
Цель работы
- Парсим сайт, используя прокси-сервера.
- Сохраняем данные в формате CSV.
- Пишем поисковик по найденным данным.
- Строим интерфейс.
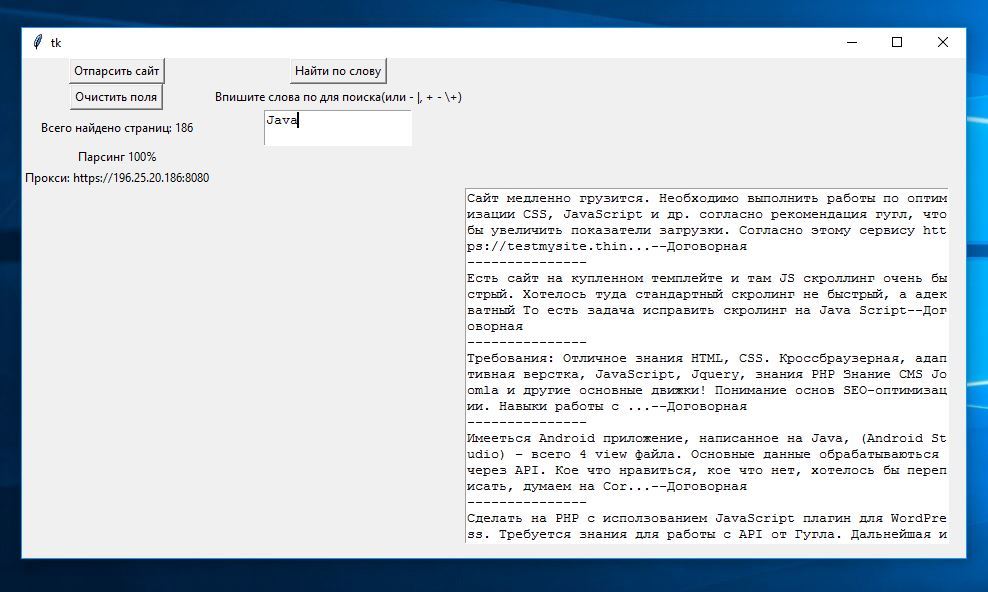
Использовать будем язык программирования Python. Сайт, с которого мы будем качать данные — www.weblancer.net (парсинг старой версии этого сайта был размещен здесь), в нем есть предложения работы по адресу www.weblancer.net/jobs. С него мы и будем получать данные — это название, цена, количество заявок, категория, краткое описание предлагаемой работы.
Вход с использованием прокси означает — вход на сайт под ненастоящим адресом. Пригодится для парсинга сайта с защитой бана по IP адресу (то есть, если вы слишком часто, за короткий отрезок времени, входите на сайт).
Импорт модулей
Модули для непосредственно парсинга: requests и BeautifulSoup, их нам будет достаточно. Сохранять данные в формате csv нам поможет модуль с аналогичным названием — csv. В работе с интерфейсом нам поможет, до боли простой, модуль tkinter (кто желает получить более качественный интерфейс, советую воспользоваться модулем pyQt5). Работу по поиску и замене данных осуществит модуль re.
import requests #осуществляет работу с HTTP-запросами
import urllib.request #библиотека HTTP
from lxml import html #библиотека для обработки разметки xml и html, импортируем только для работы с html
import re #осуществляет работу с регулярными выражениями
from bs4 import BeautifulSoup #осуществляет синтаксический разбор документов HTML
import csv #осуществляет запись файла в формате CSV
import tkinter #создание интерфейса
from tkinter.filedialog import * #диалоговые окна
Переменные
Создаем массив, где будем хранить уже использованные ранее прокси, и две текстовые переменные, к первой приравниваем адрес сайта, а вторую объявляем глобальной (есть варианты, когда использование глобальных переменных может негативно отразиться на работоспособности программы, подробнее о ее использовании — здесь), для получения ее данных в функциях.
