
… На дворе стояла середина жаркого лета 2013-го. В компанию Х устроился молодой и слегка зеленый сисадмин, с базовым пониманием об администрировании и еще более базовыми знаниями php и сопричастными mysql, html, css, js.
Компания та была пропитана модными веяниями и на понятие «ИСУП» (Информационная Система Управления Проектами), разве что не молились, полагая что с введением оной, польются молочные реки и по нажатию 1 кнопки любой заказ будет выполнен четко, качественно и полностью автоматически.
Но, в связи с некоторыми особенностями работы компании Х, «стандартные» системы из коробки, к с частью или к сожалению, не подходили и именно с этого момента началась эта история…
Как это было до
Я не знаю, когда и как было принято решение руководством компании о том, что заказ = проект, и работаем по принципам «проектного управления», но к тому моменту, когда я стал сисадмином, существовал уже целый свод условных правил, по которому работала компания. Самой примечательной особенностью сей работы было полное отсутствие общей, хм, назовем это «базы данных проектов (заказов)» и состояния по оным.
Когда приходил новый заказ, менеджер лез в гуглдокс в определенную табличку, в ней были номера заказов, методом «ручного авто инкремента» рождался новый номер проекта, который так же заносился в табличку, дабы в следующий раз не задвоить проект. Далее печаталась форма, с названием проекта, его номером… в общем, с необходимыми данными для опознания. После «стадии регистрации», проекту выдавалась персональная папка и он отправлялся дальше по отделам, кол-во распечатанных листочков с информацией о комплектации, работах, сроках, поставщиках постоянно заставляло прибавлять в весе и объеме папку проекта. После завершения работ по проекту или отказе клиента, папка, временами очень упитанная, отправлялась в архив, которым служил обычный шкаф.
Руководство ставило себе 2 стратегически важных задачи:
- Найти подходящую систему для управления проектами
- Получить прозрачность и четкое понимание в каком состоянии находится тот или иной проект и почему
Анализ ситуации и первые «hello world'ы»
Руководство четко понимало, что система бумажного обмена имела ряд неудобств: от банальной нехватки места под хранение, до злободневной потери листков (папок) проектов, что влекло за собой просрочки в проекте или вообще — отказы. С увеличением заказов, данные неудобства превращались в критические проблемы, требующие решения «еще вчера».
В результате, было принято решение о создании некоторого исполина, под названием «ИСУП» на базе MS Project. Была написана достаточно объемная (порядка 150-200 страниц) документация с описанием бизнес-процессов, что должны были бы происходить с проектом в процессе его «жизненного цикла».
Ценник данного внедрения был в районе шестизначной суммы: сервер + софт. Все лицензированное. Так как сумма была несколько не маленькая и покупка всего — задача не на 1 день, было решено хоть как-то облегчить текущую ситуацию. Поэтому, была реализована следующая идея: была заведена электронная таблица, в которой указывалось название проекта, стадии, что он прошел, ответственные за стадии и дата завершения/отказа. Таблицу актуализировал отдельный человек, собирая информацию с подобных табличек, что находились в каждом отделе. Благодаря данному «решению» ситуация более-менее стабилизировалось, количество «косяков» уменьшилось, но вместе с «решением» пришли и «бонусы» в виде не всегда актуальной информации в таблицах отделов по причине обоснованных или придуманных оправданий, но, как говорится, на безрыбье и рак — рыба.
Время шло, но внедрение project'а по разным причинам тормозилось, а «бонусы» от «решения» становились все более и более значимыми и болезненными. И тут появилась «светлая идея» в моей голове — что если сделать небольшую табличку в MySql:
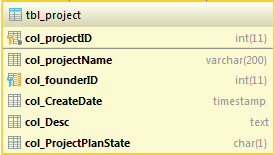
Приделать к ней некоторый интерфейс, например, на php, и получим вполне не плохой список проектов, а главное — он будет доступен всем и в одно и тоже время, и даже если каждый будет изменять данные, за которые он ответственен, не будет ругани от электронной таблицы, что сейчас уже кто-то открыл таблицу и нельзя ничего сохранить. Дешево и сердито! После некоторых консольтаций со своим руководителем отдела, идея стала известна «верхам». Сказано, согласовано — сделано.
Оставался открытым вопрос по поводу доступов и кто, что должен был делать и где сейчас «находится» проект? В результате, «список» оброс функционалом.
