

Владимир Бородин (на «Хабре» dev1ant), системный администратор группы эксплуатации систем хранения данных в «Яндекс.Почте», знакомит со сложностями миграции крупного проекта с Oracle Database на PostgreSQL. Это — расшифровка доклада с конференции HighLoad++ 2016.
Всем привет! Меня зовут Вова, сегодня я буду рассказывать про базы данных «Яндекс.Почты».
Сначала несколько фактов, которые будут иметь значение в будущем. «Яндекс.Почта» — сервис достаточно старый: он был запущен в 2000 году, и потому мы накопили много legacy. У нас — как это принято и модно говорить — вполне себе highload-сервис, больше 10 миллионов пользователей в сутки, какие-то сотни миллионов всего. В бэкенд нам прилетает более 200 тысяч запросов в секунду в пике. Мы складываем более 150 миллионов писем в сутки, прошедших проверки на спам и вирусы. Суммарный объём писем за все 16 лет — больше 20 петабайт.
О чем пойдет речь? О том, как мы перевезли метаданные из Oracle в PostgreSQL. Метаданных там не петабайты — их чуть больше трехсот терабайт. В базы влетает более 250 тысяч запросов в секунду. Надо иметь в виду, что это маленькие OLTP-запросы, по большей части чтение (80%).
Это — не первая наша попытка избавиться от Oracle. В начале нулевых была попытка переехать на MySQL, она провалилась. В 2007 или 2008 была попытка написать что-то своё, она тоже провалилась. В обоих случаях был провал не столько по технически причинам, сколько по организационным.
Что является метаданными? Здесь они выделены стрелочками. Это папки, которые собой представляют какую-то иерархию со счётчиками, метки (тоже, по сути, списки со счётчиками), сборщики, треды и, конечно же, письма.
Мы не храним сами письма в метабазах, тела писем находятся в отдельном хранилище. В метабазах мы храним конверты. Конверты — это некоторые почтовые заголовки: от кого, кому, тема письма, дата и подобные вещи. Мы храним информацию о вложениях и цепочках писем.

