

SDAccel это система программирования на OpenCL для ПЛИС фирмы Xilinx. В настоящее время всё более обостряется проблема разработки проектов для ПЛИС на традиционных языках описания аппаратуры, таких как VHDL/Verilog. Одним из методов решения проблемы является применение языка C++. OpenCL это один из вариантов применения языка С++ для разработки прошивок ПЛИС.
Небольшое вступление про фазовые переходы
Мне пришлось заняться программированием ПЛИС в далёком 2000 году. В то время компьютеры были не очень мощными, а ПЛИС — совсем маленькими. Я работал c ПЛИС серии MAX7000 фирмы Altera. Для разработки прошивок использовалась замечательная система MaxPlus II. Основным средством там был графический редактор. Поддержка VHDL и Verilog уже была, но была очень слабой. Поддерживались только синтезируемое подмножество VHDL, Verilog. Зато можно было получить VHDL модель готовой ПЛИС с sdf файлом временных задержек. И соотношение мощности компьютера и объёма ПЛИС позволяло провести моделирование всего проекта ПЛИС с временными задержками. Сейчас об этом можно только мечтать. Примерно в это время начался фазовый переход в разработке проектов ПЛИС. Это был переход от схемного ввода к использованию VHDL/Verilog для моделирования отдельных узлов и всего проекта. В нашей компании он совпал с переходом от Altera и MaxPlus II к Xilinx и ISE. У нас этот переход завершился в 2004 году.
В данный момент идёт второй фазовый переход. Он связан с переходом разработки проектов ПЛИС от VHDL/Verilog к языку С++. Дело в том, что при современном соотношении мощности компьютера и объёма ПЛИС провести сеанс моделирования проекта ПЛИС на VHDL/Verilog практически невозможно. Сеанс моделирования может длиться от нескольких часов до нескольких дней. Такое время можно позволить для окончательной верификации проекта, но не для разработки.
Что такое OpenCL ?
Система OpenCL была предложена в 2008 году компанией Apple. В дальнейшем была организована ассоциация «Khronos Group» в которую вошли ведущие компании, такие как INTEL, NVIDIA, AMD, ARM, GOOGLE, SONY, SAMSUNG и много других. Кроме OpenCL там развиваются и другие системы, например OpenXR — система виртуальной реальности.
OpenCL — это система проектирования на основе С++ для гетерогенных систем таких как:
- обычные процессоры
- многопроцессорные кластеры
- графические процессоры
- ПЛИС
OpenCL определяет модель системы, расширения языка C++, библиотеку функций для HOST компьютера.
Большое время моделирования связано с моделированием на уровне тактовой частоты. Применение языка Си удаляет сигнал тактовой частоты из описания проекта. В проекте остаются только операции с данными. Это позволяет на несколько порядков увеличить скорость моделирования и разработки.
Одной из первых заметных систем программирования на Си является система Catapult компании Mentor Graphics. Эта система появилась в 2004 году и успешно используется в том числе компанией Microsoft для реализации своего поискового сервера Bing с использованием ПЛИС Altera.
Фирма Xilinx примерно в 2013 году выпустила Vivado HLS, которая позволяет разрабатывать отдельные компоненты на С++ и впоследствии включать их в основной проект. На основе Vivado HLS созданы ещё несколько продуктов:
- SDSoc — ускорение отдельных функций. Система предназначена только для Zynq (это микросхема в которой в одном корпусе есть ПЛИС и процессор АРМ). Система уже доступна.
- SDAccel — система программирования на OpenCL. Система доступна, но не всем.
- SDNet — система проектирования сетевых приложений. Пока не доступна и говорить о ней ещё рано.
SDSoc и SDAccel характерны тем, что проект ПЛИС уже отходит на второй план. На первом плане — алгоритм. Обе системы позволяют позволяют провести моделирование на уровне исходного алгоритма написанного на С/C++ и далее перевести его на ПЛИС. Это позволяет резко увеличить сложность алгоритма. И не случайно, что сейчас обе эти системы внедряются в обработку изображений.
