
Название PROTEQ досталось по наследству от предыдущего проекта для которого была высказана похожая идея восстановления данных после сбоя.
Итак исходные данные:
• аппаратура — модуль FMC106P, две ПЛИС Virtex 6 LX130T-2 и LX240T-1
• скорость передачи — 5 Гбит/с
• число линий — 8
• источник данных — АЦП, нет возможности приостановить передачу
• двунаправленный обмен данными
• требуется реализовать быстрое восстановление данных после сбоя
• кодировка — 64/67
Основная идея — реализовать постоянную повторную передачу данных до прихода подтверждения о принятом пакете. В этом состоит главная особенность протокола и именно это позволяет ускорить восстановление данных.
Рассмотрим реализацию одной линии:
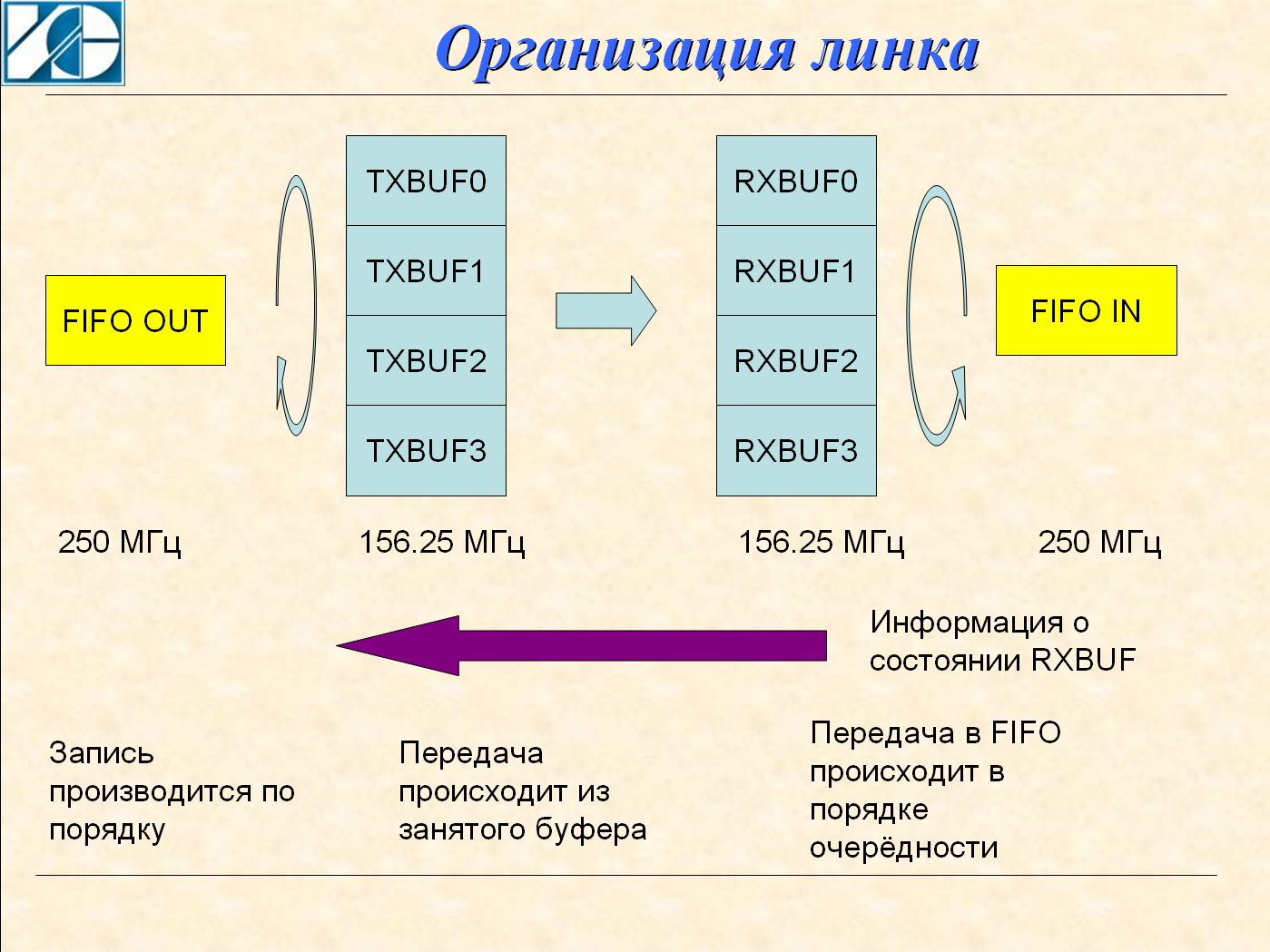
На передатчике реализованы четыре буфера. Источник данных обнаруживает свободный буфер и записывает в него данные. Запись идёт в строгом порядке 0,1,2,3; Узел передачи также по кругу опрашивает флаг заполнения буфера и начинает передавать данные из заполненных буферов. Когда от приёмника приходит подтверждение приёма, то буфер помечается свободным. При большом потоке данных подтверждение успевает прийти до передачи всех четырёх буферов и передача идёт на максимальной скорости. При маленьком потоке узел передачи успеет отправить повторный пакет, но он будет отброшен на приёмной стороне.
Это решение сильно ускоряет восстановление данных. В традиционной схеме приёмник должен принять пакет, провести его анализ и сформировать запрос на повторную передачу. Это долго.
На приёмнике также реализованы четыре буфера. В заголовке пакета находится номер буфера и пакет сразу отправляется в буфер назначения. В таком решении есть очень большая опасность. Если будет испорчен номер буфера, то возможно будут испорчены два пакета — и текущий пакет и уже принятый пакет. Чтобы этого избежать в пакете используются две контрольные суммы — одна идёт сразу за заголовком, вторая — в конце пакета.
Для скорости 5 Гбит/с на узле GTX используется шина 32 разряда с частотой 156.25 МГц. Обмен между FIFO и внутренними буферами идёт на частоте 250 МГц. Это обеспечивает запас скорости для восстановления. Например если произошла ошибка при передачи в буфер 1, а передача в буфер 2 и 3 произошла без ошибки, то запись в выходное FIFO будет задержана до повторного прихода пакета в буфер 1. Но после в FIFO будут сразу записаны пакеты из буферов 2 и 3.