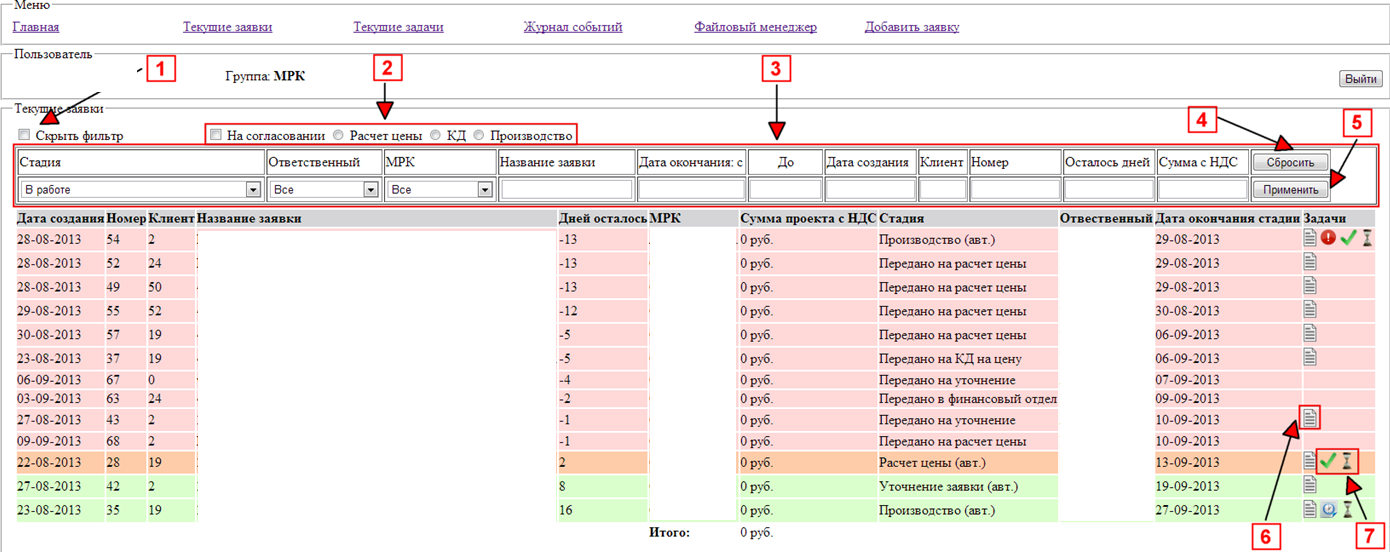
Начиная с этого момента, руководство начало задумываться на тем, а нужно ли тратить шестизначную сумму на кота в мешке, если есть руководитель IT отдела и его подчиненный сисадмин, которые, буквально, на коленке и за пару дней сделали «уже столько».
В общем, с того момента был дан карт-бланш на разработку собственной системы управления проектами на основе бизнес-процессов, что были разработаны под «ИСУП» на project.
Как это работало и работает
Под собственную систему был выделен отдельный компьютер, на которым был поднят apache + php + mysql.
Внутри система представляла собой обыкновенный сайт, написанный функциональным стилем.
с подключением через mysql_connect. К счастью, тот код уже утерян, поэтому обойдемся без примеров, как делать не надо.
К сожалению, совсем свежий пример показать не могу, по понятным причинам, однако, в качестве хобби, был создан небольшой проект на гите (ссылка в самом конце статьи), в котором аналог системы, что получилась в результате, без ряда особенностей бизнес-процессов фирмы и без пары особенностей, реализацию которых я, также, показать не могу.
Однако, о реализации проекта, что на гите — расскажу.
База системы работает на mysql.
Вся система идеологически «вертится» вокруг проекта. Проект имеет уникальный номер, но, что если проект может повторится, то есть, клиент закажет еще раз ту же услугу? Для этого номера вынесены в отдельную таблицу tbl_project_num, в которой номер и количество повторений
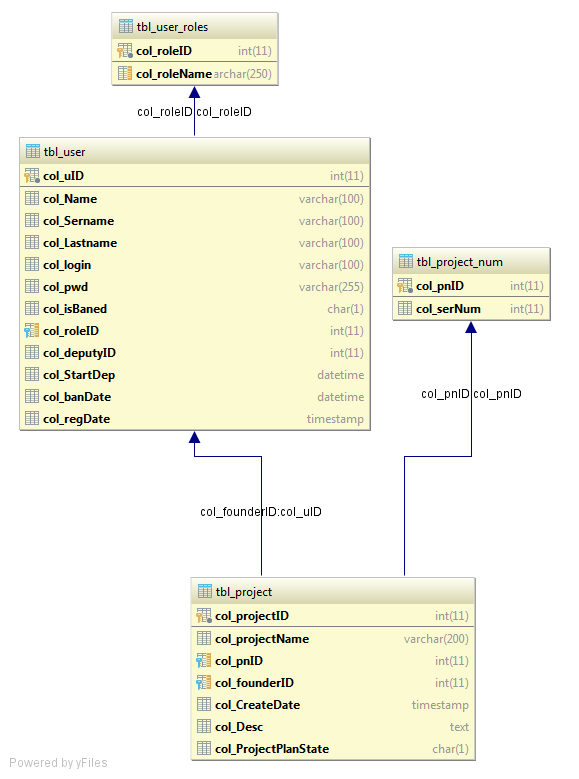
Также в проекте есть тот, кто его создал, в настройках «по default» — менеджер. Менеджер — пользователь, у которого есть определенная роль и он состоит в определенной группе. Роли собираются в группы:

По факту, роль — специальность, а группа — отдел.

Далее, каждый проект раздроблен на стадии, в 1 момент времени может быть активна только 1 стадия, но в каждой стадии может быть сколь угодно задач, запущенных с определенной последовательностью или без, которые никак не привязаны к статусу стадий. Примерно вот так:
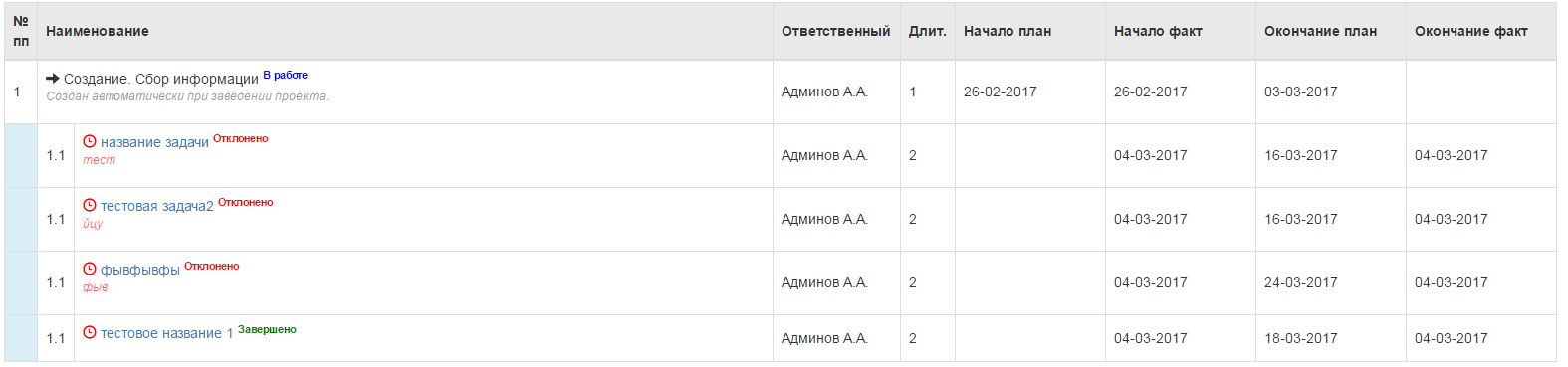
Итого получаем: проект со стадиями, и задачами, которые назначаются на основании стадии проекта.
