

Это завершение переводной статьи о разработке транзакционных приложений с использованием микросервисной архитектуры. Начало.
В первой части статьи мы говорили, что основным препятствием при использовании микросервисной архитектуры является то, что модели предметной области (domain model), транзакции и запросы удивительно устойчивы к разделению по функциональному признаку. Было показано, что решение заключается в реализации бизнес-логики каждого сервиса в виде набора DDD-агрегатов. Каждая транзакция обновляет или создает один единственный агрегат. События используются для поддержания целостности данных между агрегатами (и сервисами).
Во второй части статьи мы увидим, что ключевой задачей при использовании событий является атомарное изменение состояния агрегата и одновременная публикация события. Посмотрим, как решить эту проблему с помощью Event Sourcing — используя событийно-ориентированный подход к проектированию бизнес-логики и системы сохранения состояния. После этого опишем, как микросервисная архитектура затрудняет реализацию запросов к базе данных, и как подход, называемый Command Query Responsibility Segregation (CQRS), помогает реализовывать масштабируемые и производительные запросы.
Основные тезисы:
- Event Sourcing — это механизм надежного изменения состояния и публикации событий, позволяющий преодолеть ограничения других решений.
- Событийно-ориентированный подход, использующий Event Sourcing, хорошо согласуется с микросервисной архитектурой.
- Снапшоты могут повысить производительность запросов состояния агрегатов за счёт сочетания в себе всех событий, произошедших до определенного момента времени.
- Event sourcing может создавать проблемы для запросов, но они преодолеваются с помощью CQRS и материализованных представлений.
- Event sourcing и CQRS не требуют каких-либо специальных инструментов или программного обеспечения, многие существующие фреймворки могут взять на себя часть необходимой низкоуровневой функциональности.
Надежное обновление состояния и публикация событий
На первый взгляд, обеспечение согласованности между агрегатами с помощью событий кажется довольно простой задачей. Сервис, создавая или обновляя агрегат в базе данных, просто публикует событие. Но есть проблема: обновление базы данных и публикация события должны выполняться атомарно. Например, если что-то сломалось после обновления базы данных, но перед публикацией события, то система окажется в неустойчивом состоянии. Традиционным решением в данном случае являются распределенные транзакции с участием базы данных и брокера сообщений. Но, по причинам, описанным в первой части статьи, распределенные транзакции не являются жизнеспособным вариантом.
Есть несколько способов решения этой проблемы без использования распределенных транзакций. Например, можно использовать брокер сообщений (вроде Apache Kafka).
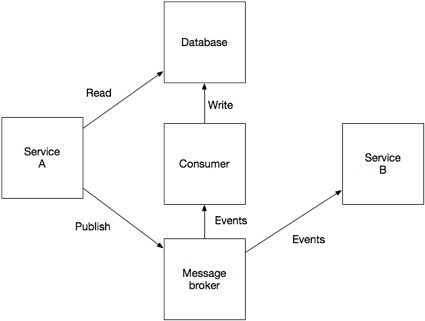
Отдельно выделенный получатель сообщений подписывается на сообщения брокера, и, получив их, обновляет базу данных. Такой подход гарантирует, что и база данных обновляется, и событие публикуется. Его недостаток заключается в том, что это гораздо более сложная модель согласованности, в которой приложение не может сразу же прочитать то, что оно само отправило для записи в базу данных.
Другим вариантом решения может быть паттерн Transaction log tailing: берутся записи из журнала транзакций, преобразуются в события и отправляются брокеру сообщений. Важным преимуществом этого подхода является то, что он не требует каких-либо изменений приложения. Недостаток, однако, заключается в том, что это может затруднить реверс-инжиниринг бизнес-событий высокого уровня — причина для обновления базы данных — от низкоуровневых изменений до строк в таблицах.

Третий вариант решения: использование таблицы базы данных в качестве временной очереди сообщений. Когда сервис обновляет агрегат, он внутри локальной транзакции добавляет событие в специальную таблицу базы данных EVENTS. Отдельный процесс периодически просматривает таблицу EVENTS и публикует события, отправляя их брокеру сообщений.