Протокол использует фиксированную длину пакета — 256 слов по 32 бита. Существуют два типа пакета:
- Пакет данных
- Служебный пакет
Формат пакета данных:
- CMD1
- CRC1
- DATA — 256 слов
- CMD2
- CRC2
Формат служебного пакета:
- CMD1
- CRC1
- CMD2
- CRC2
Накладные расходы достаточно низкие — только четыре 32-х разрядных слова. Полная длина пакета с данными — 260 слов.
Служебные пакеты передаются в случае отсутствия данных.
Для увеличения скорости реализована передача по нескольким линиям. Есть узел который работает с числом линий от 1 до 8. Для каждой линии ширина шины данных 32 бита. При использовании 8 линий общая ширина шины данных — 256 бит.
Расчётная скорость обмена для восьми линий на частоте 5 ГГц:
5000000000 * 64/67 * 256/260 * 8 / 8 /1024 / 1024 = 4484,7 Мбайт/с
Именно эта скорость достигнута в результате экспериментов. Ошибки периодически возникают, но они исправляются протоколом. Быстрое восстановление позволяет использовать небольшой размер FIFO для подключения АЦП.
Интересно сравнить эффективность PROTEQ с PCI Express v2.0 реализованном на этой же ПЛИС. Оба протокола используют восемь линков на скорости 5 Гбит/с. Максимальная скорость обмена составляет:
5000000000/8/1024/1024*8 = 4768 Мбайт/с
Эффективность PROTEQ:
4484/4768 = 0.94; т.е. 94% от максимальной скорости линии.
PCI Express обеспечивает скорость 3200 Мбайт/с
3200/4768 = 0.67; т.е. 67% от максимальной скорости линии.
Конечно главная причина низкой эффективности PCI Express v2.0 это применение кодировки 8/10;
Интересно также сравнить занимаемые ресурсы ПЛИС для реализации протоколов. На рисунке представлены области которые занимает PCI Express и PROTEQ со сравнимой функциональностью. При этом следует учитывать, что PCI Express использует ещё HARD блок.

Основным компонентом является prq_transceiver_gtx_m1
component prq_transceiver_gtx_m1 is
generic(
is_simulation : in integer:=0; -- 1 - режим моделирования
LINES : in integer; -- число MGT линий
RECLK_EN : in integer:=0; -- 1 - приёмник работает на частоте recclk
-- 0 - приёмник работает на частоте txoutclk
USE_REFCLK_IN : boolean:=FALSE; -- FALSE - используются вход MGTCLK
-- TRUE - используется вход REFCLK_IN
is_tx_dpram_use : in integer:=1; -- 1 - использование памяти для передачи
is_rx_dpram_use : in integer:=1 -- 1 - использование памяти для приёма
);
port(
clk : in std_logic; -- тактовая частота приложения - 266 МГц
clk_tx_out : out std_logic; -- тактовая частота передатчика - 156.25 МГц
clk_rx_out : out std_logic; -- тактовая частота приёмника - 156.25 МГц
--- SYNC ---
reset : in std_logic; -- 0 - сброс
sync_done : out std_logic; -- 1 - завершена инициализация
tx_enable : in std_logic; -- 1 - разрешение передачи данных
rx_enable : in std_logic; -- 1 - разрешение приёма данных
rst_buf : in std_logic:='0'; -- 1 - сброс буферов данных
transmitter_dis : in std_logic:='0'; -- 1 - запрет работы передатчика
---- DATA ----
tx_ready : out std_logic; -- 1 - готовность к передаче одного буфера
rx_ready : out std_logic; -- 1 - один буфер готов к чтению
tx_data : in std_logic_vector( 31+(LINES-1)*32 downto 0 ); -- данные для передачи
tx_data_we : in std_logic; -- 1 - запись данных
tx_data_title : in std_logic_vector( 3 downto 0 ); -- заголовок пакета
tx_data_eof : in std_logic; -- 1 - конец фрейма
tx_user_flag : in std_logic_vector( 7+(LINES-1)*8 downto 0 ); -- локальные флаги
tx_inject_error : in std_logic_vector( LINES-1 downto 0 ):=(others=>'0'); -- 1 - добавить ошибку в передаваемый буфер
rx_data : out std_logic_vector( 31+(LINES-1)*32 downto 0 ); -- принятые данные
rx_data_rd : in std_logic; -- 1 - чтение данных
rx_data_title : out std_logic_vector( 3 downto 0 ); -- заголовок принятого пакета
rx_data_eof : in std_logic; -- 1 - конец фрейма
rx_user_flag : out std_logic_vector( 7+(LINES-1)*8 downto 0 ); -- удалённые флаги
rx_user_flag_we : out std_logic_vector( (LINES-1) downto 0 ); -- 1 - обновление удалённых флагов
rx_crc_error_adr: in std_logic_vector( 2 downto 0 ):="000"; -- адрес счётчика ошибок
rx_crc_error : out std_logic_vector( 7 downto 0 ); -- счётчик ошибок для выбранного канала
--- MGT ---
rxp : in std_logic_vector( LINES-1 downto 0 );
rxn : in std_logic_vector( LINES-1 downto 0 );
txp : out std_logic_vector( LINES-1 downto 0 );
txn : out std_logic_vector( LINES-1 downto 0 );
refclk_in : in std_logic:='0';
mgtclk_p : in std_logic;
mgtclk_n : in std_logic
);
end component;
Группа сигналов tx_* организуют канал передачи. Алгоритм передачи пакта:
- Ждать появления tx_ready=1
- Записать пакет по шине tx_data с помощью строба tx_data_we=1
- Сформировать tx_data_eof=1 на один такт — пакет будет отправлен
Записать можно от 1 до 256 слов, но в любом случае будет отправлен пакет длиной 256 слов.
Аналогично, группа сигналов rx_* организует канал приёма. Алгоритм приёма пакета:
- Ждать появления rx_ready=1
- Прочитать пакет по шине rx_data с помощью строба rx_data_rd
- Сформировать rx_data_eof=1
Также как и при записи допускается прочитать не весь пакет. Вместе с пакетом передаётся четырёхбитный заголовок. При передаче вместе с пакетом будет передано значение на входе tx_data_title. При приёме вместе с готовностью tx_ready=1 появится значение на rx_data_title. Это позволяет иметь несколько источников и приёмников данных при одном канале передаче.