Отдельно хочется упомянуть о планировании проекта:
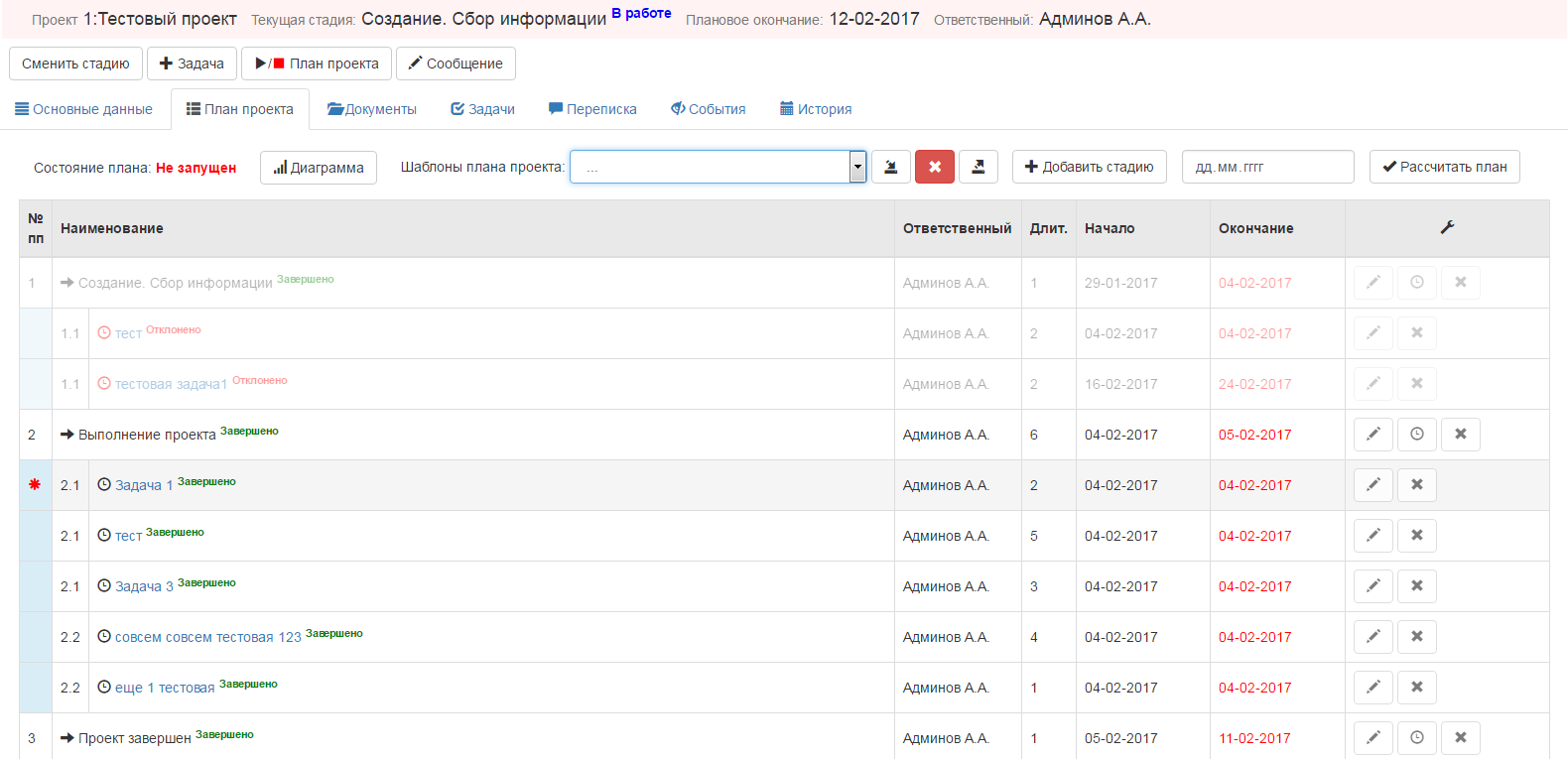
Можно запланировать весь проект, потом его запустить и в полуавтоматическом режиме — ну, нажимать на кнопку «передать проект дальше» придется, а еще придется писать причину, если просрочена стадия. Сразу хочется вспомнить пожелание руководства «чтобы по 1 кнопке все было», хотя, на самом деле, оно так не работает в 99% случаев — всегда есть какое-то «но». Хотя, в нашем случае, это из-за особенностей бизнес-процессов фирмы/типа проектов, тут ничего пока не сделать...
