
Задача подсчета частоты употребления определенных букв в английских и русских текстах является одним из этапов лингво-статистического анализа. В каталоге Каталог лингвистических программ и ресурсов в Cети отсутствует программа на Python для решения указанной задачи.
На форумах по Python встречаются отдельные части такой программы, однако они ориентированы на один язык, главным образом английский. Учитывая это обстоятельство мной разработана программа для статистической обработки, как для русских, так и для английских текстов.
Импорт и начальные переменные
import matplotlib.pyplot as plt; plt.rcdefaults()
import numpy as np
import matplotlib.pyplot as plt
from tkinter import *
from tkinter.filedialog import *
from tkinter.messagebox import *
import fileinput
import matplotlib as mpl
mpl.rcParams['font.family'] = 'fantasy'
mpl.rcParams['font.fantasy'] = 'Comic Sans MS, Arial'
Открытие файла с английским текстом
def w_open_ing():
aa=ord('a')
bb=ord('z')
op = askopenfilename()
main(op,aa,bb)
Открытие файла с русским текстом
def w_open_rus():
aa=ord('а')
bb=ord('ё')
op = askopenfilename()
main(op,aa,bb)
Универсальная обработка данных для обоих языков
def main(op,aa,bb):
alpha = [chr(w) for w in range(aa,bb+1)] #обратное преобразование кода в символы
f = open(op , 'r')
text = f.read()
f.close()
alpha_text = [w.lower() for w in text if w.isalpha()] #выбор только букв и привидение их к нижнему регистру
k={} #создание словаря для подсчета каждой буквы
for i in alpha: #заполнение словаря
alpha_count =0
for item in alpha_text:
if item==i:
alpha_count = alpha_count + 1
k[i]= alpha_count
z=0
for i in alpha: #графическая визуализация данных в поле формы
z=z+k[i]
a_a=[]
b_b=[]
t= ('|\tletter\t|\tcount\t|\tpercent,%\t\n')
txt.insert(END,t)
t=('|----------------------------|-----------------------------|---------------------------|\n')
txt.insert(END,t)
for i in alpha: #графическая визуализация данных в поле формы
persent = round(k[i] * 100.0 / z,2)
t=( '|\t%s\t|\t%d\t|\t%s\t\n' % (i, k[i], persent))
txt.insert(END,t)
a_a.append(i)
b_b.append(k[i])
t=('|----------------------------|-----------------------------|---------------------------|\n' )
txt.insert(END,t)
t=('Total letters: %d\n' % z)
txt.insert(END,t)
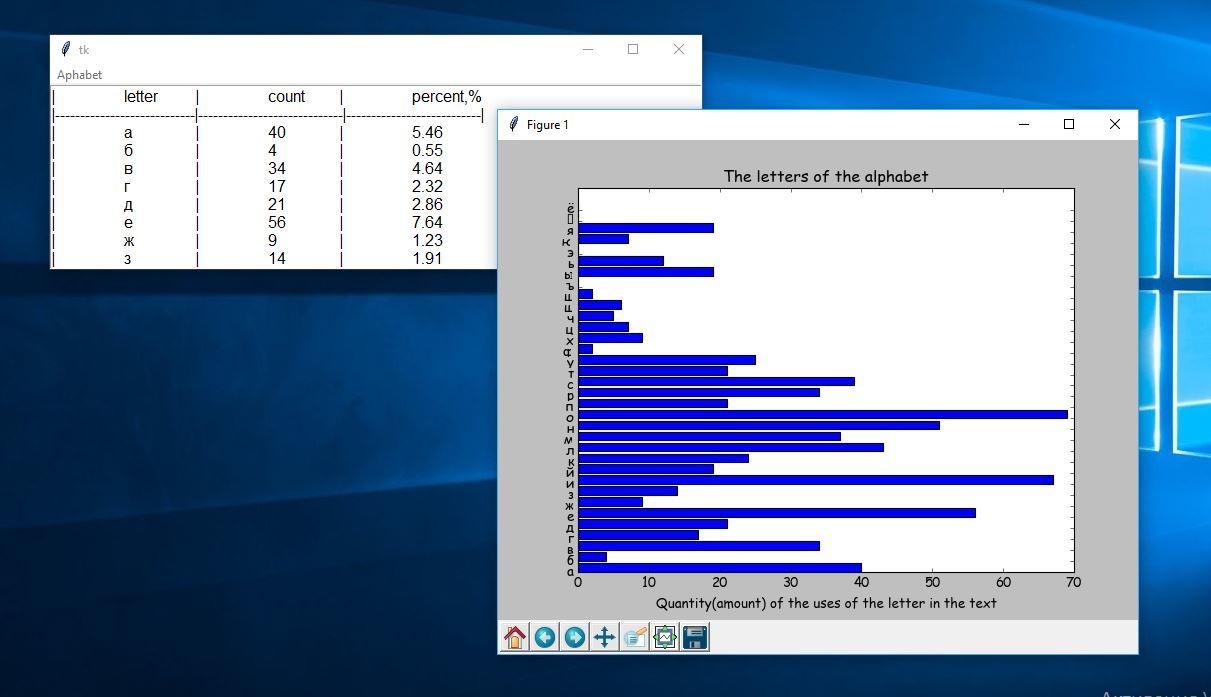
people=a_a #подготовка данных для построения диаграммы
y_pos = np.arange(len(people))
performance =b_b #подготовка данных для построения диаграммы
plt.barh(y_pos, performance)
plt.yticks(y_pos, people)