Если сравнить программирование для ПЛИС на VHDL/Verilog и на С/С++, то напрашивается аналогия между программированием для обычных процессоров на С/C++ и на ассемблере. Да, на ассемблере можно сделать более компактный и быстрый код. Но на С/С++ можно написать более сложную программу.
Модель вычислителя
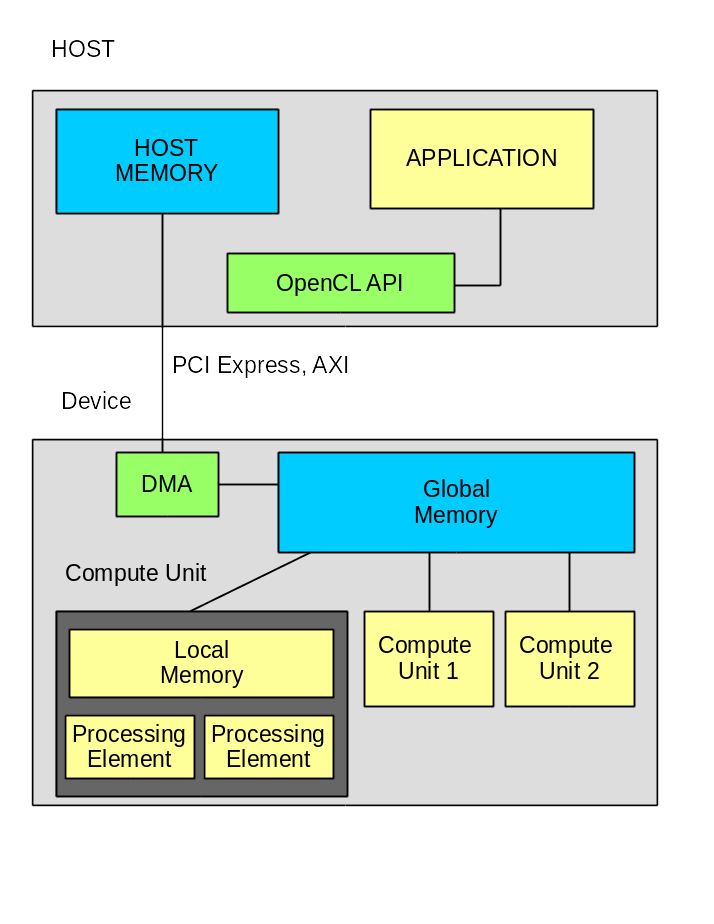
Система состоит из HOST компьютера и вычислителя, которые связаны между собой по шине. В большинстве случаев это шина PCI Express. Однако Altera уже предлагает решения для своих ПЛИС со встроенным процессором АРМ. В этом случае используется шина AXI. По некоторым слухам компания Intel (которая купила Altera) разрабатывает процессор Xeon со встроенной ПЛИС. Основной системой проектирования там будет OpenCL, а для взаимодействия между процессором и ПЛИС будет использоваться QPI.
Внутри вычислителя расположен один или несколько блоков «Compute Unit», каждый из которых состоит из одного или нескольких «Processing Element». На этом уровне есть принципиальная разница между графическими процессорами и ПЛИС. Если в графическом процессоре количество «Processing Element» определено (хотя оно разное в разных моделях), то в ПЛИС это может меняться в зависимости от задачи.
Стандарт определяет несколько классов памяти:
- HOST Memory — память доступная приложению на HOST компьютере. Обычно это оперативная память компьютера.
- Global Memory — память доступная для HOST и для вычислителя. Обычно это динамическая память подключённая к ПЛИС или к графическому процессору.
- Global Constant Memory — память доступная по чтению и записи для HOST и только для чтения на вычислителе.
- Local Memory — память доступная только в пределах одного «Compute Unit»
- Private Memory — память доступная только в пределах одного «Processing element»
Дополнительно Xilinx вводит «Global OnChip Memory» — память доступная всем «Compute Unit».