Дополнительно в канале происходит передача флагов. Данные на входе передатчика tx_user_flag передаются на выход приёмника rx_user_flag. Это может использоваться для передачи флагов состояния FIFO.
Компонент prq_transceiver_gtx_m1 может передавать данные по нескольким линиям. Количество линий настраивается через параметр LINES; От количества линий зависит ширина шин tx_data, rx_data.
Вход tx_inject_error позволяет добавить ошибку в процессе передачи. Это позволяет проверить механизм восстановления данных.
Следующим уровнем является компонент prq_connect_m1
component prq_connect_m1 is
generic(
is_simulation : in integer:=0; -- 1 - режим моделирования
RECLK_EN : in integer:=0; -- 1 - приёмник работает на частоте recclk
-- 0 - приёмник работает на частоте txoutclk
is_tx_dpram_use : in integer:=1; -- 1 - использование памяти для передачи
is_rx_dpram_use : in integer:=1; -- 1 - использование памяти для приёма
FIFO0_WITH : in integer:=1; -- ширина FIFO0: 1 - нет, 32,64,128,256 бит
FIFO0_PAF : in integer:=16; -- уровень срабатывания флага PAF
FIFO0_DEPTH : in integer:=1024; -- глубина FIFO0
FIFO1_WITH : in integer:=1; -- ширина FIFO1: 1 - нет, 32,64,128,256 бит
FIFO1_PAF : in integer:=16; -- уровень срабатывания флага PAF
FIFO1_DEPTH : in integer:=1024 -- глубина FIFO0
);
port(
--- MGT ---
rxp : in std_logic_vector( 7 downto 0 );
rxn : in std_logic_vector( 7 downto 0 );
txp : out std_logic_vector( 7 downto 0 );
txn : out std_logic_vector( 7 downto 0 );
mgtclk_p : in std_logic;
mgtclk_n : in std_logic;
---- Tranceiver ----
clk : in std_logic; -- тактовая частота приложения - 266 МГц
clk_tx_out : out std_logic; -- тактовая частота передатчика - 156.25 МГц
clk_rx_out : out std_logic; -- тактовая частота приёмника - 156.25 МГц
--- SYNC ---
reset : in std_logic; -- 0 - сброс
sync_done : out std_logic; -- 1 - завершена инициализация
tx_enable : in std_logic; -- 1 - разрешение передачи данных
rx_enable : in std_logic; -- 1 - разрешение приёма данных
---- FIFO0 ----
fi0_clk : in std_logic:='0'; -- тактовая частота записи в FIFO
fi0_data : in std_logic_vector( FIFO0_WITH-1 downto 0 ):=(others=>'0'); -- шина данных FIFO
fi0_data_en : in std_logic:='0'; -- 1 - запись в FIFO
fi0_paf : out std_logic; -- 1 - FIFO почти полное
fi0_id : in std_logic_vector( 3 downto 0 ):=(others=>'0'); -- идентификатор FIFO
fi0_rstp : in std_logic:='0'; -- 1 - сброс FIFO
fi0_enable : in std_logic:='0'; -- 1 - разрешение передачи
fi0_prs_en : in std_logic:='0'; -- 1 - включение генератора псевдослучайной последовательности
fi0_ovr : out std_logic; -- 1 - переполнение FIFO
fi0_rd_full_speed: in std_logic:='0'; -- 1 - формирование выходного потока на полной скорости
---- FIFO1 ----
fi1_clk : in std_logic:='0'; -- тактовая частота записи в FIFO
fi1_data : in std_logic_vector( FIFO1_WITH-1 downto 0 ):=(others=>'0'); -- шина данных FIFO
fi1_data_en : in std_logic:='0'; -- 1 - запись в FIFO
fi1_paf : out std_logic; -- 1 - FIFO почти полное
fi1_id : in std_logic_vector( 3 downto 0 ):=(others=>'0'); -- идентификатор FIFO
fi1_rstp : in std_logic:='0'; -- 1 - сброс FIFO
fi1_enable : in std_logic:='0'; -- 1 - разрешение передачи
fi1_prs_en : in std_logic:='0'; -- 1 - включение генератора псевдослучайной последовательности
fi1_ovr : out std_logic; -- 1 - переполнение FIFO
fi1_rd_full_speed: in std_logic:='0'; -- 1 - формирование выходного потока на полной скорости
tx_inject_error : in std_logic_vector( 7 downto 0 ):=(others=>'0'); -- 1 - добавить ошибку в передаваемый буфер
tx_user_flag : in std_logic_vector( 63 downto 0 ):=(others=>'0'); -- локальные флаги
---- Приём данных ----
fifo_data : out std_logic_vector( 255 downto 0 ); -- выход FIFO
fifo_we : out std_logic; -- 1 - запись данных
fifo_id : out std_logic_vector( 3 downto 0 ); -- идентификатор FIFO
fifo_rdy : in std_logic_vector( 15 downto 0 ); -- готовность к приёму данных
rx_crc_error_adr: in std_logic_vector( 2 downto 0 ):="000"; -- адрес счётчика ошибок
rx_crc_error : out std_logic_vector( 7 downto 0 ); -- счётчик ошибок для выбранного канала
rx_user_flag : out std_logic_vector( 63 downto 0 ); -- удалённые флаги
rx_user_flag_we : out std_logic_vector( 7 downto 0 ) -- 1 - обновление удалённых флагов
);
end component;
Он уже реализует механизм передачи потока данных через FIFO по восьми линиям. Структурная схема:

В его состав входят два FIFO, prq_transceiver, автоматы приёма и передачи.
Ширина входной шины каждого FIFO настраивается через параметры FIFOx_WITH, также настраивается количество слов и уровень срабатывания флага почти полного FIFO. Запись в каждое FIFO производится на своей тактовой частоте. Каждое FIFO сопровождается своим идентификатором fi0_id, fi1_id; Это позволяет разделить поток данных при приёме. После FIFO установлен генератор псевдослучайной последовательности. На схеме он обозначен как PSD.
