрессивно чем js, достаточно добавить немного «логики» в вычисления и php уже отстаёт
PHP этого не умеет делать пока-что.
Maiami
30.01.2017 01:47+3Но что-то он точно умеет делать (по крайней мере opcache точно умеет, который на сколько я знаю с php7 какой-то версии включен по умолчанию)
Иначе добавление небольшой логики и чтение результата не могло бы привнести такую разницу:
Пример из статьи node test1: 49ms php test1: 13ms //php как будто-бы разгромно выигрывает Пример из статьи + "логика": node test1: 67ms php test1: 83ms //php уже отстает, хотя сложности вычислений почти не добавилось
Оффтоп:
Тоже самое со всеми остальными тестами (где игнорируется совет мелкие строки всегда не складывать, а пушить в массив и потом джойнить, вместо чтения ответа с mysql читается ошибка соединения, вместо 1xphp-fpm vs 1xnode тестируется 5xphp-fpm vs 1xnode и т. д.)
Сравнивают всё равно не php-fpm vs node, а нерабочий вариант vs нерабочий вариант и даётся это под видом каких-то выводовMaiami
30.01.2017 01:53На самом деле по поводу php умеет или нет, спорить не буду, явно вы лучше в этом разбираетесь
Fesor
30.01.2017 18:17+1Но что-то он точно умеет делать (по крайней мере opcache точно умеет, который на сколько я знаю с php7 какой-то версии включен по умолчанию)
с версии 5.5.
opcache не особо умеет оптимизировать AST. Он оптимизирует поток байткода как может. В целом насколько я знаю оптимизаций вроде "схлопнуть пустой цикл" ближайшие пару лет ждать не придется (хотя они грозятся что LLVM впилят в 8-ой версии). Сейчас больше работа идет над учетом типов и оптимизации виртуальной машины (например есть одна и та же операция которая в зависимости от типа аргументов будет заменяться на более специфичные опкоды).
В целом же почти весь выхлоп с производительностью PHP получился за счет оптимизаций работы с памятью.
Пример из статьи + "логика":
зависит от логики. Да и в целом если мы внимательно посмотрим на код, то там как бы нет таких циклов которые можно выпилить оптимизатором. Даже те же запросы в базу могут вызывать глобальные сайд эффекты. Ну а выйгрыш проигрыш зависит целиком и полностью от способа работы с памятью. В PHP в этом плане сделано хорошо, но есть много других моментов которые будут замедлять код. Многие вещи в этих тестах в PHP будут работать существенно быстрее тупо потому что это прямой вызов Си-ных функций и стоимость абстракции можно почти не учитывать. А в nodejs все же есть абстракция.
Сравнивают всё равно не php-fpm vs node, а нерабочий вариант vs нерабочий вариант и даётся это под видом каких-то выводов
Вообще если мы сравниваем ноду и пых в контексте одноразовых скриптов (например когда нам важно время старта) то победитель будет php в силу своей специфики. Но PHP дико проигрывает по уровню инфраструктуры. А это намного более важный показатель.
Fortop
01.02.2017 11:29Но PHP дико проигрывает по уровню инфраструктуры.
Который раз вижу от вас эту фразу.
Хотелось бы услышать конкретику. Что имелось в виду под инфраструктурой?
И usecase где есть существенные отличия.
Если это статьи то ссылки, если это ваш личный опыт, то может быть это отличная тема для статьи на хабре? :)
В отличии от пхп с нодой весьма прохладный опыт работы недошедший до чего-то серьезного

sayber
29.01.2017 22:17Все это конечно хорошо, но реальность немного другая.
Какой бы язык не выбрать, узкое место будет БД.
Опять же, что то лучше читает, что то выполняет мат. функции и т.д.MaZaAa
29.01.2017 23:07-1Согласен, в подавляющем большинстве случаев, процессор просто ждет сетевой ввод/вывод.
point212
30.01.2017 13:09-1Вообще-то тут две разных концепции построения приложения.
На NodeJS приложение постоянно живёт. Единожды загрузившись, инициализировав фреймворк, все коннекты, подгрузив кэши — оно просто перемалывает запросы.
А PHP вынужден на каждый запрос создавать кучу соединений, подгружать кучу ресурсов (ОК, даже если они уже в виде готового кода лежат в кэше, а кэш в памяти — все равно это все инициализируется заново).
Немного нечестно такое сравнивать в лоб.

