
Ссылка на первую часть
Рассматриваемая нами конфигурация состоит из следующих элементов:

Шина AHB-Lite
Является основным инструментом для общения ядра MIPSfpga с внешним миром. Из нее в модуль доступа к SDRAM поступают команды на чтение и запись информации, по ней же передаются считываемые и записываемые данные. Основная особенность: фаза адреса последующей команды совпадает по времени с фазой данных текущей команды. Лучше всего это видно на следующей диаграмме:
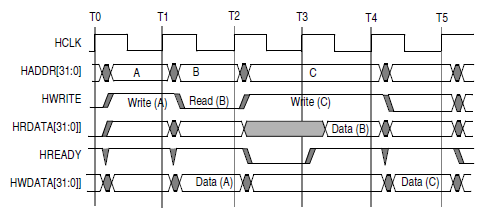
Краткое описание изображенных сигналов: HCLK — тактовый сигнал; HADDR — адрес, данные по которому мы хотим записать или прочитать на следующей фазе, задается мастером; HWRITE — при высоком уровне на следующей фазе должна быть произведена операция записи, выставляется мастером; HRDATA — прочитанные данные; HREADY — флаг завершения текущей операции; HWDATA — записываемые данные, выставляются мастером. Документация на шину, включая описание всех сигналов и их возможных комбинаций входит в состав пакета MIPSfpga.
Память SDRAM
Основные принципы, на которых построена SDRAM, очень хорошо описаны в Главе 5 учебника Харрис-энд-Харрис [1]. Отметим главные моменты:
- для хранения одного бита используется информация о наличии или отсутствии заряда конденсатора;
- память организована в виде матриц из емкостей и управляющей логики: со столбцами и строками;
- во время операции чтения заряд ячейки (конденсатора) расходуется, после чтения ее приходится подзаряжать;
- во время бездействия величина сохраненного заряда также уменьшается (пусть и медленнее) — ячейки памяти требуют периодической подзарядки (т.н. регенерации).
Дальнейшее рассмотрение продолжим на примере микросхемы MT48LC64M8A2 компании Микрон. Помимо очень удобного и детального даташита компания предоставляет Verilog модель для симуляции работы с этим чипом памяти. Что, с одной стороны, значительно упрощает разработку, а с другой, позволяет, не имея отладочной платы, запустить MIPSfpga внутри симулятора и посмотреть, как ядро взаимодействует с SDRAM.
Структурная схема чипа памяти представлена на рисунке ниже.

Основные элементы:
- банк (матрица) памяти (4x bank memory array) — именно здесь хранятся интересующие нас данные. В рассматриваемой микросхеме 4 банка, в каждом из которых 8192 строки и 1024 столбца по 16 бит каждый. Итого, суммарная емкость чипа 4х8192х1024х16 = 512 Mb = 64 MB.
- устройство управления (control logic, bank control logic) — обеспечивают декодирование полученной команды и выдачу соответствующих управляющих сигналов на остальные элементы;
- мультиплексоры, защелки и декодеры адресной шины (row-address mux, 4x bank row-address latch & decoder, column-address counter/latch, column decoder) — обеспечивают хранение адресной информации строк, столбцов и банков памяти, поступающей в разных командах;
- регистры и логика шины данных (data output register, data input register, i/o gating, dqm mask logic) — обеспечивают ввод/вывод данных при операциях чтения и записи, позволяют работать с масками (когда из 16 бит нам нужен только старший или младший байты), обеспечивают перевод выводов шины данных в Z-состояние, шина является двунаправленной.
Условия функционирования
Для корректной работы ОЗУ нам необходимо выполнить ряд условий. Часть из них рассматривать не будем: обеспечение температурного режим, стабильность частоты и питания, уровни сигналов (статическая дисциплина), правильная разводка на плате. В поле нашего зрения остается:
- подача корректных управляющих сигналов, соответствующих той или иной команде;
- удовлетворение требованиям динамической дисциплины (Глава 3 учебника Харрис-энд-Харрис [1])с учетом требований документации на микросхему [2].
Для того, чтобы предметно понимать о чем идет речь, рассмотрим, что должен сделать модуль доступа к памяти при чтении данных из ОЗУ. В качестве примера выступит случай т.н. READ With Auto Precharge — когда микросхема после операции чтения сама обеспечивает подзарядку ячеек, к которым мы обратились. Инициализация модуля (INIT), операции записи (WRITE) или автоматическая регенерация (AUTO_REFRESH) выполняются аналогичным образом, с разницей в выполняемых командах и накладываемых временных ограничениях.
Ниже приведены выкопировки из даташита: таблица истинности для команд и временная диаграмма, на которой показано как производится корректное чтение данных.