Генератор реализует три режима:
- Пропустить поток данных без изменений
- Подставить тестовую последовательность при сохранении скорости потока данных
- Подставить тестовую последовательность и передавать данные на полной скорости
На этом генераторе основано тестирование в составе реальных проектов. Этот генератор не занимает много места в ПЛИС, он есть во всех проектах и позволяет в любой момент провести проверку канала обмена.
Компоненты prq_connect_m1 и prq_transceiver_gtx_m1 являются базовыми. Они были разработаны для ПЛИС Virtex 6; Впоследствии разработаны компоненты prq_transceiver_gtx_m4 и prq_transceiver_gtx_m6;
- prq_transceiver_gtx_m4 — буфер 0 выделен для передачи командн
- prq_transceiver_gtx_m6 — для ПЛИС Kintex 7
Проект полностью моделируется, реализован последовательный запуск тестов через tcl файл.
И здесь я хочу выразить благодарность Игорю Казинову. Он внёс большой вклад в организацию моделирования в этом проекте.
Общий результат моделирования выглядит так:
Global PROTEQ TC log:
tc_00_0 PASSED
tc_00_1 PASSED
tc_00_2 PASSED
tc_00_3 PASSED
tc_02_0 PASSED
tc_02_1 PASSED
tc_02_2 PASSED
tc_02_3 PASSED
tc_02_4 PASSED
tc_02_5 PASSED
tc_03_0 PASSED
tc_05_0 PASSED
tc_05_1 PASSED
Каждая строчка в файле это результат выполнения одного теста. tc — это Test Case — тестовый случай. Для примера приведу компонент tc_00_1 — проверка передачи пакета и внесение одиночной ошибки в процесс передачи.
-------------------------------------------------------------------------------
--
-- Title : tc_00_1
-- Author : Dmitry Smekhov
-- Company : Instrumental Systems
-- E-mail : dsmv@insys.ru
--
-- Version : 1.0
--
-------------------------------------------------------------------------------
--
-- Description : Проверка на тесте prq_transceiver_tb
--
-- Приём 32-х пакетов.
-- Одиночная ошибка
--
-------------------------------------------------------------------------------
--
-- Rev0.1 - debug test #1
--
-------------------------------------------------------------------------------
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_arith.all;
use ieee.std_logic_unsigned.all;
library std;
use std.textio.all;
library work;
use work.prq_transceiver_tb_pkg.all; -- to bind testbench and its procedures
use work.utils_pkg.all; -- for "stop_simulation"
use work.pck_fio.all;
entity tc_00_1 is
end tc_00_1;
architecture bhv of tc_00_1 is
signal tx_err : std_logic;
signal rx_err : std_logic;
begin
----------------------------------------------------------------------------------
-- Instantiate TB
TB : prq_transceiver_tb
generic map(
max_pkg => 32, -- число пакетов, которое нужно принять
max_time => 100 us, -- максимальное время теста
tx_pause => 1 ns, -- минимальное время между пакетами при передаче
rx_pause => 1 ns -- минимальное время между пакетами при приёме
)
port map(
tx_err => tx_err, -- сигнал ошибки m1->m2
rx_err => rx_err -- сигнал ошибки m2->m1
);
----------------------------------------------------------------------------------
--
-- Define ERR at TIME#
--
tx_err <= '0', '1' after 27 us, '0' after 27.001 us;
rx_err <= '0';
----------------------------------------------------------------------------------
end bhv;
Компонент очень простой. Он вызывает prq_transceiver_tb (а вот он как раз сложный), настраивает параметры и формирует сигнал tx_err который вносит ошибку на линию передачи.
Остальные компоненты от tc_00_1 до tc_00_5 примерно такие же, они отличаются настроенными параметрами, что позволяет проверить передачу данных при разных условиях.
Компонент prq_transceiver_tb гораздо сложнее. Собственно он формирует тестовую последовательность, передаёт поток между двумя prq_transceiver_gtx_m1 и проверяет принятый поток данных. При необходимости — вносит ошибки в процесс передачи.
Сам компонент здесь:
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_arith.all;
use ieee.std_logic_unsigned.all;
use work.prq_transceiver_gtx_m1_pkg.all;
library std;
use std.textio.all;
use work.pck_fio.all;
use work.utils_pkg.all;
entity prq_transceiver_tb is
generic(
max_pkg : integer:=0; -- число пакетов, которое нужно принять
max_time : time:=100 us; -- максимальное время теста
tx_pause : time:=100 ns; -- минимальное время между пакетами при передаче
rx_pause : time:=100 ns -- минимальное время между пакетами при приёме
);
port(
tx_err : in std_logic:='0'; -- сигнал ошибки m1->m2
rx_err : in std_logic:='0' -- сигнал ошибки m2->m1
);
end prq_transceiver_tb;
architecture TB_ARCHITECTURE of prq_transceiver_tb is
signal clk : std_logic:='0';
signal reset : STD_LOGIC;
signal tx_data : STD_LOGIC_VECTOR(31 downto 0);
signal tx_data_we : STD_LOGIC;
signal tx_data_title : STD_LOGIC_VECTOR(3 downto 0);
signal rx_data_rd : STD_LOGIC;
signal rxp : STD_LOGIC_VECTOR(0 downto 0);
signal rxn : STD_LOGIC_VECTOR(0 downto 0);
signal mgtclk_p : STD_LOGIC;
signal mgtclk_n : STD_LOGIC;
signal mgtclk : std_logic:='0';