Назад в 2012 год
Всё это лежало в Oracle. У нас было очень много логики в самой хранимой базе. Оракловые базы были самым эффективным железом по утилизации: мы складывали очень много данных на шард, больше 10 терабайт. Условно говоря, при 30 ядрах у нас нормальный рабочий load average был 100. Это не когда всё плохо, а при штатном режиме работы.
Баз было мало, поэтому многое делалось руками, без автоматизации. Было много ручных операций. Для экономии мы делили базы на «тёплые» (75%) и «холодные» (25%). «Тёплые» — это для активных пользователей, они с SSD. «Холодные» — для неактивных пользователей, с SATA.
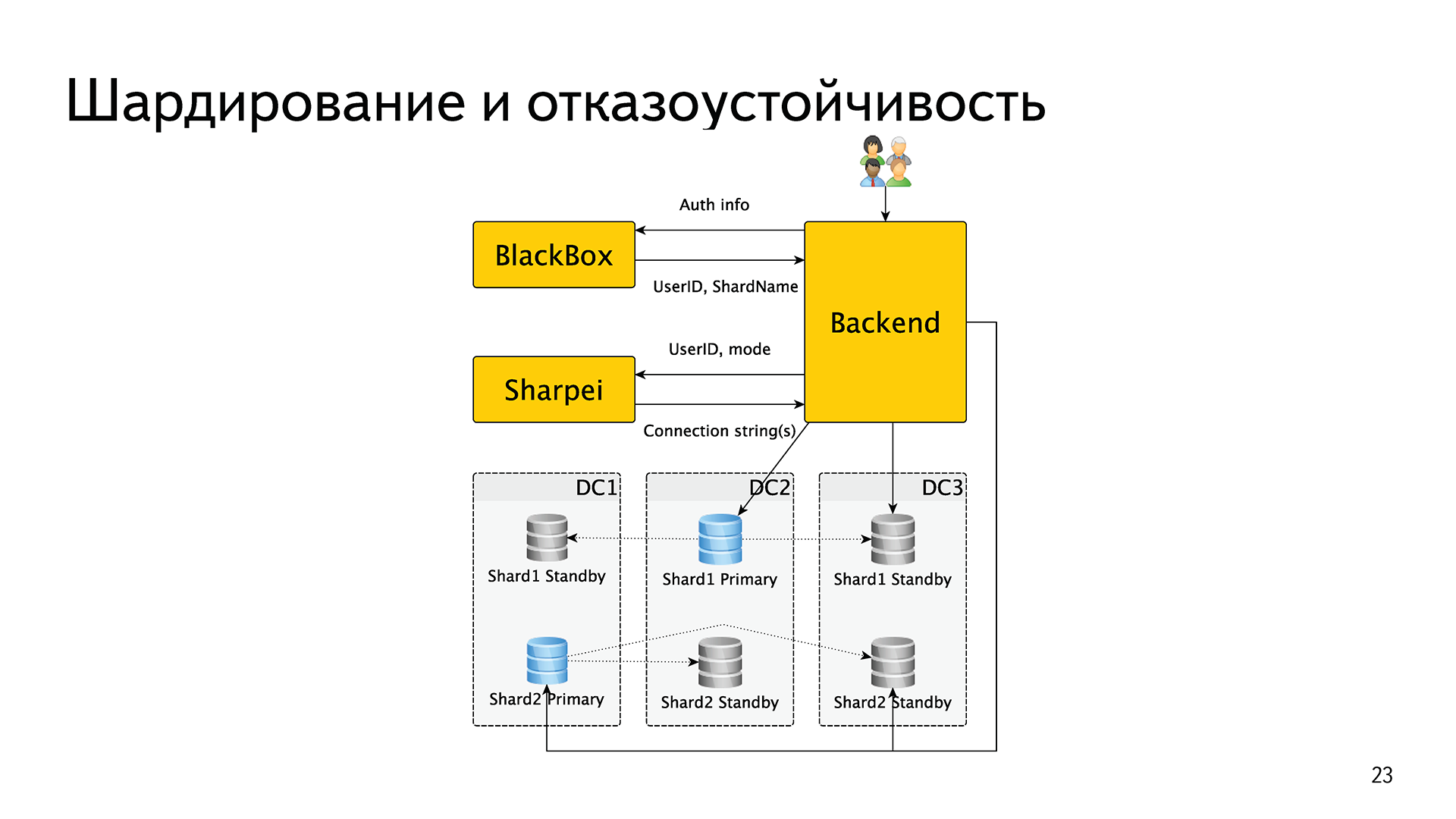
Шардирование и отказоустойчивость — важная тема в «Яндексе». Шардирование — потому что в один шард всё не запихаешь, а отказоустойчивость — потому что мы регулярно берем и отключаем один из наших дата центров, чтобы увидеть, что всё работает.
Как это было реализовано? У нас есть внутренний сервис BlackBox (чёрный ящик). Когда один запрос прилетает на один из наших бэкендов, бэкенд обменивает аутентификационные данные — логин, пароль, cookie, token или что-то подобное. Он идет с этим в BlackBox, который в случае успеха возвращает ему идентификатор пользователя и имя шарда.
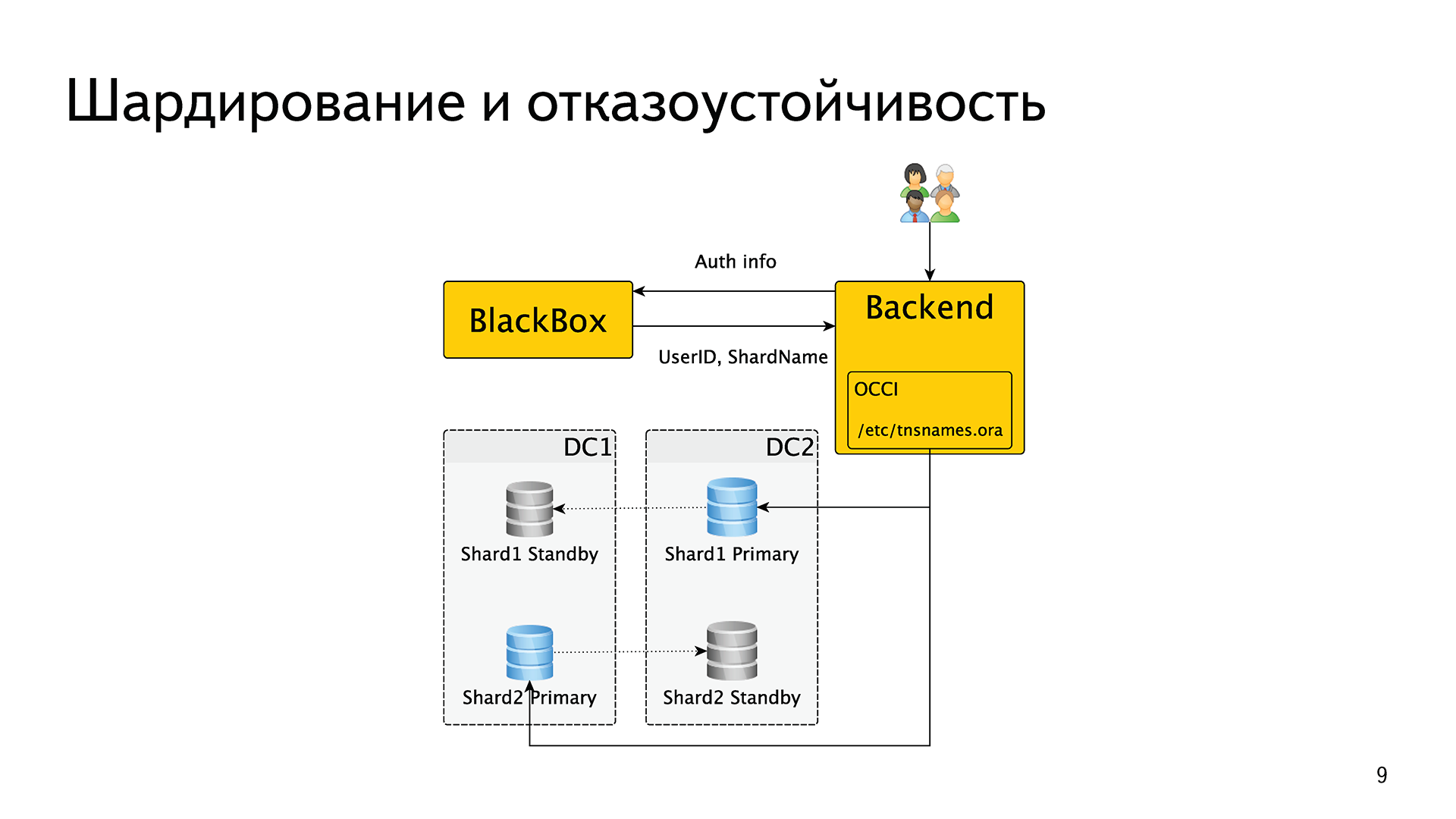
Затем бэкенд скармливал это имя шарда в оракловый драйвер OCCI, дальше внутри этого драйвера была реализована вся логика отказоустойчивости. То есть, грубо говоря, в специальном файлике /etc/tnsnames.ora были записаны shardname и список хостов, которые в этот шард входят, его обслуживают. Oracle сам решал, кто из них мастер, кто реплика, кто жив, кто мертв и т. д. Итого, шардирование было реализовано средствами внешнего сервиса, а отказоустойчивость — средствами драйвера Oracle.
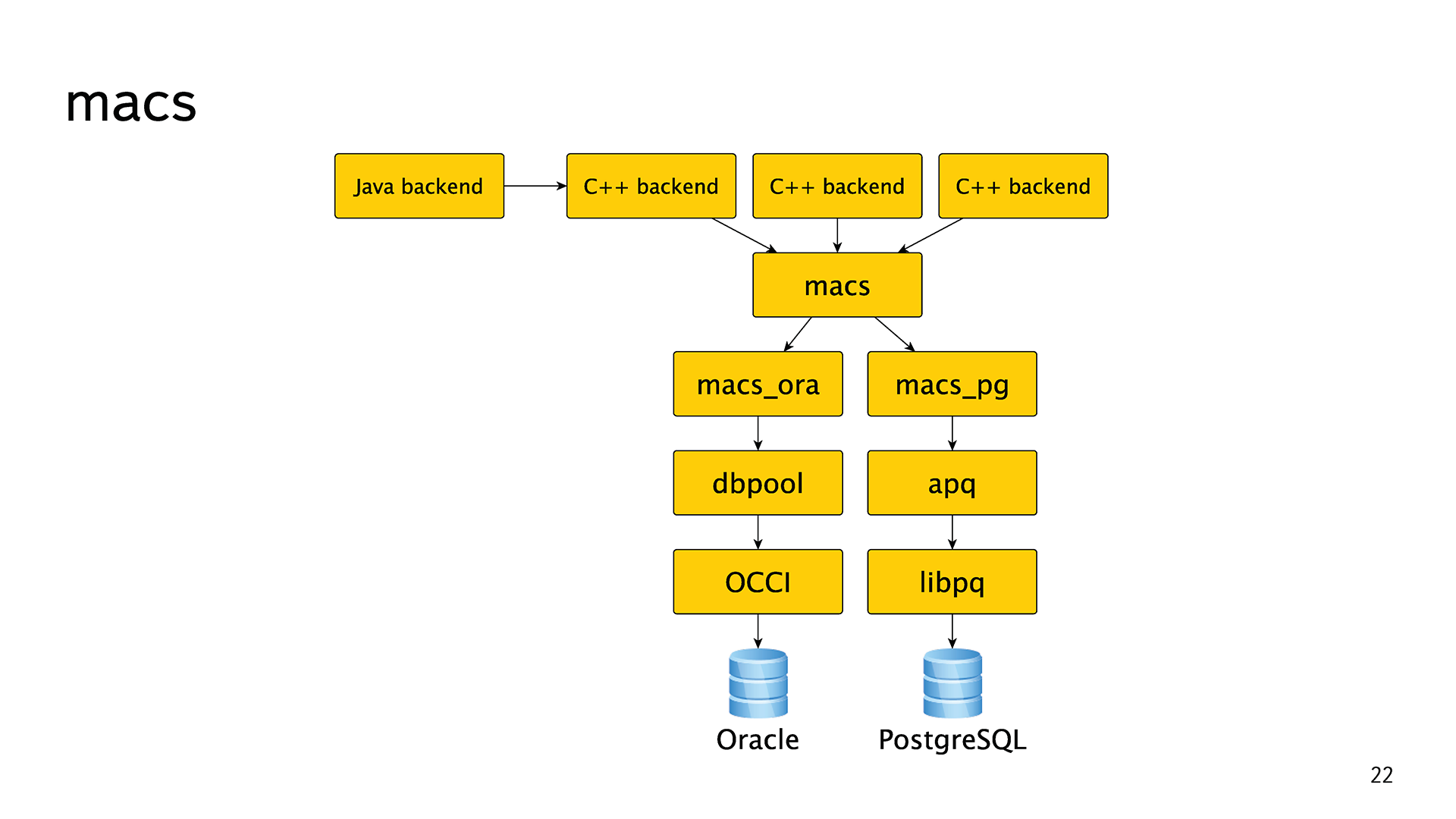
Большая часть бэкендов была написана на C++. Для того, чтобы не плодить «велосипедов», у них долгое время существовала общая абстракция macs meta access. Это просто абстракция для хождения в базы. Практически всё время у неё была одна реализация macs_ora для хождения непосредственно в Oracle. В самом низу, конечно же, OCCI. Еще была небольшая прослойка dbpool, которая реализовывала пул соединения.
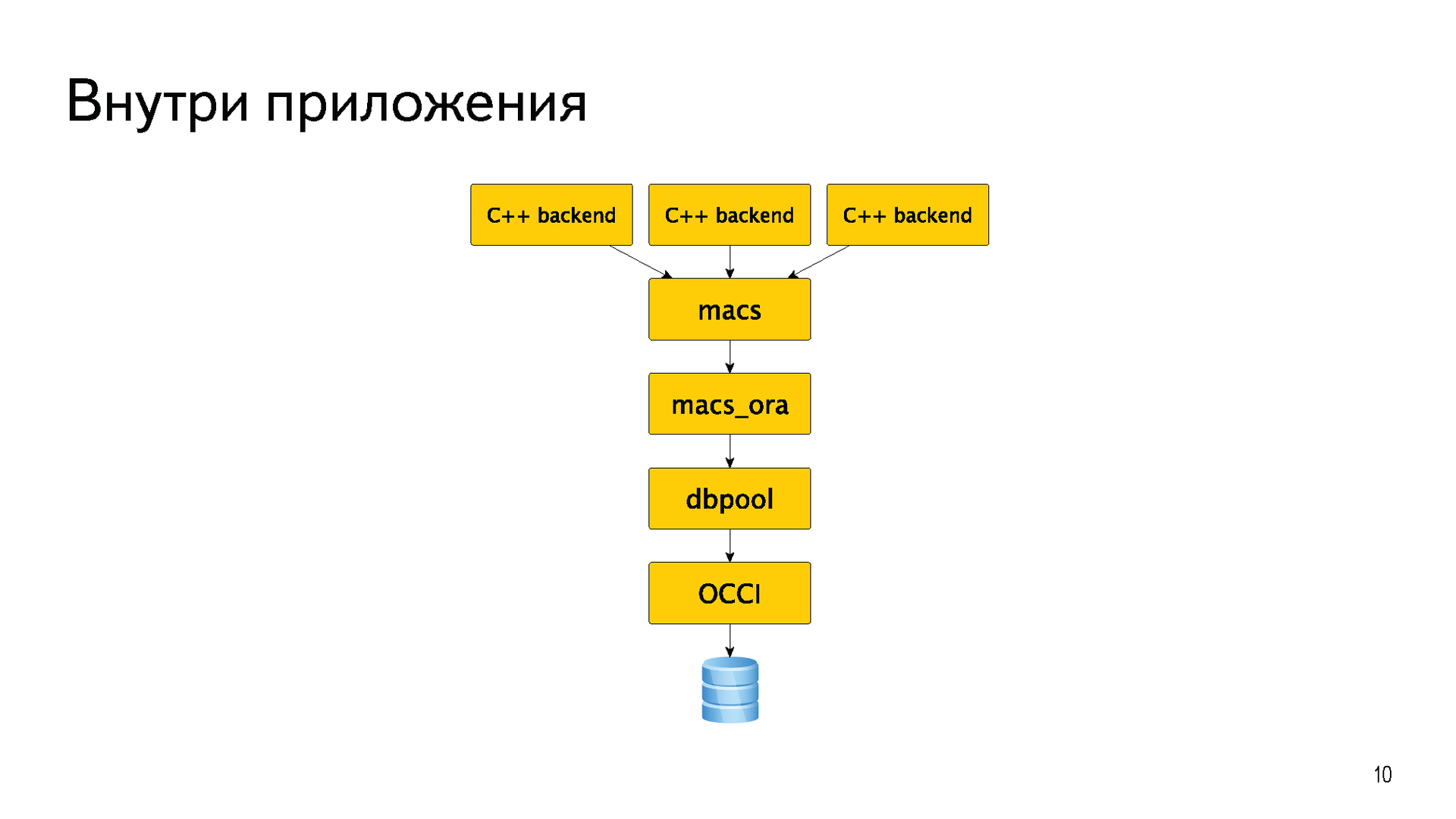
Вот так это когда-то давно задумывалось, дизайнилось и реализовывалось. С течением времени абстракции протекли, бэкенды начали использовать методы из реализации macs_ora, еще хуже если из dbpool. Появились Java и всякие другие бэкенды, которые не могли использовать эту библиотеку. Всю эту лапшу потом пришлось мучительно разгребать.
Oracle — прекрасная база данных, но и с ней были проблемы. Например, выкладка PL/SQL кода — это боль, потому что есть library cache. Если база под нагрузкой, то нельзя просто взять и обновить код функции, который сейчас используется какими-то сессиями.
Остальные проблемы связаны не столько с Oracle, сколько с тем подходом, который мы использовали. Опять же: множество ручных операций. Переключение мастеров, наливка новых баз, запуск переносов пользователей — всё делалось руками, потому что баз было немного.
С точки зрения разработки есть недостаток в том, что плюсовый [C++] оракловый драйвер имеет только синхронный интерфейс. То есть нормальный асинхронный бэкенд поверх написать не получится. Это вызывало некоторую боль в разработке. Вторую боль в разработке вызывало то, что поднять тестовую базу проблематично. Во-первых, потому что руками, во-вторых, потому что это деньги.
Кто бы что ни говорил, поддержка у Oracle есть. Хотя поддержка enterprise-компаний зачастую далека от идеала. Но главная причина перехода — это деньги. Oracle стоит дорого.
Хронология
В октябре 2012 года, больше 4 лет назад, было принято решение о том, что мы должны избавиться от Oracle. Не звучало слов PostgreSQL, не звучало каких-либо технических подробностей — это было чисто политическое решение: избавиться, срок в 3 года.