Так как проектов может быть не один, или по задаче пришло какое-то сообщение, был изобретен журнал событий, в аналоге системы оно выглядит так:
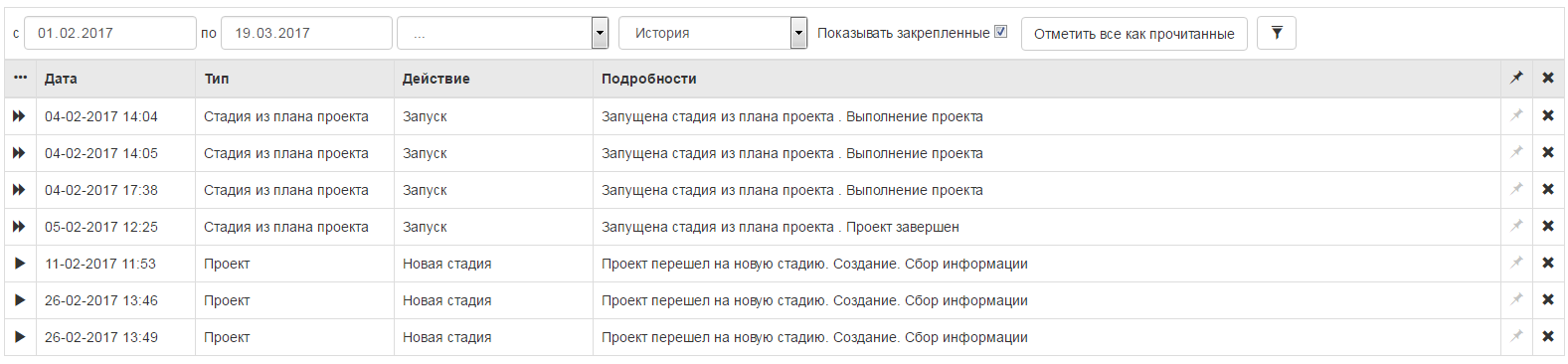
Принцип работы достаточно прост: в базе «вешаются» триггеры на создание/изменение записи в задачах, проектах, комментариях к задачам, переписке в проектах, в общем, везде, откуда нужно получить оповещение. При срабатывании триггера в базу данных в определенную таблицу, пишется запись: что случилось, куда идти, кому показать:
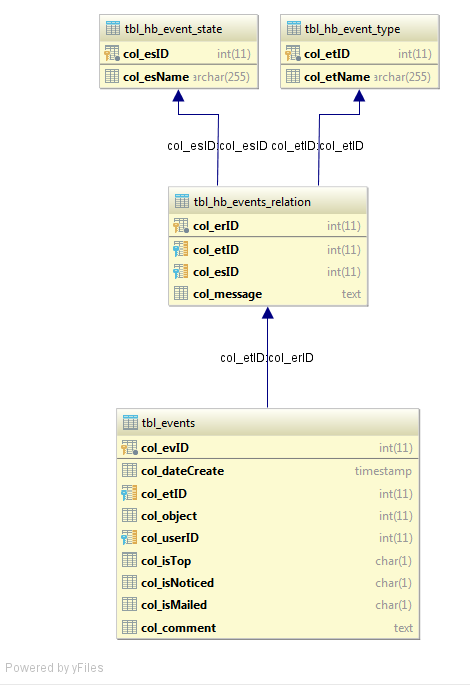
А дальше это можно отобразить в журнале, а можно и по почте послать (работу с почтой в реализации на гите пока не реализовывал, там будет использование крона) и даже больше — настроить подписку, что слать на почту, а что вообще везде игнорировать (в реализации на гите пока не реализовывал).
На самом деле, тут можно развернуть целый цикл статей, как и почему реализовывался каждый отдельно взятый модуль. Упомянуть об интерфейсе и почему он выполнен именно так, хотя, я ни разу не дизайнер и мое мнение весьма субъективно. Сейчас бы мне хотелось чуть-чуть упомянуть еще о реализации на php.
Вся система написана на php с применением MVC (а куда без него?). Кто-то пилил свой первый форум, кто-то — гостевую книгу, а я вот — небольшой и легкий движок все пилю. «Киллер фитч», по отношению к другим движкам — нет. Особенности, как и везде: создание модуля, возможность создавать плагины, возможность писать модули без использования MVC — обычным скриптом, правда, с рядом оговорок — использование классов все равно присутствует: шаблонизатор, работа с бд, конфиги и т.д. Можно создавать и использовать отдельные билды: по сути, готовые сайты, переключая в настройках параметры и/или изменяя оные в сессии к сайту. Есть возможность работы с кроном прямо из коробки, но это, действительно, другая история.
Суммарный итог
Все начиналось с шалостей и «временной замене электронных таблиц», а пришло к системе управления и планирования проектов, с возможностью хранения файлов, относящихся к проектам, с перепиской в задачах и проектах. Простая, как угол дома, не привязанная к определенной операционной системе, с исходниками «на руках», способная запуститься даже на домашнем NAS, если того требует ситуация. Но это лирика.
Системные требования:
- apache/nginx/вебсервер, что работает с php
- PHP 7
- MySQL 5.х + / MariaDB 10.х +
- ~ 10 МБ свободного места на диске (без учета хранения файлов)
Примерную реализацию можно посмотреть/скачать по ссылке в самом конце статьи.
Я не могу назвать получившуюся систему (что боевую, что аналог, что выложен на гите) лучшей, но согласитесь, системные требования подкупают, да и бесплатность с открытым кодом — тоже.
На данный момент, поделка на гитхабе — хобби и отработка некоторого полученного опыта, понятно, что 1 человек по определению гору вряд ли сдвинет, но если не поможет кому-то в подобной ситуации, то, хотя бы даст направление.
Очень буду рад, если оказался полезен. Одновременно, прошу прощения за:
- Скорее художественный, чем технический
- Сумбурное изложение
- Отсутствие, как такового, листинга с реализацией
- за найденные ошибки
Буду очень рад обоснованной критике.