Приятной особенностью этого решения является то, что служба может публиковать бизнес-события высокого уровня. Недостаток: этот подход потенциально подвержен ошибкам, так как код публикации событий должен быть синхронизирован с бизнес-логикой.

Все три варианта имеют существенные недостатки. Публикация событий через брокер сообщений с отложенным обновлением базы данных не обеспечивает условия модели согласованности Read-your-writes. Публикация событий на основе журнала транзакций обеспечивает согласованность при чтении данных, но не всегда может публиковать бизнес-события высокого уровня. Использование таблицы базы данных в качестве очереди сообщений обеспечивает согласованность при чтении и публикацию бизнес-событий высокого уровня, но подразумевает, что разработчик должен не забыть опубликовать событие при изменении состояния.
К счастью, есть еще один вариант решения. Это событийно-ориентированный подход к сохранению состояния и бизнес-логике, известный как Event Sourcing.
Разработка микросервисов с помощью Event Sourcing
Event Sourcing представляет собой событийно-ориентированный подход к сохранению состояния. Это не новая идея. Впервые я узнал об Event Sourcing более пяти лет назад, но он оставался диковинкой, пока я не начал разрабатывать микросервисы. Event Sourcing оказался отличным способом реализации событийно-ориентированной микросервисной архитектуры.
Сервис, использующий Event Sourcing, хранит состояние агрегатов как последовательность событий. Когда создается или обновляется агрегат, сервис сохраняет одно или несколько событий в специальном хранилище событий в базе данных.
Чтобы получить текущее состояние агрегата, производится загрузка событий и их воспроизведение. В терминах функционального программирования, сервис реконструирует текущее состояние агрегата, выполняя функционал fold/reduce над событиями. Поскольку события теперь и есть состояние, мы больше не имеем проблем с атомарностью обновлений состояний и публикацией событий.
Рассмотрим, например, сервис Заказ. Вместо того, чтобы хранить каждый заказ как строки в таблице ORDERS, он хранит каждый агрегат Заказ в виде последовательности событий, таких как ЗаказСоздан, ЗаказОдобрен, ЗаказОтправлен и т.д. Вот как это могло бы быть сохранено в интернет-магазине на SQL базе данных.
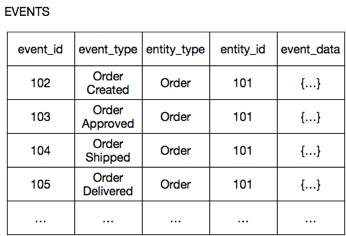
Колонки entity_type и entity_id columns — идентификаторы агрегата.
event_id — идентификатор события.
event_type — тип события.
event_data — сериализованные атрибуты события в формате JSON.
Некоторые события содержат много данных. Например, событие ЗаказСоздан содержит данные о составе заказа, платежную информацию и информацию о доставке. Событие ЗаказОтправлен содержит минимум информации и представляет собой просто переход между состояниями.
Event Sourcing и публикация событий
Строго говоря, Event Sourcing просто хранит состояние агрегатов как события. Его очень просто использовать в качестве надежного механизма публикации событий. Сохранение события по своей природе является атомарной операцией, что гарантирует, что хранилище событий будет предоставлять доступ к событиям всем заинтересованным сервисам. Например, если события сохраняются в таблице EVENTS, упомянутой выше, то подписчики могут просто периодически опрашивать таблицу для получения новых событий. Более сложные хранилища событий будут использовать другой подход, который даёт аналогичные гарантии, но является более производительным и масштабируемым. Например, Eventuate Local использует паттерн Transaction log tailing. Он читает события, вставленные в таблицу EVENTS из потока репликации MySQL, и публикует их с помощью Apache Kafka.
Использование снапшотов состояния для повышения производительности
Агрегат Заказ характеризуется относительно небольшим количеством переходов между состояниями, и поэтому он имеет лишь небольшое количество событий. В этом случае будут эффективными запрос из хранилища событий и реконструкция текущего состояния агрегата Заказ. Однако некоторые агрегаты имеют большое количество событий. Например, агрегат Клиент может потенциально иметь множество событий Credit Reserved. Со временем их загрузка и обработка стала бы неэффективной.