Спустя полгода мы начали первые эксперименты. На что были потрачены эти полгода, я могу чуть попозже рассказать. Эти полгода были важные.
В апреле 2013 мы поэкспериментировали с PostgreSQL. Тогда был очень модный тренд на всякие NoSQL-решения, и мы попробовали много всякого разного. Мы вспомнили, что у нас все метаданные уже хранятся в бэкенде поиска по почте, и может быть, можно использовать его. Это решение тоже попробовали.
Первый успешный эксперимент был со сборщиками, о нем я рассказывал на митапе в «Яндексе» в 2014 году.
Мы взяли небольшой кусочек (2 терабайта) довольно нагруженных (40 тысяч запросов в секунду) почтовых метаданных и унесли их из Oracle в PostgreSQL. Тот кусочек, который не очень связан с основными метаданными. У нас получилось, и нам понравилось. Мы решили, что PostgreSQL — наш выбор.
Далее мы запилили прототип почтовой схемы уже для PostgreSQL и начали складывать в него весь поток писем. Делали мы это асинхронно: все 150 миллионов писем в день мы складывали в PostgreSQL. Если покладка не удалась бы, то нам было бы всё равно. Это был чистый эксперимент, продакшн он не задевал.
Это позволило нам проверить первоначальные гипотезы со схемой. Когда есть данные, которые не жалко выкинуть — это очень удобно. Сделал какую-то схему, напихал в неё писем, увидел, что не работает, всё дропнул и начал заново. Отличные данные, которые можно дропать, мы такие любим.
Также благодаря этому получилось в некоторой степени провести нагрузочное тестирование прямо под живой нагрузкой, а не какой-то синтетикой, не на отдельных стендах. Так получилось сделать первоначальные прикидки по железу, которое понадобится для PostgreSQL. И конечно же, опыт. Основная цель предыдущего эксперимента и прототипа — это опыт.
Дальше началась основная работа. Разработка заняла примерно год календарного времени. Задолго до того, как она закончилась, мы перенесли из Oracle в PostgreSQL свои ящики. Мы всегда понимали, что никогда не будет такого, что мы всем покажем на одну ночь «извините, технические работы», перенесем 300 терабайт и начнем работать на PostgreSQL. Так не бывает. Мы бы обязательно сломались, откатывались, и всё было бы плохо. Мы понимали, что будет довольно длительный период времени, когда часть ящиков будет жить в Oracle, а часть — в PostgreSQL, будет идти медленная миграция.
Летом 2015 года мы перенесли свои ящики. Команда «Почты», которая её пишет, тестирует, админит и так далее, перенесла свои ящики. Это очень сильно ускорило разработку. Страдает абстрактный Вася, или страдаешь ты, но можешь это поправить, — это две разные вещи.
Даже до того, как мы дописали и реализовали все фичи, мы начали нести неактивных пользователей. Неактивным мы называем такого пользователя, которому почта приходит, мы складываем письма, но он их не читает: ни вебом, ни с мобильным, ни IMAP — ему они неинтересны. Есть такие пользователи, к несчастью. Мы начали нести таких неактивных пользователей, когда у нас, допустим, ещё не полностью был реализован IMAP, или не работала половина ручек в мобильном приложении.
Но это не потому, что мы такие смелые и решили всем ящики сломать, а потому что у нас был план Б в виде обратного переноса, и он нам очень сильно помог. Была даже автоматизация. Если мы перенесли пользователя, и он вдруг попробовал, например, зайти в веб-интерфейс — проснулся и стал активным — мы обратно переносили его в Oracle, чтобы не ломать ему никакие фичи. Это позволило нам поправить кучу багов в коде трансфера.
Затем последовала миграция. Вот несколько интересных фактов. 10 человеко-лет мы потратили на то, чтобы переписать всю нашу лапшу, которую мы накопили за 12—15 лет.
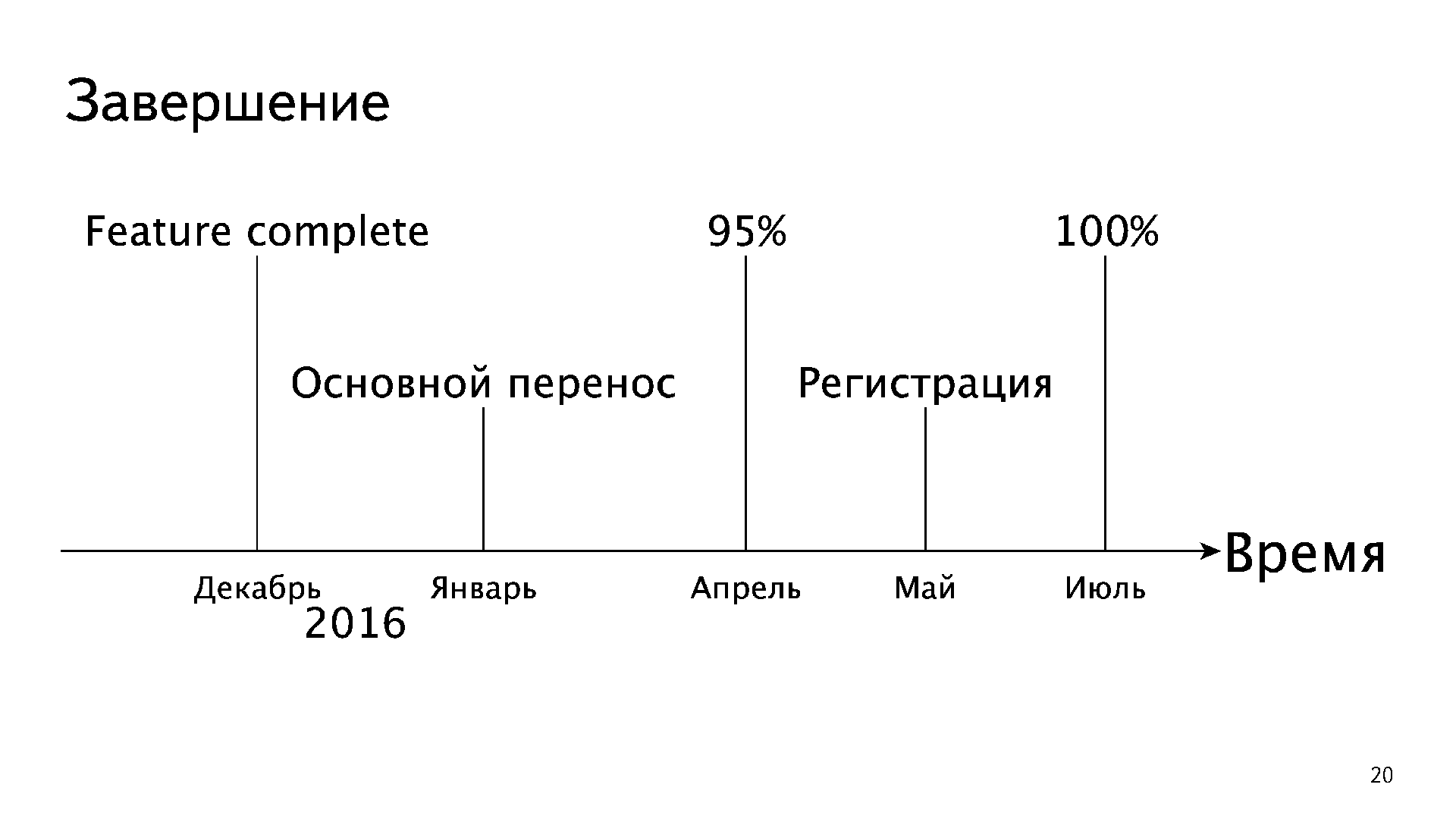
Сама миграция при этом прошла очень быстро. Это график за 4 месяца. Каждая линия — это процент нагрузки, который сервис отдаёт из PostgreSQL. Разбито на сервисы: IMAP, web, POP3, покладка, мобильные и так далее.