global proxy1 #объвляем глобальную переменную для запоминания прокси на следующий проход цикла
proxy1 = '' #и приравниваем к пустому тексту
BASE_URL = 'https://www.weblancer.net/jobs/' #адрес сайта для парсинга
massiv = [] #массив для хранения прокси
Переменные для tkinter:
root = Tk() #главное окно
root.geometry('850x500') #ширина и высота главного окна в пикселях
txt1 = Text(root, width = 18, heigh = 2) #текстовое поле для ввода поисковых слов
txt2 = Text(root, width = 60, heigh = 22) #текстовое поле для вывода данных
lbl4 = Label(root, text = '') #надпись для вывода прокси
btn1 = Button(root, text = 'Отпарсить сайт') #кнопка для парсинга
btn2 = Button(root, text = 'Найти по слову') #кнопка для поиска
btn3 = Button(root, text = 'Очистить поля') #кнопка для очистки полей
lbl1 = Label(root, text = 'Впишите ключевые слова для поиска') #надпись для поиска
lbl2 = Label(root, text = '') #надпись для вывода процента парсинга
lbl3 = Label(root, text = '') #надпись для вывода количества страниц
Переменная.grid(строка, колонка) — определяем местоположение элемента в окне отображения. Bind — нажатие клавиши. Следующий код помещаем в самый конец программы:
btn1.bind('<Button-1>', main) #при нажатии клавиши вызывает основную функцию
btn2.bind('<Button-1>', poisk) #вызывает функцию поиска нужных заказов
btn3.bind('<Button-1>', delete) #вызывает функцию очистки полей
lbl2.grid(row = 4, column = 1)
lbl4.grid(row = 5, column = 1)
lbl3.grid(row = 3, column = 1)
btn1.grid(row = 1, column = 1)
btn3.grid(row = 2, column = 1)
btn2.grid(row = 1, column = 2)
lbl1.grid(row = 2, column = 2)
txt1.grid(row = 3, column = 2)
txt2.grid(row = 6, column = 3)
root.mainloop() #запуск приложения
Основная функция
Первым делом, напишем главную функцию (почему функция, а не процедура? В будущем нам будет необходимо запускать ее с помощью bind (нажатие клавиши), это легче сделать именно с функцией), а позже будем добавлять прочие функции. Процедуры, которые нам пригодятся:
- config — вносит изменения в элементы виджетов. К примеру, мы будем заменять текст в виджетах Label.
- update — используется для обновления виджета. Столкнемся с проблемой — виджет будет изменен только после завершения цикла, update позволяет обновлять содержимое виджета каждый проход цикла.
- re.sub(шаблон, изменяемая строка, строка) — находит шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
- get — осуществляет http-запрос, если он равен «200» — вход на сайт был удачен.
- content — позволяет получить html-код.
- L.extend(K) — расширяет список L, добавляя в конец все элементы списка K
def main(event):
#запуск функции с передачей переменной event (для работы виджетов)
page_count = get_page_count(get_html(BASE_URL))
#переменную присваиваем функции пересчета страниц, где сначала выполняется другая функция, получающая http-адрес от переменной BASE_URL
lbl3.config(text='Всего найдено страниц: '+str(page_count))
#меняем текстовую часть переменной lbl3 на количество найденных страниц
page = 1
#переменная для счетчика
projects = []
#массив для хранения всей искомой информации
while page_count != page:
#цикл выполняется, пока переменная page не равна количеству найденных страниц
proxy = Proxy()
#присваиваем классу, где зададим нужные параметры
proxy = proxy.get_proxy()
#получать proxy-адрес
lbl4.update()
#обновляем виджет
lbl4.config(text='Прокси: '+proxy)
#и приравниваем к полученному прокси
global proxy1
#глобальная переменная
proxy1 = proxy
#приравниваем переменные для дальнейшей проверки их совпадения
try: #обработчик исключительных ситуаций
for i in range(1,10):
#этот цикл будет прогонять полученный прокси определенное количество раз (range - определяет, сколько раз будем его использовать для входа на сайт). Можно и каждый раз брать новый прокси, но это существенно замедлит скорость работы программы
page += 1
#счетчик необходим для подсчета выполненной работы
lbl2.update()
#обновляем виджет
lbl2.config(text='Парсинг %d%%'%(page / page_count * 100))
#меняет процент сделанной работы от 100%
r = requests.get(BASE_URL + '?page=%d' % page, proxies={'https': proxy})
#получаем данные со страницы сайта
parsing = BeautifulSoup(r.content, "lxml")
#получаем html-код по средству BeautifulSoup (чтобы позже использовать поисковые возможности этого модуля) для дальнейшей передачи переменной в функцию
projects.extend(parse(BASE_URL + '?page=%d' % page, parsing))
#получаем данные из функции parse (передавая адрес страницы и html-код) и добавляем их в массив
save(projects, 'proj.csv')
#вызываем функцию сохранения данных в csv, передаем туда массив projects
except requests.exceptions.ProxyError:
#неудача при подключеннии с прокси
continue #продолжаем цикл while