Общим решением проблемы является периодическое сохранение снапшота состояния агрегата. Приложение восстанавливает состояние агрегата путем загрузки последнего снапшота и только тех событий, которые произошли с момента его создания. В терминах функционального программирования, снимок представляет собой первоначальное значение для fold/reduce. Если агрегат имеет простую, легко сериализуемую структуру, то снимок может быть, например, в формате JSON. Снимки более сложных агрегатов могут быть сделаны с помощью паттерна Memento.
Например, агрегат Клиент в интернет-магазине имеет очень простую структуру: информация о клиенте, его кредитный лимит и данные о резервировании его кредитных средств. Снимок Клиента является просто набором данных о его состоянии в формате JSON. На рисунке показано, как воссоздать состояние Клиента из снимка, соответствующего состоянию Клиента на момент поступления события 103. Сервису клиентов нужно просто загрузить снимок и обработать события, произошедшие после 103-го.
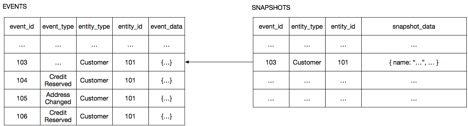
Сервис клиентов воссоздает состояние клиента, десериализуя JSON моментального снимка, а затем загружая и обрабатывая события со 104 по 106.
Реализация Event Sourcing
Хранилище событий представляет собой гибрид базы данных и брокера сообщений. Оно представляет собой базу данных, так как имеет API для вставки и извлечения событий агрегатов с помощью первичного ключа, но оно также и брокер сообщений, поскольку имеет API для подписки на события.
Есть несколько различных способов реализации хранилища событий. Одним из них является создание своего собственного event sourcing-фреймворка. Вы можете, например, сохранять события в РСУБД. Это простой, хотя и низко-производительный способ публикации событий. Подписчики просто периодически опрашивают таблицу EVENTS для получения новых событий.
Другой вариант: использовать специальное хранилище событий, которое, как правило, предоставляет богатый набор функций, более высокую производительность и масштабируемость. Грег Янг (Greg Young), пионер в event sourcing, создал на основе .NET хранилище событий с открытым исходным кодом под названием Event Store (https://geteventstore.com). Компания Lightbend, ранее известная как Typesafe, разработала микросервисный фреймворк Lagom, основанный на event sourcing. Можно отметить и стартап Eventuate, имеющий event sourcing-фреймворк, который доступен в качестве облачного сервиса, является проектом с открытым исходным кодом и использует Kafka и РСУБД.
Преимущества и недостатки Event Sourcing
Event sourcing имеет как преимущества, так и недостатки. Основным преимуществом подхода является то, что события гарантированно публикуются всякий раз, когда изменяется состояние агрегата. Это хорошая основа для управляемой событиями микросервисной архитектуры. Кроме того, поскольку каждое событие может записать идентификатор пользователя, который внес изменения, event sourcing предоставляет журнал аудита, который является гарантированно точным. Поток событий может быть использован и для других целей, в том числе для отправки уведомлений пользователям.
Еще одно преимущество event sourcing — хранение всей истории каждого агрегата. Вы можете легко реализовать временные запросы, которые возвращают состояние агрегата в прошлое. Для того, чтобы определить состояние агрегата в конкретный момент времени, нужно просто обработать события, которые произошли до этого момента. Например, можно легко рассчитать доступный кредит клиента на какой-то момент в прошлом.
Благодаря сохранению события, а не самого агрегата, Event sourcing обычно позволяет избегать проблемы «потери соответствия» (impedance mismatch). События, как правило, имеют простую, легко-сериализуемую структуру. Посредством сериализации сервис может сделать снимок состояния сложного агрегата. Паттерн Memento добавляет уровень косвенности между агрегатом и его сериализованным представлением.
Однако в технологии event sourcing не всё так гладко, и она имеет некоторые недостатки. Это другая, непривычная модель программирования, которую нужно изучить. Для того, чтобы существующее приложение начало использовать event sourcing, необходимо переписать его бизнес-логику. К счастью, это довольно механическое преобразование, которое можно сделать при переносе приложения на микросервисную структуру.