К сожалению, пропасть перепрыгнуть на 95% нельзя. Мы не смогли всех перенести к апрелю, потому что регистрация оставалась в Oracle, это довольно сложный механизм. Получилось так, что мы регистрировали новых пользователей в Oracle и сразу же ночью их переносили в PostgreSQL. В мае мы запилили регистрацию, и в июле погасили уже все базы Oracle.
Основные изменения
В нашей абстракции появилась еще одна реализация macs_pg, и мы распутали всю лапшу. Все те протекшие абстракции пришлось аккуратно переписать. Внизу у нее libpq, сделали еще небольшую прослойку apq, где реализован пул соединений, таймауты, обработка ошибок, и всё это асинхронно.
Шардирование и отказоустойчивость — всё то же самое. Бэкенд получает аутентификационные данные от пользователя, обменивает их в BlackBox на идентификатор пользователя и имя шарда. Если в имени шарда есть буква pg, то дальше он делает еще один запрос в новый сервис, который мы назвали Sharpei. Бэкенд передаёт туда идентификатор этого пользователя и режим, в котором он хочет получить базу. Например, «я хочу мастер», «я хочу синхронную реплику» или «я хочу ближайший хост». Sharpei возвращает ему строки подключения. Далее бэкенд открывает соединение, его держит и использует.
Чтобы знать информацию, кто мастер, кто реплика, кто жив, кто мертв, кто отстал, кто нет, Sharpei раз в секунду ходит в конечные базы и спрашивает их статусы. В этом месте появился компонент, который взял на себе обе функции: и шардирования, и отказоустойчивости.
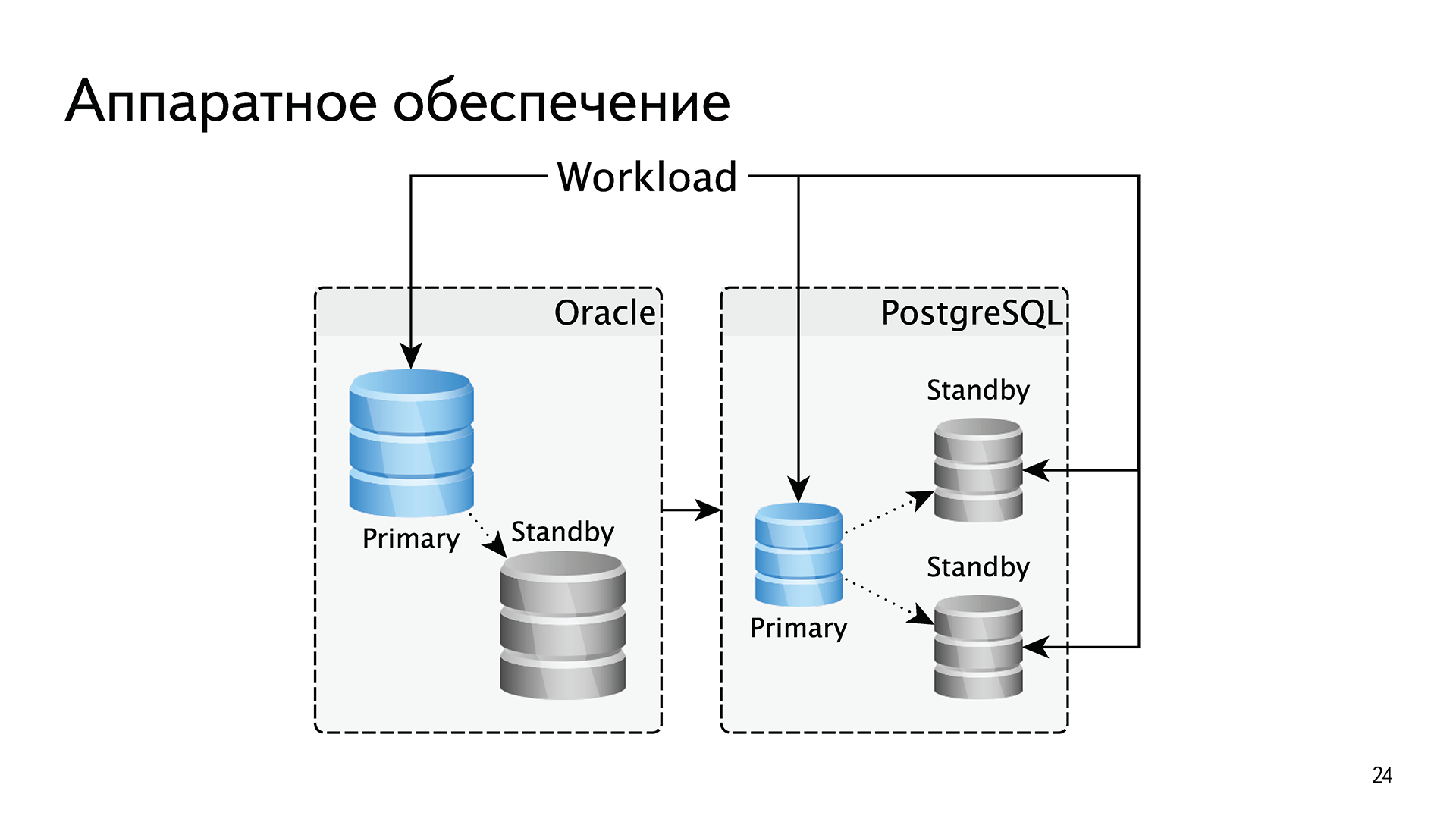
В плане железа мы сделали несколько изменений. Поскольку Oracle лицензируется по процессорным ядрам, мы были вынуждены масштабироваться вертикально. На одно процессорное ядро мы напихивали много памяти, много SSD-дисков. Было небольшое количество баз с небольшим количеством процессорных ядер, но с огромными массивами памяти и дисков. У нас всегда была строго одна реплика для отказоустойчивости, потому что все последующие — это деньги.
В PostgreSQL мы поменяли подход. Мы стали делать базы поменьше и по две реплики в каждом шарде. Это позволило нам заворачивать читающие нагрузки на реплики. То есть в Oracle всё обслуживалось с мастера, а в PostgreSQL — три машины вместо двух поменьше, и чтение заворачиваем в PostgreSQL. В случае с Oracle мы масштабировались вертикально, в случае с PostgreSQL масштабируемся горизонтально.
Помимо «тёплых» и «холодных» баз появились еще и «горячие». Почему? Потому что мы внезапно обнаружили что 2% активных пользователей создают 50% нагрузки. Есть такие нехорошие пользователи, которые нас насилуют. Под них мы сделали отдельные базы. Они мало чем отличаются от теплых, там тоже SSD, но их меньше на одно процессорное ядро, потому что процессор там активнее используется.
Разумеется, мы запилили автоматизацию переноса пользователей между шардами. Например, если пользователь неактивный, сейчас живет в саташной [с SATA-накопителем] базе и вдруг начал использовать IMAP, мы его перенесём в «тёплую» базу. Или если он в теплой базе полгода не шевелится, то мы его перенесём в «холодную».
Перемещение старых писем активных пользователей с SSD на SATA — это то, что мы очень хотим сделать, но пока не можем. Если ты активный пользователь, живешь на SSD и у тебя 10 миллионов писем, они все лежат на SSD, что не очень эффективно. Но пока что в PostgreSQL нормального секционирования нет.
Мы поменяли все идентификаторы. В случае с Oracle они были все глобально-уникальными. У нас была отдельная база, где было написано, что в этом шарде такие диапазоны, в этом — такие. Разумеется, у нас был факап, когда в силу ошибки пересеклись идентификаторы, а на их уникальность была завязана примерно половина всего. Это было больно.
В случае с PostgreSQL мы решили перейти к новой схеме, когда у нас идентификаторы уникальны в пределах одного пользователя. Если раньше уникальным был mid идентификатор письма, то теперь уникальной является пара uid mid. Во всех табличках у нас первым полем uid, им всё префиксивано, он является частью пока везде.
Кроме того, что это меньше места, есть ещё один неочевидный плюс. Поскольку все эти идентификаторы берутся из сиквенсов, у нас меньше конкуренция за последнюю страничку индекса. В Oracle мы для решения этой проблемы вкрячивали реверсивные индексы. В случае PostgreSQL так как вставки идут в разные страницы индекса, мы используем обычные B-Tree, и у нас есть range-сканы, все данные одного пользователя в индексе лежат рядом. Это очень удобно.
Мы ввели ревизии для всех объектов. Это позволило читать с реплик, во-первых, неустаревшие данные, во-вторых, инкрементальные обновления для IMAP, мобильных. То есть ответ на вопрос «что изменилось в этой папке с такой-то ревизии» за счет этого сильно упростился.
?
В PostgreSQL всё хорошо с массивами, композитами. Мы сделали денормализацию части данных. Вот один из примеров:
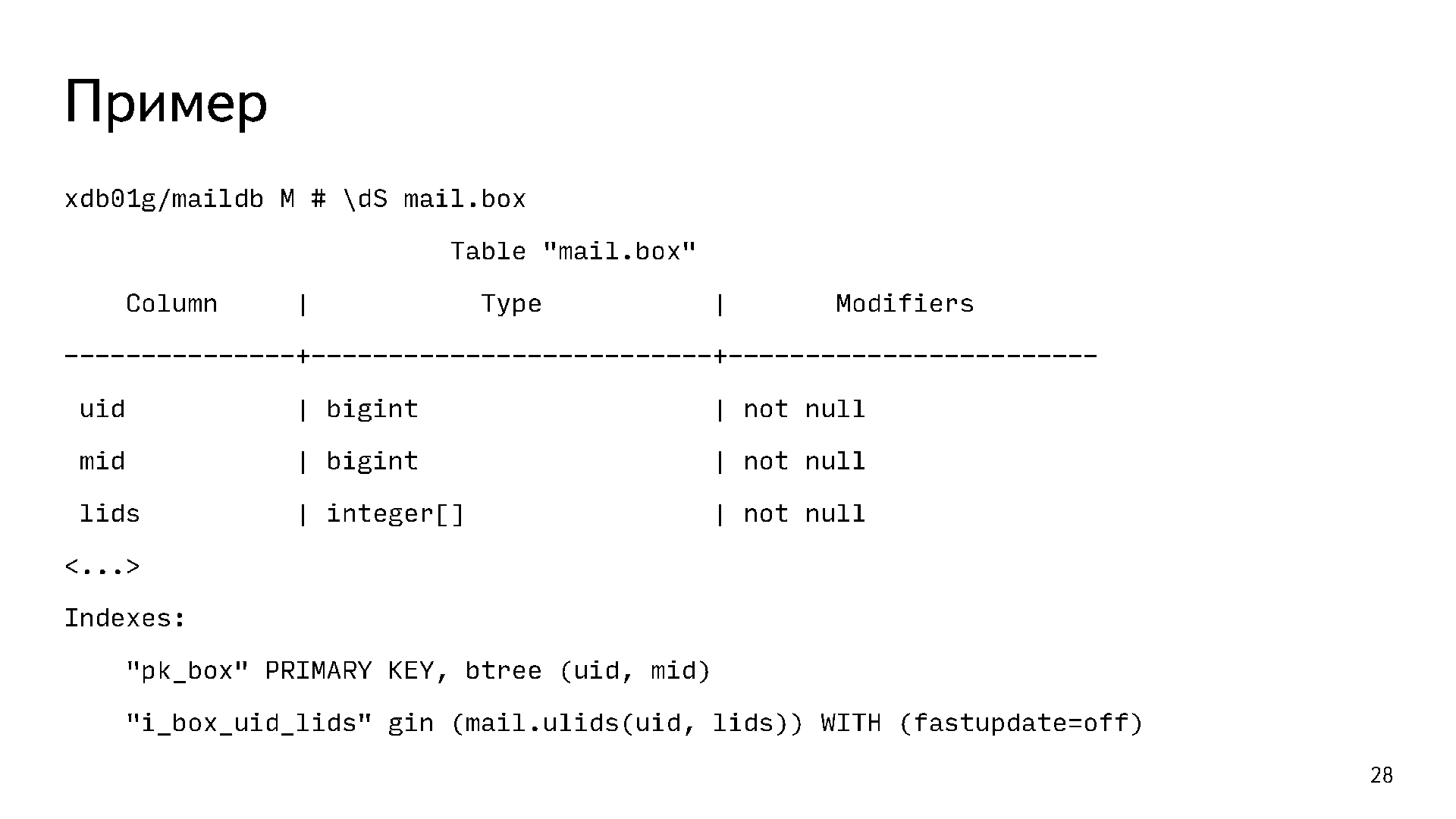
Это наша основная табличка mail.box. Она содержит по строчке на каждое письмо. Первичным ключом у нее является пара uid mid. Ещё там есть массив меток lids, потому что на одном письме может быть больше одной метки. При этом есть задача отвечать на вопрос «дай мне все письма с такой-то меткой». Очевидно, что для этого нужен какой-то индекс. Если построить B-Tree индекс по массиву, то он не будет отвечать на такой вопрос. Для этого у нас используется хитрый функциональный индекс gin по полю uid и lids. Он позволяет нам отвечать на вопрос «дай мне все письма такого-то пользователя с такими-то метками или с такой-то меткой».
Хранимая логика
- Поскольку с Oracle было очень много боли с хранимой логикой, мы зареклись что в PostgreSQL хранимой логики не будет вообще, никакой. Но в процессе наших экспериментов и прототипов мы поняли, что PL/pgSQL очень даже хорош. Он не страдает проблемой с library cache, и мы не нашли других сильно критичных проблем.
- При этом количество логики сильно сократили, оставили только ту что нужна для логической целостности данных. Например, если вы кладёте письмо, то увеличиваете счётчик в табличке с папками.
- Поскольку нет undo, цена ошибки стала сильно выше. В undo мы залазили пару раз после выкладки плохого кода, про это мой коллега Александр делал отдельный доклад у нас на митапе.
- Из-за отсутствия library cache оно сильно проще деплоится. Мы катаемся по пару раз в неделю вместо раза в квартал, как было раньше.
Подход к обслуживанию
- Поскольку мы поменяли аппаратное обеспечение и стали масштабироваться горизонтально, то и подход к обслуживаю баз мы поменяли. Базами мы теперь рулим SaltStack. Самая главная его киллер-фича для нас — это возможность видеть детальный diff между тем, что сейчас есть на базе, и тем, что мы от неё ожидаем. Если наблюдаемое устраивает, то человек нажимает кнопку «выкатить», и оно катится.
- Схему и код мы теперь изменяем через миграции. У нас был отдельный доклад про это.
- От ручного обслуживания мы ушли, всё, что можно, автоматизировали. Переключение мастеров, переносы пользователей, наливки новых шардов и так далее — всё это по кнопке и очень просто.
- Поскольку развернуть новую базу — это одна кнопка, мы получили репрезентативные тестовые окружения для разработки. Каждому разработчику по базе, по две, сколько захочет — это очень удобно.
Проблемы
Такие вещи гладко не проходят никогда.
Это список тредов в комьюнити с проблемами, которые мы самостоятельно решить не смогли.
- Problem with ExclusiveLock on inserts
- Checkpoint distribution
- ExclusiveLock on extension of relation with huge shared_buffers
- Hanging startup process on the replica after vacuuming on master
- Replication slots and isolation levels
- Segfault in BackendIdGetTransactions
То есть мы пошли в комьюнити, и нам помогли. Это была проверка, что делать, когда у тебя нет enterprise-поддержки: есть комьюнити, и оно работает. И это очень здорово. Разумеется, сильно больше проблем мы решили сами.
Например, у нас была очень популярна вот такая шутка: «В любой непонятной ситуации виноват autovacuum». Эти проблемы мы тоже порешали.
Нам очень не хватало способов диагностики PostgreSQL. Ребята из Postgres Pro запилили нам wait-интерфейс. Об этом я уже рассказывал на PG Day в 2015 году Питере. Там можно почитать, как это работает. С помощью ребят из Postgres Pro и EnterpriseDB оно вошло в ядро 9.6. Не всё, но какая-то часть этих наработок вошла в 9.6. Дальше эта функциональность будет улучшаться. В 9.6 появились столбцы, которые позволяют сильно лучше понимать, что происходит в базе.
Сюрприз. Мы столкнулись с проблемой с бэкапами. У нас recovery window 7 дней, то есть мы должны иметь возможность восстановиться на любой момент в прошлом за последние 7 дней. В Oracle размер места под все бэкапы и архивлоги был равен примерно размеру базы. База 15 терабайт — и её бэкап за 7 дней занимает 15 терабайт.
В PostgreSQL мы используем barman, и в нём под бэкапы нужно места минимум в 5 раз больше, чем размер базы. Потому что WAL сжимаются, а бэкапы нет, там есть File-level increments, которые толком не работают, вообще всё однопоточное и очень медленное. Если бы мы бэкапили as is эти 300 терабайт мета-данных, у нас понадобилось бы примерно 2 петабайта под бэкапы. Напомню, всего хранилище «Почты» — 20 петабайт. То есть 10% мы должны были бы отрезать только под бэкапы мета-баз за последние 7 дней, что довольно плохой план.
Мы не придумали ничего лучше и запатчили barman, вот pull request. Уже почти год прошел, как мы их просим запилить эту киллер-фичу, а они просят с нас денег, чтобы замержить её. Очень наглые ребята. Мой коллега Евгений, который всё это и запилил, рассказывал об этом на PGday в 2016 году. Оно правда сильно лучше жмёт бэкапы, их ускоряет, там честные инкременты.
По опыту эксперимента, прототипа, других баз, которые к тому времени появились у нас на PostgreSQL, мы ожидали кучу граблей во время переноса. А их не было. Было много проблем, но с PostgreSQL они связаны не были, что было для нас удивительно. Было полно проблем с данными, потому что за 10 лет накопилось много всякого legacy. Внезапно обнаружилось, что в каких-то базах данные лежат в кодировке KOI8-R, или другие странные вещи. Разумеется, были ошибки в логике переноса, поэтому данные тоже приходилось чинить.
Завершение
Есть вещи, которых нам очень не хватает в PostgreSQL.
Например, секционирование, чтобы двигать старые данные с SSD на SATA. Нам не хватает хорошего встроенного recovery manager, чтобы не использовать форк batman, потому что до ядра barman это, наверное, не доедет никогда. Мы уже устали: почти год их пинаем, а они не очень-то торопятся. Кажется, это должно быть не в стороне от PostgreSQL, а именно в ядре.
Мы будем развивать wait-интерфейс. Думаю, в 10-й версии случится quourum commit, там патч в хорошем состоянии. Ещё мы очень хотим нормальную работу с диском. В плане дискового I/O PostgreSQL сильно проигрывает Oracle.
Что в итоге? Если учитывать рейды-реплики, то у нас в PostgreSQL больше 1 петабайта. Недавно я считал, там чуть больше 500 миллиардов строк. Туда влетает 250 тысяч запросов в секунду. Всего у нас это заняло 3 календарных года, но мы потратили больше 10 человеко-лет. То есть усилие всей команды довольно внушительное.
Что мы получили? Стал быстрее деплой, несмотря на то, что баз стало сильно больше, а число DBA уменьшилось. DBA на этот проект сейчас меньше, чем когда был Oracle.
Хотели того мы или нет, но нам пришлось порефакторить весь код бэкенда. Всё то legacy, которое копилось годами, выпилилось. Наш код сейчас почище, и это очень хорошо.
Без ложек дёгтя не бывает. У нас сейчас в 3 раза больше железа под PostgreSQL, но это ничто по сравнению со стоимостью Oracle. Пока у нас не было крупных факапов.
Небольшое замечание от меня. В «Почте» мы используем много open source библиотек, проектов и готовых решений. К трём стульям, на которых мы плотно сидели, которые у нас есть почти везде, — Linux, nginx, postfix — добавился PostgreSQL. Сейчас мы его используем под многие базы в других проектах. Он нам понравился. Четвёртый — хороший, надёжный стул. Я считаю, это история успеха.
У меня всё. Спасибо!
Владимир Бородин — История успеха «Яндекс.Почты» с PostgreSQL
Комментарии (116)