-- Observed signals - signals mapped to the output ports of tested entity
signal clk_tx_out : STD_LOGIC;
signal clk_rx_out : STD_LOGIC;
signal sync_done : STD_LOGIC;
signal tx_enable : STD_LOGIC;
signal rx_enable : STD_LOGIC;
signal tx_ready : STD_LOGIC;
signal rx_ready : STD_LOGIC;
signal rx_data : STD_LOGIC_VECTOR(31 downto 0);
signal rx_data_title : STD_LOGIC_VECTOR(3 downto 0);
signal txp : STD_LOGIC_VECTOR(0 downto 0);
signal txn : STD_LOGIC_VECTOR(0 downto 0);
signal m2_txp : STD_LOGIC_VECTOR(0 downto 0);
signal m2_txn : STD_LOGIC_VECTOR(0 downto 0);
signal m2_rxp : STD_LOGIC_VECTOR(0 downto 0);
signal m2_rxn : STD_LOGIC_VECTOR(0 downto 0);
signal tx_err_i : std_logic_vector( 0 downto 0 );
signal rx_err_i : std_logic_vector( 0 downto 0 );
signal tx_data_eof : std_logic;
signal rx_data_eof : std_logic;
signal m2_clk : std_logic:='0';
signal m2_tx_data : STD_LOGIC_VECTOR(31 downto 0);
signal m2_tx_data_we : STD_LOGIC;
signal m2_tx_data_title : STD_LOGIC_VECTOR(3 downto 0);
signal m2_rx_data_rd : STD_LOGIC;
signal m2_tx_data_eof : std_logic;
signal m2_rx_data_eof : std_logic;
-- Observed signals - signals mapped to the output ports of tested entity
signal m2_clk_tx_out : STD_LOGIC;
signal m2_clk_rx_out : STD_LOGIC;
signal m2_sync_done : STD_LOGIC;
signal m2_tx_enable : STD_LOGIC;
signal m2_rx_enable : STD_LOGIC;
signal m2_tx_ready : STD_LOGIC;
signal m2_rx_ready : STD_LOGIC;
signal m2_rx_data : STD_LOGIC_VECTOR(31 downto 0);
signal m2_rx_data_title : STD_LOGIC_VECTOR(3 downto 0);
signal tx_user_flag : std_logic_vector( 7 downto 0 ):=x"A0";
signal rx_user_flag : std_logic_vector( 7 downto 0 );
signal rx_user_flag_we : std_logic_vector( 0 downto 0 );
signal m2_tx_user_flag : std_logic_vector( 7 downto 0 ):=x"C0";
signal m2_rx_user_flag : std_logic_vector( 7 downto 0 );
signal m2_rx_user_flag_we : std_logic_vector( 0 downto 0 );
signal m2_reset : std_logic;
begin
clk <= not clk after 1.9 ns;
mgtclk <= not mgtclk after 3.2 ns;
m2_clk <= not m2_clk after 1.8 ns;
mgtclk_p <= mgtclk;
mgtclk_n <= not mgtclk;
-- Unit Under Test port map
UUT : prq_transceiver_gtx_m1
generic map (
is_simulation => 1, -- 1 - режим моделирования
LINES => 1,
is_tx_dpram_use => 1, -- 1 - использование памяти для передачи
is_rx_dpram_use => 0 -- 1 - использование памяти для приёма
)
port map (
clk => clk,
clk_tx_out => clk_tx_out,
clk_rx_out => clk_rx_out,
--- SYNC --- --- SYNC ---
reset => reset,
sync_done => sync_done,
tx_enable => tx_enable,
rx_enable => rx_enable,
---- DATA ---- ---- DATA ----
tx_ready => tx_ready,
rx_ready => rx_ready,
tx_data => tx_data,
tx_data_we => tx_data_we,
tx_data_title => tx_data_title,
tx_data_eof => tx_data_eof,
tx_user_flag => tx_user_flag,
rx_data => rx_data,
rx_data_rd => rx_data_rd,
rx_data_title => rx_data_title,
rx_data_eof => rx_data_eof,
rx_user_flag => rx_user_flag,
rx_user_flag_we => rx_user_flag_we,
--- MGT --- --- MGT ---
rxp => rxp,
rxn => rxn,
txp => txp,
txn => txn,
mgtclk_p => mgtclk_p,
mgtclk_n => mgtclk_n
);
UUT2 : prq_transceiver_gtx_m1
generic map (
is_simulation => 1, -- 1 - режим моделирования
LINES => 1,
is_tx_dpram_use => 0, -- 1 - использование памяти для передачи
is_rx_dpram_use => 1 -- 1 - использование памяти для приёма
)
port map (
clk => m2_clk,
clk_tx_out => m2_clk_tx_out,
clk_rx_out => m2_clk_rx_out,
--- SYNC --- --- SYNC ---
reset => m2_reset,
sync_done => m2_sync_done,
tx_enable => m2_tx_enable,
rx_enable => m2_rx_enable,
---- DATA ---- ---- DATA ----
tx_ready => m2_tx_ready,
rx_ready => m2_rx_ready,
tx_data => m2_tx_data,
tx_data_we => m2_tx_data_we,
tx_data_title => m2_tx_data_title,
tx_data_eof => m2_tx_data_eof,
tx_user_flag => m2_tx_user_flag,
rx_data => m2_rx_data,
rx_data_rd => m2_rx_data_rd,
rx_data_title => m2_rx_data_title,
rx_data_eof => m2_rx_data_eof,
rx_user_flag => m2_rx_user_flag,
rx_user_flag_we => m2_rx_user_flag_we,
--- MGT --- --- MGT ---
rxp => m2_rxp,
rxn => m2_rxn,
txp => m2_txp,
txn => m2_txn,
mgtclk_p => mgtclk_p,
mgtclk_n => mgtclk_n
);
rx_err_i <= (others=>rx_err);
tx_err_i <= (others=>tx_err);
rxp <= m2_txp or rx_err_i;
rxn <= m2_txn or rx_err_i;
m2_rxp <= txp or tx_err_i;
m2_rxn <= txn or tx_err_i;
reset <= '0', '1' after 1 us;
m2_reset <= '0', '1' after 2 us;
tx_enable <= '0', '1' after 22 us;
rx_enable <= '0', '1' after 22 us;
m2_tx_enable <= '0', '1' after 24 us;
m2_rx_enable <= '0', '1' after 24 us;
m2_tx_data_we <= '0';
m2_tx_data <= (others=>'0');
m2_tx_data_title <= "0000";
m2_tx_data_eof <= '0';
pr_tx_data: process begin
tx_data_we <= '0';
tx_data_eof <= '0';
tx_data <= x"AB000000";
tx_data_title <= "0010";
loop
wait until rising_edge( clk ) and tx_ready='1';
tx_data_we <= '1' after 1 ns;
for ii in 0 to 255 loop
wait until rising_edge( clk );
tx_data <= tx_data + 1 after 1 ns;
end loop;
tx_data_we <= '0' after 1 ns;
wait until rising_edge( clk );
tx_data_eof <= '1' after 1 ns;