Еще один недостаток event sourcing заключается в том, что брокер сообщений обычно гарантирует хотя бы одну доставку. Обработчики событий, которые не являются идемпотентными, должны самостоятельно обнаружить и отвергнуть повторяющиеся события. В этом случае event sourcing-фреймворк может помочь путем присвоения каждому событию автоинкрементного идентификатора. Обработчик событий затем может обнаружить дубликаты, отслеживая максимальный идентификатор событий, которые он уже обработал.
Еще одной проблемой event sourcing является то, что схема событий (и снапшотов!) будет развиваться с течением времени. Поскольку события сохраняются навсегда, то для реконструкции состояния агрегата сервису может понадобиться обработать события, соответствующие нескольким различным версиям схемы. Один из способов упростить сервис — заставить event sourcing-фреймворк приводить все события к последней версии схемы, когда он загружает их из хранилища событий. В результате сервису нужно будет только обработать только последнюю версию событий.
Другим недостатком event sourcing является то, что запрос в хранилище событий может быть сам по себе сложной задачей. Представим, что вам нужно найти клиентов, достойных выдачи кредита, имеющих низкий кредитный лимит. Вы не можете просто написать SELECT * FROM CUSTOMER WHERE CREDIT_LIMIT <? AND CREATION_DATE >?.. Столбца, содержащего кредитный лимит, не существует. Вместо этого вы должны использовать более сложный и потенциально неэффективный запрос, содержащий вложенные SELECT для вычисления кредитного лимита путем обработки события, устанавливающие начальный кредитный лимит и затем меняющие его. Что еще хуже, NoSQL-хранилища событий, как правило, поддерживают поиск только по первичному ключу. Поэтому вы должны реализовывать запросы с помощью подхода Command Query Responsibility Segregation (CQRS).
Реализация запросов с помощью CQRS
Event sourcing является одним из основных препятствий для реализации эффективных запросов в микросервисной архитектуре. Однако это не единственная проблема. Рассмотрим, например, SQL-запрос, который находит новых клиентов, сделавших дорогие заказы.
SELECT *
FROM CUSTOMER c, ORDER o
WHERE
c.id = o.ID
AND o.ORDER_TOTAL > 100000
AND o.STATE = 'SHIPPED'
AND c.CREATION_DATE > ?В микросервисной архитектуре вы не можете соединить в одном запросе таблицы CUSTOMER и ORDER. Каждая таблица принадлежит своему сервису и доступна только через API этого сервиса. Вы не можете писать традиционные запросы, которые соединяют (join) таблицы, принадлежащие различным сервисам. Event sourcing усугубляет ситуацию, мешая писать простые прямые запросы. Давайте посмотрим на способ реализации запросов в микросервисной архитектуре.
Использование CQRS
Хорошим способом реализации запросов является использование архитектурного паттерна, известного как Command Query Responsibility Segregation (CQRS). Приложение разбивается на две части:
- командная часть обрабатывает команды (например, HTTP POST, PUT, DELETE) для создания, обновления и удаления агрегатов. Эти агрегаты, конечно же, реализованы с использованием Event sourcing.
- запросная часть приложения обрабатывает запросы (например, HTTP GET), запрашивая один или несколько материализованных представлений (materialized views) агрегатов. Запросная часть поддерживает представления синхронизированными с агрегатами, подписавшись на события, публикуемые командной частью.
В зависимости от требований, запросная часть приложения может использовать одну или несколько следующих баз данных:
| Если вам нужно | Тогда используйте | Например |
|---|---|---|
| Поиск JSON-объектов по первичному ключу | Документоориентированную базу данных, например, MongoGB, или хранилище данных типа «ключ — значение», например, Redis. | Реализация истории заказов с помощью MongoDB документа клиента, содержащего все его заказы. |
| Обычный поиск JSON-объектов | Документоориентированную базу данных, например, MongoGB. | Реализация представления для клиентов с помощью MongoDB. |
| Полнотекстовый поиск | Движок для полнотекстового поиска, например, Elasticsearch. | Реализация полнотекстового поиска в заказах с помощью Elasticsearch документов для каждого заказа. |
| Графовый запрос | Графовая система управления базами данных, например, Neo4j. | Реализация системы обнаружения мошенничества с помощью графа клиентов, заказов и других данных. |
| Традиционные SQL-запросы | РСУБД | Стандартные бизнес-отчеты и аналитика. |
Во многих отношениях, CQRS — это более общий событийно-ориентированный вариант широко применяемого подхода использования РСУБД в качестве хранилища данных и поискового движка для полнотекстового поиска (вроде Elasticsearch). CQRS использует более широкий диапазон типов баз данных, а не полнотекстовые поисковые движки. Кроме того, за счет подписки на события он обновляет представления запросной части приложения почти в реальном времени.