apro
14.02.2017 02:18+14Ещё мы очень хотим нормальную работу с диском. В плане дискового I/O PostgreSQL сильно проигрывает Oracle.
А кто-нибудь может "развернуть" это предложение, что именно не так с I/O PostgreSQL?

Triffids
14.02.2017 11:54+3у оракла есть многоблочное чтение (scattered read), когда по DMA одной SCSI командой достает 128 блоков напрямик в память.
qasta
14.02.2017 17:27И в отличии от Oracle postgresql слой чтения данных с диска в буффер ОС не оптимизирует никак (оставляет на откуп операционной системе) — это так задумано специально. Так что, можно, наверное, крутить настройки монтирования файловой системы.
P.S. Давно это было… мог и соврать.
apro
14.02.2017 21:32у оракла есть многоблочное чтение (scattered read), когда по DMA одной SCSI командой достает 128 блоков напрямик в память.
А под какой ОС он это умеет? В linux например можно работать с блочными устройствами напрямую минуя кэши из user-space, но штатного интерфейса для работы с DMA из user-space не предусмотренно.
Triffids
14.02.2017 21:53в linux не знаю, знаю в windows они ReadFileScatter пользуют из win api. оно им мимо всяких кешей файлововой системы читает прямо в память. а у постгреса выходит еще и двойное кеширование, один раз кеширует файловая система второй раз постгесовский кеш.
dev1ant
15.02.2017 09:53Под нашей нагрузкой postgres по I/O проигрывал в 4 раза. И как показал PGCon 2016, разработчики postgres'а в курсе всех проблем.
Например, нельзя отдать без малого всю память под разделяемый кэш, потому что алгоритм вытеснения буфера очень паршивый. Приходится активно использовать page cache, которым сложно управлять + двойное кэширование. Или нет нормального асинхронного I/O, потому что поддерживается 100500 платформ, во многих из которых этого и близко нет.

soshnikov
14.02.2017 03:00+7Статья позитивная очень. Прочитал с удовольствием. Спасибо.
Вот только… Практический каждый параграф просто просится развернуться в отдельную техническую статью :)dev1ant
15.02.2017 14:03+1Это ведь была не статья, а доклад, ограниченный по времени. 3 года за 40 минут рассказать сложно :)
А вообще о некоторых вещах мы отдельно рассказывали и на эти доклады ссылки есть.