wait until rising_edge( clk );
tx_data_eof <= '0' after 1 ns;
wait until rising_edge( clk );
wait for tx_pause;
end loop;
end process;
pr_rx_data: process
variable expect_data : std_logic_vector( 31 downto 0 ):= x"AB000000";
variable error_cnt : integer:=0;
variable pkg_cnt : integer:=0;
variable pkg_ok : integer:=0;
variable pkg_error : integer:=0;
variable index : integer;
variable flag_error : integer;
variable tm_start : time;
variable tm_stop : time;
variable byte_send : real;
variable tm : real;
variable velocity : real;
variable tm_pkg : time:=0 ns;
variable tm_pkg_delta : time:=0 ns;
variable L : line;
begin
m2_rx_data_rd <= '0';
m2_rx_data_eof <= '0';
--fprint( output, L, "Чтение данных\n" );
loop
loop
wait until rising_edge( m2_clk );
if( m2_rx_ready='1' or now>max_time ) then
exit;
end if;
end loop;
if( now>max_time ) then
exit;
end if;
if( pkg_cnt=0 ) then
tm_start:=now;
tm_pkg:=now;
end if;
tm_pkg_delta := now - tm_pkg;
fprint( output, L, "PKG=%3d %10r ns %10r ns\n", fo(pkg_cnt), fo(now), fo(tm_pkg_delta) );
tm_pkg:=now;
index:=0;
flag_error:=0;
m2_rx_data_rd <= '1' after 1 ns;
wait until rising_edge( m2_clk );
loop
wait until rising_edge( m2_clk );
if( expect_data /= m2_rx_data ) then
if( error_cnt<32 ) then
fprint( output, L, "ERROR: pkg=%d index=%d expect=%r read=%r \n",
fo(pkg_cnt), fo(index), fo(expect_data), fo(m2_rx_data) );
end if;
error_cnt:=error_cnt+1;
flag_error:=1;
end if;
index:=index+1;
expect_data:=expect_data+1;
if( index=255 ) then
m2_rx_data_rd <= '0' after 1 ns;
end if;
if( index=256 ) then
exit;
end if;
end loop;
if( flag_error=0 ) then
pkg_ok:=pkg_ok+1;
else
pkg_error:=pkg_error+1;
end if;
wait until rising_edge( m2_clk );
m2_rx_data_eof <= '1' after 1 ns;
wait until rising_edge( m2_clk );
m2_rx_data_eof <= '0' after 1 ns;
wait until rising_edge( m2_clk );
--wait until rising_edge( m2_clk );
wait for rx_pause;
pkg_cnt:=pkg_cnt+1;
if( pkg_cnt=max_pkg ) then
exit;
end if;
end loop;
tm_stop:=now;
fprint( output, L, "Завершён приём данных: %r ns\n", fo(now) );
fprint( output, L, " Принято пакетов: %d\n", fo( pkg_cnt ) );
fprint( output, L, " Правильных: %d\n", fo( pkg_ok ) );
fprint( output, L, " Ошибочных: %d\n", fo( pkg_error ) );
fprint( output, L, " Общее число ошибок: %d\n", fo( error_cnt ) );
byte_send:=real(pkg_cnt)*256.0*4.0;
tm := real(tm_stop/ 1 ns )-real(tm_start/ 1 ns);
velocity := byte_send*1000000000.0/(tm*1024.0*1024.0);
fprint( output, L, " Скорость передачи: %r МБайт/с\n", fo( integer(velocity) ) );
flag_error:=0;
if( max_pkg>0 and pkg_cnt/=max_pkg ) then
flag_error:=1;
end if;
if( flag_error=0 and pkg_cnt>0 and error_cnt=0 ) then
--fprint( output, L, "\n\nТест завершён успешно\n\n" );
fprint( output, L, "\n\nTEST finished successfully\n\n" );
else
--fprint( output, L, "\n\nТест завершён с ошибками\n\n" );
fprint( output, L, "\n\nTEST finished with ERR\n\n" );
end if;
utils_stop_simulation;
wait;
end process;
pr_tx_user_flag: process begin
tx_user_flag <= tx_user_flag + 1;
wait for 1 us;
end process;
pr_m2_tx_user_flag: process begin
m2_tx_user_flag <= m2_tx_user_flag + 1;
wait for 1.5 us;
end process;
end TB_ARCHITECTURE;
Результат работы теста:
# KERNEL: PKG= 0 25068 ns 0 ns
# KERNEL: PKG= 1 26814 ns 1746 ns
# KERNEL: PKG= 2 35526 ns 8712 ns
# KERNEL: PKG= 3 36480 ns 954 ns
# KERNEL: PKG= 4 37434 ns 954 ns
# KERNEL: PKG= 5 38388 ns 954 ns
# KERNEL: PKG= 6 39342 ns 954 ns
# KERNEL: PKG= 7 40858 ns 1515 ns
# KERNEL: PKG= 8 42597 ns 1738 ns
# KERNEL: PKG= 9 44339 ns 1742 ns
# KERNEL: PKG= 10 46081 ns 1742 ns
# KERNEL: PKG= 11 47827 ns 1746 ns
# KERNEL: PKG= 12 49566 ns 1738 ns
# KERNEL: PKG= 13 51309 ns 1742 ns
# KERNEL: PKG= 14 53051 ns 1742 ns
# KERNEL: PKG= 15 54790 ns 1738 ns
# KERNEL: PKG= 16 56536 ns 1746 ns
# KERNEL: PKG= 17 58278 ns 1742 ns
# KERNEL: PKG= 18 60021 ns 1742 ns
# KERNEL: PKG= 19 61759 ns 1738 ns
# KERNEL: PKG= 20 63502 ns 1742 ns
# KERNEL: PKG= 21 65248 ns 1746 ns
# KERNEL: PKG= 22 66990 ns 1742 ns
# KERNEL: PKG= 23 68729 ns 1738 ns
# KERNEL: PKG= 24 70471 ns 1742 ns
# KERNEL: PKG= 25 72210 ns 1738 ns
# KERNEL: PKG= 26 73953 ns 1742 ns
# KERNEL: PKG= 27 75699 ns 1746 ns
# KERNEL: PKG= 28 77441 ns 1742 ns
# KERNEL: PKG= 29 79180 ns 1738 ns
# KERNEL: PKG= 30 80922 ns 1742 ns
# KERNEL: PKG= 31 82661 ns 1738 ns
# KERNEL: Завершён приём данных: 83598 ns
# KERNEL: Принято пакетов: 32
# KERNEL: Правильных: 32
# KERNEL: Ошибочных: 0
# KERNEL: Общее число ошибок: 0
# KERNEL: Скорость передачи: 534 МБайт/с
# KERNEL:
# KERNEL:
# KERNEL: TEST finished successfully
Обратите внимание на правую колонку. Это время между принятыми пакетами. Обычное время ~1740 ns, однако пакет 2 принят с задержкой в 8712 ns. Это как раз действовал сигнал ошибки. И ещё обратите внимание что следующие пакеты приняты с задержкой 954 ns. Это из-за того, что неправильно был принят только один пакет, а остальные дожидались своей очереди в буферной памяти.