Упрощённый алгоритм работы:
- HOST проводит инициализацию устройства
- HOST загружает программу в вычислитель
- HOST подготавливает данные в HOST Memory
- HOST запускает DMA канал для передачи данных из HOST Memory в Global Memory и ожидает завершение DMA
- HOST запускает на выполнение вычислитель и ожидает завершение вычисления.
- HOST запускает DMA канал для передачи результата из Global Memory в HOST Memory и ожидает завершение DMA.
- HOST использует результаты вычисления.
Важно отметить следующее — всё общение между HOST и вычислителем идёт через Global Memory. В более сложных алгоритмах можно параллельно с вычислениями передавать данные для следующего цикла.
Что такое kernel ?
Kernel — это базовое понятие OpenCL. Собственно говоря, это функция которая выполняется на одном «Processing Element». Несколько kernel могут выполняться в рамках одного «Compute Unit». Это основной способ обеспечения параллельности операций для графических процессоров.
Пример определения функции:
__kernel void krnl_vadd(
__global int* a,
__global int* b,
__global int* c,
const int length);
В отличие от обычного описания здесь появляются новые ключевые слова, они как раз определены в стандарте OpenCL.
- __kernel — определяет функцию которая будет выполняться на вычислителе.
- __global — определяет что данные расположены в глобальной памяти.
SDAccel предлагает три способа реализации kernel:
- стандарт OpenCL
- C++ — при этом будут использованы все возможности Vivado HLS
- VHDL/Verilog — при этом будут использованы все возможности ПЛИС
Главное различие в реализации для GPU и ПЛИС
На примере простой функции сложения двух векторов очень удобно проследить главное различие в эффективной реализации кода для графических процессоров и для ПЛИС.
Функция сложения для GPU будет выглядеть так:
__kernel void
krnl_vadd(
__global int* a,
__global int* b,
__global int* c,
const int length)
{
int idx = get_global_id(0);
c[idx] = a[idx] + b[idx];
return;
}
А для ПЛИС вот так:
__kernel void __attribute__ ((reqd_work_group_size(1, 1, 1)))
krnl_vadd(
__global int* a,
__global int* b,
__global int* c,
const int length) {
for(int i = 0; i < length; i++){
c[i] = a[i] + b[i];
}
return;
}
Обратите внимание — в версии для GPU не используется параметр length. Предполагается, что для каждого элемента вектора будет запущен свой экземпляр kernel. Каждый экземпляр получит свой номер idx и выполнит сложение. Количество одновременно запущенных экземпляров будет определяться возможностями данного GPU. Если вектор будет слишком большим, то будет несколько запусков. Для ПЛИС так тоже можно сделать, но это не очень эффективно. Лучшие результаты даёт вариант в котором используется только один «Compute Unit» и один «Processing Elenet». Обратите внимание — перед объявлением функции добавился атрибут reqd_work_group_size( 1, 1, 1), а внутри самой функции есть цикл. Значение атрибута 1,1,1 означает что будет использоваться только один kernel. И это знание будет использоваться для оптимизации вычислительной структуры. Сам цикл с помощью дополнительных атрибутов может быть развёрнут в параллельную вычислительную структуру. Наилучший результат будет достигнут если length будет константой.
SDAccel
Начиная с версии 2016.3 SDAccel и SDSoc объединены в один пакет под названием SDx. SDSoc работает в Windows и Linux. SDAccel работает только под некоторыми версиями Linux, в частности — CentOs 6.8; Разумных объяснений таким ограничениям нет, надеюсь в будущем SDAccel будет работать и под Windows. Пакет SDx сделан на основе Eclipse. В нём добавляется тип проекта «Xilinx SDx». При создании проекта требуется выбрать платформу. Пока выбор небольшой. На рисунке представлен вид окна выбора платформы:

Платформа определят модуль и базовую прошивку ПЛИС. В SDAccel используется технология частичной перезагрузки (Partial Reconfiguration). Требуется соответствие между базовой прошивкой, которая загружена в ПЛИС и той на основе которой формируется проект SDAccel. Это соответствие поддерживается названием и версией платформы. Обратите внимание, верхняя строчка — это модуль FMC126P. Я пытаюсь создать для него платформу, пока неудачно.