coolspot
14.02.2017 04:07+11После этого поста агрессивные психопаты набежали в комментарии пулл-реквеста barman:

eshimischi
14.02.2017 09:51нашим только дай повод побузить, надо или не надо… лучше бы помогли убедить разрабов в необходимости разработки ребят из яндекса…

kamikazer
17.02.2017 14:17Ой, не надо ныть. После такой лени и вывода автора «наглые ребята» стоило дать им пинка


artemisia_borealis
14.02.2017 07:20-2>>Всего у нас это заняло 3 календарных года, но мы потратили больше 10 человеко-лет.
Т.е. вас не менее 4-ёх человек.dev1ant
15.02.2017 15:11+1Команда бэкенда почты сильно больше. Но во время миграции сделали и запустили много несвязанного с переездом, потому и человеко-годы.

zxweed
14.02.2017 08:59+2а почему не поехали сперва на standart edition? оно же сильно дешевле и переписывать почти ничего не пришлось бы…

ggo
14.02.2017 09:45+1Обычно ответ зачем нужен enterprise edition — hot standby.
Triffids
14.02.2017 12:06ну в статье говориться что стендбай для красоты стоял: Мы стали делать базы поменьше и по две реплики в каждом шарде. Это позволило нам заворачивать читающие нагрузки на реплики. То есть в Oracle всё обслуживалось с мастера
Akela_wolf
14.02.2017 12:52Он ждал своего звездного часа, чтобы когда мастер упадет самому стать мастером :)
Triffids
14.02.2017 13:30-7вобщем вопрос так и повис в воздухе, чего SE редакцию не поставили?
явно было бы на порядок дешевле переезда на постгрес
а менять одну рсубд на другую путь в никуда, яндексу явно надо было куда-то в сторону бигдата смотреть, hadoop/spark скорее всегоSjfx
14.02.2017 17:15Навряд ли на порядок дешевле постгреса.
У них явно не 30 ядер работают, а раза в 2-3 больше. 15-20 процев, на пальцах.
Стоимость SE на несколько лет все равно была бы под полляма.
Минус партиции, которых на SE никогда не будет, минус стэндбай.Triffids
14.02.2017 20:45-2откуда на 20 процев пол ляма? SE стоит $6к на проц (именно проц, не ядра), 20 штук с супортом $141k, со стандартными скидками и SE стебаями вышло бы отсилы $200к
по партишанам во первых у них партиций и так нет, во вторых в SE есть partition view (PARTITION_VIEW_ENABLED)
http://www.sql.ru/forum/actualutils.aspx?action=gotomsg&tid=801747&msg=9747235
т.е. эти лапти могли бы на SE архивированные года уносить на HDD свежие года на SSD, объединять вьюшкой и оптимизатор оракла сам бы догадывался (partition elimination) не трогать таблицы 2010 года, если обращение идет к 2017 году.Sjfx
14.02.2017 21:26примерно $6k — это для SE One, для SE — $17500 на процессор + 22% техподдержка на год
PARTITION_VIEW_ENABLED — это параметр оптимизатораTriffids
14.02.2017 21:34-2да, SE1, при шардинге ничего кроме SE1 и не нужно.
в 2016, когда они запускали постгрес, можно было уже по 40+ ядер на 2 сокета SE1 ставить. куда больше то?
dev1ant
15.02.2017 14:12+2SE мы рассматривали как альтернативу, но сейчас можно уверенно сказать, что мы сделали правильный выбор.
Да, это был более сложный путь, но не надо думать, что для SE не пришлось бы ничего переделывать. И потом оно, конечно, дешевле EE, но прямо скажем, не бесплатно :)


dmsn
14.02.2017 09:53+2Из статьи не до конца понял как реализовывалась реплика баз. Использовался pgpool-II?

Nastradamus
14.02.2017 14:16Было бы странно если бы такие ребята использовали такие костыли при переделки такого проекта :)
Streaming у них.
mspain
14.02.2017 10:04-5Я правильно понял, что эксперименты с NOSQL были в середине нулевых?
ИМХО, надо вообще убрать тогда все упоминания NOSQL из текста статьи 2017 года, т.к. в те годы оно было никакое.
А сейчас эффективность утилизации железа у того же Mongo на порядки круче, чем у Oracle (а не в 3 раза хуже, как у PG). По крайней мере на моих проектах.
Впрочем, подозреваю, что информация о том, что PG в 3 раза неэффективнее Oracle тоже устарела.Akela_wolf
14.02.2017 11:51+2А из чего следует что «PG в 3 раза неэффективнее Oracle»? В статье сказано «У нас сейчас в 3 раза больше железа под PostgreSQL», НО «сервер PostgreSQL» и «сервер Oracle» нельзя сравнивать напрямую. В статье опять же сказано, что хотелось больше серверов Оракла, но не моглось потому что резко возрастала цена лицензий. Поэтому приходилось «по максимуму» использовать имеющиеся сервера, нашпиговывая их «до упора». У постгреса 2 реплики, а не 1 — то есть серверов уже в полтора раза больше только за счет этого. Ну и подозреваю, что сервера постгреса все-таки «полегче» оракловых.
mspain
14.02.2017 12:06-1У меня домыслы, у вас домыслы. Возможно в статье безграмотная формулировка «в 3 раза больше железа», а имелось в виду не по стоимости, а по количеству например сокетов. Думаю, никто уже разьяснять не будет.
gearbox
14.02.2017 13:50Так же не забываем что неизвестно что получили на «в три раза больше железа» — то же что и было или же + какие то плюшки (я вот тоже отметил увеличение числа реплик) В общем ждем комментариев от автора.
dev1ant
15.02.2017 14:24+2Железо действительно разное и сравнивать его сложно. Из плюшек получили больше реплик, с которых обслуживаем часть нагрузки, меньшую зависимость от падения конкретной машинки и, главное, уход от вертикального масштабирования к горизонтальному.
dev1ant
15.02.2017 14:19+3Вся история происходила в 2012-2016 гг. И утверждение про слабую применимость NoSQL (особенно нахваливаемой вами MongoDB) для нашей задачи всё ещё актуально и в 2017-м.
mspain
16.02.2017 07:07Скажем так, Монго 3.0 вышла всего лишь в 2015 году.
5 лет (даже с 2012) в мире ИТ это разные эпохи.
Mongo 2.1 из 2012 примерно такой же монго 3.4 как и mysql3 и mysql10 :)
Поэтому мнение про слабую применимость остается лишь мнением. Ещё и поданным без тезисов. :)
Я, как диванный эксперт и хэйтер кустарных решений, вообще бы максимально использовал промышленные решения: линуксовый dm-cache для разделения горячих и холодных данных и гибридные НЖМД. А не патчи, скрипты, хранимочки и синюю изоленту. Вполне возможно что работало бы не хуже, а время разработки было бы не десяток человеко лет, а несколько месяцев.dev1ant
17.02.2017 03:24+3Скажем так, в Яндекс.Диске самая большая инсталляция MongoDB в мире. Да, версия 3.0 была большим шагом вперёд, но наш опыт (а не пустое мнение, как вы пишите) говорят о слабой применимости монги для задачи Яндекс.Почты. Да и сейчас ребята из 10gen ещё детские болячки долечивают — https://jepsen.io/analyses/mongodb-3-4-0-rc3.
Разделение данных на горячие/холодные внутри шарда мы только хотим сделать, а не сделали. И кучу времени мы потратили совсем не на это. Рекомендую вам сначала почитать статью/посмотреть презентацию или видео, прежде чем писать комментарии про синюю изоленту у нас.
Anross
14.02.2017 10:04-4То ли подача материала, то ли недостаток деталей, но прочитав статью возникли сомнения в компетентности админов во время работы с Oracle. А когда решили переехать взяли и поправили многие допущенные ранее ошибки.
1) Откуда и почему появилась мешанина бекэндов?
2)Остальные проблемы связаны не столько с Oracle, сколько с тем подходом, который мы использовали.
То есть все причины к отказу от Oracle по сути сводятся к дороговизне? Или все же у варианта PostgreSQL есть инструменты которые решили проблему автоматизации, а у Oracle нет?
3) Перед решением о переезде считали ли итоговые затраты Oracle+железо+доработки с PostgreSQL+железо+доработки? Получился ль реальный экономический выигрыш?
atomlib
14.02.2017 10:14+9Цитаты из текста:
«Яндекс.Почта» — сервис достаточно старый: он был запущен в 2000 году, и потому мы накопили много legacy.
Но главная причина перехода — это деньги. Oracle стоит дорого.
У нас сейчас в 3 раза больше железа под PostgreSQL, но это ничто по сравнению со стоимостью Oracle.
Anross
14.02.2017 10:21-6И легаси, если правильно понял, они правили при переносе на PostgreSQL. Неужели нереально было было сделать перенос с Oracle на Oracle с исправлением легаси?
Про стоимость возник вопрос из-за:
Мы не придумали ничего лучше и запатчили barman, вот pull request. Уже почти год прошел, как мы их просим запилить эту киллер-фичу, а они просят с нас денег, чтобы замержить её.
Сравнивать стоимость одного железа с стоимостью лицензии Oracle как-то абстрактно и не показательно.
Мне приходят на ум варианты, когда итоговая стоимость переноса выше из-за суммы: покупок доработок к PostgreSQL, стоимости разработки переноса и самого переноса, стоимости оборудования с учетом его обслуживания (больше места, электроэнергии, охлаждение, замена вышедшего из строя, больше техников).hdfan2
14.02.2017 10:31-8Неужели нереально было было сделать перенос с Oracle на Oracle с исправлением легаси?
Видимо, не смогли убедить начальство. «У нас всё и так работает, а мы влупим кучу денег и переделаем, и всё будет снова работать, но хуже, пока все баги не вычистим». Догадываюсь, куда их послали. А вот на экономию за счёт отказа от Оракла купились.
dev1ant
15.02.2017 14:36+2Не было задачи избавиться от legacy. Просто решили, что переезд на postgres — это хороший шанс упростить себе жизнь в будущем.
dev1ant
15.02.2017 14:33+2Вам уже ответили комментарием ниже. Сложный проект за долгие годы активного развития умеет обрастать костылями.
В докладе честных два слайда про причины и слайд с результатами, там ведь всё расписано. Кроме денег получили более простой deploy кода и нормальные разработческие окружения. Попробуйте, например, оракл в докер засунуть.
- Считали, получился.