Сторонние ресурсы
P.S.: Если статья пройдет модерацию, очень хочу передать привет и сказать спасибо своему бывшему руководителю отдела — он точно меня узнает по скринам с инструкции и тексту. Без него я бы не научился тому, чему он, собственно, меня и научил, хотя или нехотя.
Комментарии (41)

ellrion
22.03.2017 18:41+3Я не очень понял посыл статьи если честно, уж простите. Но вот я код посмотрел. Что сразу бросается в глаза так это бардак в именовании. Причешите. Это же делается не так долго. В идеале конечно же PSR. Паблик директория в проекте на php это просто необходимость. Вон только сегодня статья была про .git. Ну и т. д. Там много можно говорить. Не хочется хейтить и ругать просто так. Вам много еще нужно учиться это понятно. Но не написать, что ваш "роутер" сделал мне больно не могу)

UnknownQq
22.03.2017 19:53Статья о «боли» и о том, каким путем шли мы. Конечно, она несколько поздновато появилась, но все же. Правда, я несколько ушел не в сторону описания технических подробностей, а в сторону истории ситуации, возможно, потому что я участник оной.
По поводу PSR, вы имеете ввиду \\(\)* или я не совсем верно понял? В любом случае, спасибо, займусь.
HunterNNm
22.03.2017 23:21PSR — это про стандарт/рекомендация по написанию кода на php. Там и как правильно называть свои классы/методы есть. Например
namespace mwce\traits; trait tInsert
вообще не по psr
И да, венгерская аннотация уже давно не рулитUnknownQq
23.03.2017 08:08Спасибо, я знаю, что такое PSR, читал.
Возможно не вникал на все 100%, но читал и некоторых вещей я придерживаюсь. В связи с тем, что работаю не в команде с умными ребятами, а большею часть времени 1, о некоторых вещах забываю или не знаю. Если Вам не сложно, ткните меня носом в ту часть, где мне требуется особо уделить внимание, раз мой код Вы изучали.
ellrion
23.03.2017 12:55Почему у вас классы то в UpperCamelCase, то lowerCamelCase, то с нелепейшим постфиксом
_. Поддиректория (и поднеймспейс) для ошибок есть и с большой буквы, а для трейтов с маленькой. При этом интерфейсы своей поддиректории лишены. Чем они хуже?) Префиксы венгерской нотации то большая буква, то маленькая а например трейт синглтон обделен префиксом. Что он вам сделал? И т.д. и т.п. Вот что я имел ввиду под "причесать именование".
По PSR я имел ввиду не только 4 ый для автолоудинга а больше второй.
Но это всё косметика, гораздо хуже godobject'ы (типо роутер). Называние вещи не своими именами (тот же роутер, MVC и т.д.). Методы по 100 строк. Проблемы безопасности. И так далее.

Merkat0r
22.03.2017 23:17Начиная с этого момента, руководство начало задумываться на тем, а нужно ли тратить шестизначную сумму на кота в мешке, если есть руководитель IT отдела и его подчиненный сисадмин, которые, буквально, на коленке и за пару дней сделали «уже столько».
Я так понимаю, а Вы это все сделали тупо «нахаляву» в рамках обычной зп?UnknownQq
23.03.2017 08:10я это все делал потому, что было интересно и я многому в процессе научился. Но, таки, да — первое время «нахаляву».
michael_vostrikov
23.03.2017 06:19+4То, что проект работает и приносит пользу, это хорошо.
Но вот по коду много недостатков, не в плане придирок к стилю (хотя это тоже), а в плане его работы. Неплохо, что есть автозагрузка и нечто вроде миграций в папке SQL. Есть еще шаблонизатор, но я почему-то не нашел, где делается экранирование HTML. В целом, самописный движок не всегда хорошая идея.
Вся система написана на php с применением MVC
Как я понял, моделей как таковых у вас нет, вся работа ведется с массивами, только функции для работы с ними разбиты на классы.
небольшой и легкий движок
Возможны SQL-инъекции, например тут. И вообще, именованные параметры почти не используются.
Часть логики в базе — sp_CalcProjectPlan, sp_setTaskPlanQuenue.
Сокращения, префиксы, много сырого SQL, делают код не особо понятным.
ну, меня учили «правильно» давать имена, чтобы в запросе четко понимать что есть что: функция «fn_» или «f_», процедура «sp_»/«spp_», ну и триггер «t_», из основных.
Вас неправильно учили. Вернее, это подходит в каких-то случаях, но далеко не всегда, а тем более в веб-приложении. В основном это создает лишний информационный шум.
UnknownQq
23.03.2017 08:34Спасибо за отзыв!
нечто вроде миграций в папке SQL
Это установочные скрипты. Просто, я не только для этого «сайта» использую свою поделку, поэтому это как некоторая унификация — в папку SQL класть то, в чем инсталка будет искать дамб для СУБД. Я разбил общий дамб базы на скрипты, чтобы удобно было вносить изменения + для дебага это проще, на мой взгляд. К более стабильной версии, подумываю собрать все обратно в 1 файл.
я почему-то не нашел, где делается экранирование HTML
Это описано в mwce/Controller. + есть конструкция уже в чаилдах контроллера типа:
protected $postField = [ 'cardID' => ['type'=>self::INT], 'step' => ['type'=>self::INT], ]; protected $getField = array( 'type' => ['type'=>self::INT], 'uid' => ['type'=>self::INT], );
и при этом не изменено родительское:
protected $needValid = true; //проверять или нет пост и гет
То идет валидация.