Примечание: L — низкий уровень, H — высокий уровень, Х — не имеет значения, High-Z — высокий импеданс.
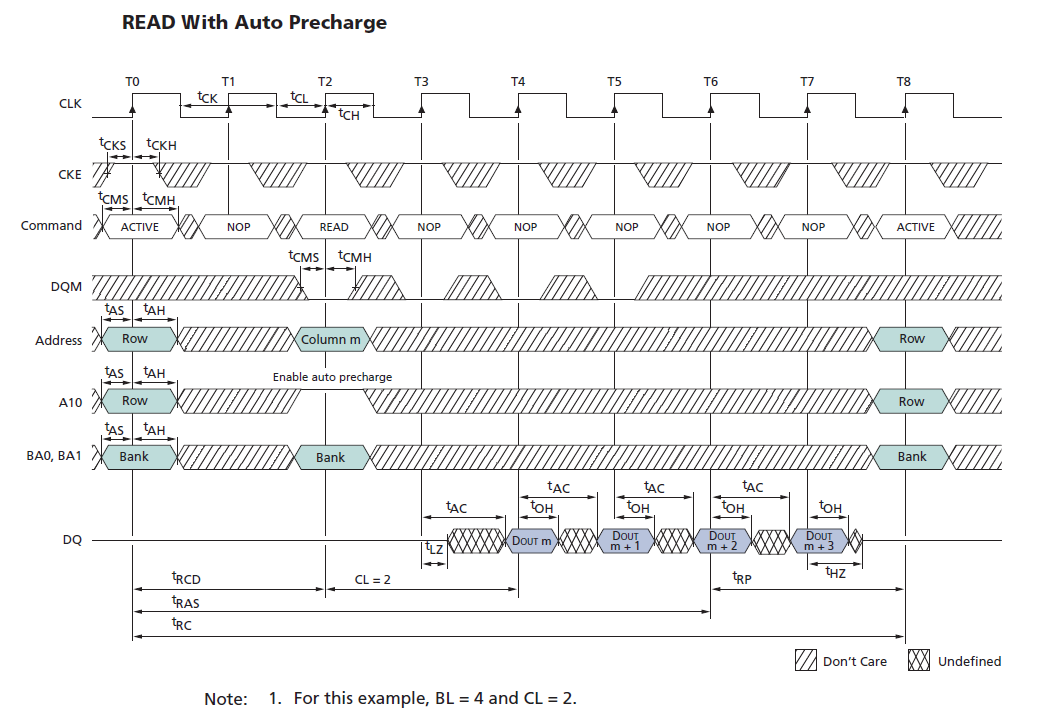
Примечание: tCMS — command setup time, tCMH — command hold time, tAS — address setup time, tAH — address hold time, tRCD — active command to read, tRAS — command period (ACT to PRE), tRC — command period (ACT to ACT), tLZ — output Low impedance time, tAC — access time from clock, tOH — output data hold time, tRP — commad period (PRE to ACT). Минимальные значения этих и других параметров для разных условий приведены в документации на чип памяти.
Последовательность действий при чтении данных (по тактам)
T0. Не позднее чем за tCMS до фронта CLK обеспечить наличие установивших сигналов на выводах CS#, RAS#, CAS#, WE#, DQM (далее — команда), соответствующих команде ACTIVE. Указанные сигналы не должны менять свое состояние в течении tCMH с момента фронта CLK. Не позднее чем за tAS до фронта tCLK установить на шине адреса (A[12:0]) адрес строки, на шине адреса банка памяти (BA[1:0]) — адрес банка памяти. Эти сигналы должны быть стабильны в течении tAH после фронта CLK.
T1. В течении (tRCD — 1 такт) подавать команду NOP. По истечении этого временного промежутка ранее переданный адрес строки будет гарантированно сохранен в row-address latch & decoder соответствующего банка памяти, произойдет выбор одной из 8192 строк (см.структурную схему чипа).
T2. Не позднее чем за tCMS до фронта CLK обеспечить ввод команды READ, не менять команду в течении tCMH с момента фронта CLK. Не позднее чем за tAS до фронта tCLK установить на шине адреса адрес столбца, на шине адреса банка памяти — адрес банка памяти. Десятый бит шины адреса устанавливается в 1 как признак того, что после чтения необходимо выполнить Auto Precharge.
T3-T7. Обеспечить подачу команды NOP на все время чтения данных и не менее чем на (tRC — 1 такт) с момента подачи команды ACTIVE.
T4. Спустя CL тактов (т.н. CAS Latency, CAS) считанные данные будут гарантированно присутствовать на шине данных DQ. Если более точно, то они появятся на шине спустя (1 такт + tAC) — для случая, когда CAS = 2. И будут стабильны в течении минимум tOH после фронта CLK. За это время данные с шины необходимо считать.
Если смотреть на взаимодействие внутри чипа, то за время (1 такт + tAC) адрес столбца будет сохранен в column-address counter/latch, на выходе соответствующего банку памяти column decoder будет установлены сигналы, выбирающие 16 бит необходимого нам столбца, эти данные поступят в data output register и, в итоге, окажутся на шине данных (DQ[15:0]).
T5-T7. Рассматриваемый нами пример предполагает, что чип памяти был настроен на выполнение пакетных операций (burst) c размером пакета BL = 4 (burst length, задается в числе других параметров командой LOAD MODE REGISTER, в текущей реализации модуля доступа к памяти он задан как BL = 2, чтобы получить 32 бита данных). По этой причине в течении последующих трех тактов column-address counter/latch будет автоматически увеличиваться на единицу, а на выход шины данных — поступит еще 3х16 бит.