Ещё один важный скришот — свойства проекта:
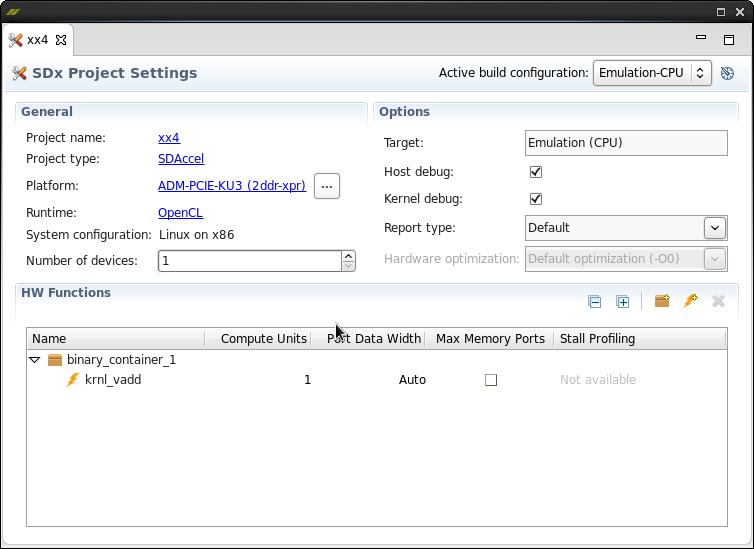
Обратите внимание на поле «HW Functions».
- binary_container_1 — это то, что будет загружено в ПЛИС.
- kernel-vadd — это имя функции
- Колонка «Comput Units» — по сути, это количество параллельных реализаций функции
- Колонка «Max Memory Ports» — разрешение дополнительной оптимизации при обращении к глобальной памяти
Очень важным является правое верхнее поле: «Active build configuration». Собственно говоря здесь заключена вся суть этой системы. Возможно три варианта:
- Emulation-CPU — реализация OpenCL на процессоре
- Emulation-HW — реализация OpenCL на симуляторе Vivado
- System — реализация OpenCL на выбранной аппаратной платформе
Результатом компиляции будет выполняемый файл, он кстати имеет расширение .exe, и файл с расширением .xclbin; Это binary_container с реализацией функций kernel.
Для трёх вариантов выполнения формируется разная среда выполнения OpenCL. Вариант Emulation-CPU самый быстрый для запуска. Компиляция и запуск производятся очень быстро. Именно в этом режиме надо проверять алгоритм.
Вариант Emulation-HW более долгий для компиляции и выполнения. В этом режиме вызывается Vivado HLS, производится синтез кода для VHDL/Verilog/SystemC и запускается симулятор Vivado для выполнения kernel. По резудьтатам компиляции можно определить занимаемые ресурсы и оценить задержки на выполнение. Моделирование может быть долгим, поскольку здесь уже есть тактовая частота и мы получаем все связанные с этим проблемы. Хотя наверняка для PCI Express и SODIMM используются упрощённые модели, что увеличивает скорость моделирования.
Вариант System является рабочим. Компиляция включает в себя трассировку ПЛИС, что является достаточно долгим процессом. Небольшой проект для ADM-PCIE-KU3 разводится около часа. Для запуска требуется установить драйвер устройства, который поставляется вместе с платформой. При запуске производится загрузка binary_container в ПЛИС с использованием технологии Partial Reconfiguration. Сама загрузка тоже не быстрая, около минуты. С чем это связано я объяснить не могу.