Хочу отметить, что автоматизированный запуск тестов мне очень помог при отладке протокола. Это позволило держать все изменения под контролем. И небольшие изменения в исходном коде не смогли привести к обрушению проекта.
Проект PROTEQ доступен как OpenSource. Ссылка на сайт — в моём профиле.
Комментарии (26)
nerudo
11.02.2017 20:57Proteq и PCIe — совершенно разного уровня протоколы, сравнивать их, особенно в части затрат ресурсов — бессмысленно на мой взгляд.

dsmv2014
11.02.2017 23:19Протоколы действительно разные, но сравнивать их можно и нужно. PCIe также можно использовать для обеспечения надёжной передачи данных между двумя ПЛИС без использования компьютера. У Xilinx есть даже такой пример. Но при таком использовании очень много свойств PCIe использоваться не будут, но ресурсы всё равно будут заняты.

lingvo
12.02.2017 11:17Есть еще Ethernet, но между чипами на плате по-моему лучше всего подходит Aurora.
И вообще ИМХО лучше всего использовать стандартные протоколы — потом легче будет переносить проект на следующую плис.
Даже из-за ограничения пропускной способности PCIe не вижу смысла. Сейчас уже вовсю продаются Ultrascale, которые и дешевле и быстрее Virtex-6. На них можно спокойно запустить PCIe gen. 3.dsmv2014
12.02.2017 17:29Aurora не обеспечивает восстановления после сбоя. Соответственно приходится строить систему с расчётом на возможность ошибки. На мой взгляд это гораздо сложнее чем обеспечить надёжную передачу пакетов.
Стандартные протоколы это конечно хорошо. Но с одной стороны Ethernet, RapidIO, Aurora, PCIe, Interlaken в данной работе хуже чем PROTEQ. С другой — перенос на другую ПЛИС всегда непредсказуем.
Например перевод PCIe c Virtex6 на Kintex7 прошёл достаточно просто. Но и PROTEQ перешёл просто. А вот PCIe для Ultrascale совершенно другой. Но и в реализации кодировки 64/67 для Ultrascale они тоже намудрили, пришлось долго разбираться.
Хочу ещё раз обратить внимание — главной задачей PROTEQ является передача данных от АЦП, которое не может приостановить свою работу. Это разумеется требует наличия FIFO перед каналом передачи. Но вот размер FIFO определяется возможными задержками, в том числе на восстановление данных. PROTEQ как раз и отличается от стандартных протоколов быстрым восстановлением данных.lingvo
14.02.2017 18:23Что ж у вас там за данные от АЦП, которые нельзя потерять? Какая проблема сегодня с гигантскими размерами ПЛИС увеличить буффер до нужных размеров, чтобы забыть об этом?
А вообще мое ИМХО вам также стоит задуматься о том, чтобы привести свой обмен к модели OSI. В модели OSI канальный уровень отвечает за целостность и обнаружение ошибока, но не отвечает за восстановление данных после сбоя — это работа следующего, транспортного уровня. Aurora реализует только канальный уровень — поэтому она и не может восстанавливать данные.
Вы же в своем PROTEQ смешиваете и канальный и транспортный уровни — это может привести к проблемам с пониманием принципов работы и в будущем.dsmv2014
14.02.2017 19:11Данные совершенно обычные. Например 4 канала по 16 разрядов (само АЦП-14 разрядов) на частоте 500 МГц. Это 3814 МБайт/с. Скорость передачи по PROTEQ на 5 Гбит/с для 8 линий — 4484 Мбайт/с. Передача идёт блоком 8 кбайт. Передача одного блока это 1.7 мкс. От АЦП этот блок поступает за 2.04 мкс. Я использую FIFO АЦП размером 32 кбайта. Т.е. на 4 блока. Допустим, что произошла ошибка, тогда за время прихода трёх блоков в FIFO АЦП должна пройти повторная передача. PROTEQ это успевает. ПЛИС хотя и большая но не резиновая. Так что экономия памяти совершенно не лишняя.
PROTEQ соответствует модели OSI. А точнее физический, канальный и частично сетевой уровень.
Физический уровень это конечно GTX. А основная реализация это канальный уровень.
Более подробно можно прочитать в «dcr1206 — Протокол обмена данными PROTEQ.pdf» — документ здесь
То что Aurora на канальном уровне не обеспечивает надёжную передачу — это её особенности.
AndruB
12.02.2017 17:29К сожалению на сайте PROTEQ-WIKI-Алгоритмы основных операций не все все документы доступны — часть выдаёт 404 ошибку.
Не могли бы Вы поправить ссылки.
Frantony
13.02.2017 12:58Однако при ближайшем рассмотрении применять стандартные протоколы в ПЛИС не всегда удобно.
…
Протоколы действительно разные, но сравнивать их можно и нужно.Вот тут бы подробнее написать, какую именно задачу Вы решаете. Судя по тексту Вам надо организовать соединение точка-точка между двумя ПЛИС Xilinx. Тогда для решения такой задачи, используя наработки RapidIO, из всего стека протоколов RapidIO надо выбрать только подходящий протокол физического уровня (physical layer).