Принцип работы: контроллер, если на то есть «указания», перебирает POST и/или GET-массивы и изменяет в нем данные в соответствии с оными. Если вообще нет никаких указаний, то он GET и POST просто экранирует от html символов.
Как я понял, моделей как таковых у вас нет, вся работа ведется с массивами, только функции для работы с ними разбиты на классы.
для меня модели — то место, где идет работа с базой данных и может храниться результат выборки, возможно даже отформатированный некоторым образом. Контроллеру обычно все равно, каким образом получаются данные, они ему нужны для манипуляций, иногда определенным образом отформатированные, а уж из базы они или из файла — это вопрос модели.
Базовая модель описана в mwce/Model. Для моих задач оно вполне подходит, если у Вас есть другое мнение — с интересом выслушаю.
Вас неправильно учили. Вернее, это подходит в каких-то случаях, но далеко не всегда, а тем более в веб-приложении. В основном это создает лишний информационный шум.
а вот тут возражу — на вкус и цвет. Моя цель — написать код так, чтобы потом кто-то другой в нем мог ориентироваться и как можно быстрее, я считаю, точнее научен был, что так вполне удобно и понятно. Пока лучше варианта, к сожалению или, к счастью, не видел.michael_vostrikov
23.03.2017 09:59Принцип работы: контроллер, если на то есть «указания», перебирает POST и/или GET-массивы и изменяет в нем данные в соответствии с оными.
А если в базе уже есть неэкранированные данные, которые попали туда, когда для этого поля не было экранирования (по ошибке например), или помимо этой формы (через какой-нибудь импорт)? Экранировать лучше во время вывода, а базе хранить то, что пришло. Потому что в некоторых случаях надо выводить не в HTML-контекст, в некоторых нужен исходный текст для поиска по нему, исходники нужны всегда. Для предотвращения SQL-инъекций свое экранирование нужно.
Контроллеру обычно все равно, каким образом получаются данные
Базовая модель описана в mwce/Model. Для моих задач оно вполне подходит, если у Вас есть другое мнение — с интересом выслушаю.Контроллеру все равно, а другим моделям нет. В бизнес-логике надо использовать термины предметной области, а не массивы. А из базы они или из файла, модель тоже знать не должна, это отдельный слой. Впрочем, в некоторых случаях они смешиваются, если до какой-то степени не мешают друг другу (ActiveRecord). Тем не менее, все равно используются типизированные объекты.
а вот тут возражу — на вкус и цвет. Моя цель — написать код так, чтобы потом кто-то другой в нем мог ориентироваться и как можно быстрее
А вот для этого как раз и придумали PSR, и не рекомендуют использовать сокращения. Префиксы подходят там, где часто используются несколько схожих вариантов, и по-другому получить информацию долго, и обычно показывают несовершенство языка или окружения. А в выражении "SELECT something FROM somewhere" и так понятно, что something это колонка, а somewhere таблица. А если зачем-то в MySQL понадобились вьюшки, и надо обязательно не спутать, им можно и префикс 'v_' добавить. А уже если ORM использовать, то в объектах префиксы колонок вообще не к месту.
UnknownQq
23.03.2017 10:35А если в базе уже есть неэкранированные данные, которые попали туда, когда для этого поля не было экранирования
Это универсальный подход. Я при разработке привык, что люди изначально экранируют данные, чтобы не поймать инъекцию, но в то же время, в Model есть конструкция позволяющая при получении полей «вертеть» ими как пожелается:
protected function _adding($name, $value) { switch ($name){ case 'col_date': $value = date_::transDate($value); break; case 'col_dateVidal': $value = date_::transDate($value); break; case 'col_Value': $value = (float)$value; break; case 'col_desc': $value = htmlspecialchars_decode($value); break; case 'col_vidano': if($value == 1) parent::_adding($name.'Legend', 'Да'); else parent::_adding($name.'Legend', 'Нет'); break; } parent::_adding($name, $value); }
в некоторых нужен исходный текст для поиска по нему
Этим можно управлять на уровне контроллера или в функции добавлении записи в модели.
предметной области, а не массивы.
я использую PDO, в нем есть конструкции: fetch(static::class), fetchAll(static::class), что позволяет вместо массивов использовать классы. Поэтому в 1 записи выборки находится не массив, а класс, который между делом, с помощью «магических функций» может «изображать» из себя массив, не теряя при этом и методы, которые можно вызывать. Почти ActiveRecord, в общем. До «не почти» не хватает унификации.
А вот для этого как раз и придумали PSR...
учту, спасибо.michael_vostrikov
23.03.2017 11:04Я при разработке привык, что люди изначально экранируют данные, чтобы не поймать инъекцию
Мне кажется, вы путаете MySQL-экранирование и HTML-экранирование. При подстановке в SQL-запрос данные надо экранировать всегда (через PDO::quote, хотя лучше использовать именованные параметры), чтобы не нарушился синтаксис запроса. После этого в базе лежат сырые данные. При выводе их в HTML надо экранировать через htmlspecialchars, при подстановке в другой SQL-запрос через PDO::quote, при выводе в JavaScript через json_encode, а при использовании в URL через urlencode.
Этим можно управлять на уровне контроллера или в функции добавлении записи в модели.
Ну вот добавили мы неэкранированную запись в базу для поиска, а как ее выводить? Или вы предлагаете дублировать данные специально для поиска? А если у нас система переводов, которые хранятся в исходном коде в отдельных файлах? В одном языке нет кавычки в слове, в другом есть. Просто раз у вас отдельный шаблонизатор, то проще в нем один раз написать экранирование и все.
я использую PDO, в нем есть конструкции: fetch(static::class), fetchAll(static::class)
А, я пропустил этот момент. Да, тогда почти ActiveRecord.