Программа для HOST
Стандарт OpenCL определяет API. На сайте Khronos Group все функции хорошо описаны. Но выглядит всё это достаточно мрачно. Однако Xilinx здесь тоже упростил нам жизнь. В состав примера vector_addition входят файлы xcl.h и xcl.cpp, в которых описаны самые необходимые функции для работы с одним устройством. Вот они:
- xcl_world_single(), xcl_world_release() — инициализация и завершение работы с устройством
- xcl_malloc() — выделение буфера в глобальной памяти на устройстве
- xcl_import_binary() — загрузка binary_container
- xcl_set_kernel_arg() — установка аргументов для функции kernel
- xcl_memcpy_to_device() — передача данных на устройство
- xcl_memcpy_from_devce() — передача данных из устройства
- xcl_run_kernel3d() — запуск функции на выполнение
Конечно программа для HOST может быть не одна. Вполне возможно сделать отдельный проект и подключить какую-либо систему Unit тестирования, например Google Test, для проверки реализации функций на ПЛИС.
А что внутри ПЛИС ?
В каталоге компонентов есть такой симпатичный элемент «SDAccel OpenCL Programmable Region»

Вот именно в него и будет загружен binary_container. Видно, что элемент имеет крайне малое количество связей. Есть шина S_AXI для управления, шина M_AXI для доступа к глобальной памяти, ну и сигналы тактовой частоты и сброса. Предполагается, что в ПЛИС есть узел DMA, контроллер динамической памяти и центральный узел axi_interconnect.
Блок SDAccel можно раскрыть, внутри он будет выглядеть так:

Не очень хорошо, но видно что есть два блока axi_interconnect, а между ними четыре блока kernel. Из такой структуры следует рекомендация не использовать большое количество kernel, поскольку на каждый блок потребуется своя шина AXI. Не рекомендуется использовать более 16 шин.
Потенциальные преимущества и реальные недостатки
Главным преимуществом системы является возможность реализации сложных алгоритмов для работы с большими массивами данных. Конечно понятия «сложный алгоритм» и «большой массив» являются условными. По моему субъективному мнению, применение системы будет эффективным для тех алгоритмов, для проверки которых требуется более 1 Мбайта тестовых данных. В первую очередь это конечно алгоритмы обработки изображений.
Другим потенциальным преимуществом является возможность перехода на другую аппаратуру. Например с ПЛИС Xilinx на ПЛИС Altera.
Основные недостатки:
- Это новая система, наверняка ещё есть необъяснимые баги
- Работа только под ограниченное количество вариантов Linux. Под Windows — не работает.
- Под вопросом эффективность трансляции с языка С++ на VHDL/Verilog. Хотя существует возможность реализации kernel на VHDL/Verilog.
Первое знакомство состоялось, что дальше
При дальнейшем изучении SDAccel я планирую следующее:
- Изучение эффективных методов работы с памятью, измерение скорости работы
- Разработка платформы для модуля FMC126P
- Реализация узла свёртки на основе библиотеки FPFFTK от Александра Капитанова ( capitanov )
P.S. Кстати, OpenCL не поддерживает
<stdio.h>, однако printf там есть. В том числе printf работает и при реализации на ПЛИС.Комментарии (26)
rPman
17.04.2017 15:17+1очень грустное ценообразование, $3k за pcie модуль, подешевле будут модули для камер, $750…
нужна, нужна очень грамотная конкуренция видеоускорителям на рынке числодробилок.
JerleShannara
17.04.2017 19:17Ну если смотреть в сторону альтеры, то там для OpenCL есть поддержка семейства Cyclone 5 SoC, а те платы стоят гораздо меньше. Вот если брать на Arria 10, то цена будет ещё больше — около 5к$. Плюс к этому надо покупать (триала на 30 дней нету вообще) лицензию на OpenCl компилятор для плис.

leshabirukov
17.04.2017 15:25А можно ли сначала написать kernel на kernel C, а потом допилить на верилоге? Например, если я хочу туда добавить что-то экзотическое, типа восьмибитной плавающей точки.

Mogwaika
19.04.2017 15:13Т.е. это по сути объединение универсальных ядер, поддерживающих openCL и исполняемый код отдельно или реализация только определённых заранее заданных последовательностей функций openCL в чистый hdl?