zBit
30.01.2017 19:55-1Пара замечаний по коду NodeJS:
1. Вместовот этогоvar array = []; for (var i = 0; i < 1000000; i++) { array.push('s'); }Fortop
01.02.2017 11:37-1php может работать асинхронно, но не out-of-the-box.
И мог это всегда (возможно за исключением версий времен php/fi)
А вот читать файл асинхронно в общем случае не получится ни в пхп, ни в ноде.
Да и не имеет смысла, вы только ухудшите производительность (для HDD) и мало что выиграете для SSD.zBit
01.02.2017 18:54+1А вот читать файл асинхронно в общем случае не получится ни в пхп, ни в ноде.
Как так? В NodeJS можно читать файл асинхронно. Может вы путаете с многопоточностью? Тут я точно знаю, что NodeJS однопоточный, но асинхронные операции не являются блокирующими и когда вы читаете файл синхронно и загружаете его весь в ОЗУ — то это плохо, т.к. синхронное чтение заблокирует поток, а файл с большим размером уронит процесс (out of memory). Самый правильный вариант (ИМХО) — создавать ReadableStream.
Да и не имеет смысла, вы только ухудшите производительность (для HDD) и мало что выиграете для SSD.
На чём строится это умозаключение?Fortop
01.02.2017 19:00-2Как так? В NodeJS можно читать файл асинхронно
Вы правы и неправы одновременно.
Правы в том смысле, что можно читать файл и выполнять другие операции параллельно.
Я ваше «синхронно» воспринял как «последовательно».
Все остальное имелось в виду в этом контексте.
Читать файл лучше и быстрее последовательно.
На чём строится это умозаключение?
Вопрос после уточнения актуален?

SerafimArts
В первых тестах вы не используете FPM, а используете zts cli версию. А во второй пачке тестов, думаю, корректнее было бы сравнивать Ratchet + PHP, а не Nginx + PHP.
P.S. Моё личное мнение, преимуществ у ноды две: Это наличие асинхронного апи (а не кусками, как в пыхе) и поддержка в браузерах.
riky
асинхронное апи это плюс для производительности но минус для скорости разработки.
посмотрим что async/await привнесет, может реально будет проще.
SerafimArts
Это не плюс. Асинхронность — наоборот снижает, как производительность, так, и, верно, скорость разработки. Асинхронность предоставляет доступ к архитектурным реализациям, которые позволяют соптимизировать определённый набор алгоритмов.
SerafimArts
Господа минусующие, что такое асинхронность и как она работает?
Есть некий эвентлуп, в который фигачатся операции, он по мере работы их выполняет и переключает контекст на следующую операцию. Постоянное переключение контекста между разными операциями требует дополнительных издержек, по-этому набор асинхронных операций де-факто медленнее синхронных. Можно погуглить по кейворду "как работает event loop".
Или есть подтверждение обратного и на постоянное переключение контекстов не требуются ресурсы компьютера?
robert_ayrapetyan
В «синхронной» модели требуются тысячи потоков и переключение контекста между ними, по вашему это быстрее?
SerafimArts
Потоки нужны в тех задачах, где нужно распараллеливание. Я не просто так написал, что асинхронность, так же как и потоки предоставляют возможность ускорить опредлённый круг задач.
Если сравнивать базовый набор из операции A и B, и асинхронной операции A, после которой в коллбеке выполняется B — первый синхронный вариант будет быстрее. Если учитывать нагрузку, то первый вариант потребует распараллеливания, в этом случае асинхронный вариант может быть быстрее, т.к. позволит в одном потоке выполнять больше операций одновременно. Но полный цикл операций от A до B в сумме всё равно будет медленнее.
Подытоживая, наличие асинхронности позволит:
1) Одновремнно принимать и обрабатывать большее количество запросов.
2) На порядок быстрее выполнять быстрые операции, если рядом с ними ещё есть тяжёлые. Синхронный цикл работы застопится на тяжёлых и не даст выполниться более легковесным до завершения предыдущих.
Разводить демагогию можно много по этому поводу, но если говорить шарообразном коне в вакууме и учитывать последовательные прогоны какого-то теста от начала до конца, то синхронность без потоков будет быстрее. Если же учитывать параллельные прогоны с тредами против асинхронность + треды, то в подавляющем большинстве случаев асинхронная работа будет быстрее.
robert_ayrapetyan
Вы тут сейчас уже пытаетесь выкрутиться, но вернемся к первоначальным утверждениям:
1. Асинхронность — наоборот снижает, как производительность…
Это ложь.
2. Постоянное переключение контекста между разными операциями требует дополнительных издержек
Никакого переключения контекста в потоке не происходит, именно поэтому асинхронные операции быстрее аналогичной реализации на потоках.
Fesor
скорее это просто повышает порог вхождения. В целом уже сейчас в node есть async/await и с ним выходит весьма удобно. В целом же разработка чего-то большого на ноде сейчас требует намного более высокий уровень знаний подходов нежели в PHP.
Как пример — для node еще нет нормальных ORM. Есть парочка многообещающих но они еще не сильно стабильны. Зато есть качественные query builder-ы, прокси и т.д. То есть при желании можно под проект реализовать DAO и спокойно жить но подавляющее большинство php разработчиков (да и разработчиков на javascript) так не особо умеют делать.
vlasenkofedor
Пример Sequelize почти 9 тысяч звезд
Fesor
под нормальной ORM я подразумеваю не очередную имплементацию active record/row-data-gateway а data mapper. На данный момент из наиболее итригующих и лично мне нравящихся решений является TypeORM но оно еще сильно сырое.
Ну то есть Sequelize в поем понимании годиться как раз для DAO/row data gateway, сверху всеравно надо заворачивать в свои объекты что бы это тестить можно было нормальо.