UnknownQq
23.03.2017 11:16При подстановке в SQL-запрос данные надо экранировать всегда (через PDO::quote, хотя лучше использовать именованные параметры)
Да, я действительно не совсем понял, однако, используется прием prepare->execute, который данную проблему решает, судя по документации в моей интерпретации.michael_vostrikov
23.03.2017 13:59Да, только массив $bind у вас нигде не используется, вы подставляете параметры напрямую в текст запроса.
UnknownQq
23.03.2017 14:28согласен, я думал об этом, но, так как сам не использую, четно говоря, не могу сказать почему, поэтому и не реализовывал. Хотя, стоило.

ilshat78
23.03.2017 11:37-5Вас неправильно учили. Вернее, это подходит в каких-то случаях, но далеко не всегда, а тем более в веб-приложении. В основном это создает лишний информационный шум.
В вопросе именования объектов БД — всё абсолютно чётко!
Это вас, таки, неправильно учили, и вы теперь свое неправильное мнение другим сообщаете. Может быть в PHP коде вы и разбираетесь, но с базами данных, похоже, работали мало. Такое именование объектов маст хев в мире разработки БД.ellrion
23.03.2017 12:39+2Венгерская нотация сама по себе раскритикована уже давным давно. А тут она еще вместе с адово неоднородным стилем именования — имена таблиц
snake_caseа столбцов после префиксаcol_тоlowerCamelCaseтоUpperCamelCaseто внезапно просто слово что в итоге даетsnake_case. Это же ппц какой то.
Но даже будь оно всё однородно вsnake_case. Наличие префиксов что нам дают? Приведите мне пример когда я не могу однозначно трактовать идентификатор чего передо мной?ilshat78
23.03.2017 12:45-2Да в коде неоднородная смесь. Но я говорю прежде всего о префиксах.
Приведите мне пример когда я не могу однозначно трактовать идентификатор чего передо мной?
Простейшее:select id from orders
Откуда поступают данные из таблицы или из вьюхи или из функции? Прошу вас с первого раза точно трактовать, что перед вами :)michael_vostrikov
23.03.2017 14:20+2Во-первых, какое мне дело, откуда у меня идут данные? Надо будет, залезу в базу и проверю. Во-вторых, насколько я знаю, в MySQL нельзя сделать SELECT из процедуры. В третьих, если у вас вся логика в БД, возможно вам удобнее с префиксами, а если у меня логика в приложении, то префиксы мне только мешают. Потому что я знаю, что у меня есть только таблицы и колонки, которые находятся в разных частях запроса, который во многих случаях генерируется ORM.
ilshat78
23.03.2017 12:51-3Венгерская нотация сама по себе раскритикована уже давным давно.
Я, похоже, ретроград и отстал от поезда. И какой стайлгайд сейчас в моде?
ellrion
23.03.2017 12:43+1Или приведите чей то стайлгайд для БД хоть более менее используемый приведите в котором есть венгерская нотация в именовании.

alexkrash
23.03.2017 13:12+1Внутри система представляла собой обыкновенный сайт, написанный функциональным стилем.
К проектам на PHP, как правило, применимо «процедурным» стилем (если имелось в виду нагромождение функций, а не оперирование функциями высших порядков).UnknownQq
23.03.2017 13:15ну я к тому, что можно писать и ооп и без ооп, при желании. Особенно, когда кто-то к поделке начинает прилаживать перламутровые пуговицы, но в php не сильно искушен.

molnij
23.03.2017 18:46#Ох сколько вас открытий чудных ждёт…
Я даже не знаю с чего начать
Если вашей компании было достаточно того, что описано в статье, вам действительно не нужно было решение на базе Project Server'а за шестизначную сумму внедрения
Но можно ж было начать с куда более приземленных вариантов… Мегаплан, любой из айтишных таск-трекеров. Да на худой конец, тот же файлик MSProject'а на сетевом диске, или ваш эксель в тех же гугл-доксах, чтобы проще переживать блокировки
И если не секрет, сколько времени с 2013 года заняла работа над проектом?UnknownQq
23.03.2017 20:42Это далеко не все. То, что описано тут + то что выложено на гите примерно 40-50% в не очень подробном пересказе от того что реально есть. На гите, по сути, лежит система управления проектами, а сейчас актуальная система, уже более года как, erp.
В ней создают комплектацию с деталями, потом просчитывается по описанной технологии стоимость + работы оборудования… в общем, сейчас это похоже на упрощенную веб-версию СПРУТ ТП, правда, не по ГОСТам и не на столько «умная» она как спрут, хотя, над этим работаем. Спрут нам не подходит в виду специфики — все рассчитано на партии, а у нас единичные проекты, но много, а партии крайне редко, да и стоимость — мое почтение. + наше руководство поняло, что каждое их «хочу» может быть реализовано, поэтому в системе присутствует и свой ServiceDesc и свой багтрекер и целая уже куча нормативных документов, которые описывают когда и что куда писать и как происходит согласование и разработка новых модулей.
В общем, из того что за эти 3+ года произошло, можно уже статью написать про ошибки неконтролируемых хотелок заказчика и чем это чревато, но таких статей — уже пруд пруди.michael_vostrikov
24.03.2017 04:36Вы бы переписали на фреймворке каком-нибудь. Yii2 больше подойдет, с ним есть некоторое сходство в архитектуре. У вас больше половины кода сократится.
UnknownQq
24.03.2017 08:24Спасибо за рекомендацию.
В статье я писал, что кто-то пишет форумы, кто-то гостевые книги, а у меня — все не как у людей, сел писать свой движок. Чужой код — всегда чужой, а свое как-то ближе к сердцу — это было девизом.