Необходимо учесть, что количество тактов не обязательно будет равным 8, как изображено на диаграмме (Т0-Т7) — оно должно быть увеличено в большую сторону с целью удовлетворения требований всех временных ограничений: tRCD, tRC и т.д.
Требования временных ограничений выполняются с помощью
- смещения фазы тактового сигнала, на котором работает память (CLK) относительно тактового сигнала, на которой работает модуль доступа к памяти — для малых промежутков (tCMS, tCMH, tAS, tAH, tAC, tOH);
- подачей пустых команд (NOP) на больших промежутках (tRCD, tRC, tRP) — где размер задержки превышает ширину 1 такта тактового сигнала. Для этого в состав конечного автомата модуля введены соответствующие состояния.
Смещение фазы тактового сигнала
Есть несколько хороших источников ([3] и [4]), которые аргументировано противопоставляют "научный" подход определения смещения фазы тактового сигнала методу "проб и ошибок". В этих документах приведен ряд формул по вычислению границ "безопасных окон", в которые нужно подставить значения задержек. После чего предлагается сместить тактовые сигналы таким образом, чтобы их фронты оказались максимально близки к центрам этих "окон". Соглашаясь с тем, что описанная методика работает, хочу обратить внимание на несколько более "ленивый" вариант этого же подхода (мне кажется, что он изображен на 12 и 20 страницах презентации, но т.к. комментариев к ней нет, то я в этом не уверен):
- берем два листка/полоски бумаги в клетку (можно миллиметровку);
- с соблюдением масштаба наносим на каждый из них несколько тактов тактового сигнал, один из них — для fpga, другой — для микросхемы памяти;
- с соблюдением масштаба отмечаем на каждом из них:
запрещенные зоны, в которых считываемый входной сигнал не должен меняться (А);
зоны, в которых значение выходного сигнала не определено;
зоны, в которых выходной сигнал является валиндным (Б). - располагаем полоски бумаги параллельно и смещаем их относительно друг друга (a-la логарифмическая линейка) так, чтобы зоны А находились как можно ближе к центрам зон Б и ни в коем случае не выходили за их границу.
- линейкой измеряем полученное смещение тактовых сигналов, переводим его в ns согласно масштаба.
Чтобы обеспечить точное и стабильное смещение фаз в состав системы необходимо включить PLL-модуль. Обычно я добавляю еще 3-й тактовый сигнал с частотой в 4 раза выше, чем другие и небольшим фазовым смещением — для того, чтобы использовать его в качестве тактовой частоты для логического анализатора (SignalTap) при отладке взаимодействия с памятью в железе.
Модуль доступа к памяти
В этом разделе приведены диаграмма состояний конечного автомата модуля доступа к памяти, а также отдельные строчки кода модуля, описывающие процедуру чтения данных (с указанием номеров строк кода для упрощения навигации). Исходные коды модуля целиком: mfp_ahb_ram_sdram.v. В случае, если чтение скриншотов с кодом доставляет вам дискомфорт, фрагменты исходников из статьи (включая комментарии к ним) продублированы на github.