PROTEQ это не соперник полному стеку RapidIO или PCI Express! Их бесмысленно сравнивать. Но можно сравнить PROTEQ и, скажем, RapidIO LP-Serial Physical Layer v3.1.
PCI Express и RapidIO работают с кодировкой 8/10 что сразу ограничивает пропускную способность.
Тут мне знающие люди подсказали, что не одним 8/10 жив RapidIO LP-Serial. В версии 3 спецификации RapidIO LP-Serial для baud rates более 3.125 Гбод используется кодирование 64b/67b (см. http://www.rapidio.org/wp-content/uploads/2014/10/RapidIO-3.1-Specification.pdf, стр. 479 и далее). А есть и совсем новая спецификация RapidIO версии 4 (см. http://www.rapidio.org/rapidio-specifications/).
Никак не критикую проделанную автором работу, просто прошу быть более последовательным в изложении и точным в деталях.
P.S. Не в коей мере не пытаюсь восхвалить RapidIO, просто знаком с RapidIO чуть лучше, чем с PCI Express или Aurora.
dsmv2014
13.02.2017 13:07+1Вот здесь возникает вопрос что значит «взять». Взять и прочитать спецификацию — но её в ПЛИС на засунешь. Нужно IP ядро. Для Rapid IO есть OpenSource ядро которое сделали в Индии, но они сами пишут что в железе не проверяли. У них это академическая разработка. Xilinx имеет IP Core для спецификации 2.0 — это кодировка 8/10. Стоит он дорого, ~2M рублей. Есть американская фирма, которая предлагает IP Core спецификации 3.0, так они мне даже цену не сообщили.
Если сравнить PROTEQ и RapidIO LP-Serial Physical Layer v3.1, то скорее всего PROTEQ будет гораздо компактнее и обеспечит более быстрое восстановление при сбое. Что мне и нужно.Frantony
13.02.2017 13:15Вот здесь возникает вопрос что значит «взять». Взять и прочитать спецификацию — но её в ПЛИС на засунешь. Нужно IP ядро. Для Rapid IO есть OpenSource ядро которое сделали в Индии, но они сами пишут что в железе не проверяли. У них это академическая разработка. Xilinx имеет IP Core для спецификации 2.0 — это кодировка 8/10. Стоит он дорого, ~2M рублей. Есть американская фирма, которая предлагает IP Core спецификации 3.0, так они мне даже цену не сообщили.
Если сравнить PROTEQ и RapidIO LP-Serial Physical Layer v3.1, то скорее всего PROTEQ будет гораздо компактнее и обеспечит более быстрое восстановление при сбое. Что мне и нужно.Вот такое объяснение звучит гораздо убедительнее, чем
PCI Express и RapidIO работают с кодировкой 8/10 что сразу ограничивает пропускную способность.
Спасибо!
dsmv2014
13.02.2017 14:24Для уточнения — поскольку PCI Express и Rapid IO работают с кодировкой 8/10 этого достаточно что бы сразу их отбросить. Даже до этапа анализа где их взять и сколько они занимают места.
asmolenskiy
А Вы установили причину периодического возникания ошибок?
Это вполне может быть потому что Вы используете кодировку, предназначенную для быстрых интерфейсов, на таких низких битрейтах.
dsmv2014
Ошибки на таких линиях это неизбежность. Можно говорить о вероятности возникновения ошибки, она достаточно маленькая. Но рассчитывать что их там не будет нельзя. По опыту работы могу сказать что фиксируется ошибка за примерно за 5 часов работы. При отладке первых экземпляров модуля выяснилось что не очень хорошо работает источник питания ПЛИС. Это приводило к десяткам ошибок за секунду, но протокол с ними справлялся.
Скорость 5 Гбит/с это максимальная скорость для ПЛИС Virtex-6 с быстродействием 1. И на сегодняшний день ещё нельзя говорить что это низкая скорость. Кодировка от скорости вообще не зависит. Кодировка нужна для балансировки среднего уровня сигнала. Выбор не очень большой. В ПЛИС Virtex-6 аппаратно поддержаны только 8/10, 64/66 и 64/67; Я и выбрал 64/67 — она лучше отслеживает балансировку среднего уровня.
asmolenskiy
Ну вот это два взаимоисключающих параграфа. Я же не просто так это написал. 64 нуля/единицы подряд на битрейтах 5Gbps и 8Gbps — дадут Вам два разных спектра. И в первом случае оно может не очень хорошо пролазить через AC-конденсаторы, так как будет лежать в области более низких частот. Даже на PCIe Gen3 вместе с 64/66 применяют скрэмблирование, как раз чтоб такая ситуация не случалась. А на вашей скорости это и подавно стоит делать.
Лучше всего балансировку отслеживает именно 8/10. Потому что более 5 одинаковых битов подряд там в принципе быть не может. Что достаточно сильно ограничивает спектр снизу.
dsmv2014
Конечно скремблер есть. Без него работать не будет на любой скорости.
asmolenskiy
Ну значит Вы молодец и это учли =) Засим ограничусь.
Оценивать целесообразность этой работы как таковой — я не берусь.
dsmv2014
Спасибо
zsergt3
В PCIe Gen3 кодировка 130/128
dsmv2014
Обычно пишут 128/130 — и важный факт, аппаратная поддержка есть только в Ultrascale+; Для Virtex 7 требуется реализация на общей логике.
asmolenskiy
Это тоже самое, просто с удвоенным телом блока. Но да — Вы правы 128/130.
ishevchuk
Какой наблюдается bit error rate при использовании кодирования 8/10, 64/66, 64/67 и без использования кодирования?
Сравнивался ли этот показатель с результатами, показанные на платами других производителей?
asmolenskiy
Без использования кодирования последовательные интерфейсы не работают. Так как основная функция кодирования — это обеспечение нарезки последовательного потока на байты и слова и дифференциация данных на служебные символы и общие. Без кодирования — поток битов — это просто поток битов.
dsmv2014
Я не оценивал bit error rate, собственно этот протокол и нужен что бы не сильно обращать внимание на bit error rate. По наблюдениям — одна ошибка примерно за пять часов работы.