Совру, если скажу, что совсем не думал о фреймворках, но… «зачем мне использовать монстра, когда особо много-то не надо» — именно такие мысли были тогда, когда это можно было делать. А когда в самой системе порядка 17 плагинов + 128 модулей ±, как-то уже поздновато. Да и, действительно, уютней когда знаешь, что ожидать от движка.

sspat
25.03.2017 23:38Посмотрел код, видно, что не бездумно делалось, но есть одна проблема. Из-за того что вы так долго делали в одиночку этот проект в полной изоляции, он очень сильно оброс понятными только вам одному конструкциями, конвенциями именования и т.д. Вы буквально стали незаменимым сотрудником. Хорошо это или плохо — смотря с чьей позиции смотреть. Я бы на вашем месте, если вы не планируете конечно там проработать до пенсии, начал думать о том, как это в случае чего передавать кому-то другому. Начал бы потихоньку переписывать на каком-то популярном фреймворке, ознакомился бы с актуальными стандартами, тесты, документация. Если убрать из вашего кода все велосипеды и использовать готовое, обьем уже не будет так пугать. Иначе в один прекрасный день компания может столкнуться с ситуацией, которая обойдется ей гораздо дороже, чем то первоначальное предложение с шестизначной суммой.
UnknownQq
26.03.2017 07:26Спасибо за рекомендацию. Согласен с Вами и не согласен одновременно. То, что глаза «замылены» — факт, но… в то же время стартапы именно так и рождались. Я сам чувствую, что засиделся в «изоляции» и именно с этой целью статья тут появилась — нужно было выйти на улицу, подышать свежим воздухом и отдохнуть.
На самом деле, получил огромное количество рекомендаций и советов, за что огромное спасибо всем, кто учавствовал. В данном случае, мне бы хотелось поднять свой велосипед на уровень выше, чем пересаживаться на чужой, который изнутри мне только только предстоит изучить. Моя «стратегия»: разбери, посмотри, что там внутри и как оно работает и подумай, чем оно тебе может пригодится и, если надо, реализуй. В противном случае, я просто буду бездумно использовать принципы, в которых вообще ничего не понимаю. Для меня, это страшнее изоляции.

vtvz_ru
Объясните мне, пожалуйста, зачем в колонках нужен префикс «col_»; вместо обычного «id» используется «projectID»; а в некоторых местах название поля с большой, а в других с маленькой буквы («projectID» vs «Desc»)? Недавно я поднял, что префикс таблиц «tbl_» нужно использовать, потому что есть еще и представления (view). Может быть и этот момент мне кто-нибудь разъяснит?
UnknownQq
ну, меня учили «правильно» давать имена, чтобы в запросе четко понимать что есть что: функция «fn_» или «f_», процедура «sp_»/«spp_», ну и триггер «t_», из основных. Я не использовал конструкции того же мускула где бы я мог спутать (ну, кроме вьюшек) элемент по его названию, но уже привык и как-то очень даже удобно. Многие пишут префиксы перед primary key: «PK». Хотя, мне, если честно, на ум приходит только дамб базы, там эти обозначения очень даже уютны.
Fesor
мне как-то казалось что при именовании вещей важно что они делают а не "что это такое". А префиксы виде
col_создают ненужный информационный шум, оно и так понятно из контекста что это колонки. Возможно вы уже просто привыкли к этому уровню шума и опускаете его, но это вы.Пример с тем же тригером например вообще невалидный. Семантика тригера все же — обработка какого-то события, потому достаточно назвать его например
on_new_clientк примеру.Я понимаю что все это субъективщина, но… просто меня всегда напрягали слепые конвенции которые заставляют больше внимания уделять несущественным мелочам нежели основному смыслу.
UnknownQq
ну, эти конвенции становятся очень полезными, когда появляются гигантские и «веселые» запросы, например, в процедурах. Раньше я действительно особо не думал о названиях и есть до сих пор, в силу некоторых обстоятельств, в боевой базе «id», «uid» и т.п. И когда в очередной раз пишешь запрос, где ~ 5-8 таблиц с группировками, с хитрыми условиями + есть функции, такие вот названия вызывают «боль».… А если еще все это в большущей процедуре, которая формирует важные отчеты, например, по зарплате, то «боль» двойная.
Я, конечно, не блещу сильными познаниями SQL и, возможно, как-то можно и по-другому было организовать алгоритм формирования, однако, сделано пока так и там префиксы очень помогают. Хотя, все, опять же, субъективно.
JSmitty
В гигантских запросах гораздо удобнее использовать префиксы, которые как-то обозначают таблицы, тогда например JOIN можно писать без указания таблиц (usr_ -> users, nws_ -> news), поскольку в разных таблицах колонки будут иметь уникальные названия. Префикс col у всего действительно не очень полезный. Нормальный редактор SQL даст подсказки для имен колонок и таблиц.
michael_vostrikov
В гигантских запросах лучше алиасы писать (users u, news n).
А еще лучше не писать гигантские запросы.Оффтоп.
Лучше бы в MySQL вместо using(название поля) сделали форму using(название внешнего ключа). Было бы сильно удобнее пользоваться.
CrazyNiger
Если использовать «projectID» как в основной таблице, так и в таблицах которые будут ссылаться на нее, то можно в описании условий объединения таблиц использовать «using(projectID)» вместо on (project.projectID = other_table.projectID). И при получении данных из таблицы в ПХП понятнее какой ID из какой таблицы (если получаем результат джойна таблиц)
kester
Это распространённая практика, она облегчает работу со сложными запросами.
Преимущество хорошо описано здесь: http://stackoverflow.com/a/208631/7074052