except requests.exceptions.ConnectionError:
#не удалось сформировать запрос
continue #продолжаем цикл while
except requests.exceptions.ChunkedEncodingError:
#сделана попытка доступа к сокету методом, запрещенным правами доступа
continue #продолжаем цикл while
Подсчет страниц сайта
Пишем функцию для получения url:
def get_html(url):
#объявление функции и передача в нее переменной url, которая является page_count[count]
response = urllib.request.urlopen(url)
#это надстройка над «низкоуровневой» библиотекой httplib, то есть, функция обрабатывает переменную для дальнейшего взаимодействия с самим железом
return response.read()
#возвращаем полученную переменную с заданным параметром read для корректного отображения
Теперь с url ищем все страницы:
def get_page_count(html):
#функция с переданной переменной html
soup = BeautifulSoup(html, 'html.parser')
#получаем html-код от url сайта, который парсим
paggination = soup('ul')[3:4]
#берем только данные, связанные с количеством страниц
lis = [li for ul in paggination for li in ul.findAll('li')][-1]
#перебираем все страницы и заносим в массив lis, писать так циклы куда лучше для работоспособности программы
for link in lis.find_all('a'):
#циклом ищем все данные связанные с порядковым номером страницы
var1 = (link.get('href'))
#и присваиваем переменной
var2 = var1[-3:]
#создаем срез, чтобы получить лишь число
return int(var2)
#возвращаем переменную как числовой тип данных
Получение прокси
Код частично был взят у Игоря Данилова. Будем использовать __init__(self) — конструктор класса, где self — элемент, на место которого подставляется объект в момент его создания. Важно! __init__ по два подчеркивания с каждой стороны.
class Proxy:
#создаем класс
proxy_url = 'http://www.ip-adress.com/proxy_list/'
#переменной присваиваем ссылку сайта, выставляющего прокси-сервера
proxy_list = []
#пустой массив для заполнения
def __init__(self):
#функция конструктора класса с передачей параметра self
r = requests.get(self.proxy_url)
#http-запрос методом get, запрос нужно осуществлять только с полным url
str = html.fromstring(r.content)
#преобразование документа к типу lxml.html.HtmlElement
result = str.xpath("//tr[@class='odd']/td[1]/text()")
#берем содержимое тега вместе с внутренними тегами для получение списка прокси
for i in result:
#перебираем все найденные прокси
if i in massiv:
#если есть совпадение с прокси уже использованными
yy = result.index(i)
#переменная равна индексу от совпавшего прокси в result
del result[yy]
#удаляем в result этот прокси
self.list = result
#конструктору класса приравниваем прокси
def get_proxy(self):
#функция с передачей параметра self
for proxy in self.list:
#в цикле перебираем все найденные прокси
if 'https://'+proxy == proxy1:
#проверяем, совпдает ли до этого взятый прокси с новым, если да:
global massiv
#massiv объявляем глобальным
massiv = massiv + [proxy]
#добавляем прокси к массиву
url = 'https://'+proxy
#прибавляем протокол к прокси
return url
#возвращаем данные
Парсинг страниц
Теперь находим на каждой странице сайта нужные нам данные. Новые процедуры:
- find_all — в html-коде страницы ищет блоки и элементы, в нем находящиеся.
- text — получение из html-кода только текст отображенный на сайте.
- L.append(K) — добавляет элемент K в конец списка L.
def parse(html,parsing):
#запуск функции с получением переменных html и parsing
projects = []
#создаем пустой массив, где будем хранить все полученные данные
table = parsing.find('div' , {'class' : 'container-fluid cols_table show_visited'})
#находим часть html-кода, хранящую название, категорию, цену, количество заявок, краткое описание
for row in table.find_all('div' , {'class' : 'row'}):
#отбираем каждую запись
cols = row.find_all('div')
#получаем название записи
price = row.find_all('div' , {'class' : 'col-sm-1 amount title'})
#получаем цену записи
cols1 = row.find_all('div' , {'class' : 'col-xs-12' , 'style' : 'margin-top: -10px; margin-bottom: -10px'})
#получаем краткое описание записи
if cols1==[]:
#если массив остался пуст,
application_text = ''
#то присваиваем пустую строку
else: #если не пуст
application_text = cols1[0].text
#приравниваем к тексту из html-кода
cols2 = [category.text for category in row.find_all('a' , {'class' : 'text-muted'})]
#с помощью цикла получаем категорию и заявку записи
projects.append({'title': cols[0].a.text, 'category' : cols2[0], 'applications' : cols[2].text.strip(), 'price' : price[0].text.strip() , 'description' : application_text})
#в массив projects помещаем поочередно все найденные данные
return projects
#возвращаем проект для сохранения
Функция очистки
Единственная, нам необходимая процедура delete — удаляет объект по указанному идентификатору или тегу.