На следующей иллюстрации показана схема CQRS применительно к интернет-магазину.
Сервисы Customer Service и Order Service входят в командную часть приложения. Они предоставляют API-интерфейсы для создания и обновления клиентов и заказов. Сервис Customer View Service входит в запросную часть. Он предоставляет API для получения данных о клиентах с помощью запросов.

Customer View Service подписывается на события, публикуемые командной частью приложения, и обновляет хранилище представлений, реализованное на MongoDB. Коллекция MongoDB содержит документы, по одному на каждого клиента. У каждого документа есть атрибуты, описывающие конкретного клиента, а также атрибут с последними заказами клиента. Эта коллекция поддерживает разнообразные запросы, включая вышеописанные.
Преимущества и недостатки CQRS
Основное преимущество CQRS заключается в том, что благодаря ему появляется возможность реализовывать запросы в микросервисной архитектуре, особенно использующие event sourcing. Это позволяет приложению эффективно поддерживать разнообразный набор запросов. Другим преимуществом является то, что разделение ответственности зачастую упрощает командную и запросную части приложения.
Одним из недостатков является то, что CQRS требует дополнительных усилий по разработке и эксплуатации системы. Необходимо создать и развернуть сервис запросной части, который умеет обновлять представления и делать запросы к ним. Кроме того, необходимо развернуть хранилище представлений.
Другой недостаток CQRS связан с временным лагом между командами и запросами. Как и следовало ожидать, существует задержка между моментом, когда командная часть обновляет агрегат, и когда представления запросной части готовы отразить эти изменения. Клиентское приложение, которое обновляет агрегат, а затем сразу же делает запрос с использованием представлений, может увидеть предыдущую версию агрегата. Поэтому приложение должно быть написано таким образом, чтобы не допустить получения пользователем этого потенциального несоответствия.
Резюме
Одна из основных проблем при использовании событий для поддержания целостности данных между сервисами — это атомарное обновление базы данных и одновременная публикация событий. Традиционное решение заключается в использовании распределенных транзакций, с задействованием базы данных и брокера сообщений. Однако этот подход не является жизнеспособным для современных приложений. Лучшим решением является использование Event sourcing, событийно-ориентированного подхода к проектированию бизнес-логики и системы сохранения состояния.
Еще одной проблемой в микросервисной архитектуре представляют собой запросы. В них часто необходимо объединять данные, принадлежащие нескольким сервисам. Однако больше нельзя так просто использовать соединения (joins), так как данные являются приватными для каждого сервиса. Еvent sourcing еще более затрудняет эффективную реализацию запросов, так как текущее состояние не хранится само по себе. Решение заключается в использовании CQRS и поддержании в актуальном состоянии одного или более материализованного представления, к которому легко можно делать запросы.
Комментарии (24)
VolCh
22.02.2017 10:12Клиентское приложение, которое обновляет агрегат, а затем сразу же делает запрос с использованием представлений, может увидеть предыдущую версию агрегата. Поэтому приложение должно быть написано таким образом, чтобы не допустить получения пользователем этого потенциального несоответствия.
Хорошие результаты показывают:
- возвращение представление агрегата приложению в ответ на команду создания/обновления средствами сервиса агрегата
- агрегирование представлений разных агрегатов на стороне приложения
При таком подходе приложение гарантированно отдаёт пользователю агрегированное представление с учётом его действий.