servekon
14.02.2017 10:59+9Планирует ли Яндекс стать спонсором или внести другой вклад в сообщество PostgreSQL?
Utopi
14.02.2017 11:54-5Уйти от Oracle из-за дороговизны и начать вливать бабки в PostgreSQL? Не думаю :) И вклад в сообщество они уже вносят, запатчив barman и отдав изменения разработчикам PostgreSQL. Только вот не нужна разработчикам PostgreSQL бесплатная помощь, они хотят что бы им помогали за деньги.
dev1ant
15.02.2017 14:40+3Ну, мы вроде и так вклад вносим. В barman, pg_repack, pg_rewind есть наше участие. В самом postgres'е при нашем активном участии в 9.6 появились зачатки wait interface'а. Надеюсь, дальше будет больше :)
zhigalin
14.02.2017 12:45Это возможно не совсем то место но в последнее время Почта регулярно рандомно выдаёт мне ошибку https SEC_ERROR_OCSP_OLD_RESPONSE в Ubuntu на последнем Firefox.
Время у меня правильное…
eviland
14.02.2017 13:19+2По-моему, Оракл — изначально неверный выбор БД для мэйл сервиса. Я себе слабо представляю, за счёт чего можно окупить энтерпрайз версию на бесплатном почтовом сервисе. Оракл — надёжный, удобный и быстрый — спору нет, но мне кажется, что с помощью хорошей архитектуры изначально можно было реализовать продукт соответствующий всем требованиям хорошего мэйл сервиса используя более дешёвые компоненты.
Akela_wolf
14.02.2017 13:30+5А какой был выбор в 2000 году? MySQL 3.23, который умел чуть менее чем ничего по сравнению с Oracle/MS SQL?
В каком состоянии был постгрес на тот момент я, к сожалению, не в курсе — об этой БД узнал значительно позже. Но, полагаю, у него тоже были определенные проблемы.
enabokov
14.02.2017 14:30-1А, так внезапно удвоившееся количество правил в почте — это, значит, ваших рук дело. А меня саппорт убеждал, что 1) меня кто-то взломал 2) «сам дурак».

tbicr
14.02.2017 15:36Интересно как работает перенос пользователей с холодной в горячую базу и назад, это через постгрэс или полностью ручками писалось?
dev1ant
15.02.2017 14:42+3Вся логика переноса — это ~ 5k строчек кода на питоне.
tbicr
15.02.2017 16:58Больше интересуют детали, например, кто решает когда пользователя нужно перекинуть, есть ли fk связи и если есть, то каким образом переносится пачка записей в разных таблицах, какой подход когда пользователь что-то пишет во время переноса, как обрабатывается ситуация когда что-то пошло не так (упало, отвалился конекшэн)?
dev1ant
15.02.2017 17:15+2Перенос можно запустить либо руками (скрипт/jenkins job), либо это делает автоматика по весьма тупым критериям (не шевелился никак кроме покладки полгода — в sata и т.п.). Сейчас думаем в это место вкрячить ML, чтобы критерии самим не прописывать.
FK, конечно же есть, многие из них deferrable. Потому данные переносятся потаблично в правильном порядке. Параллелизма для пользователя нет (один пользователь — один поток). Потребление памяти константное, потому что копирование делается поточно с помощью COPY пачками фиксированного размера.
Глобально же перенос выглядит так. Открываются транзакции в шард-источник, где пользователь блокируется на запись, в шард приёмник и в шарпей. В случае успешного переноса всё коммитится с 2PC. В случае ошибок откатывается. Во время переноса ящик пользователя в read-only, но это в общем случае не проблема, потому что ящик на 10**5 писем переносится за единицы секунд.
tbicr
15.02.2017 19:26Правильный порядок таблиц задан жёстко или есть логика которая может раскручивать зависимости каскадно? Потому что если схама часто меняется, то можно наткнуться, хотя конечно это сразу можно словить ролбэком транзакции и подправить.
Существуют ли внешние ссылки на данные в базе (например мыло или другие ключи), я так понимаю когда происходит перенос, то кто-то внешний знает где лежит конкретный ключик?
Можете подсказать что такое `шарпей` :)?dev1ant
16.02.2017 03:47+1Задан жёстко. Логика переноса лежит в том же репозитории, что и схема БД с кодом и тестами. На каждое изменение гоняются покоммитные тесты, проверяющие в т.ч. и работу трансфера.
Шарпей — это наш сервис шардирования, который хранит соответствие пользователя и шарда. И в нём, конечно, при переезде происходит обновление данных. Про это есть в презентации.

Botkin
15.02.2017 22:35Почему не использовали вместо этого хардварный или программный automated tiering (https://en.m.wikipedia.org/wiki/Automated_tiered_storage), чтобы он вам на уровне блоков данные ротировал на самом хранилище?
Triffids
15.02.2017 23:11по моему такое противопоказано рсубд с оптимизаторами, эта фигня дурит оптимизатор. у нас оракловый оптимизатор с ума сходил, он ночью собирал статистику и рассчитывает пробежать по индексам на SSD за 4 секунды, но эти блоки были вытеснены на HDD и реально вместо секунд 30 минут долбит HDD одноблочным…
dev1ant
16.02.2017 03:54+1Выше речь идёт про перенос между физическими шардами, никаких NAS/SAN там и близко нет из соображений производительности.
Что касается разделения данных на горячие и холодные внутри шарда, то стоит об этом подумать, хотя я бы предпочёл, чтобы база про это знала при планировании запросов. А подскажите какое-нибудь программное решение для linux'а?Botkin
16.02.2017 10:00Неужели SAN медленнее, чем просто диски в сервере? Там же FC, кеши, вот это всё… Или вопрос сугубо экономический?
По поводу программного тиринга на Linux говорят что-то про lvmts, но личного опыта не имею, поэтому советовать ничего не стану
mspain
16.02.2017 10:26-1«А подскажите какое-нибудь программное решение для linux'»
Удивительный вопрос от людей, которые «всё учли» и «10 человеколет переписывали скрипты». А Dm-cache ещё в 2013 в ванилле (3.9) появился.dev1ant
17.02.2017 03:31+3И снова я вам порекомендую внимательно почитать, в этот раз комментарий от Botkin. В нём есть ссылка, по которой можно увидеть, что нахваливаемый вами dm-cache не является решением для automated tiering.
Ещё раз повторю, что 10 человеко-лет мы потратили совсем не на "скрипты". И фраз "всё учли" я что-то тоже не припоминаю.
vlanko
14.02.2017 15:37+3Чтоб все ужаснулись, сколько стоит Оракл за 1 ядро, и сколько их было?
khanid
14.02.2017 17:41+2Уж не знаю, наколько цены одинаковы для всех, но в процессе общения на одном из форумов админской тематике всплыла цена что-то вроде $9100 за одно ядро. Всплыло это в контексте лицензирования (кажется, надо лицензировать все ядра на железе во всём кластере, даже если под БД отдано всего 4 ядра). В общем-то итоговая цена в скриншоте для сервера в кластере была в районе $19 000 000.
Опять же. Говорю только на основе скриншота и слов того форумного собеседника.Triffids
14.02.2017 20:55-2звучит бредово.
если речь о EE редакции то там ценник $25 000 за ядро ($50 000 за «ядро» * 0.5 коефициент x86) + каждая опция отдельно. типа партишенинг + $25к*0.5 + дата гвард +…
если речь о SE то там $6k на сокет. не ядро, сокет.
т.е. о чем бы речь не шла, все мимо.


Sleuthhound
14.02.2017 15:52-2Все конечно классно в Yandex.Почта, но вот с почтой в Yandex.PDD… не очень, она на неделе порой по 2 раза рушится, то не работает отправка писем, то прием идет с задержкой в десятки минут… тех.поддержка говорит что проблемы… устраняем, а тем временем пользователи толпами ходят возле меня и жалуются.
Скоро я чувствую придется съезжать с Yandex.PDD обратно на свой почтовый сервер, пусть нас зальет спам, но это лучше, чем не получать или не отправлять вовремя почту клиентам.
До Gmail Yandex.Почте как до китая пешком.
helgisbox
14.02.2017 17:16-5Непонятно отношение к коллегам: «Уже почти год прошел, как мы их просим запилить эту киллер-фичу, а они просят с нас денег, чтобы замержить её. Очень наглые ребята.» А сам Вова и его команда бесплатно все вот это реализовывали?
PostGreSQL хорош своими коммьюнити, но это будет не всегда. Чем больше будет серьезных проектов, где «большие деньги»крутятся и отвественность большая, все захотят, что бы советчики «отвечали» за свои советы. И все разом махнет из открытой коммьюнити на какой-нибудь платный сервис. Хотя не спорю — у Оракл поддержка — это нечто запредельное. И тогда вот станет не понятно, стоило ла овчинка выделки, тем более, что железа уже сейчас стала в 3 раза больше: «Без ложек дёгтя не бывает. У нас сейчас в 3 раза больше железа под PostgreSQL, но это ничто по сравнению со стоимостью Oracle.»dev1ant
15.02.2017 15:24+4Начнём с того, что речь не про сообщество PostgreSQL, а про mainteiner'ов одного околопостгрешного проекта (barman). И все эти ребята работают строго в одной компании (2ndQuadrant-it).
И мы (люди снаружи) прислали им патч с реализацией крутой фичи, в лучших традициях open source разработки. А они не удосужились за год на него посмотреть. Имеют право, конечно, но IMHO как-то некрасиво.
Все последующие ваши рассуждения мне не очень понятны.