dsmv2014
19.04.2017 17:57Существует три способа написания kernel
1. Стандарт OpenCL
2. C++ — используется Vivado HLS со всеми возможностями оптимизации
3. RTL — на языках VHDL/Verilog.
Естественно, если идёт разработка на VHDL/Verilog, то в него можно вставлять компоненты на Vivado HLS.
Для варианта RTL в итоге получается компонент, которому стандартным образом передаются параметры и который запускается стандартной командой из программы HOST. Также есть стандартный механизм информирования о завершении работы. А всё остальное — определяется фантазией и возможностями разработчика.
old_bear
19.04.2017 23:34Для варианта RTL в итоге получается компонент, которому стандартным образом передаются параметры и который запускается стандартной командой из программы HOST. Также есть стандартный механизм информирования о завершении работы. А всё остальное — определяется фантазией и возможностями разработчика.
Хороший вариант, особенно в комплекте с возможностью проработать алгоритмическую часть на 1-м или 2-м варианте.
P.S. Извините, не в ту ветку уехало.
nerudo
В современных FPGA слишком много ресурсов, чтобы их использовать на HDL. Поэтому лишние мы займем рантаймом C++ ;)
dsmv2014
В runtime входит DMA контроллер, контроллер DDR, несколько AXI_INTERCONNECT (как минимум три). Это не много и соответствует обычному проекту. Но вопрос эффективности перевода С++ в HDL конечно остаётся.
old_bear
Думаю, что всё так же плохо как и раньше, как только делаешь маленький шажок в сторону от хелло-вордов типа сложения векторов.
IMHO, жизнеспособный вариант здесь только с написанием потрохов на HDL-е в комплекте с быстрым накидыванием интерфейса к хосту. А С-версию только в качестве раннего прототипа использовать.
JerleShannara
Не так давно altera\intel провела сравнение по производительности (кажись это был gzip) между «пишем на opencl для fpga» и «берём команду матёрых hdl-щиков»(кажись они были из IBM) и сравниваем производительность. Результат — opencl реализация слила, но менее чем на 10%, а время на разработку ушло гораздо меньше.
Mogwaika
А если сравнивать с GPU чипом производительность стала лучше?
dsmv2014
Это требует исследований. На данный момент GPU имеют преимущество по скорости памяти. Это очень серьёзное преимущество. А также PCI Express v3.0 x16 для GPU совершенно обычное дело. Для ПЛИС в основном только x8; Кроме того GPU гораздо дешевле. Но по утверждению Xilinx вычислитель на ПЛИС имеет на порядок меньшее энергопортебление. Я тут прикинул, для среднего дата центра с потреблением 20 Мегаватт экономия на электроэнергии составит около 100 миллионов рублей в год. (а то и больше). Это перекрывает все затраты. А также это даёт возможность при том же потреблении увеличить производительность.
nerudo
Сравнивать энергопотребление имеет смысл только в расчете на единицу производительности. И тут не совсем ясно, за счет чего у FPGA может быть столь значительное преимущество.
dsmv2014
GPU имеет определённую структуру. При это всё что не используется всё равно потребляет, хотя возможно и меньше чем в рабочем режиме. ПЛИС имеет изменяемую структуру. При этом то что не используется — не потребляет
JerleShannara
На жирной ПЛИС я могу запилить 1 ядро, или 2000 ядер. На топовом GPU я могу запилить 1 ядро, или максимум столько, сколько у этого GPU есть. На ПЛИС я могу запилить 10GbE, могу запилить 40GbE, на GPU — извините. На ПЛИС я могу поиметь QDR IV, на GPU — извините. И жрать оно может в разных конфигурация меньше, чем GPU. Опять-же, на ПЛИС я могу иметь несколько DDR/QDR/RLDRAM контроллеров, что даст мне прирост производительности в некоторых задачах.
Mogwaika
Но вы не забывайте, что готовая микросхема/asic под заданную функцию эффективнее ПЛИС и по частоте и по потреблению.