Другой вариант:
- возвращать в ответ на команду монотонно возрастающий идентификатор последнего события (или его вообще приложение создаёт), учтенного при обработке команды, или версию агрегата, или ещё какой-то монотонно увеличивающийся признак типа таймстампа или количества событий
- сервис агрегированных представлений добавляет к агрегатам последний известный ему идентификатор событий агрегатов или версию
При таком подходе приложение отправляет команду, запоминает версию агрегата, если команда выполнилась, идёт за представлением нескольких агрегатов и проверяет версии тех, которые он изменял. Если версия меньше, то либо перечитывает, либо как-то сигнализирует пользователю, что данные устаревшие.

rezdm
22.02.2017 11:57Мы пытались прикрутить идею CQRS в нашем проекте. Задача стоит такая:
— «обслуживать» текущий процесс
— именть возможность поднять состояние системы в прошлом (то есть пользователь говорит: хочу увидеть состояние системы как 1 месяц, 3 дня, 4 часа и 5 минут назад).
Мысль была — не заипсывать сущности в рдбмс, а записывать собственно ивентами. Пришли к идее cqrs.
Но и обломались:
1. нет ничего хоть сколь-нибудь готового
2. для подъёма системы «месяц назад» надо, грубо говоря, проиграть «от начала времени» до «месяц назад» и воссоздать объекты — как/кто — неясно
3. изменение модели данных неясно, как обрабатывать, когда система уже в глубоко использованииVolCh
22.02.2017 12:07Сильно зависит от уже используемого стека и возможности его сменить.
Все сеттеры и иные мутаторы объекта преобразуются в добавление событий, все геттеры в проигрыватели с необязательным параметром типа таймстампа. Плохо только если у объекта были публичные свойства, с которыми работали все кому не лень, а стек (например PHP) не позволяет их малой кровью заменить на геттеры/сеттеры, тгда нужно городить фабрики с таймстампом и формировать объекты.
- Если всё получилось удачно инкапсулировать, то проблемы могут быть только с быстродействием, которые обходятся снэпшотами, и с потребляемой памятью.
rezdm
22.02.2017 12:22Для (2) не нашлось ничего готового (C# с пропертями, но некритично, можно и поменять на яву).
Но всё равно проблема остаётся с изменением модели данных. «Старые события» могут быть несовместимыми с обновлёной моделью данных. Необходимо обновлять «старые события», но, т.к. события не привязаны к данным (в «стиле» рдбмс — ключи, юникнесс, т.п.), то обновления могут привести к значительной порче данных.oxidmod
22.02.2017 13:41я вижу тут лишь одно решение.
Нужно при изменении в структуре моделей/событий не менять существующие обработчики. Нужна некая фабрика которая будет создавать старый/новый обработчик в зависимости от таймстампа события. Соотвественно и классы события тоже не модицицировать, а создавать новый класс. Возможно есть смысл привязатсья к некоторым версиям. Аналогично с моделью. Несколько версий и некий сервис, который из заполненой старой версии создает новую по тем же правилам, по которым вы меняли схему. История хранится в событиях, и должна храниться в коде, чтобы мы действительно могли вернуться в прошлое.
Зы. мы всегда можем поставить ограничить глубину возврата. И врем от времени подчищать старые события в хранилище и соотвествуюющие им классы в коде.
VolCh
22.02.2017 14:23Сделать какой-то абстрактный класс события с минимально необходимым набором полей типа идентификатор и таймстамп, а уж от него наследовать старые и новые события, храня их в базе в каком-то виде, используемом для хранения наследования. В "проигрывателе" же выбирать обработчик для конкретного класса.

YuryZakharov
22.02.2017 12:07Реализация истории заказов с помощью MongoDB документа клиента, содержащего все его заказы.
А разве история заказов не укладывается в реляционную модель?
И вообще вся структура Клиент-Заказ-Товар.
Зачем NoSql тут?
Какие дает преимущества?VolCh
22.02.2017 14:56На реляционную модель истории ложатся плохо. Реляционная модель подразумевает что в выборках используются актуальные значения записей, связанных первичными/внешними ключами. Клиент сменил фамилию, изменилась цена товара и в выборке по заказам в реляционной модели должны быть новые значения по ключам, что обычно сильно противоречит бизнес-логике, требующей фиксации данных на момент какого-то бизнес-события типа выставления счёта на оплату заказа.