plt.xlabel('Quantity(amount) of the uses of the letter in the text')
plt.title('The letters of the alphabet')
plt.show() #визуализация диаграммы
Очистка поля
def clear_text():
txt.delete(1.0, END)
Запись данных из поля в файл
def save_file():
save_as = asksaveasfilename()
try:
x =txt.get(1.0, END)
f = open(save_as, "w")
f.writelines(x.encode('utf8'))
f.close()
except:
pass
Закрытие программы
def close_win():
if askyesno("Exit", "Do you want to quit?"):
tk.destroy()
Стандартный интерфейс ткинтер
tk= Tk()
main_menu = Menu(tk)
tk.config(menu=main_menu)
file_menu = Menu(main_menu)
main_menu.add_cascade(label="Aphabet", menu=file_menu)
file_menu.add_command(label="English text", command= w_open_ing)
file_menu.add_command(label="Russian text", command= w_open_rus)
file_menu.add_command(label="Save file", command=save_file)
file_menu.add_command(label="Cleaning", command=clear_text)
file_menu.add_command(label="Exit", command=close_win)
txt = Text(tk, width=72,height=10,font="Arial 12",wrap=WORD)
txt.pack()
tk.mainloop()
Преимущества
- Программа написана на Python, что упрощает ее использование в BigARTM и Gensim.
- Учитывает разницу русских букв «ё» и «е».
- Имеет графический интерфейс и при этом «распространяет свободно».
Поделиться с друзьями
Комментарии (6)

Amet13
05.03.2017 20:40+8SomeOneWhoCares и Scorobey либо один и тот же человек, либо два одногруппника.
Слишком много студенческих статей по питону за последнюю неделю, плюс перекрестные комментарии в топиках.
UPD: Вот еще один LingvoLena
Один вопрос, зачем?
Evgenym
05.03.2017 22:31+1Вероятно, близится защита диплома и хочется поделиться с миром своими наработками.
Amet13
05.03.2017 23:02+1Ну что ж, ждем тогда
парсинг сайтов с использованием lxml, urlib3 и pyparcing

YaakovTooth
09.03.2017 03:46+1Слишком сложные технологии, регулярные выражения и велосипед на сокетах — вот это действительно ждём.
Crandel
Позволю себе оставить несколько замечаний.
1) Все переменные надо называть так, чтобы было понятно их назначение, а не а_а и b_b. — Через месяц при необходимости что-то исправить или добавить фичу — надо будет потратить кучу времени на вникание в код.
2) В питоне считается нормой открывать файли через контекстные менеджеры with
3) Ваше посторение таблицы никуда не годится, сначала лучше все посчитать, постоить список словарей
А потом передать этот список в отдельную функцию, которая уже будет создавать таблицу по шаблону, что-то типа такого
4) Ну и обработка ошибок должна быть объязательно