Состояния конечного автомата, описывающие процедуру чтения, полностью соответствуют тому, что было описано выше на примере диаграммы READ With Auto Precharge.

Правила перехода между этими состояниями:
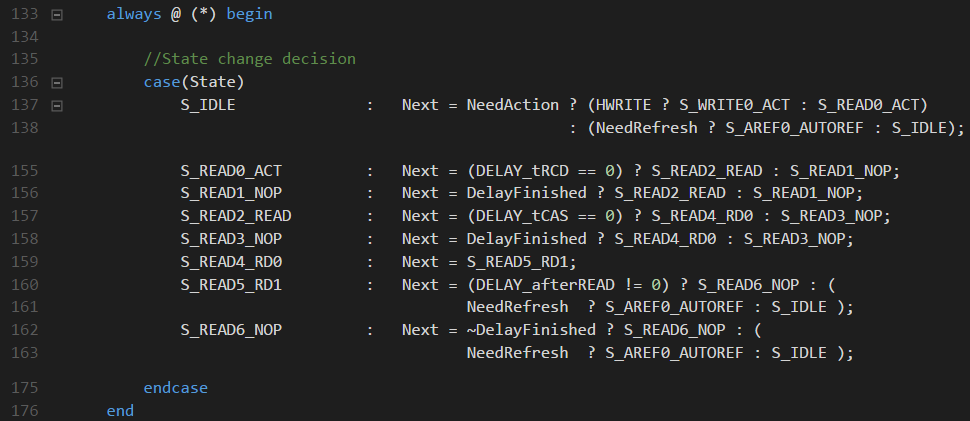
Там, где необходима задержка, она заносится в регистр delay_n, нулевое значение регистра соответствует флагу DelayFinished. На статусах S_READ4_RD0 и S_READ4_RD1 производится считывание данных из шины DQ:
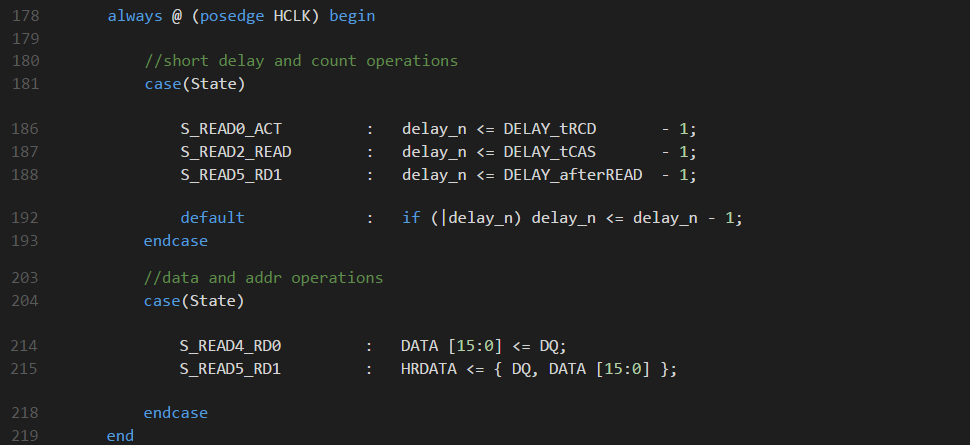
Кодирование команд и их вывод в зависимости от текущего состояния:
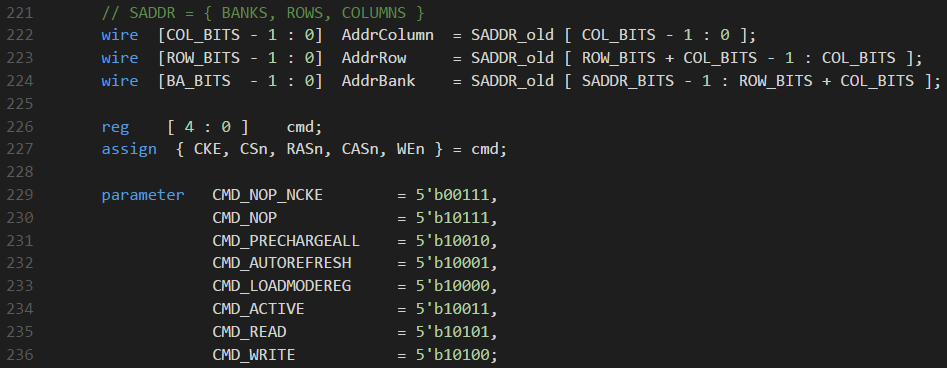

Все задержки являются настраиваемыми и задаются в параметрах модуля, что должно упростить портирование на другие платы, а также модификацию настроек в случае изменения частоты тактового сигнала.

Список литературы
[1] Учебник Дэвида Харриса и Сары Харрис «Цифровая схемотехника и архитектура компьютера»
[2] Документация на микросхему памяти MT48LC64M8A2 компании Микрон;
[3] Документация Quartus. Ядро конроллера SDRAM (перевод)
[4] SDRAM PLL Tuning (презентация)
[5] Ryan Donohue. Synchronization in Digital Logic Circuits (презентация)
[6] Документация на микросхему памяти IS42S16320D
Все даташиты, статьи и презентации на которые есть ссылки в статье, доступны на github.
iCpu
Я, конечно, эстет, и тёмные темы студии мне визуально очень нравятся, но, может, оставите код в теге [CODE], хотя бы в спойлере под картинками?
SparF
Честно пытался вставить код в тег, но местная подсветка синтаксиса + умирающие отступы превращают его во что-то страшное и нечитаемое. Продублировал часть статьи на github.