Что-то мне подсказывает, что всяких CUDA-ядер в одном процессоре тоже сотни или тысячи…
dsmv2014
Всё правильно, если функциональность известна, то можно сделать asic и он будет более эффективен чем ПЛИС. Но дело в том, что никто не будет делать asic под одну задачу. А ПЛИС уже есть и на ней можно экспериментировать.
В GPU TESLA K40 есть 2880 процессорных ядер. ПЛИС Kintex Ultrascale KU060 имеет 2760 DSP блоков. Хотя надо учитывать что DSP блок совершенно не одно и то же что процессорное ядро. Но для задач с фиксированной точкой это уже сравнимо. А Kintex Ultrascale KU115 имеет уже 5520 DSP блоков.
Mogwaika
Тут же обсуждается, как реализуются функции OpenCL на GPU kernels и FPGA kernels. Пока мне кажется, что для разных функций FPGA kernels могут тоже оказаться одинаковыми.
Ну DSP совсем не то же самое, иначе можете добавить ещё несколько тысяч ядер, реализованных на LUT-ах…
dsmv2014
На примере сложения векторов уже можно увидеть что kernel для GPU и FPGA ДОЛЖНЫ БЫТЬ РАЗНЫМИ Это следует из структуры.
Для GPU: каждый kernel это сложение одного элемента, или нескольких. Для ускорения параллельно запускается много экземпляров. Счёт экземпляров идёт на тысячи.
Для FPGA: нельзя сделать много kernel. Это ограничивается числом AXI портов в компоненте AXI_INTERCONNECT. Рекомендация Xilinx — это 16 портов. Это либо 16 kernels, либо меньше если kernel имеет несколько портов. Но зато каждый kernel может легко реализовать параллельное вычисление на всех доступных ресурсах.
rPman
т.е. компилятор не будет разворачивать мой код на все доступные ресурсы? грусть печаль.
dsmv2014
Будет. Компилятор может использовать все доступные ресурсы в пределах одного kernel.
rPman
значит я не понимаю фразу:
тупой пример сложения векторов в памяти, которая так же реализуется на FPGA, будет работать всего в 16 'потоков'?
Я думал что компилятор попытается приделать сумматор к каждому числу в этой памяти и для итогового вычисления будет все сделано за один проход/такт.
dsmv2014
Давайте рассмотрим пример сложения векторов. В заголовке статьи фото модуля ADM-PCIE-KU3; Этот модуль содержит два SODIMM 8ГБ — 1600; Внутри ПЛИС для каждого SODIMM есть свой контроллер. Шина контроллера — 512 бит.Частота 200 МГц. Скорость доступа к SODIMM около 10 Гбайт/с. Через AXI_INTERCONNECT эти два контроллера подключены к области OpenCL. Суммарная скорость обращения к памяти — около 20 Гбайт/с. Она будет разделяться между всеми клиентами. Принципиального различия в количестве kernel нет. Если будет один, то для него можно сделать два порта для двух SODIMM и получить максимальную скорость доступа к памяти. Можно сделать несколько kernel, в этом случае они будут толкаться на INTERCONNECT. Если портов будет больше 16, то накладные расходы резко возрастут, что вызовет дополнительные проблемы.
С точки зрения быстродействия, то лучше всего разместить два исходных вектора в разных SODIMM, а результат складывать тоже в разные SODIMM.При этом возможно получить скорость близкую к максимальной.
Хотя надо не забывать про PCI Express на котором 5 Гбайт/с.
На шине 512 бит будет 16 отсчётов по 32 бита. Для их сложения потребуется 16 DSP блоков. С некоторой натяжкой можно считать что обработка будет проводится в 16-ти «потоках». Так что здесь всё сводится к быстродействию памяти.
rPman
вы говорите про внешнюю память на узкой шине данных, естественно количество kernel буде ограничено пропускной способностью шины.
я спрашивал про ситуацию, когда внутренние промежуточные буферы реализуются тоже на вентилях fpga, тут же в коде opencl/verilog.
dsmv2014
Промежуточные буферы будут реализованы на внутренней памяти ПЛИС. OpenCL определяет несколько вариантов, Xilinx их поддерживает.