popov654
14.02.2017 18:39В PostgreSQL мы используем barman, и в нём под бэкапы нужно места минимум в 5 раз больше, чем размер базы
Интересно, а нельзя логировать именно запросы к БД в виде журнала? Такое должно хорошо сжиматься. То есть создать один неикрементный бэкап, а потом накапливать историю изменений. Можно какой-то велосипед было соорудить, который бы такое делал, или неэффективно?dev1ant
15.02.2017 14:47+1Нет, нельзя, это сломает point in time recovery. Кроме того, уже есть WAL (в postgres'е бинарный), который мы храним.
helgisbox
15.02.2017 18:06+1К своей софтине всегда делаю логгирование SQL запросов со штампом времени. Нет никакой проблемы повторить все DML-ки с определенного момента времени. Или я чего-то недопонимаю? Отдельно можно создать не просто бэкапы, а полные копии-хранилища данных и накатывать на них эти самые запросы. Будет соотношение бэкап-исходные данные в соотношении 1:1, при этом из бэкапа восстановиться можно будет без долгого копирования всех терабайтов самой БД. Накатывать с отставанием в те же самые 7 дней.
dev1ant
16.02.2017 07:00+1На самом деле всё не так просто, как вы пишите.
1. Бэкендов, которые что-то модифицируют в базе, много. Время на них, конечно, синхронизируется, но NTP не даёт нужной точности.
2. Даже если предположить, что время идеально синхронизировано, в READ COMMITTED (уровень изоляции по-умолчанию и мы используем его) видны изменения уже закомиченных конкурентных транзакций. Транзакция А могла прочитать что-то, что было закомичено в транзакции B, но завершиться после транзакции C, которая изменений в B не видела в момент чтения. Потому 100% консистентности достичь будет сложно.
3. Накатывать такой логический лог запросов с параллелизмом сложно, а в один поток оно упрётся в одно ядро при хоть какой-то нагрузке. Именно потому в postgres'е WAL бинарный и накат на репликах легко справляется одним ядром, не отставая, упираясь в ядро.popov654
17.02.2017 04:47+1Транзакция А могла прочитать что-то, что было закомичено в транзакции B, но завершиться после транзакции C, которая изменений в B не видела в момент чтения
И в чём суть конфликта? Не очень понял пример. Вы наверное имелди в виду наоборот, что C со своими устаревшими данными завершится после A?dev1ant
18.02.2017 14:20+1Суть конфликта в том, что в результате наката statement'ов этих транзакций, упорядоченных по времени коммита, на реплике получится другой результат.
Например, в транзакции B в табличке foo заменили какое-то поле с 1 на 2 во всех строчках. Транзакция C читает чиселку из foo и получает 1, потому что B ещё не закоммитилась. Транзакция C записывает вычитанную чиселку в табличку bar и делает что-то ещё, повисая на блокировке. Транзакция B коммитится, транзакция А читает чиселку из foo (получает уже 2), пишет её в табличку baz и коммитится. Транзакция C успешно коммитится. Итого на мастере получается следующая картина маслом:
foo: 2,
bar: 1,
baz: 2.
Если же теперь повторить транзакции на реплике по времени коммита, то получится вот так:
foo: 2,
bar: 2,
baz: 2.
Отсюда вывод, что применять такой лог запросов по timestamp'у коммита нельзя, а другого timestamp'а у вас как бы и нет. Можно было бы писать timestamp каждого statement'а (вернее, когда БД вернула ответ на него), но во-первых, это уже включает в себя передачу по сети, которая может вносить произвольный лаг, а во-вторых, это не покрывает работы триггеров или хранимую логику.
Короче, реализовать свою логическую репликацию сильно сложнее, чем кажется. Не стоит так делать.
popov654
17.02.2017 04:46К стыду своему не знал, что такое WAL. Почитал, разобрался. А зачем тогда вам barman? И сколько эти двоичные журналы весят? Достаточно ли их, чтобы обеспечить откат на любой произвольный момент во времени?

Uzix
15.02.2017 18:08Собственно, в этом и есть суть WAL, который, как и отмечено в статье, отлично сжимается. Проблема, насколько я понял, в хранении именно неинкрементальной версии (версий), на которую уже накатываются WAL.

robert_ayrapetyan
14.02.2017 19:56Рассматривали ли вариант использования готовых решений для шардинга (CitusDB, Postgres-XL)?
dev1ant
15.02.2017 14:49+1Рассматривали, хотя в то время были только XC и XL на базе 9.2. Но даже текущие решения не выглядят довольно стабильными для OLTP.
Triffids
14.02.2017 21:11-3а зачем с такой архитектурой понадобился enterprise edition? все что нужно, начиная с standby (тот который SE standby на скриптах), заканчивая partitioned view с его partition elimination есть в SE edition, которое стоило уже в те времена лишь $6k на сокет?
partitioned view + partition elimination замечательно бы развели бы старые майлы на HDD, свежие на SSD. выглят что в яндексе просто не было хардкорного ораклойда.helgisbox
15.02.2017 07:32Да и на стандарте много раз, на внедрениях, где руководство зажимало деньги, реализовывал скриптовый стендбай со своим мониторингом. Работало годами и переключалось нормально.
dev1ant
15.02.2017 14:58+4Вы правда считаете, что Яндекс много лет жил почтой на оракле и до сих пор живёт другими сервисами без хорошей экспертизы в оракле!? Если да, то я вас разочарую, вы ошибаетесь.
Что касается архитектуры, то не всё мы рассказывали/рассказываем. И потому это всё было в формате доклада на конференциях, а не статьи на Хабре, чтобы на какие-то вопросы можно было ответить в кулуарах, а не публично.
Triffids
15.02.2017 15:32-3вы почту держали на оракле EE и толком не пользовали его возможности. вы платили сумасшедшие деньги за EE standby, а он стоял без дела. ну согласитесь есть повод подозревать, что вы не совсем понимали сколько стоит EE и где преимущества оракла с его UNDO, блокировками в блоке данных, мегаоптимизатоаре и прочим не нужным почте грузом. все ваши конкуренты за долго до 2012 в hadoop облаках и с noSql.
опять же по своему опыту, если бы у вас были бы хардкорный ораклойды, они бы бились за оракл до последнего (как я) и вариант с SE1 edtion + partitioned view как минимум серьезно бы продемонстрировали бы.
helgisbox
15.02.2017 18:08Мы потому и спрашиваем. Всплыло в этом докладе то, что мягко говоря не ожидаешь от такого уровня как яндекс, которым практически вся страна пользуется. Вот и хотелось бы узнать про реализацию, хотя бы примерную, других сервисов.

worldmind
14.02.2017 21:34+2> У нас сейчас в 3 раза больше железа под PostgreSQL,
наверно стоит оговориться что это не потому что постгрес тормозной, а потому что стали горизонтально масштабироватьсяAkirus98
15.02.2017 00:44Думаю что оракл дорогой не для Яндекс а для Яндекс почты, т.к. это далеко не единственный сервис, и вполне возможно для бюджета почты это менее позволительно чем какому-нибудь другому сервису.

QtRoS
14.02.2017 22:44+3Оракл слишком дорогой даже для Яндекс? Для кого тогда нет?

bezumkin
16.02.2017 13:11Для бесплатной Яндекс.Почты, у которой еще и бесплатная почта для доменов.
Мне уже давно интересно, как настолько отличный сервис могут отдавать просто так.QtRoS
17.02.2017 20:11Товарищ, но Yandex Поиск, Переводчик, <продукт X> и даже Диск тоже бесплатный. Не аргумент.
helgisbox
15.02.2017 07:34А яндекс.деньги на какой реализации у них живут?! Как раз ведь и народ.ру был выкинут яндексом то же в то же время. Видать реально разрослись. Народ.ру жалко конечно.
bRUtality
15.02.2017 13:41ТС, что это за проблема с секционированием, о которой вы упомянули?
У Постгресса партиции настраиваются вручную и им можно указать tablespace, который физически м.б. размещен хоть на харде, хоть на ssd, хоть в ОП. Я так и делаю, вынося горячие данные в оперативку.
Или вы что-то другое имеете ввиду?dev1ant
15.02.2017 15:07+1Во-первых, партиций много не создашь, время планирования сильно деградирует. Во-вторых, нужен триггер на insert.
Эти проблемы решает pg_pathman, который мы используем в одном проекте (на наш взгляд он пока сыроват, но ребята оперативно его штопают), и нормальный partitioning, который закоммитили в 10-ую версию.
В-третьих, теряется ссылочная целостность на секционируемые таблицы, что не есть хорошо.
В-четвёртых, далеко не все запросы в таблички с письмами делаются с фильтром по полю, по которому производится секционирование. И эту проблему без изменения логики приложения не победить.
bRUtality
15.02.2017 15:22Понял вас.
Но что для вас «нормальный partitioning»?dev1ant
15.02.2017 15:25+1Решение проблем 1-3 из моего предыдущего комментария.
bRUtality
15.02.2017 15:33Вы ожидаете, что проблему 1 решат на уровне движка?
dev1ant
15.02.2017 17:01+1Declarative partitioning — https://www.depesz.com/2017/02/06/waiting-for-postgresql-10-implement-table-partitioning/ — в 10-й версии должен решать первые две проблемы.
bRUtality
15.02.2017 17:10Тогда ждем от вас продолжения статьи — как решились проблемы после перехода на 10-ку. У себя, к счастью, проверить не могу — мне повезло, что удалось нарезать партиции по условиям из поиска, при этом кол-во партиций или их размер не стремятся в бесконечность.
dev1ant
15.02.2017 15:48+1Для тех, кто впервые увидел этот материал, очень рекомендую посмотреть слайды — https://simply.name/ru/slides-pgday2016.html — или лучше видео (только на английском) — https://simply.name/video-pgcon2016.html.
А то редакторы и копирайтеры местами поломали смысл. Ну и откровенные ошибки есть. Например, trench вместо range или web-интерфейс вместо wait-интерфейса.
Triffids
16.02.2017 20:09-3какой ужас. 300 тб данных, по 10 тб на сервере. т.е. 30, явно не односокетных серверов + 30 стенбаев, т.е. это лицензировать минимум 200+ ЕЕ ядер + standby option. это же многие сотни тысяч только за супорт в год.
яндекс реально не осознавал куда идет, запуская бесплатную почту на оракле?

dctabuyz
21.02.2017 18:11как пользователь, скажу что работа стала менее комфортной, быстродействие заметно снизилось, часть функционала начала работать некорректно (например сортировка при группировке писем, обновление счётчиков), часть была урезана (например отсутствие сортировок писем и пагинации в поиске)

VMichael
21.02.2017 19:25Не по теме, но добавлю — яндекс.почта для андроида превратилась в какой то кошмар. И уже несколько месяцев. Причем сторонние приложения работают нормально.
Nizametdinov
Свитер просто класс!!! Наконец то true админ с докладом, а не хз кто, со следами смузи на бороде.
Shapelez
На свитере комета обходит по орбите звезду, направляясь дальше с лёгким смещением.