def delete(event): #запуск функции
txt1.delete(1.0, END) #удаляет текст с вводимыми данными
txt2.delete(1.0, END) #удаляет текст с выведенными данными
Поиск данных
Функция будет осуществлять поиск предложений, в описании которых упоминаются необходимые нам слова. Запись в поле придется осуществлять с учетом знаний регулярных выражений (к примеру, python|Python, С\+\+).
- csv.DictReader — конструктор возвращает объекты-итераторы для чтения
данных из файла. - split — разбивает строку на части, используя разделитель, и возвращает эти части списком.
- join — преобразовывает список в строку, рассматривая каждый элемент как строку.
- insert — добавление элементы в список по индексу.
def poisk(event):
#запуск функции с передачей переменной event для работоспособности интерфейса
file = open("proj.csv", "r")
#открытие файла, где мы сохранили все данные
rdr = csv.DictReader(file, fieldnames = ['name', 'categori', 'zajavki', 'case', 'opisanie'])
#читаем данные из файла по столбцам
poisk = txt1.get(1.0, END)
#получаем данные из поля для поиска соответствий
poisk = poisk[0:len(r)-1]
#конкотенация необходима для отбрасывания последнего символа, который программа добавляет самостоятельно ('\n')
for rec in rdr:
#запуск цикла, проход по каждой строке csv-файла
data = rec['opisanie'].split(';')
#к переменной приравниваем данные по описанию задания
data1 = rec['case'].split(';')
#к переменной приравниваем данные по цене задания
data = ('').join(data)
#преобразовываем в строку
data1 = ('').join(data1)
#преобразовываем в строку
w = re.findall(poisk, data)
#ищем в описании совпадение с поисковыми словами
if w != []:
#условие, если переменная w не равна пустому массиву, то продолжать
if data1 == '':
#условие проверяющее, если цена не была получена, то продолжать
data1 = 'Договорная' #заменяем пустое значение на текст
txt2.insert(END, data+'--'+data1+'\n'+'---------------'+'\n')
#соединяем краткое описание заказа, его цену, переход на новую строку, символы, разделяющие заказы и снова переход на новую строку
Сохранение данных
Как уже говорил: данные будем сохранять в формате csv. При желании можно переписать функцию под любой другой формат.
def save(projects, path):
#функция с переданной переменной и названием файла как переменная path
with open(path, 'w') as csvfile:
#открываем файл как path и w (Открывает файл только для записи. Указатель стоит в начале файла. Создает файл с именем имя_файла, если такового не существует)
writer = csv.writer(csvfile)
#writer - осуществляет запись файла, csv - определяет формат файла
writer.writerow(('Проект', 'Категории', 'Заявки' , 'Цена' , 'Описание'))
#writerow - создает заглавия каждого заполняемого столбца
for project in projects:
#перебираем элементы в массиве
try:
#обработчик исключительных ситуаций
writer.writerow((project['title'], project['category'], project['applications'], project['price'], project['description']))
#каждому параметру присвоим данные
except UnicodeEncodeError:
#в description иногда будут попадаться символы из других кодировок, придется брать как пустую строку
writer.writerow((project['title'], project['category'], project['applications'], project['price'], ''))
#каждому параметру присваиваем данные
Надеюсь, данная информация будет полезна в вашей работе. Желаю удачи.
Поделиться с друзьями
Комментарии (7)


alexmay
26.02.2017 19:50+1Нормальные комментарии, малех избыточны, но лучше чем никаких, а для обучения -самое то. )))


Zack
27.02.2017 10:29В заключении хорошо бы выдавать готовый скрипт, для тех, кто хотел бы опробовать результат.


LingvoLena
05.03.2017 15:11Интересная постановка задачи, но код требует доработки в плане оптимизации.
ookami_kb
Жесть. Это просто какая-то мешанина из объяснений синтаксиса питона, отвратительного кода, избыточности комментариев и издевательств над языком. Не надо так писать, даже для себя, а уж тем более учить такому других.