Тут не столько у NoSql явные преимущества, сколько преимущества Sql практически не используются. То есть ситуация "можно без проблем использовать NoSql СУБД, если вам важны их общие преимущества типа гораздо большей легкости горизонтального масштабирования".
YuryZakharov
22.02.2017 17:40Как-то Вы странно представляете себе реляционную модель…
Если цена меняется во времени, об этом есть записи.
Клиент сменил фамилию, об этом тоже есть запись. В Вашей модели его история потеряется
И речь шла не о преимуществах SQL, а как раз о недостатках NoSQL для представления определенных структур данныхoxidmod
22.02.2017 17:58Он говорит о том, чтобы не держать в реляционной базе таблу ордеред продукт с записями которые дублируют состояния продукта на момент ордера. Не держать там и таблицу ордеров с инфой о имени и адресе доставки которые были использованы в заказе. Не джойнить все это добро при необходимости.
Он предлагает держать в монге документ заказ, создержащий в себе все эти данные в денормализированном виде. Это будет ровно один простой запрос чтобы получить историю ордеров клиентаYuryZakharov
22.02.2017 18:04Какие-то ненормализованные «таблы» получаются. В таком случае да, разницы нет, как хранить
все это добро
VolCh
22.02.2017 18:33Так в том-то и дело, что если нужно фиксировать фио клиента и цены на товары на момент создания заказа, то нам нужно либо дублировать данные в записях заказов, копируя их из основных таблиц на момент создания, либо вести лог изменений записей клиентов и товаров и при желании просмотреть заказ выбирать из этого лога все значения с тамйстмапом меньшим чем время создания заказа, либо хранить снэпшоты записей клиента и товаров и выбирать последний с меньшей датой. В общем или сплошная дупликация, либо какая-то вариация ивентсорсинга.
oxidmod
22.02.2017 19:03А что вы предлагаете? Требование ровно одно. Клиент запрашивает историю заказов или квитанцию в разные моменты времени и гарантировано всегда получает одинаковый результат.
YuryZakharov
22.02.2017 19:29Вы это серьезно?
На RDBMS это невозможно.oxidmod
22.02.2017 19:43Я имею ввиду, какую структуру бд вы предлагаете? Так чтобы без дублирования данных, нормализировано и без затыков с производительностью?
YuryZakharov
22.02.2017 20:22Вы троллите так?
create table [dbo].[order] ( [id] [int] primary key clustered, [customerId] [int] not null foreign key references [dbo].[customer]([id]), [deliveryAddressId] [int] not null foreign key references [dbo].[address]([id]), [date] [datetime] not null ); create table [dbo].[orderItem] ( [orderId] [int] not null foreign key references [dbo].[order]([id]), [itemId] [int] not null foreign key references [dbo].[goods]([id]), [price] [money] not null );
Обвязку из [customer], [address], [customerHistory] и прочего сами додумаете?
Адресов на клиента будет в среднем 1.01, имен — 1.0000000000001
Запрос тоже написать или основы поизучаете?
И да, если у Вас на таком join'е все заткнется, научите, как такого достичь?
VolCh
22.02.2017 20:30Про историю самое интересное. С запросом на обновление данных товара(включая название и категорию, а не только цену, а других данных в товаре и нет)/клиента(включая телефоны для связи, которые некоторые меняют чуть ли не раз в месяц) и запросом на выборку заказа с актуальными на date данными по клиенту и товарам.
VolCh
22.02.2017 20:21Оно возможно, но никаких особых преимуществ буква R не даёт. Записи заказа должны будут дублировать все значимые для них поля записей клиента и товаров, ссылаясь на них лишь для поддержания ссылочной целостности для каких-то аналитических задач типа подсчёта количества заказов у клиента. Либо должна в том или ином виде поддерживаться полная история история изменений записей клиентов и товаров, что опять же приводит к массовому дублированию данных при версионировании посредством снэпшотов, или сложным механизмам "наложения патчей"
YuryZakharov
23.02.2017 12:16Вы бы знали, сколько подобной каши я повидал…
Но дело Ваше. Чем больше пионэров, тем больше моя ценность, как специалиста.
/* Это сарказм и ирония, если что */
Hronom
Кто-то использовал RethinkDB в качестве Event Sourcing, как замена стека БД и брокер сообщений?